Chapter 10. UDP and IP Fragmentation
- 과목: Computer Network
- 기준 교재: TCP/IP Illustrated, Volume 1
- 관련 페이지: PDF pp. 512-549
- 우선순위: 필수
개요
UDP(User Datagram Protocol)는 transport layer에서 가장 단순한 datagram-oriented protocol이다. Application이 한 번 write한 message boundary를 보존하고, 보통 하나의 UDP output operation이 하나의 UDP datagram, 그리고 하나의 IP datagram으로 이어진다. TCP처럼 byte stream을 만들거나, sequencing, retransmission, duplicate elimination, flow control, congestion control을 제공하지 않는다.
그 대신 UDP는 connectionless라 overhead가 작고, Chapter 9의 broadcast/multicast처럼 connection을 만들기 어려운 one-to-many 통신과 잘 맞는다. Application이 reliability, ordering, congestion behavior를 직접 설계할 수 있다는 점도 장점이다. 이 장은 UDP header/checksum에서 시작해, UDP가 IP fragmentation, path MTU discovery, server design, NAT/translation, attack surface와 어떻게 연결되는지 다룬다.
핵심 개념
- UDP: message boundary를 보존하는 connectionless transport protocol이다.
- UDP datagram: UDP header 8 bytes와 payload data로 구성된다.
- UDP port number: IP가 UDP로 넘긴 datagram을 process/socket으로 demultiplexing하기 위한 16-bit abstract endpoint다.
- UDP checksum: UDP header, UDP data, IP pseudo-header를 덮는 end-to-end checksum이다.
- pseudo-header: 실제로 전송되지는 않지만 checksum 계산에 포함되는 IP-layer field 묶음이다.
- DF(Don’t Fragment): IPv4 fragmentation을 막는 bit field이며, 이후 path MTU discovery와 연결된다.
- ICMP Destination Unreachable / Port Unreachable: UDP destination port에 listener가 없을 때 host가 보낼 수 있는 ICMP error다.
세부 정리
10.1 Introduction
UDP는 “최소 기능 transport”라고 보는 편이 정확하다. UDP 자체는 datagram을 IP layer에 넘겨 보낼 뿐이며, 도착 보장이나 순서 보장을 하지 않는다. Sender가 UDP datagram을 보내도 receiver까지 도달한다는 guarantee가 없고, receiver가 같은 순서로 받는다는 guarantee도 없다. 또한 protocol 차원에서 빠른 UDP sender가 network를 과도하게 점유하지 못하게 막는 congestion control도 없다.
하지만 이 단순함은 설계상의 의도다. UDP는 application이 직접 retransmission unit, timeout, reliability policy, duplicate handling을 고를 수 있게 한다. 예를 들어 multimedia, DNS-like request/response, discovery, broadcast/multicast application은 TCP의 connection setup과 stream abstraction보다 UDP의 datagram abstraction이 더 자연스러울 수 있다.
TCP와의 가장 큰 차이는 application write와 network packet의 관계다.
| 구분 | UDP | TCP |
|---|---|---|
| abstraction | datagram/message-oriented | byte stream-oriented |
| application write와 packet 관계 | 보통 write 1회가 UDP datagram 1개 | write boundary와 TCP segment boundary는 독립 |
| 기본 reliability | 없음 | retransmission, ACK, ordering 제공 |
| flow/congestion control | 없음 | protocol에 포함 |
| broadcast/multicast | 자연스러움 | connection-oriented model과 맞지 않음 |
UDP/IPv4에서 IPv4 Protocol field 값은 17이고, UDP/IPv6에서는 IPv6 Next Header field에도 같은 값 17이 사용된다.
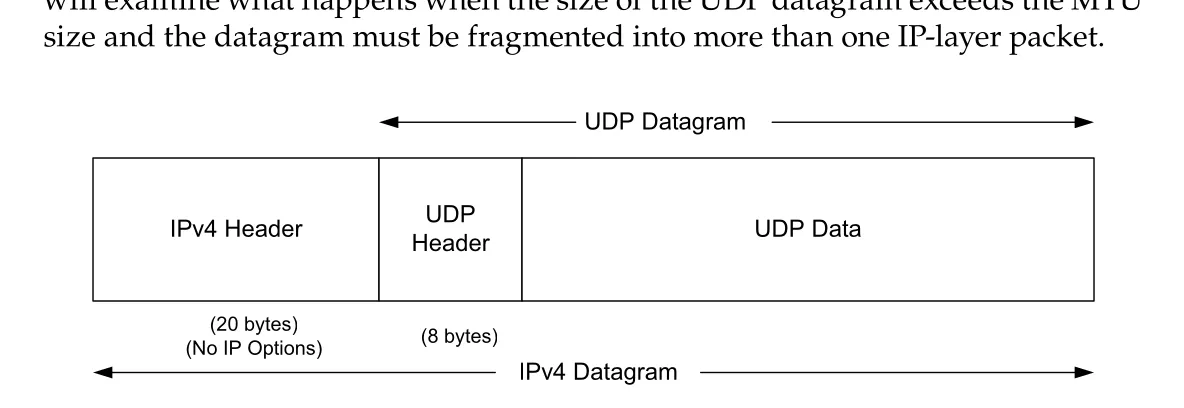
Figure 10-1 · PDF p. 513 · 일반적인 UDP/IPv4 encapsulation은 IPv4 header, 8-byte UDP header, UDP data 순서로 구성된다
Figure 10-1은 fragmentation이 없는 전형적 case를 보여 준다. UDP header는 IP payload 안에 들어가고, UDP data는 다시 UDP header 뒤에 붙는다. 나중에 UDP datagram이 MTU보다 커지면 이 하나의 UDP datagram이 여러 IP fragment로 나뉠 수 있는데, 그때 UDP header는 첫 fragment에만 나타난다. 이 점이 firewall/NAT 처리와 공격에서 중요해진다.
10.2 UDP Header
UDP header는 항상 8 bytes다. Field는 Source Port Number, Destination Port Number, Length, Checksum 네 개뿐이다.
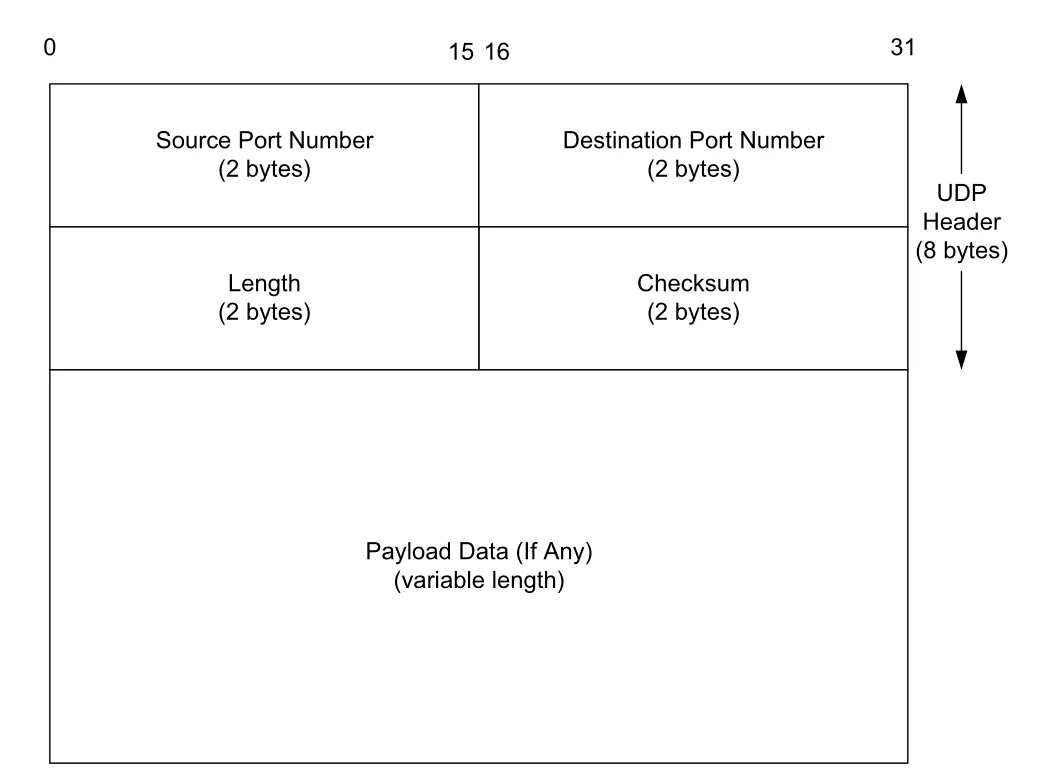
Figure 10-2 · PDF p. 514 · UDP header는 source port, destination port, length, checksum 네 field로 이루어진 8-byte header다
Port number는 process를 찾기 위한 추상적 mailbox다. 물리적 장치나 network interface가 아니라, host 안에서 transport protocol implementation이 incoming data를 어떤 socket/process로 넘길지 결정하는 demultiplexing key다. UDP port number는 16-bit 양수이고, source port는 reply가 필요 없으면 0으로 둘 수 있다.
IP layer는 IPv4의 Protocol field 또는 IPv6의 Next Header field로 “이 payload는 UDP다”를 먼저 결정한다. 그 다음 UDP layer가 destination port로 process/socket을 찾는다. 이 계층적 demultiplexing 때문에 TCP port number와 UDP port number는 protocol별로 독립이다. 같은 IP address와 같은 numeric port를 TCP server와 UDP server가 동시에 사용할 수 있다. 다만 well-known service는 편의상 TCP/UDP에 같은 port number를 배정하는 경우가 많다.
UDP Length field는 UDP header와 UDP data를 합친 byte length다. 일반 UDP에서 최소값은 header만 있는 8이다. 0-byte UDP data도 가능하지만 흔하지 않다. 이 length는 IPv4 Total Length나 IPv6 Payload Length에서 계산할 수 있으므로 중복 정보다. 그래도 UDP layer가 자기 datagram boundary를 확인하고 checksum 계산에 사용할 수 있게 header 안에 포함된다.
10.3 UDP Checksum
UDP checksum은 이 책 흐름에서 처음 등장하는 진짜 transport-layer end-to-end checksum이다. IPv4 header checksum은 IP header만 덮고 router hop마다 TTL 감소 때문에 재계산된다. 반면 UDP checksum은 initial sender가 계산하고 final destination이 확인하며, NAT처럼 주소/port를 바꾸는 장비를 제외하면 transit router가 수정하지 않는다.
UDP checksum이 덮는 범위는 세 부분이다.
| Checksum 대상 | 실제 전송 여부 | 이유 |
|---|---|---|
| UDP header | 전송됨 | port, length, checksum field 보호 |
| UDP data | 전송됨 | application payload 오류 검출 |
| IP pseudo-header | 전송되지 않음 | source/destination IP, Protocol/Next Header, UDP Length를 포함해 misdelivery 검출 |
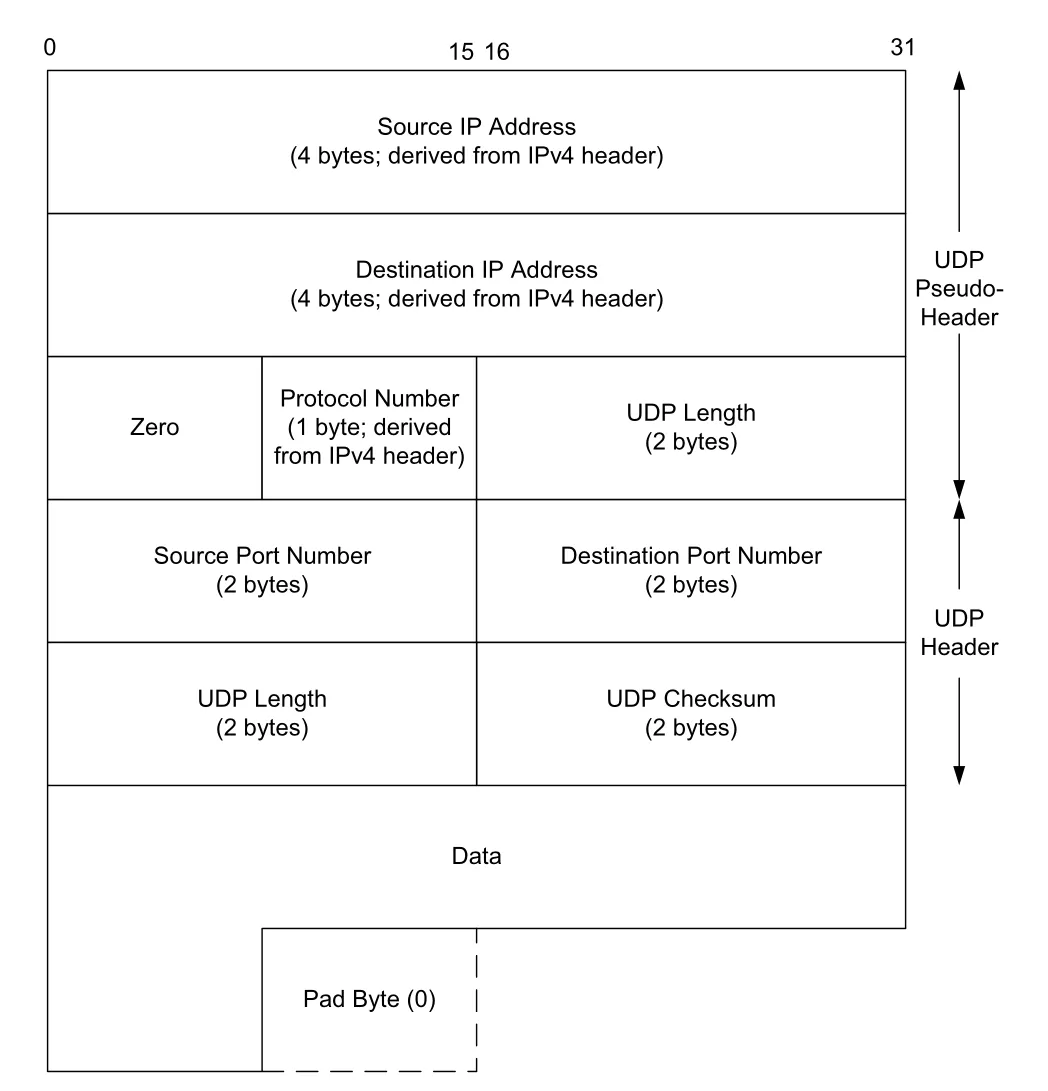
Figure 10-3 · PDF p. 516 · UDP/IPv4 checksum은 IPv4 pseudo-header, UDP header, data를 포함해 계산된다
Pseudo-header는 layering violation처럼 보인다. Transport layer인 UDP가 IP layer의 source/destination address와 Protocol field를 checksum에 넣기 때문이다. 하지만 목적은 분명하다. IP가 잘못된 destination으로 datagram을 넘겼거나, UDP가 아닌 transport payload를 UDP로 넘기는 오류를 검출하기 위해서다. Pseudo-header와 pad byte는 checksum 계산에만 쓰이고 packet에 실려 전송되지 않는다.
Checksum algorithm 자체는 Chapter 5의 Internet checksum과 같다. 16-bit word들의 one’s complement sum을 만들고 다시 one’s complement를 취한다. UDP data length가 odd number of bytes이면 checksum 계산용으로만 virtual pad byte 0을 끝에 붙인다. 이 pad byte는 실제로 전송되지 않는다.
특수 값 처리도 중요하다. 계산 결과가 0x0000이면 header에는 one’s complement arithmetic에서 동등한 0xFFFF로 저장한다. 수신 UDP header의 Checksum field가 0x0000이면 sender가 checksum을 계산하지 않았다는 뜻이다. Sender가 checksum을 계산했고 receiver가 checksum error를 발견하면 UDP datagram은 조용히 discard된다. 별도 ICMP error를 만들지 않고, 통계 counter 정도만 증가할 수 있다.
IPv4에서 UDP checksum은 원래 optional이지만 강하게 권장되며, host에서는 기본적으로 enabled여야 한다. IPv6에서 UDP checksum은 mandatory다. IPv6 header에는 IPv4 header checksum이 없으므로, UDP가 IPv6 위에서 error detection을 제공하지 않으면 application까지 corrupted data가 올라갈 수 있다.
NAT와 checksum의 관계는 Chapter 7과 이어진다. UDP checksum pseudo-header에 IP source/destination address가 포함되고, UDP header에는 port number가 포함된다. 따라서 NAT가 address나 port를 바꾸면 IPv4 header checksum뿐 아니라 UDP checksum도 같이 고쳐야 한다. 특히 UDP datagram이 fragmented 되어 있으면 NAT가 필요한 transport header를 모든 fragment에서 바로 볼 수 없기 때문에 처리가 더 까다로워진다.
10.4 Examples
예시는 sock program으로 UDP datagram을 만들고 tcpdump로 관찰한다. 첫 번째 경우에는 destination host 10.0.0.3에서 discard port 9 server가 실행 중이고, client 10.0.0.5가 1024-byte UDP payload를 1024번 보낸다. Capture에서는 각 packet이 UDP payload 1024 bytes + UDP header 8 bytes + IPv4 header 20 bytes = 총 1052 bytes로 보인다.
이 trace에서 확인할 수 있는 내용은 다음과 같다.
| 관찰값 | 의미 |
|---|---|
[udp sum ok] | UDP checksum이 enabled이고 tcpdump 검증을 통과 |
udp 1024 | UDP payload가 1024 bytes |
len 1052 | IPv4 total length = 20 + 8 + 1024 |
(DF) | IPv4 Don’t Fragment bit가 set |
ttl 64 | host가 보낸 IPv4 TTL initial value |
id 증가 | 각 IPv4 datagram마다 Identification 값이 다름 |
Server가 살아 있으면 ICMP traffic은 생기지 않는다. UDP에는 ACK가 없으므로 sender는 packet이 실제 application까지 전달되었는지 protocol만으로 확신할 수 없다. 단지 error가 돌아오지 않았고 local write가 성공했다는 정도만 알 수 있다.
두 번째 경우에는 같은 destination port로 보내지만 server가 꺼져 있다. 이때 receiver host의 UDP implementation은 ICMPv4 Destination Unreachable (Port Unreachable)를 만들어 sender에게 돌려보낼 수 있다. ICMP error message에는 offending datagram의 앞부분이 포함되어 sender가 어떤 UDP flow와 port에서 문제가 났는지 식별할 수 있다. 이 ICMP error가 firewall 등에서 버려지지 않고, sender application이 아직 살아 있으면 application은 Connection refused 같은 오류를 볼 수 있다.
예시에서 source UDP port는 실행할 때마다 46274, 46294처럼 바뀐다. 이는 client ephemeral port다. Chapter 1에서 권장 ephemeral port range는 49152-65535였지만, 실제 OS 설정에 따라 이 범위 밖 값을 쓸 수도 있다. Linux에서는 /proc/sys/net/ipv4/ip_local_port_range, Windows에서는 netsh로 dynamic port range를 조정할 수 있다.
10.5 UDP and IPv6
UDP가 IPv6 위에서 동작할 때 header 자체는 거의 변하지 않는다. 중요한 차이는 IPv6 address가 128-bit라 pseudo-header가 커지고, IPv6에는 IP-layer header checksum이 없다는 점이다. 그래서 UDP/IPv6에서는 UDP checksum이 mandatory다. UDP checksum을 끄면 IPv6 source/destination address와 transport payload 전체를 end-to-end로 검증하는 장치가 사라진다.

Figure 10-4 · PDF p. 520 · UDP/TCP over IPv6 pseudo-header는 128-bit source/destination address와 32-bit Length를 포함한다
IPv6 pseudo-header의 Length field는 32 bits다. UDP header의 Length field는 16 bits라 일반 UDP datagram length를 표현하는 데 충분하지만, IPv6는 jumbogram을 지원할 수 있다. IPv6 jumbogram에서는 UDP/IPv6 datagram이 65,535 bytes를 넘을 수 있고, 이때 UDP header의 Length field는 0으로 둔다. 실제 length 검증은 IPv6 Jumbo Payload option에서 얻은 payload length에서 extension header 길이를 빼서 계산한다.
IPv6의 minimum MTU는 1280 bytes다. IPv4가 모든 host가 지원해야 하는 최소 size로 576 bytes를 요구했던 것과 다르다. 이 차이는 UDP application이 “작은 datagram이면 fragmentation 없이 안전하다”라고 판단할 때 기준을 바꾼다. 다만 실제 path MTU는 link마다 다를 수 있어, UDP에서도 큰 datagram을 보낼 때는 path MTU discovery가 중요해진다.
10.5.1 Teredo: Tunneling IPv6 through IPv4 Networks
Teredo는 IPv6 connectivity가 없는 host가 IPv6 datagram을 UDP/IPv4 payload 안에 encapsulate해 IPv4-only infrastructure와 NAT를 통과하도록 만든 transition mechanism이다. 순수 IPv6 packet을 IPv4 packet에 넣는 6to4 같은 방식은 NAT traversal 문제가 크다. Teredo는 이 문제를 UDP encapsulation과 server/relay 구조로 우회한다.
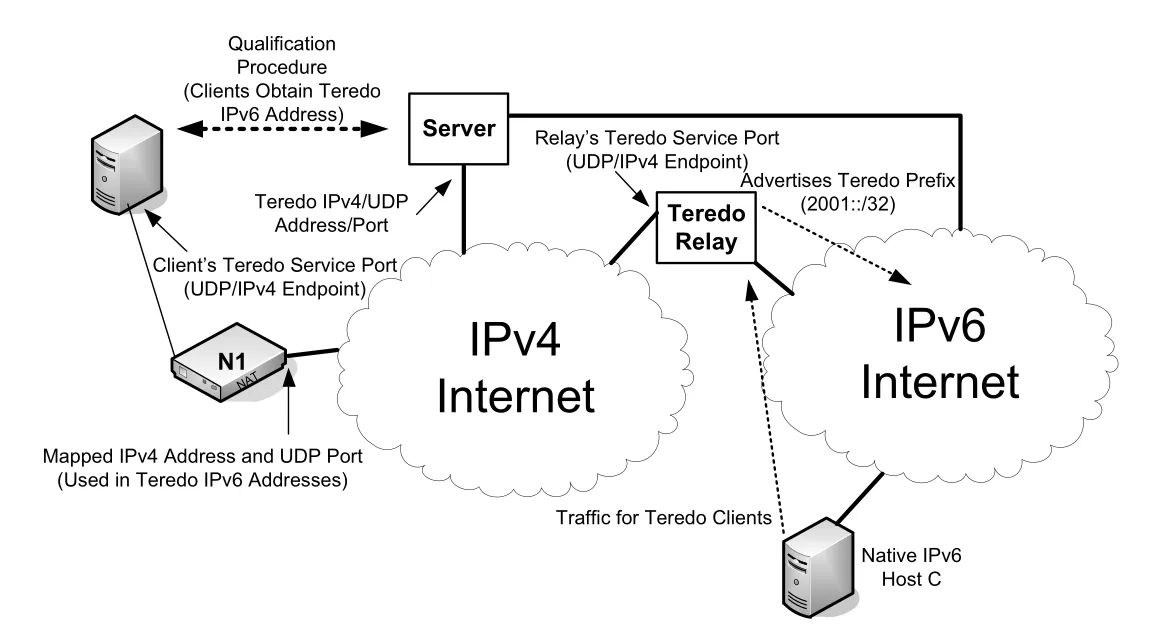
Figure 10-5 · PDF p. 522 · Teredo는 IPv6 datagram을 UDP/IPv4 payload로 실어 NAT 뒤 client와 IPv6 Internet 사이를 연결한다
Teredo 구성 요소는 세 가지로 정리할 수 있다.
| 구성 요소 | 역할 |
|---|---|
| Teredo client | IPv4/IPv6 host가 Teredo tunneling interface를 구현하고 UDP/IPv4로 IPv6 traffic을 encapsulate/decapsulate |
| Teredo server | client qualification, mapped IPv4 address/UDP port 확인, Teredo IPv6 address 형성 지원 |
| Teredo relay | Teredo client와 native IPv6 host 또는 다른 transition mechanism 사이 traffic forwarding |
Client는 Teredo server의 IPv4 address/name과 UDP port, 보통 3544를 알고 시작한다. Qualification procedure에서 client는 link-local IPv6 source address로 ICMPv6 Router Solicitation(RS)을 만들고, 이를 Teredo service port의 UDP/IPv4 datagram 안에 넣어 server로 보낸다. Server는 Router Advertisement(RA)를 돌려주며, client가 NAT 밖에서 보이는 mapped IPv4 address와 UDP port를 알려 준다. Client는 이 정보를 사용해 Teredo IPv6 address를 만든다.
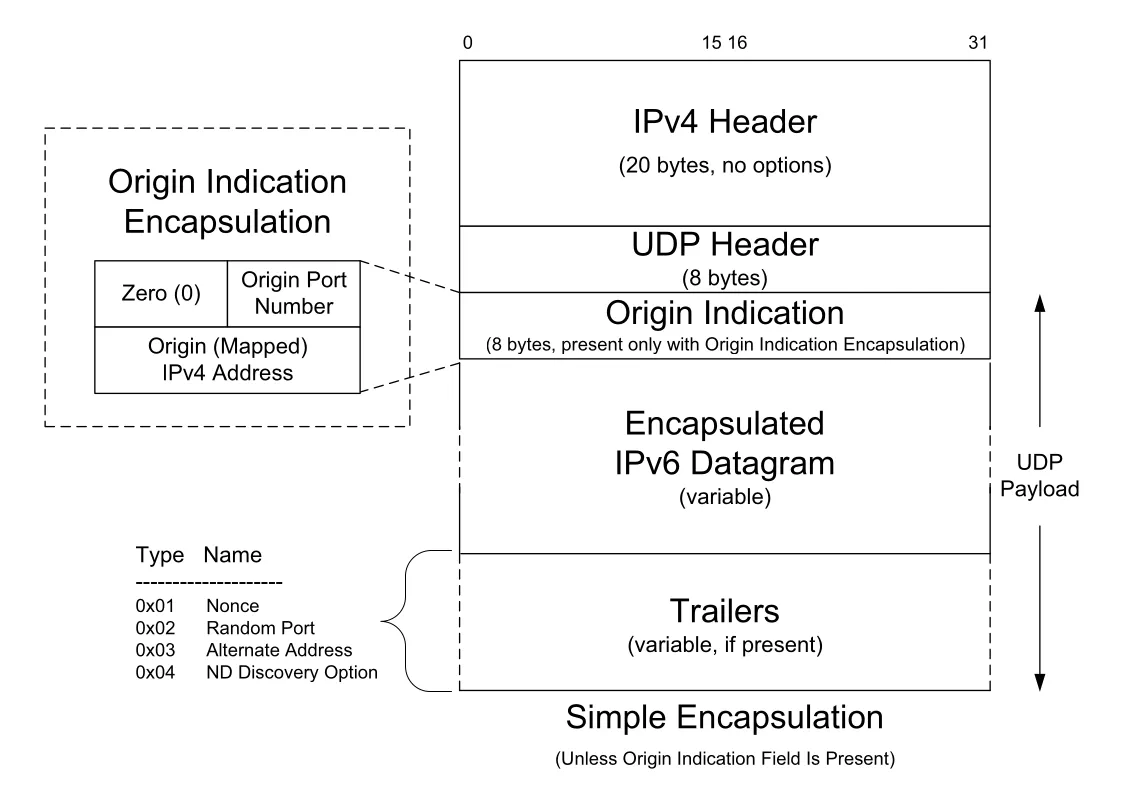
Figure 10-6 · PDF p. 523 · Teredo UDP payload에는 optional Origin Indication, encapsulated IPv6 datagram, optional trailer가 들어갈 수 있다
Teredo encapsulation에는 Simple Encapsulation과 Origin Indication Encapsulation이 있다. Origin Indication은 UDP header와 encapsulated IPv6 datagram 사이에 origin port와 mapped IPv4 address 정보를 넣는다. 이 정보는 client가 자신의 mapped address/port를 알아 Teredo address를 만들 때 쓰인다. Address와 port는 bitwise inversion으로 obfuscation되는데, 일부 NAT가 payload 안의 주소 정보를 멋대로 rewrite하는 것을 피하려는 목적이다.
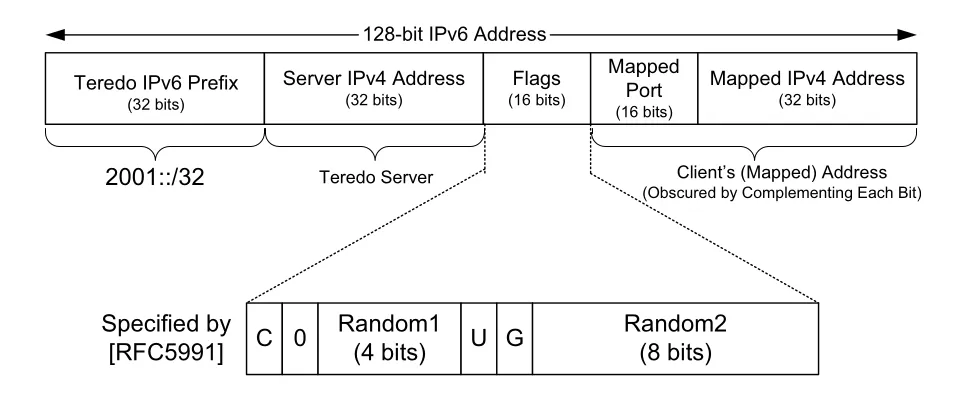
Figure 10-7 · PDF p. 523 · Teredo IPv6 address는 2001::/32 prefix, server IPv4 address, flags, mapped port/address를 담는다
Teredo address는 2001::/32 prefix로 시작하고, Teredo server IPv4 address, 16-bit Flags, mapped UDP port, mapped IPv4 address를 담는다. 마지막 두 값은 client가 NAT 밖에서 어떻게 보이는지 나타내며 bitwise-inverted 형태로 들어간다. Flags에는 NAT type 관련 정보와 random bits가 포함될 수 있고, random bits는 address guessing attack을 줄이기 위한 보안 장치다.
Qualified client가 Teredo address를 얻은 뒤에는 세 종류의 상대와 통신할 수 있다. 같은 link의 Teredo client를 찾을 때는 IPv4 multicast 224.0.0.253과 data payload가 없는 Teredo bubble packet을 사용할 수 있다. IPv4 Internet 안의 다른 Teredo client와 통신할 때는 상대 Teredo address 안의 mapped IPv4 address/port를 이용한다. Native IPv6 host와 통신할 때는 Teredo relay를 찾아 UDP/IPv4로 encapsulated packet을 보낸다.
Teredo의 핵심은 UDP가 NAT traversal에서 상대적으로 유리하다는 점을 이용하는 것이다. Restrictive NAT에서는 bubble packet으로 UDP NAT mapping을 만들고, relay/server를 통해 초기 reachability 정보를 얻는다. 하지만 relay는 processing resource를 많이 쓸 수 있으므로 Teredo는 “다른 IPv6 connectivity가 없을 때 쓰는 last-resort option”으로 취급된다.
Teredo extension은 symmetric NAT 같은 까다로운 NAT behavior를 지원하기 위해 trailer를 사용한다. Trailer는 encapsulated IPv6 payload 뒤에 붙는 TLV(type-length-value) 목록이다. 예를 들어 Nonce trailer는 replay attack 방지에 쓰이고, Alternate Address는 같은 NAT 뒤 client들이 사용할 수 있는 추가 address/port 쌍을 담으며, Random Port는 predicted mapped port를 전달한다. 세부 type 암기보다 “UDP/IPv4 tunnel 안에 IPv6 datagram과 NAT traversal metadata를 함께 실을 수 있다”는 구조를 잡는 것이 중요하다.
10.6 UDP-Lite
UDP-Lite 또는 UDPLite는 일부 payload bit error를 application이 견딜 수 있는 경우를 위해 만들어진 UDP 변형이다. 일반 UDP checksum은 payload 전체를 덮거나, IPv4에서 sender가 checksum을 아예 생략하는 두 극단만 제공한다. UDP-Lite는 header와 payload 일부만 checksum으로 보호하는 partial checksum을 제공한다.
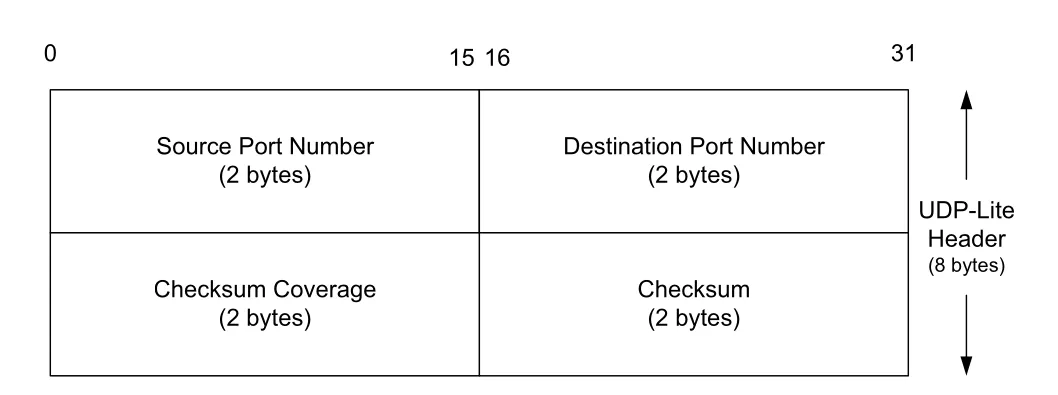
Figure 10-8 · PDF p. 526 · UDP-Lite는 UDP Length field 대신 Checksum Coverage field를 사용한다
UDP-Lite는 UDP와 별도 transport protocol로 취급된다. IPv4 Protocol value와 IPv6 Next Header value는 136이고, 일반 UDP의 17과 다르다. Header 크기는 여전히 8 bytes지만, 기존 UDP Length field 위치가 Checksum Coverage field로 바뀐다. 이 field는 UDP-Lite header 첫 byte부터 몇 byte가 checksum으로 보호되는지 나타낸다.
Checksum Coverage 값의 의미는 다음과 같다.
| Checksum Coverage 값 | 의미 |
|---|---|
0 | conventional UDP처럼 전체 datagram을 checksum으로 보호 |
1-7 | invalid. UDP-Lite header 8 bytes는 항상 보호되어야 함 |
>= 8 | header 전체와 payload 앞부분 일부만 checksum으로 보호 |
UDP-Lite는 corrupted media payload 일부를 버리지 않고 application까지 전달하고 싶은 경우에 의미가 있다. 예를 들어 multimedia codec이 payload 일부 bit error를 concealment할 수 있다면, 전체 UDP datagram을 discard하는 것보다 부분 손상 데이터를 전달하는 편이 더 나을 수 있다. 단, header와 demultiplexing에 필요한 부분은 반드시 checksum으로 보호해야 한다. IPv6 jumbogram에서는 Checksum Coverage field가 16-bit라 coverage를 최대 64KB 또는 전체 datagram으로만 표현할 수 있다는 제한도 있다.
10.7 IP Fragmentation
Link layer frame에는 보낼 수 있는 최대 크기, 즉 MTU(Maximum Transmission Unit)가 있다. IP는 상위 layer에 “하나의 IP datagram” abstraction을 제공하면서도 여러 link MTU를 통과해야 하므로 fragmentation과 reassembly를 제공한다. IP layer는 forwarding table lookup으로 outgoing interface를 고르고, 그 interface의 MTU와 datagram size를 비교해 datagram이 너무 크면 fragment로 나눈다.
IPv4 fragmentation은 original sending host뿐 아니라 intermediate router에서도 일어날 수 있다. 또한 이미 fragment된 datagram fragment가 다시 fragment될 수도 있다. IPv6는 다르다. IPv6에서는 intermediate router가 fragmentation하지 않고, source host만 Fragment extension header를 사용해 fragmentation할 수 있다.
Fragmented IP datagram은 final destination에 도착할 때까지 reassembly되지 않는다. Router 중간에서 재조립하지 않는 이유는 두 가지다.
| 이유 | 설명 |
|---|---|
| router 부담 감소 | router forwarding path에 reassembly state와 buffer를 요구하지 않음 |
| path 다양성 | 같은 original datagram의 fragment들이 서로 다른 path를 지나갈 수 있어 한 router가 모든 fragment를 보지 못할 수 있음 |
두 번째 이유가 특히 강하다. Fragment들이 서로 다른 path를 거치면 중간 router는 subset만 보게 되므로 original datagram을 재조립할 수 없다. 따라서 reassembly는 destination host의 책임이다.
10.7.1 Example: UDP/IPv4 Fragmentation
UDP application은 한 번에 큰 datagram을 만들기 쉽기 때문에 fragmentation을 직접 유발하기 쉽다. Ethernet MTU가 1500 bytes이고 IPv4 header가 20 bytes, UDP header가 8 bytes라면, fragmentation 없이 보낼 수 있는 UDP application data는 보통 1500 - 20 - 8 = 1472 bytes다. IPv4 option이 있으면 IPv4 header가 더 커져 이 값은 더 줄어든다.
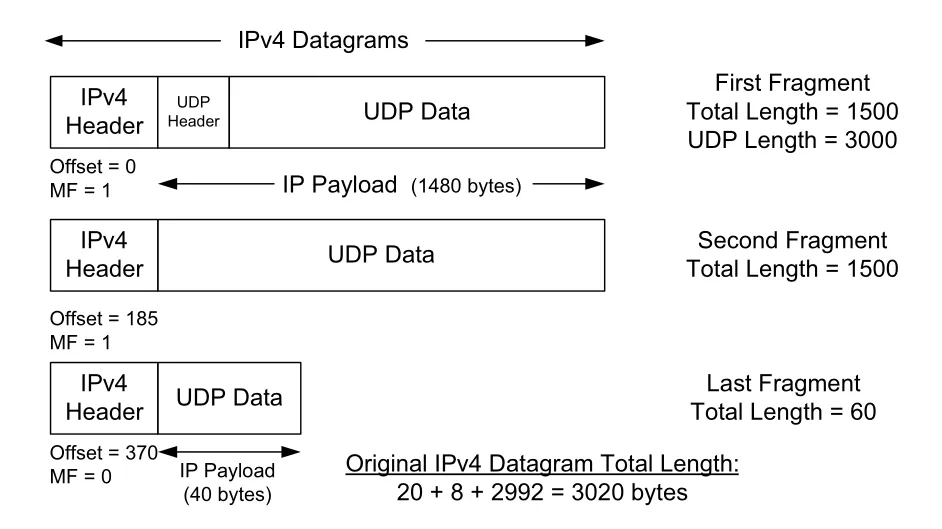
Figure 10-9 · PDF p. 528 · 2992-byte UDP payload를 가진 UDP/IPv4 datagram이 세 개의 IPv4 fragment로 나뉜다
Figure 10-9의 original IPv4 datagram은 IPv4 header 20 bytes + UDP header 8 bytes + UDP payload 2992 bytes = Total Length 3020 bytes다. MTU 1500인 link를 지나야 하므로 세 fragment가 만들어진다. 새로 생긴 fragment마다 IPv4 header 20 bytes가 붙어, 총 전송 byte 수는 3020이 아니라 3060 bytes가 된다. 여기서는 IP-layer overhead가 약 1.3% 증가한다.
Fragmentation을 이해할 때 봐야 할 IPv4 header field는 세 가지다.
| Field | 역할 |
|---|---|
Identification | 같은 original datagram에서 나온 fragment들을 묶는 값 |
Fragment Offset | original datagram payload 안에서 이 fragment payload가 시작하는 위치. 8-byte unit |
MF (More Fragments) | 뒤에 fragment가 더 있으면 1, 마지막 fragment면 0 |
Figure 10-9에서 첫 fragment는 offset 0, MF 1이다. 두 번째 fragment는 first fragment의 IP payload 1480 bytes 뒤에서 시작하므로 offset은 1480 / 8 = 185다. 세 번째 fragment는 offset 370이고 MF 0이다. MF가 0인 fragment가 도착하면 receiver는 original datagram의 전체 길이를 계산할 수 있다. Offset은 original datagram 기준이므로 fragment가 out of order로 도착해도 reassembly할 수 있다.
Fragmentation의 중요한 제약은 마지막 fragment를 제외한 모든 fragment payload size가 8 bytes의 배수여야 한다는 점이다. Fragment Offset이 8-byte unit으로 표현되기 때문이다. 그래서 1500-byte Ethernet에서 option 없는 IPv4 header 20 bytes를 빼면 first fragment payload 1480 bytes가 되고, 1480은 8의 배수라 잘 맞는다.
실제 sock 예시에서는 UDP payload 1471, 1472 bytes는 fragmentation 없이 각각 IPv4 total length 1499, 1500으로 전송된다. 하지만 1473 bytes는 IPv4 total length 1501이 되어 fragment된다. 첫 fragment는 1500-byte packet이고, 두 번째 fragment에는 남은 1 byte만 들어간다. 1474 bytes도 마찬가지로 남은 2 bytes를 담는 second fragment가 생긴다.
Fragmentation이 성능상 꺼려지는 가장 큰 이유는 loss amplification이다. Fragment 중 하나만 잃어도 original IP datagram 전체를 reassemble할 수 없고, 따라서 전체 UDP datagram이 손실된다. IP layer는 fragment 하나만 다시 보내는 mechanism이 없다. TCP라면 결국 전체 TCP segment를 다시 보내고, UDP라면 application이 자체 timeout/retransmission을 구현하지 않는 한 복구가 없다. Intermediate router가 fragmentation했다면 original sender는 datagram이 어떻게 쪼개졌는지도 알 수 없다.
또 다른 실무 문제는 UDP header가 첫 fragment에만 있다는 점이다. Source/destination port number는 UDP header 안에 있으므로, 첫 fragment가 아닌 fragment만 보면 firewall, NAT, packet capture tool이 어느 UDP flow인지 바로 알 수 없다. tcpdump도 later fragment의 port number를 표시하려면 reassembly해야 하지만 일반적으로 그렇게 하지 않는다. 이런 특성은 NAT와 firewall 정책, 그리고 fragmentation attack에서 중요해진다.
10.7.2 Reassembly Timeout
Destination IP layer는 어떤 fragment가 처음 도착하면 reassembly timer를 시작해야 한다. 그러지 않으면 마지막 fragment가 영원히 오지 않는 datagram 때문에 receiver buffer가 계속 묶이고, 이는 resource exhaustion attack surface가 된다.
원문 예시에서는 ICMPv4 Echo Request의 일부 fragment만 보내고 마지막 fragment는 보내지 않는다. Target은 첫 fragment를 받은 뒤 timer를 시작하고, 20초 뒤 두 번째 fragment가 와도 timer를 reset하지 않는다. 첫 fragment 수신 후 30초가 지나자 target은 incomplete datagram을 discard하고 ICMPv4 Time Exceeded (code 1)를 sender에게 보낸다. 이 code 1은 TTL expired가 아니라 fragment reassembly time exceeded를 의미한다.
Reassembly timeout의 중요한 규칙은 다음과 같다.
| 항목 | 의미 |
|---|---|
| timer 시작 | 같은 datagram의 어떤 fragment라도 처음 도착한 시점 |
| timer reset 여부 | 새 fragment가 와도 reset되지 않음 |
| 일반 timeout | 구현에 따라 30s 또는 60s가 흔함 |
| timeout 시 동작 | incomplete datagram discard, 경우에 따라 ICMP Time Exceeded code 1 전송 |
| ICMP error 조건 | first fragment(offset 0)가 없으면 transport header가 없어 process 식별이 어려워 ICMP error를 생략할 수 있음 |
역사적으로 일부 Berkeley-UNIX 계열 구현은 timer가 만료되면 fragment들을 discard했지만 ICMP error를 만들지 않았다. 이런 차이 때문에 higher-layer protocol은 결국 자기 timeout에 의존해야 한다. UDP application도 큰 datagram을 쓴다면 “fragment loss는 전체 datagram loss”라는 전제를 가지고 timeout/retry 정책을 설계해야 한다.
10.8 Path MTU Discovery with UDP
UDP는 application이 outgoing datagram size를 직접 고르는 경우가 많다. 따라서 fragmentation을 피하려면 destination까지의 path에서 fragment 없이 보낼 수 있는 최대 packet size, 즉 Path MTU (PMTU)를 알아야 한다. Conventional Path MTU Discovery (PMTUD)는 Chapter 8의 ICMP Packet Too Big (PTB) message를 이용한다.
UDP application 입장에서 PMTUD가 까다로운 이유는 ICMP PTB가 보통 UDP layer 아래의 IP layer에서 처리된다는 점이다. Application이 직접 ICMP message를 보지 못할 수 있으므로, OS API를 통해 per-destination PMTU estimate를 조회하거나, IP layer가 독립적으로 PMTUD cache를 관리한다. 이 PMTU 정보는 destination별로 cache되고, 일정 시간 refresh되지 않으면 stale로 간주된다.
10.8.1 Example
예시에서는 UDP payload 1473 bytes를 보내 IPv4 total length 1501 bytes datagram을 만든다. Sender host와 local LAN은 1500보다 큰 MTU를 지원하지만, Internet으로 나가는 router link의 MTU는 1500 bytes다. IPv4 DF bit가 set되어 있으므로 router는 fragment하지 못하고 ICMPv4 PTB를 돌려준다.
흐름을 압축하면 다음과 같다.
| 단계 | 동작 |
|---|---|
| 1 | Sender가 DF set, total length 1501인 UDP/IPv4 datagram 전송 |
| 2 | Router가 next-hop MTU 1500보다 datagram이 크고 DF가 set된 것을 확인 |
| 3 | Router가 offending datagram 일부를 포함한 ICMPv4 PTB 전송 |
| 4 | Sender IP layer가 destination의 PMTU estimate를 1500으로 cache |
| 5 | 이후 전송은 error를 application에 돌려주거나, DF 없이 fragmentation하는 방식으로 조정될 수 있음 |
원문 첫 예시에서는 application이 세 UDP datagram을 1ms도 안 되는 짧은 시간에 모두 보내 버린다. ICMP PTB가 돌아와 처리되기 전에 program이 끝났기 때문에, application은 PMTU feedback을 제때 반영하지 못한다. 이것은 UDP에서 PMTUD가 application timing과 맞물린다는 점을 보여 준다.
두 번째 예시에서는 send 사이에 2초 delay를 넣는다. 첫 실행에서 ICMP PTB가 돌아오고 error condition이 sender에게 전달되어 Message too long 같은 오류가 발생한다. 이후 같은 destination으로 다시 보내면 system이 PMTU 1500을 이미 알고 있어, 해당 datagram들을 fragmentation해 보낸다. 일정 시간이 지나 PMTU cache가 stale해지면 다시 큰 unfragmented datagram을 보내고, 또 ICMP PTB를 받아 PMTU를 갱신한다. RFC1191은 PMTU estimate를 10분 뒤 stale로 간주할 것을 권한다.
PMTUD의 약점은 ICMP 의존성이다. Firewall이나 filtering gateway가 ICMP를 무차별적으로 drop하면 sender는 packet이 너무 크다는 feedback을 받지 못한다. 그러면 UDP datagram은 계속 사라지지만 application은 원인을 모를 수 있다. 이런 문제 때문에 system-wide 또는 socket별로 PMTUD를 끄는 설정이 있고, ICMP에 의존하지 않는 대안 PMTUD(RFC4821)도 제안되었다.
PPPoE 환경처럼 link overhead가 붙는 경우에도 PMTU가 줄어든다. 예를 들어 Ethernet 1500 bytes에서 PPPoE header 6 bytes와 PPP header 2 bytes를 빼면 encapsulated IP datagram에 쓸 수 있는 MTU는 1492 bytes가 된다. UDP application이 “Ethernet이면 1500”이라고 단정하면 이런 path에서 문제가 생길 수 있다.
10.9 Interaction between IP Fragmentation and ARP/ND
Fragmentation은 link-layer address resolution과도 상호작용한다. IPv4에서는 ARP가 same-subnet IP address를 MAC address로 mapping하고, IPv6에서는 ND가 비슷한 역할을 한다. 큰 UDP datagram이 여러 fragment로 나뉘었는데 destination MAC address가 아직 ARP cache에 없다면, 구현은 두 질문을 처리해야 한다.
| 질문 | 잘못 처리하면 생기는 문제 |
|---|---|
| fragment마다 ARP request를 보낼 것인가? | ARP flooding 발생 |
| ARP resolution 동안 몇 개 fragment를 queue할 것인가? | 일부 fragment만 보존하면 datagram 전체 손실 |
원문 실험에서는 8192-byte UDP payload를 보내 Ethernet MTU 1500에서 약 six fragments가 생기게 한다. Destination 10.0.0.20이 실제로 없을 때는 ARP request가 1초 간격으로 세 번 나가고 응답이 없어 포기한다. Destination 10.0.0.3이 있을 때는 ARP reply가 약 250 microseconds 후 오고, 약 20 microseconds 뒤 fragment들이 매우 빠르게 연속 전송된다. Linux에서는 last fragment가 먼저 보내지는 behavior가 관찰된다.
역사적으로는 fragment마다 ARP request를 보내거나, ARP reply를 기다리는 동안 fragment 중 하나만 queue해 나머지를 잃는 구현 문제가 있었다. RFC1122는 ARP flooding을 막아야 한다고 요구했고, 권장 maximum rate는 초당 하나다. 또한 unresolved IP address에 대해 적어도 하나의 packet을 저장해야 한다고 했지만, 하나만 저장하면 fragmented datagram에는 충분하지 않다. 현대 구현은 ARP pending 동안 더 큰 queue를 제공해 불필요한 datagram loss를 줄인다.
10.10 Maximum UDP Datagram Size
이론상 IPv4 datagram의 maximum size는 IPv4 Total Length field가 16 bits이므로 65,535 bytes다. IPv4 header option이 없으면 header 20 bytes, UDP header 8 bytes를 빼서 maximum UDP user data는 65,535 - 20 - 8 = 65,507 bytes다.
IPv6에서 jumbogram을 쓰지 않는다면 IPv6 Payload Length field도 16 bits라 IPv6 payload는 최대 65,535 bytes다. 이 payload 안에 UDP header 8 bytes가 들어가므로 maximum UDP user data는 65,535 - 8 = 65,527 bytes다.
| 환경 | 제한 field | 최대 UDP user data |
|---|---|---|
| UDP/IPv4, no IPv4 options | IPv4 Total Length 16 bits | 65,507 bytes |
| UDP/IPv6, no jumbogram | IPv6 Payload Length 16 bits | 65,527 bytes |
| UDP/IPv6 jumbogram | Jumbo Payload option + UDP Length 0 | 65,535 bytes 초과 가능 |
하지만 이론상 maximum이 end-to-end delivery를 보장하지는 않는다. Local protocol implementation의 buffer/API 제한, path MTU와 fragmentation loss, receiver application buffer size가 모두 실제 전달 가능 크기를 제한한다.
10.10.1 Implementation Limitations
Socket API는 send/receive buffer size를 제공하며, UDP socket에서 이 크기는 application이 한 번에 읽거나 쓸 수 있는 UDP datagram 크기와 직접 관련된다. Default buffer size는 구현마다 다르며 8192 bytes 또는 65,535 bytes 같은 값이 쓰일 수 있고, 대개 setsockopt()로 조정할 수 있다.
Chapter 5에서 본 것처럼 IPv4 host는 reassembly 후 최소 576-byte IPv4 datagram을 받을 수 있어야 한다. 그래서 많은 UDP application은 application data를 512 bytes 이하로 제한해 IPv4 datagram 전체가 576 bytes 아래에 머물도록 설계했다. DNS(Chapter 11)와 DHCP(Chapter 6)가 이런 보수적 UDP datagram size 설계의 대표 사례다.
10.10.2 Datagram Truncation
UDP는 message boundary를 보존한다. 따라서 receiver application이 read call에서 “최대 N bytes만 받겠다”고 했는데 실제 UDP datagram이 N bytes보다 크면 문제가 생긴다. 일반적인 behavior는 excess data를 truncate하고 버리는 것이다. 하지만 세부 동작은 OS/API마다 다르다.
| 구현/API behavior | 결과 |
|---|---|
| 대부분의 구현 | application buffer를 넘는 datagram tail을 discard |
Linux MSG_TRUNC | truncation된 전체 datagram size를 알 수 있음 |
HP-UX MSG_TRUNC | 일부 data가 truncation되었다는 flag를 반환 |
| SVR4/Solaris 2.x sockets | excess data를 subsequent reads에서 반환, application이 한 UDP datagram이 여러 read로 나뉜 사실을 모를 수 있음 |
이 점은 TCP와 반대다. TCP는 byte stream이라 application이 원하는 만큼 읽고, 남은 bytes는 stream에 계속 남는다. UDP는 datagram boundary가 의미 있으므로, API가 truncation을 어떻게 처리하는지 모르면 message format parsing이 깨질 수 있다. UDP application은 maximum datagram size와 receive buffer size를 protocol 설계와 함께 정해야 한다.
10.11 UDP Server Design
UDP server는 보통 하나의 well-known port에서 잠자고 있다가 client datagram이 도착하면 깨어나 request를 처리한다. UDP는 connection setup이 없으므로 client는 단순하지만, server는 여러 client가 동시에 보내는 datagram을 구분하고, 필요하면 reply를 돌려보내야 한다. 여기서 UDP의 protocol 특성, 즉 source/destination address와 port, wildcard binding, queue overflow, IPv4/IPv6 address family가 server design에 직접 영향을 준다.
10.11.1 IP Addresses and UDP Port Numbers
UDP server application이 receive하는 것은 UDP payload다. IP header와 UDP header는 kernel에서 제거되므로, server가 reply를 하려면 OS가 별도 metadata로 source IP address와 source UDP port number를 알려줘야 한다. 이 metadata 덕분에 single UDP server가 여러 client request를 처리하고 각각에게 reply할 수 있다.
어떤 server는 source뿐 아니라 destination IP address도 알아야 한다. Multihoming, IP address aliasing, IPv6 multiple scopes 때문에 한 host에는 여러 local IP address가 있을 수 있고, 하나의 wildcard-bound server는 그중 어느 주소로 온 datagram도 받을 수 있다. DNS server처럼 destination IP address에 따라 response ordering이나 policy를 달리하는 service도 있다. Broadcast/multicast destination으로 온 datagram을 다르게 처리해야 하는 service도 있다. 예를 들어 RFC1122는 TFTP server가 broadcast address로 온 datagram을 ignore해야 한다고 말한다.
따라서 UDP server에는 payload뿐 아니라 다음 4-tuple 정보가 중요하다.
| 정보 | 필요성 |
|---|---|
| source IP address | reply destination 결정 |
| source UDP port | reply destination port 결정 |
| destination IP address | multihoming, alias, broadcast/multicast policy 구분 |
| destination UDP port | local service demultiplexing |
IPv4와 IPv6를 모두 지원하는 UDP server는 address length와 data structure 차이도 고려해야 한다. IPv4 address는 32 bits, IPv6 address는 128 bits이고, IPv4-mapped IPv6 address 같은 interoperability mechanism 때문에 IPv6 socket이 IPv4 traffic까지 받을 수 있는 구현도 있다.
10.11.2 Restricting Local IP Addresses
많은 UDP server는 local IP address를 wildcard로 bind한다. 즉 특정 local address가 아니라 *.port 또는 0.0.0.0:port 같은 형태로 endpoint를 만들고, 해당 port로 들어오는 datagram을 host의 어떤 local IP address에서든 받는다. Linux netstat에서 *:7777처럼 보이는 경우가 이에 해당한다.
반대로 server가 local IP address를 명시하면, destination IP address가 그 local address와 일치하는 datagram만 받는다. 예를 들어 127.0.0.1:7777에 bind하면 local loopback interface로 들어온 datagram만 받으며, 같은 Ethernet의 다른 host가 보낸 datagram은 server에 전달되지 않는다. Destination port가 열려 있지 않은 것으로 처리되어 ICMPv4 Port Unreachable이 돌아갈 수 있다.
10.11.3 Using Multiple Addresses
한 host가 여러 IP address를 가지고 있으면 같은 UDP port에 대해 서로 다른 local IP address로 여러 server instance를 띄울 수 있다. 보통은 application이 SO_REUSEADDR 같은 socket option으로 같은 port number 재사용이 허용됨을 OS에 알려야 한다.
예를 들어 host에 10.0.2.13, 10.0.2.14, native 10.0.0.30, loopback 127.0.0.1이 있을 때 세 server를 같은 UDP port 8888에 bind할 수 있다.
| Binding | 받는 datagram |
|---|---|
10.0.2.13:8888 | destination IP가 10.0.2.13인 datagram |
10.0.2.14:8888 | destination IP가 10.0.2.14인 datagram |
0.0.0.0:8888 또는 wildcard | specific binding이 없는 local address, broadcast, loopback 등 |
Endpoint selection에는 priority가 있다. Destination IP address와 정확히 일치하는 specific endpoint가 wildcard endpoint보다 항상 먼저 선택된다. Wildcard endpoint는 specific match가 없을 때만 사용된다. 이 규칙을 모르면 “wildcard server가 모든 datagram을 먼저 받는다”고 오해하기 쉽다.
10.11.4 Restricting Foreign IP Address
UDP endpoint는 foreign address와 foreign port도 제한할 수 있다. 일반 server의 foreign address는 wildcard라서 어느 client IP/port에서 온 datagram도 받는다. 하지만 특정 client와만 통신하도록 foreign IP address와 port를 설정하면, 그 endpoint는 해당 peer의 datagram만 받는다. Server가 처음 client request를 받은 뒤 이후 traffic을 그 client로 제한하는 식의 filtering에 사용할 수 있다.
Foreign address를 지정하면 local address가 자동으로 선택되는 side effect가 있다. Local address를 명시하지 않았다면 kernel은 specified foreign address로 가기 위해 routing table이 선택하는 interface의 local IP address를 endpoint local address로 삼는다. 이 경우 netstat에서는 UDP인데도 State column이 ESTABLISHED처럼 보일 수 있다. UDP에 TCP식 connection이 생긴 것은 아니고, endpoint association이 local/foreign 4-tuple로 고정되었다는 뜻에 가깝다.
UDP server binding match 순서는 다음과 같이 가장 specific한 것부터 가장 덜 specific한 것 순서다.
| Local Address | Foreign Address | 의미 |
|---|---|---|
local_IP.local_port | foreign_IP.foreign_port | 특정 local address/port와 특정 client에 제한 |
local_IP.local_port | *.* | 특정 local address/port, client는 누구든 가능 |
*.local_port | *.* | local port만 제한, local/foreign address wildcard |
Incoming UDP datagram을 어느 endpoint에 전달할지 결정할 때 UDP module은 위 순서대로 matching한다.
10.11.5 Using Multiple Servers per Port
대부분의 구현은 기본적으로 하나의 address family 안에서 (local IP address, UDP port number) pair를 한 application endpoint만 사용할 수 있게 한다. 같은 local address와 같은 UDP port로 두 번째 server를 띄우면 Address already in use 오류가 난다.
Multicast 지원을 위해서는 예외가 필요하다. Broadcast 또는 multicast destination address로 온 UDP datagram은 같은 (local IP, port)에 여러 endpoint가 있으면 각 endpoint에 한 copy씩 전달될 수 있다. Application은 보통 SO_REUSEADDR 또는 BSD 계열의 SO_REUSEPORT 같은 option으로 이를 허용해야 한다.
Unicast datagram은 다르다. 같은 unicast destination IP/port에 여러 endpoint가 있더라도 일반적으로 한 endpoint에만 전달된다. 어느 endpoint가 받는지는 implementation-dependent일 수 있지만, 이 정책은 multiprocess/multithreaded server가 같은 incoming request를 중복 처리하지 않게 해 준다.
| Destination type | 여러 endpoint가 같은 port를 공유할 때 |
|---|---|
| broadcast | 각 endpoint에 copy 전달 가능 |
| multicast | 각 endpoint에 copy 전달 가능 |
| unicast | 한 endpoint에만 전달, 선택은 구현 의존 |
10.11.6 Spanning Address Families: IPv4 and IPv6
UDP server는 IPv4와 IPv6를 모두 처리하도록 만들 수 있다. 문제는 OS에 따라 IPv4와 IPv6의 port space가 공유될 수 있다는 점이다. 어떤 system에서는 IPv4 UDP port에 bind하면 IPv6 port space에서도 같은 port가 점유되고, 반대도 가능하다. 또한 IPv6 wildcard binding이 IPv4-mapped IPv6 address mechanism 때문에 IPv4 traffic까지 받을 수 있다.
Linux에서는 port space가 공유되고, wildcard IPv6 binding은 대응되는 IPv4 binding도 암시하는 것으로 동작한다. FreeBSD에서는 IPV6_V6ONLY socket option으로 IPv6 binding이 IPv6 space에만 존재하게 할 수 있다. Cross-platform server를 작성할 때는 IPv4/IPv6 dual-stack socket behavior를 OS별로 확인해야 한다.
10.11.7 Lack of Flow and Congestion Control
많은 UDP server는 iterative server다. 하나의 server process/thread가 하나의 UDP port에 도착한 client request들을 순서대로 처리한다. UDP port마다 limited-size input queue가 있고, 여러 client request가 거의 동시에 오면 UDP layer가 FCFS(first come, first served) 방식으로 queue에 쌓아 application이 읽을 때 전달한다.
Queue가 overflow되면 UDP implementation은 incoming datagram을 discard한다. UDP에는 flow control이 없으므로 server가 client에게 “천천히 보내라”고 protocol 차원에서 말할 방법이 없다. 또한 reliability mechanism도 없으므로 application은 UDP input queue overflow로 datagram이 버려졌다는 사실을 자동으로 알 수 없다.
Network 내부 router queue가 full이 되어 packet이 discard되는 경우는 congestion이다. UDP는 congestion을 감지하거나 sender rate를 줄이는 mechanism이 없다. 이 때문에 high-rate UDP application은 다른 network user에게 피해를 줄 수 있다. UDP를 쓰는 application은 자체 rate limiting, congestion response, backoff policy를 설계해야 한다. TCP congestion control은 Chapter 16에서 다룬다.
10.12 Translating UDP/IPv4 and UDP/IPv6 Datagrams
Chapter 7의 IPv4/IPv6 translation framework와 Chapter 8의 ICMP translation처럼, UDP도 IPv4와 IPv6 사이에서 translation될 수 있다. UDP-specific issue는 checksum이다. UDP/IPv4에서는 Checksum field가 0일 수 있지만, UDP/IPv6에서는 checksum이 mandatory이므로 0이 허용되지 않는다.
Translation 규칙을 요약하면 다음과 같다.
| 입력 datagram | Translation 문제 | 처리 |
|---|---|---|
complete UDP/IPv4, checksum 0 | UDP/IPv6에서는 checksum mandatory | translator가 full pseudo-header checksum을 계산하거나 packet drop. configuration option 필요 |
| UDP checksum nonzero | address mapping이 checksum-neutral이 아니면 checksum 변경 필요 | pseudo-header 변경을 반영해 checksum update |
fragmented UDP/IPv4, checksum 0, stateless translator | 모든 fragment 재조립 없이 UDP/IPv6 checksum 계산 불가 | drop |
fragmented UDP/IPv4, checksum 0, stateful translator/NAT64 | fragments reassembly 가능 | checksum 계산 후 translation 가능 |
| fragmented UDP/IP with computed checksum | 일반 fragment translation 규칙 적용 | Chapter 7 방식대로 처리 |
즉 UDP translation에서 가장 위험한 조합은 IPv4 UDP checksum이 0이고 datagram이 fragmented된 상태다. Stateless translator는 UDP/IPv6에 필요한 checksum을 만들 수 없으므로 drop해야 한다. Stateful translator는 fragment를 reassemble할 수 있지만, 그만큼 state와 buffer를 사용한다.
10.13 UDP in the Internet
Internet traffic에서 UDP 비중은 측정 지점과 시기에 따라 다르지만, 원문이 인용한 연구들은 UDP가 관찰 traffic의 10-40% 정도를 차지할 수 있고 peer-to-peer, multimedia, VoIP 사용 증가와 함께 중요해졌다고 설명한다. 그래도 packet 수와 byte 수 기준으로는 TCP traffic이 여전히 우세하다.
Fragmented traffic은 전체 Internet traffic에서 매우 작다. 인용 연구에서는 packet 기준 약 0.3%, byte 기준 약 0.8% 정도였지만, 그중 UDP가 큰 비중을 차지했다. Fragmented traffic 중 UDP가 약 68.3%였고, UDP-based multimedia와 VPN tunnel 같은 encapsulated/tunneled traffic이 주요 원인으로 나타났다.
Fragmentation이 생기는 주된 원인은 두 가지다.
| 원인 | 설명 |
|---|---|
| careless encapsulation | VPN/tunnel처럼 여러 layer header가 추가되어 원래 1500-byte MTU에 맞던 packet이 더 이상 맞지 않음 |
| PMTUD/adaptation 부족 | video처럼 큰 UDP message를 쓰는 application이 path MTU에 맞춰 size를 줄이지 않음 |
특히 불행한 case는 원래 IPv4 packet에는 DF bit를 set해 PMTUD를 하려 했지만, 그것을 다시 UDP tunnel 안에 넣는 과정에서 outer UDP/IP packet에는 DF가 없어서 fragmentation이 발생하는 경우다. 이러면 원래 application은 fragmentation 발생 사실을 알지 못하고 PMTUD의 의미도 약해진다.
10.14 Attacks Involving UDP and IP Fragmentation
UDP 관련 공격은 대체로 shared resource exhaustion이나 implementation bug exploitation으로 이어진다. UDP는 sender rate를 protocol이 제어하지 않으므로, 단순히 대량 UDP traffic을 빠르게 보내는 것만으로도 link capacity, router queue, server input queue를 고갈시킬 수 있다. 악의가 없어도 잘못 설계된 high-rate UDP application이 같은 문제를 만들 수 있다.
UDP magnification attack은 더 교묘하다. Attacker가 작은 request를 보내 다른 시스템들이 훨씬 큰 response를 victim에게 보내게 만든다. fraggle attack은 UDP sender가 source IP address를 victim으로 spoofing하고 destination을 directed broadcast address 같은 broadcast 형태로 설정한다. 여러 server가 request에 응답하면 response가 모두 victim에게 몰린다. 이는 Chapter 8의 ICMP smurf attack과 같은 amplification 구조다.
Fragmentation attack은 reassembly code의 복잡성을 노린다.
| 공격 | 핵심 아이디어 |
|---|---|
| zero-data fragments | data가 없는 fragment를 보내 IPv4 reassembly bug를 유발 |
| teardrop attack | overlapping Fragment Offset field를 가진 fragment series로 crash 또는 이상 동작 유발 |
| UDP header overwrite variant | later overlapping fragment가 earlier fragment의 UDP header를 덮도록 구성 |
| ping of death | reassembly 후 IPv4 maximum size 65,535 bytes를 넘는 datagram이 되도록 fragment 조작 |
IPv6에서는 overlapping fragments가 RFC5722에 의해 금지되었다. Ping of death의 원리는 Fragment Offset이 최대 8191까지 가능하고, 이는 byte offset 8191 * 8 = 65,528에 해당한다는 점을 악용한다. 이 offset에서 7 bytes를 넘는 fragment가 reassembled되면 maximum datagram size 65,535 bytes를 초과할 수 있다. 현대 stack은 이런 case를 방어하지만, fragmentation은 여전히 보안상 까다로운 처리 경로다.
10.15 Summary
UDP가 IP 위에 추가로 제공하는 핵심 기능은 port number와 checksum뿐이다. UDP는 flow control, congestion control, error correction, sequencing, duplicate elimination을 제공하지 않는다. 대신 message boundary를 보존하고, UDP/IPv4에서는 optional이지만 기본적으로 켜야 하는 checksum, UDP/IPv6에서는 mandatory checksum을 제공한다.
UDP는 connection establishment overhead를 피하고 싶을 때, broadcast/multicast 같은 multipoint delivery를 사용할 때, TCP의 heavyweight reliability semantics가 필요 없거나 application이 직접 reliability를 설계하려 할 때 적합하다. VoIP/RTP, SIP, multimedia, peer-to-peer, DNS, DHCP, NAT traversal(STUN), IPv6 transition(Teredo), IPsec NAT traversal 같은 영역에서 UDP가 자주 등장하는 이유가 여기에 있다.
IP fragmentation은 UDP와 함께 이해해야 한다. UDP application은 큰 datagram을 쉽게 만들 수 있고, 그 결과 MTU를 넘으면 fragmentation이 발생한다. Fragment 중 하나만 사라져도 전체 datagram이 사라지고, UDP header가 첫 fragment에만 있어 firewall/NAT/translator가 later fragment를 처리하기 어렵다. 가능하면 PMTUD와 application-level sizing으로 fragmentation을 피하는 설계가 좋다.
연결 관계
- Chapter 3 Link Layer: MTU, Ethernet 1500-byte payload, CRC와 UDP checksum의 역할 차이.
- Chapter 4 ARP: fragmentation된 UDP datagram을 보내기 전 ARP resolution과 queueing 문제가 발생한다.
- Chapter 5 IP: IPv4 Total Length, Identification, Fragment Offset, MF, IPv6 Fragment header, jumbogram이 이 장의 기반이다.
- Chapter 7 NAT: UDP pseudo-header checksum, Teredo, STUN/NAT traversal, UDP translation에서 checksum update가 연결된다.
- Chapter 8 ICMP: Port Unreachable, Packet Too Big, Time Exceeded code 1이 UDP/fragmentation 동작을 feedback한다.
- Chapter 9 Broadcast/Multicast: UDP는 broadcast/multicast application에서 자연스러운 transport다.
- Chapter 11 DNS: DNS는 UDP datagram size, truncation, TCP fallback을 이해하는 대표 application이다.
- Chapter 15-16 TCP: TCP는 stream abstraction, retransmission, congestion control로 UDP와 대비된다.
오해하기 쉬운 내용
| 오해 | 정정 |
|---|---|
| UDP는 아무 error detection도 없다 | UDP checksum이 있다. IPv4에서는 optional이지만 기본 enabled여야 하고, IPv6에서는 mandatory다 |
| UDP write가 여러 packet으로 나뉘어도 receiver가 일부만 받을 수 있다 | UDP는 datagram boundary를 보존한다. 단, IP fragmentation은 UDP 아래에서 일어나며 하나라도 잃으면 전체 UDP datagram이 손실된다 |
| Fragmentation은 router가 중간에서 다시 합칠 수 있다 | IP fragments는 final destination에서만 reassembly된다 |
| UDP port number는 TCP port number와 충돌한다 | TCP와 UDP port space는 transport protocol별로 독립이지만, well-known service는 편의상 같은 번호를 쓰는 경우가 많다 |
| Wildcard UDP server가 항상 먼저 datagram을 받는다 | Specific local address binding이 wildcard보다 우선한다 |
UDP server가 ESTABLISHED로 보이면 TCP처럼 connection이 생긴 것이다 | UDP endpoint의 local/foreign address pair가 고정되었다는 구현 표시일 뿐, UDP protocol connection은 아니다 |
| PMTUD는 UDP application에 항상 투명하다 | ICMP PTB가 application timing/API와 맞지 않으면 error만 보이거나 feedback을 놓칠 수 있다 |
면접 질문
- UDP가 TCP와 달리 message boundary를 보존한다는 말은 packetization 관점에서 무슨 뜻인가?
- UDP checksum에 pseudo-header가 포함되는 이유는 무엇이며, 이것이 NAT와 어떤 문제를 만드는가?
- UDP/IPv4 checksum은 optional인데 UDP/IPv6 checksum은 mandatory인 이유는 무엇인가?
- Ethernet MTU 1500에서 IPv4 option이 없을 때 fragmentation 없이 보낼 수 있는 UDP payload 최대값은 왜 1472 bytes인가?
- IPv4 fragmentation에서 Identification, Fragment Offset, MF field는 각각 reassembly에 어떻게 쓰이는가?
- Fragment 중 하나만 손실되어도 전체 UDP datagram이 손실되는 이유는 무엇인가?
- PMTUD가 ICMP PTB에 의존할 때 firewall이 ICMP를 drop하면 어떤 문제가 생기는가?
- UDP server에서 wildcard binding과 specific binding이 동시에 있을 때 datagram delivery 우선순위는 어떻게 되는가?
- Broadcast/multicast UDP datagram과 unicast UDP datagram은 multiple endpoints per port 상황에서 delivery 방식이 어떻게 다른가?
- Stateless IPv4/IPv6 translator가 fragmented UDP/IPv4 datagram with zero checksum을 UDP/IPv6로 변환할 수 없는 이유는 무엇인가?
10.16 References
이 장에서 개념 이해와 직접 연결되는 표준은 다음 정도를 중심으로 기억하면 된다.
| Reference | 연결되는 내용 |
|---|---|
RFC0768 | UDP 기본 specification |
RFC1122 | UDP checksum default, ARP/fragmentation host requirements |
RFC1191 | IPv4 Path MTU Discovery |
RFC2460 | IPv6, UDP/IPv6 pseudo-header checksum requirement |
RFC2675 | IPv6 jumbograms |
RFC3128 | tiny fragment variant protection |
RFC3828 | UDP-Lite |
RFC4380 | Teredo |
RFC4787 | NAT behavioral requirements for UDP |
RFC4821 | Packetization Layer Path MTU Discovery |
RFC5405 | UDP usage guidelines for application designers |
RFC5722 | IPv6 overlapping fragments 금지 |