Chapter 1. Introduction
- 과목: Operating System
- 기준 교재: Operating System Concepts 10th
- 관련 페이지: PDF pp. 29-82
- 우선순위: 필수
개요
운영체제(operating system)는 사용자와 컴퓨터 하드웨어(computer hardware) 사이에서 프로그램이 편리하고 효율적으로 실행될 수 있는 환경을 제공하는 소프트웨어다. 동시에 CPU, memory, storage, I/O devices 같은 자원을 직접 관리하고, 여러 프로그램이 같은 하드웨어를 공유할 때 충돌하지 않도록 조정한다. 이 장은 이후 장의 출발점으로서 computer-system organization, computer-system architecture, operating-system operations, resource management, protection/security, virtualization, distributed systems, kernel data structures, computing environments, free/open-source operating systems를 넓게 연결한다.
운영체제는 하나의 작은 프로그램이 아니라 큰 시스템이다. 그래서 설계할 때는 전체 목표를 먼저 정하고, 입력(input), 출력(output), 기능(function)이 명확한 구성요소로 나누어 만든다. 이 관점은 Chapter 2의 operating-system services, system calls, OS structure로 이어지고, Chapter 3 이후의 process, memory, storage, file, I/O 관리 주제로 확장된다.
핵심 개념
- 운영체제는 application programs가 하드웨어 자원을 올바르게 쓰도록 중재하는 intermediary다.
- 사용자 관점(user view)에서는 ease of use, responsiveness, 편의성이 중요하고, 시스템 관점(system view)에서는 resource allocation, control, fairness, efficiency가 중요하다.
- 운영체제의 핵심 실행 부분은 보통 kernel이라고 부르며, system programs와 middleware는 kernel 밖에 있지만 운영체제 경험을 구성하는 중요한 계층이다.
- 현대 컴퓨터는 CPU, memory, device controllers, system bus, shared memory로 구성되며, I/O 완료나 오류 같은 비동기 사건은 interrupt로 CPU에 알려진다.
- interrupt는 interrupt vector, interrupt service routine, interrupt priority, maskable/nonmaskable interrupt 같은 장치로 빠르게 처리된다.
세부 정리
1.1 What Operating Systems Do
컴퓨터 시스템은 크게 hardware, operating system, application programs, user로 볼 수 있다. Hardware는 CPU, memory, I/O devices처럼 실제 계산 자원을 제공하고, application programs는 word processor, compiler, web browser처럼 사용자 문제를 풀기 위해 그 자원을 사용하는 방식을 정의한다. Operating system은 이 둘 사이에서 하드웨어를 제어하고 여러 application programs가 자원을 사용하도록 조정한다.
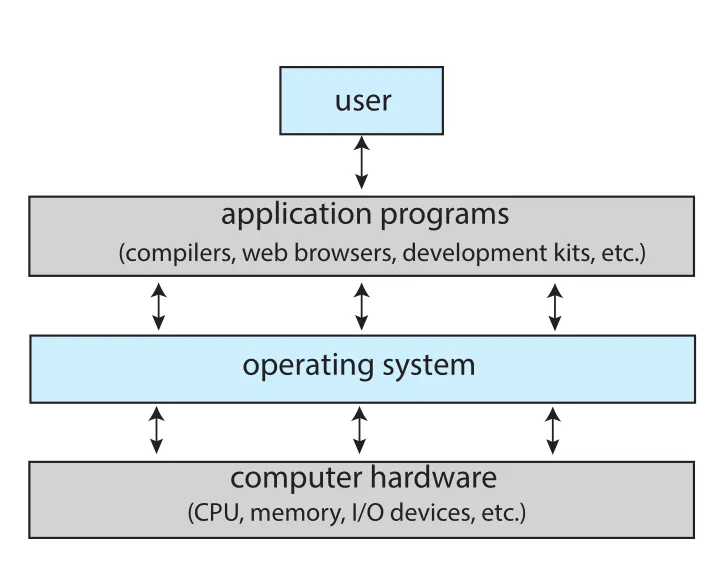
Figure 1.1 · PDF p. 32 · 컴퓨터 시스템을 user, application programs, operating system, hardware 계층으로 본 추상 구조
이 구조에서 운영체제는 정부(government)와 비슷하다. 정부 자체가 직접 생산 활동을 하는 것은 아니지만 사람들이 일을 할 수 있는 규칙과 환경을 제공하듯, 운영체제도 직접 사용자 문제를 해결하기보다는 다른 프로그램이 유용한 일을 할 수 있는 실행 환경을 제공한다.
User View
사용자 관점(user view)은 사용하는 시스템 형태에 따라 달라진다.
- 개인용 PC나 laptop에서는 한 사용자가 대부분의 자원을 독점하므로 운영체제 목표가 ease of use에 치우친다. Performance와 security도 고려하지만, 여러 사용자가 자원을 어떻게 나눠 쓰는지(resource utilization)는 상대적으로 덜 중요하다.
- Smartphone, tablet 같은 mobile devices에서는 touch screen, wireless network, voice recognition interface 같은 인터페이스가 중심이 된다. 운영체제는 제한된 전력과 이동성 안에서 앱 실행 환경과 사용자 입력을 조율한다.
- Embedded computers는 사용자가 직접 운영체제를 의식하지 않는 경우가 많다. 자동차, 가전, IoT 장치처럼 정해진 기능을 사용자 개입 없이 수행하도록 설계된다.
즉 운영체제의 “좋음”은 하나로 고정되지 않는다. 같은 operating system 개념이라도 interactive personal system에서는 반응성과 사용성이 중요하고, embedded system에서는 안정성, 자동 실행, 제한된 자원 사용이 더 중요해질 수 있다.
System View
시스템 관점(system view)에서 운영체제는 하드웨어와 가장 밀접하게 연결된 프로그램이며, 두 가지 역할로 설명된다.
첫째, 운영체제는 자원 할당자(resource allocator)다. CPU time, memory space, storage space, I/O devices 같은 자원을 여러 프로그램과 사용자 요청 사이에 배분한다. 이때 요청은 동시에 들어오고 서로 충돌할 수 있으므로, 운영체제는 효율성(efficiency)과 공정성(fairness)을 함께 고려해야 한다.
둘째, 운영체제는 제어 프로그램(control program)이다. User programs가 오류를 내거나 컴퓨터를 부적절하게 사용하는 것을 막고, 특히 I/O devices의 동작을 제어한다. 이 관점은 뒤의 protection, security, user mode/kernel mode, system call로 바로 이어진다.
Defining Operating Systems
운영체제를 완전히 만족스럽게 정의하기는 어렵다. 컴퓨터는 embedded devices부터 cloud computing environments까지 매우 다양한 형태로 존재하고, 운영체제가 포함하는 기능 범위도 시스템마다 크게 다르기 때문이다.
이 책에서 따르는 실용적 정의는 다음과 같다.
- Kernel: 컴퓨터에서 항상 실행 중인 핵심 프로그램이다. 하드웨어 제어, 자원 관리, 보호 기능의 중심이 된다.
- System programs: 운영체제와 관련되어 시스템 관리와 실행 환경을 돕지만 반드시 kernel 자체는 아니다.
- Application programs: 시스템 운영 자체가 아니라 사용자 작업을 수행하는 프로그램이다.
- Middleware: 특히 mobile operating systems에서 application developers에게 database, multimedia, graphics 같은 공통 framework services를 제공하는 계층이다.
따라서 넓은 의미의 operating system은 항상 실행되는 kernel만이 아니라, system programs와 middleware까지 포함해 사용자와 개발자가 체감하는 실행 환경 전체로 볼 수 있다. 다만 이 책의 핵심 분석 대상은 general-purpose operating systems의 kernel이다.
1.2 Computer-System Organization
현대 general-purpose computer system은 하나 이상의 CPU, 여러 device controllers, shared memory, 그리고 이들을 연결하는 common bus 또는 system bus로 구성된다. Device controller는 disk drive, audio device, graphics display 같은 특정 장치 유형을 담당하고, 자체 local buffer storage와 special-purpose registers를 가진다.
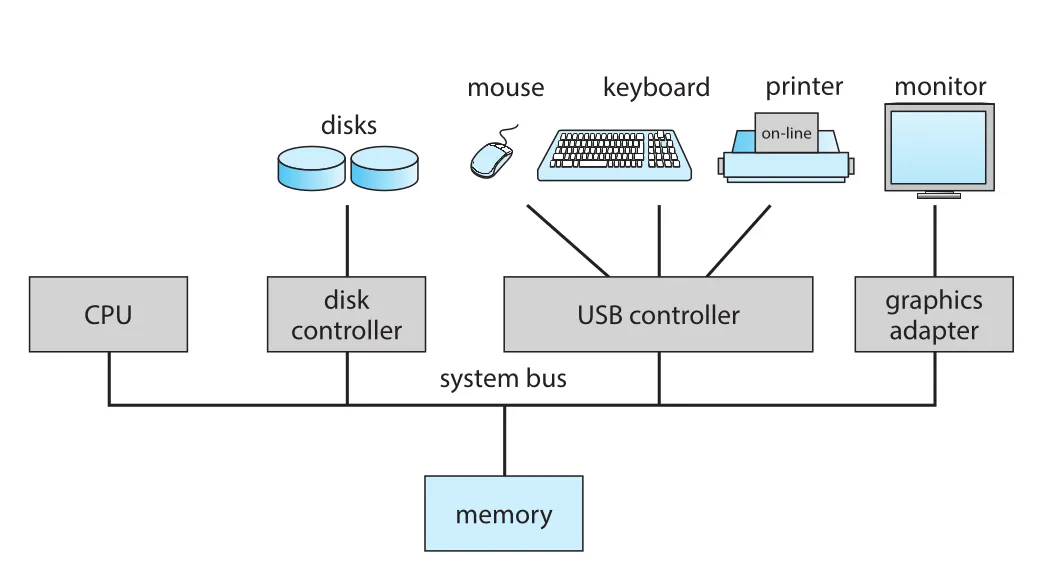
Figure 1.2 · PDF p. 35 · CPU, device controllers, memory가 system bus로 연결된 전형적 PC 구조
운영체제는 각 device controller마다 보통 device driver를 둔다. Device driver는 controller의 세부 동작을 이해하고, 운영체제의 나머지 부분에는 장치를 균일한 인터페이스로 보이게 한다. CPU와 device controllers는 병렬로 실행될 수 있고, shared memory 접근을 두고 경쟁할 수 있으므로 memory controller가 memory access를 동기화한다.
Interrupts
Interrupt는 하드웨어나 장치가 CPU의 주의를 필요로 하는 사건을 알리는 메커니즘이다. 예를 들어 프로그램이 I/O를 시작하면 device driver가 device controller의 registers에 명령을 적고, controller는 장치와 local buffer 사이에서 데이터를 옮긴다. 작업이 끝나면 controller는 interrupt를 발생시켜 device driver와 운영체제에 완료, 오류, busy 같은 상태를 알린다.
CPU가 interrupt를 받으면 현재 실행을 멈추고 정해진 위치의 interrupt service routine 또는 interrupt handler로 제어를 넘긴다. Handler는 필요한 상태를 저장하고, interrupt 원인을 확인하고, 필요한 처리를 수행한 뒤 상태를 복원하고 return from interrupt instruction으로 이전 계산을 재개한다. 이때 interrupted computation은 논리적으로 interrupt가 없었던 것처럼 이어진다.
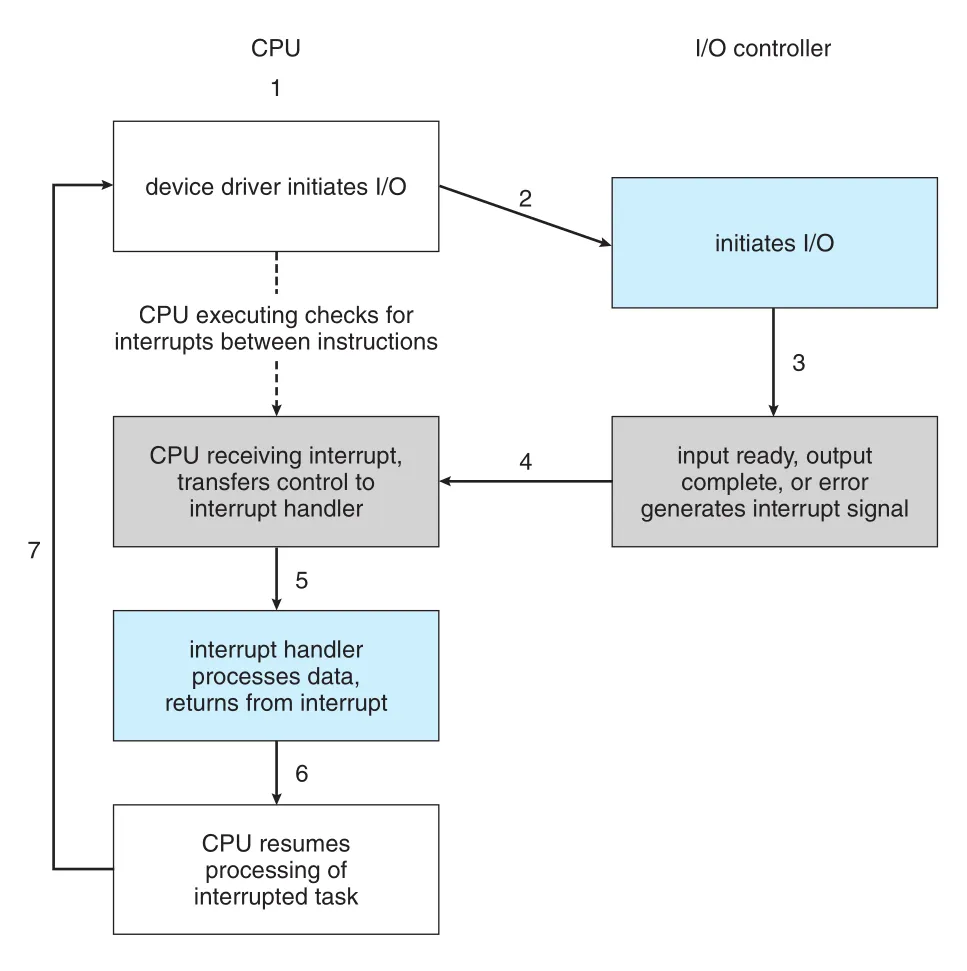
Figure 1.4 · PDF p. 38 · device driver가 I/O를 시작하고 interrupt handler가 완료 사건을 처리하는 interrupt-driven I/O cycle
Interrupt 처리는 매우 자주 발생하므로 빠른 dispatch가 중요하다. 단일 handler가 모든 장치를 검사하면 느리기 때문에, 대부분의 시스템은 interrupt number를 interrupt vector의 index로 사용해 해당 interrupt service routine 주소를 바로 찾는다. 이 방식은 Windows와 UNIX처럼 다른 운영체제에서도 공통적으로 사용된다.
Interrupt 구현에서 중요한 용어는 다음과 같다.
| 용어 | 의미 | 왜 중요한가 |
|---|---|---|
| interrupt-request line | CPU가 명령어 실행 사이에 감지하는 interrupt 요청 신호선 | CPU가 비동기 사건을 알아차리는 기본 통로 |
| interrupt vector | interrupt number를 handler 주소로 매핑하는 table | 빠른 interrupt dispatch 제공 |
| interrupt handler / interrupt service routine | interrupt 원인을 처리하는 routine | 장치 완료, 오류, 예외 처리를 실제 수행 |
| interrupt chaining | vector entry가 handler list의 head를 가리키는 구조 | 큰 interrupt table과 느린 단일 검색 사이의 절충 |
| maskable interrupt | CPU가 임계 구간에서 잠시 비활성화할 수 있는 interrupt | critical instruction sequence 보호 |
| nonmaskable interrupt | 끌 수 없는 interrupt | unrecoverable memory error 같은 긴급 사건 처리 |
| interrupt priority levels | interrupt 간 우선순위 | urgent work를 먼저 처리하고 high-priority interrupt가 low-priority interrupt를 preempt 가능 |
Figure 1.5의 Intel event-vector table은 0-31번을 주로 nonmaskable error conditions에, 32-255번을 device-generated maskable interrupts 등에 배치하는 예를 보여준다. 특정 번호를 암기하는 것보다 중요한 점은 interrupt vector가 “사건 번호 → handler 주소” 매핑을 제공하고, priority와 masking으로 긴급도와 critical section을 조절한다는 것이다.
Interrupt는 운영체제와 하드웨어가 맞물리는 핵심 접점이다. 이후 system call, exception, timer interrupt, process scheduling, I/O completion, page fault 모두 interrupt/exception 처리 모델 위에서 이해된다.
Storage Structure
CPU는 instruction을 memory에서만 가져와 실행할 수 있다. 따라서 프로그램은 실행되기 전에 memory로 적재되어야 한다. 일반적인 main memory는 random-access memory(RAM)이고, 보통 dynamic random-access memory(DRAM)로 구현된다. RAM은 빠르지만 volatile storage라서 전원이 꺼지면 내용이 사라진다.
컴퓨터 저장 단위는 bit에서 시작한다. Byte는 8 bits이고, 대부분의 컴퓨터에서 편리하게 옮길 수 있는 최소 저장 단위다. Word는 특정 architecture의 native data unit으로, 예를 들어 64-bit registers와 64-bit memory addressing을 가진 컴퓨터는 보통 64-bit, 즉 8-byte word를 자연스러운 연산 단위로 사용한다. KB, MB, GB, TB, PB는 보통 1024의 거듭제곱 단위로 설명되지만, 제조사 표기에서는 10진수로 둥글게 말하는 경우도 있다. 반면 networking measurements는 데이터를 bit 단위로 이동시키므로 bits를 주로 쓴다.
Von Neumann architecture의 instruction-execution cycle은 대략 다음 순서다.
- Program counter가 가리키는 memory address에서 instruction을 fetch한다.
- Instruction register에 저장한 뒤 decode한다.
- 필요하면 operands를 memory에서 fetch해 internal register로 가져온다.
- 연산을 수행하고 결과를 register 또는 memory에 store한다.
Memory unit은 주소 흐름만 본다. 그 주소가 instruction counter, indexing, indirection, literal address 중 무엇으로 생겼는지, instruction인지 data인지는 memory 입장에서 구분하지 않는다. 운영체제는 결국 실행 중인 프로그램이 만들어내는 memory address sequence와 그 주소들이 실제 자원에 어떻게 매핑되는지를 관리하게 된다.
Main memory만으로 모든 프로그램과 데이터를 영구히 보관할 수 없는 이유는 두 가지다. 첫째, 용량이 충분하지 않다. 둘째, volatile이라 전원이 사라지면 내용이 사라진다. 그래서 대부분의 시스템은 secondary storage를 main memory의 확장처럼 사용한다. 대표적인 secondary-storage devices는 hard-disk drives(HDDs)와 nonvolatile memory(NVM) devices다.
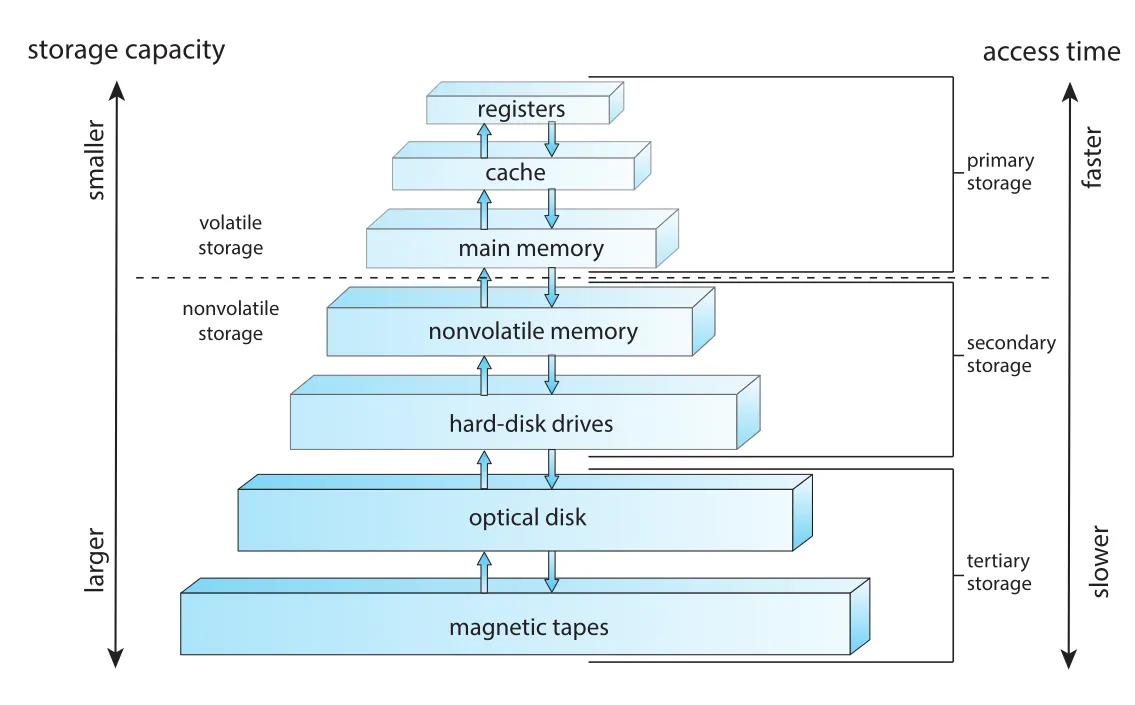
Figure 1.6 · PDF p. 41 · registers에서 magnetic tapes까지 이어지는 storage-device hierarchy
Storage hierarchy의 핵심 trade-off는 speed, size, volatility다. CPU에 가까울수록 registers, cache, main memory처럼 작고 빠르며 비싸고, 멀수록 HDD, optical disk, magnetic tapes처럼 크고 느리며 저렴하다. Volatile storage는 전원이 꺼지면 내용을 잃고, nonvolatile storage(NVS)는 내용을 유지한다. 이 책의 용어에서는 volatile storage를 보통 memory라고 부르고, NVS 중 secondary storage를 많이 다룬다.
NVS는 크게 mechanical storage와 electrical storage로 나눌 수 있다.
| 구분 | 예 | 특성 |
|---|---|---|
| mechanical storage | HDD, optical disk, magnetic tape | 크고 byte당 저렴하지만 느림 |
| electrical storage / NVM | flash memory, SSD, FRAM, NRAM | 빠르지만 더 비싸고 상대적으로 작음 |
완전한 storage system 설계는 “필요한 만큼만 비싼 빠른 memory를 쓰고, 가능한 한 많은 데이터를 저렴한 nonvolatile storage에 둔다”는 균형 문제다. Cache는 두 구성요소 사이의 access time 또는 transfer rate 차이가 클 때 성능을 보완하기 위해 들어간다. 이 관점은 Chapter 10의 virtual memory, Chapter 11의 mass-storage structure, Chapter 14-15의 file system 구현으로 이어진다.
I/O Structure
운영체제 코드의 큰 부분은 I/O 관리에 쓰인다. 이유는 두 가지다. I/O는 시스템 신뢰성과 성능에 직접 영향을 주고, 장치 종류가 매우 다양해 균일하게 다루기 어렵기 때문이다.
Interrupt-driven I/O는 keyboard 입력처럼 작은 데이터 이동에는 적합하지만, NVS I/O처럼 큰 block을 옮길 때는 interrupt가 너무 자주 발생해 overhead가 커진다. 이를 줄이기 위해 direct memory access(DMA)를 사용한다. DMA에서는 운영체제와 device driver가 buffer, pointer, counter를 설정한 뒤, device controller가 CPU 개입 없이 device와 main memory 사이의 block 전체를 직접 전송한다. CPU는 block마다 한 번의 interrupt만 받으므로 그 사이 다른 작업을 수행할 수 있다.
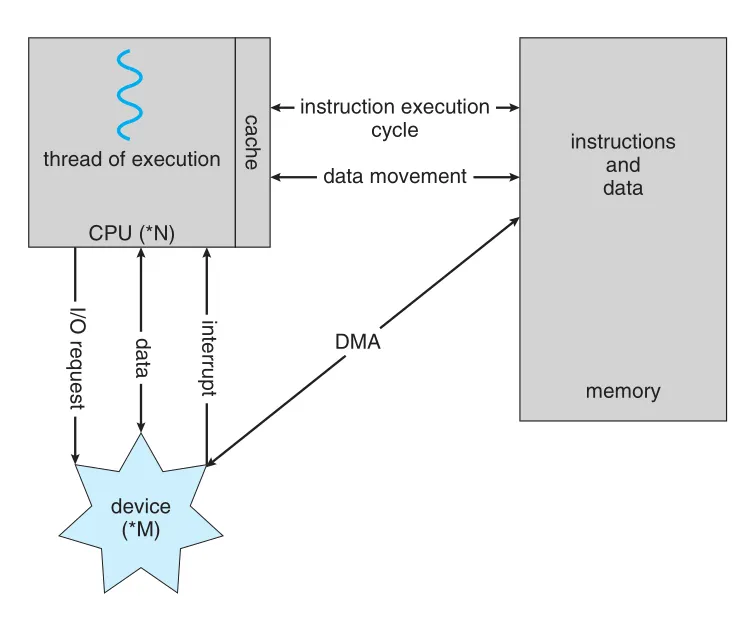
Figure 1.7 · PDF p. 43 · CPU, cache, memory, device, DMA, interrupt가 함께 동작하는 현대 컴퓨터 시스템
Bus architecture에서는 여러 구성요소가 shared bus를 두고 경쟁하지만, 일부 high-end systems는 switch architecture를 사용해 여러 구성요소가 동시에 통신할 수 있게 한다. 이런 구조에서는 DMA의 장점이 더 커진다.
1.3 Computer-System Architecture
Computer-system architecture는 general-purpose processors가 몇 개 있고 어떻게 연결되는지에 따라 크게 single-processor systems, multiprocessor systems, clustered systems로 볼 수 있다.
Single-Processor Systems
전통적인 single-processor system은 하나의 general-purpose CPU와 하나의 processing core를 가진다. 여기서 core는 instruction을 실행하고 local data를 저장하는 register를 가진 기본 계산 단위다. 시스템에는 disk controller, keyboard controller, graphics controller처럼 special-purpose processors도 있을 수 있지만, 이들은 제한된 instruction set만 실행하고 user process를 실행하지 않는다.
따라서 keyboard 안의 microprocessor나 disk-controller microprocessor가 있다고 해서 multiprocessor system이 되는 것은 아니다. 기준은 “general-purpose CPU/core가 몇 개 user process와 OS 작업을 수행할 수 있는가”다. 이 정의에 따르면 현대 시스템 대부분은 더 이상 순수한 single-processor system이 아니다.
Multiprocessor Systems
Multiprocessor system은 둘 이상의 processor를 사용해 throughput을 높이는 구조다. 그러나 processor가 N개라고 성능이 정확히 N배가 되지는 않는다. 협력 overhead, shared resource contention, memory/bus contention 때문에 실제 speed-up은 N보다 작다.
가장 흔한 구조는 symmetric multiprocessing(SMP)이다. SMP에서는 각 peer CPU processor가 user processes뿐 아니라 operating-system functions도 수행할 수 있다. 각 CPU는 own registers와 local cache를 가지지만, physical memory는 system bus를 통해 공유한다.
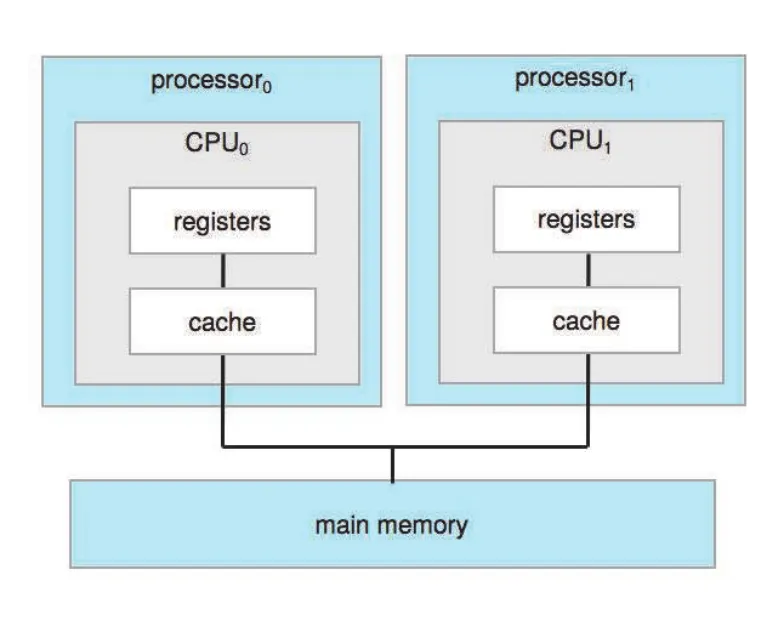
Figure 1.8 · PDF p. 45 · 여러 CPU가 memory를 공유하는 symmetric multiprocessing(SMP) 구조
SMP의 장점은 여러 process가 동시에 실행될 수 있다는 점이다. N CPUs가 있으면 이상적으로 N processes가 동시에 실행될 수 있다. 하지만 CPU별 부하가 불균형하면 한 CPU는 idle이고 다른 CPU는 overloaded일 수 있다. 이를 줄이려면 processors가 scheduling state, memory state 같은 일부 data structures를 공유해야 하며, 이 공유는 Chapter 5의 CPU scheduling과 Chapter 6의 synchronization 문제로 이어진다.
현대 multiprocessor 개념에는 multicore systems도 포함된다. Multicore는 하나의 physical chip 안에 여러 computing cores를 넣은 구조다. On-chip communication은 chip 간 통신보다 빠르고, 하나의 multicore chip은 여러 single-core chips보다 전력 효율이 좋다. 다만 operating system 관점에서는 N cores가 대체로 N standard CPUs처럼 보이므로, OS와 application programmer는 이 cores를 효율적으로 사용하도록 설계해야 한다. 이 문제는 Chapter 4의 threads and concurrency와 직접 연결된다.
NUMA(non-uniform memory access)는 processor 또는 processor group마다 local memory를 두고, 전체는 shared system interconnect로 하나의 physical address space를 공유하는 구조다.
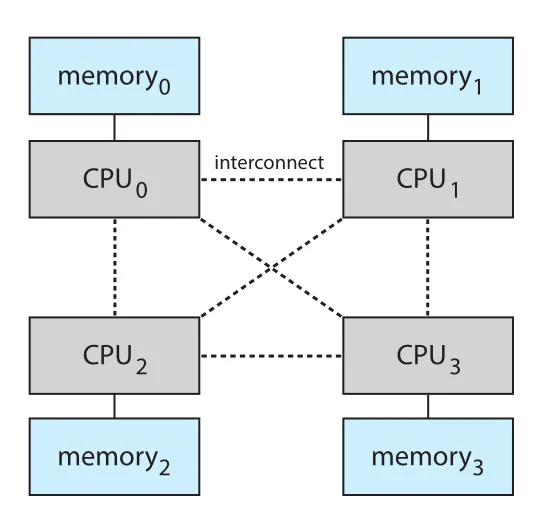
Figure 1.10 · PDF p. 47 · CPU마다 local memory를 두어 확장성을 높이는 NUMA multiprocessing architecture
NUMA의 장점은 CPU가 자기 local memory에 접근할 때 빠르고 system interconnect contention이 작다는 것이다. 단점은 remote memory 접근 latency가 커져 성능 penalty가 생긴다는 점이다. 운영체제는 CPU scheduling과 memory management를 통해 “프로세스가 실행되는 CPU와 그 process가 자주 쓰는 memory의 위치”를 가깝게 유지해야 한다.
Clustered Systems
Clustered system은 여러 독립 시스템 또는 nodes를 network로 묶은 loosely coupled 구조다. 각 node는 보통 multicore system이고, cluster는 shared storage와 LAN 또는 InfiniBand 같은 빠른 interconnect로 연결된다.
Cluster의 대표 목적은 high availability다. 일부 node가 실패해도 서비스를 계속 제공하기 위해 redundancy를 둔다. Cluster software는 node들을 감시하다가 monitored machine이 실패하면 다른 machine이 storage ownership을 가져가고 applications를 재시작한다. 사용자는 짧은 service interruption만 경험한다.
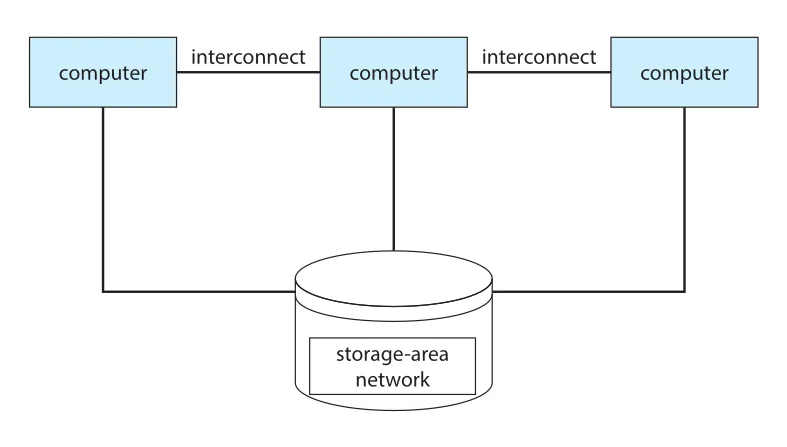
Figure 1.11 · PDF p. 49 · 여러 computer가 interconnect와 storage-area network로 연결된 clustered system 구조
Cluster 관련 용어는 다음처럼 구분된다.
| 용어 | 의미 |
|---|---|
| graceful degradation | 일부 hardware가 실패해도 살아남은 hardware 수준에 비례해 서비스를 계속 제공 |
| fault tolerant | 단일 구성요소 실패를 견디고 계속 동작할 수 있는 시스템 |
| asymmetric clustering | active server 하나와 hot-standby machine이 있는 구조 |
| symmetric clustering | 둘 이상의 hosts가 applications를 실행하면서 서로 감시하는 구조 |
| parallelization | 문제를 여러 부분으로 나누어 nodes/cores에서 병렬 실행하고 결과를 결합하는 기법 |
| distributed lock manager(DLM) | shared disk/data에 대한 conflicting operations를 막기 위한 distributed locking 계층 |
| storage-area network(SAN) | 여러 시스템이 storage pool에 접근할 수 있게 하는 전용 storage network |
Cluster는 high-performance computing에도 쓰인다. 여러 nodes가 하나의 application을 병렬로 실행하려면 application 자체가 parallelization을 고려해 작성되어야 한다. Hadoop 예시는 distributed file system, YARN, MapReduce가 cluster에서 data와 resource와 parallel computation을 나누어 관리하는 구조를 보여준다. 여기서 중요한 점은 특정 제품명이 아니라 “cluster에서는 계산, storage, scheduling, failure handling이 분산되어야 한다”는 설계 원리다.
1.4 Operating-System Operations
컴퓨터가 켜지거나 reboot될 때 처음 실행되는 프로그램은 bootstrap program이다. Bootstrap program은 보통 firmware에 저장되어 CPU registers, device controllers, memory contents 같은 시스템 요소를 초기화하고, operating-system kernel을 찾아 memory에 load한 뒤 실행을 시작한다.
Kernel이 실행되면 운영체제 서비스가 시작된다. 일부 서비스는 kernel 밖의 system programs가 제공하며, boot time에 memory로 올라와 system daemons로 계속 실행된다. Linux의 systemd처럼 첫 system program이 다른 daemons를 시작할 수 있다. Boot가 완료되면 시스템은 event를 기다린다.
Event는 대부분 interrupt로 신호된다. 여기에는 hardware interrupt뿐 아니라 trap 또는 exception도 포함된다. Trap/exception은 division by zero, invalid memory access 같은 오류로 발생하거나, user program이 운영체제 서비스를 요청하기 위해 system call을 실행할 때 발생한다.
Multiprogramming and Multitasking
단일 프로그램은 일반적으로 CPU와 I/O devices를 항상 바쁘게 유지하지 못한다. 어떤 process가 I/O를 기다리는 동안 CPU가 idle이 되면 자원이 낭비된다. Multiprogramming은 여러 processes를 memory에 동시에 두고, 하나가 I/O 등을 기다리면 운영체제가 다른 process로 CPU를 넘겨 CPU utilization을 높이는 방식이다.
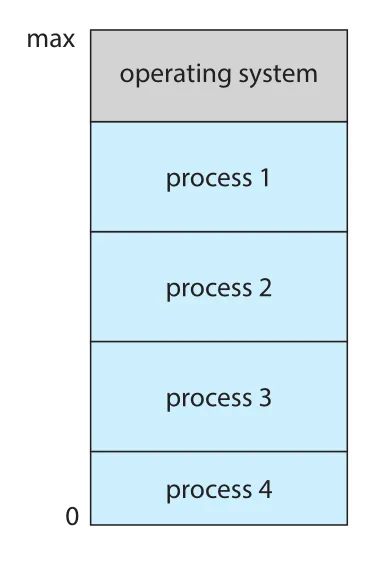
Figure 1.12 · PDF p. 51 · 여러 process가 memory에 동시에 올라간 multiprogramming system의 memory layout
Multitasking은 multiprogramming의 논리적 확장이다. CPU가 여러 processes 사이를 자주 switching하여 사용자가 빠른 response time을 느끼게 한다. Interactive I/O는 사람의 입력 속도에 묶이므로 컴퓨터 기준에서는 매우 느리다. 따라서 사용자가 keyboard, mouse, touch screen 입력을 하는 동안 운영체제는 CPU를 다른 process에 할당한다.
Multiprogramming과 multitasking은 다음 운영체제 기능을 필수로 요구한다.
| 필요한 기능 | 이유 | 이어지는 장 |
|---|---|---|
| memory management | 여러 process를 memory에 동시에 올리고 서로 침범하지 않게 해야 함 | Chapter 9, Chapter 10 |
| CPU scheduling | 여러 ready processes 중 다음 실행 대상을 골라야 함 | Chapter 5 |
| virtual memory | process 전체가 physical memory에 없어도 실행되게 하여 큰 프로그램 실행과 logical memory abstraction 제공 | Chapter 10 |
| file system | 프로그램과 데이터를 secondary storage에 구조화해 저장 | Chapter 13-15 |
| storage management | secondary storage를 효율적으로 배치하고 접근 | Chapter 11 |
| protection | 여러 process가 서로와 OS 자원을 부적절하게 침범하지 못하게 함 | Chapter 17 |
| synchronization and communication | concurrent processes가 질서 있게 협력하게 함 | Chapter 6, Chapter 7 |
| deadlock handling | processes가 서로를 영원히 기다리는 상황을 다룸 | Chapter 8 |
Dual-Mode and Multimode Operation
운영체제와 사용자 프로그램은 같은 hardware와 software resources를 공유한다. 따라서 잘못된 user program이나 malicious program이 다른 프로그램 또는 operating system 자체를 망가뜨리지 못하게 해야 한다. 이를 위해 대부분의 컴퓨터 시스템은 execution mode를 구분하는 hardware support를 제공한다.
가장 기본은 dual-mode operation이다.
- User mode: user application을 대신해 실행되는 모드다. 일반 명령만 실행할 수 있다.
- Kernel mode: operating system을 대신해 실행되는 모드다. privileged instructions를 실행할 수 있다.
- Mode bit: 현재 모드를 표시하는 hardware bit다. 보통 kernel mode는 0, user mode는 1로 표현된다.
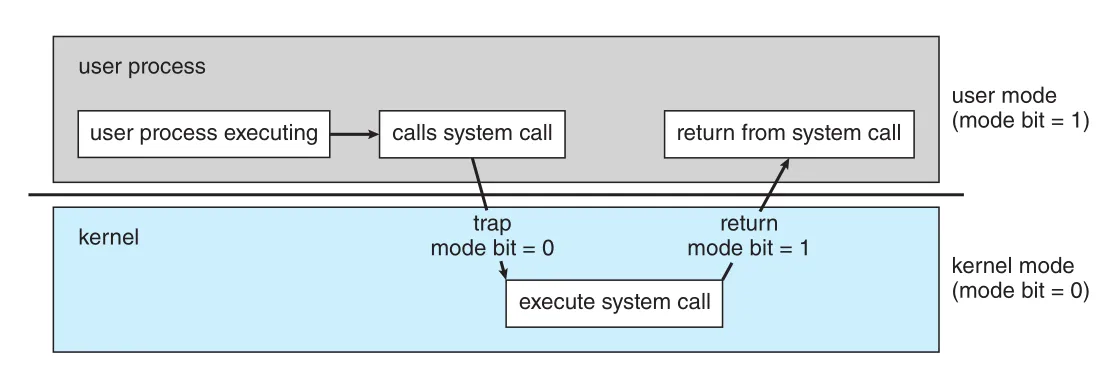
Figure 1.13 · PDF p. 53 · user process가 system call을 호출하면 trap을 통해 kernel mode로 전환되고, 처리 후 user mode로 돌아가는 흐름
System boot time에는 hardware가 kernel mode에서 시작한다. 운영체제가 load된 뒤 user applications는 user mode에서 시작된다. Trap, interrupt, system call이 발생하면 hardware가 mode bit를 0으로 바꾸어 kernel mode로 전환한다. 운영체제가 user program에 제어를 넘기기 전에는 다시 mode bit를 1로 바꾸어 user mode로 돌아간다.
Privileged instructions는 user mode에서 실행되면 위험한 명령이다. 예를 들어 I/O control, timer management, interrupt management, kernel mode로 전환하는 명령은 user program이 직접 실행할 수 없어야 한다. User mode에서 privileged instruction 실행을 시도하면 hardware는 그 명령을 실행하지 않고 illegal operation으로 보아 operating system에 trap한다.
Multimode operation은 이 구조를 더 세분화한 것이다. Intel processors의 protection rings는 ring 0을 kernel mode, ring 3을 user mode로 사용하고, ARMv8은 더 많은 mode를 제공한다. Virtualization을 지원하는 CPU는 virtual machine manager(VMM)가 guest OS를 관리할 수 있도록 별도 mode를 제공하기도 한다. 이때 VMM은 user process보다 권한이 크지만 host kernel보다는 제한된 권한을 가진다.
System call은 user program이 운영체제만 수행할 수 있는 작업을 요청하는 통로다. 보통 특정 interrupt vector 위치로 trap을 발생시키며, hardware는 이를 software interrupt처럼 처리한다. Kernel은 요청된 system call 종류와 parameters를 확인하고, parameter가 correct/legal인지 검사한 뒤 요청을 수행하고 system call 다음 instruction으로 제어를 반환한다. 이 구조는 Chapter 2의 system calls에서 구체화된다.
Timer
Timer는 운영체제가 CPU 통제권을 잃지 않기 위한 장치다. User program이 infinite loop에 빠지거나 system service를 호출하지 않은 채 CPU를 계속 점유하면 운영체제가 개입할 수 있어야 한다. 운영체제는 user program에 제어를 넘기기 전에 timer를 설정하고, 지정된 시간이 지나면 timer interrupt가 발생하도록 한다.
Variable timer는 보통 fixed-rate clock과 counter로 구현된다. Clock tick마다 counter가 감소하고, counter가 0이 되면 interrupt가 발생한다. Timer interrupt가 발생하면 제어권은 자동으로 운영체제에 넘어가며, 운영체제는 해당 프로그램을 오류로 처리하거나 더 실행할 시간을 줄 수 있다. Timer 내용을 바꾸는 명령은 당연히 privileged instruction이어야 한다.
Linux의 HZ와 jiffies 예시는 timer가 실제 kernel에서 시간 측정과 주기적 interrupt의 기준으로 쓰인다는 점을 보여준다. HZ는 초당 timer interrupts 빈도를 나타내고, jiffies는 boot 이후 발생한 timer interrupts 수를 나타낸다.
1.5 Resource Management
운영체제는 resource manager다. 이 장에서는 CPU, memory space, file-storage space, I/O devices를 중심으로 어떤 자원을 왜 관리해야 하는지 개괄한다.
Process Management
Program은 disk에 저장된 passive entity이고, process는 실행 중인 active entity다. 예를 들어 compiler 프로그램 파일 자체는 process가 아니지만, compiler가 CPU에서 실행되기 시작하면 process가 된다. 같은 program을 두 번 실행해도 두 process는 별도의 execution sequence다.
Single-threaded process는 다음에 실행할 instruction을 가리키는 program counter 하나를 가진다. Multithreaded process는 thread마다 program counter를 가진다. Process는 system의 work unit이고, 운영체제는 user processes와 system processes를 함께 관리한다. 이 processes는 single CPU core에서 multiplexing될 수도 있고, multiple CPU cores에서 parallel execution될 수도 있다.
Process management에서 운영체제가 맡는 활동은 다음과 같다.
- User/system processes 생성과 삭제
- Processes와 threads를 CPUs에 scheduling
- Processes의 suspend/resume
- Process synchronization mechanism 제공
- Process communication mechanism 제공
이 주제는 Chapter 3의 process, Chapter 4의 threads, Chapter 5의 CPU scheduling, Chapter 6-7의 synchronization/communication으로 이어진다.
Memory Management
Main memory는 CPU와 I/O devices가 공유하는 빠른 byte array다. 각 byte는 address를 가지며, CPU는 instruction-fetch cycle에서 instruction을 읽고 data-fetch cycle에서 data를 읽거나 쓴다. CPU가 disk data를 처리하려면 먼저 disk에서 main memory로 옮겨야 하고, instruction도 실행되려면 memory에 있어야 한다.
Program이 실행되려면 absolute addresses로 mapping되고 memory에 loaded되어야 한다. 실행 중에는 instruction과 data를 memory address로 접근하고, 종료되면 그 memory space가 다시 available 상태가 된다. 여러 programs를 memory에 동시에 유지하면 CPU utilization과 response time이 좋아지지만, 이를 위해 운영체제는 memory 사용 상태를 추적해야 한다.
Memory management의 핵심 책임은 다음과 같다.
- Memory의 어떤 부분이 사용 중인지, 어떤 process가 쓰는지 추적
- 필요할 때 memory space를 allocate/deallocate
- 어떤 processes 또는 process parts/data를 memory 안팎으로 옮길지 결정
각 memory-management algorithm은 특정 hardware support를 요구한다. 따라서 memory management는 순수 software 정책이 아니라 address translation, protection bit, page table 같은 hardware와 함께 설계된다.
File-System Management
운영체제는 storage의 물리적 특성을 숨기고, 사용자에게 file이라는 uniform logical storage unit을 제공한다. File은 creator가 정의한 related information의 모음이며, source/object program, text, numeric data, binary data, rigid formatted file 등 다양한 형태를 가질 수 있다.
File-system management는 storage media와 device의 물리적 특성을 logical file abstraction으로 바꾸는 작업이다. Files는 사용하기 쉽게 directories로 조직되고, 여러 users가 접근할 수 있다면 read, write, append 같은 접근 권한도 제어해야 한다.
운영체제의 file management 책임은 다음과 같다.
- Files 생성과 삭제
- Directories 생성과 삭제
- Files/directories 조작 primitives 제공
- Files를 mass storage에 mapping
- Stable nonvolatile storage media에 backup
이 주제는 Chapter 13-15에서 file-system interface, implementation, internals로 확장된다.
Mass-Storage Management
Secondary storage는 main memory를 보조하며 programs와 data의 장기 저장 위치가 된다. 현대 시스템은 주로 HDDs와 NVM devices를 online storage media로 사용한다. Secondary storage는 자주, 넓게 사용되므로 그 성능과 관리 알고리즘이 전체 시스템 속도를 좌우할 수 있다.
운영체제의 secondary storage management 책임은 다음과 같다.
- Mounting/unmounting
- Free-space management
- Storage allocation
- Disk scheduling
- Partitioning
- Protection
Tertiary storage는 backup, seldom-used data, long-term archival storage처럼 느리지만 저렴하거나 큰 저장소가 필요할 때 사용된다. Magnetic tape, CD/DVD/Blu-ray 등이 예다. 성능 핵심은 아니지만 media mounting/unmounting, exclusive device allocation, secondary-to-tertiary data migration 같은 관리가 필요할 수 있다.
Cache Management
Caching은 느린 저장 계층에 있는 정보를 더 빠른 저장 계층에 임시로 복사해 두는 원리다. 어떤 정보가 필요하면 먼저 cache에 있는지 확인하고, 있으면 cache copy를 직접 사용한다. 없으면 원래 storage에서 가져오고, 곧 다시 쓸 것이라는 기대 아래 cache에 복사한다.
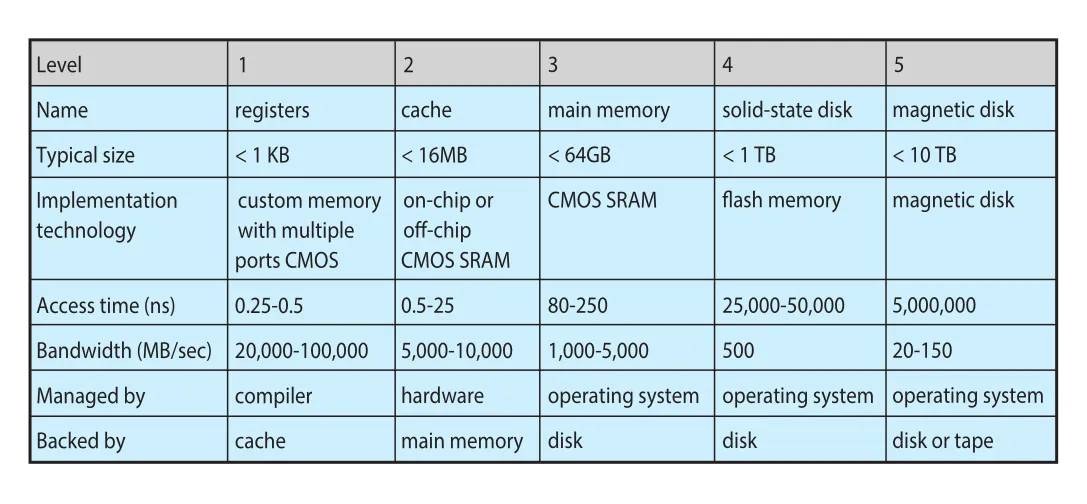
Figure 1.14 · PDF p. 59 · registers, cache, main memory, SSD, magnetic disk의 크기·속도·관리 주체 비교
일부 cache는 hardware가 관리한다. Instruction cache와 data cache는 CPU가 main memory를 기다리는 시간을 줄인다. Registers는 compiler 또는 programmer가 register allocation/replacement를 통해 활용하는 고속 cache처럼 볼 수 있다. 반면 disk에서 memory로 data를 옮기는 일은 보통 operating system이 제어한다.
Cache는 크기가 제한되어 있으므로 replacement policy가 중요하다. 어떤 항목을 cache에 남기고 어떤 항목을 내보낼지의 선택이 성능을 크게 바꾼다. Software-controlled cache의 replacement algorithms는 Chapter 10의 virtual memory에서도 중요하게 등장한다.

Figure 1.15 · PDF p. 60 · disk의 integer A가 main memory, cache, hardware register로 이동하며 여러 copy가 생기는 흐름
같은 data가 여러 storage hierarchy level에 동시에 존재하면 consistency 문제가 생긴다. Single process 환경에서는 가장 높은 계층의 copy를 쓰면 되지만, multitasking environment에서는 여러 processes가 같은 data에 접근할 때 최신 값을 보장해야 한다. Multiprocessor environment에서는 여러 CPUs의 local caches에 같은 data copy가 존재할 수 있으므로 cache coherency가 필요하다. Distributed environment에서는 서로 다른 computers에 replicas가 있을 수 있어 replica update propagation 문제가 추가된다.
I/O System Management
운영체제의 목적 중 하나는 specific hardware devices의 특성을 사용자와 운영체제 대부분으로부터 숨기는 것이다. UNIX 계열처럼 I/O subsystem을 두면 device-specific details는 device driver에 가두고, 나머지 운영체제는 일반화된 인터페이스로 I/O를 다룰 수 있다.
I/O subsystem의 핵심 구성요소는 다음과 같다.
- Buffering, caching, spooling을 포함하는 memory-management component
- General device-driver interface
- Specific hardware devices를 위한 drivers
Interrupt handlers와 device drivers는 efficient I/O subsystem의 기반이며, Chapter 12에서 device management, data transfer, I/O completion detection으로 자세히 이어진다.
1.6 Security and Protection
Protection은 processes 또는 users가 computer system의 resources에 접근하는 방식을 제어하는 mechanisms다. Files, memory segments, CPU, I/O devices 같은 자원은 proper authorization을 얻은 process만 조작할 수 있어야 한다.
Protection의 예는 운영체제 전체에 걸쳐 있다.
- Memory-addressing hardware는 process가 자기 address space 안에서만 실행되게 한다.
- Timer는 process가 CPU를 영원히 점유하지 못하게 한다.
- Device-control registers는 user가 직접 접근하지 못하게 하여 peripheral devices의 integrity를 보호한다.
Protection은 controls를 지정하는 수단과 그 controls를 enforce하는 수단을 모두 제공해야 한다. 또한 subsystem interfaces에서 latent errors를 빨리 감지해 malfunctioning subsystem이 healthy subsystem을 오염시키지 못하게 하므로 reliability를 높인다.
Security는 시스템을 external/internal attacks로부터 방어하는 일이다. Protection이 제대로 되어 있어도 사용자의 authentication information이 도난당하면 해당 사용자의 권한으로 data를 복사하거나 삭제할 수 있다. Security 공격에는 viruses, worms, denial-of-service attacks, identity theft, theft of service 등이 포함된다. Protection은 Chapter 17, security는 Chapter 16에서 더 깊게 다룬다.
운영체제는 사용자를 구분하기 위해 user names와 user identifier(user ID)를 유지한다. Windows에서는 security ID(SID)라는 표현을 쓴다. Login 시 authentication stage가 user ID를 결정하고, 이 ID는 해당 사용자의 processes와 threads에 연결된다. Group 단위 권한이 필요하면 group name과 group identifier를 두고, process/thread에 group IDs를 함께 연결한다.
Privilege escalation은 정상 사용 중 일시적으로 더 큰 권한이 필요할 때 사용된다. UNIX의 setuid attribute는 program을 현재 사용자 ID가 아니라 file owner의 user ID로 실행하게 하여 특정 작업에 필요한 effective UID를 제공한다. 이 기능은 강력하지만 잘못 설계되면 security 취약점이 되므로 protection/security 경계에서 중요하다.
1.7 Virtualization
Virtualization은 하나의 물리 computer hardware(CPU, memory, disk drives, network interface cards 등)를 여러 execution environments로 추상화하여, 각 environment가 자기 private computer에서 실행되는 것처럼 보이게 하는 기술이다. 여러 operating systems가 동시에 실행될 수 있고, 사용자는 single OS에서 processes를 전환하듯 virtual machines 사이를 전환할 수 있다.
Emulation과 virtualization은 구분해야 한다.
| 구분 | 핵심 | 비용 |
|---|---|---|
| emulation | source CPU type과 target CPU type이 다를 때 hardware를 software로 흉내냄 | machine-level instruction을 번역해야 하므로 느릴 수 있음 |
| virtualization | 같은 CPU architecture용으로 compile된 OS를 다른 native OS 또는 VMM 위에서 실행 | native execution에 가까워 emulation보다 효율적 |
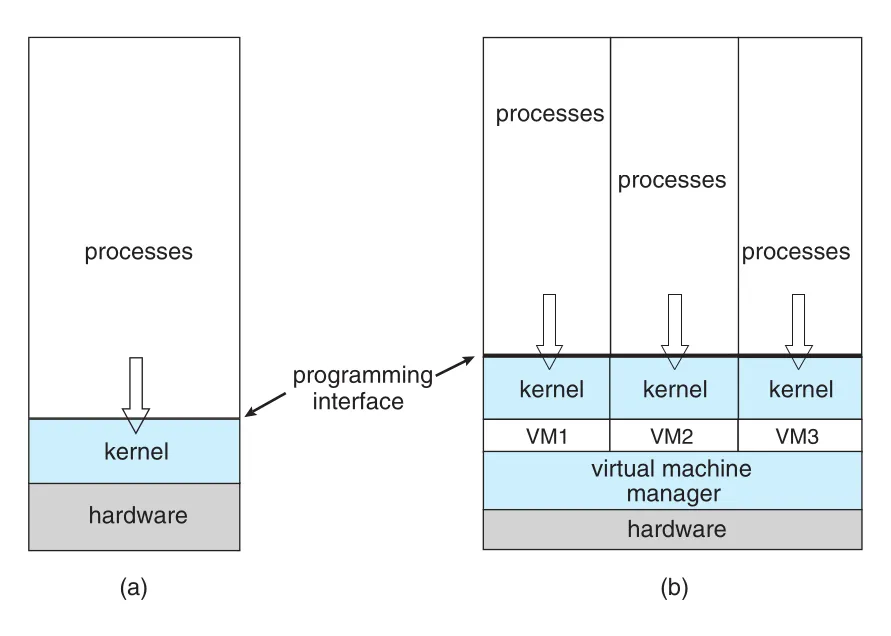
Figure 1.16 · PDF p. 63 · 단일 operating system 실행 구조와 VMM 위의 세 virtual machines 실행 구조 비교
Virtual machine manager(VMM)는 guest operating systems를 실행하고, guest들의 resource use를 관리하며, guest 간 isolation을 제공한다. 초기 desktop virtualization에서는 host operating system 위에서 VMM application이 실행되었지만, data center 환경에서는 VMware ESX, Citrix XenServer처럼 VMM 자체가 host operating system 역할을 하며 virtual machine processes에 services와 resource management를 제공하기도 한다.
Virtualization의 유용성은 여러 OS를 테스트하거나, host OS와 다른 OS용 applications를 실행하거나, development/testing/debugging 환경을 한 physical server에 모으거나, data center resource management를 유연하게 만드는 데 있다. 자세한 구현은 Chapter 18로 이어진다.
1.8 Distributed Systems
Distributed system은 물리적으로 분리되어 있고 때로는 heterogeneous한 computer systems가 network로 연결되어, 사용자에게 여러 resources에 대한 access를 제공하는 구조다. Shared resource에 접근할 수 있으면 computation speed, functionality, data availability, reliability가 향상될 수 있다.
Network는 둘 이상의 systems 사이의 communication path다. Distributed systems는 network 없이는 기능할 수 없다. Network는 protocols, node 사이 거리, transport media에 따라 달라진다. TCP/IP는 Internet의 기본 architecture를 제공하는 가장 흔한 network protocol이며, 대부분의 general-purpose operating systems가 지원한다.
거리 기준 network 용어는 다음과 같다.
| 용어 | 범위 |
|---|---|
| LAN(local-area network) | 방, 건물, campus 수준 |
| WAN(wide-area network) | 도시, 국가, 세계 각지 office 연결 수준 |
| MAN(metropolitan-area network) | 도시 내부 건물 연결 수준 |
| PAN(personal-area network) | Bluetooth, 802.11 등 가까운 개인 장치 연결 수준 |
Network operating system은 file sharing과 remote process communication 기능을 제공하지만, 각 computer는 기본적으로 autonomous하게 동작한다. Distributed operating system은 더 밀접하게 협력하여 network 전체가 하나의 operating system에 의해 제어되는 것처럼 보이게 한다. 이 구분은 Chapter 19의 computer networks와 distributed systems에서 확장된다.
1.9 Kernel Data Structures
운영체제 구현은 추상적인 정책만으로 이루어지지 않는다. Process table, ready queue, page table, file descriptor table, buffer cache, device queue처럼 kernel 내부에는 많은 data가 있고, 이 data를 빠르게 찾고, 삽입하고, 삭제하고, 순회하기 위해 적절한 data structures가 필요하다.
Lists, Stacks, and Queues
Array는 각 element에 direct access가 가능한 단순 구조다. Main memory 자체도 byte array로 볼 수 있다. 그러나 저장할 item 크기가 가변적이거나, 중간 item을 삭제하면서 나머지 순서를 유지해야 한다면 array만으로는 불편하다. 이때 list 계열 구조가 자주 쓰인다.
List는 data values를 sequence로 표현한다. 대표 구현은 linked list다.
| 구조 | 핵심 | OS에서의 의미 |
|---|---|---|
| singly linked list | 각 item이 successor를 가리킴 | 단순 순회와 삽입/삭제에 적합 |
| doubly linked list | predecessor와 successor를 모두 참조 가능 | 양방향 순회, 중간 삭제가 쉬움 |
| circularly linked list | 마지막 element가 null이 아니라 첫 element를 참조 | ready queue처럼 순환적 처리에 적합 |
Linked list는 다양한 크기의 item을 수용하고 insertion/deletion이 쉽다. 단점은 특정 item 검색이 worst case O(n)이라는 점이다. Kernel algorithms에서 list를 직접 쓰기도 하지만, stacks와 queues 같은 더 강한 구조를 만드는 기반으로도 자주 쓴다.
Stack은 last in, first out(LIFO) 원칙을 따른다. 삽입은 push, 제거는 pop이다. 운영체제와 runtime은 function call을 처리할 때 stack을 사용한다. Function call 시 parameters, local variables, return address가 stack에 push되고, return 시 pop된다.
Queue는 first in, first out(FIFO) 원칙을 따른다. 먼저 들어온 item이 먼저 제거된다. Printer jobs는 보통 제출 순서대로 출력되고, CPU를 기다리는 tasks도 Chapter 5에서 ready queue 형태로 조직된다. Queue는 scheduling을 이해할 때 핵심 자료구조다.
Trees
Tree는 hierarchical data를 표현하는 구조다. Parent-child relationships로 data values를 연결하며, binary tree는 parent가 최대 두 children(left child, right child)을 가진다. Binary search tree(BST)는 ordering을 추가해 left child <= right child 관계를 유지한다.
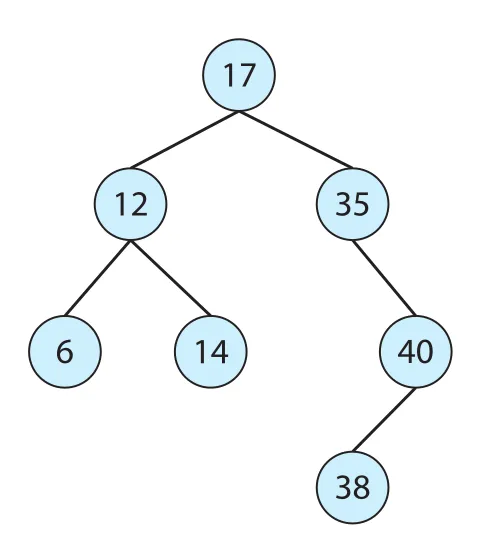
Figure 1.20 · PDF p. 67 · 값의 ordering으로 검색 경로를 줄이는 binary search tree 예
BST 검색의 worst-case는 tree가 한쪽으로 치우치면 O(n)이 될 수 있다. 이를 줄이기 위해 balanced binary search tree를 사용하면 n items가 있을 때 height를 최대 lg n 수준으로 유지하여 worst-case O(lg n)을 보장할 수 있다. Linux CPU-scheduling algorithm은 balanced BST의 한 종류인 red-black tree를 사용한다. 이 연결은 Chapter 5의 scheduler 구현에서 중요하다.
Hash Functions and Maps
Hash function은 input data에 numeric operation을 적용해 numeric value를 반환하고, 그 값을 table index로 사용해 data를 빠르게 찾게 한다. List에서 n개 item 중 하나를 찾으려면 worst-case O(n)이지만, 좋은 hash function과 table 구현을 사용하면 평균적으로 O(1)에 가까운 retrieval이 가능하다.
Hash collision은 서로 다른 inputs가 같은 output value를 만드는 상황이다. 흔한 해결책은 해당 table location에 linked list를 두어 같은 hash value를 가진 items를 연결하는 것이다. Collision이 많아질수록 hash function 효율은 떨어진다.
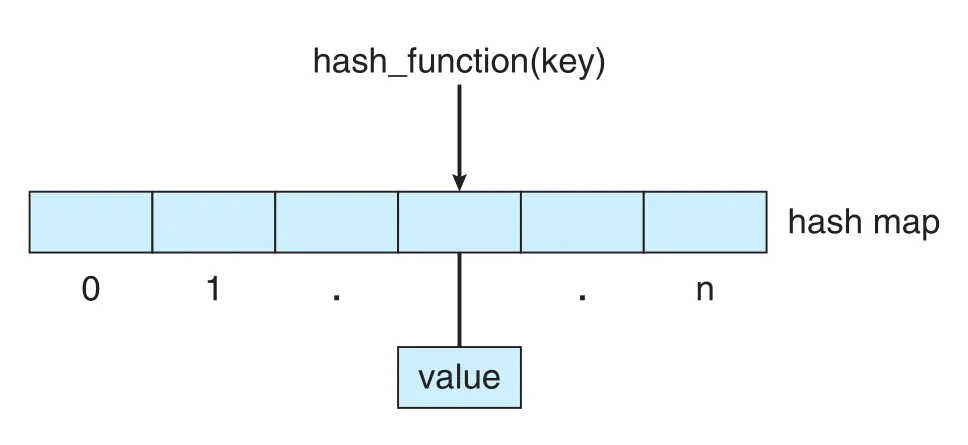
Figure 1.21 · PDF p. 67 · key에 hash_function을 적용해 value 위치를 찾는 hash map 구조
Hash map은 [key:value] pairs를 hash function으로 연결한다. 예를 들어 user name을 key로 password를 찾는 authentication 구조를 생각할 수 있다. 실제 보안 시스템은 password를 평문으로 저장하지 않는 등 더 복잡하지만, 여기서 중요한 점은 hash map이 “key 기반 빠른 lookup”을 제공한다는 것이다.
Bitmaps
Bitmap은 n개의 binary digits로 n개 items의 상태를 표현하는 구조다. 예를 들어 각 bit가 resource 하나에 대응하고, 0은 available, 1은 unavailable을 의미하게 만들 수 있다. 원문 예시 001011101에서는 resources 2, 4, 5, 6, 8이 unavailable이고, 0, 1, 3, 7이 available이다.
Bitmap의 장점은 space efficiency다. 각 resource 상태를 8-bit Boolean으로 저장하면 bitmap보다 8배 많은 공간이 필요하다. Disk drive를 수천 개의 disk blocks로 나누고 각 block의 사용 가능 여부를 표시할 때 bitmap이 적합하다. 이후 file-system free-space management에서도 이 구조가 다시 등장한다.
Linux kernel은 <linux/list.h>의 linked-list structure, kfifo queue, <linux/rbtree.h>의 red-black tree처럼 여러 data structures를 kernel source code 안에 구현해 둔다. 이 장의 목적은 세부 코드를 암기하는 것이 아니라, kernel algorithms가 실제로는 이런 구조 위에서 동작한다는 감각을 잡는 것이다.
1.10 Computing Environments
운영체제는 하나의 환경에서만 쓰이지 않는다. Traditional computing, mobile computing, client-server computing, peer-to-peer computing, cloud computing, real-time embedded systems는 각각 자원 제약, 사용자 인터페이스, 네트워크 구조, 보호 요구가 다르다.
Traditional Computing
전통적인 사무 환경은 PCs가 network에 연결되고 servers가 file/print services를 제공하는 구조에서 출발했다. 지금은 web technologies와 WAN bandwidth 증가로 경계가 흐려졌다. Companies는 internal servers에 web portal을 제공하고, thin clients 또는 network computers를 사용해 security와 maintenance를 단순화하기도 한다. 가정 환경도 빠른 network 연결과 firewall을 갖춘 작은 network로 바뀌었다.
Batch systems는 jobs를 미리 준비된 input과 함께 묶어 처리하고, interactive systems는 user input을 기다린다. Time-sharing systems는 timer와 scheduling algorithms로 processes를 빠르게 CPU에 순환시켜 여러 users가 자원을 나눠 쓰게 했다. 오늘날 전통적 의미의 다중 사용자 time-sharing은 드물지만, 같은 scheduling 기법은 desktop, laptop, server, mobile computer에서 여전히 쓰인다. 차이는 여러 users가 아니라 한 사용자와 system processes가 같은 CPU time을 나눠 쓰는 경우가 많다는 점이다.
Mobile Computing
Mobile computing은 smartphones와 tablet computers 같은 handheld devices에서의 computing을 말한다. Mobile devices는 portable, lightweight라는 물리적 특성을 얻는 대신 전통적으로 screen size, memory capacity, processing power, battery capacity에서 제약을 가졌다. 하지만 현대 mobile devices는 e-mail, web browsing뿐 아니라 music/video, digital books, photos, high-definition video recording/editing까지 수행한다.
Mobile OS가 desktop OS와 다른 압력을 받는 이유는 hardware 특성 때문이다.
- GPS chips는 location-aware applications를 가능하게 한다.
- Accelerometers와 gyroscopes는 orientation, tilting, shaking을 입력으로 사용할 수 있게 한다.
- 802.11 wireless와 cellular data networks가 online services 접근을 제공한다.
- 제한된 storage, memory, processing cores, power consumption 때문에 OS는 energy efficiency와 responsiveness를 더 강하게 고려해야 한다.
iOS와 Android는 mobile computing의 대표 operating systems이며, Chapter 2에서 더 자세히 다룬다.
Client-Server Computing
Client-server system은 server systems가 client systems의 requests를 처리하는 specialized distributed system이다.
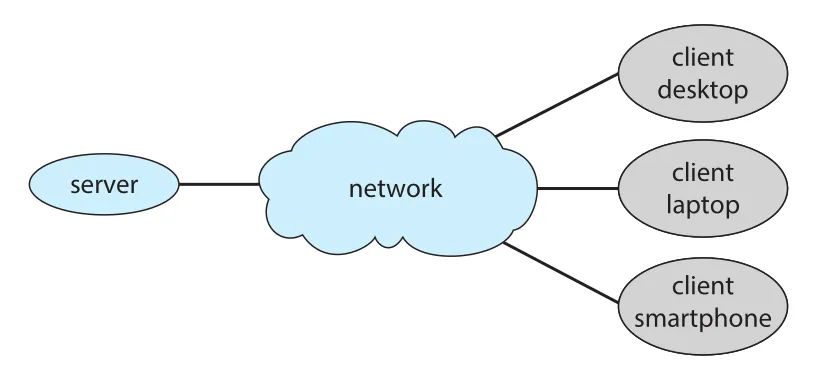
Figure 1.22 · PDF p. 70 · server가 network를 통해 desktop, laptop, smartphone clients의 요청을 처리하는 client-server system
Server systems는 크게 두 범주로 볼 수 있다.
| 서버 유형 | 역할 | 예 |
|---|---|---|
| compute-server system | client request에 따라 action을 수행하고 result를 반환 | database server가 data request에 응답 |
| file-server system | clients가 files를 create, update, read, delete할 수 있는 file-system interface 제공 | web server가 browser clients에 files 전달 |
Client-server 구조의 핵심은 역할 분리다. Client는 요청과 사용자 인터페이스를 담당하고, server는 shared resource, computation, storage, policy enforcement를 담당한다.
Peer-to-Peer Computing
Peer-to-peer(P2P) model에서는 clients와 servers를 고정적으로 구분하지 않는다. 모든 nodes는 peers이며, 어떤 순간에는 service를 요청하는 client처럼, 다른 순간에는 service를 제공하는 server처럼 동작할 수 있다. Traditional client-server system에서는 server가 bottleneck이 될 수 있지만, P2P에서는 services가 network 전체의 여러 nodes에 분산될 수 있다.
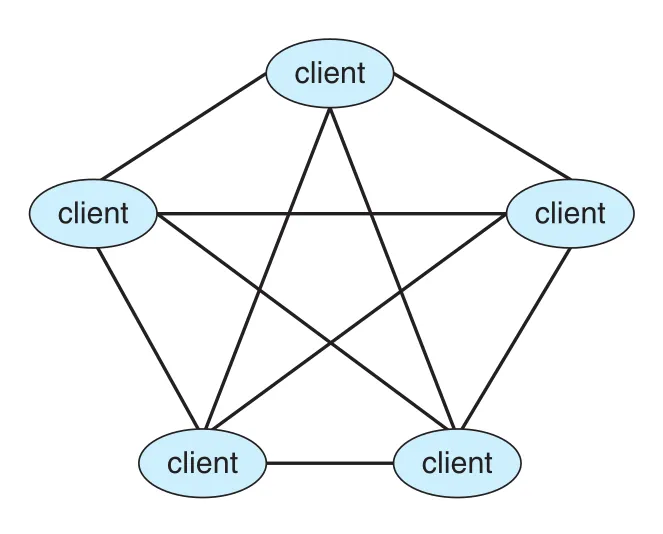
Figure 1.23 · PDF p. 72 · 중앙 service 없이 peers가 서로 요청과 응답을 주고받는 peer-to-peer system
P2P에서 service discovery 방식은 두 가지로 나눌 수 있다.
- Centralized lookup service: node가 network에 join할 때 service를 중앙 lookup service에 등록하고, 다른 node는 먼저 lookup service에 물어본 뒤 실제 통신은 service provider와 직접 한다.
- Broadcast/discovery protocol: 중앙 lookup 없이 request를 network peers에 broadcast하고, service를 제공할 수 있는 node가 직접 응답한다.
Napster는 중앙 index를 두고 file exchange는 peers 사이에서 일어나게 한 방식에 가깝고, Gnutella는 broadcast request 방식에 가깝다. Skype는 centralized login server와 decentralized peers를 섞은 hybrid peer-to-peer approach를 사용했다. 여기서 중요한 개념은 P2P가 중앙 병목을 줄이지만 discovery, trust, copyright, abuse 같은 정책 문제를 함께 만든다는 점이다.
Cloud Computing
Cloud computing은 computing, storage, applications를 network를 통해 service로 제공하는 computing model이다. Virtualization을 기능 기반으로 사용한다는 점에서 virtualization의 논리적 확장이다. 사용자는 physical servers를 직접 소유하지 않고, 필요한 virtual machines, storage, applications를 사용량 기반으로 빌려 쓴다.
Cloud 유형은 다음처럼 구분된다.
| 유형 | 의미 |
|---|---|
| public cloud | Internet을 통해 비용을 지불한 누구나 사용할 수 있는 cloud |
| private cloud | 한 조직이 자기 용도로 운영하는 cloud |
| hybrid cloud | public/private cloud components가 결합된 cloud |
| SaaS(Software as a service) | applications를 Internet service로 제공 |
| PaaS(Platform as a service) | application 실행을 위한 software stack 제공 |
| IaaS(Infrastructure as a service) | servers 또는 storage 같은 infrastructure 제공 |
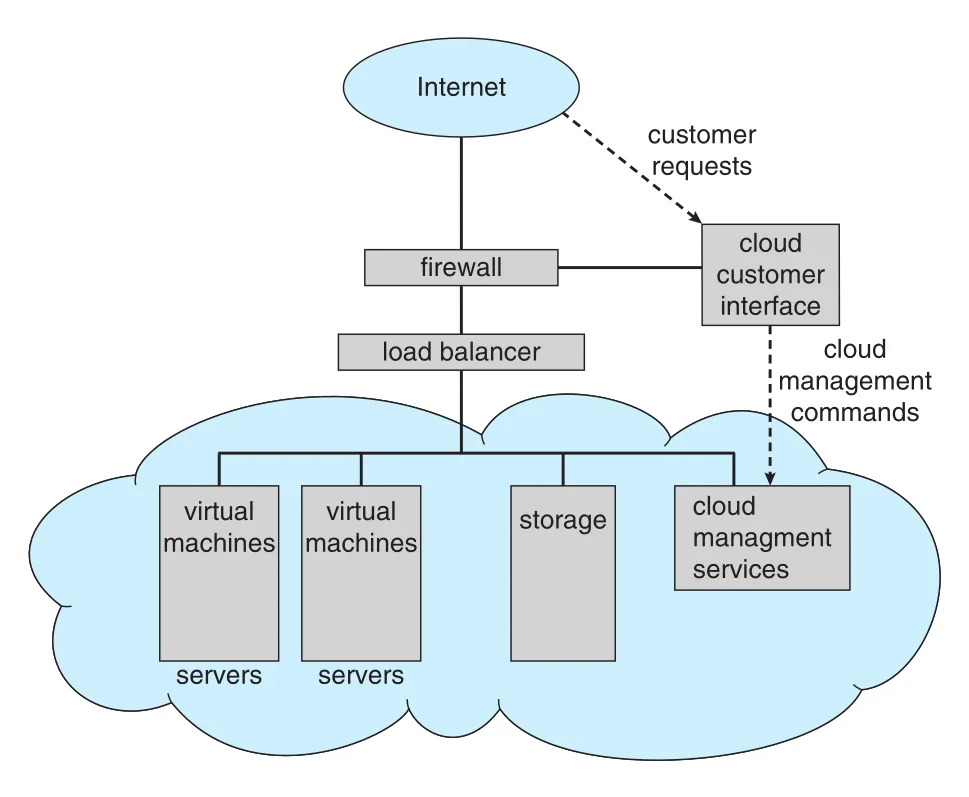
Figure 1.24 · PDF p. 73 · firewall, load balancer, virtual machines, storage, cloud management services로 구성된 public cloud 예
Cloud infrastructure 안에는 traditional operating systems, virtual machines를 관리하는 VMMs, 그리고 그 VMMs와 cloud resources를 관리하는 cloud management tools가 함께 존재한다. 이 tools는 cloud components에 대한 interface와 resource management를 제공하므로, 넓은 의미에서 새로운 종류의 operating system처럼 볼 수 있다.
Real-Time Embedded Systems
Embedded computers는 가장 널리 존재하는 컴퓨터 형태다. Car engines, manufacturing robots, optical drives, microwave ovens, home appliances처럼 특정 작업을 수행하기 위해 시스템 안에 들어간다. 많은 embedded systems는 사용자 인터페이스가 거의 없고, hardware devices를 monitoring/managing하는 데 집중한다.
Embedded systems는 다양하다.
- General-purpose operating system(Linux 등) 위에서 special-purpose applications를 실행하는 경우
- 원하는 기능만 제공하는 special-purpose embedded operating system을 쓰는 경우
- Application-specific integrated circuits(ASICs)가 운영체제 없이 직접 작업을 수행하는 경우
Embedded systems는 대개 real-time operating systems를 실행한다. Real-time system은 processor 동작이나 data flow에 rigid time requirements가 있는 시스템이다. Correct result만으로는 충분하지 않고, 정해진 time constraints 안에 결과를 내야 correct하다. 예를 들어 robot arm이 차체에 부딪힌 뒤 멈추면 계산 결과가 “정지”로 맞아도 시스템은 실패한 것이다.
Traditional laptop system에서는 빠른 응답이 desirable이지만 mandatory는 아니다. 반면 real-time system에서는 deadline을 놓치면 failure다. 이 차이는 Chapter 5의 real-time CPU scheduling과 Chapter 20의 Linux real-time components로 이어진다.
1.11 Free and Open-Source Operating Systems
Free/open-source operating systems는 source-code format으로 제공되기 때문에 운영체제를 내부에서 학습할 수 있게 한다. Binary만 있을 때 source를 reverse engineering하는 것은 어렵고 comments 같은 정보는 복구되지 않는다. Source code가 있으면 학생과 개발자는 운영체제를 수정하고 compile/run하여 변화의 효과를 직접 확인할 수 있다.
Free software와 open-source software는 같은 말이 아니다.
| 구분 | 핵심 의미 |
|---|---|
| free software / libre software | source code 공개뿐 아니라 no-cost use, redistribution, modification을 허용하는 freedom 중심 licensing |
| open-source software | source code를 볼 수 있지만 license가 반드시 free software의 자유를 모두 보장하지는 않을 수 있음 |
| closed-source / proprietary software | source code 접근과 사용 권한을 소유자가 제한 |
GNU General Public License(GPL)는 free software를 위한 대표 license다. GPL은 binaries와 함께 source code를 배포하게 하고, modified versions도 같은 GPL license로 배포하도록 요구한다. 이런 copyleft 방식은 redistribution 이후에도 freedom이 유지되도록 만든다.
GNU/Linux는 free/open-source OS의 대표 사례다. GNU Project는 compilers, editors, utilities, libraries 등을 만들었고, Linux kernel은 Linus Torvalds가 1991년에 공개한 UNIX-like kernel에서 출발했다. 1992년에 Linux가 GPL로 rerelease되면서 GNU tools와 Linux kernel이 결합된 GNU/Linux 생태계가 빠르게 성장했다. Red Hat, SUSE, Fedora, Debian, Slackware, Ubuntu 같은 distributions는 목적, 설치 application, hardware support, user interface가 서로 다르다.
BSD UNIX, FreeBSD, NetBSD, OpenBSD, DragonflyBSD, Darwin/macOS, Solaris/OpenSolaris/Illumos 같은 사례는 open-source operating systems가 하나의 계보가 아니라 서로 다른 licensing, design goal, community, code history를 가진다는 점을 보여준다. 이 장에서 중요한 것은 세부 역사를 외우는 것이 아니라 source availability가 operating system study를 바꿨다는 점이다.
Open-source systems는 학습 도구로 강력하다.
- Source code를 직접 읽어 kernel algorithms와 data structures를 확인할 수 있다.
- 코드를 수정하고 compile/run하여 실험할 수 있다.
- Bugs를 찾고 고치며 mature system의 실제 설계를 배울 수 있다.
- Virtualization 덕분에 별도 hardware 없이 여러 operating systems를 안전하게 실행해 볼 수 있다.
연결 관계
Chapter 1은 운영체제 전체 책의 지도 역할을 한다. 각 개념은 뒤 장에서 구체적인 알고리즘과 자료구조로 내려간다.
| Chapter 1 개념 | 뒤에서 이어지는 주제 |
|---|---|
| interrupt, trap, system call | Chapter 2 system calls, Chapter 12 I/O systems, page fault 처리 |
| process, program, multitasking | Chapter 3 processes, Chapter 4 threads, Chapter 5 CPU scheduling |
| timer, privileged instructions, user/kernel mode | Chapter 5 scheduling, Chapter 16 security, Chapter 17 protection |
| memory management, virtual memory | Chapter 9 main memory, Chapter 10 virtual memory |
| storage hierarchy, cache, NVS | Chapter 10 caching/replacement, Chapter 11 mass storage |
| file abstraction, directory, backup | Chapter 13-15 file systems |
| synchronization, communication, deadlock | Chapter 6 synchronization tools, Chapter 7 examples, Chapter 8 deadlocks |
| virtualization, VMM | Chapter 18 virtual machines |
| distributed systems, LAN/WAN/PAN, client-server/P2P/cloud | Chapter 19 networks and distributed systems |
| red-black tree, queue, bitmap, hash map | Scheduler, memory allocator, file-system free-space management 등 kernel internals 전반 |
오해하기 쉬운 내용
- 운영체제는 “사용자에게 보이는 GUI”만이 아니다. Kernel, system programs, middleware가 함께 운영체제 경험을 구성하지만, 이 책의 핵심은 kernel의 자원 관리와 보호다.
- Program과 process는 다르다. Program은 passive file이고, process는 CPU, memory, files, I/O resources를 가진 active execution이다.
- Interrupt와 trap/system call은 모두 제어권을 kernel로 넘길 수 있지만, interrupt는 보통 hardware event이고 trap/exception/system call은 software-generated event로 이해하면 좋다.
- Multiprogramming은 CPU utilization을 높이기 위해 여러 processes를 memory에 두는 것이고, multitasking은 frequent switching으로 interactive response time을 제공하는 확장이다.
- Kernel mode는 “빠른 모드”가 아니라 privileged instructions를 실행할 수 있는 보호 모드다.
- Multiprocessor, multicore, clustered system은 모두 병렬성을 제공할 수 있지만 결합 방식이 다르다. SMP/multicore는 memory를 공유하는 tightly coupled 성격이 강하고, cluster는 nodes가 network로 연결된 loosely coupled 구조다.
- Cache는 성능을 높이지만 consistency 문제를 만든다. 특히 multitasking, multiprocessor, distributed environment로 갈수록 최신 값 보장이 어려워진다.
- Protection과 security는 겹치지만 같지 않다. Protection은 resource access control mechanism이고, security는 attacks와 misuse로부터 시스템을 방어하는 더 넓은 문제다.
- Virtualization은 emulation과 다르다. Emulation은 다른 CPU architecture를 software로 흉내 내므로 느릴 수 있고, virtualization은 같은 architecture에서 execution environments를 분리한다.
- Real-time system에서 중요한 것은 평균적으로 빠른 것이 아니라 deadline 안에 correct result를 내는 것이다.
면접 질문
- 운영체제를 user view와 system view에서 각각 설명하고, resource allocator와 control program의 차이를 말해보라.
- Kernel, system programs, middleware, application programs를 구분해보라.
- Interrupt-driven I/O cycle에서 device controller, device driver, interrupt handler가 각각 어떤 역할을 하는가?
- Interrupt vector를 사용하는 이유는 무엇이며, interrupt chaining은 어떤 trade-off를 해결하는가?
- DMA가 interrupt-driven byte-by-byte I/O보다 효율적인 이유를 설명하라.
- Storage hierarchy에서 speed, size, volatility, cost 사이의 trade-off를 설명하라.
- SMP, multicore, NUMA, clustered system의 구조적 차이를 비교하라.
- Multiprogramming과 multitasking의 관계를 설명하고, 왜 memory management와 CPU scheduling이 필요한지 말해보라.
- User mode와 kernel mode는 어떻게 protection을 제공하는가? Privileged instruction 예를 들어보라.
- System call이 trap/software interrupt 형태로 처리되는 이유를 설명하라.
- Timer가 운영체제의 CPU 제어권 유지에 왜 필요한가?
- Process와 program의 차이, single-threaded process와 multithreaded process의 차이를 설명하라.
- Cache coherency와 distributed replica consistency가 왜 어려운 문제인지 설명하라.
- Protection과 security의 차이를 예와 함께 설명하라.
- Virtualization과 emulation의 차이를 설명하고, VMM의 역할을 말해보라.
- Linked list, queue, red-black tree, hash map, bitmap이 운영체제 내부에서 쓰이는 이유를 각각 하나씩 말해보라.
- Client-server system과 peer-to-peer(P2P) system의 병목과 discovery 문제를 비교하라.
- Cloud computing이 virtualization의 확장이라고 볼 수 있는 이유는 무엇인가?
- Real-time system이 일반 interactive system과 다른 기준으로 correct하다고 판단되는 이유는 무엇인가?
- Free software와 open-source software의 차이, GPL/copyleft의 핵심 의도를 설명하라.