Chapter 14. TCP Timeout and Retransmission
- 과목: Computer Network
- 기준 교재: TCP/IP Illustrated, Volume 1
- 관련 페이지: PDF pp. 686-729
- 우선순위: 필수
개요
TCP는 IP 위에서 reliable data delivery를 제공하지만, IP는 packet을 잃거나(loss), 중복하거나(duplication), 순서를 바꿔(reordering) 전달할 수 있다. TCP가 reliable byte stream을 유지하려면 “어떤 data가 사라졌다고 판단할 것인가”와 “그때 무엇을 다시 보낼 것인가”를 계속 결정해야 한다. 이 장의 주제는 TCP retransmission, 즉 timeout과 ACK 구조를 이용해 loss를 추정하고 복구하는 방법이다.
TCP retransmission은 크게 두 축으로 이해한다. 첫째는 timer-based retransmission이다. TCP가 data를 보낼 때 retransmission timer를 걸고, ACK가 오기 전에 timer가 만료되면 RTO(Retransmission Timeout)에 의해 해당 data를 다시 보낸다. 둘째는 fast retransmit이다. cumulative ACK가 전진하지 않거나 SACK(Selective Acknowledgment)이 out-of-order data block을 알려 주면, timer 만료를 기다리지 않고 loss를 추정해 더 빠르게 재전송한다.
이 장은 RTO를 RTT(Round-Trip Time) 측정으로 어떻게 설정하는지, timeout이 실제로 어떤 재전송을 일으키는지, duplicate ACK와 SACK이 어떻게 missing data를 드러내는지, spurious retransmission/reordering/duplication이 왜 TCP를 헷갈리게 하는지, 그리고 repacketization과 retransmission 관련 attack이 어떤 문제를 만드는지 다룬다.
핵심 개념
- RTO(Retransmission Timeout)는 TCP가 ACK를 기다리는 시간이다. 너무 짧으면 불필요한 retransmission이 늘고, 너무 길면 실제 loss 복구가 늦어진다.
- TCP는 RTT sample을 바탕으로 SRTT(smoothed RTT), RTTVAR(RTT variation), RTO를 계산한다.
- timer-based retransmission은 timeout이 발생해야 시작되므로 보통 느리지만, ACK 정보가 충분하지 않은 loss에서는 마지막 안전망이다.
- fast retransmit은 duplicate ACK 또는 SACK 정보를 이용해 timeout 전에 loss를 추정한다.
- SACK은 receiver가 이미 받은 out-of-order block을 sender에게 알려 주므로, 여러 hole을 더 효율적으로 복구할 수 있다.
- spurious timeout/retransmission은 실제 loss가 아닌 delay spike, reordering, duplication 때문에 TCP가 잘못 재전송하는 상황이다.
- retransmission 판단은 congestion control과 강하게 연결된다. 무엇을 다시 보낼지는 이 장의 주제이고, 얼마나 보낼지는 Chapter 16의 주제다.
세부 정리
14.1 Introduction
앞 장들까지는 TCP가 올바르게 동작하는가, 즉 connection을 만들고 byte stream을 순서대로 전달할 수 있는가가 중심이었다. Chapter 14부터는 TCP가 얼마나 효율적으로 동작하는가가 중요해진다. TCP는 error-free exchange를 제공하기 위해 receiver에서 sender로 계속 흐르는 ACK stream에 의존한다. data segment나 ACK가 손실되면 sender는 아직 acknowledgment를 받지 못한 data를 retransmit한다.
TCP가 loss를 판단하는 방법은 두 가지다.
| 방식 | trigger | 장점 | 한계 |
|---|---|---|---|
| timer-based retransmission | retransmission timer 만료 | ACK 정보가 부족해도 동작하는 기본 안전망 | RTO까지 기다리므로 느릴 수 있음 |
| fast retransmit | duplicate ACK 또는 SACK 정보 | timeout 없이 빠르게 loss 복구 가능 | ACK 구조가 loss를 충분히 드러내야 함 |
fast retransmit은 대개 timer-based retransmission보다 효율적이다. cumulative ACK가 계속 같은 ACK number를 반복하거나, SACK option이 receiver에 out-of-order segment가 있음을 알려 주면 sender는 “중간의 data가 빠졌을 가능성”을 추정한다. 이때 sender는 새 data를 보낼지, 이미 보낸 data를 retransmit할지 선택해야 한다.
다만 이 장은 “무엇을 retransmit할 것인가”를 주로 다룬다. loss가 congestion을 의미할 수 있으므로 “얼마나 많이 보낼 것인가”는 congestion control 문제이며 Chapter 16에서 다룬다.
14.2 Simple Timeout and Retransmission Example
timeout과 retransmission은 이전 장들에서도 이미 등장했다. UDP 기반 TFTP client가 고정 5초 timeout으로 재전송하던 단순 전략, Chapter 13에서 nonexistent host에 TCP SYN을 보낼 때 점점 길어지는 재시도 간격, Chapter 3의 Ethernet collision backoff는 모두 timer expiration으로 시작되는 복구/재시도 메커니즘이다.
본문 예제는 client가 Web server와 TCP connection을 established한 뒤 server host를 분리하고, client가 GET / HTTP/1.0 요청을 보내는 상황이다. server가 분리되어 있으므로 이 요청은 전달되지 못하고 client TCP send queue에 남는다. netstat 출력에서 Send-Q = 18로 보이는 18 bytes는 HTTP request 문자와 CRLF 쌍들을 포함한 data다.
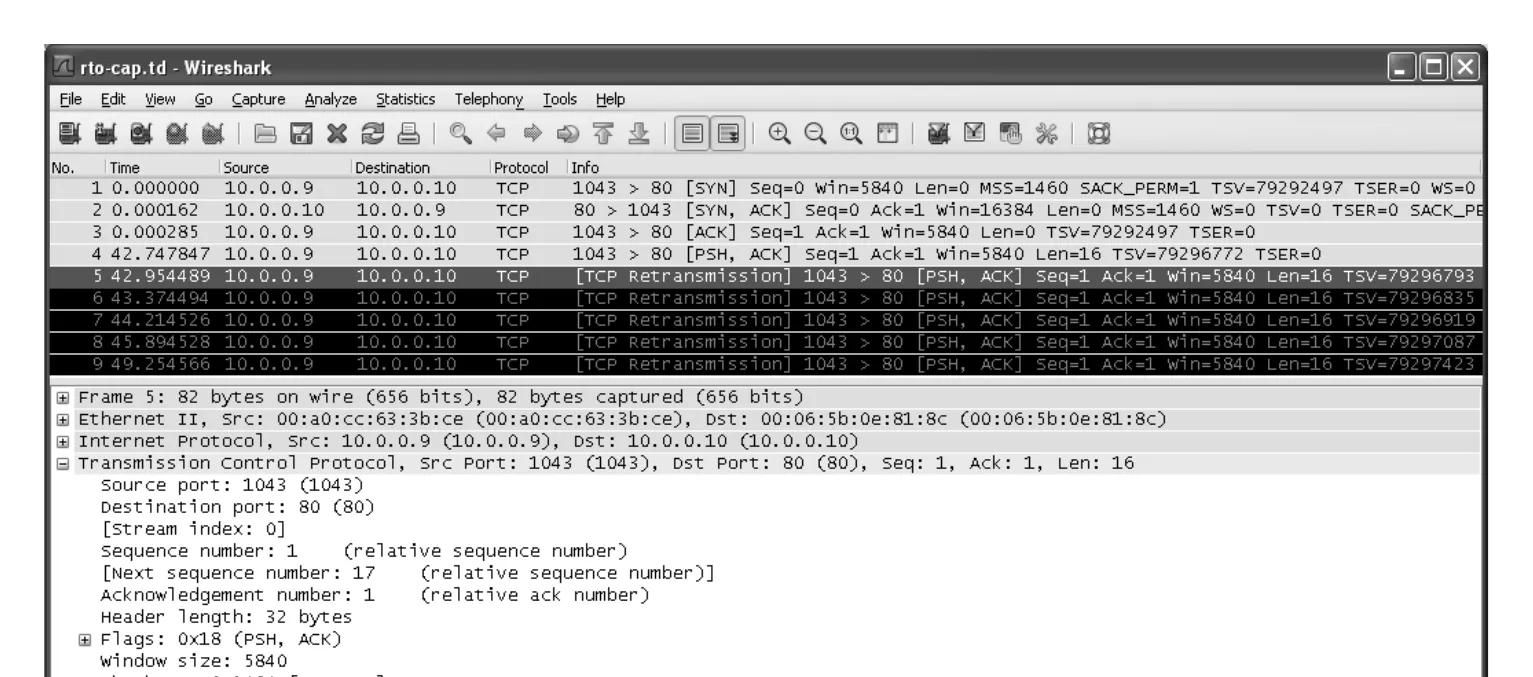
Figure 14-1 · PDF p. 688 · timer-based retransmission과 timeout doubling 예제
Figure 14-1에서 client는 segment 4로 처음 request를 보낸 뒤 ACK를 받지 못한다. 이후 같은 segment를 반복 retransmit하는데, 각 retransmission 간격이 대략 206ms → 420ms → 841ms → 1.68s → 3.36s처럼 증가한다. 같은 segment에 대해 timeout 간격이 두 배씩 늘어나는 이 패턴을 binary exponential backoff라고 한다.
TCP는 무한정 같은 segment를 다시 보내지 않는다. RFC 1122 계열 설명에서는 두 threshold를 둔다.
| Threshold | 의미 | 대표 목적 |
|---|---|---|
| R1 | 일정 횟수/시간 동안 재전송 실패 후 IP layer에 negative advice 전달 | route 재평가 등 하위 layer 힌트 |
| R2 | 더 큰 한계에 도달하면 connection 포기 | connection abort |
R1은 적어도 3 retransmissions, R2는 적어도 100초가 권장된다. SYN segment의 connection establishment 재시도에는 data segment와 다른 값이 쓰일 수 있고, SYN의 R2는 적어도 3분이어야 한다.
Linux에서는 regular data segment의 R1/R2가 net.ipv4.tcp_retries1, net.ipv4.tcp_retries2로 노출된다. 이 값들은 시간 단위가 아니라 retransmission 횟수다. 기본 tcp_retries2 = 15는 connection RTO에 따라 대략 13-30분 정도에 해당할 수 있고, tcp_retries1 = 3이 기본이다. SYN에는 net.ipv4.tcp_syn_retries, net.ipv4.tcp_synack_retries가 대응한다. Windows에서는 TcpMaxDataRetransmissions가 Linux의 tcp_retries2와 비슷한 역할을 한다.
정적 환경이라면 timeout 값을 하나로 고정할 수도 있겠지만, TCP는 LAN, WAN, wireless, rerouted path, congestion 등 다양한 환경에서 동작해야 한다. link failure로 traffic path가 바뀌면 RTT가 크게 변할 수 있다. 따라서 TCP는 current situation에 맞춰 RTO를 동적으로 결정해야 한다.
14.3 Setting the Retransmission Timeout (RTO)
RTO 설정의 핵심은 특정 connection에서 경험하는 RTT를 계속 측정하고, 그 변화에 맞춰 timeout 값을 조정하는 것이다. RTO가 실제 RTT보다 너무 짧으면 sender는 아직 도착 가능한 segment를 lost로 오판해 duplicate traffic을 네트워크에 넣는다. 반대로 RTO가 RTT보다 너무 길면 실제 loss가 발생했을 때 idle 시간이 길어지고 single-connection throughput이 떨어진다.
RTT sample은 특정 sequence number를 가진 byte를 보낸 뒤, 그 byte를 cover하는 ACK가 돌아올 때까지 걸린 시간이다. TCP는 connection별로 RTT estimator를 따로 유지한다. sequence number를 소비하는 data가 in flight이면, SYN/FIN을 포함해 retransmission timer가 하나 pending될 수 있다.
14.3.1 The Classic Method
original TCP specification(RFC 0793)의 classic method는 SRTT(smoothed RTT)를 EWMA(Exponentially Weighted Moving Average), 즉 low-pass filter로 갱신한다.
SRTT <- alpha * SRTT + (1 - alpha) * RTTsRTTs는 새 RTT sample이고, alpha는 smoothing factor다. 권장 범위는 0.8-0.9였으므로 새 SRTT의 80-90%는 이전 estimate, 10-20%는 새 sample에서 온다. 이 방식은 이전 SRTT 하나만 저장하면 되므로 구현이 간단하다.
classic method의 RTO 계산은 다음 형태다.
RTO = min(ubound, max(lbound, beta * SRTT))beta는 delay variance factor로 1.3-2.0 정도가 제안되었고, lbound는 lower bound, ubound는 upper bound다. 결과적으로 RTO가 대개 1초 또는 SRTT의 약 두 배로 설정된다. RTT 분포가 안정적인 네트워크에서는 충분했지만, RTT 변동이 큰 packet radio network 같은 환경에서는 unnecessary retransmission을 자주 일으켰다.
14.3.2 The Standard Method
Jacobson 방식은 RTT 평균뿐 아니라 RTT 변동성까지 estimate해야 한다는 점에서 classic method를 개선했다. RTT가 커지고 흔들리는 상황은 이미 네트워크 load가 높다는 신호일 수 있는데, 이때 RTO가 너무 낮으면 unnecessary retransmission으로 load를 더 키운다. 따라서 RTO는 mean만이 아니라 variation을 반영해야 한다.
standard method의 핵심 estimator는 srtt와 rttvar다. srtt는 RTT 평균의 EWMA이고, rttvar는 평균에서 얼마나 벗어나는지에 대한 mean deviation의 EWMA다. 표준 형태는 다음과 같다.
srtt <- (1 - g) * srtt + g * M
rttvar <- (1 - h) * rttvar + h * |M - srtt|
RTO = srtt + 4 * rttvar구현 효율을 위해 같은 의미를 다음처럼 쓸 수 있다.
Err = M - srtt
srtt <- srtt + g * Err
rttvar <- rttvar + h * (|Err| - rttvar)
RTO = srtt + 4 * rttvar여기서 M은 RTT measurement, g = 1/8, h = 1/4다. deviation 쪽 gain인 h가 더 크므로 RTT가 갑자기 변할 때 RTO가 더 빠르게 올라간다. g와 h가 2의 음의 거듭제곱인 이유는 multiply/divide 대신 shift/add fixed-point integer arithmetic으로 구현하기 좋기 때문이다.
classic method와 standard method의 차이는 다음처럼 요약된다.
| 항목 | classic method | standard method |
|---|---|---|
| RTT 평균 | SRTT EWMA | srtt EWMA |
| 변동성 반영 | beta * SRTT의 고정 배수 | rttvar로 mean deviation 반영 |
| RTO 적응 | RTT 변동이 크면 둔감 | RTT fluctuation에 더 안정적 |
| 현대성 | 초기 TCP | RFC 6298 기반 현대 TCP의 기초 |
14.3.2.1 Clock Granularity and RTO Bounds
TCP clock은 무한 정밀한 시간이 아니라 system clock을 따라 증가하는 변수에 가깝다. clock tick 길이를 granularity G라고 한다. 오래된 구현에서는 500ms 정도로 거칠었지만, 현대 구현은 Linux처럼 1ms 수준의 더 fine-grained clock을 쓰는 경우가 많다.
RFC 6298 계열 standard method는 clock granularity와 lower bound를 반영해 RTO를 다음처럼 제한한다.
RTO = max(srtt + max(G, 4 * rttvar), 1000ms)즉 RTO는 적어도 1초다. upper bound도 둘 수 있지만, 적어도 60초 이상이어야 한다. lower bound는 spurious retransmission을 줄이는 보수적 장치다.
14.3.2.2 Initial Values
첫 SYN exchange 전에는 TCP가 RTT를 모른다. forwarding table 등에 cached hint가 없다면 initial RTO는 RFC 6298 기준 1초가 권장된다. 단, initial SYN에서 timeout이 발생한 경우에는 3초가 사용된다.
첫 RTT measurement M이 들어오면 estimator를 다음처럼 초기화한다.
srtt <- M
rttvar <- M / 2이후부터는 앞의 EWMA update를 적용한다.
14.3.2.3 Retransmission Ambiguity and Karn’s Algorithm
retransmission ambiguity problem은 retransmitted segment에 대한 ACK가 도착했을 때, 그 ACK가 첫 번째 전송본을 가리키는지 재전송본을 가리키는지 알 수 없는 문제다. Timestamp option이 없으면 ACK는 ACK number만 제공하므로 어느 copy가 ACK되었는지 구분하지 못한다.
Karn’s algorithm의 첫 번째 부분은 timeout과 retransmission이 발생한 data에 대해, 그 ACK가 나중에 도착하더라도 RTT estimator를 update하지 않는 것이다. 애매한 sample을 버려 RTT estimate 오염을 막는다. 이는 RFC 6298에서 요구되는 동작이다.
두 번째 부분은 RTO backoff다. retransmission timer가 다시 만료될 때마다 TCP는 RTO에 backoff factor를 적용하고, 이 factor를 두 배로 늘린다. retransmitted 적이 없는 segment에 대한 ACK가 도착하면 backoff factor는 1로 돌아가고, binary exponential backoff가 취소된다.
timeout 발생 -> ambiguous RTT sample 무시
연속 timeout -> RTO backoff factor doubling
새 non-retransmitted segment ACK -> estimator update 가능, backoff resetTimestamp option(TSOPT)을 사용하면 ACK ambiguity를 피할 수 있으므로 Karn’s algorithm의 첫 번째 부분은 적용되지 않을 수 있다. 하지만 timeout이 congestion control을 유발하고 sending rate를 바꾼다는 점은 여전히 Chapter 16과 연결된다.
14.3.2.4 RTT Measurement (RTTM) with the Timestamps Option
TCP Timestamps option(TSOPT)은 Chapter 13의 PAWS뿐 아니라 RTTM(RTT Measurement)에도 쓰인다. sender는 각 segment의 TSOPT 안에 자신의 TCP clock 값을 TSV(Timestamp Value)로 넣고, receiver는 ACK의 TSER(Timestamp Echo Reply)에 최근 적절한 TSV를 되돌려 보낸다. sender는 현재 TCP clock에서 TSER를 빼 RTT sample을 얻는다.
RTTM 절차는 다음처럼 이해할 수 있다.
| 단계 | 동작 |
|---|---|
| 1 | sender가 각 TCP segment의 TSV에 송신 시점 TCP clock 값을 넣는다 |
| 2 | receiver는 최근 TSV를 TsRecent, 마지막 ACK number를 LastACK로 추적한다 |
| 3 | 새 segment가 LastACK에 해당하는 next expected segment이면 그 TSV를 TsRecent에 저장한다 |
| 4 | receiver가 ACK를 보낼 때 TsRecent를 TSER에 넣어 echo한다 |
| 5 | sender는 window를 advance하는 ACK에서 current clock - TSER를 RTT sample로 사용한다 |
TCP는 모든 segment마다 ACK를 보내지 않을 수 있다. 대량 전송에서는 보통 두 segment당 하나의 ACK를 보내기도 하고, loss/reordering/retransmission이 있으면 cumulative ACK와 segment 사이의 일대일 대응이 깨진다. TSOPT의 TsRecent 규칙은 이런 상황에서도 RTT sample을 비교적 일관되게 얻기 위한 장치다.
Linux에서는 net.ipv4.tcp_timestamps가 timestamp 사용 여부를 제어한다. Windows에서는 Tcp1323Opts 값이 관련된다. 현대 TCP에서는 peer가 timestamp를 사용하면 응답 쪽도 timestamp를 사용하는 방식이 흔하다.
14.3.3 The Linux Method
Linux RTT estimation은 standard method와 비슷하게 srtt와 rttvar를 유지하지만, 실제 구현은 몇 가지 중요한 보정을 둔다. Linux는 1ms clock granularity와 TSOPT를 사용해 RTT를 자주 측정할 수 있다. 이 조합은 RTT 평균 estimate를 정밀하게 만들지만, packet마다 매우 비슷한 RTT sample이 많이 쌓이면 mean deviation이 지나치게 작아져 rttvar가 거의 0에 가까워질 수 있다. 그러면 RTO가 너무 낮아져 spurious retransmission 위험이 커진다.
또 다른 문제는 standard method가 sample이 srtt보다 크게 낮아져도 |M - srtt| 때문에 rttvar를 키울 수 있다는 점이다. 실제 RTT가 감소하는 상황에서 RTO가 오히려 증가하는 것은 직관적이지 않다. Linux는 RTT sample이 예상 범위보다 크게 낮을 때 deviation update의 weight를 줄여 이 문제를 완화한다.
Linux가 추가로 유지하는 핵심 변수는 다음과 같다.
| 변수 | 의미 |
|---|---|
mdev | standard algorithm에 가까운 running mean deviation estimate |
mdev_max | 최근 measured RTT window 동안 관찰한 mdev의 최대값 |
rttvar | RTO 계산에 쓰이는 deviation 값, mdev_max 이상이 되도록 관리 |
Linux의 중요한 제약은 mdev_max가 50ms보다 작아지지 않도록 하는 것이다. 따라서 rttvar >= 50ms가 되고, RTO = srtt + 4 * rttvar 구조상 RTO는 사실상 200ms 아래로 내려가지 않는다. TCP_RTO_MIN은 kernel configuration이나 일부 route 설정으로 바꿀 수 있지만, global Internet에서는 지나치게 작은 minimum RTO가 권장되지 않는다. data-center network처럼 RTT가 microseconds 단위인 환경에서는 200ms minimum RTO가 incast 문제에서 loss recovery를 심하게 늦출 수 있어 별도 tuning이 논의된다.
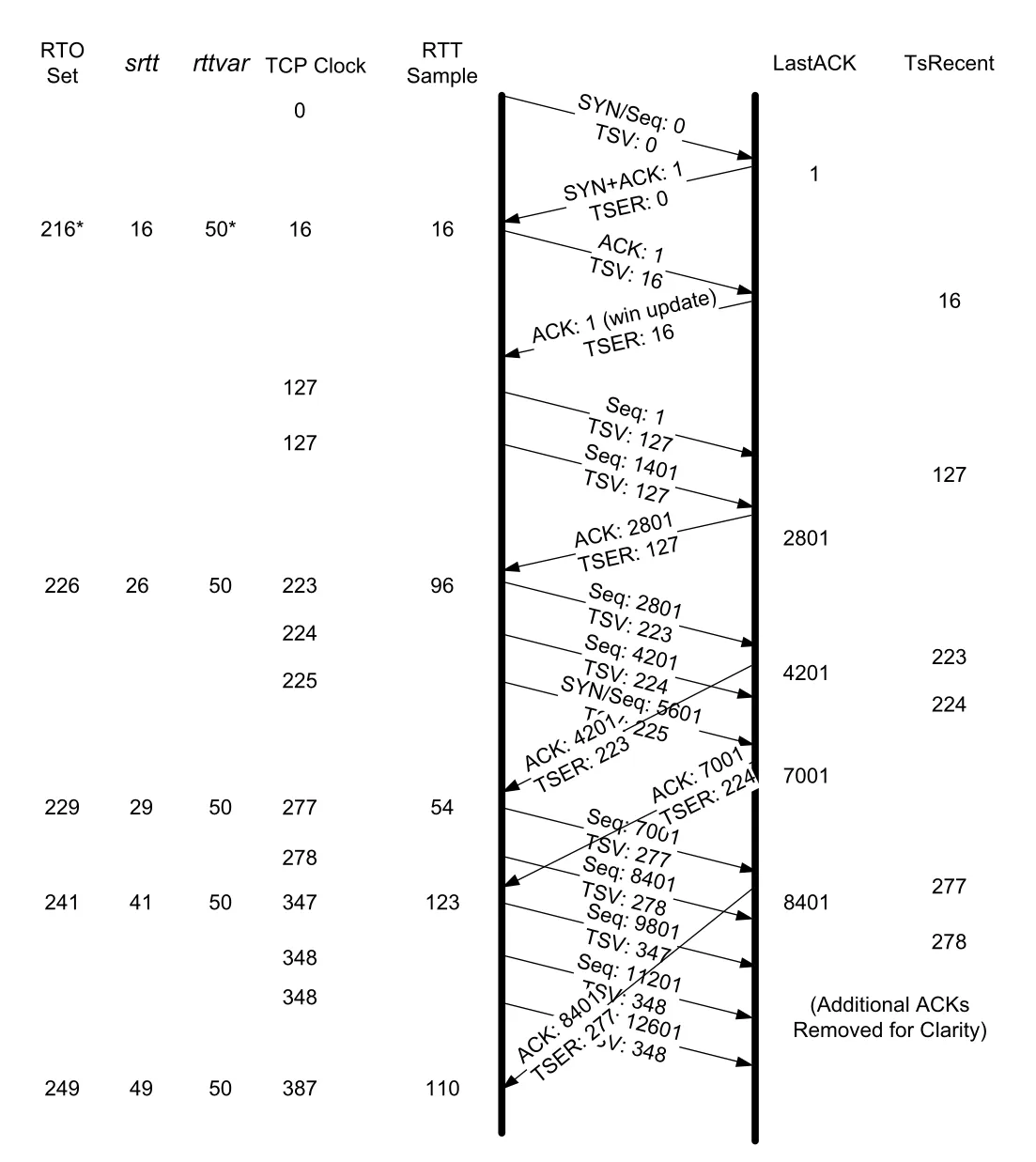
Figure 14-2 · PDF p. 697 · Linux에서 TSOPT 기반 RTT sample로 srtt/rttvar/RTO를 갱신하는 흐름
Figure 14-2의 초기 SYN RTT가 16ms라면 Linux는 다음처럼 초기값을 잡는다.
srtt = 16ms
mdev = 16 / 2 = 8ms
rttvar = mdev_max = max(8ms, 50ms) = 50ms
RTO = srtt + 4 * rttvar = 16 + 200 = 216msACK-only segment나 window update처럼 data, SYN, FIN을 포함하지 않는 segment는 sequence number space를 소비하지 않고 TCP가 reliable하게 재전송하지도 않는다. 따라서 이런 segment에는 retransmission timer를 걸 필요가 없고, RTT estimator update도 수행하지 않는다. TCP options도 option 자체만으로 reliable delivery 대상이 아니다. option이 SYN/FIN/data segment에 포함될 때만 해당 segment 재전송의 부수 효과로 다시 전달된다.
첫 application write가 back-to-back으로 여러 segment를 내보내면 TCP clock granularity 때문에 여러 segment가 같은 TSV를 가질 수 있다. receiver는 LastACK와 TsRecent 규칙에 따라 next expected segment의 timestamp만 echo한다. 예를 들어 두 full-size segment가 연속 도착했을 때 첫 segment가 LastACK에 맞으면 TsRecent가 갱신되고, 뒤 segment가 out of sequence가 아니더라도 LastACK와 일치하지 않으면 TsRecent를 갱신하지 않는다.
Linux의 deviation update는 RTT가 예상보다 낮게 떨어지는 경우를 특별히 다룬다.
if (m < srtt - mdev)
mdev = (31/32) * mdev + (1/32) * |srtt - m|
else
mdev = (3/4) * mdev + (1/4) * |srtt - m|새 RTT sample m이 예상 RTT range의 하단보다 낮으면, Linux는 deviation sample의 weight를 8배 줄인다. 이렇게 하면 “RTT가 좋아졌는데 RTO가 커지는” 현상을 줄일 수 있다.
Figure 14-2에서 ACK 7001의 TSER가 가장 최근 도착 segment가 아니라 아직 ACK되지 않았던 가장 오래된 segment의 TSV를 담는 것도 중요하다. sender에게 필요한 것은 순수 network RTT만이 아니라 “ACK가 돌아올 것으로 기대할 수 있는 시간”이다. delayed ACK나 erratic ACK가 있으면 ACK rate가 packet sending rate보다 낮을 수 있고, RTO는 이 현실을 반영해야 한다.
14.3.4 RTT Estimator Behaviors
RTT estimator의 차이는 synthetic sample에서도 드러난다. Figure 14-3은 첫 100개 sample은 N(200, 50), 다음 100개 sample은 N(50, 50)에서 뽑아 standard method와 Linux method를 비교한다. 설명을 위해 standard method의 1s minimum RTO는 제거되어 있다.
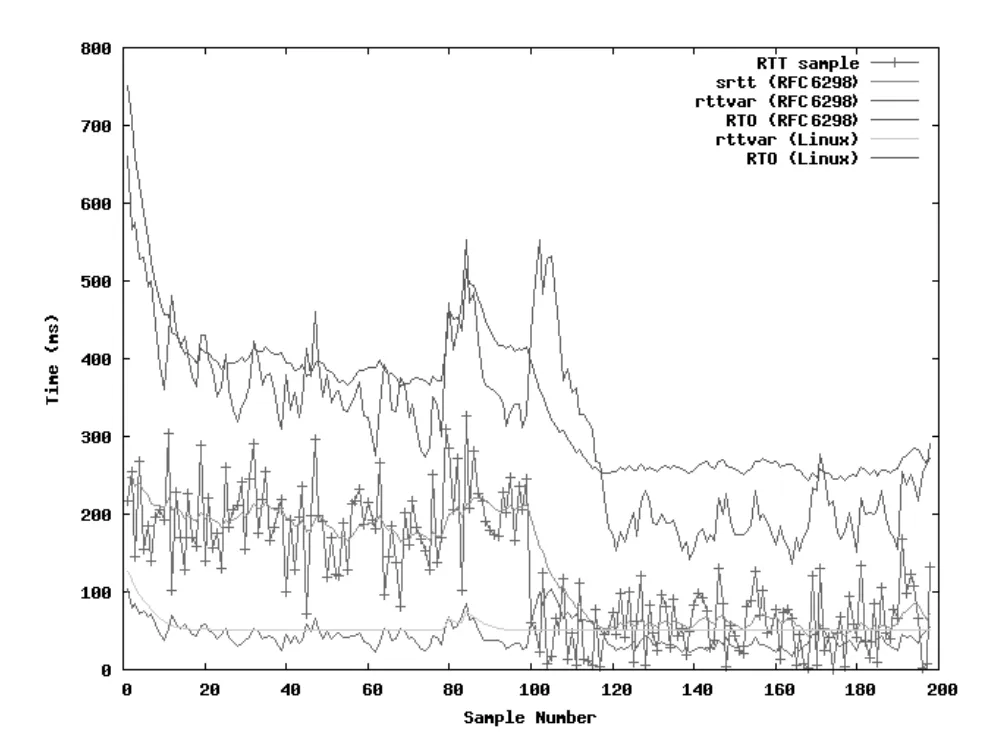
Figure 14-3 · PDF p. 701 · standard RTO와 Linux RTO estimator의 synthetic sample 대응 비교
sample 100 이후 RTT 평균이 급격히 낮아질 때 Linux RTO는 빠르게 낮아진다. 반면 standard method는 rttvar가 커지는 영향 때문에 약 20 sample 정도 더 늦게 따라간다. Linux의 rttvar는 50ms minimum 때문에 비교적 일정하게 유지되고, 그 결과 RTO가 200ms 아래로 내려가지 않는다. 이 보수성은 loss가 났을 때 timer가 더 늦게 fire될 수 있다는 비용을 만들지만, RTO가 너무 낮아지는 spurious retransmission을 막는 데 도움이 된다.
14.3.5 RTTM Robustness to Loss and Reordering
TSOPT 기반 RTTM은 정상 순서 전달뿐 아니라 loss와 reordering 상황도 고려해 설계되어 있다. receiver가 out-of-order segment를 받으면 fast retransmit을 돕기 위해 즉시 duplicate ACK를 보내는 것이 일반적이다. 이 ACK의 TSER에는 방금 도착한 out-of-order segment의 timestamp가 아니라, receiver window를 마지막으로 advance시킨 in-order segment의 timestamp가 들어간다.
이 동작은 sender의 RTT sample을 크게 만드는 방향으로 bias를 준다. RTT estimate가 커지면 RTO도 커지고, sender는 reordering을 loss로 성급하게 판단하지 않게 된다. 즉 packet reordering이 있을 때 TCP가 조금 덜 공격적으로 retransmit하도록 만드는 안전장치다.
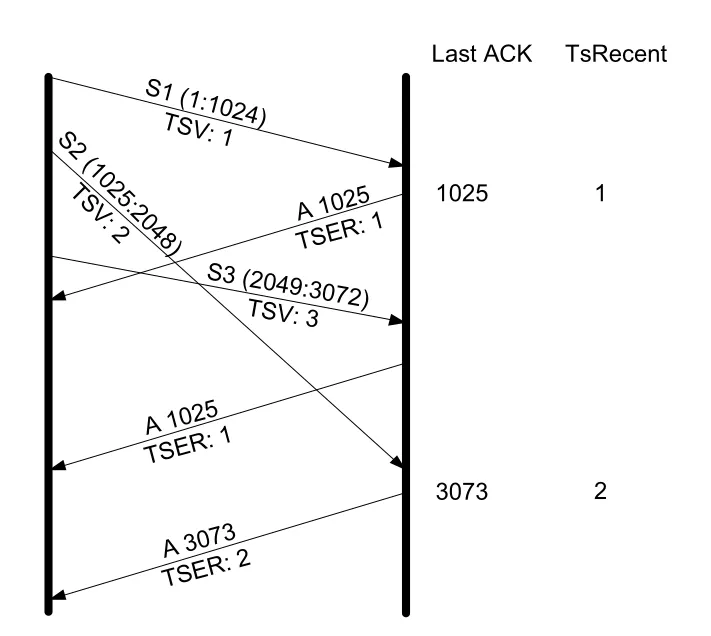
Figure 14-4 · PDF p. 702 · reordering 상황에서 TSER가 window를 advance한 마지막 segment의 timestamp를 반영하는 방식
Figure 14-4의 예시는 S1(1-1024), S3(2049-3072), S2(1025-2048) 순서로 segment가 도착하는 reordering 상황이다. receiver는 처음에 ACK 1025를 보내며 segment 1의 timestamp를 echo한다. segment 3이 먼저 도착해도 hole이 있으므로 duplicate ACK 1025를 보내며 여전히 segment 1의 timestamp를 echo한다. 나중에 segment 2가 도착해 hole이 메워지면 ACK 3073을 보내며 segment 2의 timestamp를 echo한다.
반대로 successful retransmission이 hole을 메워 window가 크게 advance되는 경우에는 가장 최근 도착한 segment의 timestamp를 echo한다. 오래된 timestamp를 echo하면 한 RTO보다 오래된 sample이 RTT estimate를 과하게 키울 수 있기 때문이다.
TSOPT가 유용하려면 TCP clock이 실제 시간에 비례하고 적절한 granularity를 가져야 한다. clock은 plausible RTT마다 적어도 한 번 tick해야 하지만, 너무 빨리 tick해 32-bit TSV가 IP layer가 허용하는 packet lifetime 안에 wrap되어서도 안 된다. 이런 조건이 맞으면 TSOPT는 delay, loss, reordering이 있어도 sender가 RTT를 계속 추정하게 해 준다.
14.4 Timer-Based Retransmission
sender TCP는 RTO를 정한 뒤 data를 담은 segment를 보낼 때 retransmission timer를 적절히 설정한다. 이때 timed segment의 sequence number를 기록한다. ACK가 제때 도착하면 timer를 cancel하고, 다음 data segment를 보낼 때 새 sequence number에 대해 timer를 다시 설정한다. 즉 TCP는 connection마다 하나의 retransmission timer를 계속 set/cancel/reset한다. data loss가 없다면 이 timer는 만료되지 않는다.
운영체제 timer 관점에서 TCP는 특이한 workload를 만든다. 일반 OS timer facility는 timer를 설정하고 만료시켜 callback/system function을 호출하는 일이 중요하지만, TCP에서는 잘 동작할수록 timer가 expire되지 않는다. 따라서 TCP timer 구현에는 expiration보다 timer setting/reset/cancel 효율이 매우 중요하다.
timer가 RTO 안에 ACK를 받지 못해 expire되면 TCP는 timer-based retransmission을 수행한다. TCP는 이를 큰 사건으로 취급한다. timeout은 congestion 또는 심각한 path 문제의 신호일 수 있으므로, TCP는 두 방향으로 보수적으로 반응한다.
| 반응 | 의미 | 연결 장 |
|---|---|---|
| congestion control로 sending window 축소 | 네트워크에 넣는 data rate를 줄임 | Chapter 16 |
| RTO backoff factor 증가 | 같은 segment 재전송 간격을 점점 늘림 | Karn’s algorithm |
RTO backoff는 다음처럼 표현할 수 있다.
backed-off RTO = gamma * RTO일반 상황에서 gamma = 1이다. 같은 segment가 계속 timeout되면 gamma는 2, 4, 8, ...처럼 두 배로 증가한다. Linux는 실제 사용 RTO가 TCP_RTO_MAX, 기본 120초를 넘지 않게 제한한다. acceptable ACK가 도착하면 gamma는 다시 1로 reset된다.
14.4.1 Example
본문 예제는 sequence number 1401인 segment를 의도적으로 두 번 drop해 timer-based retransmission을 관찰한다. 첫 번째 data pair에서 sequence 1과 1401이 전송되지만, 1401 segment가 drop된다. receiver는 delayed ACK 정책 때문에 즉시 응답하지 않고, sender는 219ms 안에 ACK를 받지 못해 retransmission timer가 expire된다.
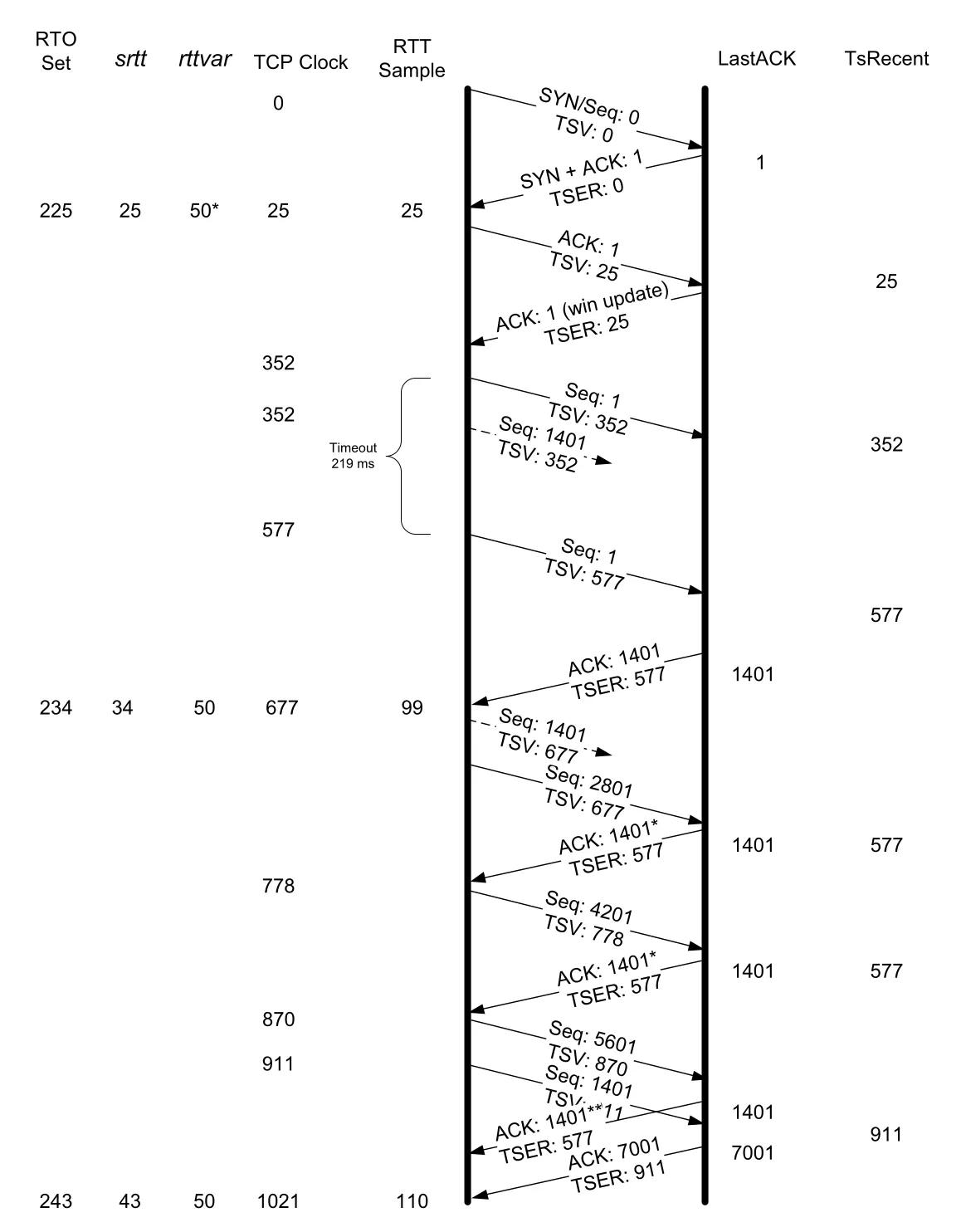
Figure 14-5 · PDF p. 705 · segment 1401 loss로 timer-based retransmission이 발생하는 예제
timeout 후 sender는 sequence 1 segment를 다시 보낸다. 이 retransmission이 receiver에 도착하면 ACK가 돌아오고, 이 ACK는 sender window를 advance하므로 TSER 값을 이용해 srtt와 RTO를 갱신한다. 예제에서는 srtt = 34, RTO = 234로 업데이트된다.
이후 도착하는 일부 ACK에는 asterisk가 붙어 있으며 SACK information을 포함한다. 하지만 이 duplicate ACK들은 sender window를 advance하지 않으므로 TSER가 RTT estimator update에 사용되지 않는다. estimator는 “새롭게 ACK된 data가 window를 앞으로 밀었는가”를 기준으로 조심스럽게 갱신된다.
segment 1401이 결국 재전송되어 receiver에 도착하면 hole이 메워지고 receiver는 ACK 7001을 보낸다. 이 ACK는 모든 data가 받아졌음을 나타낸다.
timer-based retransmission은 connection이 더 이상 정상적으로 data를 밀어내지 못할 때 다시 움직이게 하는 last-resort restart에 가깝다. 하지만 RTO는 보통 RTT보다 두 배 이상 크게 설정되므로 timer가 만료될 때까지 기다리면 network capacity가 비어 있는 시간이 생길 수 있다. 그래서 TCP는 가능한 경우 fast retransmit으로 더 빨리 복구하려고 한다.
14.5 Fast Retransmit
fast retransmit은 retransmission timer expiration을 기다리지 않고 receiver feedback을 보고 loss를 추정해 retransmission을 시작하는 TCP 절차다. receiver가 out-of-order segment를 받으면 즉시 duplicate ACK를 보내야 한다. ACK가 지연되지 않는 이유는 sender에게 “hole이 생겼고, 나는 이 sequence number를 아직 기다린다”는 정보를 빠르게 주기 위해서다.
duplicate ACK는 loss의 힌트지만, 항상 loss를 뜻하지는 않는다. network reordering 때문에 기대보다 뒤쪽 sequence number의 packet이 먼저 도착해도 duplicate ACK가 생길 수 있다. 그래서 TCP는 보통 duplicate ACK를 몇 개 기다린 뒤 loss라고 판단한다. 이 기준을 duplicate ACK threshold, 줄여서 dupthresh라고 하며 전통적인 값은 3이다. Linux 같은 일부 구현은 측정된 reordering 정도에 따라 이 값을 조정하기도 한다.
기본 fast retransmit 판단은 다음처럼 요약할 수 있다.
out-of-order segment 도착 -> receiver가 즉시 duplicate ACK 전송
sender가 dupthresh 개수 이상의 duplicate ACK 수신
-> missing segment로 보이는 data를 retransmit
-> congestion control도 함께 진입SACK이 없으면 sender는 대개 acceptable ACK가 돌아오기 전까지 한 RTT에 하나의 hole만 복구할 수 있다. SACK이 있으면 ACK 안에 receiver가 이미 받은 out-of-order block 정보가 들어가므로, 한 RTT 안에서도 여러 hole을 더 잘 파악하고 메울 수 있다.
14.5.1 Example
본문 예제는 SACK을 끈 상태에서 segment 23801과 26601을 drop한다. sender는 Linux 2.6, receiver는 FreeBSD 5.4다. 이 예제는 non-SACK TCP가 duplicate ACK와 partial ACK를 이용해 hole을 하나씩 복구하는 모습을 보여 준다.
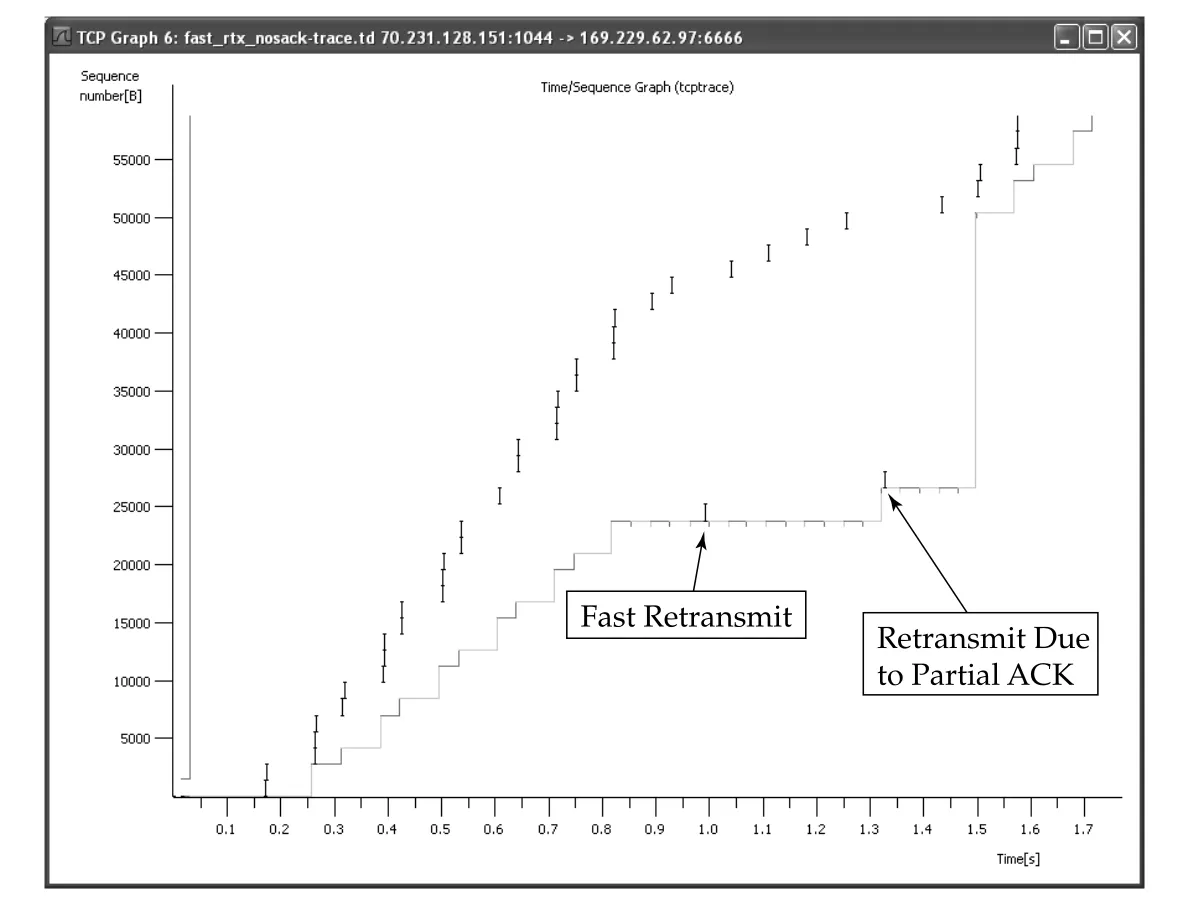
Figure 14-6 · PDF p. 707 · duplicate ACK 3개로 fast retransmit이 발생하고 partial ACK가 다음 retransmission을 유발하는 흐름
Figure 14-6에서 time 0.993s에 sequence number 23801이 fast retransmit된다. 초기 전송본은 TCP 아래에서 drop되었기 때문에 plot에는 보이지 않는다. retransmission trigger는 세 번째 duplicate ACK다. 이 connection은 SACK을 쓰지 않기 때문에 한 RTT에 한 receiver hole만 복구할 수 있다.
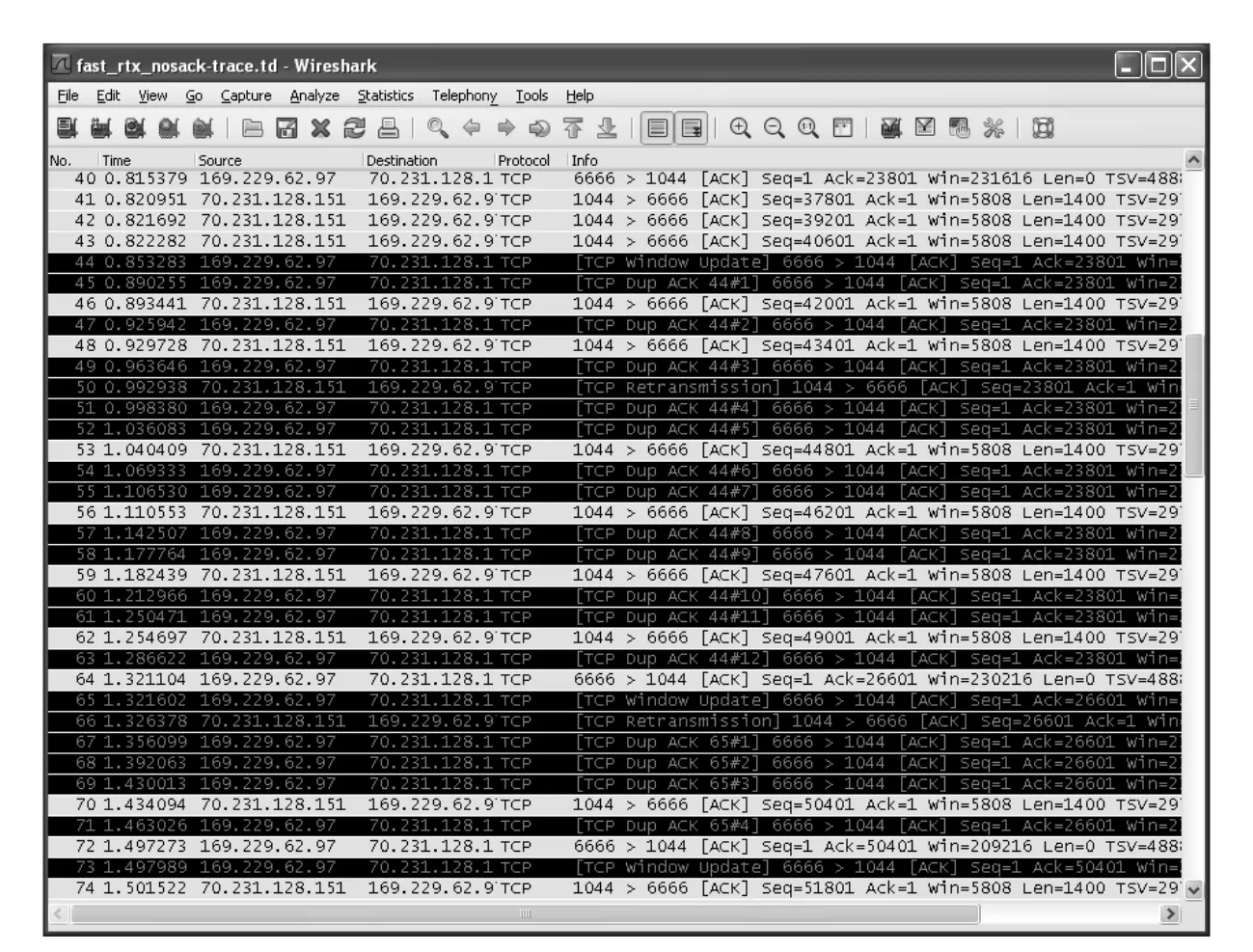
Figure 14-7 · PDF p. 708 · Wireshark trace에서 packet 50과 66이 retransmission으로 표시되는 예
Wireshark trace에서는 ACK 23801이 처음 등장한 뒤, 같은 ACK number가 반복되는 duplicate ACK들이 보인다. 단, time 0.853의 ACK는 sequence number 관점에서는 duplicate처럼 보일 수 있지만 flow control window update를 포함하므로 fast retransmit을 위한 duplicate ACK count에 포함되지 않는다. window update는 receiver의 advertised window 정보를 갱신하는 것이며 Chapter 15와 연결된다.
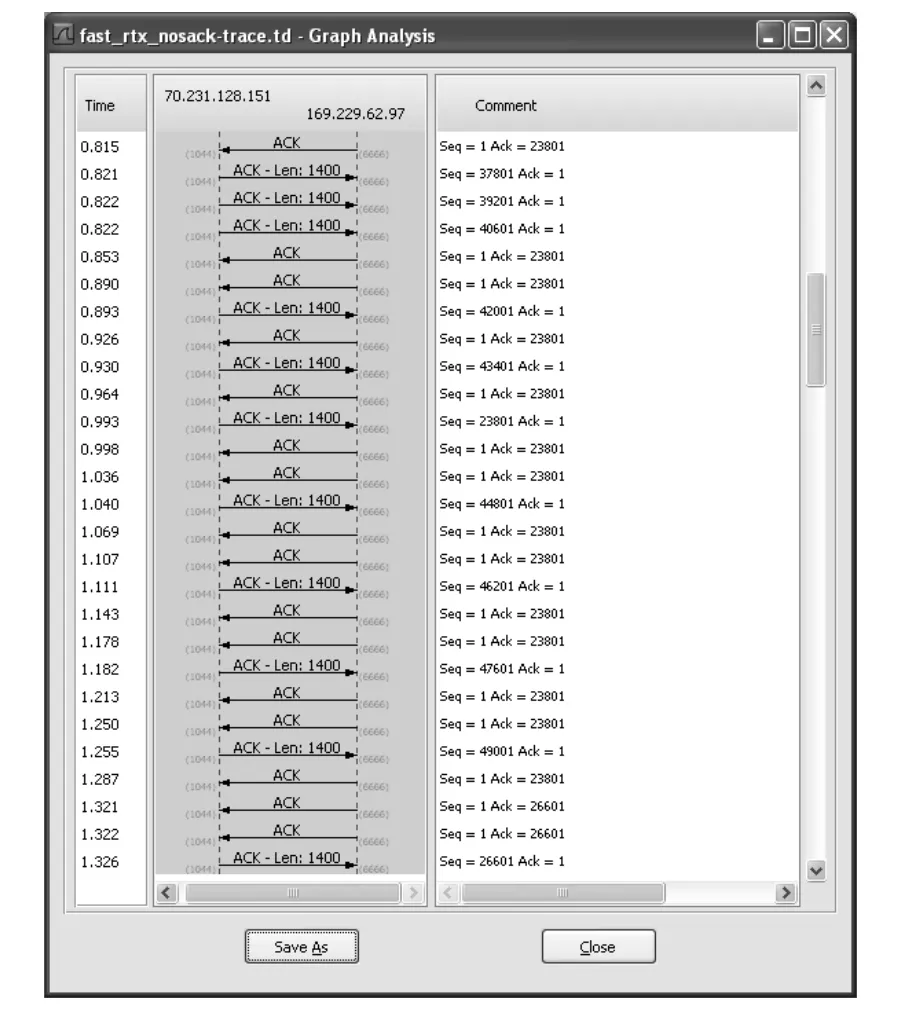
Figure 14-8 · PDF p. 709 · duplicate ACK 3개가 fast retransmit trigger가 되는 Flow Graph
time 0.890, 0.926, 0.964에 도착한 ACK들은 모두 sequence number 23801에 대한 duplicate ACK다. 세 번째 duplicate ACK가 도착한 뒤 time 0.993에 segment 23801이 retransmit된다. timer expiration을 기다리지 않으므로 복구가 빠르다.
첫 fast retransmit이 발생할 때 sender는 그 직전에 보낸 highest sequence number를 기록한다. 예제에서는 43401 + 1400 = 44801이 recovery point다. TCP는 recovery point 이상의 ACK를 받을 때까지 loss recovery 중이라고 본다.
나중에 도착한 ACK가 이전 highest ACK보다 크지만 recovery point에는 도달하지 못하면 partial ACK라고 한다. 예제에서 ACK 26601은 이전 ACK 23801보다 전진했지만 recovery point 44801에는 못 미친다. NewReno sender는 partial ACK를 받으면 아직 missing으로 보이는 segment, 여기서는 26601을 즉시 retransmit하고 recovery 상태를 유지한다.
SACK이 없는 NewReno에서는 ACK number가 lowest-numbered hole이 메워졌을 때만 전진한다. 그래서 sender는 receiver에 hole이 여러 개 있어도 한 RTT에 한 hole씩만 배운다. plain Reno는 acceptable ACK 하나로 recovery를 빠져나가므로 다중 loss에서 성능 문제가 생길 수 있고, NewReno와 SACK은 이런 older approach와 구분되는 advanced loss recovery 기법으로 이해하면 된다.
14.6 Retransmission with Selective Acknowledgments
SACK(Selective Acknowledgment)은 cumulative ACK Number field만으로 표현할 수 없는 receiver 상태를 sender에게 알려 준다. receiver가 cumulative ACK 이후의 out-of-sequence data를 buffer에 들고 있으면, ACK number와 그 data 사이의 빈 구간은 hole이다. SACK은 “나는 이 뒤쪽 block은 이미 받았다”를 알려 sender가 receiver가 이미 가진 data를 다시 보내지 않게 돕는다.
SACK block 하나는 continuous out-of-sequence data block의 left edge와 right edge를 32-bit sequence number 두 개로 표현한다. n개의 SACK block을 가진 SACK option의 길이는 8n + 2 bytes다. TCP option 공간은 40 bytes뿐이고, 현대 TCP는 TSOPT도 같이 쓰는 경우가 많으므로 실제로는 ACK 하나에 SACK block을 보통 3개 정도 담는다.
SACK의 핵심 이득은 한 RTT에 여러 hole 정보를 줄 수 있다는 점이다. congestion control이 허용한다면 SACK-capable sender는 여러 hole을 같은 RTT 안에서 채울 수 있다. non-SACK sender는 cumulative ACK가 전진해야 다음 hole을 알기 때문에 한 RTT에 하나씩만 배울 수 있다.
14.6.1 SACK Receiver Behavior
receiver는 connection establishment 중 SYN에서 SACK-Permitted option을 받은 경우에만 SACK을 생성할 수 있다. 일반적으로 out-of-order data가 receive buffer에 있으면 SACK option을 넣은 ACK를 보낸다. out-of-order의 원인은 loss일 수도 있고 reordering일 수도 있다.
SACK receiver는 가장 최근에 받은 segment의 sequence range를 첫 번째 SACK block에 넣는다. 최신 정보를 가능한 한 sender에게 먼저 제공하기 위해서다. 나머지 SACK block들은 이전 SACK option에서 첫 번째 block이었던 정보들을 반복하되, 새로 넣을 block의 subset이 아닌 것만 넣는다. 이렇게 반복하는 이유는 ACK/SACK 자체도 손실될 수 있고, TCP는 ACK-only segment를 재전송하지 않기 때문이다.
14.6.2 SACK Sender Behavior
SACK receiver가 올바른 SACK block을 만든다고 해서 충분하지 않다. sender도 SACK 정보를 해석해 receiver가 이미 가진 data를 재전송하지 않는 selective retransmission, 즉 selective repeat을 수행해야 한다. SACK sender는 cumulative ACK 정보와 SACK block 정보를 함께 추적하고, retransmission buffer 안의 segment마다 SACKed 여부를 표시할 수 있다.
SACK sender가 retransmission 기회를 얻는 시점은 보통 SACK을 받았거나 multiple duplicate ACK를 봤을 때다. 이때 sender는 새 data를 보낼지, old data를 retransmit할지 선택한다. 일반적인 전략은 먼저 receiver의 hole을 채우고, congestion control이 허용하면 그다음 새 data를 보내는 것이다.
SACK block은 advisory다. receiver가 SACK으로 “이 range를 받았다”고 알린 뒤 나중에 buffer pressure 등으로 그 data를 버릴 수 있는데, 이를 reneging이라고 한다. 그래서 sender는 SACK만 받았다고 retransmission buffer에서 data를 free하면 안 된다. regular cumulative ACK number가 해당 data의 highest sequence number를 지나가야 안전하게 버릴 수 있다.
timer-based retransmission이 발생하면 sender는 SACK에서 얻은 out-of-sequence receiver state를 잊어야 한다. receiver에게 out-of-sequence data가 여전히 있으면, retransmitted segment에 대한 ACK가 다시 SACK block을 담아 sender에게 알려 줄 수 있다. 실제 reneging은 드물고 권장되지 않지만, SACK 설계는 이 가능성을 안전하게 다룬다.
14.6.3 Example
본문 예제는 앞의 fast retransmit 실험과 비슷하지만 sender와 receiver가 SACK을 사용한다. sequence number 23601과 28801을 drop한 상황에서, SACK sender는 첫 missing segment를 retransmit한 뒤 다음 RTT를 기다리지 않고 두 번째 missing segment도 같은 RTT 안에서 알게 된다.
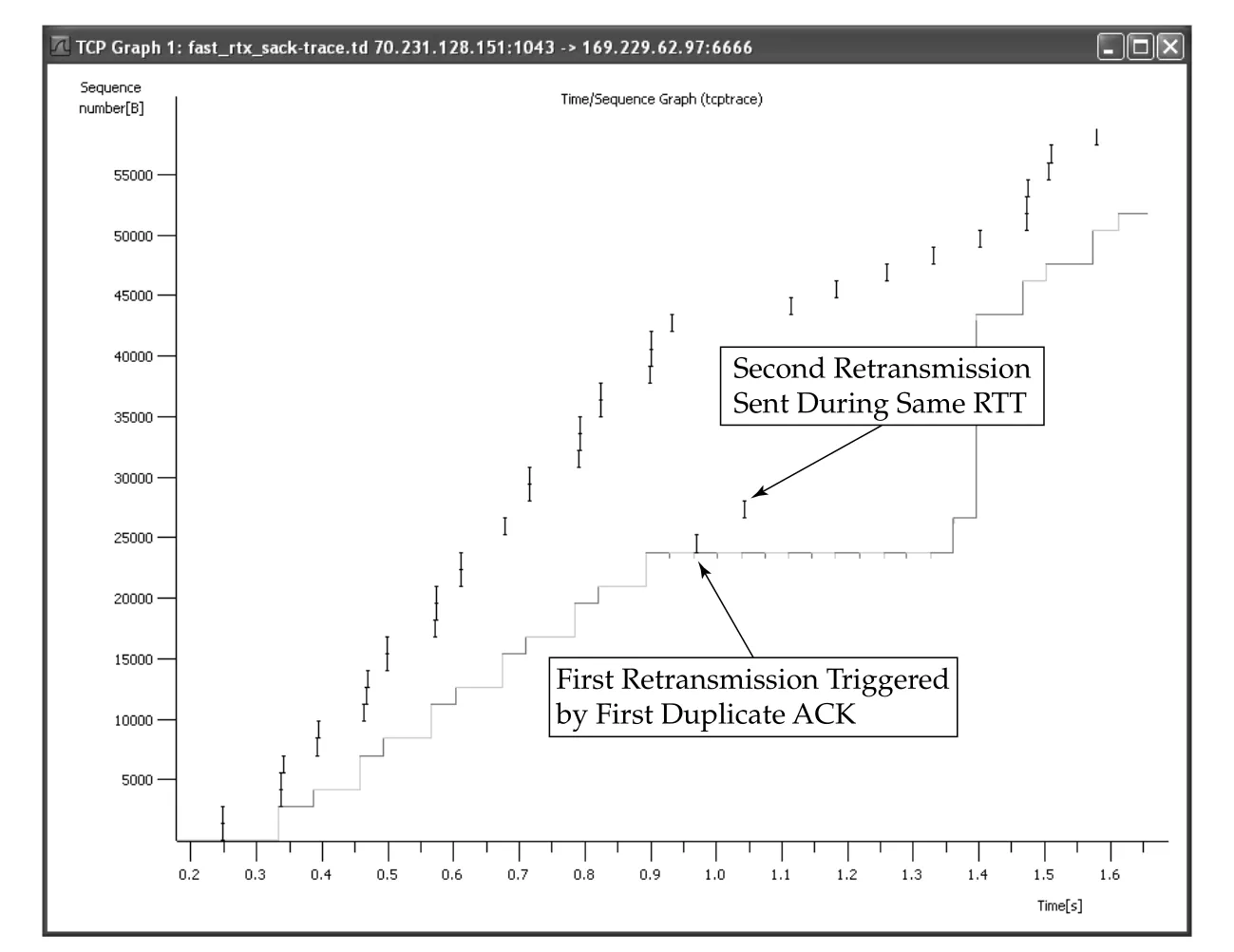
Figure 14-9 · PDF p. 713 · SACK 정보로 같은 RTT 안에서 두 번째 missing segment까지 복구하는 fast retransmit
Figure 14-9는 Figure 14-6과 비슷하지만, SACK sender가 lost segment 23601을 retransmit한 뒤 lost segment 28801을 알기 위해 한 RTT 전체를 기다리지 않는다는 점이 다르다. arriving ACK 안의 SACK information이 receiver의 다른 out-of-order block을 알려 주기 때문이다.
Figure 14-10 · PDF p. 714 · SYN에서 SACK-Permitted option이 교환되는 connection setup
SACK은 connection setup 때 SACK-Permitted option으로 capability를 교환해야 한다. 이 option은 SYN bit가 켜진 segment에만 나타난다. 현대 TCP는 connection establishment 중 MSS, Timestamps, Window Scale, SACK-Permitted를 함께 사용하는 경우가 많다.
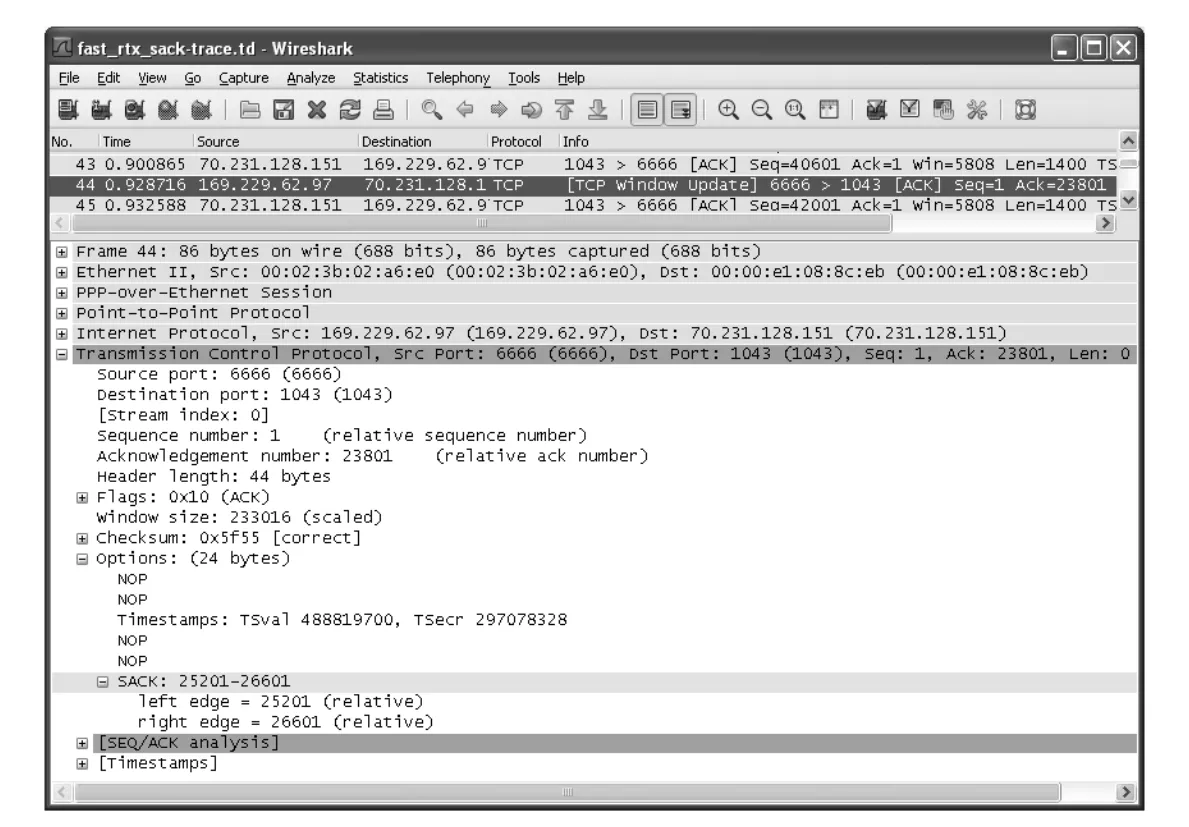
Figure 14-11 · PDF p. 715 · SACK block의 left edge/right edge가 out-of-order range를 나타내는 예
Figure 14-11에서 ACK 23801은 SACK block [25201, 26601]을 포함한다. 이는 receiver가 25201부터 26600까지의 out-of-order block을 갖고 있다는 뜻이다. 따라서 hole은 [23801, 25200]이고, 이는 sequence number 23801에서 시작하는 1400-byte segment가 빠졌음을 의미한다.
뒤이어 도착한 SACK은 [28001, 29401]과 [25201, 26601] 두 block을 포함한다. 최신 block이 첫 번째에 오고, 이전 block이 반복된다. 이 ACK는 ACK 23801에 대한 duplicate ACK이며, receiver가 이제 두 full-size segment, 즉 23801과 26601을 필요로 함을 암시한다. sender는 즉시 fast retransmit을 시작하지만 congestion control 제약 때문에 먼저 23801 하나만 retransmit하고, 추가 ACK가 도착한 뒤 26601을 retransmit한다.
SACK이 항상 throughput을 즉시 높인다고 단정하면 안 된다. 본문 live test에서는 non-SACK NewReno가 131,074 bytes를 3.592s에 끝내고, SACK sender는 3.674s에 끝냈다. 조건이 완전히 동일한 simulation이 아니므로 단순 비교는 어렵다. SACK의 이득은 RTT가 크고 packet loss가 심해 한 RTT에 여러 hole을 채우는 능력이 중요해질 때 더 뚜렷하다.
14.7 Spurious Timeouts and Retransmissions
spurious retransmission은 실제로 data가 lost되지 않았는데 TCP가 retransmission을 시작하는 바람직하지 않은 상황이다. 원인은 spurious timeout, packet reordering, packet duplication, lost ACK 등이다. spurious timeout은 실제 RTT가 최근 RTO보다 크게 증가했을 때 발생할 수 있으며, wireless처럼 lower-layer 성능 변동이 큰 환경에서 특히 문제가 된다.
spurious timeout 대응은 보통 detection algorithm과 response algorithm으로 나뉜다.
| 구분 | 역할 |
|---|---|
| detection algorithm | timeout 또는 retransmission이 spurious였는지 판단 |
| response algorithm | spurious로 판정된 뒤 TCP가 한 조치를 되돌리거나 완화 |
이 장에서 다루는 response는 주로 segment retransmission 동작이고, congestion control 상태 복구는 Chapter 16과 연결된다.
Figure 14-12 · PDF p. 717 · delay spike로 spurious timeout이 발생하고 go-back-N식 낭비가 생기는 예
Figure 14-12는 packet 8 이후 ACK path에 delay spike가 생겨, sender가 packet 5에 대해 timeout을 잘못 판단하는 예다. sender는 packet 5를 retransmit하지만, 원래 전송된 packet 5-8에 대한 ACK들이 이미 network 안에 있다. 그 ACK들이 뒤늦게 도착하면 TCP는 이미 receiver가 가진 packet 6, 7, 8까지 다시 보내는 go-back-N behavior를 보일 수 있다. 이 중복 전송은 receiver에서 duplicate ACK를 만들고, 심하면 fast retransmit까지 유발할 수 있다.
14.7.1 Duplicate SACK (DSACK) Extension
DSACK 또는 D-SACK(Duplicate SACK)은 receiver가 duplicate segment를 받았음을 sender에게 알리는 SACK 확장 규칙이다. 일반 SACK은 cumulative ACK 이후의 out-of-order block을 알리는 데 초점을 두지만, DSACK은 첫 번째 SACK block을 사용해 duplicate로 도착한 segment의 sequence range를 표시한다.
DSACK의 목적은 sender가 “방금 한 retransmission이 필요 없었을 가능성”을 배우게 하는 것이다. 이를 통해 sender는 packet reordering, ACK loss, network packet replication, spurious retransmission 같은 현상을 추론할 수 있다.
DSACK은 별도 negotiation이 필요 없고 conventional SACK과 상호 운용된다. 다만 DSACK receiver와 sender logic이 모두 있어야 이득이 생긴다. DSACK 정보는 일반 SACK block처럼 여러 ACK에 반복되지 않고 하나의 ACK에만 담기므로 ACK loss에 더 취약하다. RFC 2883은 DSACK 정보를 받은 sender가 정확히 어떤 response를 해야 하는지는 강제하지 않는다.
14.7.2 The Eifel Detection Algorithm
Eifel Detection Algorithm은 TCP TSOPT를 이용해 spurious retransmission을 더 일찍 감지한다. retransmission timeout 또는 fast retransmit으로 segment가 다시 보내지면 sender는 그 retransmitted segment의 TSV를 저장한다. 이후 그 sequence number를 cover하는 첫 acceptable ACK가 도착하면 ACK의 TSER를 검사한다.
판정 원리는 단순하다.
if incoming ACK's TSER < retransmitted segment's stored TSV:
ACK는 original transmit에 의해 생성된 것
-> retransmission은 spuriousACK의 TSER가 retransmitted copy보다 오래된 timestamp를 echo한다면, receiver는 retransmission이 도착하기 전에 이미 original transmit을 받고 ACK를 만든 것이다. 따라서 retransmission은 필요 없었다. Eifel은 DSACK보다 빠르게 탐지할 수 있다. DSACK은 duplicate segment가 receiver에 실제로 도착하고, 그 DSACK이 sender에게 돌아온 뒤에야 판단할 수 있기 때문이다.
Eifel Detection은 ACK loss에도 비교적 견고하다. ACK 하나가 사라져도 같은 window 안의 다른 ACK들이 retransmitted segment의 TSV보다 작은 TSER를 담을 수 있기 때문이다. 다만 window 전체의 ACK가 사라지고 original transmit과 retransmission이 모두 receiver에 도착한 경우에는 DSACK과 함께 해석할 수 있다.
14.7.3 Forward-RTO Recovery (F-RTO)
F-RTO(Forward-RTO Recovery)는 retransmission timer expiration 때문에 생긴 spurious retransmission을 탐지하는 표준 알고리즘이다. TCP option을 요구하지 않으므로 TSOPT를 지원하지 않는 오래된 receiver와도 쓸 수 있다. 단, packet reordering이나 duplication 같은 다른 원인까지 모두 탐지하는 것은 아니다.
일반 TCP는 timeout-based retransmission 후, 추가 ACK가 오면 인접한 old packet을 순서대로 다시 보내는 go-back-N behavior를 보일 수 있다. F-RTO는 이 동작을 바꿔 첫 ACK가 도착하면 아직 보내지 않은 new data를 보낸다. 그리고 두 번째 ACK를 관찰한다.
F-RTO 판정은 다음처럼 직관적이다.
| 첫 두 ACK의 성격 | 해석 |
|---|---|
| 둘 중 하나라도 duplicate ACK | receiver에 hole이 있음, retransmission이 타당했을 가능성 |
| 둘 다 acceptable ACK로 sender window advance | new data가 정상적으로 receiver window를 밀고 있음, timeout은 spurious |
new data를 보냈을 때 acceptable ACK가 돌아온다면 network가 막힌 것이 아니라 delay spike 등으로 timer가 너무 일찍 fire된 가능성이 크다. 반대로 duplicate ACK가 돌아오면 receiver에 아직 hole이 있으므로 retransmission이 필요한 상황으로 본다.
14.7.4 The Eifel Response Algorithm
Eifel Response Algorithm은 retransmission이 spurious로 판정된 뒤 실행할 표준 response 절차다. 이름은 Eifel Detection과 연결되어 있지만, 논리적으로 decoupled되어 있어 DSACK, Eifel Detection, F-RTO 같은 detection algorithm과 함께 사용할 수 있다. 현재 specification은 timer-based retransmission에 대한 response를 중심으로 한다.
response algorithm은 첫 retransmission timer event에서만 동작한다. timer가 expire되면 현재 estimator를 snapshot으로 저장한다.
srtt_prev = srtt + 2 * G
rttvar_prev = rttvarG는 TCP clock granularity다. srtt_prev에 2 * G를 더하는 이유는 spurious timeout이 srtt가 아주 조금 작아서 발생했을 수 있기 때문이다. 약간 키운 값을 저장해 이후 RTO 재설정의 기초로 삼는다.
detection 결과는 SpuriousRecovery에 들어간다.
| 값 | 의미 |
|---|---|
SPUR_TO | early spurious timeout, original transmission ACK로 조기 탐지 |
LATE_SPUR_TO | late spurious timeout, DSACK처럼 retransmission 이후 늦게 탐지 |
| 기타 | spurious가 아니므로 일반 timeout 처리 |
SPUR_TO이면 recovery가 끝나기 전에 sender는 다음 전송 sequence number SND.NXT를 첫 new unsent segment인 SND.MAX로 조정할 수 있다. 이렇게 하면 initial retransmission 이후의 undesirable go-back-N behavior를 피한다. LATE_SPUR_TO이면 initial retransmission에 대한 ACK가 이미 발생했으므로 SND.NXT는 바꾸지 않는다. 두 경우 모두 congestion control state reset은 Chapter 16의 주제다.
spurious timeout 후 새 data에 대한 acceptable ACK가 오면 estimator는 다음처럼 갱신될 수 있다.
srtt <- max(srtt_prev, m)
rttvar <- max(rttvar_prev, m / 2)
RTO = srtt + max(G, 4 * rttvar)m은 timeout 뒤 보낸 data의 첫 acceptable ACK로 얻은 RTT sample이다. 이 식은 실제 path RTT가 갑자기 커졌을 수도 있고, 일시적 delay spike였을 수도 있다는 두 가능성 사이에서 균형을 잡는다. 새 sample이 더 크면 estimator history를 사실상 재초기화하고, 그렇지 않으면 기존 estimator를 유지해 timeout이 있었다는 사실을 무시하는 쪽에 가깝다.
14.8 Packet Reordering and Duplication
TCP retransmission 논의는 대부분 packet loss를 중심으로 하지만, IP network에서는 packet reordering과 duplication도 발생할 수 있다. TCP 입장에서는 reordered packet과 duplicated packet을 lost packet과 구분해야 한다. 그러나 receiver가 out-of-order segment를 받는다는 관찰만으로는 “앞 segment가 진짜 사라졌는지” 또는 “늦게 오는 중인지”를 바로 알 수 없다.
14.8.1 Reordering
IP는 packet delivery order를 보장하지 않는다. 경로 변경, router 내부의 병렬 data path, packet별 processing delay 차이 때문에 나중에 보낸 packet이 먼저 도착할 수 있다. TCP connection에서는 data forward path와 ACK reverse path가 다를 수 있으므로, reordering은 data 방향 또는 ACK 방향, 또는 양쪽 모두에서 발생할 수 있다.
ACK 방향 reordering은 sender가 window를 크게 advance하는 ACK를 먼저 받은 뒤, 나중에 오래된 redundant ACK를 받게 만들 수 있다. 이 redundant ACK들은 discard되지만, sender의 sending pattern에 순간적인 burstiness를 만들거나 congestion control이 available bandwidth를 활용하는 방식을 어렵게 할 수 있다.
data 방향 reordering은 loss와 더 직접적으로 헷갈린다. receiver는 expected sequence number보다 뒤쪽 data를 받으면 hole이 있다고 보고 duplicate ACK를 즉시 보낸다. 이것은 loss가 있을 때 fast retransmit을 빠르게 유도하는 데 필요하지만, 단순 reordering에서도 duplicate ACK가 만들어진다.
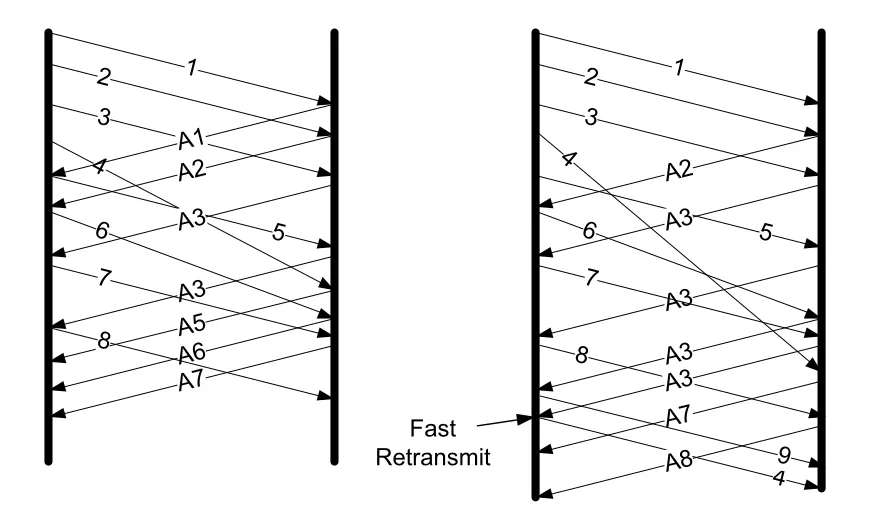
Figure 14-13 · PDF p. 723 · mild reordering은 무시되지만 severe reordering은 spurious fast retransmit을 유발하는 예
Figure 14-13의 왼쪽처럼 작은 reordering에서는 duplicate ACK가 하나 정도만 생기므로 dupthresh = 3 기준에 도달하지 않고 TCP가 문제를 넘긴다. 오른쪽처럼 packet 4가 세 위치 이상 밀려 도착하면 receiver가 duplicate ACK를 세 개 만들 수 있고, sender는 이를 loss로 오해해 fast retransmit을 수행한다. 결과적으로 receiver가 이미 받거나 곧 받을 data에 대한 spurious retransmission이 생긴다.
loss와 reordering을 구분하는 문제는 “sender가 receiver hole을 메우기 전에 얼마나 기다려야 하는가”의 문제다. Internet에서는 severe reordering이 흔하지 않기 때문에 기본 dupthresh = 3이 많은 상황을 처리하지만, 더 심한 reordering을 다루기 위해 dynamic dupthresh 같은 연구와 구현이 존재한다. Linux TCP도 측정된 reordering 정도에 따라 dupthresh를 조정할 수 있다.
14.8.2 Duplication
IP packet duplication은 드물지만 가능하다. 예를 들어 link-layer protocol이 retransmission을 수행하는 과정에서 같은 IP packet copy가 두 번 이상 전달될 수 있다. TCP receiver는 duplicate packet을 받으면 같은 ACK를 반복해 보내므로, sender는 이를 loss로 오인할 수 있다.
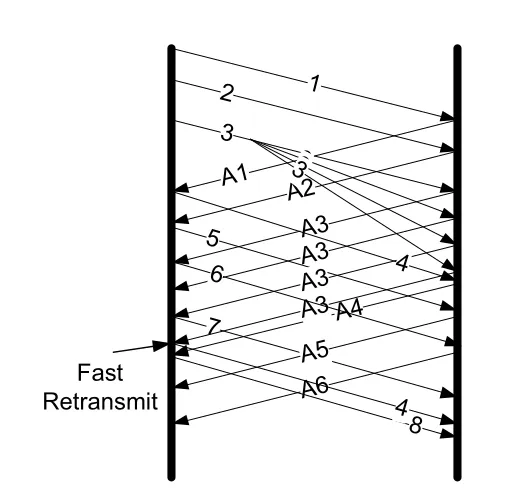
Figure 14-14 · PDF p. 723 · packet duplication이 duplicate ACK를 만들어 spurious fast retransmission을 유발하는 예
Figure 14-14에서는 packet 3이 세 번 duplicate되어 receiver에 도착한다. 이로 인해 ACK 3이 여러 번 반복되고, non-SACK sender는 packet 5와 6이 먼저 도착한 것처럼 오해해 spurious fast retransmit을 수행할 수 있다.
SACK, 특히 DSACK이 있으면 duplication 진단이 쉬워진다. duplicate ACK의 DSACK information이 “segment 3은 이미 받았다”를 알려 주고, 동시에 out-of-order data indication이 없다면 arriving packet 또는 그 ACK가 duplicate였다고 판단할 수 있다. 이 경우 TCP는 spurious retransmission을 억제할 가능성이 커진다.
14.9 Destination Metrics
TCP는 connection이 진행되는 동안 path 특성을 배운다. srtt, rttvar, packet reordering estimate, PMTU, congestion window 관련 값들이 그 예다. 오래된 구현에서는 connection이 닫히면 이 학습 정보도 사라져, 같은 destination으로 새 connection을 열 때 처음부터 다시 estimate해야 했다.
현대 구현은 routing table, forwarding table entry, 또는 system-wide data structure에 destination metrics를 cache할 수 있다. 새 connection이 만들어질 때 TCP는 같은 destination host에 대한 최근 정보가 있는지 확인하고, 있으면 srtt, rttvar 같은 초기값을 이전 경험에 기반해 설정할 수 있다. connection이 닫힐 때는 새로 측정한 통계를 기존 통계에 반영할 기회를 갖는다.
Linux 2.6 예시에서는 ip route show cache <destination>으로 cached metrics를 볼 수 있다. 출력에는 mtu, rtt, rttvar, cwnd, advmss, hoplimit 같은 값이 포함될 수 있다. cwnd는 Chapter 16의 congestion control과 연결되고, advmss와 mtu는 PMTUD/MSS 선택과 연결된다.
14.10 Repacketization
TCP가 timeout 후 retransmit할 때 반드시 원래와 동일한 segment를 다시 보내야 하는 것은 아니다. TCP는 byte stream protocol이므로 data를 segment number가 아니라 byte number로 식별하고 ACK한다. 따라서 같은 byte range를 더 크거나 다른 크기의 segment로 다시 묶어 보내는 repacketization이 가능하다.
repacketization된 segment는 receiver가 광고한 MSS를 넘을 수 없고, path MTU도 넘지 않아야 한다. 이 제약 안에서 더 큰 segment로 묶어 보내면 overhead를 줄여 성능을 높일 수 있다.
본문 예제에서는 처음 hello there가 정상 전송되고, network가 끊긴 동안 line number 2와 and 3가 입력된다. 나중에 trace를 보면 sequence 29:36의 and 3는 out-of-order로 도착하고, receiver는 ACK 14와 SACK block {29:36}을 보낸다. 중간의 sequence 14부터 28까지가 빠져 있기 때문이다.
이후 TCP는 sequence number 14에 대한 retransmission을 수행하지만, 원래 빠진 작은 조각만 보내지 않고 sequence 14:36을 포함하는 22-byte segment로 repacketize한다. 이 segment는 SACK block에 이미 보고된 data와 overlap하며 FIN bit도 함께 가진다. 핵심은 TCP receiver가 byte number 기준으로 ACK/SACK을 해석하기 때문에, retransmitted segment boundary가 original segment boundary와 달라도 protocol상 문제가 없다는 점이다.
repacketization은 retransmission ambiguity를 다루는 아이디어와도 연결된다. STODER 같은 접근은 repacketization을 이용해 spurious timeout을 탐지하려는 시도다. 세부 알고리즘을 암기하기보다, “TCP는 byte stream이므로 재전송 때 packetization boundary를 바꿀 수 있다”는 원리를 잡으면 된다.
14.11 Attacks Involving TCP Retransmission
TCP retransmission은 공격자가 TCP의 timing 판단을 속일 수 있다는 점에서 attack surface가 된다. low-rate DoS attack은 attacker가 gateway나 host에 주기적 burst traffic을 보내 victim TCP가 retransmission timeout을 경험하게 만드는 공격이다. attacker가 victim의 retransmission 시점을 예측할 수 있으면, 매 retransmission attempt마다 burst를 맞춰 넣어 victim이 계속 congestion을 느끼게 할 수 있다.
이 경우 victim TCP는 sending rate를 거의 0에 가깝게 줄이고, Karn’s algorithm에 따라 RTO를 계속 backoff한다. 처리량은 매우 낮아진다. 대응 아이디어는 RTO에 randomization을 추가해 attacker가 정확한 retransmission 시점을 예측하기 어렵게 만드는 것이다.
또 다른 공격은 RTT estimate를 왜곡하는 것이다. attacker가 victim TCP segment를 느리게 만들어 RTT estimate를 지나치게 높이면, victim TCP는 loss가 났을 때 retransmit을 너무 늦게 하는 passive TCP가 된다. 반대로 attacker가 data가 실제 receiver에 도착하기 전에 forged ACK를 보내면 victim TCP는 RTT가 실제보다 훨씬 작다고 믿고, 너무 aggressive하게 retransmit하여 불필요한 traffic을 만들 수 있다.
14.12 Summary
TCP timeout and retransmission 전략의 출발점은 RTO다. sender는 RTT를 측정하고, smoothed RTT estimator(srtt)와 smoothed mean deviation estimator(rttvar)를 유지하며, 이를 바탕으로 다음 retransmission timeout을 정한다. Karn’s algorithm은 retransmission ambiguity를 피하기 위해 retransmitted segment의 ACK를 RTT sample로 쓰지 않고, 연속 timeout에서 binary exponential backoff를 적용한다.
Timestamps option(TSOPT)은 오늘날 대부분의 TCP에서 RTTM에 쓰인다. TSOPT가 있으면 각 segment를 더 세밀하게 timing할 수 있고, reordering이나 duplication 상황에서도 timestamp echo 규칙을 통해 비교적 robust한 RTT sample을 얻을 수 있다.
timer-based retransmission은 TCP의 안전망이지만 보통 느리다. fast retransmit은 duplicate ACK 또는 SACK information을 이용해 timer expiration 없이 receiver hole을 메운다. SACK-capable TCP는 ACK에 여러 SACK block을 담아 sender가 한 RTT 안에서 여러 hole을 파악하고 복구할 수 있게 한다.
spurious retransmission은 실제 loss 없이 timeout, reordering, duplication, ACK loss 등으로 잘못 retransmit하는 상황이다. DSACK은 duplicate segment 도착을 알려 sender가 불필요한 retransmission을 추론하게 하고, Eifel Detection은 TSOPT를 이용해 original transmit에 대한 ACK를 조기에 식별한다. F-RTO는 timestamp 없이도 timeout 후 새 data를 보내 첫 두 ACK의 성격으로 spurious timeout을 판단한다. Eifel Response Algorithm은 spurious timeout이 확인되면 go-back-N behavior를 피하고 RTT/RTO estimator를 조정한다.
마지막으로 TCP는 connection이 끝난 뒤에도 destination metrics를 cache할 수 있고, byte stream 기반이므로 retransmission 때 repacketization을 수행할 수 있다. retransmission timing은 low-rate DoS, RTT inflation, forged ACK 같은 공격에도 영향을 받으며, 이 공격들의 congestion control 결과는 Chapter 16에서 더 중요해진다.