Chapter 4. Threads and Concurrency
- 과목: Operating System
- 기준 교재: Operating System Concepts 10th
- 관련 페이지: PDF pp. 216-254
- 우선순위: 필수
개요
Chapter 3의 process model은 하나의 process가 하나의 thread of control을 가진다고 단순화했다. Chapter 4는 이 가정을 확장한다. 현대 운영체제의 process는 하나의 실행 흐름만 갖는 것이 아니라, 같은 process 안에 여러 threads of control을 포함할 수 있다. Thread는 CPU utilization의 기본 단위이며, multicore system에서 parallelism을 끌어내기 위한 핵심 추상화다.
Thread를 쓰면 한 application 안에서 UI 응답, background I/O, computation, request handling 같은 작업을 동시에 진행할 수 있다. 그러나 thread는 같은 address space와 process resource를 공유하므로, 성능과 responsiveness를 얻는 대신 data dependency, synchronization, testing/debugging, cancellation, signal handling 같은 문제가 따라온다. 이 장은 thread의 구조, multicore programming의 어려움, user threads와 kernel threads의 mapping model, thread library, implicit threading, threading issues, Windows/Linux thread representation을 순서대로 다룬다.
핵심 개념
| 개념 | 핵심 의미 |
|---|---|
thread | CPU utilization의 기본 단위. thread ID, program counter, register set, stack을 가짐 |
multithreaded process | 같은 process 안에 여러 threads of control을 가진 process |
code/data/files sharing | 같은 process의 threads는 code section, data section, open files, signals 같은 resource를 공유 |
responsiveness | 일부 작업이 block되어도 application이 계속 사용자에게 반응할 수 있는 성질 |
economy | process보다 thread 생성과 thread context switch가 더 싸다는 성질 |
scalability | multicore/multiprocessor에서 threads가 parallel하게 실행되어 성능 이득을 얻는 성질 |
concurrency | 여러 task가 진행되도록 지원하는 성질. single core에서도 interleaving으로 가능 |
parallelism | 여러 task가 실제로 동시에 실행되는 성질. multiple cores가 필요 |
data parallelism | 같은 operation을 data subset별로 나눠 multiple cores에서 수행 |
task parallelism | 서로 다른 task/thread를 multiple cores에 나눠 수행 |
Amdahl's Law | serial portion이 multicore speedup의 상한을 제한한다는 법칙 |
세부 정리
4.1 Overview
Thread의 구성 요소와 process와의 차이
thread는 CPU utilization의 basic unit이다. Thread 하나는 다음 실행 상태를 가진다.
thread IDprogram counter (PC)register setstack
반면 같은 process에 속한 threads는 다음 process resource를 공유한다.
code sectiondata sectionopen filessignals- 기타 operating-system resources
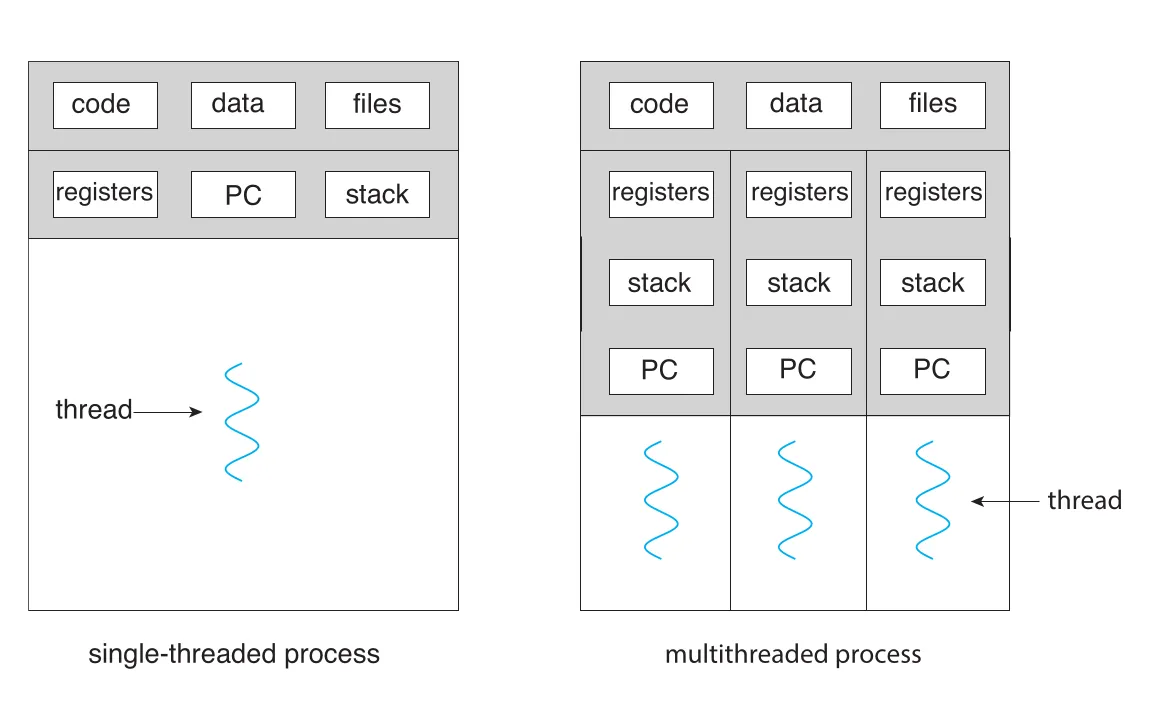
Figure 4.1 · PDF p. 217 · single-threaded process와 multithreaded process의 resource 공유 차이
Figure 4.1은 process와 thread의 경계를 잘 보여준다. Single-threaded process는 register, PC, stack이 하나씩이고 실행 흐름도 하나다. Multithreaded process는 code/data/files를 공유하지만, 각 thread가 자기 registers, PC, stack을 따로 가진다. 따라서 thread는 “가벼운 process”처럼 보일 수 있지만, 독립 address space를 갖는 process와 달리 같은 address space 안에서 실행된다는 점이 핵심 차이다.
Motivation: 왜 threads가 필요한가
현대 application은 대부분 multithreaded다. 예시는 다음과 같다.
- Image collection에서 각 image thumbnail을 별도 thread로 생성한다.
- Web browser가 한 thread로 image/text를 display하고, 다른 thread로 network에서 data를 retrieve한다.
- Word processor가 graphics display, keystroke response, spelling/grammar checking을 별도 threads로 수행한다.
Web server 예시는 thread의 경제성을 잘 보여준다. Busy web server는 수많은 clients의 web page, image, sound request를 동시에 처리해야 한다. Single-threaded server라면 한 번에 한 client만 처리하므로 대기 시간이 길어진다. 예전 방식처럼 request마다 process를 새로 만들 수도 있지만 process creation은 time-consuming하고 resource intensive하다. 같은 server code와 resource를 대부분 공유하는 request handler라면 process보다 thread를 만드는 편이 훨씬 효율적이다.
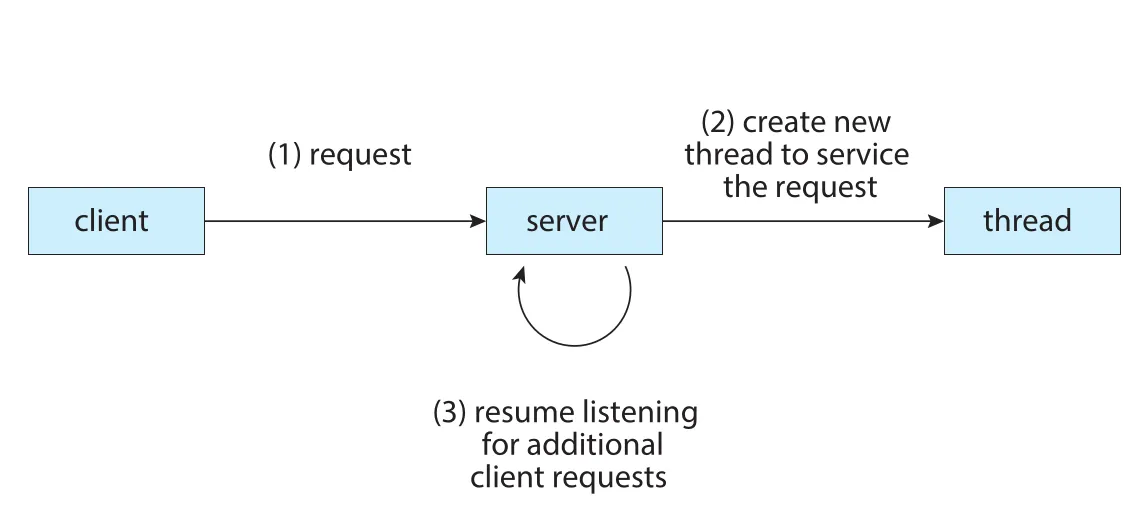
Figure 4.2 · PDF p. 218 · server가 request마다 새 thread를 만들고 다시 listening으로 돌아가는 구조
Figure 4.2의 multithreaded server는 request를 받으면 새 thread를 만들어 해당 request를 처리하게 하고, main server thread는 다시 client request를 listen한다. 이 구조는 responsiveness와 throughput을 모두 높인다.
Operating system kernel 자체도 보통 multithreaded다. Linux는 boot time에 device management, memory management, interrupt handling 같은 task를 담당하는 여러 kernel threads를 만든다. ps -ef로 확인하면 kthreadd가 pid 2를 가지며 다른 kernel threads의 parent 역할을 하는 것을 볼 수 있다. 즉 threads는 application-level convenience만이 아니라 kernel 내부 작업 분해에도 쓰인다.
Benefits of Multithreading
Multithreaded programming의 benefit은 네 가지로 요약된다.
| Benefit | 의미 | 예시/효과 |
|---|---|---|
responsiveness | 일부 thread가 block되거나 긴 작업을 수행해도 process 전체가 멈추지 않음 | UI thread는 반응 유지, background thread가 긴 작업 수행 |
resource sharing | 같은 process의 memory/resources를 threads가 기본적으로 공유 | shared memory/message passing을 별도 구성하지 않아도 code/data 공유 |
economy | thread creation/context switch가 process보다 일반적으로 저렴 | request마다 process 대신 thread 생성 |
scalability | multiprocessor/multicore에서 threads가 parallel하게 실행 가능 | 여러 cores에 threads를 분산 |
Resource sharing은 장점이면서 위험이다. Threads는 같은 address space를 공유하므로 data exchange가 쉽지만, 동시에 같은 data를 수정하면 race condition이 생긴다. 이 문제는 Chapter 6의 synchronization으로 이어진다.
4.2 Multicore Programming
Concurrency와 Parallelism
Multicore system은 한 chip 안에 여러 computing cores를 두고, 각 core가 운영체제에는 별도의 CPU처럼 보이게 한다. Multithreaded programming은 이런 cores를 더 효율적으로 활용하는 mechanism이다.
Single-core system에서도 여러 threads는 concurrent하게 실행될 수 있다. 다만 한 순간에 하나의 thread만 core에서 실행되므로, scheduler가 threads를 빠르게 switch하면서 interleaving할 뿐이다.

Figure 4.3 · PDF p. 220 · single core에서 T1-T4가 interleaving되어 concurrent하게 진행되는 모습
Multicore system에서는 여러 threads가 서로 다른 cores에 배정되어 실제로 동시에 실행될 수 있다.
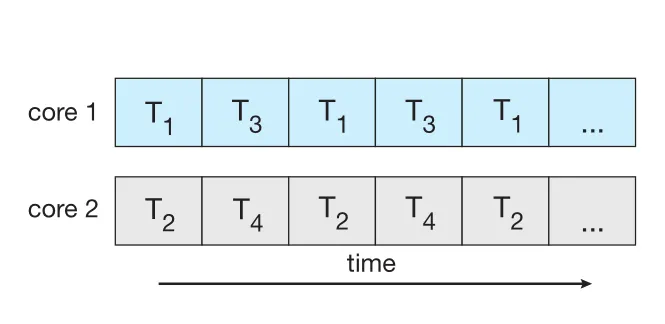
Figure 4.4 · PDF p. 220 · multiple cores에서 여러 threads가 동시에 실행되는 parallel execution
| 구분 | 의미 | single core 가능 여부 | multicore 필요 여부 |
|---|---|---|---|
concurrency | 여러 tasks가 모두 progress하도록 지원 | 가능 | 필수 아님 |
parallelism | 여러 tasks가 같은 시간에 실제로 실행 | 불가능 | 필요 |
즉 concurrency without parallelism은 가능하다. Single-core 시대의 scheduler는 빠른 context switch로 parallelism의 illusion을 제공했다. 그러나 실제 simultaneous execution은 multicore/multiprocessor가 있어야 한다.
Multicore programming challenges
Multicore programming은 단순히 thread를 많이 만들면 끝나는 문제가 아니다. 원문은 다섯 가지 challenge를 제시한다.
| Challenge | 설명 | 주의점 |
|---|---|---|
identifying tasks | application에서 분리 가능한 concurrent tasks를 찾음 | 독립적으로 run 가능한 task일수록 parallel 실행에 적합 |
balance | tasks가 비슷한 양과 가치의 일을 하도록 조정 | 어떤 task가 너무 작으면 별도 core 사용 비용이 더 클 수 있음 |
data splitting | task가 접근할 data를 cores별로 나눔 | data partition이 불균형하면 일부 core가 놀 수 있음 |
data dependency | task 사이 data dependency를 분석 | dependency가 있으면 synchronization 필요 |
testing and debugging | parallel execution paths를 검증 | 실행 순서가 다양해 single-threaded program보다 어렵다 |
운영체제 설계자에게도 challenge가 있다. Scheduler는 multiple processing cores를 활용해 threads가 실제 parallel execution을 하도록 scheduling algorithm을 설계해야 한다. Application programmer는 기존 sequential program을 multithreaded form으로 바꾸거나, 처음부터 parallelism을 염두에 둔 design을 해야 한다.
Amdahl’s Law
Multicore를 추가한다고 성능이 무한히 선형 증가하지는 않는다. Amdahl's Law는 application 안에 serial component와 parallel component가 함께 있을 때, 추가 cores로 얻을 수 있는 speedup의 상한을 보여준다.
Serial portion을 , processing cores 수를 이라고 하면:
예를 들어 application의 75%가 parallel이고 25%가 serial이면, 2 cores에서는 speedup이 약 1.6배, 4 cores에서는 약 2.28배다. 이 infinity로 가도 speedup은 에 수렴한다. 즉 50%가 serial이면 core를 아무리 늘려도 maximum speedup은 2배다.
이 법칙의 핵심은 serial portion이 전체 성능 이득에 disproportionate effect를 준다는 점이다. Thread를 늘리는 것보다 더 중요한 것은 serial bottleneck을 줄이고, parallelizable portion을 잘 찾아내는 것이다.
Data parallelism과 Task parallelism
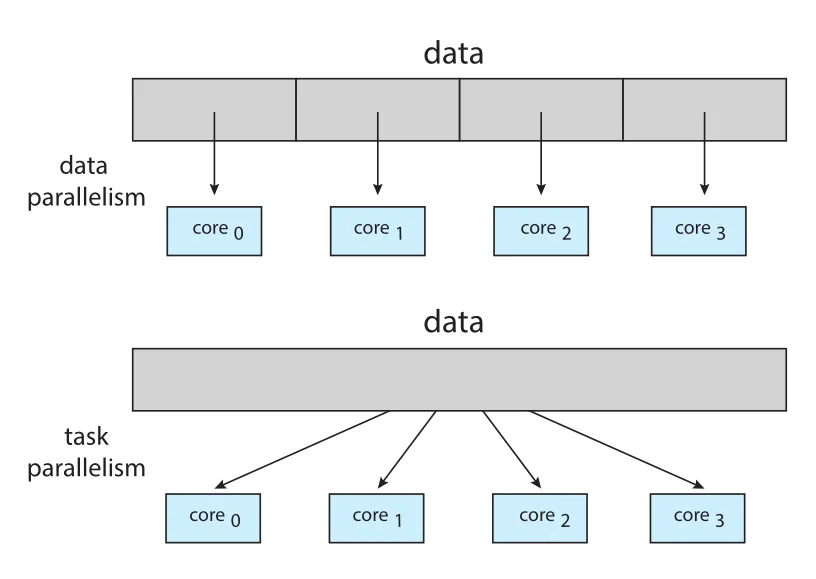
Figure 4.5 · PDF p. 222 · data parallelism과 task parallelism의 분배 방식 차이
Parallelism은 크게 두 유형으로 나뉜다.
| 유형 | 핵심 아이디어 | 예시 |
|---|---|---|
data parallelism | 같은 data set을 subset으로 나누고, 각 core가 같은 operation을 수행 | array summation을 , 로 나눠 처리 |
task parallelism | 서로 다른 tasks/threads를 multiple cores에 나눠 배치 | 같은 array에 대해 한 thread는 평균, 다른 thread는 표준편차 계산 |
Data parallelism은 “data를 나눈다”가 중심이고, task parallelism은 “일의 종류를 나눈다”가 중심이다. 둘은 mutually exclusive하지 않다. 실제 application은 data parallelism과 task parallelism을 hybrid로 사용할 수 있다.
4.3 Multithreading Models
User threads와 Kernel threads
Thread support는 user level 또는 kernel level에서 제공될 수 있다.
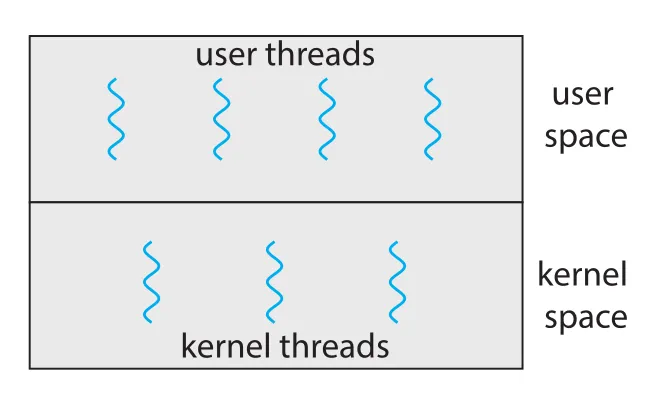
Figure 4.6 · PDF p. 223 · user space의 user threads와 kernel space의 kernel threads 관계
| 구분 | 의미 | 관리 주체 |
|---|---|---|
user threads | kernel 위 user space에서 지원되는 threads | thread library가 kernel support 없이 관리 |
kernel threads | 운영체제가 직접 지원하고 관리하는 threads | kernel scheduler와 OS가 관리 |
현대 운영체제인 Windows, Linux, macOS는 모두 kernel threads를 지원한다. 그러나 application이 보는 user-level thread와 kernel이 실제 schedule하는 kernel thread 사이에는 mapping relationship이 필요하다. 대표 model은 many-to-one, one-to-one, many-to-many다.
Many-to-One Model
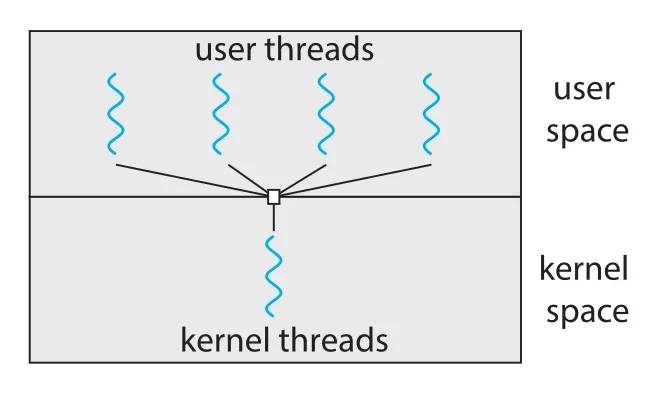
Figure 4.7 · PDF p. 223 · 여러 user-level threads가 하나의 kernel thread에 mapping되는 many-to-one model
many-to-one model은 many user-level threads를 one kernel thread에 mapping한다. Thread management가 user space의 thread library에서 이루어지므로 효율적이다. User-level function call로 thread switching이 가능하고 kernel system call 비용을 피할 수 있기 때문이다.
하지만 구조적 한계가 크다.
- 어떤 thread가 blocking system call을 호출하면 전체 process가 block된다.
- 한 번에 하나의 thread만 kernel에 접근할 수 있으므로 multiple threads가 multicore에서 parallel하게 실행될 수 없다.
- 개발자는 user threads를 많이 만들 수 있지만 kernel이 schedule할 kernel thread는 하나뿐이다.
Solaris의 Green threads와 초기 Java의 thread library가 이 model을 사용했지만, multicore 활용이 불가능하다는 약점 때문에 현재는 거의 쓰이지 않는다.
One-to-One Model
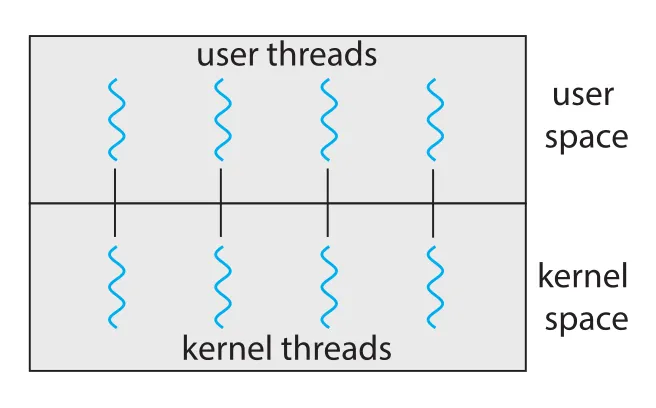
Figure 4.8 · PDF p. 224 · 각 user thread가 하나의 kernel thread에 대응되는 one-to-one model
one-to-one model은 each user thread를 one kernel thread에 mapping한다. 어떤 thread가 blocking system call을 호출해도 다른 thread는 계속 실행될 수 있고, multiprocessor/multicore에서 여러 threads가 parallel하게 실행될 수 있다. 따라서 many-to-one보다 concurrency와 parallelism이 좋다.
단점은 user thread를 만들 때마다 corresponding kernel thread도 만들어야 한다는 점이다. Kernel thread가 많아지면 kernel memory, scheduling overhead, context-switch overhead가 커질 수 있다. 그래서 어떤 system은 process가 만들 수 있는 thread 수를 제한하기도 한다.
Linux와 Windows 계열 운영체제는 one-to-one model을 구현한다. 현대 multicore 환경에서는 kernel thread 수를 줄이는 것보다 실제 parallel execution을 얻는 것이 더 중요해졌기 때문에 이 model이 주류가 되었다.
Many-to-Many Model과 Two-Level Model
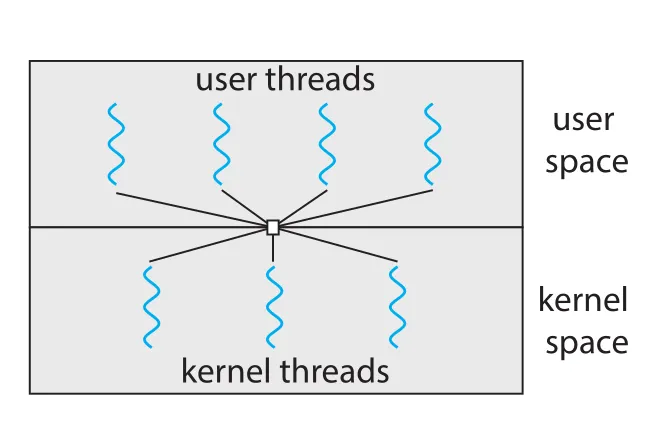
Figure 4.9 · PDF p. 224 · 여러 user-level threads를 더 적거나 같은 수의 kernel threads에 multiplex하는 many-to-many model
many-to-many model은 many user-level threads를 smaller or equal number의 kernel threads에 multiplex한다. Kernel thread 수는 application 또는 machine 특성에 맞게 조정될 수 있다. 예를 들어 8-core system에서는 4-core system보다 더 많은 kernel threads를 application에 배정할 수 있다.
Many-to-many model의 의도는 many-to-one과 one-to-one의 단점을 함께 피하는 것이다.
- 개발자는 필요한 만큼 user threads를 만들 수 있다.
- Kernel threads는 multiprocessor에서 parallel하게 실행될 수 있다.
- 한 user thread가 blocking system call을 수행해도 kernel은 다른 thread를 schedule할 수 있다.
- Kernel thread 수를 user thread 수보다 적게 유지해 resource burden을 조절할 수 있다.
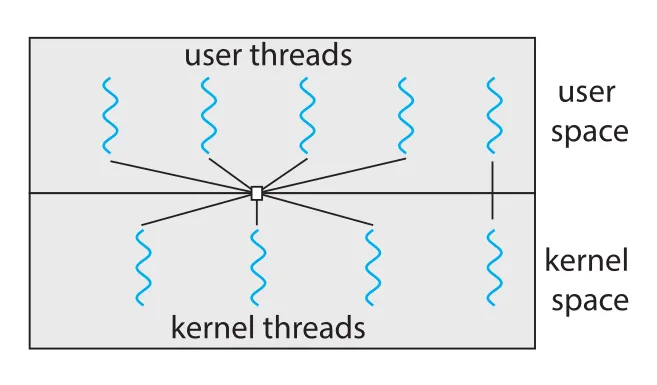
Figure 4.10 · PDF p. 225 · many-to-many mapping에 특정 user thread와 kernel thread binding을 허용하는 two-level model
two-level model은 many-to-many model의 variation이다. 기본적으로 many user-level threads를 smaller/equal number의 kernel threads에 multiplex하지만, 특정 user-level thread를 특정 kernel thread에 bind할 수도 있다.
| Model | 장점 | 단점 |
|---|---|---|
many-to-one | user-space management로 빠름, thread 생성이 가벼움 | blocking system call이 전체 process를 block, multicore parallelism 불가 |
one-to-one | blocking call 중에도 다른 thread 실행 가능, true parallelism 가능 | user thread마다 kernel thread 필요, 너무 많은 threads가 system burden |
many-to-many | user thread 수와 kernel thread 수를 분리해 유연함 | 구현이 어렵고 runtime/kernel 협력이 복잡 |
two-level | many-to-many 유연성 + 필요한 thread binding | complexity 증가 |
Many-to-many는 이론적으로 flexible하지만 구현이 어렵다. 또한 processing cores가 많아지면서 kernel thread 수를 강하게 제한할 필요가 줄어들었다. 그래서 대부분의 OS는 one-to-one model을 사용한다. 다만 Section 4.5의 일부 concurrency libraries는 developer가 tasks를 식별하면 library/runtime이 tasks를 threads에 mapping하는 방식으로 many-to-many 아이디어를 다시 활용한다.
4.4 Thread Libraries
Thread library 구현 방식
thread library는 programmer에게 threads를 create/manage하는 API를 제공한다. 구현 방식은 두 가지다.
| 구현 방식 | 위치 | API 호출 비용 | 특징 |
|---|---|---|---|
| user-space library | library code와 data structures가 user space에 존재 | local function call | kernel support 없이 빠르지만 kernel scheduling과의 연결이 약함 |
| kernel-level library | code와 data structures가 kernel space에 존재 | 보통 system call | OS가 직접 관리하므로 kernel threads와 잘 연결됨 |
주요 thread libraries는 세 가지다.
| Library | 특징 |
|---|---|
POSIX Pthreads | POSIX standard의 thread extension. user-level 또는 kernel-level 구현 가능 |
Windows thread library | Windows systems에서 제공되는 kernel-level library |
Java thread API | Java program에서 threads 생성/관리. 실제 구현은 host OS thread library 위에 놓이는 경우가 많음 |
Java threads는 JVM 위에서 제공되지만, JVM 자체가 host OS 위에서 실행되므로 보통 OS thread library를 사용한다. Windows에서는 Windows API, UNIX/Linux/macOS에서는 Pthreads를 사용하는 식이다.
POSIX와 Windows threading에서 function 밖에 선언된 global data는 같은 process의 모든 threads가 공유한다. Java에는 C식 global data 개념이 없으므로 shared data access를 명시적으로 구성해야 한다.
Asynchronous threading과 Synchronous threading
Thread creation strategy는 크게 두 가지다.
| Strategy | 의미 | 주 사용처 |
|---|---|---|
asynchronous threading | parent가 child thread를 만든 뒤 즉시 자기 실행을 계속함. parent/child가 독립적으로 concurrent 실행 | multithreaded server, responsive UI |
synchronous threading | parent가 one or more children을 만든 뒤 모든 children이 terminate/join할 때까지 기다림 | parallel calculation 후 결과 combine |
Asynchronous threading은 일반적으로 data sharing이 적다. Request handler나 background UI task처럼 parent가 child 완료를 기다리지 않아도 되는 경우에 적합하다. Synchronous threading은 children이 계산한 결과를 parent가 모아야 하는 경우가 많으므로 significant data sharing이 발생한다. 원문의 Pthreads/Windows/Java summation examples는 모두 synchronous threading을 사용한다.
Pthreads
Pthreads는 POSIX standard(IEEE 1003.1c)가 정의한 thread creation과 synchronization API다. Pthreads는 implementation이 아니라 specification이다. OS designer는 이 specification을 원하는 방식으로 구현할 수 있다. Linux와 macOS 같은 UNIX-type systems가 대표적으로 Pthreads를 구현한다. Windows는 native Pthreads를 지원하지 않지만 third-party implementation은 존재한다.

Figure 4.11 · PDF p. 227 · `pthread_create()`와 `pthread_join()`으로 summation thread를 만드는 Pthreads 예제
Figure 4.11은 non-negative integer N에 대해 sum = 1 + 2 + ... + N을 별도 thread에서 계산한다. 핵심 흐름은 다음과 같다.
pthread.h를 include한다.pthread_t tid로 thread identifier를 선언한다.pthread_attr_t attr로 thread attributes를 선언한다.pthread_attr_init(&attr)로 default attributes를 설정한다.pthread_create(&tid, &attr, runner, argv[1])로 새 thread를 만들고, 그 thread가runner()에서 시작하게 한다.- Parent thread는
pthread_join(tid, NULL)로 summation thread가 끝날 때까지 wait한다. - Child thread는
pthread_exit(0)으로 종료한다.
이 예제에서 sum은 global variable이므로 parent thread와 summation thread가 공유한다. Thread가 같은 process address space를 공유한다는 사실이 code에서 직접 드러나는 부분이다.
여러 threads를 기다릴 때는 pthread_join()을 loop로 호출할 수 있다.

Figure 4.12 · PDF p. 228 · ten Pthreads를 `pthread_join()` loop로 기다리는 예제
Windows Threads
Windows thread API도 Pthreads와 유사하게 thread function을 지정하고 parent가 child thread completion을 기다린다. Windows API를 쓰려면 windows.h를 include한다.

Figure 4.13 · PDF p. 229 · `CreateThread()`와 `WaitForSingleObject()`를 사용하는 Windows summation thread 예제
Figure 4.13에서 Sum은 global variable이며, child thread가 Summation() function에서 값을 누적한다. Windows의 주요 API는 다음과 같다.
| API/Type | 역할 |
|---|---|
CreateThread() | 새 thread 생성 |
DWORD | unsigned 32-bit integer type |
LPVOID | void *에 해당하는 Windows pointer type |
HANDLE | 생성된 thread object에 접근하는 handle |
WaitForSingleObject() | 하나의 thread/object가 signaled 상태가 될 때까지 wait |
WaitForMultipleObjects() | 여러 thread/object completion을 wait |
CloseHandle() | thread handle close |
CreateThread()는 security attributes, stack size, thread function, function parameter, creation flags, thread identifier pointer를 받는다. Default creation flags를 사용하면 thread는 suspended state가 아니라 CPU scheduler에 의해 run 가능한 상태가 된다.
Pthreads의 pthread_join()에 해당하는 Windows API는 WaitForSingleObject(ThreadHandle, INFINITE)다. 여러 child threads를 기다릴 때는 WaitForMultipleObjects(N, THandles, TRUE, INFINITE)를 사용한다. 여기서 TRUE는 모든 objects가 signaled될 때까지 기다린다는 뜻이다.
Java Threads의 시작점
Java program에서 threads는 program execution의 fundamental model이다. 단순히 main() method만 있는 Java program도 JVM 안에서 single thread로 실행된다. Java thread API는 Windows, Linux, macOS처럼 JVM을 제공하는 system에서 사용할 수 있고, Android application에서도 사용할 수 있다.
Java에서 explicit하게 thread를 만드는 기본 방법은 두 가지다.
| 방식 | 설명 |
|---|---|
Thread class 상속 | 새 class가 Thread를 extend하고 run() method를 override |
Runnable interface 구현 | class가 Runnable을 implement하고 public void run()에 thread code 작성 |
더 일반적으로 쓰이는 방식은 Runnable 구현이다. Runnable은 thread가 수행할 task를 object로 분리하므로, Java의 single inheritance 제약을 덜 받고 thread 실행 대상과 thread object를 더 명확히 나눌 수 있다.
Java에서 thread creation은 Thread object를 만들고, Runnable을 구현한 object를 넘긴 뒤, start()를 호출하는 방식으로 이루어진다.
Thread worker = new Thread(new Task());
worker.start();start()를 호출하면 두 일이 일어난다.
- JVM 안에 새 thread를 위한 memory를 allocate하고 initialize한다.
- 그 thread가
run()method를 실행할 수 있도록 JVM scheduler에 eligible하게 만든다.
주의할 점은 programmer가 run()을 직접 호출하지 않는다는 것이다. run()을 직접 호출하면 새 thread가 생기는 것이 아니라 현재 thread에서 ordinary method call처럼 실행된다. 새 thread를 만들려면 반드시 start()를 호출해야 한다.
Parent thread가 child thread completion을 기다릴 때는 Java의 join() method를 사용한다. 이는 Pthreads의 pthread_join()과 Windows의 WaitForSingleObject()에 해당한다. 여러 threads를 기다릴 때는 join()을 loop로 호출할 수 있다.
Java 1.8 이후에는 Lambda expression으로 Runnable을 더 짧게 만들 수 있다.
Runnable task = () -> {
System.out.println("I am a thread.");
};
Thread worker = new Thread(task);
worker.start();Lambda expression과 closure는 이후 OpenMP, GCD, TBB 같은 parallel programming interface에서 task를 간결하게 표현하는 방식과도 연결된다.
Java Executor Framework
Java는 초기부터 Thread object를 직접 만드는 방식을 지원했지만, Java 1.5 이후 java.util.concurrent package를 통해 thread creation과 task execution을 분리하는 concurrency feature를 제공한다. 중심 interface는 Executor다.
public interface Executor {
void execute(Runnable command);
}Executor를 쓰면 developer는 new Thread(...).start()를 직접 호출하는 대신, task를 Executor에게 제출한다.
Executor service = new Executor;
service.execute(new Task());Executor framework는 producer-consumer model로 이해할 수 있다. Runnable tasks가 produced되고, 이 tasks를 실행하는 threads가 consume한다. 장점은 thread creation과 execution을 분리할 뿐 아니라 concurrent tasks 사이 communication과 result handling을 지원하는 구조로 확장할 수 있다는 점이다.
Java는 C/Pthreads처럼 global data를 쉽게 공유하는 model이 아니다. Runnable은 task를 실행할 수는 있지만 result를 return하지 못한다. 이를 보완하기 위해 Callable과 Future가 등장한다.
| Interface/Object | 역할 |
|---|---|
Runnable | run()을 실행하지만 result를 return하지 않음 |
Callable<V> | call()을 실행하고 result를 return할 수 있음 |
Future<V> | 아직 끝나지 않았을 수 있는 asynchronous computation의 result handle |
Future.get() | result가 available할 때까지 wait한 뒤 value를 가져옴 |

Figure 4.14 · PDF p. 233 · `Callable`, `ExecutorService`, `Future`를 이용한 Java summation 예제
Figure 4.14에서 Summation class는 Callable<Integer>를 implement하고, thread에서 실행될 code는 call() method에 들어간다. Executors.newSingleThreadExecutor()는 ExecutorService를 만들고, pool.submit(new Summation(upper))는 task를 제출하면서 Future<Integer>를 반환한다. Parent는 result.get()으로 summation result가 준비될 때까지 기다린다.
이 model은 단순 thread creation/join보다 복잡해 보이지만 중요한 장점이 있다.
- Thread가 result를 return할 수 있다.
- Parent는 thread termination 자체가 아니라 result availability를 기다린다.
- Thread pool 같은 더 강한 management 도구와 자연스럽게 결합된다.
4.5 Implicit Threading
Multicore processing이 계속 확산되면서 application 하나가 hundreds 또는 thousands of threads를 포함할 가능성이 커졌다. 하지만 programmer가 thread creation, scheduling, load balancing, synchronization detail을 모두 직접 관리하면 correctness와 maintainability가 크게 어려워진다.
implicit threading은 thread creation/management를 application developer가 아니라 compiler와 run-time library로 넘기는 전략이다. Developer는 “어떤 task가 parallel하게 실행될 수 있는가”를 식별하고, library/runtime이 실제 thread 생성, task assignment, thread pool management를 처리한다. 일반적으로 task는 function 형태로 작성되고, runtime이 many-to-many model과 비슷하게 tasks를 threads에 mapping한다.
Thread Pools
Thread-per-request server는 process-per-request보다 낫지만 여전히 문제가 있다.
- Request마다 thread를 새로 만들면 creation cost가 반복된다.
- Work가 끝난 thread를 바로 discard하면 재사용 이점이 없다.
- Concurrent requests마다 새 thread를 무제한 만들면 CPU time, memory 같은 system resources가 고갈될 수 있다.
thread pool은 startup 때 일정 수의 threads를 미리 만들고 pool에 대기시킨다. Server가 request를 받으면 thread를 새로 만들지 않고 task를 pool에 submit한다. Available thread가 있으면 즉시 깨어나 request를 처리하고, 없으면 task는 queue에서 기다린다. Work를 끝낸 thread는 종료되지 않고 pool로 돌아가 다음 work를 기다린다.
Thread pool의 장점은 세 가지다.
| 장점 | 설명 |
|---|---|
| faster service | 기존 thread를 깨우는 것이 새 thread를 만드는 것보다 빠른 경우가 많음 |
| resource bound | 동시에 존재하는 thread 수를 제한해 system resource exhaustion을 막음 |
| policy separation | task 자체와 thread creation mechanics를 분리해 delayed/periodic execution 같은 전략을 적용 가능 |
Thread pool size는 CPU 수, physical memory, expected concurrent client requests 같은 요소를 바탕으로 heuristic하게 정할 수 있다. 더 정교한 architecture는 load가 낮을 때 pool을 줄이고, load가 높을 때 pool을 늘리는 식으로 dynamic adjustment를 한다.
Android의 AIDL도 thread pool을 제공한다. Remote service는 pool의 separate thread를 이용해 multiple concurrent requests를 처리할 수 있다. 이는 Chapter 3의 Android RPC와 자연스럽게 연결된다.
Windows thread pool API에서는 QueueUserWorkItem() 같은 function으로 pool에 work를 제출한다.
QueueUserWorkItem(&PoolFunction, NULL, 0);이 호출은 thread pool의 thread가 programmer 대신 PoolFunction()을 실행하게 만든다. Windows thread pool API에는 periodic interval이나 asynchronous I/O completion 시 function을 invoke하는 utility도 포함된다.
Java Thread Pools
Java의 java.util.concurrent package는 여러 thread-pool architecture를 제공한다.
| Factory method | 의미 |
|---|---|
newSingleThreadExecutor() | size 1 thread pool |
newFixedThreadPool(int size) | 지정한 수의 threads를 가진 fixed-size pool |
newCachedThreadPool() | 필요에 따라 threads를 reuse하는 unbounded thread pool |
각 factory method는 ExecutorService를 implement하는 object를 반환한다. ExecutorService는 Executor를 extend하므로 execute()를 제공하고, 추가로 pool termination management method를 제공한다.

Figure 4.15 · PDF p. 237 · `Executors.newCachedThreadPool()`로 Java thread pool을 만들고 tasks를 실행하는 예제
Figure 4.15는 newCachedThreadPool()로 pool을 만들고, command-line에서 받은 numTasks만큼 pool.execute(new Task())로 tasks를 제출한다. 마지막의 pool.shutdown()은 추가 task를 거부하고 기존 tasks가 모두 끝나면 pool을 종료한다.
Fork Join
fork-join model은 parent thread가 one or more child threads를 fork하고, children이 terminate한 뒤 join하여 결과를 combine하는 synchronous model이다. Section 4.4의 explicit thread creation도 fork-join으로 볼 수 있다. Implicit threading에서는 programmer가 직접 threads를 만들지 않고 parallel tasks만 지정하며, library가 task 수와 실제 threads 수를 관리한다.
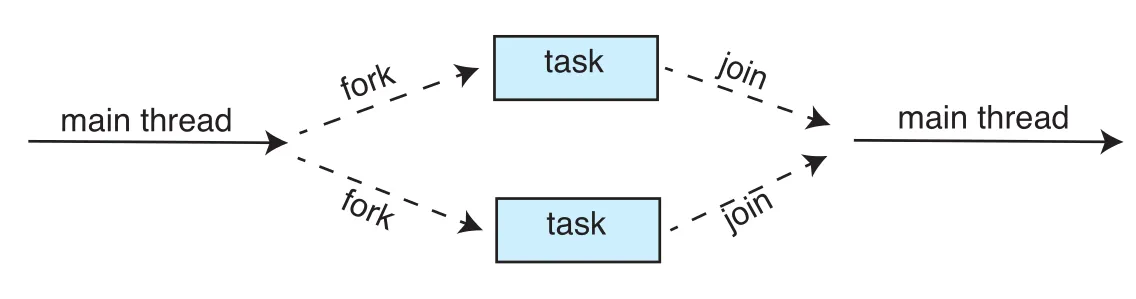
Figure 4.16 · PDF p. 238 · main thread가 tasks를 fork하고 join으로 결과를 회수하는 fork-join parallelism
Java 1.7의 fork-join library는 Quicksort, Mergesort 같은 recursive divide-and-conquer algorithms에 적합하다. 큰 problem을 작은 subproblems로 나누고, subtask를 fork한 뒤, 각 subtask result를 join해 combine한다.
일반 형태는 다음과 같다.
Task(problem)
if problem is small enough
solve directly
else
subtask1 = fork(new Task(subset of problem))
subtask2 = fork(new Task(subset of problem))
result1 = join(subtask1)
result2 = join(subtask2)
return combined results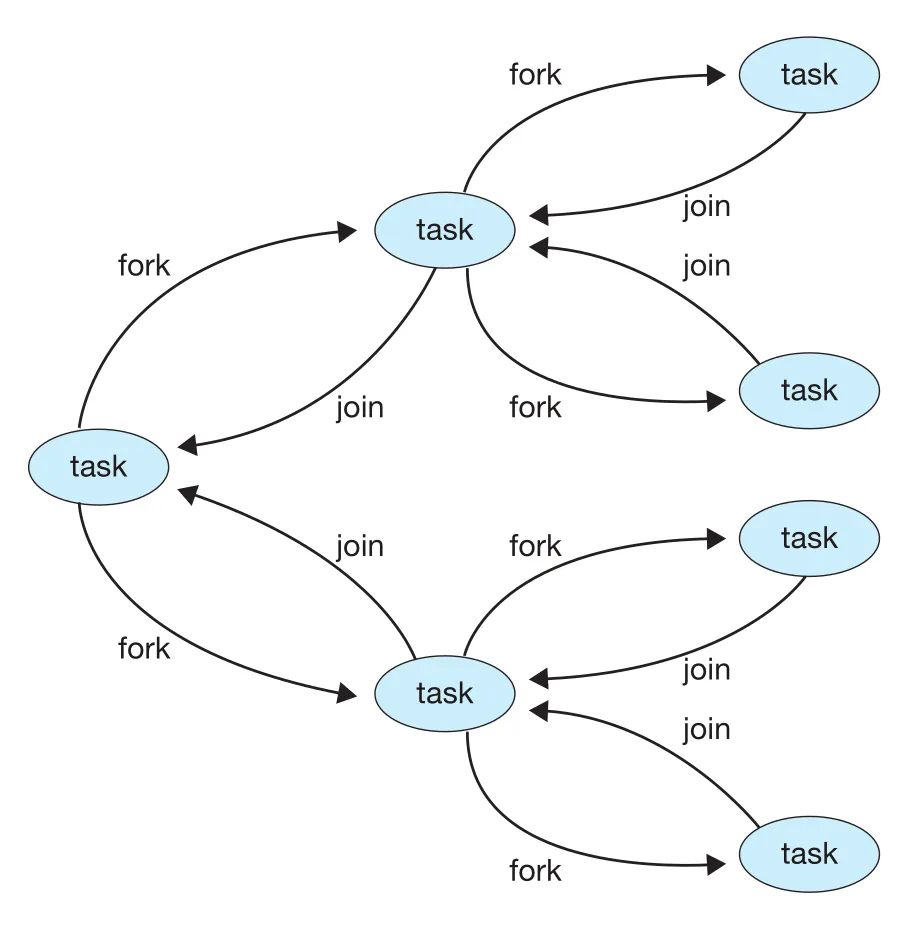
Figure 4.17 · PDF p. 239 · Java fork-join에서 recursive tasks가 fork/join되는 구조
Java fork-join example은 integer array sum을 divide-and-conquer로 계산한다. ForkJoinPool에 initial task를 invoke()하면, library가 worker threads를 만들어 tasks를 실행하고 최종 sum을 돌려준다.

Figure 4.18 · PDF p. 240 · `RecursiveTask
SumTask의 핵심은 compute() method다. Subarray size가 THRESHOLD보다 작으면 직접 sum을 계산한다. 그렇지 않으면 middle point를 잡아 left/right tasks를 만들고 fork()한 뒤, join()으로 결과를 기다려 합친다.
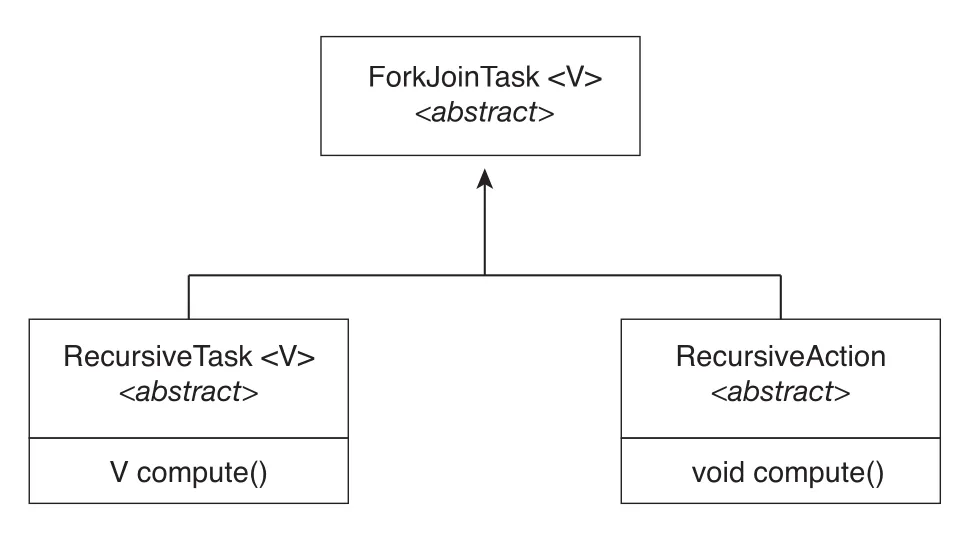
Figure 4.19 · PDF p. 241 · `ForkJoinTask`, `RecursiveTask`, `RecursiveAction`의 관계
| Class | 역할 |
|---|---|
ForkJoinTask<V> | Java fork-join의 abstract base class |
RecursiveTask<V> | result를 return하는 recursive task. V compute() |
RecursiveAction | result를 return하지 않는 recursive action. void compute() |
실무적으로 중요한 문제는 “small enough” threshold를 정하는 것이다. 너무 작게 나누면 task management overhead가 커지고, 너무 크게 잡으면 parallelism이 줄어든다. 원문 예제는 THRESHOLD = 1000을 arbitrary하게 둔다. 실제 값은 timing trials로 조정해야 한다.
Java fork-join의 흥미로운 점은 work stealing algorithm이다. ForkJoinPool의 각 worker thread는 자신이 fork한 tasks queue를 가진다. 어떤 worker의 queue가 비면 다른 worker의 queue에서 task를 훔쳐 실행할 수 있다. 이 방식은 tasks가 매우 많고 worker threads가 적을 때 load balancing을 돕는다.
OpenMP
OpenMP는 C, C++, FORTRAN programs를 위한 compiler directives와 API set이다. Shared-memory environment에서 parallel programming을 지원한다. Developer는 parallel하게 실행될 수 있는 code block에 compiler directive를 삽입하고, OpenMP runtime library가 해당 region을 parallel하게 실행한다.
가장 기본 directive는 다음과 같다.
#pragma omp parallel
{
printf("I am a parallel region.");
}OpenMP가 #pragma omp parallel을 만나면 system의 processing cores 수만큼 threads를 만든다. Dual-core면 2 threads, quad-core면 4 threads가 만들어지고, 모든 threads가 parallel region을 동시에 실행한다.
Loop parallelization도 지원한다.
#pragma omp parallel for
for (i = 0; i < N; i++) {
c[i] = a[i] + b[i];
}이 경우 OpenMP는 loop iteration work를 생성한 threads 사이에 나눠 실행한다. Developer는 thread creation을 직접 작성하지 않고, parallelizable region만 표시한다. OpenMP는 thread 수를 수동으로 설정하거나, data가 threads 사이에서 shared인지 private인지 지정하는 기능도 제공한다.
Grand Central Dispatch (GCD)
Grand Central Dispatch (GCD)는 Apple의 macOS/iOS를 위한 run-time library, API, language extensions의 조합이다. OpenMP와 마찬가지로 developer가 parallel하게 실행할 code section, 즉 tasks를 식별하면 GCD가 threading detail을 관리한다.
GCD는 tasks를 dispatch queue에 넣고, queue에서 task를 꺼낼 때 GCD가 관리하는 thread pool의 available thread에 배정한다. Dispatch queue는 두 종류다.
| Dispatch queue | 의미 | 용도 |
|---|---|---|
serial queue | tasks를 FIFO로 꺼내며, 한 task가 끝나야 다음 task를 꺼냄 | sequential execution 보장 |
concurrent queue | FIFO order를 유지하되 여러 tasks를 동시에 꺼낼 수 있음 | multiple tasks parallel execution |
각 process는 자기 main queue라는 serial queue를 가지며, developer는 additional serial queues를 만들 수 있다. Serial queues는 private dispatch queues라고도 하며, 여러 tasks를 반드시 순서대로 실행해야 할 때 유용하다.
Concurrent queues는 global dispatch queues로 제공되며 quality-of-service class로 나뉜다.
| QoS class | 의미 | 예시 |
|---|---|---|
QOS_CLASS_USER_INTERACTIVE | 사용자와 직접 상호작용하며 즉시 끝나야 하는 짧은 task | UI, event handling |
QOS_CLASS_USER_INITIATED | 사용자가 시작했고 계속 진행하려면 완료가 필요한 task | file 또는 URL 열기 |
QOS_CLASS_UTILITY | 오래 걸리지만 즉시 결과가 필요하지 않은 task | data import |
QOS_CLASS_BACKGROUND | 사용자에게 보이지 않고 time-sensitive하지 않은 task | mailbox indexing, backup |
GCD task는 C/C++/Objective-C에서는 block, Swift에서는 closure로 표현된다. 예를 들어 Swift에서는 global concurrent queue를 얻고 dispatch_async()로 closure를 submit한다. 내부적으로 GCD thread pool은 POSIX threads로 구성되며, GCD는 application demand와 system capacity에 따라 thread pool 크기를 늘리거나 줄인다.
Intel Thread Building Blocks (TBB)
Intel Thread Building Blocks (TBB)는 C++ parallel applications를 위한 template library다. Special compiler나 language support 없이 library로 제공된다. Developer는 parallel하게 실행 가능한 tasks를 지정하고, TBB task scheduler가 tasks를 underlying threads에 mapping한다.
TBB scheduler는 load balancing을 제공하고 cache aware하다. 즉 cache memory에 data가 있을 가능성이 높은 task를 우선해 더 빠르게 실행될 수 있게 한다. TBB는 parallel loop templates, atomic operations, mutual exclusion locking, thread-safe concurrent data structures(hash map, queue, vector 등)를 제공한다.
Serial loop가 다음과 같다고 하자.
for (int i = 0; i < n; i++) {
apply(v[i]);
}TBB에서는 parallel_for template로 표현할 수 있다.
parallel_for(size_t(0), n, [=](size_t i) { apply(v[i]); });TBB는 iteration space 0부터 n-1까지를 chunks로 나누고, 그 chunks에 대해 tasks를 만든 뒤, available threads에 배정한다. 이 방식의 장점은 developer가 physical core 수에 맞춰 직접 data partition을 작성하지 않아도 된다는 것이다. Hardware별 core 수가 달라도 algorithm을 다시 고치고 recompile할 필요를 줄인다.
TBB의 핵심 방향은 “developer는 parallel 가능한 operation을 표시하고, library가 division/load balancing/thread assignment를 맡는다”는 것이다. 이 점에서 Java fork-join과 유사하며, implicit threading의 대표 사례다.
4.6 Threading Issues
fork() and exec() System Calls
Chapter 3에서 fork()는 separate duplicate process를 만드는 system call로 설명되었다. 그러나 multithreaded program에서는 fork()의 semantics가 애매해진다. Process 안에 여러 threads가 있을 때 한 thread가 fork()를 호출하면 child process는 무엇을 duplicate해야 하는가?
가능성은 두 가지다.
fork() semantics | 의미 | 적합한 상황 |
|---|---|---|
| duplicate all threads | parent process의 모든 threads를 child에 복제 | child가 exec()를 바로 호출하지 않고 같은 multithreaded structure를 유지해야 할 때 |
| duplicate only calling thread | fork()를 호출한 thread만 child에 복제 | child가 곧바로 exec()를 호출해 process image를 교체할 때 |
exec()는 Chapter 3과 동일하게 동작한다. 어떤 thread가 exec()를 호출하면 exec() parameter로 지정된 program이 entire process를 replace한다. 즉 기존 process 안의 모든 threads가 사라지고 새 program image가 들어온다.
따라서 fork() 직후 바로 exec()할 예정이면 모든 threads를 복제할 필요가 없다. Calling thread만 복제하면 충분하다. 반대로 child process가 exec() 없이 계속 실행되어야 한다면 모든 threads를 복제하는 semantics가 필요할 수 있다.
Signal Handling
UNIX에서 signal은 특정 event가 발생했음을 process에 알리는 mechanism이다. Signal은 source와 reason에 따라 synchronous 또는 asynchronous일 수 있다.
Signal 처리 흐름은 항상 세 단계다.
- Event occurrence가 signal을 generate한다.
- Signal이 process에 deliver된다.
- Delivered signal이 handle된다.
| Signal type | 발생 원인 | delivery 대상 |
|---|---|---|
synchronous signal | running program 내부의 illegal memory access, division by zero 등 | 해당 operation을 수행한 process/thread |
asynchronous signal | process 외부 event, <control><C>, timer expiration 등 | 보통 다른 process 또는 process 전체 |
Signal handler는 두 종류다.
| Handler | 의미 |
|---|---|
default signal handler | kernel이 signal마다 제공하는 기본 처리 |
user-defined signal handler | programmer가 default action을 override하는 handler |
어떤 signal은 ignore될 수 있고, illegal memory access처럼 program termination으로 처리되는 signal도 있다.
Single-threaded program에서는 signal이 process에 deliver되면 된다. 그러나 multithreaded process에서는 “어느 thread가 signal을 받을 것인가”가 문제가 된다. 가능한 정책은 다음과 같다.
- signal이 적용되는 thread에 deliver한다.
- process의 모든 threads에 deliver한다.
- process 안의 특정 threads에만 deliver한다.
- process의 모든 signals를 담당하는 specific thread를 둔다.
Synchronous signal은 signal을 유발한 thread에 deliver되어야 한다. 다른 thread가 division by zero를 처리할 이유가 없다. 반면 asynchronous signal은 더 애매하다. 예를 들어 <control><C>처럼 process termination을 의미하는 signal은 모든 threads에 보내는 것이 자연스럽다.
UNIX의 standard signal delivery function은 다음과 같다.
kill(pid_t pid, int signal)kill()은 특정 process id에 signal을 보낸다. Multithreaded UNIX에서는 각 thread가 어떤 signals를 accept/block할지 지정할 수 있다. Signal은 보통 blocking하지 않는 첫 thread에 deliver된다. POSIX Pthreads는 특정 thread에 signal을 보내는 API도 제공한다.
pthread_kill(pthread_t tid, int signal)Windows는 UNIX-style signal을 명시적으로 제공하지 않지만 asynchronous procedure calls (APCs)로 유사한 기능을 제공한다. APC는 특정 event notification을 받았을 때 user thread가 지정한 function을 호출하게 한다. 중요한 차이는 UNIX signal은 process-level delivery 문제를 다뤄야 하지만, APC는 particular thread에 deliver되므로 multithreaded 환경에서 더 직접적이라는 점이다.
Thread Cancellation
thread cancellation은 thread가 work를 완료하기 전에 종료시키는 것이다. 취소 대상 thread는 target thread라고 한다. 예를 들어 여러 threads가 database를 동시에 search하다가 하나가 result를 찾으면 나머지를 cancel할 수 있다. Browser에서 user가 stop button을 누르면 image loading threads를 cancel하는 것도 같은 예다.
Cancellation 방식은 두 가지다.
| 방식 | 의미 | 위험/장점 |
|---|---|---|
asynchronous cancellation | 한 thread가 target thread를 즉시 terminate | 즉각적이지만 resource cleanup, shared data consistency가 위험 |
deferred cancellation | target thread가 주기적으로 cancel 여부를 확인하고 안전한 지점에서 스스로 종료 | orderly termination 가능 |
Cancellation이 어려운 이유는 target thread가 resource를 할당받았거나 shared data를 update하는 중일 수 있기 때문이다. Asynchronous cancellation은 OS가 일부 system resources는 회수해도 application-level resource나 system-wide resource를 모두 안전하게 정리하지 못할 수 있다. 그래서 일반적으로 deferred cancellation이 더 안전하다.
Pthreads에서 cancellation request는 pthread_cancel()로 보낸다.
pthread_t tid;
pthread_create(&tid, 0, worker, NULL);
...
pthread_cancel(tid);
pthread_join(tid, NULL);중요한 점은 pthread_cancel()이 target thread를 즉시 죽인다는 뜻이 아니라 cancellation request를 보낸다는 뜻이다. 실제 cancellation 여부와 시점은 target thread의 cancellation state/type에 달려 있다.
| Mode | State | Type |
|---|---|---|
| Off | Disabled | - |
| Deferred | Enabled | Deferred |
| Asynchronous | Enabled | Asynchronous |
Pthreads의 default cancellation type은 deferred cancellation이다. Cancellation은 thread가 cancellation point에 도달했을 때 발생한다. POSIX와 standard C library의 많은 blocking system calls가 cancellation point다. 예를 들어 read()에서 input을 기다리는 thread는 cancellation point에 있으므로 cancel될 수 있다.
Programmer가 명시적으로 cancellation point를 만들고 싶으면 pthread_testcancel()을 호출할 수 있다.
while (1) {
/* do some work for awhile */
pthread_testcancel();
}Pending cancellation request가 있으면 pthread_testcancel()은 return하지 않고 thread가 terminate된다. 없으면 return하여 thread가 계속 실행된다. Pthreads는 thread cancellation 시 cleanup handler를 호출해 acquired resources를 release할 수 있게 한다. 원문은 asynchronous cancellation을 Pthreads documentation이 권장하지 않는다고 설명한다.
Java thread cancellation은 deferred cancellation과 비슷하다. Target thread에 interrupt()를 호출하면 interruption status가 true로 설정된다.
worker.interrupt();Thread는 자기 interruption status를 확인하며 안전한 지점에서 종료할 수 있다.
while (!Thread.currentThread().isInterrupted()) {
...
}Thread-Local Storage (TLS)
Threads는 같은 process data를 공유한다. 이것이 multithreading의 장점이지만, 때로는 각 thread가 자기만의 data copy를 가져야 한다. 이를 thread-local storage (TLS)라고 한다.
예를 들어 transaction-processing system에서 각 transaction을 separate thread로 처리하고, 각 transaction에 unique identifier를 붙여야 한다면 thread마다 고유한 transaction ID가 필요하다. 이때 TLS를 사용한다.
TLS는 local variable과 다르다.
| 구분 | Visibility/Lifetime |
|---|---|
| local variable | single function invocation 동안만 visible |
thread-local storage (TLS) | thread별로 unique하며 function invocations를 가로질러 visible |
| static data | process-wide로 하나만 존재 |
TLS는 static data와 비슷하지만 thread마다 separate copy가 있다는 점이 다르다. Thread pool처럼 developer가 thread creation을 직접 control하지 못하는 implicit threading 환경에서도 thread별 state를 관리하려면 TLS가 필요할 수 있다.
지원 방식은 language/library마다 다르다.
| System | TLS support |
|---|---|
| Java | ThreadLocal<T> class, set()/get() |
| Pthreads | pthread_key_t |
| C# | [ThreadStatic] storage attribute |
| gcc | __thread storage class keyword |
예를 들어 gcc에서는 thread마다 고유한 identifier를 다음처럼 선언할 수 있다.
static __thread int threadID;Scheduler Activations
scheduler activations는 many-to-many 또는 two-level model에서 kernel과 user-level thread library가 협력하기 위한 mechanism이다. 이런 model에서는 kernel threads 수를 application 상황에 맞게 dynamic adjustment해야 성능이 좋아진다.
Many-to-many/two-level model을 구현하는 여러 system은 user threads와 kernel threads 사이에 intermediate data structure를 둔다. 이 structure가 lightweight process (LWP)다.
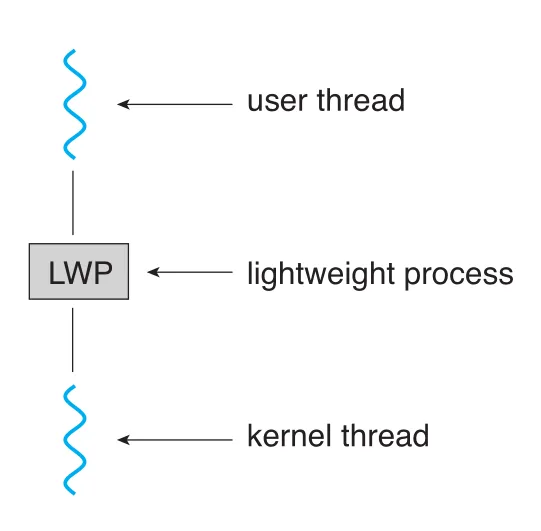
Figure 4.20 · PDF p. 250 · user thread와 kernel thread 사이의 virtual processor 역할을 하는 LWP
Thread library 입장에서 LWP는 user thread를 schedule할 수 있는 virtual processor처럼 보인다. 각 LWP는 kernel thread에 붙어 있고, 실제 physical processor에 schedule되는 것은 kernel thread다. Kernel thread가 I/O wait 등으로 block되면 LWP도 block되고, 그 LWP에 붙은 user-level thread도 block된다.
필요한 LWP 수는 application 성격에 따라 다르다.
- Single processor에서 CPU-bound application이면 한 번에 하나의 thread만 run 가능하므로 LWP 하나로 충분할 수 있다.
- I/O-intensive application은 concurrent blocking system calls 수만큼 LWPs가 필요할 수 있다.
- 예를 들어 simultaneous file-read requests가 5개라면, 모두 kernel에서 I/O completion을 기다릴 수 있으므로 5 LWPs가 필요하다. LWP가 4개뿐이면 5번째 request는 LWP가 돌아올 때까지 기다려야 한다.
Scheduler activation의 흐름은 다음과 같다.
- Kernel이 application에게 virtual processors, 즉 LWPs 집합을 제공한다.
- Application의 thread library가 available LWP 위에 user threads를 schedule한다.
- Kernel이 특정 event를 application에 알려야 할 때
upcall을 보낸다. - Thread library는
upcall handler로 upcall을 처리한다. - Upcall handler도 virtual processor 위에서 실행되어야 한다.
예를 들어 application thread가 block되려는 순간 kernel은 thread library에 upcall을 보내 어떤 thread가 block될지 알려준다. Kernel은 새 virtual processor를 application에 할당하고, application은 upcall handler를 실행해 blocking thread state를 저장한 뒤, 그 thread가 쓰던 virtual processor를 relinquish한다. 이후 upcall handler는 새 virtual processor에서 실행 가능한 다른 thread를 schedule한다.
나중에 blocking event가 끝나면 kernel은 다시 upcall로 previously blocked thread가 run 가능해졌음을 알린다. Thread library는 해당 thread를 eligible로 표시하고 available virtual processor에 적절한 thread를 schedule한다. 이 구조는 kernel scheduling과 user-level thread scheduling 사이의 coordination을 가능하게 한다.
4.7 Operating-System Examples
Windows Threads
Windows application은 separate process로 실행되고, 각 process는 one or more threads를 포함할 수 있다. Windows는 Section 4.3의 one-to-one mapping을 사용한다. 즉 user-level thread 하나가 associated kernel thread 하나에 mapping된다.
Windows thread의 일반 component는 다음과 같다.
thread ID: thread를 unique하게 식별register set: processor status 표현program counteruser stack: user mode에서 실행될 때 사용kernel stack: kernel mode에서 실행될 때 사용private storage area: run-time libraries와 dynamic link libraries(DLLs)가 사용하는 private area
Register set, stacks, private storage area를 thread의 context라고 한다. Windows thread의 주요 data structures는 ETHREAD, KTHREAD, TEB다.
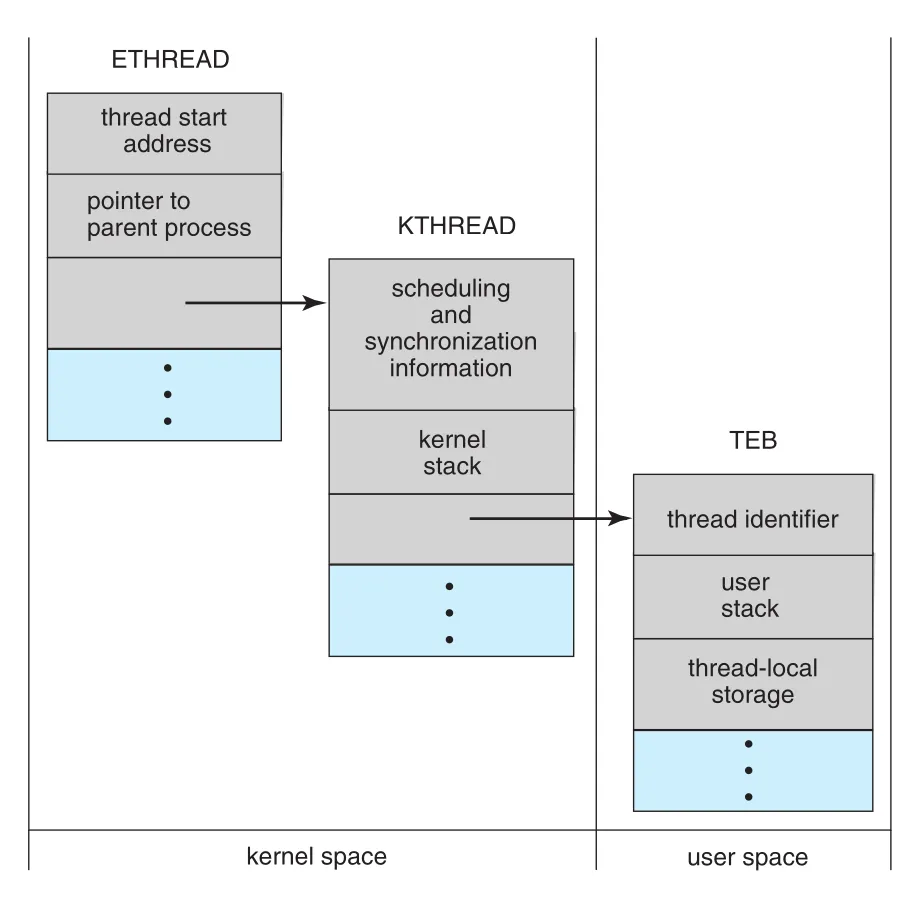
Figure 4.21 · PDF p. 252 · Windows thread의 ETHREAD, KTHREAD, TEB 구조와 kernel/user space 경계
| Structure | 위치 | 역할 |
|---|---|---|
ETHREAD | kernel space | executive thread block. parent process pointer와 thread start routine address 포함 |
KTHREAD | kernel space | kernel thread block. scheduling/synchronization information, kernel stack, TEB pointer 포함 |
TEB | user space | thread environment block. thread identifier, user stack, thread-local storage array 포함 |
ETHREAD와 KTHREAD는 entirely kernel space에 있으므로 kernel만 접근할 수 있다. TEB는 user mode에서 thread가 실행될 때 접근되는 user-space structure다. Figure 4.21은 Windows thread가 kernel scheduling 정보와 user-mode execution context를 분리해 관리한다는 점을 보여준다.
Linux Threads
Linux는 전통적인 process duplication을 위해 fork() system call을 제공하지만, thread creation에는 clone() system call을 사용한다. 중요한 특징은 Linux가 processes와 threads를 구분하지 않는다는 점이다. Linux kernel은 program 안의 flow of control을 process나 thread 대신 task라고 부른다.
clone()은 flags를 받아 parent와 child tasks 사이에 얼마나 많은 resource를 공유할지 결정한다.
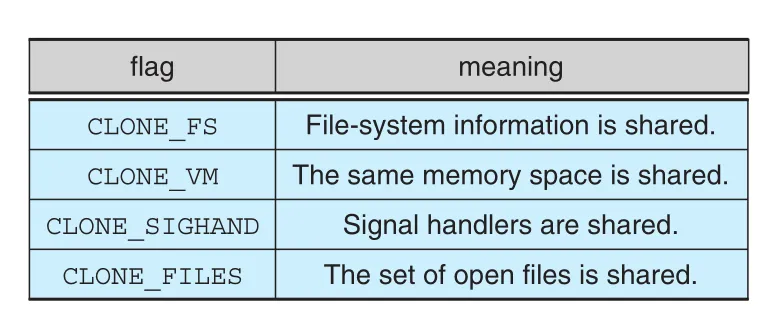
Figure 4.22 · PDF p. 253 · `clone()` 호출 시 sharing 수준을 정하는 주요 flags
| Flag | 의미 |
|---|---|
CLONE_FS | file-system information 공유. current working directory 등 |
CLONE_VM | 같은 memory space 공유 |
CLONE_SIGHAND | signal handlers 공유 |
CLONE_FILES | open files set 공유 |
예를 들어 clone()에 CLONE_FS, CLONE_VM, CLONE_SIGHAND, CLONE_FILES를 넘기면 parent와 child tasks가 file-system information, memory space, signal handlers, open files를 공유한다. 이는 이 장에서 설명한 thread creation과 같다. 반대로 flags를 하나도 설정하지 않으면 sharing이 일어나지 않아 Chapter 3의 fork()와 비슷한 기능이 된다.
Linux에서 이런 유연성이 가능한 이유는 task representation 때문이다. 각 task마다 unique kernel data structure인 struct task_struct가 존재한다. 이 structure는 open files, signal-handling information, virtual memory 같은 data를 직접 모두 저장하기보다, 해당 data structures를 가리키는 pointers를 포함한다.
| 호출 | Linux task 생성 방식 |
|---|---|
fork() | 새 task를 만들고 parent process의 associated data structures를 copy |
clone() | 새 task를 만들고 flags에 따라 parent task의 data structures를 share |
즉 Linux에서 process-like task와 thread-like task의 차이는 본질적으로 “무엇을 copy하고 무엇을 share하는가”의 차이다. 이 clone()의 sharing flag mechanism은 container creation으로도 확장된다. Container는 하나의 Linux kernel 아래 isolated Linux systems를 만드는 OS-level virtualization technique이며, 추가 clone() flags가 container isolation 구성에 쓰인다. Container 자체는 Chapter 18에서 더 다룬다.
연결 관계
| 이 장의 개념 | 이어지는 장/주제 |
|---|---|
thread, thread ID, PC, register set, stack | Chapter 5 CPU scheduling에서 thread scheduling 단위 이해 |
shared address space | Chapter 6 synchronization, race condition, critical section |
concurrency vs parallelism | multicore scheduling, performance analysis |
Amdahl's Law | parallel algorithm speedup, bottleneck analysis |
many-to-one, one-to-one, many-to-many | OS thread implementation, kernel scheduler와 runtime 협력 |
Pthreads, Windows threads, Java threads | 실제 system programming API |
thread pool, fork-join, OpenMP, GCD, TBB | high-level parallel programming framework |
thread cancellation, signal handling, TLS | robust multithreaded application design |
LWP, scheduler activations | user-level thread library와 kernel coordination |
Linux clone() | process/thread/container를 sharing level로 이해하는 Linux kernel model |
오해하기 쉬운 내용
- Thread는 process와 같은 것이 아니다. Thread는 register set, PC, stack을 따로 가지지만 code/data/files 같은 process resource를 공유한다.
- Multithreading은 항상 parallelism을 의미하지 않는다. Single core에서는 threads가 concurrent하게 interleaving될 뿐 simultaneous execution은 없다.
- Core 수를 늘리면 성능이 무조건 선형 증가하지 않는다.
Amdahl's Law때문에 serial portion이 speedup 상한을 제한한다. - Many-to-one model은 thread management가 빠를 수 있지만, blocking system call 하나가 process 전체를 block할 수 있고 multicore parallelism을 얻지 못한다.
- One-to-one model은 parallelism에 유리하지만 user thread마다 kernel thread가 필요하므로 thread 수가 너무 많으면 overhead가 커진다.
start()와run()은 Java에서 다르다.start()가 새 thread를 만들고,run()직접 호출은 현재 thread에서 method를 실행할 뿐이다.Runnable은 result를 return하지 못한다. Result가 필요한 task에는Callable과Future가 필요하다.- Thread pool은 단순히 thread를 모아 둔 자료구조가 아니라, thread creation overhead와 resource exhaustion을 동시에 줄이는 scheduling policy다.
- Deferred cancellation은 “언젠가 자동으로 안전하게 죽는다”가 아니다. Target thread가 cancellation point 또는 interrupt check 같은 안전 지점에 도달해야 한다.
- TLS는 local variable이 아니다. Local variable은 function invocation 단위지만,
thread-local storage (TLS)는 thread마다 고유하고 여러 function calls를 가로질러 유지될 수 있다. - Linux는 kernel 내부에서 process/thread를 엄격히 구분하지 않는다.
task_struct와clone()sharing flags로 process-like 또는 thread-like behavior를 만든다.
면접 질문
- Thread가 가지는 독립 상태와 같은 process의 threads가 공유하는 resource를 구분해 설명하라.
- Multithreaded web server가 process-per-request server보다 효율적인 이유는 무엇인가?
- Multithreaded programming의 네 가지 benefit인 responsiveness, resource sharing, economy, scalability를 예시와 함께 설명하라.
concurrency와parallelism의 차이를 single-core와 multicore 관점에서 설명하라.Amdahl's Law가 multicore speedup에 대해 말하는 핵심 한계는 무엇인가?data parallelism과task parallelism을 array summation 예시로 비교하라.many-to-one,one-to-one,many-to-manythread model의 장단점을 비교하라.- 왜 현대 Windows와 Linux는 one-to-one model을 주로 사용하는가?
asynchronous threading과synchronous threading의 차이를 server와 summation 예제로 설명하라.- Pthreads에서
pthread_create(),pthread_join(),pthread_exit()의 역할을 설명하라. - Windows thread API에서
CreateThread()와WaitForSingleObject()는 Pthreads의 어떤 기능에 대응되는가? - Java에서
Thread.start()와run()직접 호출의 차이는 무엇인가? Callable,Future,ExecutorService가Runnable/Thread직접 생성 방식보다 제공하는 장점은 무엇인가?- Thread pool이 request마다 thread를 새로 만드는 방식보다 나은 이유는 무엇인가?
- Java fork-join framework에서
RecursiveTask,fork(),join(),work stealing의 역할을 설명하라. - OpenMP의
#pragma omp parallel for가 programmer에게 숨겨 주는 thread 관리 detail은 무엇인가? - GCD의 serial queue와 concurrent queue, 그리고 QoS class가 해결하려는 문제는 무엇인가?
- Multithreaded program에서
fork()와exec()semantics가 왜 단순하지 않은가? - Multithreaded process에서 signal을 어느 thread에 deliver할지 결정하는 기준은 무엇인가?
- Asynchronous cancellation보다 deferred cancellation이 선호되는 이유는 무엇인가?
thread-local storage (TLS)가 필요한 상황을 예로 들어 설명하라.lightweight process (LWP)와scheduler activation이 many-to-many model에서 필요한 이유는 무엇인가?- Windows thread의
ETHREAD,KTHREAD,TEB는 각각 어디에 있으며 무엇을 담당하는가? - Linux
clone()flags가 process-like task와 thread-like task를 어떻게 구분하게 만드는가?