개요
Chapter 3의 transport layer는 process-to-process communication을 제공했지만, 그 아래에서 host-to-host communication이 어떻게 구현되는지는 알 필요가 없었다. Chapter 4와 Chapter 5는 바로 이 network layer를 다룬다. network layer는 application/transport layer와 달리 모든 host와 router 안에 구현되어 있고, datagram이 source host에서 destination host까지 router들을 거쳐 이동하게 만든다.
이 책은 network layer를 두 부분으로 나눈다. Chapter 4는 data plane, 즉 router 안에서 arriving datagram을 어떤 output link로 보낼지 결정하고 실제로 forwarding하는 per-router 기능을 다룬다. Chapter 5는 control plane, 즉 end-to-end route를 계산하고 forwarding table을 채우는 network-wide logic을 다룬다.
Chapter 4의 흐름은 다섯 축이다. 첫째, forwarding/routing과 data plane/control plane의 분리. 둘째, router 내부 구조와 switching/queueing/scheduling. 셋째, traditional IP forwarding을 가능하게 하는 IPv4 datagram, addressing, DHCP, NAT, IPv6. 넷째, destination address만 보지 않는 generalized forwarding과 SDN/OpenFlow의 match/action model. 다섯째, forwarding 외 기능을 수행하는 middleboxes다.
핵심 개념
4.1 Overview of Network Layer
network layer는 sender host의 transport-layer segment를 network-layer datagram으로 encapsulation하고, 여러 routers를 통과시킨 뒤, destination host에서 다시 segment를 꺼내 transport layer로 올린다. router는 application layer나 transport layer를 실행하지 않고, truncated protocol stack처럼 network/link/physical layer 중심으로 datagram을 forwarding한다.
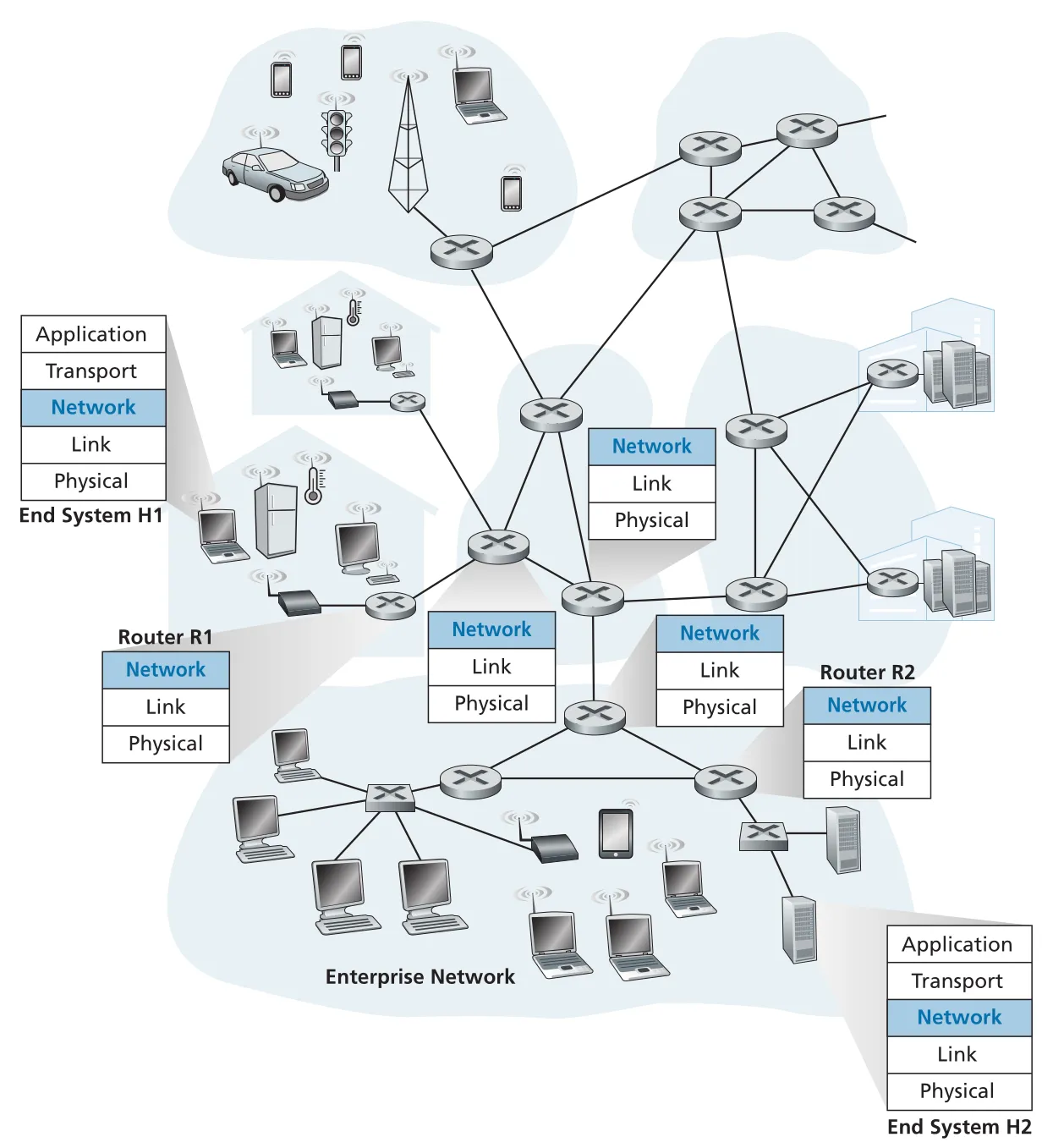 Figure 4.1 · PDF p. 316 · network layer가 hosts와 routers에 걸쳐 datagram forwarding을 담당하는 위치
Figure 4.1 · PDF p. 316 · network layer가 hosts와 routers에 걸쳐 datagram forwarding을 담당하는 위치
4.1.1 Forwarding and Routing: The Data and Control Planes
network layer의 역할은 “packet을 sending host에서 receiving host로 이동시키는 것”이지만, 이를 위해 두 기능을 구분해야 한다.
| 용어 | 범위 | 시간 규모 | 보통 구현 위치 | 의미 |
|---|---|---|---|---|
forwarding | router-local | nanoseconds 수준 | hardware/data plane | input link로 들어온 packet을 적절한 output link로 옮기는 동작 |
routing | network-wide | seconds 수준 | software/control plane | source에서 destination까지 packet이 따라갈 path/route를 계산하는 동작 |
forwarding은 자동차가 하나의 interchange에 들어와 어떤 출구로 나갈지 결정하는 것에 가깝다. routing은 Pennsylvania에서 Florida까지 전체 여행 경로를 계획하는 것에 가깝다. 이 둘을 섞어 말하면 network layer 구조가 흐려진다. forwarding은 local action이고, routing은 전체 path를 결정하는 global logic이다.
forwarding의 핵심 자료구조는 forwarding table이다. router는 arriving packet header의 하나 이상의 field 값을 보고 forwarding table을 index한다. table entry는 이 packet을 어떤 output link interface로 보낼지를 알려준다. traditional IP forwarding에서는 주로 destination IP address를 기준으로 table lookup을 하지만, Section 4.4의 generalized forwarding에서는 여러 header fields를 match해 block, duplicate, rewrite 같은 action도 수행할 수 있다.
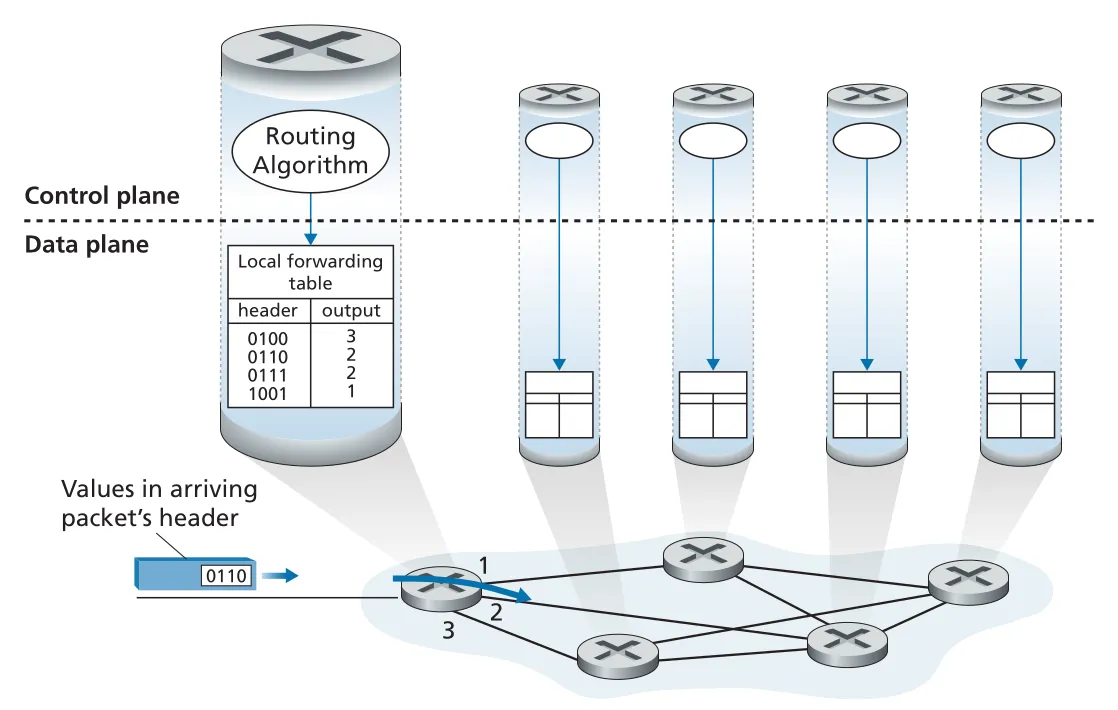 Figure 4.2 · PDF p. 318 · traditional approach에서 각 router의 routing algorithm이 local forwarding table 값을 계산한다
Figure 4.2 · PDF p. 318 · traditional approach에서 각 router의 routing algorithm이 local forwarding table 값을 계산한다
traditional control plane에서는 각 router 안에 routing component가 있고, routers끼리 routing protocol messages를 교환해 forwarding table을 계산한다. 이 방식에서는 forwarding과 routing이 같은 physical router 안에 들어 있다. 사람이 모든 router에 직접 forwarding table을 설정할 수도 이론상 가능하지만, topology 변화에 느리고 오류가 많기 때문에 실제 networks는 routing algorithms/protocols를 사용한다.
SDN (Software-Defined Networking) approach에서는 data plane과 control plane을 더 명시적으로 분리한다. router는 forwarding만 수행하고, 별도의 remote controller가 forwarding table을 계산해 routers에 내려준다. router와 controller는 forwarding table과 routing information을 담은 messages를 교환한다. 여기서 network가 software-defined라고 불리는 이유는 forwarding behavior를 결정하는 controller logic이 software로 구현되고, 점점 더 open implementation 형태로 발전했기 때문이다.
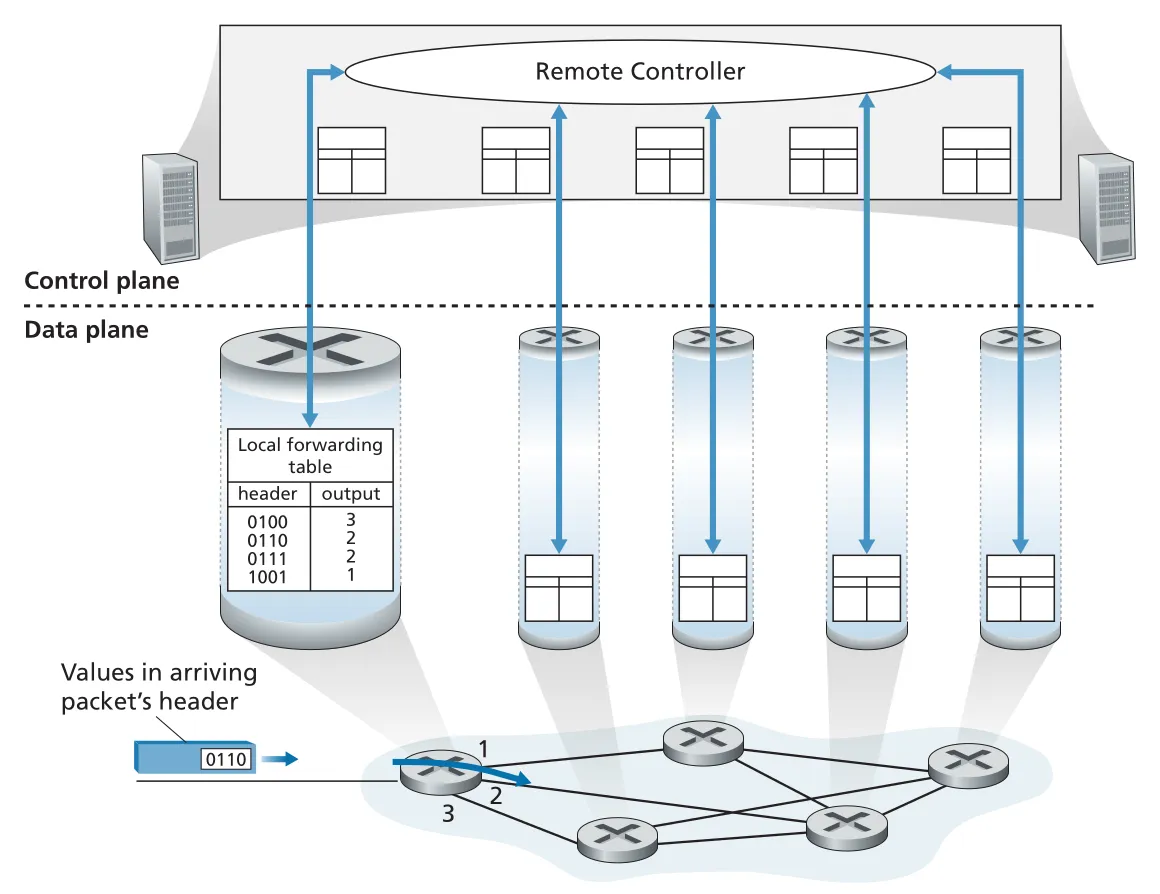 Figure 4.3 · PDF p. 319 · SDN approach에서 remote controller가 forwarding table을 계산하고 routers에 배포한다
Figure 4.3 · PDF p. 319 · SDN approach에서 remote controller가 forwarding table을 계산하고 routers에 배포한다
4.1.2 Network Service Model
network service model은 sending host와 receiving host 사이에서 packet delivery가 어떤 특성을 갖는지 정의한다. transport layer 입장에서 network layer에 기대할 수 있는 질문은 다음과 같다.
| 가능한 service | 의미 |
|---|---|
guaranteed delivery | 보낸 packet이 destination host에 eventually 도착함을 보장 |
guaranteed delivery with bounded delay | packet delivery뿐 아니라 특정 host-to-host delay bound 안의 도착을 보장 |
in-order packet delivery | packets가 보낸 순서대로 destination에 도착함을 보장 |
guaranteed minimal bandwidth | source-destination 사이에 지정된 bit rate의 virtual link처럼 동작 |
security | datagram encryption/decryption으로 transport-layer segment confidentiality 제공 |
Internet network layer의 service model은 best-effort service다. best-effort는 delivery, order, delay, minimal bandwidth를 보장하지 않는다. 이름만 보면 “거의 no service”처럼 보이지만, 실제 Internet은 adequate bandwidth provisioning과 DASH 같은 bandwidth-adaptive application-level protocols를 결합해 streaming, VoIP, conferencing까지 넓은 applications를 충분히 지원해 왔다. 중요한 교훈은 network layer가 단순한 service model을 제공하더라도, upper layer와 application design이 이를 보완할 수 있다는 점이다.
4.2 What’s Inside a Router?
router의 forwarding function은 incoming link에서 packet을 받아 appropriate outgoing link로 넘기는 실제 data-plane 동작이다. high-level router architecture는 네 component로 나뉜다.
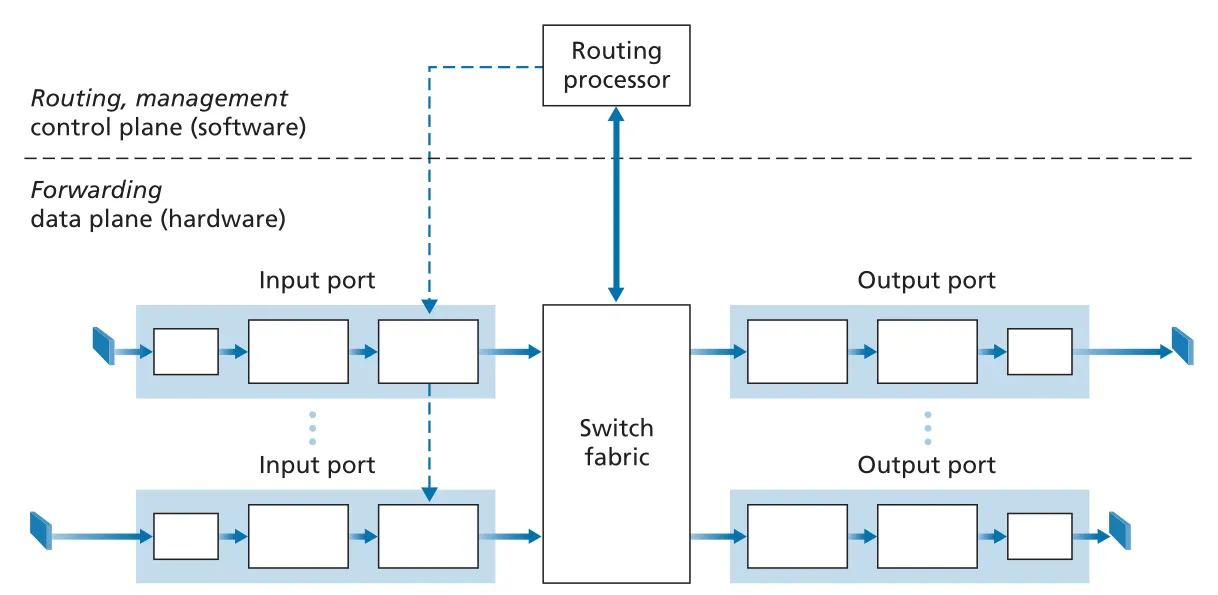 Figure 4.4 · PDF p. 322 · input ports, switching fabric, output ports, routing processor로 이루어진 router architecture
Figure 4.4 · PDF p. 322 · input ports, switching fabric, output ports, routing processor로 이루어진 router architecture
| Router component | 역할 |
|---|---|
input ports | physical/link-layer termination, forwarding table lookup, switching fabric으로 packet 전달 |
switching fabric | input port와 output port를 router 내부에서 연결하는 “network inside a router” |
output ports | switching fabric에서 받은 packets를 buffering하고 outgoing link로 transmission |
routing processor | traditional router에서는 routing protocol 실행과 table 계산, SDN router에서는 remote controller와 통신 및 management 수행 |
여기서 router의 port는 Chapter 2-3의 application socket port number가 아니라 physical input/output interface를 뜻한다. input/output ports와 switching fabric은 line rate로 packet을 처리해야 하므로 거의 항상 hardware로 구현된다. 예를 들어 100 Gbps link에서 64-byte IP datagram이 들어오면 다음 datagram까지 약 5.12 ns밖에 없으므로 software-only processing으로는 감당하기 어렵다.
data plane은 nanosecond time scale에서 동작하지만, routing protocols 실행, link up/down 대응, SDN controller와의 통신, management 같은 control functions는 millisecond 또는 second time scale에서 동작한다. 그래서 control plane 기능은 보통 routing processor 위의 software로 구현된다.
4.2.1 Input Port Processing and Destination-Based Forwarding
input port는 physical/link-layer processing뿐 아니라 lookup과 forwarding decision을 수행한다. forwarding table은 traditional router에서는 routing processor가 routing protocol로 계산하고, SDN router에서는 remote controller가 계산해 보낸다. 중요한 구현 포인트는 forwarding table이 routing processor에서 input line cards로 복사되어 각 input port가 local lookup을 수행한다는 점이다. 매 packet마다 centralized routing processor를 호출하면 line-rate forwarding이 불가능해지므로, forwarding decision은 input port 가까이에서 처리한다.
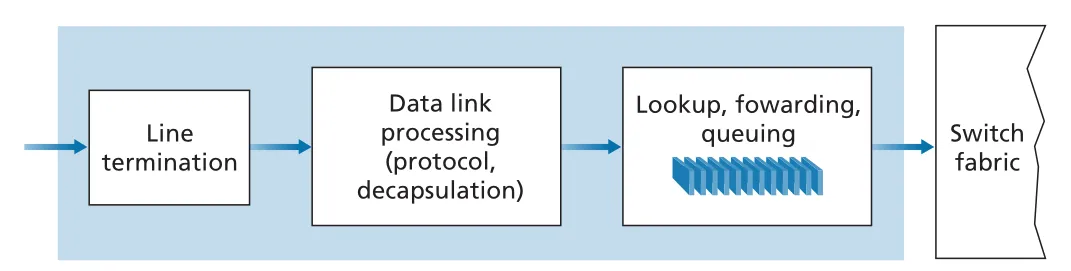 Figure 4.5 · PDF p. 325 · input port가 line termination, link-layer processing, lookup/forwarding/queueing을 수행하는 구조
Figure 4.5 · PDF p. 325 · input port가 line termination, link-layer processing, lookup/forwarding/queueing을 수행하는 구조
destination-based forwarding의 naive한 방법은 32-bit IP address마다 forwarding table entry를 두는 것이다. 하지만 가능한 IPv4 address가 2^32개이므로 불가능하다. 대신 router는 address range를 prefix로 표현하고, destination address와 table entry의 prefix를 비교한다.
예를 들어 forwarding table이 다음과 같다고 하자.
| Prefix | Link interface |
|---|---|
11001000 00010111 00010 | 0 |
11001000 00010111 00011000 | 1 |
11001000 00010111 00011 | 2 |
| otherwise | 3 |
destination address가 여러 prefix와 동시에 match될 수 있다. 이때 router는 longest prefix matching rule을 사용한다. 즉 가장 긴 matching prefix를 선택하고, 그 entry의 output link interface로 packet을 보낸다. 이 규칙은 Section 4.3의 hierarchical addressing과 route aggregation에서 왜 필요한지 다시 드러난다. 더 구체적인 route가 있으면 넓은 aggregate route보다 우선되어야 하기 때문이다.
line-rate lookup은 단순 linear search로 처리하기 어렵다. router는 fast lookup algorithms, on-chip DRAM/SRAM, TCAM (Ternary Content Addressable Memory) 같은 hardware를 사용한다. TCAM은 IP address를 넣으면 matching entry를 거의 constant time으로 돌려주는 memory 구조라 high-speed forwarding에 유리하다.
lookup 뒤에도 input port는 여러 작업을 수행한다.
| Input-port 작업 | 의미 |
|---|---|
| physical/link-layer processing | incoming link termination, frame decapsulation |
| forwarding table lookup | destination address 또는 header fields 기반 output port 결정 |
| header checks/update | IP version, checksum, TTL (time-to-live) 확인 및 일부 field rewrite |
| management counters | received datagram 수 같은 management statistics update |
| input queueing | switching fabric이 바쁘면 packet을 input port에서 대기 |
input port의 match와 action은 generalized forwarding의 기본형이다. IP router에서는 destination IP address를 match하고 output port로 send하는 action을 수행한다. link-layer switch는 link-layer destination address를 match하고, firewall은 source/destination IP와 port 조합을 match해 drop할 수 있으며, NAT는 transport-layer port를 match해 header field를 rewrite할 수 있다. 이 match plus action abstraction이 Section 4.4의 OpenFlow/SDN forwarding model의 중심이다.
4.2.2 Switching
switching fabric은 input port에서 output port로 packet을 실제로 이동시키는 router 내부의 핵심이다. 책은 세 가지 switching technique을 비교한다.
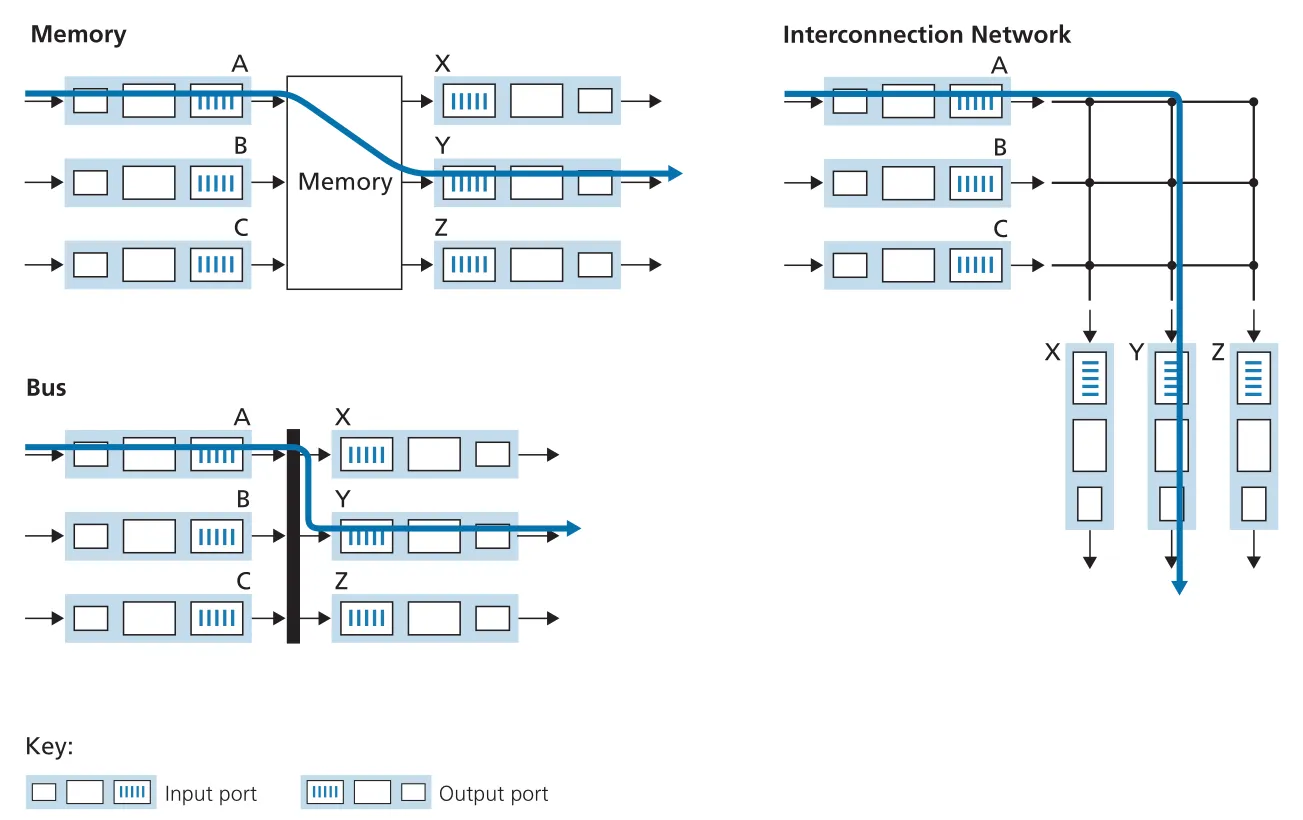 Figure 4.6 · PDF p. 328 · memory, bus, interconnection network를 이용한 세 가지 switching 방식
Figure 4.6 · PDF p. 328 · memory, bus, interconnection network를 이용한 세 가지 switching 방식
| 방식 | 동작 | 병목과 trade-off |
|---|---|---|
switching via memory | input packet을 processor memory로 copy하고, lookup 후 output port buffer로 copy | memory read/write bandwidth가 throughput을 제한한다. 한 번에 하나의 memory operation만 가능하면 total forwarding throughput은 memory bandwidth의 절반 이하가 된다. |
switching via bus | input port가 internal label을 붙여 shared bus에 packet을 올리고, matching output port만 packet을 keep | shared bus를 한 번에 하나의 packet만 사용할 수 있어 bus speed가 router switching speed를 제한한다. small LAN/enterprise routers에는 충분할 수 있다. |
switching via interconnection network | crossbar 또는 multistage fabric으로 여러 input-output pairs를 병렬 연결 | 서로 다른 output ports로 가는 packets는 병렬 forwarding 가능하다. 하지만 두 input packets가 같은 output port를 원하면 하나는 input에서 기다려야 한다. |
crossbar switch는 N input ports와 N output ports를 2N buses로 연결하고, crosspoint를 열고 닫아 input-output pair를 만든다. A-to-Y와 B-to-X처럼 output이 다르면 동시에 forwarding할 수 있으므로 memory/bus 방식보다 parallelism이 좋다. 단, 같은 output port로 향하는 packets 사이의 contention은 피할 수 없다. 더 큰 routers는 multistage interconnection network나 multiple switching fabrics를 병렬로 사용하고, packet을 chunks로 나누어 여러 fabrics에 분산시킨 뒤 output에서 reassemble하기도 한다.
4.2.3 Output Port Processing
output port는 switching fabric에서 받은 packets를 output memory에 저장하고, outgoing link로 전송한다. 여기에는 packet scheduling, de-queueing, link-layer encapsulation, physical-layer transmission이 포함된다.
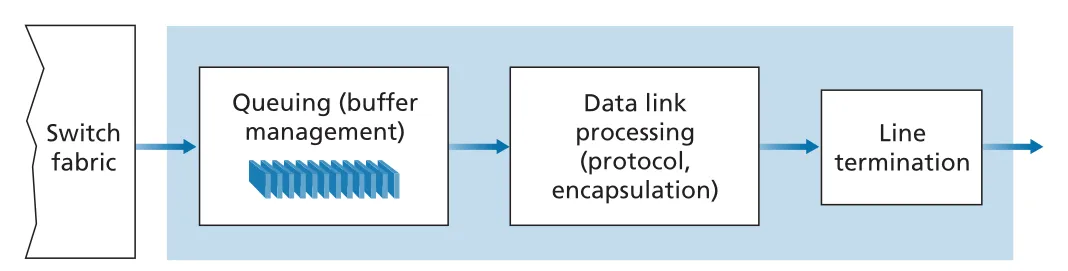 Figure 4.7 · PDF p. 330 · output port가 queued packets를 선택해 link-layer/physical-layer transmission으로 내보내는 구조
Figure 4.7 · PDF p. 330 · output port가 queued packets를 선택해 link-layer/physical-layer transmission으로 내보내는 구조
4.2.4 Where Does Queuing Occur?
router 안의 queue는 input port와 output port 둘 다에서 생길 수 있다. queue가 커지면 router memory가 고갈되고, 새로 도착한 packet을 저장할 공간이 없어져 packet loss가 발생한다. Chapter 3에서 “packet이 network 안에서 lost된다” 또는 “router에서 dropped된다”고 했던 실제 위치가 바로 이 input/output queues다.
queue 발생 위치는 traffic load, switching fabric speed, line speed의 상대 관계에 따라 달라진다. input/output line speed가 모두 Rline packets/sec이고 N input ports, N output ports가 있다고 하자. switching fabric transfer rate Rswitch가 이면, worst case로 N input ports의 packets가 모두 같은 output port를 향해도 한 packet time 안에 N packets를 fabric을 통해 output port로 밀어 넣을 수 있으므로 input queueing은 거의 생기지 않는다. 그러나 output port는 여전히 한 packet time에 하나만 outgoing link로 보낼 수 있으므로 output queueing은 생길 수 있다.
Input Queueing과 HOL blocking. switching fabric이 충분히 빠르지 않거나, crossbar에서 여러 input packets가 같은 output port를 원하면 input port에서 packet이 기다린다. 이때 HOL blocking (head-of-the-line blocking)이 생길 수 있다. input queue의 맨 앞 packet이 busy output port를 기다리면, 그 뒤에 있는 packet은 자신의 output port가 free여도 앞 packet 때문에 fabric을 통과하지 못한다.
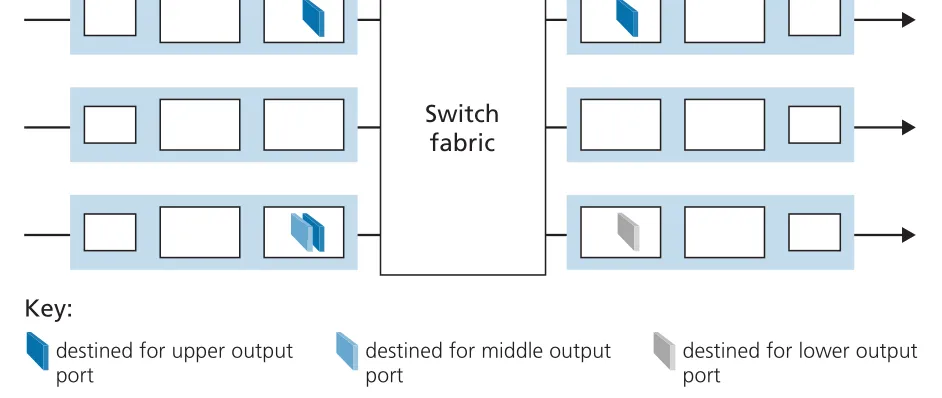 Figure 4.8 · PDF p. 332 · input queue 맨 앞 packet이 막혀 뒤 packet까지 기다리는 HOL blocking
Figure 4.8 · PDF p. 332 · input queue 맨 앞 packet이 막혀 뒤 packet까지 기다리는 HOL blocking
HOL blocking은 input-queued switch의 throughput을 크게 낮출 수 있다. 원문은 특정 가정하에서 input link arrival rate가 capacity의 약 58%에 도달해도 input queue가 unbounded하게 커질 수 있음을 언급한다. 요점은 “fabric이 parallelism을 제공해도 queue head의 output contention이 뒤 packet까지 묶는다”는 것이다.
Output Queueing. switching fabric이 만큼 빠르더라도, N input ports에서 같은 output port로 packets가 몰리면 output queue가 생긴다. output link는 한 packet time에 하나만 전송할 수 있는데, fabric은 그 사이 여러 packets를 output port로 가져올 수 있기 때문이다.
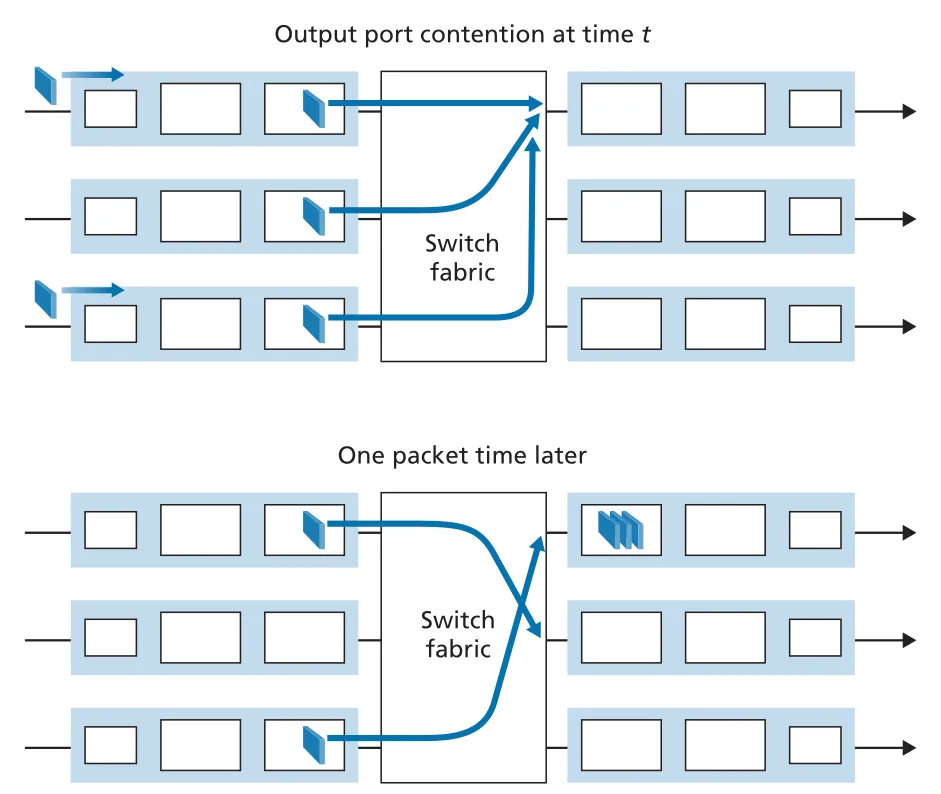 Figure 4.9 · PDF p. 333 · 여러 input ports의 packets가 하나의 output port로 몰릴 때 output queue가 형성되는 흐름
Figure 4.9 · PDF p. 333 · 여러 input ports의 packets가 하나의 output port로 몰릴 때 output queue가 형성되는 흐름
output buffer가 부족하면 router는 packet을 drop하거나 이미 queued된 packet을 제거해 새 packet을 받을 수 있다. 가장 단순한 정책은 buffer가 꽉 찼을 때 arriving packet을 버리는 drop-tail이다. 반대로 buffer가 full이 되기 전에 packet을 drop하거나 mark해 sender에게 congestion signal을 주는 방식도 있다. 이런 proactive dropping/marking 정책을 AQM (Active Queue Management)라고 하며, RED (Random Early Detection), PIE, CoDel 같은 알고리즘이 여기에 속한다. ECN bits를 mark하는 방식은 Chapter 3의 ECN congestion indication과 직접 연결된다.
How Much Buffering Is Enough? buffer는 short-term burst를 흡수해 loss를 줄이지만, 너무 크면 queueing delay가 커진다. 오래된 rule of thumb은 buffer size B를 average RTT와 link capacity C의 곱으로 잡는 것이었다.
예를 들어 RTT가 250 ms이고 link capacity가 10 Gbps이면 약 2.5 Gbits buffer가 필요하다는 계산이 나온다. 하지만 많은 independent TCP flows N이 한 link를 공유하면 필요한 buffering은 더 작아질 수 있다.
중요한 trade-off는 buffer가 loss를 줄이는 동시에 delay를 늘린다는 점이다. interactive gaming, teleconferencing처럼 delay-sensitive application에서는 수십 ms도 중요하다. 더 큰 buffer는 packet loss를 줄일 수 있지만 end-to-end delay와 RTT를 늘려 TCP sender의 congestion response를 느리게 만들 수 있다.
bufferbloat는 buffer가 너무 커서 persistent queueing delay가 생기는 현상이다. 예를 들어 home router outgoing link에 queue가 계속 남아 있으면 bottleneck link는 full로 사용되지만, queueing delay가 상시 붙는다. ACK clocking 때문에 하나가 빠질 때마다 새 packet이 들어와 queue length가 유지될 수도 있다. 이 경우 throughput은 괜찮아 보여도 interactive user는 큰 delay를 경험한다.
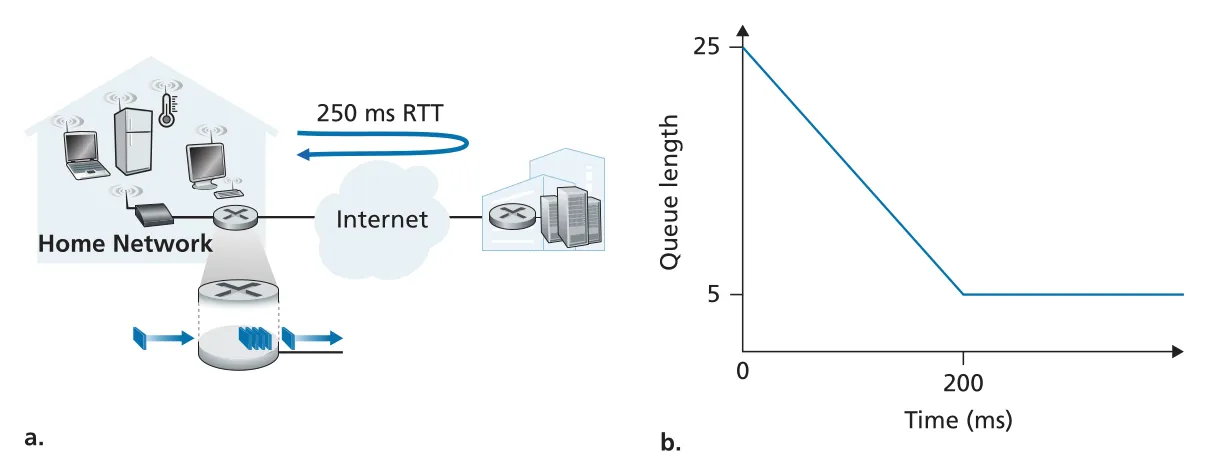 Figure 4.10 · PDF p. 335 · ACK clocking과 큰 buffer가 persistent queue를 만들어 bufferbloat delay를 유발하는 예
Figure 4.10 · PDF p. 335 · ACK clocking과 큰 buffer가 persistent queue를 만들어 bufferbloat delay를 유발하는 예
4.2.5 Packet Scheduling
packet scheduling은 output queue에 쌓인 packets 중 다음에 outgoing link로 전송할 packet을 고르는 문제다. queueing discipline은 delay, fairness, service differentiation, policy에 직접 영향을 준다.
FIFO/FCFS. FIFO (First-In-First-Out) 또는 FCFS (First-Come-First-Served)는 packet이 도착한 순서대로 전송한다. 단일 queue에서 가장 단순하고 예측하기 쉽지만, traffic class별 priority나 bandwidth share를 표현하지 못한다.
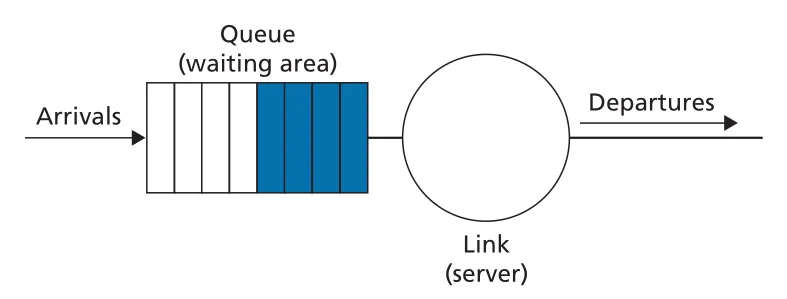 Figure 4.11 · PDF p. 336 · arriving packets가 단일 FIFO queue에서 순서대로 service를 기다리는 추상 모델
Figure 4.11 · PDF p. 336 · arriving packets가 단일 FIFO queue에서 순서대로 service를 기다리는 추상 모델
Priority Queueing. priority queueing은 arriving packets를 priority classes로 분류하고, nonempty queues 중 가장 높은 priority class의 packet을 먼저 전송한다. 예를 들어 network management traffic, real-time VoIP packets을 일반 email traffic보다 높은 priority로 줄 수 있다. 같은 priority class 안에서는 보통 FIFO를 사용한다. non-preemptive priority queue에서는 이미 packet transmission이 시작되면 더 높은 priority packet이 도착해도 현재 transmission을 중단하지 않는다.
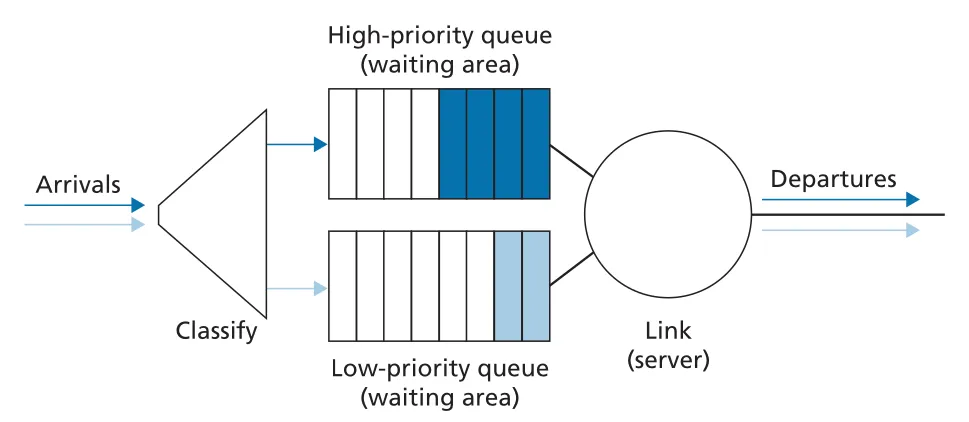 Figure 4.13 · PDF p. 337 · high-priority queue와 low-priority queue를 분리해 scheduling하는 priority queueing model
Figure 4.13 · PDF p. 337 · high-priority queue와 low-priority queue를 분리해 scheduling하는 priority queueing model
priority scheduling은 QoS와 traffic management에 강력하지만, policy 문제도 만든다. ISP가 IP header fields나 TCP/UDP port numbers를 기준으로 특정 service/company/source traffic에 우선권을 주거나 block/throttle할 수 있기 때문이다. 이 지점이 net neutrality 논쟁과 연결된다. 원문은 미국 정책 변천을 소개하지만, 핵심 개념은 packet scheduling mechanism이 technical policy enforcement 도구가 될 수 있다는 점이다.
Round Robin and WFQ. round robin은 classes 사이를 순서대로 돌며 service를 제공한다. strict priority와 달리 low-priority class도 turn을 얻을 수 있다. work-conserving discipline은 어떤 class를 확인했을 때 비어 있으면 다음 class를 바로 확인해, queue에 packet이 있는데 link가 idle로 남지 않게 한다.
WFQ (Weighted Fair Queuing)는 round robin을 일반화해 class마다 weight wi를 둔다. class i에 queued packets가 있는 동안, 그 class는 전체 active weights 대비 자신의 weight 비율만큼 service를 보장받는다.
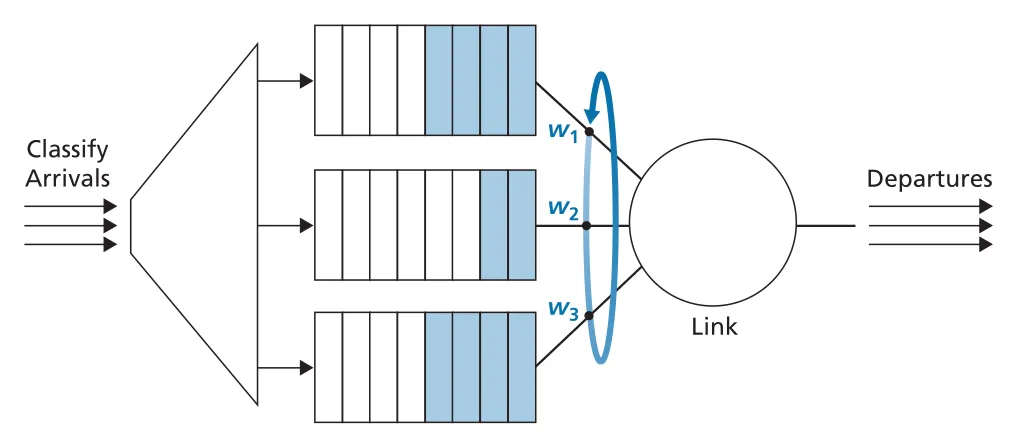 Figure 4.16 · PDF p. 341 · WFQ가 class별 weight에 따라 outgoing link service share를 나누는 구조
Figure 4.16 · PDF p. 341 · WFQ가 class별 weight에 따라 outgoing link service share를 나누는 구조
정리하면 FIFO는 단순성, priority queueing은 우선순위, round robin은 class 간 순환 공정성, WFQ는 weighted bandwidth share를 제공한다. router data plane에서 scheduling은 단순히 “어떤 packet을 먼저 보낼까”가 아니라 delay-sensitive traffic, fairness, congestion signal, policy enforcement가 만나는 지점이다.
4.3 The Internet Protocol (IP): IPv4, Addressing, IPv6, and More
앞 절까지는 data plane, forwarding/routing, router internals를 특정 protocol에 크게 의존하지 않고 보았다. 이제 Internet network layer의 핵심 protocol인 IP (Internet Protocol)를 본다. 현재 Internet에는 IPv4와 IPv6가 함께 사용된다. 먼저 IPv4 datagram format과 addressing을 이해해야 traditional IP forwarding이 어떻게 가능한지 보인다.
4.3.1 IPv4 Datagram Format
Internet network-layer packet은 datagram이라고 부른다. IPv4 datagram header는 router가 forwarding, loop prevention, transport demultiplexing, error detection을 수행하는 데 필요한 fields를 담는다.
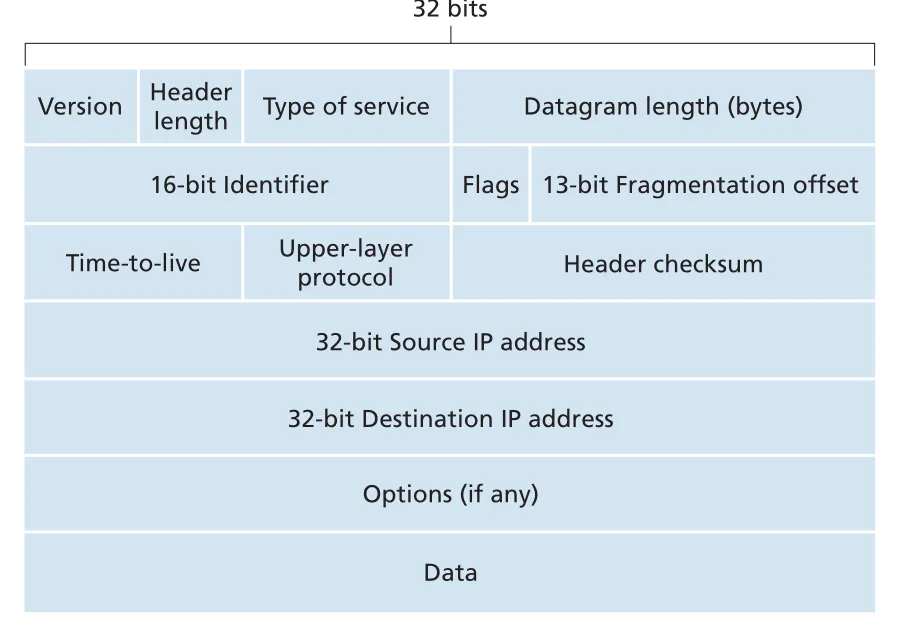 Figure 4.17 · PDF p. 342 · IPv4 datagram header의 주요 fields와 payload 구조
Figure 4.17 · PDF p. 342 · IPv4 datagram header의 주요 fields와 payload 구조
| IPv4 field | 역할 |
|---|---|
version number | IP version을 표시한다. IPv4와 IPv6는 datagram format이 다르므로 router가 해석 방식을 결정한다. |
header length | IPv4 header가 variable length일 수 있어 payload 시작 위치를 알려준다. options가 없으면 보통 20 bytes header다. |
type of service (TOS) | real-time/non-real-time traffic 구분 같은 service differentiation에 사용될 수 있다. ECN bits도 이 영역과 연결된다. |
datagram length | header + data 전체 길이(bytes). 16-bit field라 이론상 최대 65,535 bytes지만 실제로는 Ethernet MTU 때문에 훨씬 작은 경우가 많다. |
identifier, flags, fragmentation offset | IPv4 fragmentation/reassembly 관련 fields. IPv6는 router fragmentation을 허용하지 않는다. |
time-to-live (TTL) | router를 지날 때마다 1씩 감소한다. 0이 되면 datagram을 drop해 routing loop에서 무한 순환하지 않게 한다. |
protocol | destination host에서 payload를 어느 upper-layer protocol로 넘길지 표시한다. TCP는 6, UDP는 17이다. |
header checksum | IPv4 header bit error를 탐지한다. TTL이 매 router에서 바뀌므로 checksum도 router마다 recompute된다. |
source IP address / destination IP address | datagram의 출발 interface와 ultimate destination interface 주소. forwarding은 주로 destination IP address를 사용한다. |
options | 드물게 header 확장 정보를 담는다. variable header length와 variable processing time을 만들어 high-speed router 구현을 복잡하게 한다. IPv6 base header에서는 제거되었다. |
data (payload) | 보통 TCP/UDP segment가 들어가지만, ICMP 같은 다른 network-layer data도 들어갈 수 있다. |
IP protocol field는 network layer와 transport layer를 묶는 glue다. TCP/UDP segment의 port number가 transport layer와 application layer 사이에서 어느 socket/process로 보낼지 알려주는 것처럼, IP protocol number는 datagram payload를 TCP, UDP, ICMP 등 어느 upper protocol로 넘길지 알려준다.
IPv4 header checksum은 IP header만 검사한다. TCP/UDP checksum은 transport segment 전체를 대상으로 한다. 이중 error checking은 중복처럼 보이지만 layer별 책임이 다르다. IP는 TCP/UDP가 아닌 payload도 운반할 수 있고, TCP/UDP도 이론상 IP가 아닌 network protocol 위에서 동작할 수 있다.
4.3.2 IPv4 Addressing
IPv4 address는 host나 router “전체”가 아니라 interface에 붙는다. host는 보통 network로 나가는 single interface를 가지지만, router는 datagram을 한 link에서 받아 다른 link로 forward해야 하므로 여러 interfaces를 가진다. IP datagram을 send/receive할 수 있는 각 host/router interface는 IP address가 필요하다.
IPv4 address는 32 bits, 즉 4 bytes다. 보통 각 byte를 decimal로 쓰고 dot으로 구분하는 dotted-decimal notation을 사용한다.
193.32.216.9
= 11000001 00100000 11011000 00001001global Internet의 각 interface address는 원칙적으로 globally unique해야 한다. 단 NAT 뒤의 private addresses는 예외가 된다. 주소는 임의로 고르는 것이 아니라 interface가 연결된 subnet에 의해 prefix가 정해진다.
subnet은 router를 거치지 않고 서로 도달할 수 있는 interfaces의 집합이다. 예를 들어 같은 Ethernet LAN 또는 wireless access point에 붙은 host interfaces와 router interface는 하나의 subnet을 이룬다. 223.1.1.0/24에서 /24는 왼쪽 24 bits가 subnet address라는 뜻이며, subnet mask라고도 부른다.
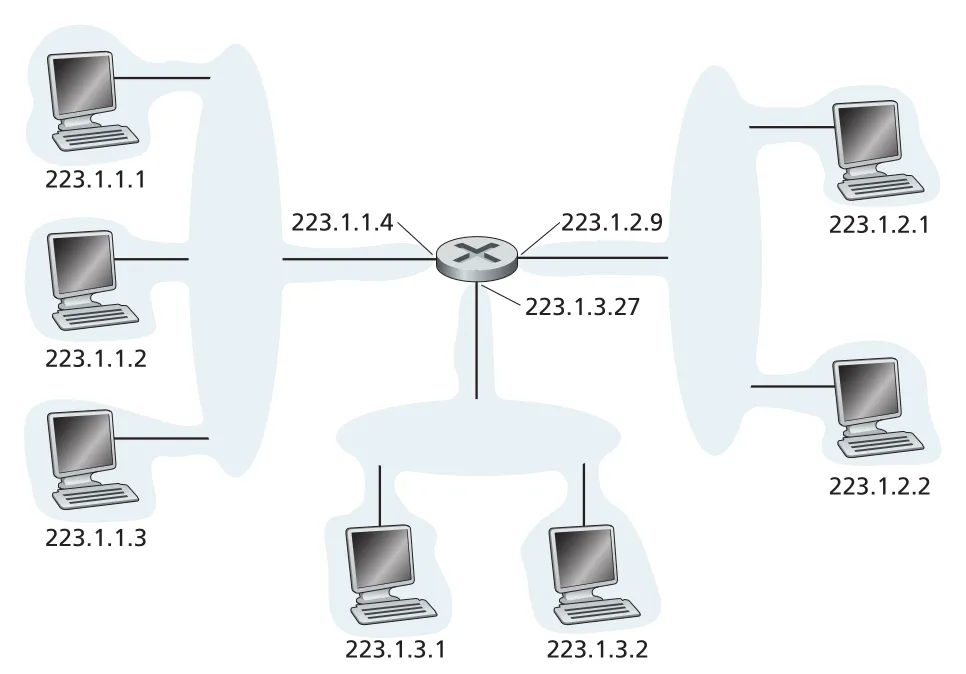 Figure 4.18 · PDF p. 346 · router interfaces와 host interfaces가 subnet별 IPv4 address prefix를 공유하는 예
Figure 4.18 · PDF p. 346 · router interfaces와 host interfaces가 subnet별 IPv4 address prefix를 공유하는 예
subnet을 찾는 절차는 다음처럼 생각할 수 있다.
1. 각 host/router interface를 장치에서 떼어낸다고 생각한다.
2. router 없이 서로 연결된 isolated network island를 찾는다.
3. 각 island가 하나의 subnet이다.point-to-point router link도 subnet이다. Figure 4.20처럼 세 routers가 서로 point-to-point links로 연결되어 있고 각 router가 host-facing LAN도 갖는다면, host LAN subnets뿐 아니라 router-to-router links도 각각 별도 subnet을 이룬다.
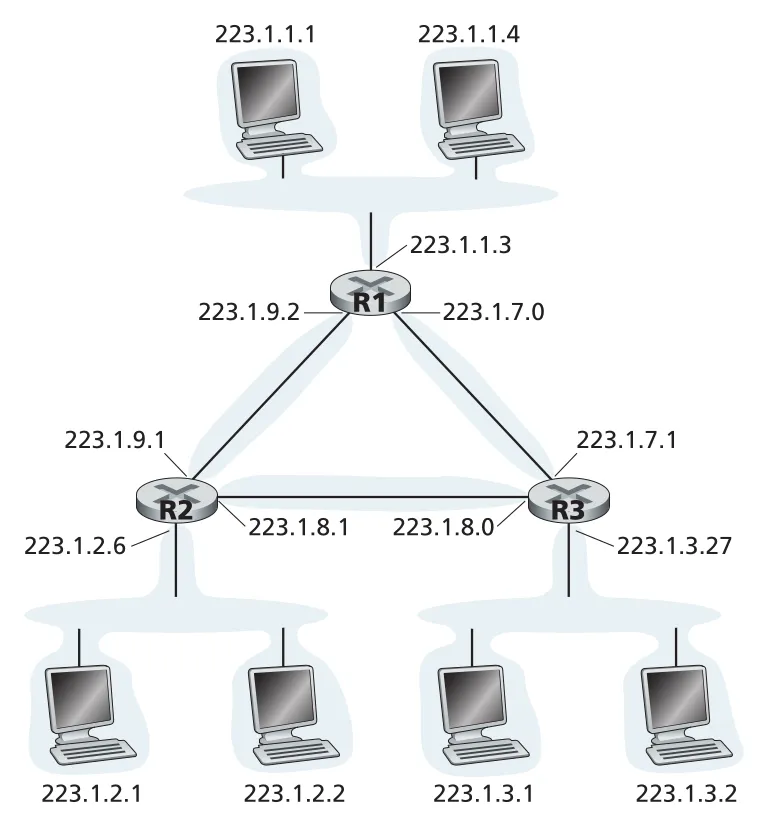 Figure 4.20 · PDF p. 348 · host LAN subnets와 router-to-router point-to-point link subnets가 함께 존재하는 구조
Figure 4.20 · PDF p. 348 · host LAN subnets와 router-to-router point-to-point link subnets가 함께 존재하는 구조
Internet address assignment는 CIDR (Classless Interdomain Routing)를 사용한다. CIDR은 address를 a.b.c.d/x 형태로 표현하며, 왼쪽 x bits를 network prefix로 본다. organization은 보통 contiguous address block, 즉 common prefix를 공유하는 address range를 할당받는다. 외부 routers는 destination이 그 organization 안에 있는지 판단할 때 x leading prefix bits만 보면 되므로 forwarding table size가 크게 줄어든다.
a.b.c.d/x
|--- x bits ---|--- 32-x bits ---|
network prefix host/subnet part inside organizationCIDR 이전의 classful addressing은 network portion 길이를 8, 16, 24 bits로 고정했다. Class C(/24)는 최대 254 hosts라 작고, Class B(/16)는 65,534 hosts라 중간 규모 organization에는 너무 컸다. 이 때문에 address space가 낭비되었다. CIDR은 prefix length를 유연하게 해 address allocation과 route aggregation을 가능하게 했다.
address aggregation, route aggregation, route summarization은 여러 networks를 하나의 더 짧은 prefix로 advertise하는 기술이다. 예를 들어 ISP가 200.23.16.0/20을 Internet에 advertise하면, 외부 routers는 그 block 안의 여러 organizations 세부 subnet을 몰라도 해당 ISP로 traffic을 보낼 수 있다.
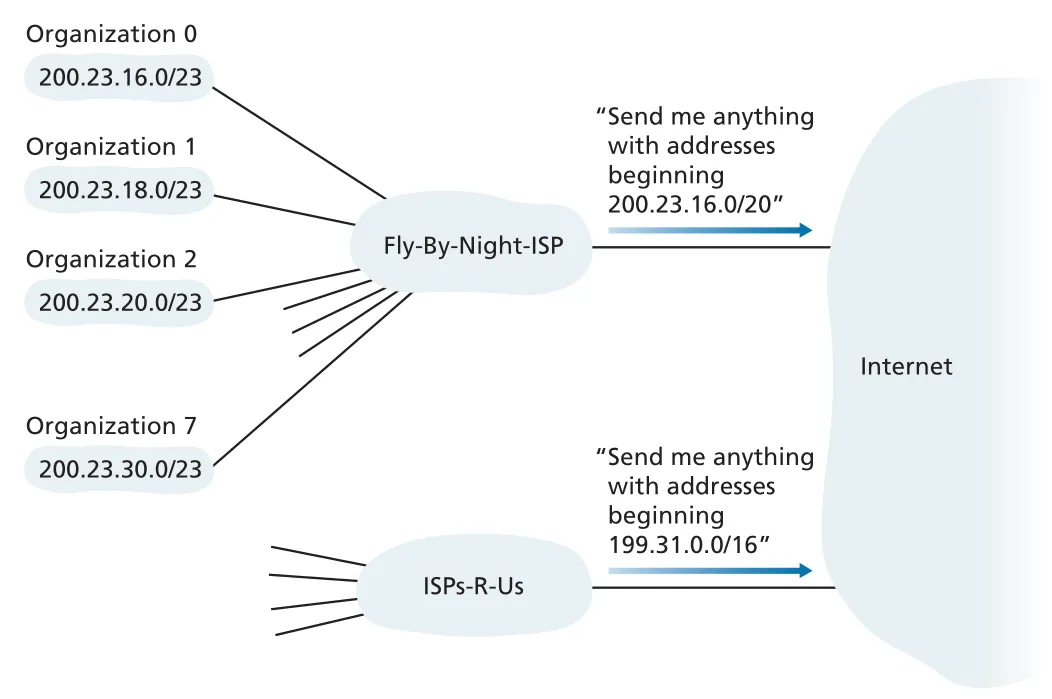 Figure 4.21 · PDF p. 350 · ISP가 여러 organizations의 address blocks를 하나의 aggregate prefix로 advertise하는 구조
Figure 4.21 · PDF p. 350 · ISP가 여러 organizations의 address blocks를 하나의 aggregate prefix로 advertise하는 구조
하지만 더 specific route가 별도로 advertise될 수도 있다. Figure 4.22처럼 200.23.16.0/20 aggregate와 200.23.18.0/23 more-specific prefix가 동시에 보이면, routers는 longest prefix matching으로 더 긴 prefix인 /23 route를 선택한다. 이 때문에 Section 4.2.1의 longest prefix matching은 forwarding lookup의 구현 세부가 아니라 CIDR routing의 핵심 규칙이다.
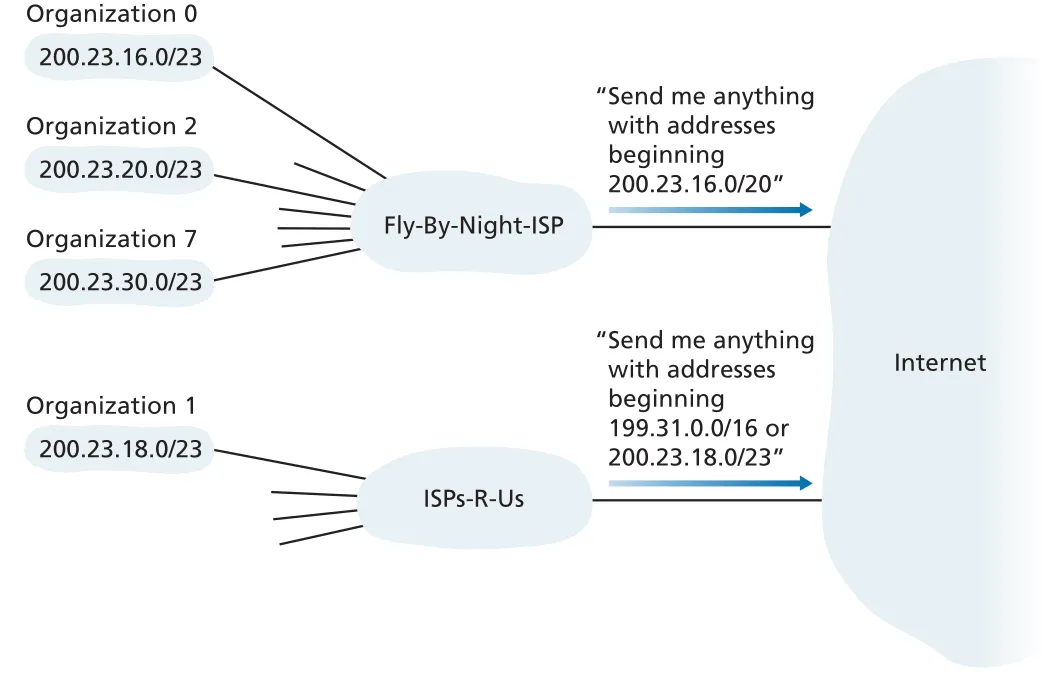 Figure 4.22 · PDF p. 350 · aggregate route보다 더 specific한 prefix가 있으면 longest prefix matching으로 더 specific route가 선택된다
Figure 4.22 · PDF p. 350 · aggregate route보다 더 specific한 prefix가 있으면 longest prefix matching으로 더 specific route가 선택된다
IPv4에는 broadcast address도 있다. 255.255.255.255 destination address로 datagram을 보내면 같은 subnet의 모든 hosts에 전달된다. routers가 neighboring subnets로 forward할 수도 있지만, 보통은 그렇게 하지 않는다.
Obtaining a Block of Addresses. organization이 IP address block을 얻는 일반적인 경로는 ISP로부터 ISP가 가진 더 큰 block의 일부를 할당받는 것이다. ISP 자신은 더 큰 address authority로부터 block을 받는다. global IP address space는 ICANN (Internet Corporation for Assigned Names and Numbers) 권한 아래 관리되며, regional Internet registries가 지역별 address allocation/management를 맡는다. 이 세부 기관 이름 자체보다 중요한 점은 IP address가 global uniqueness와 route aggregation을 위해 hierarchical하게 관리된다는 것이다.
Obtaining a Host Address: DHCP. organization이 address block을 얻은 뒤에는 host/router interfaces에 individual IP addresses를 할당해야 한다. router interface는 administrator가 manually configure하는 경우가 많지만, hosts는 보통 DHCP (Dynamic Host Configuration Protocol)로 자동 설정한다.
DHCP는 host에게 단순히 IP address만 주지 않는다. 보통 다음 network configuration information을 함께 제공한다.
| DHCP가 알려주는 정보 | 의미 |
|---|---|
| host IP address | host interface가 사용할 IPv4 address |
| subnet mask | 같은 subnet prefix를 판별하는 mask |
| first-hop router / default gateway | subnet 밖으로 나갈 때 보낼 router address |
| local DNS server | DNS query를 보낼 server address |
| lease time | 할당된 address를 사용할 수 있는 기간 |
DHCP는 plug-and-play 또는 zeroconf protocol이라고도 불린다. laptop이 dormitory, library, classroom처럼 다른 subnet으로 이동할 때마다 새 IP address와 configuration이 필요하기 때문에, join/leave가 빈번한 residential, enterprise, wireless LAN에서 특히 중요하다.
DHCP는 client-server protocol이다. subnet에 DHCP server가 직접 있을 수도 있고, 없으면 router가 DHCP relay agent로 동작해 다른 subnet의 DHCP server와 통신하게 할 수 있다.
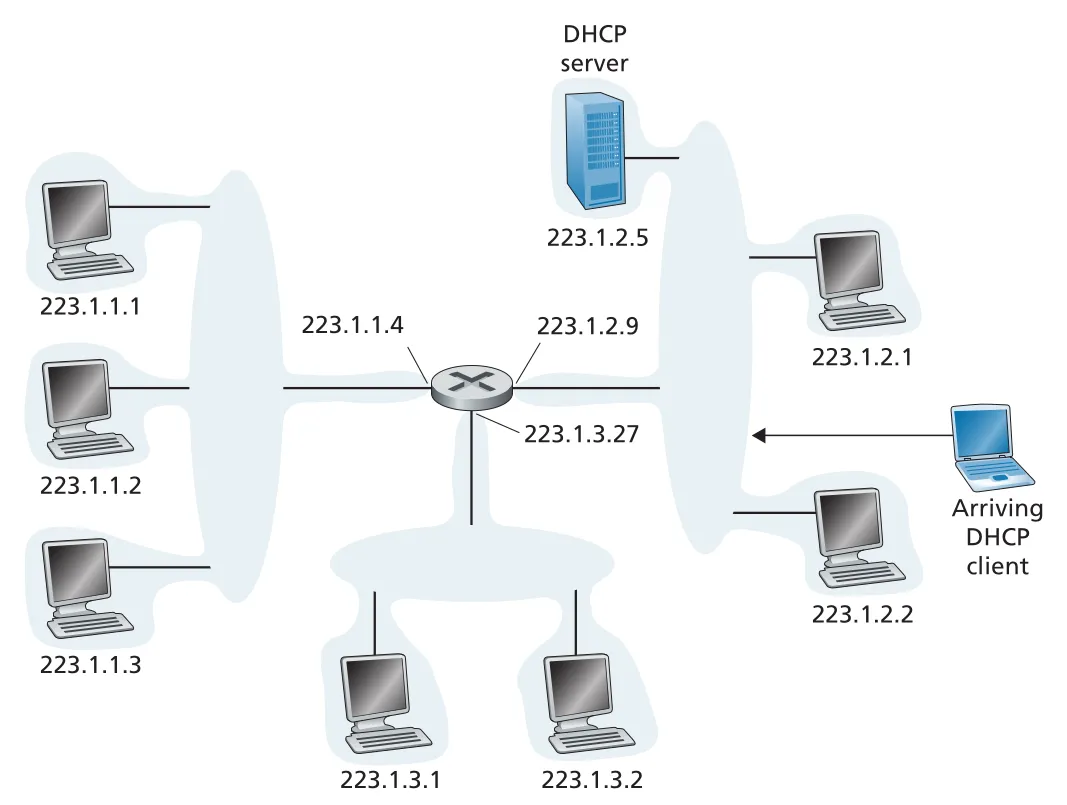 Figure 4.23 · PDF p. 353 · DHCP server가 특정 subnet에 있고 router가 다른 subnets의 relay agent 역할을 할 수 있는 구성
Figure 4.23 · PDF p. 353 · DHCP server가 특정 subnet에 있고 router가 다른 subnets의 relay agent 역할을 할 수 있는 구성
새로 들어온 host가 DHCP로 주소를 얻는 절차는 네 단계다. client는 처음에 자신의 IP address도, DHCP server address도 모르므로 broadcast를 사용한다.
1. DHCP discover
client: 0.0.0.0:68 -> 255.255.255.255:67
"DHCP server가 있으면 응답해 달라"
2. DHCP offer
server: server_IP:67 -> 255.255.255.255:68
proposed IP address, subnet mask, lease time, server ID 제공
3. DHCP request
client: 0.0.0.0:68 -> 255.255.255.255:67
선택한 offer의 parameters를 요청
4. DHCP ACK
server: server_IP:67 -> 255.255.255.255:68
requested parameters 확정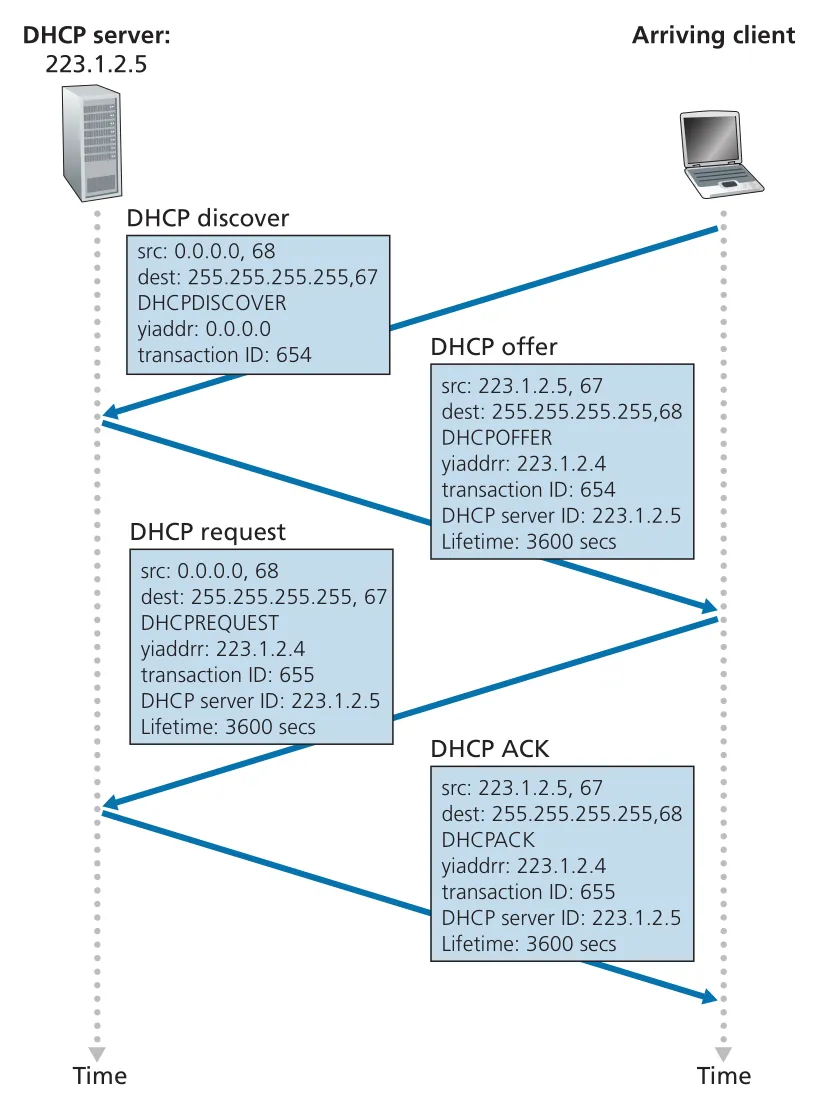 Figure 4.24 · PDF p. 354 · DHCP discover, offer, request, ACK로 이어지는 client-server interaction
Figure 4.24 · PDF p. 354 · DHCP discover, offer, request, ACK로 이어지는 client-server interaction
DHCP ACK를 받으면 client는 lease duration 동안 할당된 IP address를 사용할 수 있고, 필요하면 lease renewal을 수행한다. DHCP의 한계도 있다. node가 새 subnet에 붙을 때 새 IP address를 받으면 기존 TCP connection은 유지되기 어렵다. Chapter 7의 cellular mobility는 이동 중에도 IP address와 ongoing TCP connections를 유지하는 별도 mechanism을 다룬다.
4.3.3 Network Address Translation (NAT)
NAT (Network Address Translation)는 private network 안의 여러 devices가 하나의 public-facing IP address를 공유해 Internet과 통신하게 하는 mechanism이다. SOHO/home network처럼 많은 devices를 ISP가 각각 public IPv4 address로 할당하기 어려운 환경에서 널리 쓰인다.
Figure 4.25의 home network는 private address block 10.0.0.0/24를 사용한다. 더 넓게는 10.0.0.0/8 같은 address ranges가 private network용으로 예약되어 있다. private address는 해당 private realm 안에서만 의미가 있으므로 global Internet으로 그대로 나가면 안 된다. 외부 Internet에서 보면 NAT-enabled router는 내부 network 전체를 숨기고 하나의 device처럼 보인다.
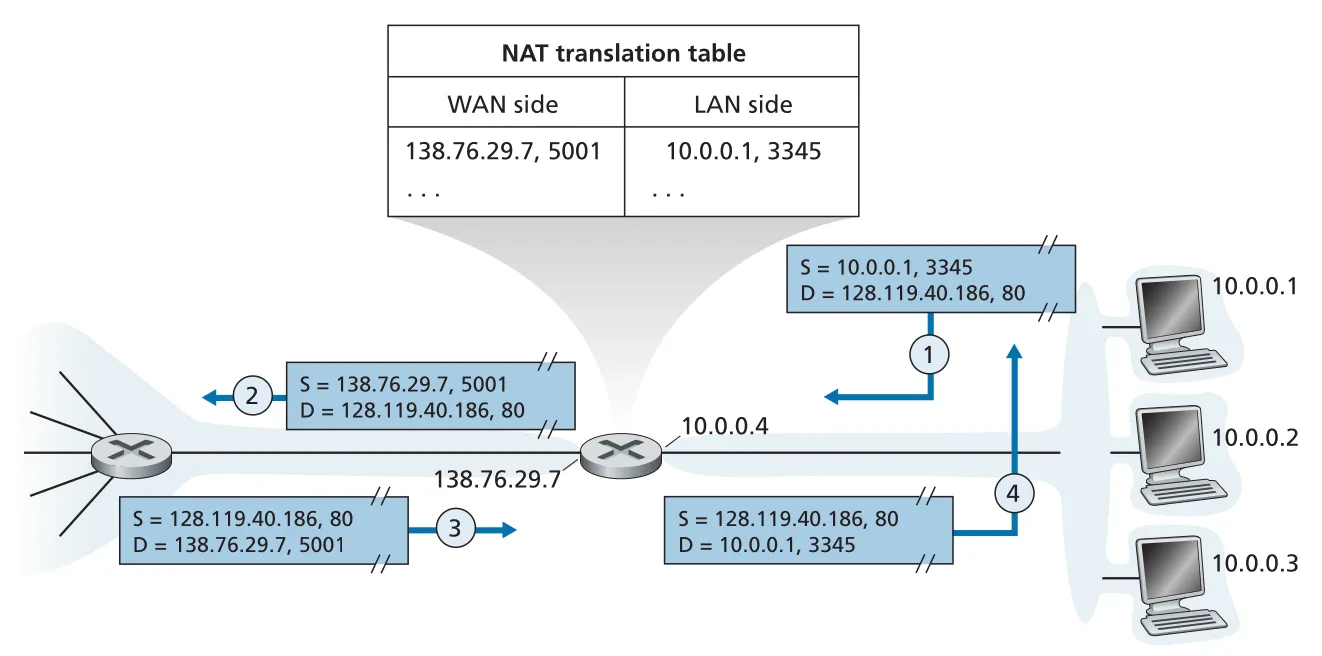 Figure 4.25 · PDF p. 356 · NAT router가 private LAN address/port와 public WAN address/port를 translation table로 매핑하는 방식
Figure 4.25 · PDF p. 356 · NAT router가 private LAN address/port와 public WAN address/port를 translation table로 매핑하는 방식
NAT의 핵심은 NAT translation table에 IP address뿐 아니라 transport-layer port number까지 함께 저장한다는 점이다.
Outbound:
LAN host 10.0.0.1:3345 -> Web server 128.119.40.186:80
NAT rewrites source to 138.76.29.7:5001
table: 138.76.29.7:5001 <-> 10.0.0.1:3345
Inbound reply:
Web server 128.119.40.186:80 -> 138.76.29.7:5001
NAT table lookup rewrites destination to 10.0.0.1:3345port number field가 16 bits라서 하나의 public WAN-side IP address로도 수만 개 simultaneous connections를 구분할 수 있다. NAT router 자체도 ISP의 DHCP server에게 WAN-side IP address를 받을 수 있고, 동시에 내부 LAN hosts에게 private addresses를 나눠주는 DHCP server로 동작할 수 있다.
NAT의 장점은 IPv4 address pressure를 줄이고, home network 내부 구조를 외부에 숨기며, 사용자가 address allocation을 직접 관리하지 않아도 된다는 점이다. 하지만 architectural trade-off도 크다.
| NAT 논점 | 설명 |
|---|---|
| port number misuse | port number는 원래 process addressing용인데, NAT에서는 internal host 구분에도 사용된다. |
| incoming connection difficulty | NAT 뒤의 host가 server 역할을 하거나 P2P peer로 incoming connection을 받아야 할 때 문제가 생긴다. |
| layer violation | router가 layer 3 device라면 network-layer header까지만 봐야 한다는 순수한 layering 관점과 충돌한다. NAT는 transport-layer port number까지 읽고 rewrite한다. |
| middlebox debate | NAT는 forwarding만 하는 router가 아니라 packet header를 수정하는 middlebox 성격을 가진다. |
NAT traversal tools는 NAT 뒤 host와 외부 peer가 연결될 수 있게 돕지만, NAT 자체가 end-to-end principle을 약화시키고 debugging/deployment complexity를 키운다는 비판은 남는다. 이 논의는 Section 4.5의 middleboxes로 이어진다.
원문은 이 지점에서 firewalls와 IDS/IPS도 소개한다. firewall은 source/destination IP addresses, TCP/UDP port numbers, ICMP type 같은 header fields를 검사해 suspicious datagrams를 block할 수 있다. IDS (Intrusion Detection System)는 payload까지 검사하는 deep packet inspection으로 attack signatures를 찾고 alert를 만든다. IPS (Intrusion Prevention System)는 alert뿐 아니라 packet blocking까지 수행한다. 이들은 forwarding 외 기능을 수행한다는 점에서 middlebox discussion의 preview다.
4.3.4 IPv6
IPv6는 IPv4의 32-bit address space가 고갈될 것이라는 문제의식에서 설계되었다. 단순히 address 길이만 늘린 것이 아니라, IPv4 운영 경험을 바탕으로 router processing을 빠르게 만들기 위해 header 구조도 조정했다.
IPv6의 큰 변화는 세 가지다.
| 변화 | 의미 |
|---|---|
| expanded addressing | IP address가 32 bits에서 128 bits로 확장된다. unicast/multicast 외에 group 중 하나에게 전달하는 anycast address도 도입된다. |
| streamlined 40-byte header | fixed-length 40-byte header로 router processing을 단순화한다. IPv4의 일부 fields는 제거되거나 optional next header로 이동한다. |
| flow labeling | flow label로 special handling이 필요한 datagram flow를 식별할 수 있게 한다. QoS/real-time service 가능성을 염두에 둔 설계다. |
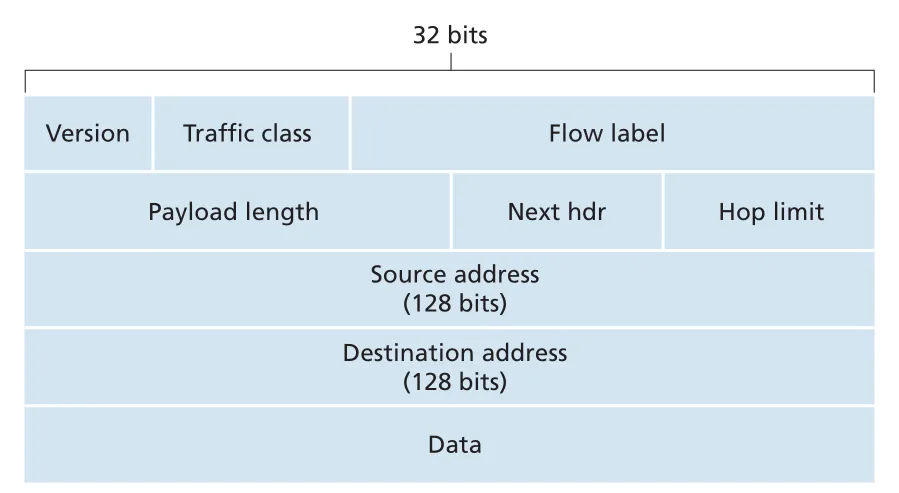 Figure 4.26 · PDF p. 360 · fixed-length 40-byte IPv6 datagram header와 128-bit source/destination addresses
Figure 4.26 · PDF p. 360 · fixed-length 40-byte IPv6 datagram header와 128-bit source/destination addresses
IPv6 header fields는 IPv4와 이름이 비슷해도 처리 철학이 다르다.
| IPv6 field | 역할 |
|---|---|
version | IP version 6을 표시한다. 이 field에 4를 넣는다고 IPv4 datagram이 되는 것은 아니다. |
traffic class | IPv4 TOS처럼 datagrams에 priority나 class를 줄 수 있다. |
flow label | 특정 flow에 속하는 datagrams를 식별한다. |
payload length | fixed 40-byte header 뒤 payload bytes 수를 나타낸다. |
next header | payload를 TCP/UDP 등 어느 protocol로 넘길지 나타낸다. IPv4의 protocol field와 같은 값 체계를 사용한다. |
hop limit | IPv4 TTL과 같은 loop-prevention 역할. router마다 1씩 감소하고 0이면 discard된다. |
source/destination addresses | 각각 128-bit IPv6 address다. |
data | next header가 가리키는 upper-layer payload다. |
IPv6에서 빠진 IPv4 기능도 중요하다.
| IPv4에는 있지만 IPv6 base header에는 없는 것 | 왜 제거/변경했는가 |
|---|---|
| router fragmentation/reassembly | intermediate router가 fragmentation을 수행하지 않는다. 너무 큰 datagram은 drop하고 Packet Too Big ICMP error를 sender에게 보낸다. fragmentation은 source/destination에서 처리한다. |
| header checksum | TCP/UDP와 link layer도 checksum을 제공하므로 network-layer checksum을 제거해 router processing 비용을 줄였다. IPv4에서는 TTL 변경 때문에 매 hop recompute가 필요했다. |
| options in base header | options는 fixed header 밖의 next header 형태로 처리된다. base header가 fixed-length가 되어 fast forwarding에 유리하다. |
Transitioning from IPv4 to IPv6. IPv6-capable systems는 IPv4도 처리하도록 만들 수 있지만, 이미 배포된 IPv4-only routers는 IPv6 datagram을 이해하지 못한다. 전 세계 devices를 특정 날짜에 모두 끄고 IPv6로 바꾸는 flag day는 현실적으로 불가능하다. 그래서 가장 널리 쓰인 전환 방식 중 하나가 tunneling이다.
tunneling에서는 IPv6 routers 사이에 IPv4-only routers 구간이 있을 때, sending-side IPv6 node가 전체 IPv6 datagram을 IPv4 datagram payload 안에 넣어 보낸다. IPv4 tunnel 내부 routers는 payload가 IPv6 datagram이라는 사실을 몰라도 된다. receiving-side IPv6 node는 IPv4 datagram의 protocol number 41을 보고 payload가 IPv6 datagram임을 인식한 뒤, 내부 IPv6 datagram을 꺼내 정상적으로 forwarding한다.
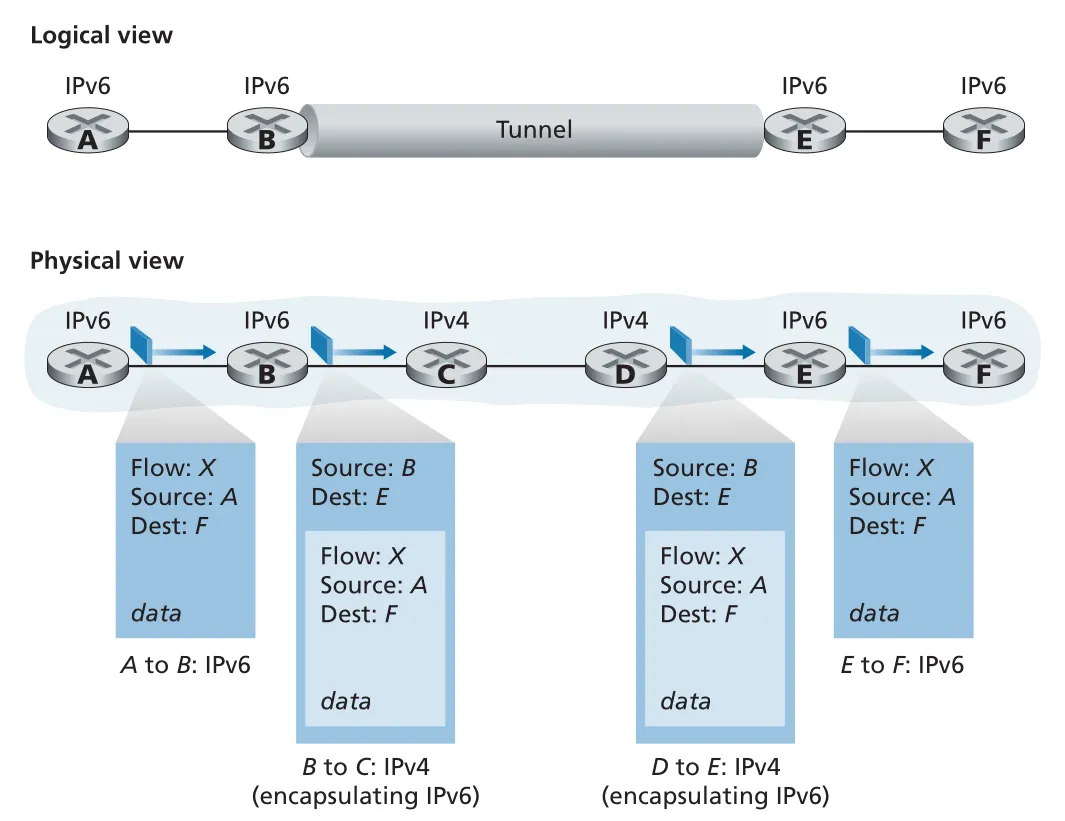 Figure 4.27 · PDF p. 363 · IPv6 datagram을 IPv4 datagram 안에 encapsulation해 IPv4 tunnel을 통과시키는 방식
Figure 4.27 · PDF p. 363 · IPv6 datagram을 IPv4 datagram 안에 encapsulation해 IPv4 tunnel을 통과시키는 방식
IPv6 사례의 큰 교훈은 network-layer protocol을 바꾸는 일이 매우 어렵다는 점이다. network layer는 Internet의 foundation에 가까워서, 새 protocol을 배포하려면 hosts, routers, operational practices가 광범위하게 바뀌어야 한다. 반대로 application-layer protocol은 Web, streaming, messaging처럼 훨씬 빠르게 배포될 수 있다. 이 차이는 왜 QUIC 같은 기능이 application layer에서 빠르게 진화할 수 있었는지와도 연결된다.
4.4 Generalized Forwarding and SDN
destination-based forwarding은 destination IP address를 match하고 특정 output port로 보내는 action을 수행하는 특수한 경우다. generalized forwarding은 이 match-plus-action paradigm을 여러 protocol layers의 header fields로 확장한다.
match 대상은 destination IP address 하나가 아니라 link-layer, network-layer, transport-layer fields가 될 수 있다. action도 단순 forwarding을 넘어 drop, duplicate, multicast, load balancing, NAT처럼 header rewrite, DPI server로 redirect 등을 포함할 수 있다. 따라서 generalized forwarding device는 layer 2 switch나 layer 3 router라고만 부르기보다 packet switch라고 부르는 것이 자연스럽다.
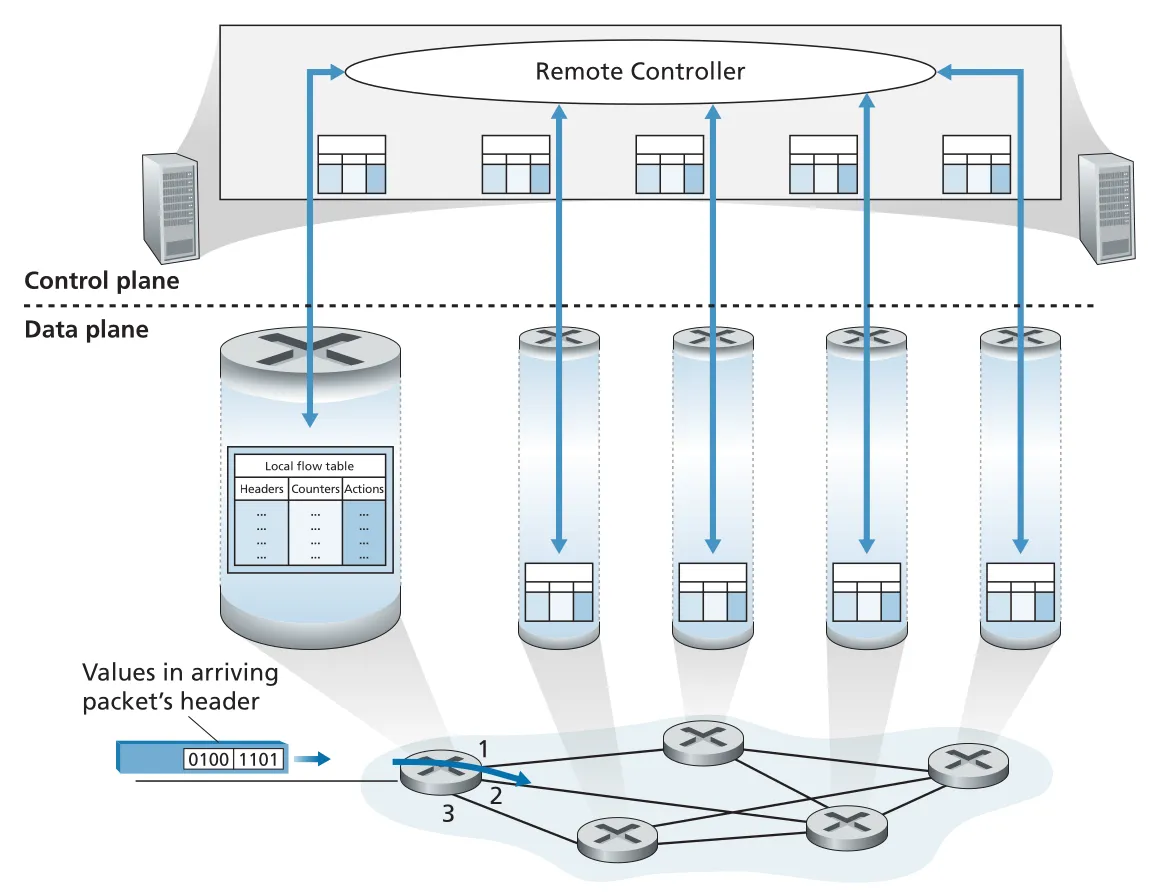 Figure 4.28 · PDF p. 365 · remote controller가 각 packet switch의 match-plus-action flow table을 계산하고 배포하는 generalized forwarding 구조
Figure 4.28 · PDF p. 365 · remote controller가 각 packet switch의 match-plus-action flow table을 계산하고 배포하는 generalized forwarding 구조
OpenFlow는 match-plus-action forwarding abstraction과 controller-based SDN을 널리 알린 대표 standard다. OpenFlow의 forwarding table은 flow table이라고 부르며, 각 entry는 세 부분으로 구성된다.
| Flow table entry 구성 | 의미 |
|---|---|
| match fields | incoming packet header fields와 비교할 값들. match 실패 시 drop하거나 controller로 보낼 수 있다. |
| counters | 해당 entry에 match된 packets 수, 마지막 update 이후 시간 같은 statistics |
| actions | match된 packet에 수행할 동작. forward, drop, duplicate, header rewrite 등 |
flow table은 packet switch behavior를 programming하는 API처럼 볼 수 있다. 개별 switch의 flow table을 설정하면 local forwarding behavior가 바뀌고, network 전체 switch들의 flow tables를 함께 설정하면 routing, layer-2 switching, firewalling, load balancing, virtual networks 같은 network-wide behavior를 만들 수 있다.
4.4.1 Match
OpenFlow 1.0은 incoming port ID와 11개의 packet-header fields를 match할 수 있다. fields는 link layer, network layer, transport layer에 걸쳐 있다. 이는 strict layering principle을 과감하게 넘어서지만, 실제 data-plane policy를 표현하는 데 강력하다.
 Figure 4.29 · PDF p. 366 · OpenFlow 1.0 flow table이 ingress port와 layer 2/3/4 header fields를 match하는 범위
Figure 4.29 · PDF p. 366 · OpenFlow 1.0 flow table이 ingress port와 layer 2/3/4 header fields를 match하는 범위
| Layer | Match examples |
|---|---|
| ingress | Ingress Port |
| link layer | Src MAC, Dst MAC, Eth Type, VLAN ID, VLAN Pri |
| network layer | IP Src, IP Dst, IP Proto, IP TOS |
| transport layer | TCP/UDP Src Port, TCP/UDP Dst Port |
flow table entry에는 wildcard가 들어갈 수 있다. 예를 들어 128.119.*.*는 first 16 bits가 128.119인 IP address와 match된다. 여러 entries가 동시에 match될 수 있으므로 각 entry는 priority를 가진다. packet이 여러 entries와 match되면 highest-priority matching entry의 action이 선택된다.
모든 IP header field를 match할 수 있는 것은 아니다. 예를 들어 OpenFlow 1.0은 TTL이나 datagram length 기준 match를 허용하지 않는다. 이는 abstraction 설계의 trade-off다. 너무 많은 fields와 기능을 넣으면 표현력은 커지지만 hardware complexity와 interface complexity가 커진다. 좋은 abstraction은 필요한 기능을 충분히 제공하면서도 지나치게 general하지 않아야 한다.
4.4.2 Action
flow table entry의 action list는 match된 packet에 수행할 processing을 지정한다. 여러 actions가 있으면 list 순서대로 수행된다.
| Action | 의미 |
|---|---|
forward | 특정 physical output port로 보내거나, all ports로 broadcast하거나, selected ports로 multicast한다. |
send to controller | packet을 encapsulation해 remote controller로 보내고, controller가 새 flow entries를 설치하거나 packet을 되돌려 보낼 수 있다. |
drop | action이 없는 flow entry는 matched packet을 drop한다. firewall rule처럼 쓸 수 있다. |
modify-field | forwarding 전에 selected header fields를 rewrite한다. NAT, traffic steering 등에 쓰인다. |
4.4.3 OpenFlow Examples of Match-plus-action in Action
Figure 4.30의 network는 three packet switches s1, s2, s3, six hosts h1-h6, 그리고 OpenFlow controller로 구성된다. 같은 physical topology라도 flow table entries를 어떻게 설치하느냐에 따라 전혀 다른 logical behavior를 만들 수 있다.
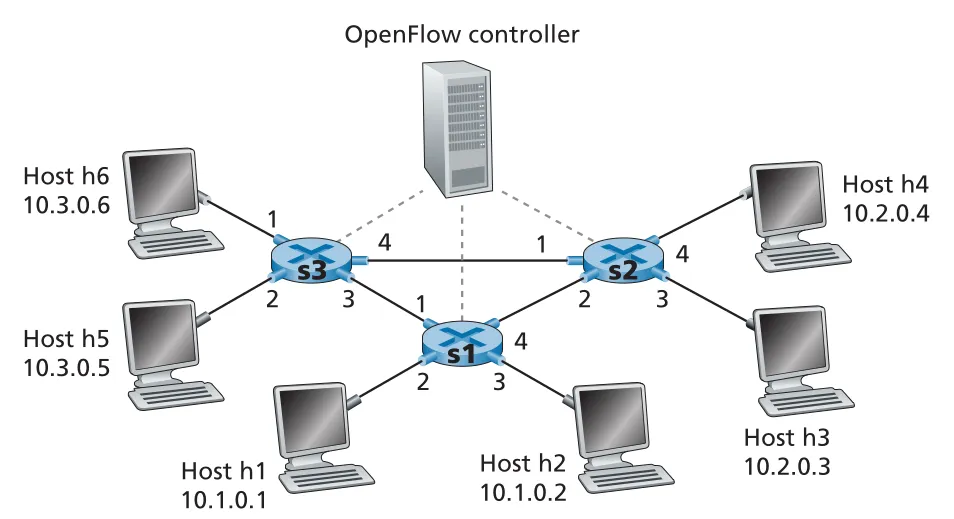 Figure 4.30 · PDF p. 368 · OpenFlow controller가 세 packet switches의 flow tables로 network-wide behavior를 만드는 예시 topology
Figure 4.30 · PDF p. 368 · OpenFlow controller가 세 packet switches의 flow tables로 network-wide behavior를 만드는 예시 topology
Simple Forwarding. h5/h6에서 h3/h4로 가는 traffic을 s3-s2 direct link가 아니라 s3 -> s1 -> s2 path로 보내고 싶다면, 각 switch에 source/destination prefix와 ingress port를 match하는 entries를 넣으면 된다.
s3: IP Src = 10.3.*.* ; IP Dst = 10.2.*.* -> Forward(3)
s1: Ingress Port = 1 ; IP Src = 10.3.*.* ; IP Dst = 10.2.*.* -> Forward(4)
s2: Ingress Port = 2 ; IP Dst = 10.2.0.3 -> Forward(3)
s2: Ingress Port = 2 ; IP Dst = 10.2.0.4 -> Forward(4)Load Balancing. destination prefix가 같아도 source나 ingress port에 따라 다른 path를 선택할 수 있다. 예를 들어 h3에서 10.1.*.*로 가는 datagrams는 s2 -> s1 direct link로 보내고, h4에서 같은 destination prefix로 가는 datagrams는 s2 -> s3 -> s1로 보낼 수 있다. 이는 destination-based IP forwarding만으로는 표현하기 어렵다.
s2: Ingress port = 3 ; IP Dst = 10.1.*.* -> Forward(2)
s2: Ingress port = 4 ; IP Dst = 10.1.*.* -> Forward(1)Firewalling. s2에 붙은 hosts가 s3 쪽 hosts에서 오는 traffic만 받게 하려면 source prefix 10.3.*.*와 destination host를 match하는 entries만 두고, 다른 matching entry를 두지 않으면 된다. no action/miss 처리 정책에 따라 나머지 traffic은 drop된다.
s2: IP Src = 10.3.*.* ; IP Dst = 10.2.0.3 -> Forward(3)
s2: IP Src = 10.3.*.* ; IP Dst = 10.2.0.4 -> Forward(4)이 예시들의 공통점은 data plane rule이 “destination으로 가는 next hop”에만 묶이지 않는다는 점이다. source, destination, ingress port, transport port, VLAN, MAC address 등 여러 fields를 조합해 routing, switching, firewalling, load balancing을 같은 flow-table abstraction으로 표현한다.
OpenFlow flow table은 limited programmability다. header values와 matching conditions에 따라 forwarding/manipulation rule을 지정하지만, 일반적인 programming language처럼 variables, functions, arbitrary arithmetic/Boolean operations를 폭넓게 제공하지는 않는다. 원문은 더 풍부한 line-rate datagram processing language로 P4 (Programming Protocol-independent Packet Processors)를 언급한다. 핵심은 data plane이 점점 “고정 기능 hardware”에서 “programmed packet processing” 방향으로 확장되고 있다는 점이다.
4.5 Middleboxes
middlebox는 source host와 destination host 사이의 data path 위에 있으면서, standard IP router의 normal forwarding 외 기능을 수행하는 intermediary box다. 이 장과 앞 장에서 이미 Web cache, TCP connection splitter, NAT, firewall, IDS/IPS, load balancer 같은 middlebox 성격의 장치들을 만났다.
middleboxes가 수행하는 service는 크게 세 부류로 볼 수 있다.
| Middlebox service | 예 | 기능 |
|---|---|---|
NAT translation | home/SOHO NAT router | private addresses를 public address/port로 rewrite하고 translation table 유지 |
security services | firewall, IDS, IPS, email security gateway | header fields 또는 payload를 검사해 block, alert, filtering 수행 |
performance enhancement | Web cache, compression box, load balancer | caching, compression, service request 분산 등으로 performance 개선 |
middleboxes가 늘어나면 운영 부담도 커진다. specialized hardware boxes, separate software stacks, separate management skills가 필요하기 때문이다. 이를 줄이려는 접근이 NFV (Network Function Virtualization)다. NFV는 commodity networking/computing/storage hardware 위에 specialized software를 올려 middlebox functions를 구현하려는 방향이다. SDN이 control/forwarding behavior를 software로 다루려 했던 것처럼, NFV는 middlebox 기능 자체를 software service로 다루려 한다. 또 다른 방식은 middlebox functionality를 cloud로 outsource하는 것이다.
middleboxes는 Internet architecture의 오래된 구분을 흔든다. 전통적 Internet에서는 network core의 routers가 IP header fields만 보고 datagrams를 forward하고, transport/application intelligence는 network edge의 hosts에 있었다. 하지만 NAT는 IP address와 transport-layer port numbers를 rewrite하고, firewall은 application/transport/network header fields를 조합해 block하며, IDS는 payload까지 검사한다. 즉 middlebox는 strict layering과 end-to-end principle을 깨뜨리지만, 실제 operational/security/performance 필요 때문에 널리 배치된다.
Architectural Principles: IP Hourglass and End-to-End Argument
Internet architecture의 중요한 직관은 IP hourglass다. physical/link layers에는 Ethernet, WiFi, cellular, optical 등 많은 기술이 있고, transport/application layers에도 TCP, UDP, QUIC, HTTP, DASH 등 많은 protocols가 있다. 하지만 network layer의 narrow waist에는 universal protocol인 IP가 있다. 모든 Internet-connected devices가 IP를 구현하면, 위아래의 다양한 기술이 IP라는 공통 service interface를 통해 연결될 수 있다.
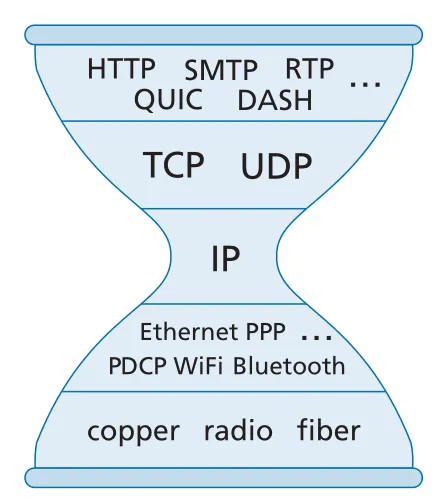 Figure 4.31 · PDF p. 373 · 다양한 lower/upper protocols 사이에서 IP가 narrow waist 역할을 하는 Internet hourglass
Figure 4.31 · PDF p. 373 · 다양한 lower/upper protocols 사이에서 IP가 narrow waist 역할을 하는 Internet hourglass
end-to-end argument는 어떤 기능이 application endpoints의 지식과 도움 없이는 완전하고 올바르게 구현될 수 없다면, 그 기능을 network 내부에 넣어도 완전한 해결이 되기 어렵다는 주장이다. reliable data transfer가 대표 예다. link layer가 local error control을 제공할 수 있어도, router crash, path break, queue loss 같은 end-to-end 문제를 완전히 해결하려면 endpoints의 TCP가 ACK, retransmission, sequence number로 reliability를 구현해야 한다.
이 주장은 network 내부 기능이 항상 나쁘다는 뜻은 아니다. network 내부의 incomplete function이 performance enhancement로 유용할 수는 있다. 하지만 correctness가 application semantics에 의존하는 기능은 end systems에서 책임져야 한다는 기준을 준다. middleboxes는 이 원칙과 현실적 필요 사이의 긴장을 보여준다.
4.6 Summary
이 장은 network layer의 data plane을 다뤘다. data plane은 각 router에서 arriving datagram을 어느 output link로 보낼지 결정하고 실제로 forwarding하는 per-router 기능이다. 반대로 control plane은 forwarding table을 계산하고 network-wide routes를 결정하는 logic이며 Chapter 5에서 다룬다.
핵심 흐름을 다시 묶으면 다음과 같다.
| 범위 | 핵심 |
|---|---|
| 4.1 Overview | forwarding vs routing, data plane vs control plane, Internet best-effort service model |
| 4.2 Router internals | input port lookup, switching fabric, output port queueing, buffer sizing, packet scheduling |
| 4.3 IP | IPv4 datagram format, interface-based addressing, subnet, CIDR, DHCP, NAT, IPv6, tunneling |
| 4.4 Generalized forwarding | destination-based forwarding을 match-plus-action flow table로 일반화, OpenFlow/SDN 예시 |
| 4.5 Middleboxes | NAT, firewall, IDS/IPS, load balancer, NFV, end-to-end principle과의 긴장 |
Chapter 4의 큰 그림은 “Internet network layer는 단순한 best-effort IP service를 narrow waist로 삼고, routers의 fast data plane이 forwarding을 수행한다”는 것이다. 하지만 실제 Internet에서는 performance, security, address shortage, policy, programmability 요구 때문에 NAT, firewalls, SDN, NFV 같은 기능이 data path에 들어오며, 순수한 end-to-end model보다 더 복잡한 현실적 architecture가 만들어진다.
Review and Practice Targets
Chapter 4의 review questions와 problems는 다음 능력을 점검한다.
| 범위 | 연습 초점 |
|---|---|
| Section 4.1 | datagram/packet switch 용어, data plane/control plane 구분, forwarding/routing 차이, best-effort service model |
| Section 4.2 | router components의 hardware/software 분리, shadow forwarding table, switching fabric 비교, HOL blocking, output queueing, FIFO/priority/RR/WFQ scheduling |
| Section 4.3 | IPv4 header fields, TTL/protocol/checksum, subnet/CIDR 계산, longest prefix matching, DHCP values, NAT translation table, IPv4 vs IPv6, tunneling |
| Section 4.4 | destination-based forwarding과 generalized forwarding 차이, OpenFlow flow table, match fields/action types, firewall/load-balancing rules |
| Wireshark IP lab | 실제 packet trace에서 IP datagram fields와 fragmentation/TTL/protocol/header structure 관찰 |
Vinton Cerf 인터뷰는 IP의 설계 질문을 잘 보여준다. 핵심은 “heterogeneous packet networks를 바꾸지 않고 어떻게 interoperate하게 할 것인가”였고, 그 답이 IP narrow waist와 end-to-end host communication으로 이어졌다는 점이다. 이 장의 data plane은 그 설계 철학이 router forwarding, addressing, tunneling, middleboxes와 만나는 지점을 보여준다.