개요
Chapter 4가 router 내부에서 packet을 어느 output port로 보낼지 결정하는 data plane을 다뤘다면, Chapter 5는 network-wide logic인 control plane을 다룬다. control plane은 source host에서 destination host까지 datagram이 지나갈 route를 결정하고, forwarding table/flow table을 계산, 유지, 설치하며, network-layer components와 services를 configuration/management하는 기능까지 포함한다.
이 장의 중심축은 세 가지다. 첫째, least-cost path를 계산하는 routing algorithms다. 둘째, 실제 Internet routing protocols인 OSPF와 BGP다. OSPF는 하나의 ISP/organization 내부에서 동작하는 intra-AS routing protocol이고, BGP는 Internet의 여러 networks를 이어 붙이는 inter-AS routing protocol이어서 Internet의 “glue”라고 불린다. 셋째, SDN (Software-Defined Networking) control plane이다. traditional routers는 data-plane forwarding과 control-plane routing을 router 내부에 함께 넣었지만, SDN은 forwarding devices와 별도 controller service를 분리한다.
후반부에서는 IP network 운영에 꼭 필요한 ICMP (Internet Control Message Protocol), SNMP (Simple Network Management Protocol), NETCONF, YANG을 다룬다. 이들은 routing algorithm 자체라기보다, network가 실제로 오류를 알리고 상태를 관찰하며 설정을 바꾸는 데 쓰이는 control/management 도구다.
핵심 개념
5.1 Introduction
network control plane을 이해하려면 Chapter 4의 두 table을 다시 떠올려야 한다. destination-based forwarding에서는 forwarding table, generalized forwarding에서는 flow table이 data plane과 control plane을 연결한다. table entry는 router-local data-plane behavior를 지정한다. 예를 들어 packet forwarding, dropping, replication, layer 2/3/4 header rewriting 같은 action이 여기서 결정된다.
Chapter 5의 질문은 “이 table들이 어떻게 계산되고, 유지되고, router에 설치되는가?”다. 답은 크게 두 control model로 나뉜다.
| Control model | table 계산 위치 | router 간 상호작용 | 대표 예 | 핵심 특징 |
|---|---|---|---|---|
per-router control | 각 router 내부 routing component | routers의 routing components가 서로 protocol message 교환 | OSPF, BGP | routing과 forwarding 기능이 router 안에 함께 존재 |
logically centralized control | 별도 controller service | router의 control agent (CA)는 controller와 통신 | SDN | controller가 forwarding/flow table을 계산해 배포 |
per-router control에서는 모든 router가 routing algorithm을 실행한다. 각 router의 routing component가 다른 routers의 routing component와 정보를 주고받고, 그 결과로 자기 forwarding table을 계산한다. Internet에서 오래 사용된 전통적인 방식이고, 이 장의 OSPF/BGP가 이 model에 속한다.
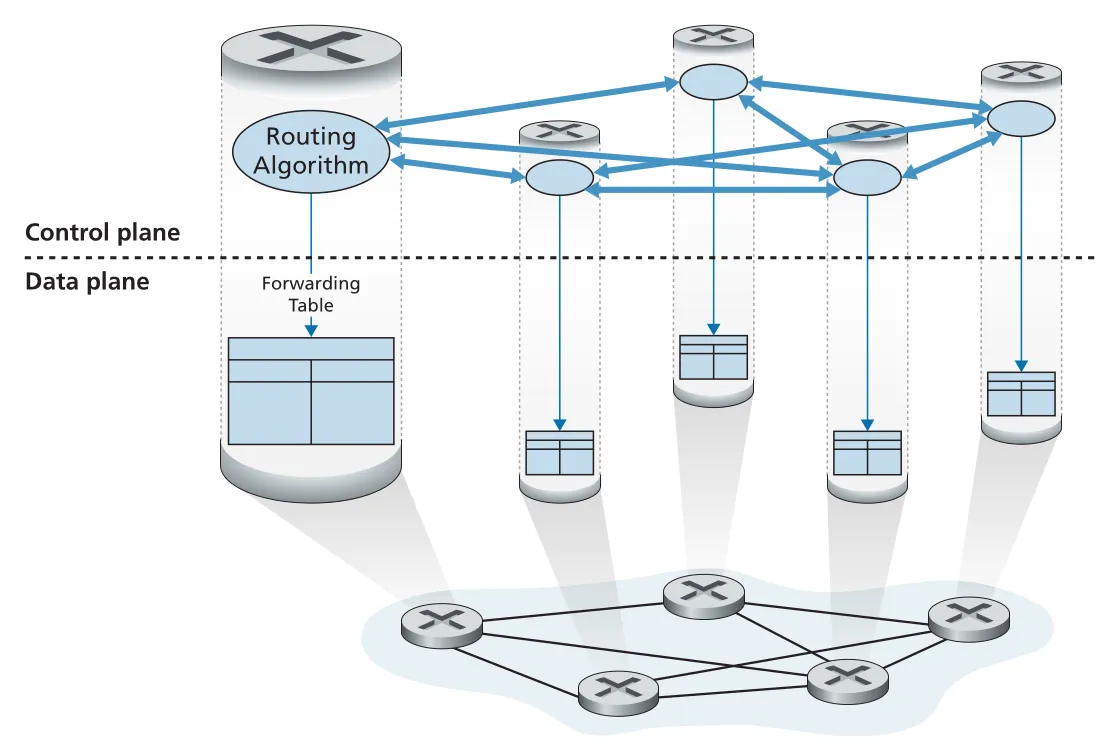 Figure 5.1 · PDF p. 389 · 각 router 내부 routing algorithm이 control plane에서 상호작용해 forwarding table을 만든다
Figure 5.1 · PDF p. 389 · 각 router 내부 routing algorithm이 control plane에서 상호작용해 forwarding table을 만든다
logically centralized control에서는 controller가 각 router의 forwarding/flow table을 계산하고 배포한다. router 내부의 control agent (CA)는 기능이 작다. CA는 controller와 protocol로 통신하고, controller가 내려주는 명령을 수행한다. CA끼리는 직접 routing 정보를 교환하지 않으며, path 계산에도 적극 참여하지 않는다.
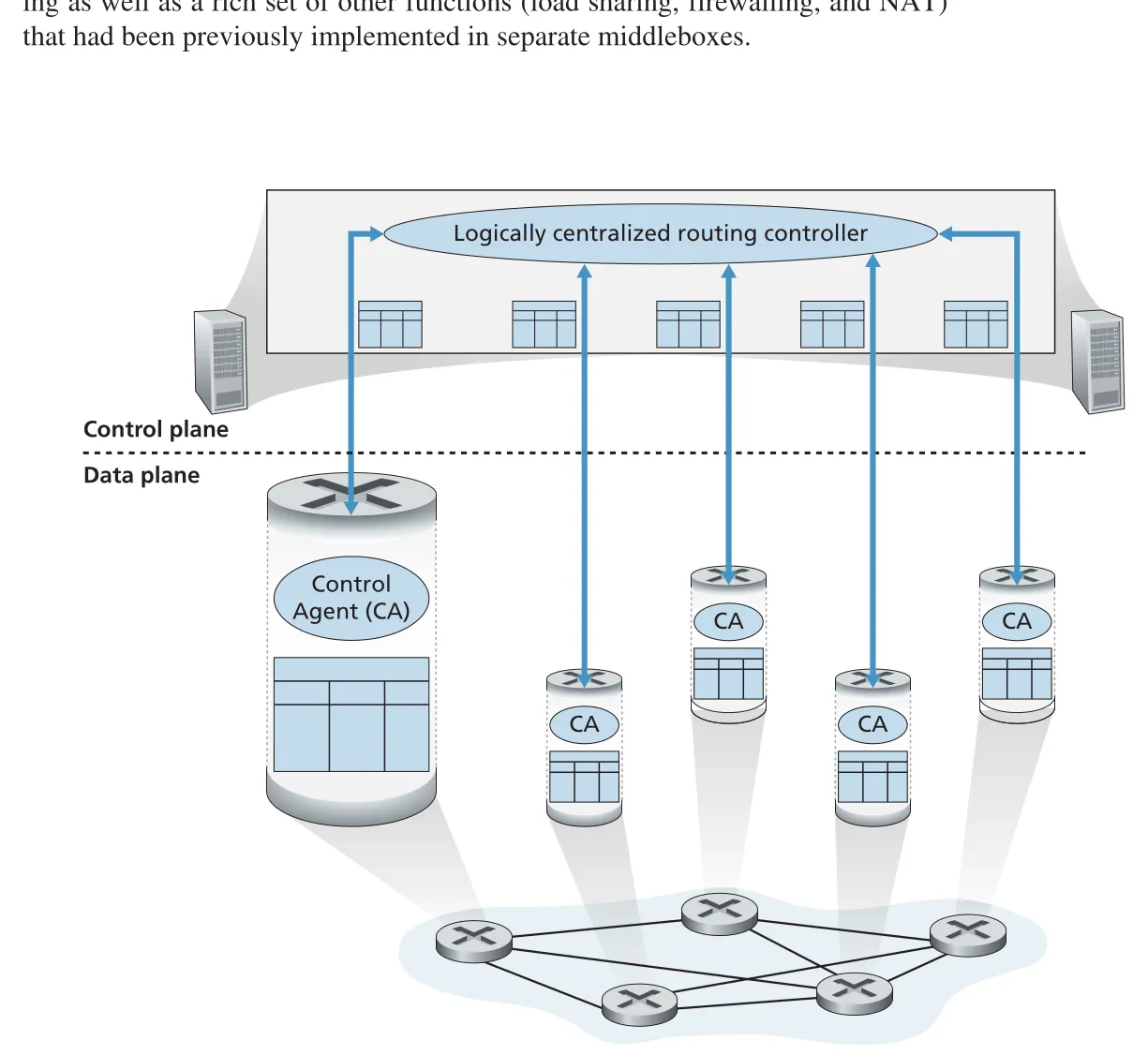 Figure 5.2 · PDF p. 390 · logically centralized controller가 각 router의 CA와 통신해 flow table을 관리한다
Figure 5.2 · PDF p. 390 · logically centralized controller가 각 router의 CA와 통신해 flow table을 관리한다
여기서 logically centralized는 실제 구현이 반드시 단일 서버라는 뜻이 아니다. 외부에서는 하나의 central service처럼 접근되지만, 내부적으로는 fault tolerance와 scalability를 위해 여러 servers로 구현될 수 있다. SDN controller도 이 의미에서 logically centralized다. 중요한 점은 “control decision의 논리적 관점이 중앙화되어 있다”는 것이지, 물리적으로 한 장비에 모든 것이 몰려 있다는 뜻이 아니다.
5.2 Routing Algorithms
routing algorithm의 목표는 senders에서 receivers까지 routers network를 통과하는 좋은 path, 즉 route를 결정하는 것이다. 일반적으로 좋은 path는 least-cost path지만, 실제 network에서는 policy도 개입한다. 예를 들어 “organization Y의 router x는 organization Z에서 온 packet을 forwarding하지 않는다” 같은 규칙은 순수 비용 최적화만으로 설명되지 않는다.
control plane이 per-router 방식이든 SDN 방식이든, packet이 실제로 따라갈 well-defined sequence of routers는 필요하다. 따라서 routing algorithm은 forwarding table을 채우기 전의 근본 계산 문제다.
routing 문제는 graph 로 모델링한다. N은 nodes의 집합, E는 edges의 집합이다. network-layer routing에서는 보통 node가 router이고, edge가 routers 사이의 physical link다. BGP 같은 inter-domain routing에서는 node가 network/AS를 뜻하고, edge는 networks 사이의 direct connectivity 또는 peering을 뜻할 수 있다.
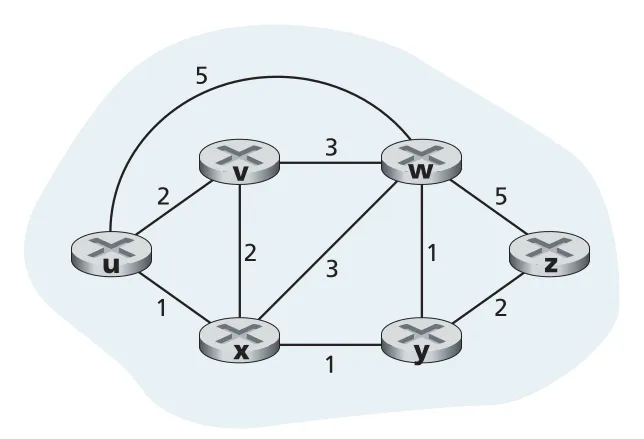 Figure 5.3 · PDF p. 392 · routers와 links를 nodes/edges로 추상화한 routing graph
Figure 5.3 · PDF p. 392 · routers와 links를 nodes/edges로 추상화한 routing graph
edge cost 는 link 길이, link speed, monetary cost 등으로 정할 수 있다. 가 edge가 아니면 로 본다. 이 장의 기본 설명은 undirected graph를 가정하지만, 알고리즘은 방향별 cost가 다른 directed links에도 확장할 수 있다. node y가 node x에 직접 연결되어 있으면 y는 x의 neighbor다.
path 의 cost는 경로 위 edge costs의 합이다. least-cost path는 가능한 paths 중 cost가 최소인 path다. 모든 edge cost가 같다면 least-cost path는 hop 수가 가장 작은 shortest path와 같다. 하지만 cost가 bandwidth, delay, policy weight 등을 반영하면 shortest path와 least-cost path는 달라진다.
routing algorithms는 세 축으로 분류할 수 있다.
| 분류 기준 | 선택지 | 의미와 trade-off |
|---|---|---|
| 정보 범위 | centralized vs decentralized | centralized는 전체 topology/link cost를 알고 계산한다. decentralized는 각 node가 neighbor와 정보를 교환하며 점진적으로 계산한다. |
| 변화 반응 | static vs dynamic | static은 사람이 link cost를 바꾸는 등 route 변화가 느리다. dynamic은 topology/load/cost 변화에 반응하지만 routing loop, route oscillation에 더 취약하다. |
| load 반영 | load-sensitive vs load-insensitive | load-sensitive는 congestion을 link cost에 반영해 우회하려 한다. 오늘날 RIP, OSPF, BGP는 current congestion을 직접 cost에 넣지 않는 load-insensitive 방식이다. |
centralized routing algorithm은 모든 nodes 간 connectivity와 모든 link costs를 입력으로 받아 least-cost path를 계산한다. 계산 자체는 한 controller에서 수행될 수도 있고, 모든 router가 동일한 global state를 받아 각자 수행할 수도 있다. 중요한 특징은 complete information이다. 이런 algorithm을 link-state (LS) algorithm이라고 부른다.
decentralized routing algorithm은 각 node가 처음에는 자기 directly attached links의 costs만 안다. 이후 neighbors와 정보를 반복 교환하면서 destinations까지의 cost estimates를 갱신한다. 이 장의 대표 decentralized algorithm은 distance-vector (DV) algorithm이다. 각 node가 다른 모든 nodes까지의 distance estimates vector를 유지하기 때문에 이런 이름이 붙었다.
세부 정리
5.2.1 The Link-State (LS) Routing Algorithm
link-state (LS) routing algorithm은 network topology와 모든 link costs가 알려져 있다는 전제에서 출발한다. 실제 protocol에서는 각 node가 자신의 attached links와 costs를 담은 link-state packets를 network 전체에 broadcast한다. 그 결과 모든 routers가 동일한 topology view를 갖고, 각 router가 locally 같은 algorithm을 실행해 least-cost paths를 계산한다.
이 장의 LS algorithm은 Dijkstra's algorithm이다. source node를 u라고 할 때, Dijkstra는 u에서 모든 destination nodes까지의 least-cost paths를 반복적으로 확정한다. 핵심 변수는 다음과 같다.
| 기호 | 의미 |
|---|---|
현재 iteration 기준 source u에서 destination v까지 알려진 least-cost estimate | |
현재 least-cost path에서 v 바로 앞에 오는 predecessor node | |
N' | source에서 least-cost path가 확정된 nodes의 집합 |
Dijkstra의 핵심 루프는 “아직 확정되지 않은 node 중 가 최소인 w를 골라 N'에 넣고, w의 neighbors에 대해 로 갱신”하는 것이다. k번째 iteration이 끝나면 k개의 destination nodes에 대한 least-cost paths가 확정된다. 종료 후 각 destination의 predecessor chain을 거꾸로 따라가면 full path를 복원할 수 있고, source router의 forwarding table에는 각 destination으로 가는 next-hop만 저장하면 된다.
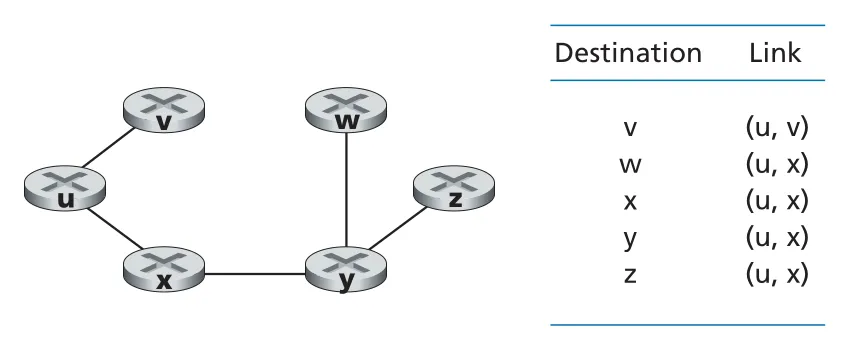 Figure 5.4 · PDF p. 397 · node u 기준 least-cost paths와 forwarding table의 next-hop 관계
Figure 5.4 · PDF p. 397 · node u 기준 least-cost paths와 forwarding table의 next-hop 관계
단순 구현에서 Dijkstra는 매 iteration마다 아직 확정되지 않은 nodes 중 minimum 를 찾아야 하므로 worst-case complexity가 다. heap 같은 자료구조를 사용하면 minimum search를 logarithmic time으로 줄일 수 있다. routing protocol 설명에서 중요한 포인트는 복잡도 자체보다 “global state를 수집한 뒤 각 router가 shortest-path tree를 계산한다”는 구조다.
LS algorithm의 주의점은 load-sensitive metric을 쓸 때 route oscillation이 생길 수 있다는 점이다. link cost가 그 link의 현재 traffic load나 delay를 반영하면, routers가 동시에 “혼잡한 곳을 피하자”고 판단하면서 traffic을 반대편으로 몰고, 다음 계산 때 다시 되돌리는 진동이 발생할 수 있다.
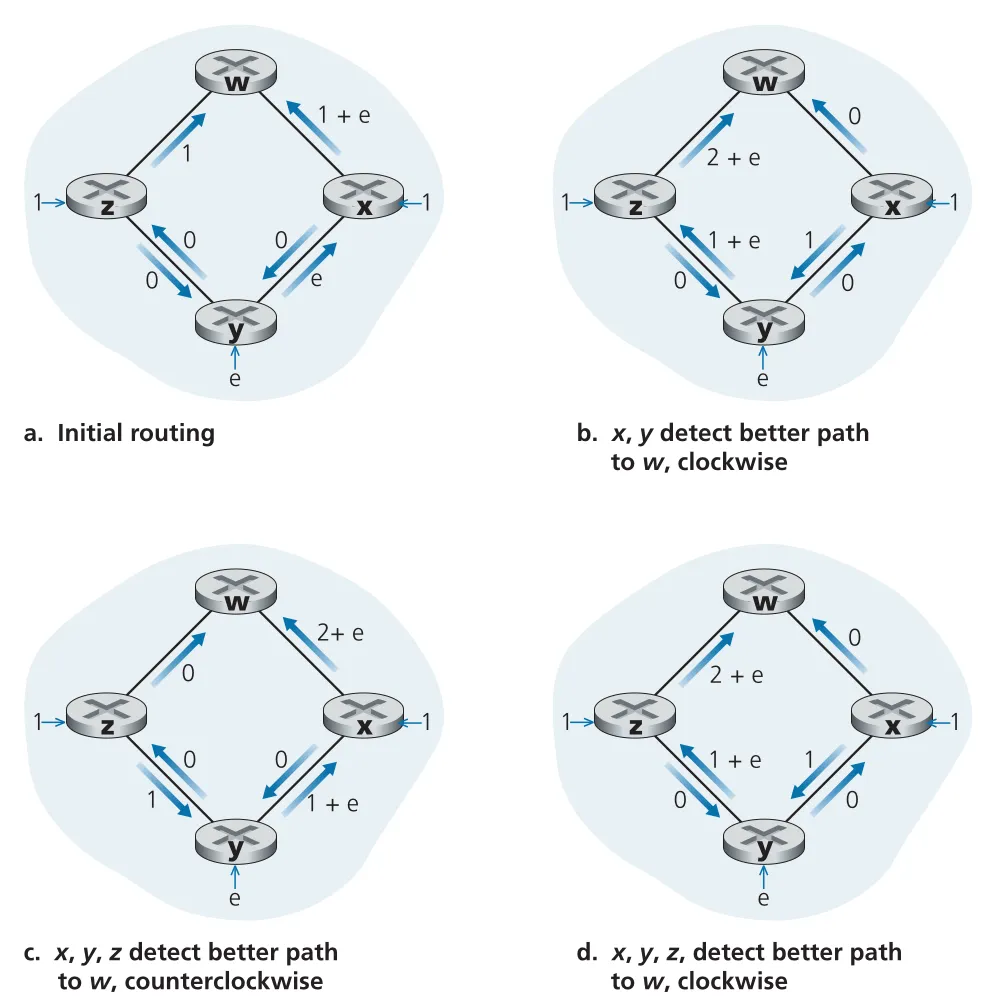 Figure 5.5 · PDF p. 398 · congestion-sensitive routing에서 traffic load와 route choice가 서로 밀어내며 oscillation을 만드는 예
Figure 5.5 · PDF p. 398 · congestion-sensitive routing에서 traffic load와 route choice가 서로 밀어내며 oscillation을 만드는 예
oscillation을 줄이는 방법 중 하나는 모든 routers가 LS algorithm을 동시에 실행하지 않게 만드는 것이다. 하지만 같은 period를 가진 routers가 시간이 지나며 self-synchronize될 수 있으므로, link advertisement 전송 시간을 randomize하는 방식이 필요할 수 있다. 이 때문에 실제 Internet의 OSPF/BGP 같은 algorithms는 current congestion을 link cost에 직접 넣지 않는 load-insensitive 성격을 갖는다.
5.2.2 The Distance-Vector (DV) Routing Algorithm
distance-vector (DV) routing algorithm은 LS와 반대로 global topology를 요구하지 않는다. DV는 iterative, asynchronous, distributed algorithm이다. 각 node는 directly attached neighbors로부터 일부 정보를 받고, 자기 계산을 수행한 뒤, 결과를 다시 neighbors에게 보낸다. 모든 node가 lockstep으로 동시에 움직일 필요도 없고, 더 이상 update가 없으면 자연스럽게 멈추는 self-terminating 구조다.
DV의 수학적 기반은 Bellman-Ford equation이다.
여기서 는 node x에서 destination y까지의 true least-cost path cost이고, v는 x의 neighbor다. 의미는 직관적이다. x에서 y로 가려면 첫 hop으로 어떤 neighbor v를 선택해야 하고, 그 뒤에는 v에서 y까지의 least-cost path를 따르면 된다. 따라서 x는 모든 neighbors v에 대해 를 비교하고, 그중 최소를 선택한다.
이 식은 forwarding table에도 바로 연결된다. minimum을 만드는 neighbor 가 destination y로 가는 next-hop이다. DV에서 각 node x는 , 즉 모든 destinations까지의 cost estimates vector를 유지한다. 또한 각 neighbor v로부터 받은 distance vector Dv를 저장한다.
DV update의 핵심은 다음과 같다.
node x는 직접 link cost가 바뀌거나 neighbor로부터 distance vector update를 받으면 위 식으로 자기 vector를 갱신한다. 자기 vector가 바뀌면 그 새 vector를 neighbors에게 보낸다. 충분히 update가 교환되면 각 는 실제 least-cost 로 수렴한다.
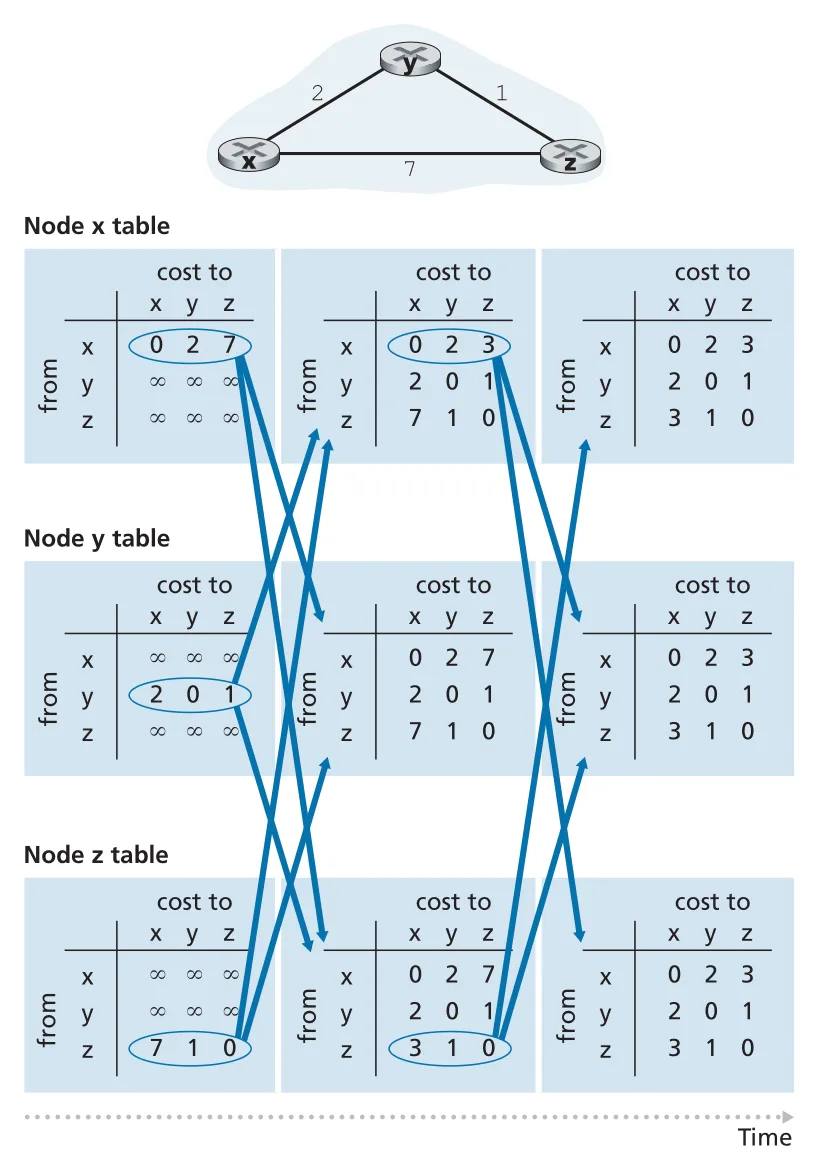 Figure 5.6 · PDF p. 402 · DV algorithm에서 neighbors의 vectors를 받아 distance table을 갱신하는 흐름
Figure 5.6 · PDF p. 402 · DV algorithm에서 neighbors의 vectors를 받아 distance table을 갱신하는 흐름
DV가 감소한 link cost를 전파할 때는 보통 빠르게 수렴한다. 예를 들어 y-x link cost가 4에서 1로 줄면, y가 자기 vector를 갱신해 z에게 알리고, z도 더 싼 path를 계산한 뒤 update하면 짧은 교환 뒤 quiescent state에 도달한다. 책은 이를 “good news travels fast”로 설명한다.
문제는 link cost 증가나 link failure다. y-x cost가 4에서 60으로 증가했는데 z가 예전 정보로 “나는 x까지 5로 갈 수 있다”고 y에게 알려 둔 상태라면, y는 z를 통해 x로 가는 cost 6을 믿고 z로 보낸다. 그런데 z도 y를 통해 x로 간다고 생각하면 y-z 사이에 routing loop가 생긴다. 이후 y와 z가 서로 더 큰 cost를 조금씩 주고받으며 수렴하는데, 이 현상이 count-to-infinity problem이다.
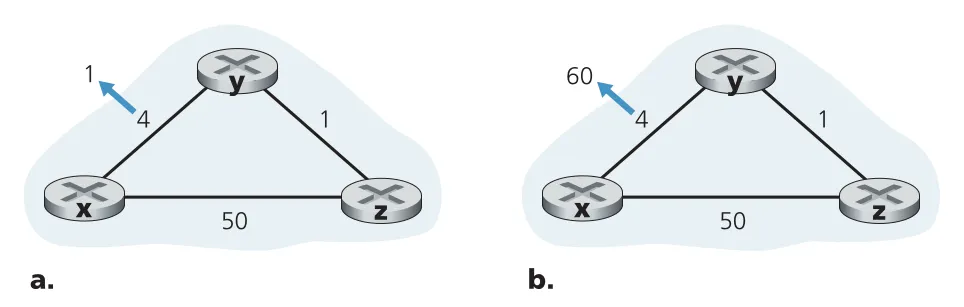 Figure 5.7 · PDF p. 404 · link cost 감소는 빠르게 전파되지만 cost 증가는 count-to-infinity를 만들 수 있다
Figure 5.7 · PDF p. 404 · link cost 감소는 빠르게 전파되지만 cost 증가는 count-to-infinity를 만들 수 있다
poisoned reverse는 인접한 두 node 사이의 특정 loop를 막기 위한 기법이다. z가 destination x로 가기 위해 y를 next-hop으로 쓰고 있다면, z는 y에게 “내가 x까지 가는 cost는 infinity”라고 광고한다. 즉 실제로는 y를 통해 x에 갈 수 있더라도, y가 다시 z를 통해 x로 우회하려는 잘못된 판단을 하지 않도록 reverse path를 poison한다. 다만 poisoned reverse는 2-node loop에는 효과적이지만, 세 개 이상의 nodes가 얽힌 loop까지 일반적으로 해결하지는 못한다.
LS와 DV의 비교는 다음처럼 정리할 수 있다.
| 항목 | Link-State (LS) | Distance-Vector (DV) |
|---|---|---|
| 필요한 정보 | 전체 topology와 모든 link costs | directly connected link costs와 neighbors의 distance vectors |
| message pattern | link-state information을 network 전체에 broadcast | directly connected neighbors끼리 vector 교환 |
| 계산 방식 | Dijkstra로 source 기준 shortest-path tree 계산 | Bellman-Ford update를 반복 |
| convergence | 계산 자체는 명확하지만 link-state dissemination 필요 | 느릴 수 있고 routing loop/count-to-infinity 가능 |
| robustness | 잘못된 link cost broadcast 영향은 해당 정보 중심 | 잘못된 distance estimate가 neighbors를 거쳐 network 전체로 확산 가능 |
어느 쪽도 절대적인 승자는 아니다. 둘 다 Internet에서 쓰인다. OSPF는 LS 계열이고, RIP와 BGP는 DV-like 성격을 갖는다. 핵심은 LS가 “전체 지도를 모두 갖고 각자 계산”하는 방식이고, DV가 “neighbors의 말만 듣고 추정치를 반복 개선”하는 방식이라는 차이다.
5.3 Intra-AS Routing in the Internet: OSPF
지금까지는 모든 routers가 같은 routing algorithm을 실행하는 하나의 homogeneous network처럼 보았지만, Internet 규모에서는 이 model이 성립하기 어렵다. 이유는 두 가지다.
첫째, scale 문제다. Internet 전체 routers가 서로의 routing information을 모두 저장하고, 모든 connectivity/link cost update를 broadcast하며, 하나의 거대한 DV algorithm을 수렴시키는 것은 현실적이지 않다. 둘째, administrative autonomy 문제다. Internet은 여러 ISPs와 organizations의 network들의 결합이고, 각 ISP는 자기 내부 routing algorithm, topology, policy를 외부에 드러내지 않고 독립적으로 운영하고 싶어 한다.
이를 해결하는 단위가 autonomous system (AS)이다. AS는 같은 administrative control 아래 있는 routers의 집합이며, globally unique autonomous system number (ASN)으로 식별된다. 같은 AS 내부 routers는 같은 intra-autonomous system routing protocol, 줄여서 intra-AS routing protocol을 실행한다.
OSPF (Open Shortest Path First)는 Internet에서 널리 쓰이는 intra-AS routing protocol이다. 이름의 Open은 protocol specification이 공개되어 있음을 뜻한다. OSPF와 비슷한 intra-AS LS protocol로 IS-IS도 자주 함께 언급된다.
OSPF의 핵심은 LS + Dijkstra다. 각 OSPF router는 AS 전체에 대한 complete topological map, 즉 graph를 만들고, 자기 자신을 root로 하는 shortest-path tree를 Dijkstra’s algorithm으로 계산한다. 그 결과 각 subnet으로 가는 next-hop이 forwarding table에 들어간다.
OSPF에서 link weights는 protocol이 자동으로 정해 주지 않는다. network administrator가 설정한다. 모든 link cost를 1로 두면 minimum-hop routing이 되고, link capacity에 반비례하게 두면 low-bandwidth links를 덜 선호하게 만들 수 있다. 더 현실적으로는 operator가 원하는 traffic engineering 목표, 예를 들어 maximum link utilization 최소화를 달성하도록 OSPF weights를 조정한다. 즉 “weights가 routing을 결정한다”는 원리뿐 아니라, 운영에서는 “원하는 routing을 만들기 위해 weights를 설계한다”는 역방향 사고도 중요하다.
OSPF message의 주요 특징은 다음과 같다.
| 항목 | 의미 |
|---|---|
| link-state flooding | router가 neighbor뿐 아니라 AS 내부 모든 routers에게 link-state information을 전파 |
| update trigger | link cost 변화, link up/down 변화가 있을 때 advertisement |
| periodic refresh | 변화가 없어도 적어도 30분마다 link-state advertisement를 재전송해 robustness 확보 |
| IP protocol number | OSPF messages는 IP 위에 직접 실리며 upper-layer protocol number는 89 |
| reliability responsibility | TCP/UDP에 기대지 않으므로 OSPF 자체가 reliable message transfer와 link-state broadcast 기능을 구현 |
| HELLO message | attached neighbor와 link가 operational한지 확인하고 neighbor의 link-state database를 얻는 데 사용 |
OSPF는 단순 LS algorithm 이상의 운영 기능을 포함한다.
| OSPF 기능 | 핵심 의미 |
|---|---|
| authentication/security | OSPF packets를 인증해 AS 내부 trusted routers만 routing information을 주입하게 함. simple authentication은 plaintext password라 약하고, MD5 authentication은 shared secret key와 hash, sequence number로 authenticity와 replay protection을 제공 |
| multiple same-cost paths | 같은 cost의 paths가 여러 개면 하나만 고르지 않고 여러 paths를 사용할 수 있음. Equal-cost multipath 성격 |
| unicast/multicast integration | MOSPF가 기존 OSPF link database와 advertisement mechanism을 확장해 multicast routing 지원 |
| hierarchy within AS | AS를 여러 area로 나누고, 각 area가 자체 LS routing을 수행하며, backbone area가 areas 사이 traffic을 운반 |
OSPF hierarchy는 한 AS 내부에서도 scale을 줄이기 위한 구조다.
Area 내부 router
-> area border router
-> backbone area
-> destination area의 area border router
-> destination area 내부 목적지각 area는 자기 내부에서만 link-state flooding을 수행한다. area border router는 area 밖으로 나가는 packets를 담당한다. AS 안에는 정확히 하나의 backbone area가 있고, backbone은 모든 area border routers를 포함한다. inter-area routing은 먼저 source area 내부 routing으로 area border router까지 가고, backbone을 거쳐 destination area의 border router로 이동한 뒤, 다시 destination area 내부 routing으로 최종 destination에 도달한다.
5.4 Routing Among the ISPs: BGP
BGP (Border Gateway Protocol)는 Internet의 inter-AS routing protocol이다. 같은 AS 내부 destination으로 가는 forwarding table entries는 OSPF 같은 intra-AS protocol이 결정하지만, destination이 다른 AS에 있으면 BGP가 필요하다. Internet의 모든 AS가 같은 inter-AS protocol인 BGP를 실행하기 때문에, BGP는 수많은 ISPs를 하나의 Internet으로 묶는 핵심 glue다.
BGP는 DV와 닮은 decentralized/asynchronous protocol이지만, pure least-cost routing이 아니다. Internet AS 사이에서는 performance보다 policy와 business relationship이 강하게 작동한다. 따라서 BGP를 이해할 때는 “shortest path protocol”이 아니라 “prefix reachability와 policy-aware route selection을 전파하는 protocol”로 보아야 한다.
5.4.1 The Role of BGP
BGP에서 destination은 하나의 host address가 아니라 CIDRized prefix다. 예를 들어 138.16.68/22 같은 prefix는 여러 IP addresses를 대표한다. router forwarding table의 BGP 관련 entry는 대략 (prefix x, interface I) 형태다.
BGP가 각 router에게 제공하는 기능은 두 가지다.
| BGP 기능 | 의미 |
|---|---|
| prefix reachability information 획득 | 어떤 prefix가 어디에 존재하고, 어떤 AS path를 통해 도달 가능한지 neighboring ASs로부터 학습 |
| best route 결정 | 같은 prefix에 여러 routes가 있을 때 policy와 reachability attributes를 고려해 route-selection procedure 실행 |
즉 BGP는 어떤 subnet이 “I exist and I am here”라고 Internet에 알릴 수 있게 하고, routers가 그 prefix로 갈 route를 고르게 한다. BGP가 없다면 각 subnet은 전 세계 routers에게 알려지지 않은 고립된 섬이 된다.
5.4.2 Advertising BGP Route Information
BGP advertisement는 AS 전체가 추상적으로 말하는 것이 아니라, routers 사이의 BGP sessions를 통해 전달된다. AS edge에서 다른 AS router와 직접 연결된 router를 gateway router라 하고, AS 내부 host/router에만 연결된 router를 internal router라 한다.
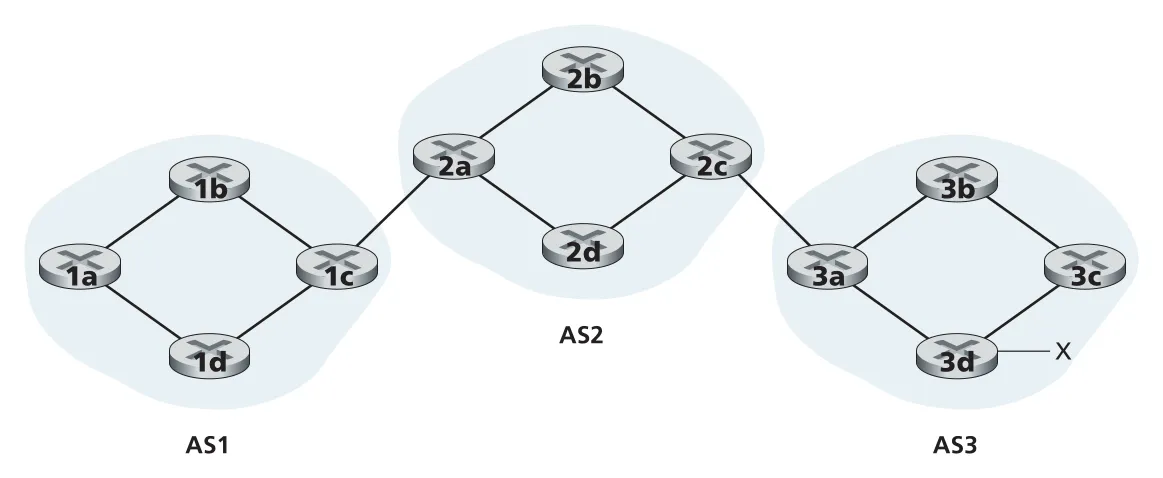 Figure 5.8 · PDF p. 412 · AS3의 prefix x를 AS2와 AS1로 광고하는 기본 BGP 예
Figure 5.8 · PDF p. 412 · AS3의 prefix x를 AS2와 AS1로 광고하는 기본 BGP 예
예를 들어 AS3에 prefix x가 있으면, AS3는 AS2에게 “AS3 x”라는 reachability를 알린다. AS2는 AS1에게 “AS2 AS3 x”라고 광고한다. 이때 AS1은 x의 존재뿐 아니라 x로 가려면 AS2와 AS3를 차례로 지나야 한다는 AS-level path도 배운다.
BGP routers는 semi-permanent TCP connection으로 routing information을 교환하며, BGP는 TCP port 179를 사용한다. 이 TCP connection과 그 위의 BGP messages를 BGP connection이라고 한다. 두 AS 사이 gateway routers를 잇는 BGP connection은 external BGP (eBGP)이고, 같은 AS 내부 routers 사이의 BGP session은 internal BGP (iBGP)다.
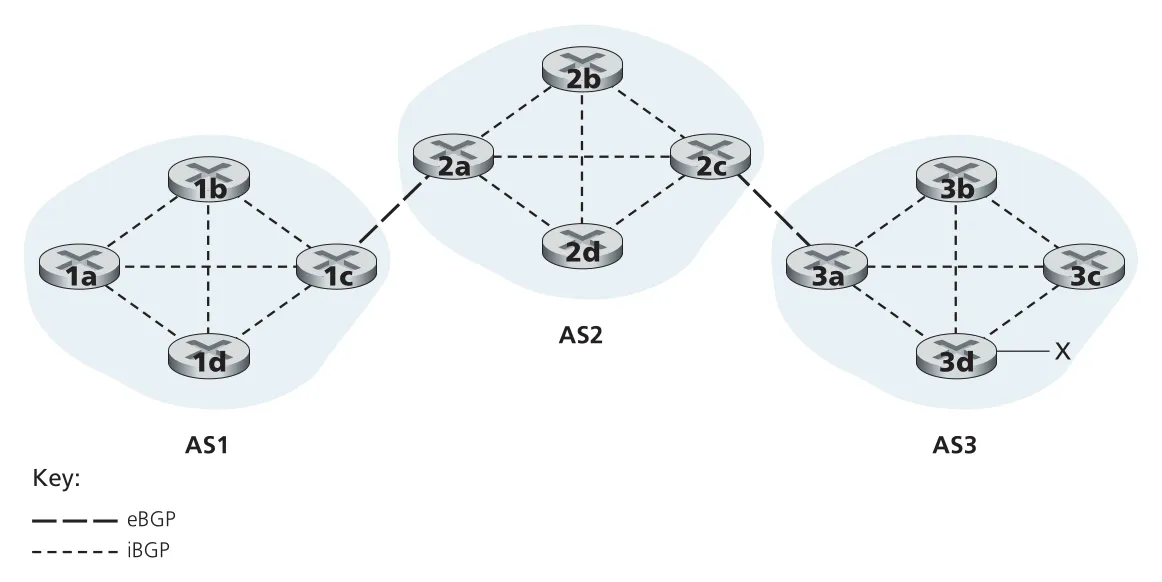 Figure 5.9 · PDF p. 413 · AS 사이 eBGP와 AS 내부 iBGP sessions가 prefix reachability를 전파한다
Figure 5.9 · PDF p. 413 · AS 사이 eBGP와 AS 내부 iBGP sessions가 prefix reachability를 전파한다
prefix x가 AS3에서 AS1 전체로 전파되는 흐름은 다음과 같다.
AS3 gateway 3a
--eBGP: "AS3 x"-->
AS2 gateway 2c
--iBGP: "AS3 x"-->
AS2 내부 routers와 gateway 2a
--eBGP: "AS2 AS3 x"-->
AS1 gateway 1c
--iBGP: "AS2 AS3 x"-->
AS1 내부 routerseBGP는 AS boundary를 넘는 advertisement를 담당하고, iBGP는 AS 내부 routers에게 그 external reachability를 퍼뜨린다. iBGP connections는 반드시 physical link와 일치할 필요가 없고, 같은 AS 내부 routers 사이에 TCP sessions mesh로 구성될 수 있다.
5.4.3 Determining the Best Routes
한 router는 같은 prefix에 대해 여러 BGP routes를 받을 수 있다. route를 고르려면 BGP attributes를 이해해야 한다. BGP에서 route는 prefix와 attributes의 묶음이다. 대표 attributes는 AS-PATH와 NEXT-HOP이다.
| Attribute | 의미 | 핵심 사용 |
|---|---|---|
AS-PATH | advertisement가 지나온 ASNs의 list | route length 비교, loop detection |
NEXT-HOP | AS-PATH가 시작되는 router interface의 IP address | inter-AS route와 intra-AS path를 연결 |
local preference | AS 내부 policy로 정하는 preference 값 | BGP route selection에서 가장 먼저 적용 |
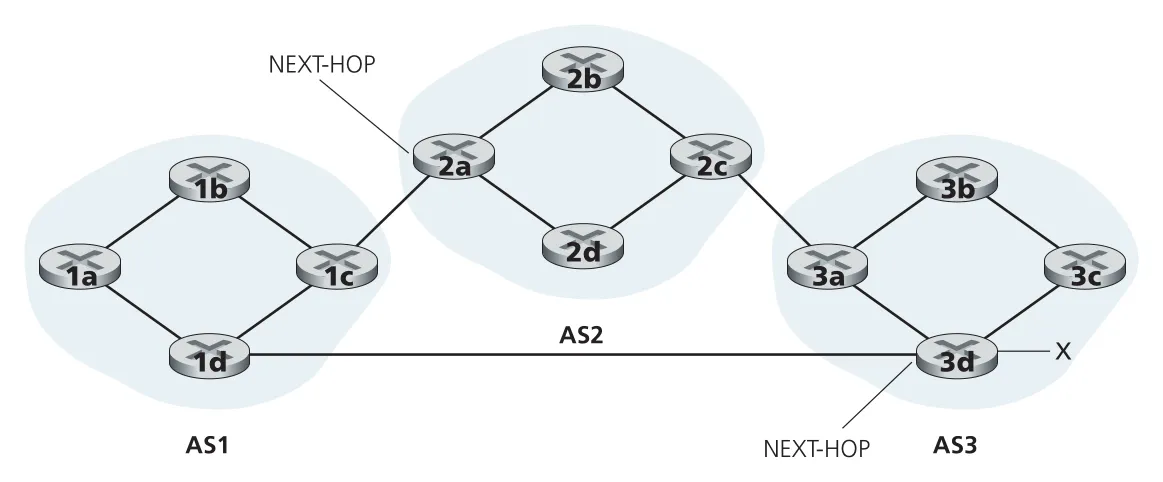 Figure 5.10 · PDF p. 414 · AS1이 prefix x로 가는 두 BGP routes와 서로 다른 NEXT-HOP을 배우는 상황
Figure 5.10 · PDF p. 414 · AS1이 prefix x로 가는 두 BGP routes와 서로 다른 NEXT-HOP을 배우는 상황
AS-PATH는 route advertisement가 AS를 통과할 때마다 해당 AS가 자기 ASN을 앞에 붙여 만든다. router가 advertisement에서 자기 AS를 발견하면 loop를 막기 위해 그 advertisement를 reject한다.
NEXT-HOP은 inter-AS와 intra-AS routing을 연결하는 중요한 bridge다. AS1 내부 router가 prefix x에 대해 (NEXT-HOP=2a interface, AS-PATH=AS2 AS3, x)와 (NEXT-HOP=3d interface, AS-PATH=AS3, x) 두 routes를 배웠다고 하자. BGP는 어느 external gateway로 나갈지를 결정하지만, AS 내부에서 그 NEXT-HOP까지 가는 구체적인 router path는 OSPF 같은 intra-AS protocol이 계산한 forwarding table을 사용한다.
hot potato routing은 가능한 routes 중 NEXT-HOP router까지의 intra-AS cost가 가장 작은 route를 고르는 방식이다. 목표는 packet을 자기 AS 밖으로 가능한 빨리 던지는 것이다. 그래서 end-to-end cost를 보지 않고 자기 AS 내부 cost만 최소화하는 selfish algorithm 성격이 있다. 같은 AS 내부의 서로 다른 routers가 같은 prefix에 대해 서로 다른 AS paths를 선택할 수도 있다.
 Figure 5.11 · PDF p. 415 · 외부 prefix를 forwarding table에 넣을 때 BGP와 intra-AS routing이 함께 쓰이는 단계
Figure 5.11 · PDF p. 415 · 외부 prefix를 forwarding table에 넣을 때 BGP와 intra-AS routing이 함께 쓰이는 단계
실제 BGP route-selection algorithm은 hot potato만 쓰지 않는다. 같은 prefix에 대해 여러 accepted routes가 있으면 대략 다음 순서로 elimination한다.
| 순서 | Rule | 의미 |
|---|---|---|
| 1 | highest local preference | AS administrator가 정한 policy가 최우선 |
| 2 | shortest AS-PATH | AS hop count가 작은 route 선호 |
| 3 | closest NEXT-HOP | 남은 routes 중 hot potato routing 적용 |
| 4 | BGP identifier | 그래도 여러 개면 tie-breaker 사용 |
이 순서가 중요하다. local preference가 가장 먼저이므로 policy가 shortest AS-PATH나 hot potato보다 우선한다. shortest AS-PATH rule이 hot potato보다 먼저 적용되면, 자기 AS 밖으로 빨리 내보내는 route보다 AS-level path가 더 짧은 route를 고를 수 있다.
5.4.4 IP-Anycast
IP-anycast는 여러 지리적 위치에 같은 service를 복제해 두고, 사용자를 BGP 관점에서 가까운 instance로 보내는 기법이다. CDN이나 DNS처럼 같은 content/record를 여러 locations에 복제하는 경우가 대표적이다.
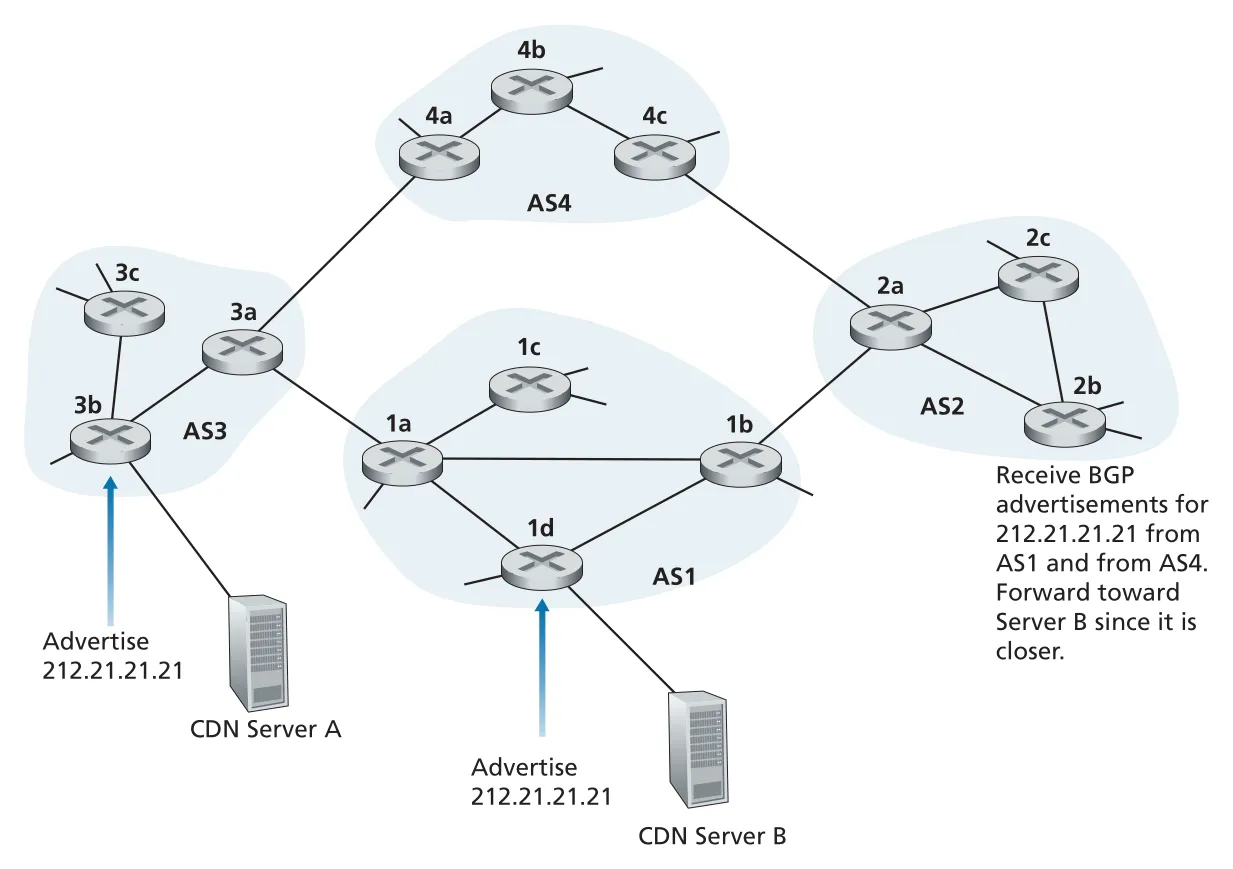 Figure 5.12 · PDF p. 418 · 여러 locations가 같은 IP address를 BGP로 광고하고 사용자를 가까운 server로 유도하는 IP-anycast
Figure 5.12 · PDF p. 418 · 여러 locations가 같은 IP address를 BGP로 광고하고 사용자를 가까운 server로 유도하는 IP-anycast
configuration 단계에서 service provider는 여러 servers에 같은 IP address를 부여하고, 각 location에서 그 IP address를 BGP로 광고한다. Internet routers는 이를 “같은 IP prefix로 가는 여러 paths”로 보고 자기 BGP route-selection algorithm에 따라 best path를 고른다. 이후 client가 그 common IP address로 packet을 보내면, routers는 BGP가 고른 “가까운” location으로 packet을 forward한다.
CDN 예시는 개념을 보여 주기 좋지만, 실제 CDNs는 TCP connection의 서로 다른 packets가 BGP 변화 때문에 다른 server instance로 가는 문제를 피하려고 IP-anycast를 항상 선호하지는 않는다. 반면 DNS root servers는 IP-anycast를 널리 사용한다. 13개의 root DNS IP addresses 각각 뒤에는 여러 물리적 DNS root servers가 있고, query는 anycast로 가까운 instance에 전달된다.
5.4.5 Routing Policy
BGP에서는 routing policy가 route selection을 압도할 수 있다. route-selection algorithm의 첫 단계가 local preference인 이유가 여기에 있다. policy는 “어떤 traffic을 carry할 것인가”, “어떤 neighbor에게 어떤 routes를 advertise할 것인가”를 결정한다.
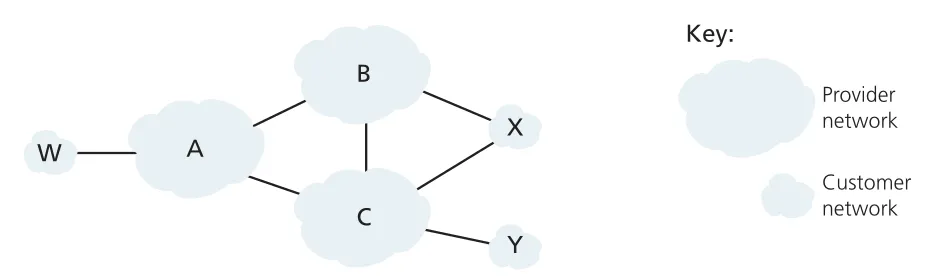 Figure 5.13 · PDF p. 419 · provider/customer 관계에서 selective route advertisement로 transit traffic을 제어하는 BGP policy 예
Figure 5.13 · PDF p. 419 · provider/customer 관계에서 selective route advertisement로 transit traffic을 제어하는 BGP policy 예
access ISP나 customer network는 자기 network가 source 또는 destination인 traffic만 처리하고, 다른 provider들 사이의 transit traffic을 대신 운반하지 않으려 한다. multi-homed access ISP X가 provider B와 C에 모두 연결되어 있더라도, X가 “나는 나 자신 외의 destination으로 가는 path가 없다”고 광고하면 B나 C는 X를 통해 다른 AS로 traffic을 보내지 않는다. 이것이 selective route advertisement로 stub network behavior를 구현하는 방식이다.
provider network도 비슷한 경제적 이유로 transit을 제한한다. AS B가 AS A를 통해 W로 가는 path AW를 배웠다고 해서, 이를 provider peer인 C에게 무조건 광고하면 C의 traffic이 B backbone을 공짜로 통과할 수 있다. 상업적 ISP의 기본 원칙은 자기 backbone을 지나는 traffic의 source 또는 destination 중 적어도 하나가 자기 customer network여야 한다는 것이다. 이런 policy 때문에 inter-AS routing에서는 pure performance metric보다 business relationship이 더 중요해질 수 있다.
inter-AS와 intra-AS routing protocol이 다른 이유도 여기서 정리된다.
| 기준 | inter-AS routing, BGP | intra-AS routing, OSPF 등 |
|---|---|---|
| policy | AS 간 business/policy가 지배적 | 하나의 administrative control 아래라 상대적으로 덜 중요 |
| scale | Internet 전체 prefixes/ASs를 다뤄야 함 | 한 AS 내부로 범위 제한, 필요하면 areas로 분할 |
| performance | policy를 만족하는 route가 우선이라 성능은 종종 secondary | link weights를 통해 performance-oriented routing 가능 |
5.4.6 Putting the Pieces Together: Obtaining Internet Presence
작은 회사가 public Web server, mail server, DNS server를 Internet에 공개하려면 여러 장의 개념이 합쳐진다. 먼저 local ISP와 계약해 physical connectivity와 IP address range, 예를 들어 /24 prefix를 받는다. 회사는 그 address range에서 Web server, mail server, DNS server, gateway router에 IP addresses를 할당한다.
다음으로 registrar를 통해 domain name을 얻고, registrar에게 회사 DNS server의 IP address를 알려 top-level-domain servers에 delegation 정보가 들어가게 한다. 회사 DNS server에는 www.example.com -> Web server IP, mail server hostname -> mail server IP 같은 records를 넣는다. 그러면 외부 사용자는 DNS를 통해 server IP address를 얻을 수 있다.
마지막으로 전 세계 routers가 회사 prefix의 존재를 알아야 한다. 이것이 BGP의 역할이다. local ISP는 회사의 prefix를 BGP로 자기 upstream ISPs에 advertise하고, 그 ISPs가 다시 propagate한다. 결국 Internet routers는 회사 prefix 또는 그 prefix를 포함하는 aggregate에 대한 forwarding table entry를 갖게 되어, TCP SYN 같은 IP datagram이 회사 Web/mail servers까지 도달할 수 있다.
5.5 The SDN Control Plane
SDN control plane은 SDN-enabled devices 사이의 packet forwarding, device configuration, service management를 network-wide logic으로 제어한다. SDN 문맥에서는 forwarding devices를 흔히 packet switches 또는 switches라고 부른다. 이 switches는 network-layer source/destination addresses뿐 아니라 link-layer, transport-layer header fields 등 다양한 fields를 기준으로 forwarding decision을 내릴 수 있다.
SDN architecture의 네 가지 특징은 다음과 같다.
| SDN 특징 | 의미 |
|---|---|
flow-based forwarding | destination IP address 하나가 아니라 L2/L3/L4 header fields 조합으로 match/action forwarding 수행 |
| data/control plane separation | switches는 fast data plane, controller/applications는 software control plane 담당 |
| external control functions | control software가 switches 내부가 아니라 remote servers에서 실행 |
| programmable network | network-control applications가 controller APIs로 forwarding, access control, load balancing 등을 program |
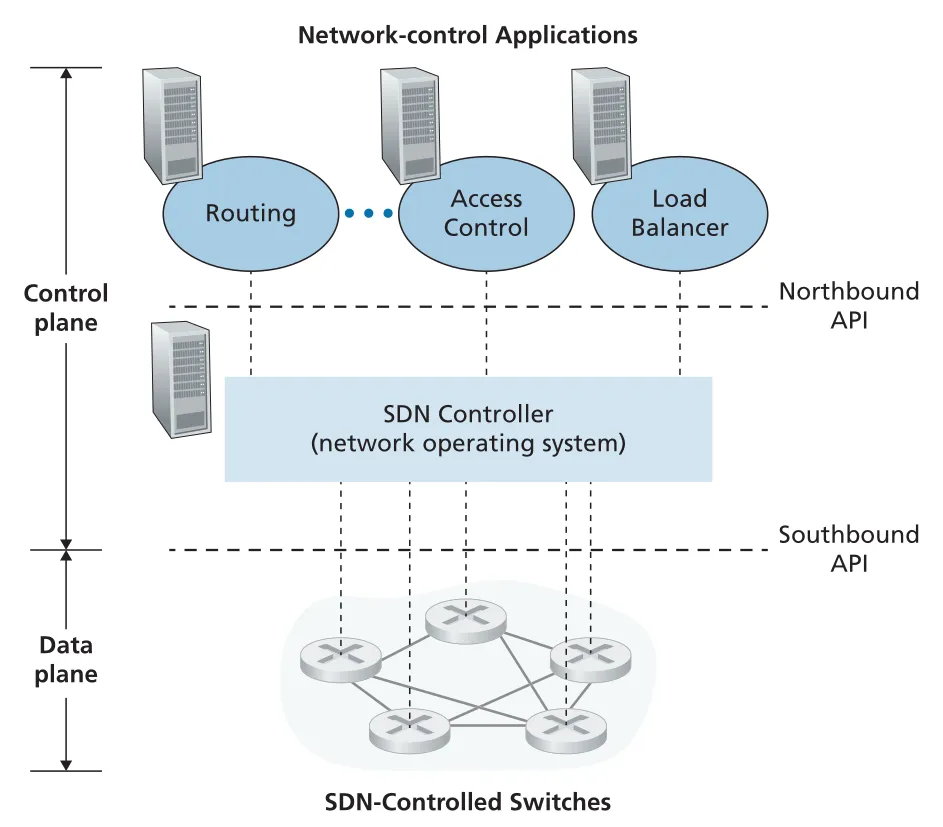 Figure 5.14 · PDF p. 424 · SDN-controlled switches, SDN controller, network-control applications의 계층 구조
Figure 5.14 · PDF p. 424 · SDN-controlled switches, SDN controller, network-control applications의 계층 구조
SDN은 network functionality의 unbundling이다. 기존 router/switch는 forwarding hardware, control-plane software, routing protocol implementation이 한 vendor의 vertically integrated product로 묶여 있었다. SDN에서는 data-plane switches, SDN controller, network-control applications가 분리되며, 서로 다른 vendors/organizations가 각각 제공할 수 있다. 이 분리는 routing, access control, firewalling, load balancing 같은 functions를 software applications로 바꾸어 더 빠르게 실험하고 배포하게 만든다.
5.5.1 The SDN Control Plane: Controller and Applications
SDN control plane은 크게 SDN controller와 SDN network-control applications로 나뉜다. controller는 단일 중앙 서버처럼 보이지만, 실제로는 fault tolerance, high availability, performance를 위해 distributed servers로 구현되는 경우가 많다. 따라서 logically centralized이면서 physically distributed인 구조다.
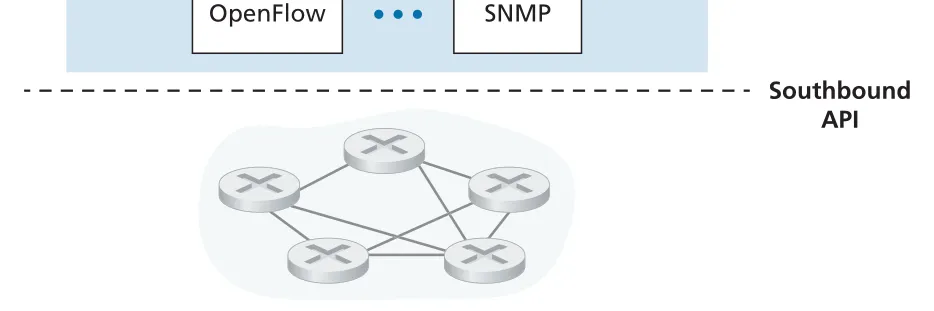 Figure 5.15 · PDF p. 426 · communication, state management, northbound API로 나뉘는 SDN controller 구성
Figure 5.15 · PDF p. 426 · communication, state management, northbound API로 나뉘는 SDN controller 구성
controller 기능은 세 layers로 정리할 수 있다.
| Controller layer | 역할 |
|---|---|
| communication layer | SDN controller와 controlled switches/devices 사이 communication. switch는 link up/down, device join, heartbeat 같은 locally observed events를 controller에 알림 |
| network-wide state-management layer | links, switches, hosts, counters, flow tables 같은 network state를 유지. applications가 최신 network view를 기반으로 decision하도록 함 |
| interface to network-control applications | northbound API를 통해 applications가 state/flow tables를 읽고 쓰며, state-change events에 subscription 가능 |
controller와 devices 사이 interface는 southbound interface라고 부른다. OpenFlow는 대표적인 southbound protocol이다. 반대로 applications가 controller에 접근하는 interface는 northbound interface다. REST-style API, intent API 등이 여기에 속한다. SDN의 추상화에서 중요한 점은 applications가 low-level switches를 직접 만지는 것이 아니라, controller가 제공하는 state와 API를 통해 network behavior를 지정한다는 점이다.
5.5.2 OpenFlow Protocol
OpenFlow protocol은 SDN controller와 OpenFlow API를 구현한 SDN-controlled switch/device 사이에서 동작한다. Chapter 4에서 본 OpenFlow match/action table을 controller가 관리하려면, controller와 switch 사이에 table 조회, 수정, event 통지가 필요하다. OpenFlow는 TCP 위에서 동작하고 default port number는 6653이다.
OpenFlow message는 방향별로 역할이 다르다.
| 방향 | Message | 의미 |
|---|---|---|
| controller -> switch | Configuration | switch configuration parameters를 query/set |
| controller -> switch | Modify-State | flow table entries를 add/delete/modify하고 switch port properties 설정 |
| controller -> switch | Read-State | flow table/ports의 statistics와 counter values 수집 |
| controller -> switch | Send-Packet | controller가 payload에 담은 특정 packet을 switch의 지정 port로 내보내게 함 |
| switch -> controller | Flow-Removed | timeout 또는 modify-state 결과로 flow entry가 제거되었음을 알림 |
| switch -> controller | Port-status | port status 변화, 예를 들어 link up/down을 알림 |
| switch -> controller | Packet-in | flow table miss 또는 matched action에 따라 packet을 controller로 보냄 |
OpenFlow의 의미는 “routing algorithm 자체”가 아니라 “controller가 switches의 flow table을 program하고, switches가 events/statistics를 controller로 보고하는 communication mechanism”이다. Google B4 같은 사례는 SDN/OpenFlow가 traffic engineering과 WAN utilization 개선에 쓰일 수 있음을 보여 주지만, 시험/개념상 핵심은 controller-device protocol과 flow table management다.
5.5.3 Data and Control Plane Interaction: An Example
SDN에서 link-state routing을 구현하면 traditional OSPF와 구조가 달라진다. Dijkstra’s algorithm은 switches 안에서 실행되지 않고, controller 위의 network-control application으로 실행된다. switches는 link-state updates를 서로 flooding하지 않고 controller에게 보낸다.
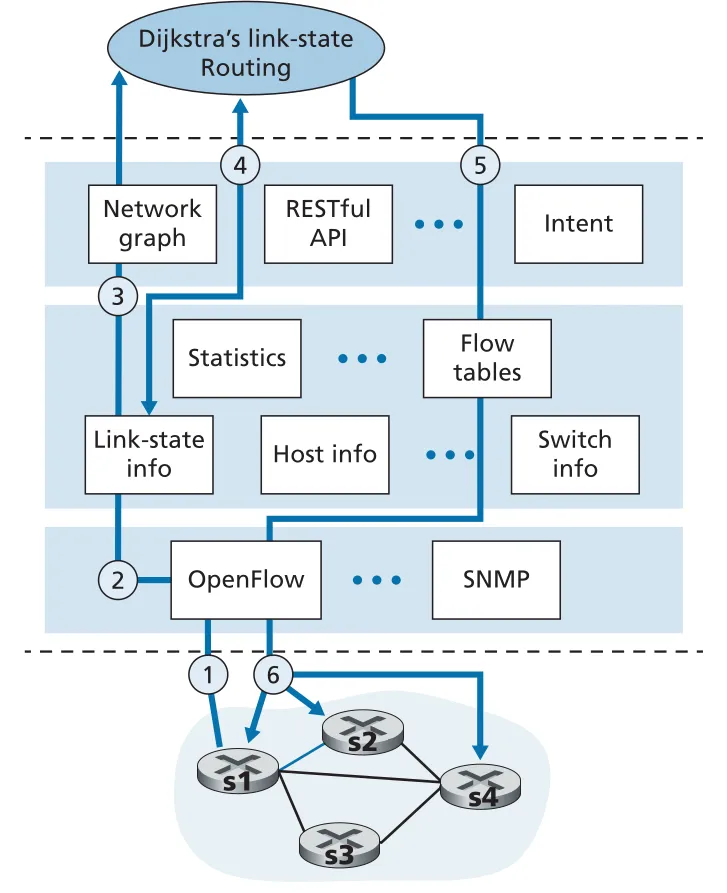 Figure 5.16 · PDF p. 429 · SDN controller에서 link-state change가 routing application과 flow table update로 이어지는 흐름
Figure 5.16 · PDF p. 429 · SDN controller에서 link-state change가 routing application과 flow table update로 이어지는 흐름
link s1-s2가 down된 상황에서 SDN control plane은 다음 흐름으로 동작한다.
1. switch s1 detects link failure
2. s1 -> controller: OpenFlow Port-status
3. controller updates link-state database
4. registered Dijkstra routing application receives event
5. application reads updated network state and computes new least-cost paths
6. flow table manager determines affected flow entries
7. controller -> affected switches: OpenFlow Modify-State이 예시는 SDN의 장점을 잘 보여 준다. 기존 per-router control에서는 모든 routers의 routing software가 link-state protocol을 실행해야 한다. SDN에서는 routing policy를 바꾸고 싶을 때 switches의 embedded routing software를 바꾸는 대신 controller 위의 application-control software를 바꾸면 된다. 따라서 least-cost routing에서 traffic engineering, load balancing, firewalling 같은 더 맞춤화된 forwarding behavior로 비교적 쉽게 이동할 수 있다.
5.5.4 SDN: Past and Future
SDN의 핵심 아이디어는 data plane과 control plane의 분리, simple flow-based switches, centralized controller, programmable match-plus-action flow tables다. Ethane project가 flow-based Ethernet switches와 centralized controller, unmatched packets의 controller forwarding 같은 아이디어를 운영 network로 보여 주었고, 이는 OpenFlow로 이어졌다.
향후 SDN의 확장은 두 방향으로 이해하면 충분하다. 하나는 dedicated monolithic switches/routers를 commodity switching hardware와 software control plane으로 대체하는 흐름이다. 다른 하나는 NFV (Network Functions Virtualization)처럼 기존 middleboxes 기능을 commodity servers, switching, storage 위의 software functions로 옮기는 흐름이다. SDN concepts를 intra-AS를 넘어 inter-AS control에도 확장하려는 연구도 있다.
OpenDaylight와 ONOS 같은 controllers는 구현 세부를 외울 대상이라기보다, controller가 northbound APIs, state-management core, southbound protocol plugins를 통해 logically centralized service를 제공한다는 사례로 이해하면 된다. 특히 YANG, NETCONF, SNMP, OVSDB 같은 management/configuration protocols가 SDN controller 생태계와도 연결된다는 점은 Section 5.7로 이어진다.
5.6 ICMP: The Internet Control Message Protocol
ICMP (Internet Control Message Protocol)는 hosts와 routers가 network-layer information을 서로 알리기 위해 사용한다. 가장 대표적인 용도는 error reporting이다. 예를 들어 router가 destination host로 가는 path를 찾지 못하면 source host에게 “destination network unreachable” 같은 ICMP error message를 보낼 수 있다.
ICMP는 흔히 IP의 일부처럼 취급되지만, 구조적으로는 IP 바로 위에 있다. ICMP messages는 TCP/UDP segments처럼 IP datagram payload로 실린다. IP datagram의 upper-layer protocol number가 1이면 receiver는 payload를 ICMP로 demultiplex한다.
ICMP message는 type과 code field를 갖고, error를 발생시킨 원래 IP datagram의 header와 처음 8 bytes를 포함한다. 이렇게 해야 sender가 어떤 datagram 때문에 error가 발생했는지 식별할 수 있다.
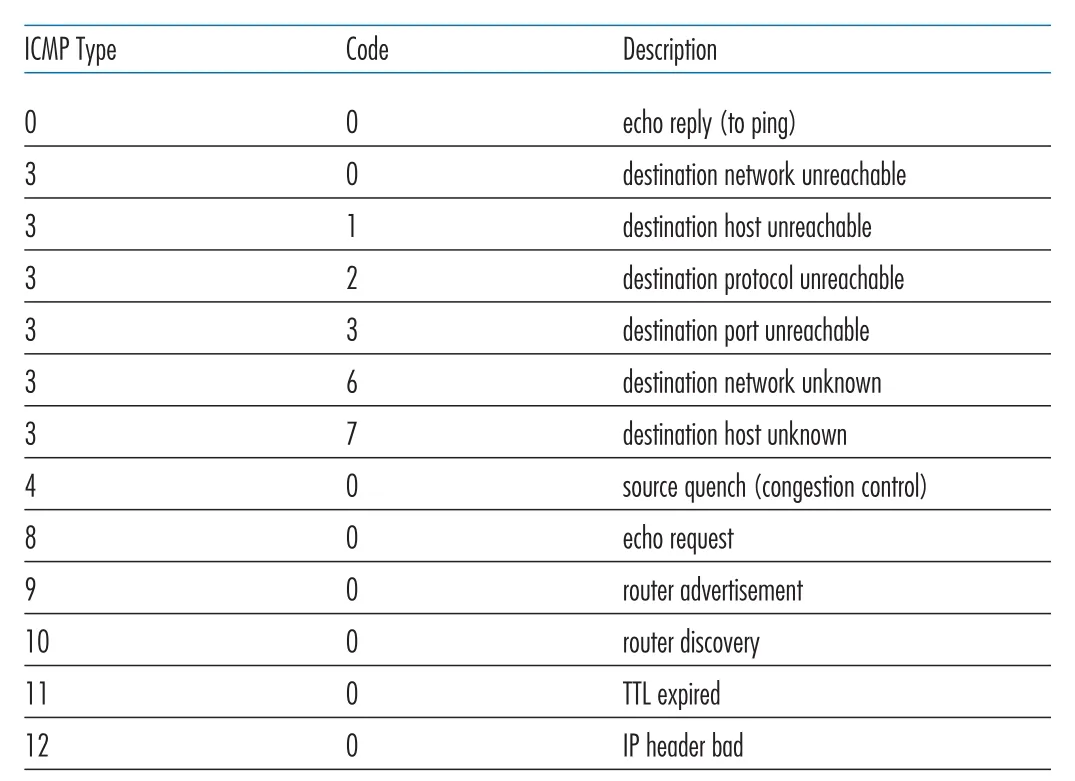 Figure 5.19 · PDF p. 435 · ping, unreachable, TTL expired 등 대표 ICMP type/code
Figure 5.19 · PDF p. 435 · ping, unreachable, TTL expired 등 대표 ICMP type/code
ping은 ICMP의 가장 잘 알려진 사용 예다. ping client는 destination host에게 type 8 code 0 ICMP echo request를 보낸다. destination host는 이를 보고 type 0 code 0 ICMP echo reply를 돌려준다. 많은 TCP/IP implementations에서는 ping server가 user process가 아니라 operating system 안에 직접 구현되어 있다.
source quench는 원래 congested router가 host에게 transmission rate를 줄이라고 알리는 용도였지만, 실제로는 거의 쓰이지 않는다. Chapter 3에서 본 것처럼 TCP는 transport layer에서 자체 congestion control을 수행하고, network devices는 ECN bits를 통해 congestion을 signal할 수 있다.
Traceroute는 ICMP와 IP TTL을 결합한다. source는 destination을 향해 UDP segments를 담은 IP datagrams를 보내되, TTL 값을 1, 2, 3, …으로 증가시킨다. TTL이 n인 datagram은 nth router에서 TTL이 0이 되어 discard되고, 그 router는 source에게 type 11 code 0 TTL expired ICMP message를 보낸다. source는 이 ICMP message에서 router의 name/IP address를 얻고, timer로 round-trip time을 계산한다.
Traceroute가 멈추는 시점도 ICMP로 알 수 있다. 어떤 probe가 destination host까지 도달하면, payload는 unlikely UDP port number를 가진 UDP segment이므로 destination은 type 3 code 3 destination port unreachable ICMP message를 source에게 보낸다. source는 이 message를 받고 destination에 도달했음을 알고 더 이상 probes를 보내지 않는다. 표준 Traceroute는 같은 TTL에 대해 보통 세 packets를 보내므로 각 hop마다 세 RTT 결과가 나온다.
ICMPv6는 IPv6에 맞게 ICMP type/code를 재정리하고, Packet Too Big, unrecognized IPv6 options 같은 IPv6 기능에 필요한 messages를 추가한다. IPv4 fragmentation과 IPv6 path MTU discovery를 연결해서 볼 때 Packet Too Big은 특히 중요하다.
5.7 Network Management and SNMP, NETCONF/YANG
network는 links, switches, routers, hosts, middleboxes, protocols가 얽힌 복잡한 system이다. network management는 hardware, software, human elements를 배치, 통합, 조정해 network와 element resources를 monitor, test, poll, configure, analyze, evaluate, control하는 활동이다. 이 절은 운영자의 의사결정 전체가 아니라, 관리 architecture, protocols, data model을 다룬다.
5.7.1 The Network Management Framework
network management framework의 핵심 구성요소는 managing server, managed device, data, agent, protocol이다.
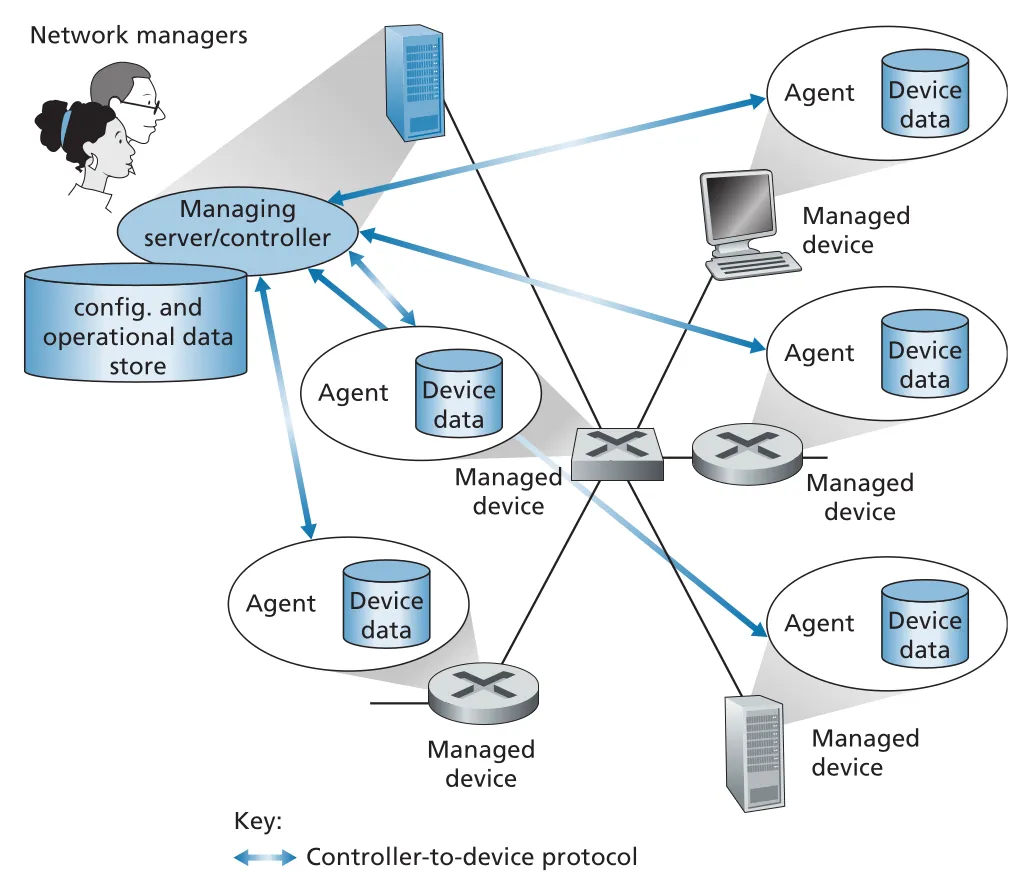 Figure 5.20 · PDF p. 438 · managing server/controller, agents, managed devices, device data의 관계
Figure 5.20 · PDF p. 438 · managing server/controller, agents, managed devices, device data의 관계
| 구성요소 | 의미 |
|---|---|
managing server | NOC의 network management station에서 실행되는 application. management information/commands의 collection, processing, analysis, dispatch의 중심 |
managed device | 관리 대상 host, router, switch, middlebox, modem, sensor 등. hardware/software components와 configuration parameters를 가짐 |
device data 또는 state | configuration data, operational data, device statistics를 포함 |
network management agent | managed device 안에서 실행되어 managing server 명령을 받고 local actions를 수행하는 software process |
network management protocol | managing server와 managed devices 사이에서 query, set, notification을 가능하게 하는 protocol |
device data는 세 종류로 나눠 보면 좋다. configuration data는 manager가 명시적으로 설정한 IP address, interface speed 같은 값이다. operational data는 device가 동작하면서 얻는 정보, 예를 들어 OSPF immediate neighbors list다. device statistics는 dropped packets count, fan speed 같은 counters/status indicators다. managing server는 remote data를 query하고, 경우에 따라 write해서 device를 control한다.
중요한 구분은 network management protocol 자체가 network를 “관리”하는 것이 아니라는 점이다. protocol은 managing server와 agents가 상태를 읽고, 설정을 바꾸고, event를 알릴 수 있는 capabilities를 제공한다. 실제 관리 판단은 tools와 humans 또는 automation logic이 수행한다.
운영자가 network를 관리하는 방식은 크게 세 가지다.
| 방식 | 특징 | 한계/용도 |
|---|---|---|
CLI | console, Telnet, SSH 등으로 device-specific commands 실행 | vendor/device-specific이고 오류가 쉬우며 대규모 자동화에 약함 |
SNMP/MIB | MIB objects를 SNMP로 query/set | monitoring과 statistics query에 강하지만 configuration management와 scale에는 한계 |
NETCONF/YANG | YANG data model과 NETCONF protocol로 configuration/operational data 관리 | network-wide, structured, transactional configuration에 더 적합 |
5.7.2 SNMP and MIB
SNMPv3 (Simple Network Management Protocol version 3)는 managing server와 managed device agent 사이의 network-management control/information messages를 전달하는 application-layer protocol이다. 가장 흔한 사용은 request-response다. managing server가 agent에게 MIB object values를 query하거나 set하는 request를 보내고, agent가 action을 수행한 뒤 response를 보낸다.
또 다른 사용은 trap message다. trap은 agent가 managing server에게 비동기적으로 보내는 unsolicited notification이다. 예를 들어 link interface up/down, neighbor loss, authentication failure 같은 exceptional event가 발생하면 agent는 trap으로 알릴 수 있다.
MIB (Management Information Base)는 managed device의 operational state와 일부 configuration data를 objects로 표현한 것이다. SMI (Structure of Management Information)는 MIB objects의 syntax/semantics를 정의하는 data description language다. 관련 MIB objects는 MIB modules로 묶인다. MIB object는 dropped IP datagrams counter, Ethernet carrier sense errors, DNS server software version, device health status, routing path information 같은 값을 나타낼 수 있다.
SNMPv3의 PDU types는 다음처럼 이해하면 된다.
| PDU type | 방향 | 역할 |
|---|---|---|
GetRequest | manager -> agent | 하나 이상의 MIB object instance 값을 요청 |
GetNextRequest | manager -> agent | list/table에서 다음 MIB object instance 값을 요청 |
GetBulkRequest | manager -> agent | large table 같은 큰 block data를 효율적으로 요청 |
SetRequest | manager -> agent | 하나 이상의 MIB object 값을 설정 |
Response | agent -> manager 또는 manager -> manager | request에 대한 값/상태 응답 |
InformRequest | manager -> manager | 다른 managing entity에게 remote MIB 정보를 알림 |
SNMPv2-Trap | agent -> manager | exceptional event를 비동기적으로 알림 |
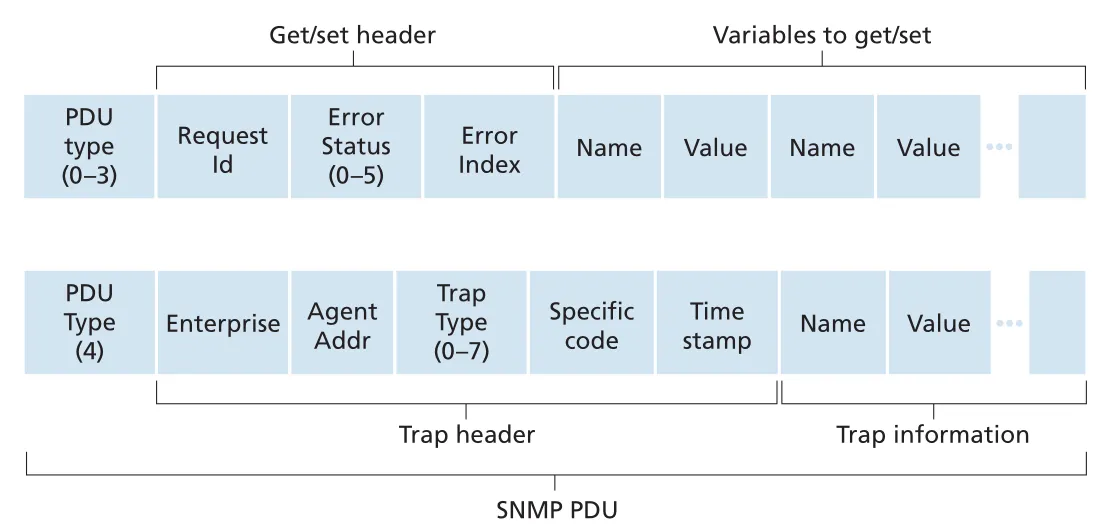 Figure 5.21 · PDF p. 441 · get/set PDU와 trap PDU의 header 및 variable binding 구조
Figure 5.21 · PDF p. 441 · get/set PDU와 trap PDU의 header 및 variable binding 구조
SNMP PDU는 여러 transport protocols에 실릴 수 있지만, 일반적으로 UDP datagram payload로 운반된다. UDP는 unreliable이므로 request나 response가 반드시 도착한다는 보장은 없다. SNMP PDU의 request ID는 managing server가 request와 response를 matching하고 lost request/reply를 감지하는 데 쓰인다. 다만 SNMP standard는 retransmission 절차를 강제하지 않고, managing server가 “responsibly” 재전송 여부와 빈도를 결정하도록 둔다.
SNMPv3는 SNMPv2에 security와 administration capabilities를 더한 것으로 이해하면 된다. 초기 SNMP는 security가 약해 SetRequest를 통한 active control보다는 monitoring에 주로 쓰였다. 이 점은 network management에서도 authentication/security가 나중에 덧붙은 것이 아니라 설계 중심에 있어야 함을 보여 준다.
5.7.3 NETCONF and YANG
NETCONF (Network Configuration Protocol)는 managing server와 managed network devices 사이에서 configuration data를 retrieve/set/modify하고, operational data/statistics를 query하며, notifications를 subscribe하기 위한 protocol이다. SNMP/MIB가 device monitoring에 강했다면, NETCONF/YANG은 structured configuration management에 더 큰 무게가 있다.
NETCONF는 RPC (remote procedure call) paradigm을 사용한다. protocol messages와 device configurations는 XML로 encoding되고, TLS over TCP 같은 secure, connection-oriented session 위에서 교환된다.
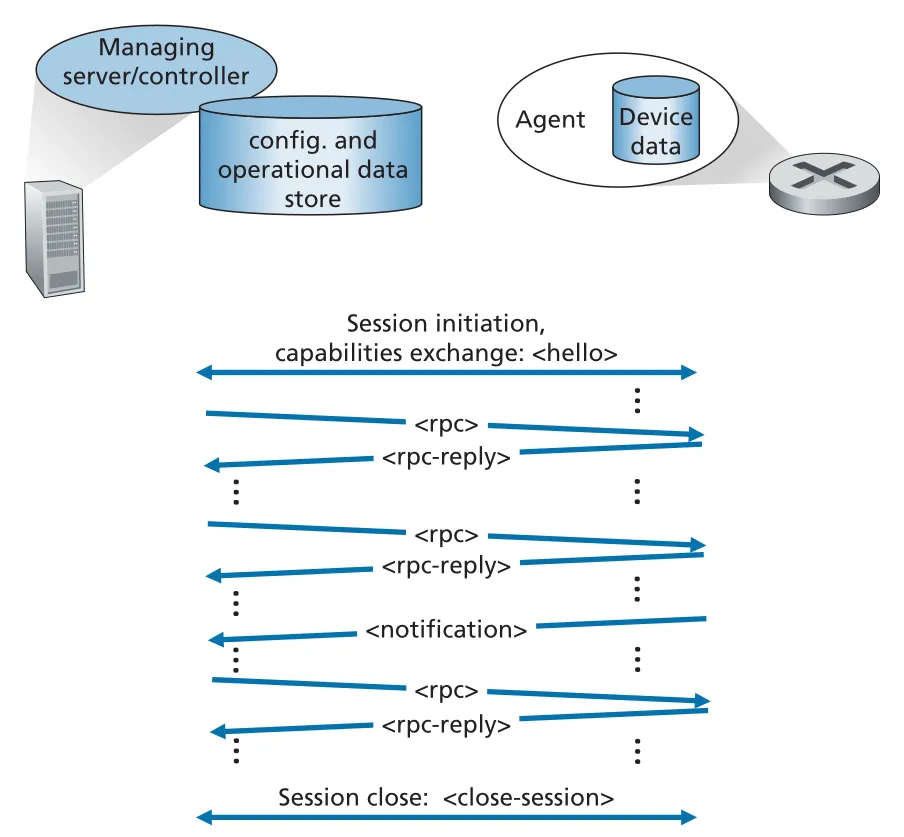 Figure 5.22 · PDF p. 444 · NETCONF session에서 hello, rpc/rpc-reply, notification, close-session이 오가는 흐름
Figure 5.22 · PDF p. 444 · NETCONF session에서 hello, rpc/rpc-reply, notification, close-session이 오가는 흐름
NETCONF session의 흐름은 다음과 같다.
1. managing server establishes secure connection to managed device
2. both sides exchange <hello> messages and declare capabilities
3. managing server sends <rpc>
4. managed device replies with <rpc-reply>
5. managed device may send asynchronous <notification>
6. session closes with <close-session>NETCONF의 selected operations는 configuration 중심성을 잘 보여 준다.
| NETCONF operation | 의미 |
|---|---|
<get-config> | 특정 configuration의 전체 또는 일부 retrieve |
<get> | configuration state와 operational state data retrieve |
<edit-config> | managed device의 configuration 일부 또는 전체 변경. running configuration을 바꾸거나 error 시 rollback 가능 |
<lock>, <unlock> | configuration datastore를 잠그고 풀어 다른 NETCONF/SNMP/CLI commands와의 충돌 방지 |
<create-subscription>, <notification> | 특정 events에 대한 asynchronous notification subscription 생성 |
NETCONF가 중요한 이유는 single device command를 넘어서 multi-device management transactions를 구성할 수 있기 때문이다. operations를 조합해 여러 devices에 대해 “모두 성공적으로 완료되거나, 실패 시 이전 상태로 되돌리는” atomic transaction 성격을 만들 수 있다. 이는 운영자가 individual devices가 아니라 network as a whole의 configuration에 집중하게 하려는 요구와 연결된다.
YANG은 NETCONF에서 사용하는 network management data의 structure, syntax, semantics를 정밀하게 정의하는 data modeling language다. SNMP에서 SMI가 MIBs를 정의하는 역할을 했다면, NETCONF에서는 YANG modules가 device capabilities와 configuration/operational data model을 정의한다. YANG은 built-in data types를 제공하고, valid NETCONF configuration이 만족해야 하는 constraints도 표현할 수 있다. 따라서 YANG은 configuration correctness와 consistency를 기계적으로 검증하는 기반이 된다.
SNMP/MIB와 NETCONF/YANG을 대비하면 다음과 같다.
| 항목 | SNMP/MIB | NETCONF/YANG |
|---|---|---|
| 주 용도 | monitoring, operational state/statistics query | configuration management, operational query, notifications |
| data model | MIB objects, SMI | YANG modules |
| message style | compact PDU fields | XML-encoded RPC |
| transport 관행 | UDP 선호 | secure connection-oriented session, 예: TLS over TCP |
| scale 관점 | device-by-device monitoring에 강함 | network-wide configuration, constraints, transactions에 유리 |
연결 관계
Chapter 4와 Chapter 5는 network layer를 data plane과 control plane으로 나눠 완성한다. Chapter 4의 forwarding table/flow table은 packet을 실제로 어디로 보낼지 결정하는 local data-plane state이고, Chapter 5는 그 state가 어떻게 계산, 설치, 갱신, 관리되는지를 설명한다.
LS/Dijkstra와 DV/Bellman-Ford는 단순한 알고리즘 예제가 아니라, 실제 protocols의 기반이다. OSPF는 LS flooding과 Dijkstra를 intra-AS routing에 적용한다. BGP는 DV-like advertisement를 사용하지만, AS-PATH, NEXT-HOP, local preference, policy 때문에 pure shortest-path algorithm이 아니다.
OSPF와 BGP의 차이는 Internet 구조 자체에서 나온다. AS 내부에서는 하나의 administrative control 아래 performance-oriented routing이 가능하다. AS 사이에서는 policy, scale, business relationship이 dominant하므로 BGP가 controlled route advertisement와 policy-aware selection을 제공한다.
SDN은 routing algorithm을 없애는 것이 아니라, algorithm을 실행하는 위치와 control abstraction을 바꾼다. Dijkstra 같은 logic은 router 내부가 아니라 controller 위 network-control application에서 실행될 수 있고, 결과는 OpenFlow 같은 southbound protocol을 통해 flow tables로 내려간다.
ICMP, SNMP, NETCONF/YANG은 forwarding path 계산과 별개로, 운영되는 IP network가 오류를 알리고 상태를 관찰하며 configuration을 바꾸는 데 필요하다. ICMP는 packet-level error/control signaling, SNMP/MIB는 device monitoring, NETCONF/YANG은 structured configuration management에 가깝다.
다음 Chapter 6의 link layer는 network layer보다 훨씬 local한 범위를 다룬다. network layer가 source-to-destination path를 계산하고 AS들 사이 reachability를 다룬다면, link layer는 같은 link 또는 LAN 안에서 frame을 어떻게 이동시키는지에 집중한다.
오해하기 쉬운 내용
logically centralized control은 물리적으로 controller가 단일 서버라는 뜻이 아니다. 하나의 service처럼 보이지만 내부는 distributed servers, replicated state, consistency/coordination mechanism으로 구현될 수 있다.
centralized routing algorithm과 per-router control은 같은 말이 아니다. LS algorithm은 global information을 사용한다는 의미에서 centralized algorithm이지만, 실제 OSPF에서는 각 router가 같은 global state를 받아 자기 내부에서 Dijkstra를 실행한다. 반대로 SDN controller도 centralized하게 route를 계산할 수 있다.
OSPF advertisement는 direct neighbors에게만 보내는 DV update가 아니다. OSPF는 link-state information을 AS 또는 area 내부 전체에 flooding한다. direct neighbor와의 HELLO는 link 확인/adjacency 관리를 위한 것이고, LS information dissemination의 범위와 혼동하면 안 된다.
BGP route는 단순히 prefix만이 아니다. BGP route는 prefix plus attributes이며, 특히 AS-PATH, NEXT-HOP, local preference가 route selection과 policy에 영향을 준다.
shortest AS-PATH가 항상 선택되는 것은 아니다. BGP route-selection에서는 local preference가 먼저 적용되므로, policy가 shortest AS-PATH보다 우선할 수 있다. 또한 선택된 AS-PATH가 짧다고 해서 router-level latency가 반드시 작다는 보장도 없다.
NEXT-HOP은 destination prefix 자체가 아니라, 해당 AS-PATH를 시작하는 router interface다. BGP가 NEXT-HOP을 고른 뒤, 그 NEXT-HOP까지 AS 내부에서 어떻게 갈지는 OSPF/RIP 같은 intra-AS routing이 만든 forwarding table을 사용한다.
poisoned reverse는 count-to-infinity의 일반 해법이 아니다. 두 neighboring nodes 사이의 loop는 막을 수 있지만, 세 개 이상의 nodes가 얽힌 loop에서는 여전히 count-to-infinity가 발생할 수 있다.
SDN은 모든 packet을 controller가 직접 forwarding한다는 뜻이 아니다. 보통 data packets는 switches의 flow table에 따라 line rate로 처리되고, controller는 flow table rules, events, unmatched packets, statistics를 관리한다.
ICMP는 transport protocol이 아니다. IP datagram payload에 실리지만, TCP/UDP처럼 application data transport를 제공하는 protocol이 아니라 network-layer error/control signaling을 위한 protocol이다.
SNMP가 UDP를 쓴다고 해서 reliability를 완전히 포기한다는 뜻은 아니다. SNMP PDU의 request ID로 request/response matching과 loss detection이 가능하고, retransmission 여부는 managing server가 결정한다.
NETCONF/YANG은 SNMP의 단순한 새 버전이 아니다. SNMP/MIB는 device monitoring과 MIB object query에 강하고, NETCONF/YANG은 structured configuration, constraints, atomic/transactional management에 더 초점이 있다.
면접 질문
data plane과control plane의 차이를 forwarding table/flow table 관점에서 설명해 보라.per-router control과logically centralized control의 차이를 OSPF/BGP와 SDN 예로 설명해 보라.Link-State (LS)routing과Distance-Vector (DV)routing의 필요한 정보, message exchange, convergence 문제를 비교해 보라.- Dijkstra’s algorithm에서 , ,
N'가 각각 무엇이고, forwarding table의 next-hop은 어떻게 얻는가? - Bellman-Ford equation 가 DV update와 forwarding table entry에 어떻게 연결되는가?
count-to-infinity problem은 왜 link cost 감소보다 증가/실패에서 문제가 되는가?poisoned reverse는 어디까지 해결하는가?- Internet에서 왜
intra-AS routing과inter-AS routingprotocol을 다르게 사용하는가? - OSPF가 link-state protocol이라는 말은 message 범위와 algorithm 측면에서 무엇을 뜻하는가?
- BGP에서
prefix,AS-PATH,NEXT-HOP,local preference를 각각 정의하고 route selection 순서에 맞춰 설명해 보라. hot potato routing은 왜 selfish algorithm이라고 불리는가?- BGP
routing policy가 provider/customer 관계에서 transit traffic을 어떻게 제어하는가? IP-anycast가 DNS root servers에 잘 맞고 일반 CDN TCP connection에는 조심스러운 이유는 무엇인가?- SDN controller의 communication layer, network-wide state-management layer, northbound API의 역할을 구분해 보라.
- OpenFlow에서 controller-to-switch messages와 switch-to-controller messages를 각각 두 개씩 예로 들고 목적을 설명해 보라.
- SDN에서 link failure가 발생했을 때 Port-status, state update, routing application, flow table update가 어떤 순서로 이어지는가?
- ICMP
echo request/reply,TTL expired,destination port unreachable이 ping/traceroute에서 어떻게 쓰이는가? - SNMP의
GetRequest,SetRequest,Trap은 각각 어떤 management 상황에 쓰이는가? MIB/SMI와YANG의 역할을 비교해 보라.- NETCONF의
<get>,<edit-config>,<lock>이 configuration management에서 왜 중요한가? - Jennifer Rexford 인터뷰의 관점처럼, programmable network에서 좋은 abstraction이 왜 중요한가? flow table entries 같은 low-level details를 application writer에게 숨기는 장점과 위험을 함께 설명해 보라.