Chapter 11. Mass-Storage Structure
- 과목: Operating System
- 기준 교재: Operating System Concepts 10th
- 관련 페이지: PDF pp. 573-609
- 우선순위: 필수
개요
mass storage는 computer의 nonvolatile storage system이다. Modern computers에서 중심은 secondary storage이고, 보통 HDD (hard disk drive)와 NVM (nonvolatile memory) devices가 제공한다. 일부 systems는 더 느리지만 큰 tertiary storage, 예를 들어 magnetic tape, optical disks, cloud storage도 사용한다.
Chapter 11의 핵심 질문은 “storage device의 physical structure가 OS의 I/O scheduling, address mapping, formatting, bad-block handling, swap-space management, attachment 방식, RAID 설계에 어떤 제약과 기회를 주는가?”이다. HDD는 mechanical movement 때문에 seek/rotational latency가 중요하고, NVM은 erase-before-write, wear, flash translation layer가 중요하다. OS는 이 차이를 logical blocks라는 uniform interface로 숨기지만, 성능과 reliability를 위해 device 특성을 알아야 한다.
핵심 개념
| 개념 | 핵심 의미 |
|---|---|
mass storage | computer의 nonvolatile storage system 전체를 가리키는 말. |
secondary storage | HDD, NVM devices처럼 main memory보다 크고 nonvolatile한 일반 저장장치. |
tertiary storage | magnetic tape, optical disk, cloud storage처럼 더 느리지만 large capacity/backup에 쓰이는 저장 계층. |
NVS | Nonvolatile Storage. HDD, NVM 등 전원이 꺼져도 data가 남는 storage를 포괄한다. |
HDD | Hard Disk Drive. rotating platters와 moving heads로 magnetic data를 읽고 쓰는 mechanical storage. |
platter, track, sector, cylinder | HDD physical/logical geometry. sector는 HDD의 smallest transfer unit이다. |
seek time | disk arm을 desired cylinder로 이동시키는 시간. |
rotational latency | desired sector가 head 아래로 회전해 올 때까지 기다리는 시간. |
transfer rate | storage device와 computer 사이 data가 흐르는 속도. |
positioning time, random-access time | seek time과 rotational latency를 합친 HDD random access 비용. |
head crash | disk head가 platter surface에 닿아 magnetic surface를 손상시키는 HDD failure. |
NVM device | moving parts 없이 semiconductor에 data를 저장하는 nonvolatile memory device. SSD, USB flash, motherboard-mounted storage 등이 포함된다. |
SSD | Solid-State Disk. disk-drive-like package로 제공되는 flash-based NVM device. |
NAND flash | page 단위 read/write, block 단위 erase, program-erase cycle wear를 갖는 flash memory. |
DWPD | Drive Writes Per Day. drive capacity를 하루 몇 번 쓸 수 있는지로 NAND lifespan을 표현하는 지표. |
FTL | Flash Translation Layer. logical blocks를 current valid physical flash pages로 mapping하는 controller table. |
garbage collection | valid data를 다른 곳으로 복사해 invalid pages만 남은 blocks를 erase 가능하게 만드는 NVM controller 작업. |
over-provisioning | SSD가 user-visible capacity 밖의 spare pages/blocks를 따로 두어 writes, GC, wear leveling에 쓰는 기법. |
wear leveling | erase cycles가 특정 blocks에 몰리지 않도록 writes/erases를 분산해 device lifespan을 늘리는 controller algorithm. |
RAM drive, RAM disk | DRAM 일부를 storage device처럼 보이게 만든 volatile high-speed temporary storage. |
ATA, SATA, SAS, USB, FC, NVMe | storage device connection/interface families. NVMe는 PCIe 기반 fast NVM interface다. |
controller, HBA | host와 device 사이 commands/data transfer를 처리하는 electronic processor. |
DMA | Direct Memory Access. device/controller가 host DRAM과 직접 data transfer를 수행하는 방식. |
logical block, LBA | OS와 algorithms가 사용하는 one-dimensional storage address unit. physical sector/page details를 숨긴다. |
CLV, CAV | Constant Linear Velocity, Constant Angular Velocity. rotating media의 data rate/sector density 관리 방식. |
HDD scheduling | pending storage I/O requests의 service order를 조정해 seek/latency를 줄이고 bandwidth를 높이는 작업. |
FCFS, FIFO | First-Come, First-Served. 요청 도착 순서대로 처리하는 가장 단순하고 fair한 scheduling. |
SCAN, elevator algorithm | disk arm이 한 방향으로 이동하며 요청을 처리하고 끝에서 방향을 바꾸는 HDD scheduling algorithm. |
C-SCAN | Circular SCAN. 한 방향으로만 servicing하고 끝에 도달하면 반대쪽 끝으로 jump해 uniform wait time을 노리는 algorithm. |
deadline scheduler | Linux I/O scheduler. read/write와 LBA/FCFS queues를 조합해 starvation을 제한한다. |
NOOP scheduler | Linux scheduler. fast storage/NVM에 적합한 FCFS 기반 scheduler로 adjacent requests를 merge한다. |
CFQ | Completely Fair Queueing. Linux scheduler. request queues와 historical behavior로 fairness/locality를 조절한다. |
IOPS | Input/Output Operations Per Second. random-access I/O performance 지표. |
write amplification | application write 하나가 NVM garbage collection/space management 때문에 여러 internal reads/writes를 유발하는 현상. |
parity bit | data bits의 1 개수가 even/odd인지 저장해 single-bit error를 detect하는 bit. |
checksum | fixed-length words에 modular arithmetic 등을 적용해 data corruption을 detect하는 값. |
CRC | Cyclic Redundancy Check. hash-like function으로 multiple-bit errors를 detect하는 방법. |
ECC | Error-Correcting Code. error를 detect할 뿐 아니라 일정 범위의 bit errors를 correct하는 code. |
soft error, hard error | ECC로 recoverable한 error와 correct할 수 없는 noncorrectable error. |
low-level formatting, physical formatting | storage device를 controller가 read/write할 수 있는 sectors/pages와 metadata 구조로 초기화하는 작업. |
partition | storage device의 blocks/pages를 나눈 그룹. OS는 각 partition을 separate device처럼 다룰 수 있다. |
volume | mount 가능한 file-system storage 단위. partition, RAID set, logical volume 등이 될 수 있다. |
logical formatting | file system을 생성하고 free/allocated space maps, initial directory 같은 초기 data structures를 기록하는 작업. |
mounting | file system을 system namespace에 연결해 users와 system이 사용할 수 있게 하는 작업. |
cluster | file-system I/O 효율을 위해 blocks를 묶은 larger chunk. |
boot block, bootstrap loader, MBR | boot 과정에서 firmware가 읽어 OS kernel loading으로 이어지게 하는 fixed-location boot data/code. |
bad block | defective sector/page. controller나 OS가 spare location으로 대체하거나 사용하지 않게 한다. |
sector sparing, forwarding | bad sector를 spare sector로 logical replacement하는 recovery scheme. |
sector slipping | bad sector 이후 sectors를 한 칸씩 밀어 spare를 사용하게 하는 remapping 방식. |
swap-space management | virtual memory가 secondary storage를 main memory extension처럼 쓰도록 swap areas를 관리하는 OS task. |
swap file, swap partition | file-system 안의 swap file 또는 raw partition에 마련된 swap space. |
swap map | Linux swap area에서 page slots의 availability와 mapping count를 기록하는 array. |
host-attached storage | local I/O ports를 통해 host가 직접 access하는 storage. read/write logical blocks interface가 중심이다. |
NAS | Network-Attached Storage. network를 통해 file-system style storage를 제공하는 system. |
NFS, CIFS | UNIX/Linux와 Windows에서 NAS access에 쓰이는 file-sharing protocols. |
iSCSI | IP network 위에 SCSI protocol을 실어 remote storage를 block device처럼 쓰게 하는 protocol. |
cloud storage | Internet/WAN을 통해 remote data center storage를 API로 사용하는 storage service. |
SAN | Storage-Area Network. servers와 storage units를 private storage network로 연결한다. |
storage array | drives, controllers, ports, RAID/snapshot/replication/compression 등 storage features를 제공하는 purpose-built device. |
JBOD | Just a Bunch of Disks. RAID protection 없이 여러 drives를 제공하는 구성. |
RAID | Redundant Arrays of Independent Disks. 여러 drives를 parallelism/redundancy로 묶어 performance와 reliability를 높이는 storage organization. |
mirroring | 같은 data를 두 physical drives에 duplicate해 한쪽 failure에도 data를 읽을 수 있게 하는 redundancy 기법. |
striping | data를 여러 drives에 분산해 parallel access와 transfer rate를 높이는 기법. |
parity, XOR parity | data blocks로부터 계산한 recovery information. single drive failure 시 missing data reconstruction에 사용된다. |
MTBF, MTTR | Mean Time Between Failures, Mean Time To Repair. RAID reliability 계산에서 drive failure 간격과 repair/rebuild 시간을 나타낸다. |
RAID 0, RAID 1, RAID 4, RAID 5, RAID 6 | striping, mirroring, dedicated/distributed parity, double redundancy를 조합한 대표 RAID levels. |
RAID 0 + 1, RAID 1 + 0 | striping과 mirroring을 결합한 nested RAID. RAID 1 + 0은 single drive failure 후에도 더 많은 drives가 계속 available하다. |
hot spare | 평소 data를 저장하지 않다가 drive failure 시 자동 rebuild 대상이 되는 spare drive. |
snapshot, replication | 특정 시점 file system view와 remote/local duplicate writes로 availability/disaster recovery를 높이는 storage features. |
ZFS | file-system management와 volume management를 통합하고 checksums/pools로 consistency와 flexibility를 제공하는 file system. |
object storage | file path hierarchy 대신 object ID와 metadata로 data objects를 저장/조회하는 storage model. |
세부 정리
11.1 Overview of Mass-Storage Structure
Modern secondary storage는 대부분 HDDs와 NVM devices가 담당한다. 이 절은 두 device의 physical mechanisms를 보고, OS가 이 physical properties를 logical blocks로 추상화하는 address mapping을 설명한다.
11.1.1 Hard Disk Drives
HDD는 magnetic platters와 moving read-write heads로 구성된다. 각 platter surface는 circular tracks로 나뉘고, track은 sectors로 subdivide된다. Disk arm이 특정 위치에 있을 때 모든 platter surfaces에서 같은 radius의 tracks 집합이 cylinder다. sector는 fixed size이며 HDD의 smallest transfer unit이다. 과거에는 512 bytes sectors가 흔했고, 이후 4 KB sectors로 이동했다.
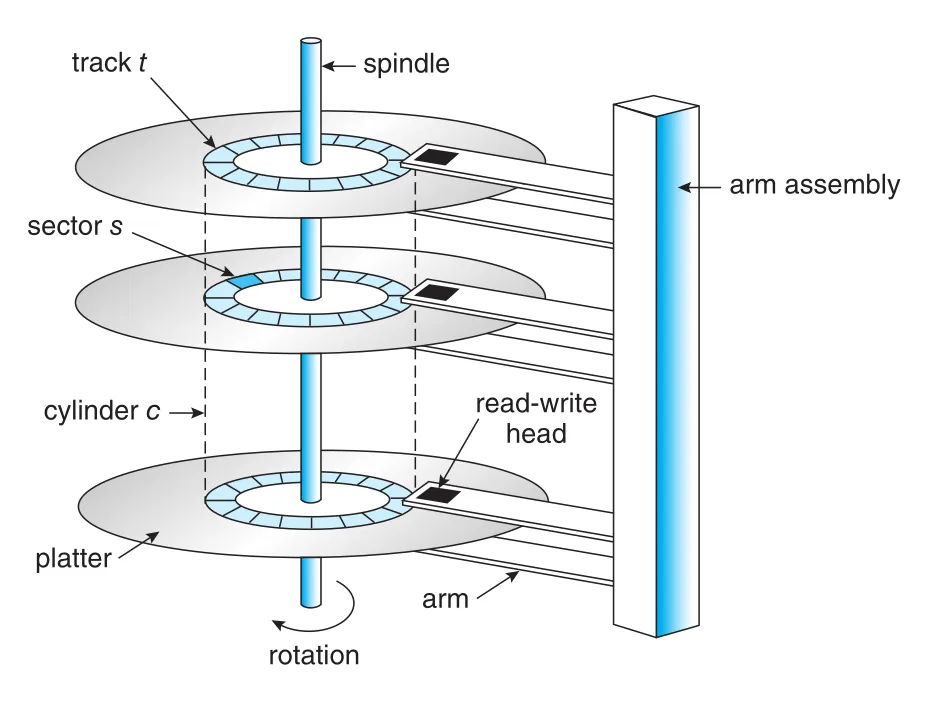
Figure 11.1 · PDF p. 574 · platter, track, sector, cylinder, arm/head로 구성되는 HDD moving-head mechanism
HDD performance는 mechanical movement 때문에 결정된다. Motor는 platters를 high RPM으로 회전시키며, common speeds는 5,400, 7,200, 10,000, 15,000 RPM이다. Data가 drive와 computer 사이를 흐르는 속도는 transfer rate다. 하지만 random access에서는 data transfer보다 positioning time이 중요하다.
seek time은 disk arm을 desired cylinder로 옮기는 시간이고, rotational latency는 desired sector가 head 아래로 올 때까지 기다리는 시간이다. Typical HDDs는 seek/rotational latency가 several milliseconds이고, transfer rate는 tens to hundreds of MB/s다. Drive controller의 DRAM buffer는 performance를 높이는 데 쓰인다.

Figure 11.2 · PDF p. 575 · cover를 제거한 3.5-inch HDD의 platter와 actuator 구조
HDD head는 platter surface 바로 위를 microns 단위 air/gas cushion 위에서 떠다닌다. Head가 platter surface에 닿으면 head crash가 발생할 수 있다. 보통 수리할 수 없고 drive를 교체해야 하며, data는 backup 또는 RAID protection이 없으면 손실된다. 일부 chassis는 hot removal/replacement를 지원해 bad drive를 system shutdown 없이 교체할 수 있다.
11.1.2 Nonvolatile Memory Devices
NVM devices는 mechanical storage가 아니라 electrical semiconductor storage다. 흔한 형태는 controller와 flash NAND die semiconductor chips로 구성된 device다. Flash-based NVM이 disk-drive-like container로 제공되면 SSD (solid-state disk)라고 부른다. USB flash drive, DRAM stick 형태, smartphone motherboard에 surface-mounted된 storage도 같은 범주로 볼 수 있다.

Figure 11.3 · PDF p. 576 · moving parts 없이 controller와 NAND chips로 구성되는 SSD circuit board
NVM devices는 moving parts가 없어 HDD보다 reliable할 수 있고, seek time과 rotational latency가 없어 빠르며, power consumption도 낮다. 단점은 전통적 HDD보다 per-megabyte cost가 높고, 최대 capacity가 큰 HDD보다 작을 수 있다는 점이다. 하지만 capacity 증가와 price drop이 빠르게 진행되어 laptops/mobile devices에서 사용이 크게 늘었다.
NVM device가 HDD보다 매우 빠르기 때문에 bus interface가 throughput bottleneck이 될 수 있다. 그래서 일부 NVM devices는 PCIe 같은 system bus에 직접 연결된다. 이 흐름이 NVMe interface로 이어진다.
NAND Flash Characteristics
NAND flash는 read/write/erase granularity가 다르다. Page increment로 read/write할 수 있지만, 이미 write된 data를 overwrite할 수는 없다. 먼저 erase해야 하며, erase는 여러 pages로 구성된 block 단위로 일어난다. Erase는 read보다 훨씬 느리고, write보다도 느리다.
NAND flash에는 병렬성이 있다. 여러 die와 datapaths가 있어 operations를 parallel하게 수행할 수 있다. 하지만 NAND cells는 erase cycle마다 wear가 누적되고, 일정 program-erase cycles 후에는 data retention이 불가능해질 수 있다. 그래서 NAND lifespan은 단순 years가 아니라 DWPD (Drive Writes Per Day)로 표현된다. 예를 들어 1 TB drive with 5 DWPD는 warranty period 동안 하루 5 TB writes를 견딜 것으로 기대된다는 뜻이다.
NAND Flash Controller Algorithms
NAND는 overwrite가 불가능하므로 invalid data pages가 자연스럽게 생긴다. File-system block이 한 번 쓰인 뒤 다시 write되면, 첫 physical page에는 old invalid data가 남고, 두 번째 physical page가 current valid data가 된다.
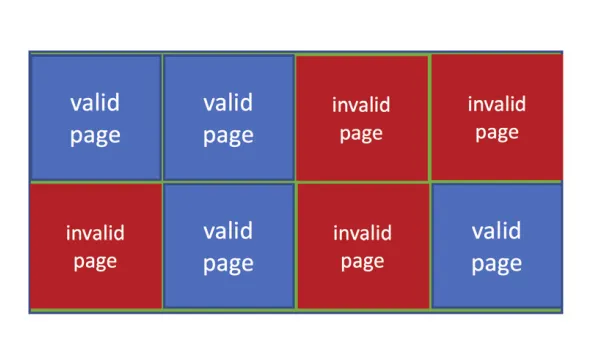
Figure 11.4 · PDF p. 577 · NAND block 안에 valid pages와 invalid pages가 함께 존재하는 상태
Controller는 FTL (Flash Translation Layer)을 유지해 logical blocks가 현재 어느 physical pages에 valid data로 있는지 mapping한다. 또한 어떤 physical blocks가 invalid pages만 포함해 erase 가능한지도 tracking한다.
SSD가 가득 찬 상태에서 write가 오면 문제가 복잡해진다. Free erased block이 있으면 erase 후 write할 수 있지만, free block이 없고 invalid pages가 scattered되어 있으면 garbage collection이 필요하다. GC는 valid data를 다른 곳으로 복사하고, invalid-only block을 만들어 erase한 뒤 write에 사용할 수 있게 한다. 문제는 GC 중 valid data를 복사할 공간도 필요하다는 점이다.
이를 위해 SSD는 over-provisioning을 사용한다. User-visible capacity 외에 spare pages/blocks를 따로 두어 writes, GC, full-device 상황을 처리한다. Over-provisioning area는 device가 full이어도 write 가능한 공간을 제공하고, invalid blocks를 erase해 free pool로 돌리는 완충 역할을 한다.
wear leveling은 blocks의 erase counts를 균등하게 분산한다. 특정 blocks만 반복 erase되면 그 blocks가 먼저 wear out되어 device lifespan이 줄어든다. Controller는 less-erased blocks에 data를 배치하고 future erases가 분산되도록 algorithm을 적용한다.
Data protection 측면에서 NVM devices도 HDDs처럼 error-correcting codes (ECC)를 data와 함께 저장한다. Correctible errors가 자주 발생하는 page는 bad로 mark되어 future writes에서 제외될 수 있다. 단일 device의 catastrophic failure에는 RAID protection이 필요하다.
11.1.3 Volatile Memory
DRAM은 volatile하지만 storage device처럼 쓰일 수 있다. RAM drive 또는 RAM disk는 device driver가 system DRAM 일부를 떼어 storage device처럼 보여 주는 것이다. Raw block device로 쓸 수도 있고, file system을 만들어 standard file operations로 쓸 수도 있다.
RAM drive는 crash, shutdown, power down 후 data가 사라진다. 하지만 user와 programs가 standard file operations로 high-speed temporary data를 저장할 수 있다는 장점이 있다. Linux의 /dev/ram, macOS의 diskutil로 만든 RAM disks, Solaris/Linux의 tmpfs 기반 /tmp가 예다. Linux boot 과정의 temporary root file system initrd도 storage device drivers가 준비되기 전에 root file system contents를 제공하는 데 쓰인다.
Magnetic tape는 nonvolatile이고 large capacity지만 random access가 매우 느리다. HDD보다 random access가 약 1,000배, SSD보다 약 100,000배 느릴 수 있어 secondary storage보다는 backup, infrequently used information storage, system 간 transfer에 적합하다.

Figure 11.5 · PDF p. 579 · backup과 archival storage에 주로 쓰이는 LTO-6 tape drive와 cartridge
11.1.4 Secondary Storage Connection Methods
Secondary storage device는 system bus 또는 I/O bus로 computer에 attached된다. 대표 interfaces는 ATA, SATA, eSATA, SAS, USB, FC (fibre channel)가 있고, 흔한 방식은 SATA다. NVM devices는 HDD보다 빠르므로 전용 high-speed interface인 NVMe가 만들어졌다. NVMe는 PCI bus에 직접 연결해 throughput을 높이고 latency를 줄인다.
Data transfer는 controllers 또는 host-bus adapters (HBA)가 수행한다. Host controller는 computer end에 있고, device controller는 storage device 안에 있다. OS가 mass storage I/O를 수행할 때 host controller에 command를 넣고, host controller는 device controller에 message를 보내며, device controller가 drive hardware를 조작한다. Device controller는 보통 built-in cache를 가진다. Drive 내부에서는 cache와 storage media 사이에서 transfer가 일어나고, host 측에서는 cache와 host DRAM 사이 transfer가 DMA로 빠르게 수행된다.
11.1.5 Address Mapping
OS는 storage devices를 large one-dimensional arrays of logical blocks로 본다. logical block은 smallest transfer unit이고, physical HDD sector 또는 semiconductor page에 mapping된다. LBA (logical block address)는 old-style HDD geometry인 cylinder/head/sector tuple이나 NVM의 chip/block/page tuple보다 algorithms가 다루기 쉽다.
HDD에서 이론적으로 LBA를 cylinder, track, sector로 변환할 수 있지만, 실제로는 어렵다.
| 이유 | 설명 |
|---|---|
| defective sectors hiding | drive가 spare sectors로 대체해 LBA sequence는 유지하지만 physical sector location은 달라진다. |
| variable sectors per track | outer tracks와 inner tracks의 sectors 수가 다를 수 있다. |
| internal manufacturer mapping | modern drives는 LBA-to-physical mapping을 내부적으로 관리해 LBA와 physical sector 관계가 약하다. |
그래도 HDD scheduling algorithms는 대체로 ascending logical addresses가 ascending physical addresses와 어느 정도 관련 있다고 가정한다.
Rotating media의 mapping에는 CLV와 CAV가 있다. CLV (constant linear velocity)는 bit density를 track 전체에 uniform하게 유지하므로 outer tracks가 더 많은 sectors를 담고, head가 안쪽으로 갈수록 rotation speed를 높여 data rate를 유지한다. CD-ROM/DVD-ROM이 이 방식을 쓴다. CAV (constant angular velocity)는 rotation speed를 일정하게 유지하고, hard disks에서 쓰인다. 이 경우 data rate/performance가 위치에 따라 비교적 일정하게 유지되도록 bit density가 조정된다.
Storage devices는 HDD/NVM만 있는 것이 아니다. Shingled magnetic recording drives, NVM+HDD hybrid devices, volume managers가 여러 devices를 하나의 storage unit처럼 묶는 구조도 있다. 이런 devices는 mainstream HDD/NVM과 다른 performance 특성을 가지므로 caching/scheduling algorithms도 달라질 수 있다.
11.2 HDD Scheduling
OS의 책임 중 하나는 hardware를 효율적으로 쓰는 것이다. HDD에서는 access time을 줄이고 data transfer bandwidth를 높이는 것이 핵심이다. HDD access time은 주로 두 요소로 구성된다.
device bandwidth는 첫 request service 시작부터 마지막 transfer 완료까지의 전체 시간으로 나눈 total bytes transferred다. Pending I/O requests의 service order를 조정하면 access time과 bandwidth를 개선할 수 있다.
Process가 drive I/O를 요청할 때 OS system call에는 보통 다음 정보가 포함된다.
| 정보 | 의미 |
|---|---|
| input/output 여부 | read인지 write인지 |
| open file handle | 어떤 file에 대한 operation인지 |
| memory address | transfer buffer 주소 |
| amount of data | transfer할 data 크기 |
Drive/controller가 idle이면 즉시 처리할 수 있다. Busy이면 request는 device queue에 들어간다. Multiprogramming system에서는 queue에 pending requests가 여러 개 있을 수 있고, device driver는 이 queue ordering으로 performance를 개선할 기회를 얻는다.
과거 HDD interfaces는 track/head 같은 physical detail을 host가 알 수 있었기 때문에 disk scheduling algorithms가 physical head movement를 직접 줄이는 데 초점을 맞췄다. Modern drives는 LBA-to-physical mapping을 drive 내부에서 관리하므로 host가 정확한 head location이나 physical cylinder를 알 수 없다. 그래도 LBAs가 가까우면 physical blocks도 대체로 가깝다고 rough하게 가정할 수 있어, sequential I/O를 bunching하는 scheduling은 여전히 유용하다. 현대 disk scheduling의 목표는 fairness, timeliness, sequential optimization의 균형이다.
11.2.1 FCFS Scheduling
FCFS (First-Come, First-Served) 또는 FIFO scheduling은 request arrival order대로 처리한다. Intrinsically fair하지만 fastest service를 보장하지 않는다.
예를 들어 queue가 다음 cylinders를 요청하고 head가 cylinder 53에서 시작한다고 하자.
queue = 98, 183, 37, 122, 14, 124, 65, 67
head starts at 53FCFS는 53 → 98 → 183 → 37 → 122 → 14 → 124 → 65 → 67 순서로 이동해 total head movement가 640 cylinders가 된다.
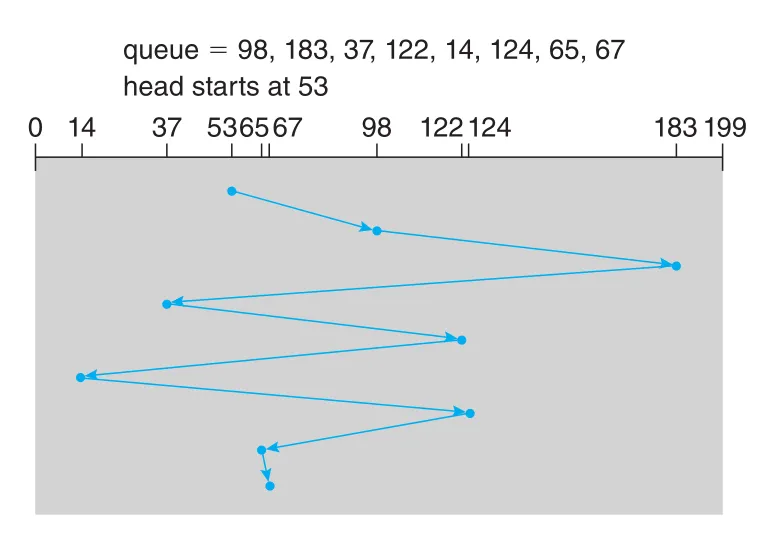
Figure 11.6 · PDF p. 583 · 요청 도착 순서대로 처리해 head가 크게 왕복하는 FCFS disk scheduling
122에서 14로 갔다가 다시 124로 가는 큰 swing이 FCFS의 문제를 보여 준다. 37과 14를 함께 처리하고, 122와 124를 함께 처리하면 total head movement를 크게 줄일 수 있다.
11.2.2 SCAN Scheduling
SCAN은 disk arm이 한쪽 끝에서 다른쪽 끝으로 이동하며 지나가는 cylinders의 requests를 처리하고, 끝에 도달하면 방향을 바꿔 다시 처리한다. Elevator가 위로 가며 요청을 처리하고 끝에서 아래로 내려오는 것과 같아 elevator algorithm이라고도 한다.
위 queue에서 head가 53에 있고 0 방향으로 이동 중이라고 하자. SCAN은 37, 14를 처리하고 cylinder 0에서 방향을 바꾼 뒤 65, 67, 98, 122, 124, 183을 처리한다.
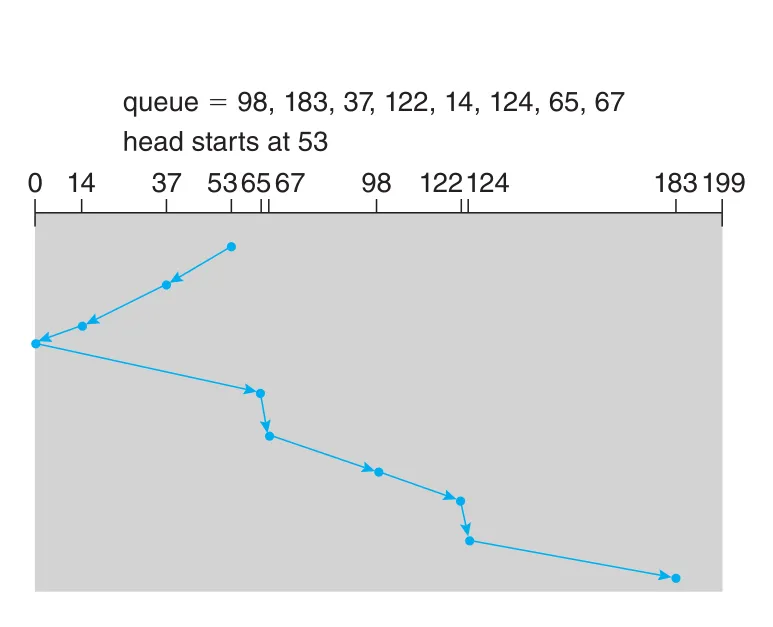
Figure 11.7 · PDF p. 583 · 한 방향으로 이동하며 requests를 처리하고 끝에서 방향을 바꾸는 SCAN scheduling
SCAN의 특성상 head 바로 앞에 도착한 request는 빠르게 처리되지만, head 바로 뒤에 도착한 request는 head가 끝까지 갔다가 돌아올 때까지 기다려야 한다. 또한 끝에서 방향을 바꾼 직후에는 앞쪽 requests가 상대적으로 적고, 반대쪽 끝에는 오래 기다린 requests가 많이 쌓이는 경향이 있다.
11.2.3 C-SCAN Scheduling
C-SCAN (Circular SCAN)은 wait time을 더 uniform하게 만들기 위한 SCAN 변형이다. Head는 한 방향으로 이동하며 requests를 처리한다. 끝에 도달하면 return trip에서는 requests를 처리하지 않고 즉시 시작점으로 돌아간다. Cylinders를 마지막에서 처음으로 wrap around되는 circular list처럼 보는 셈이다.
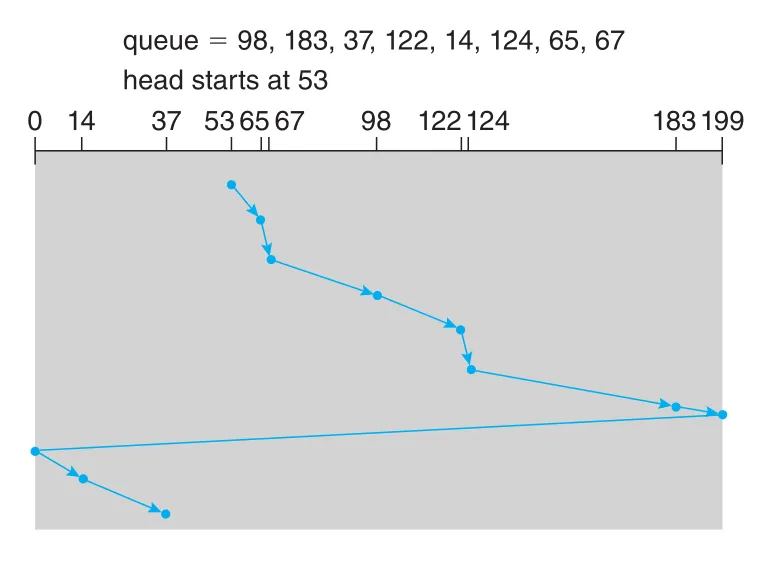
Figure 11.8 · PDF p. 584 · 한 방향으로만 servicing하고 끝에서 처음으로 돌아가는 C-SCAN scheduling
C-SCAN은 SCAN보다 wait time 분포가 균일하다. 모든 requests가 같은 방향 sweep에서 처리되기 때문이다.
11.2.4 Selection of a Disk-Scheduling Algorithm
Particular request list에 대해 optimal order를 계산할 수는 있지만, 그 계산 비용이 SCAN보다 얻는 이익을 정당화하지 못할 수 있다. Scheduling performance는 queue length와 request type에 크게 의존한다. Queue에 outstanding request가 하나뿐이면 모든 algorithm은 FCFS와 같다.
Heavy disk load에서는 SCAN/C-SCAN이 starvation 가능성을 줄이고 throughput을 개선할 수 있다. 하지만 starvation이 완전히 사라지는 것은 아니다. Linux는 이를 완화하기 위해 deadline scheduler를 만들었다. Deadline은 read/write queues를 나누고, read에 priority를 준다. Processes는 write보다 read에서 block될 가능성이 높기 때문이다. LBA-order queues로 C-SCAN에 가까운 batching을 하되, FCFS queues에서 configured age, 기본 500 ms보다 오래된 requests가 있으면 그 queue를 다음 batch로 선택해 starvation을 제한한다.
Linux에는 NOOP과 CFQ 같은 schedulers도 있다. NOOP은 fast storage, 특히 NVM devices를 사용하는 CPU-bound systems에 적합하며 FCFS에 adjacent request merge를 더한다. CFQ (Completely Fair Queueing)는 real-time, best-effort, idle queues를 두고 LBA order를 유지하며, process가 곧 추가 I/O를 낼지 historical data로 예측해 locality를 활용하기도 한다.
11.3 NVM Scheduling
앞의 disk scheduling algorithms는 HDD처럼 mechanical platter와 moving head가 있는 storage에 맞춰져 있다. NVM devices에는 moving head가 없으므로 head movement를 줄일 필요가 없다. 그래서 일반적으로 simple FCFS policy가 자연스럽다. Linux NOOP scheduler는 FCFS를 쓰되 adjacent requests를 merge한다.
NVM에서 read service time은 비교적 uniform하지만, flash memory 특성 때문에 write service time은 uniform하지 않다. 그래서 일부 SSD schedulers는 adjacent write requests만 merge하고, read requests는 FCFS로 처리한다.
Sequential access는 HDD/tape 같은 mechanical devices에 특히 유리하다. Data가 read/write head 근처에 있기 때문이다. Random-access I/O는 IOPS로 측정되며 HDD에서는 head movement 때문에 느리다. HDD는 hundreds of IOPS 수준인 반면, SSD는 hundreds of thousands of IOPS를 낼 수 있다.
하지만 raw sequential throughput에서는 NVM의 이점이 random I/O만큼 크지 않을 수 있다. HDD head seeks가 최소화되고 media transfer가 중심이 되면 reads에서 HDD와 NVM이 비슷하거나 NVM이 한 order 정도 빠른 수준일 수 있다. Writes는 NVM에서 reads보다 느리므로 advantage가 더 줄어든다. 또 HDD write performance는 device lifetime 동안 비교적 consistent하지만, NVM write performance는 fullness, garbage collection, over-provisioning 상태, wear 정도에 따라 변한다. End-of-life에 가까운 NVM device는 새 device보다 성능이 훨씬 낮을 수 있다.
NVM write performance를 이해하는 핵심은 write amplification이다. Random read/write load에서 all blocks가 write된 뒤 invalid data가 scattered되어 있으면 GC가 필요하다. Application write 하나가 실제로는 다음 internal operations를 만들 수 있다.
application write
-> page write of new data
-> GC reads of valid pages from victim block
-> writes of valid pages to over-provisioning space
-> erase of all-invalid-data block즉 application이 요청하지 않은 reads/writes가 controller 내부 space management 때문에 발생한다. 이 현상이 write amplification이고, worst case에서는 write request 하나가 여러 extra I/Os를 유발해 write performance를 크게 낮춘다. File system이 deleted files의 blocks를 device에 알려 주면 device가 해당 blocks를 미리 erase/reclaim할 수 있어 lifespan과 performance가 개선된다.
11.4 Error Detection and Correction
error detection and correction은 memory, networking, storage 모두에서 핵심이다. Error detection은 DRAM bit flip, network packet corruption, storage block corruption처럼 data가 바뀌었는지 확인한다. 이를 통해 system은 corrupted data propagation을 막고, user/admin에게 error를 보고하거나 failing device warning을 줄 수 있다.
가장 단순한 예는 parity bit다. Byte마다 parity bit를 두어 1 bits 수가 even인지 odd인지 기록한다. Data bit 하나가 flipped되면 computed parity와 stored parity가 달라져 single-bit error를 detect할 수 있다. Stored parity bit 자체가 damaged되어도 mismatch가 난다. 하지만 double-bit errors는 parity로 detection되지 않을 수 있다. Parity는 bits의 XOR로 쉽게 계산되지만 byte마다 extra bit storage가 필요하다.
checksum은 fixed-length words에 modular arithmetic을 적용해 computed/stored values를 비교하는 error-detection method다. Networking에서 흔한 CRC (cyclic redundancy check)는 multiple-bit errors를 detect하기 위해 hash function에 가까운 방식을 사용한다.
ECC (Error-Correcting Code)는 error를 detect할 뿐 아니라 correct한다. 추가 storage와 algorithm을 사용해 corrupted bits가 어느 bits인지 식별하고 correct value를 계산한다. Disk drives는 per-sector ECC, flash drives는 per-page ECC를 사용한다. Write 시 data bytes로부터 ECC value를 계산해 함께 저장하고, read 시 ECC를 재계산해 stored value와 비교한다.
Mismatch가 있으면 data corruption 또는 bad media 가능성을 뜻한다. 적은 수의 bits만 corrupted되었으면 controller가 correct하고 recoverable soft error를 보고한다. 너무 많은 changes가 있어 ECC가 correct할 수 없으면 noncorrectable hard error가 signal된다. ECC processing은 sector/page read/write 때 controller가 자동 수행한다.
11.5 Storage Device Management
OS는 storage device를 단순히 read/write하는 것만이 아니라, drive initialization, booting, bad-block recovery도 관리한다.
11.5.1 Drive Formatting, Partitions, and Volumes
새 storage device는 처음에는 blank slate다. HDD라면 magnetic recording material로 된 platters이고, NVM이라면 uninitialized semiconductor cells다. Device가 data를 저장하려면 controller가 read/write할 수 있는 sectors 또는 pages로 나누어져야 한다. NVM은 pages initialization과 FTL creation도 필요하다. 이 과정이 low-level formatting 또는 physical formatting이다.
Low-level formatting은 각 sector/page에 special data structure를 채운다. 보통 header, data area, trailer로 구성되며, header/trailer에는 sector/page number와 error detection/correction code 같은 controller용 metadata가 들어간다. 대부분의 drives는 factory에서 low-level formatting된다. 이때 manufacturer는 device를 test하고 logical block numbers를 defect-free sectors/pages에 mapping한다.
OS가 drive를 files storage로 사용하려면 세 단계가 필요하다.
| 단계 | 작업 | 결과 |
|---|---|---|
1. partitioning | device blocks/pages를 one or more groups로 나눈다. | 각 partition을 separate device처럼 다룰 수 있다. |
2. volume creation/management | partition 하나를 volume으로 쓰거나, multiple partitions/devices를 RAID/logical volume으로 묶는다. | mount 가능한 storage unit을 만든다. |
3. logical formatting | file system data structures를 device에 기록한다. | free/allocated space maps, empty directory 등 초기 file system이 생긴다. |
Linux에서는 fdisk가 partitions를 관리하고, OS가 device를 인식하면 partition information을 읽어 /dev 아래 device entries를 만든다. /etc/fstab 같은 configuration file은 어떤 partition의 file system을 어디에 mount할지, read-only 같은 mount options는 무엇인지 알려 준다. mounting은 file system을 system과 users가 사용할 수 있게 연결하는 작업이다.
Volume은 단순히 partition 안에 file system을 둔 것일 수도 있고, multiple devices를 RAID set으로 묶은 후 그 위에 file systems를 spread한 것일 수도 있다. Linux의 lvm2는 logical volume management를 제공하고, ZFS는 volume management와 file system을 통합한다.
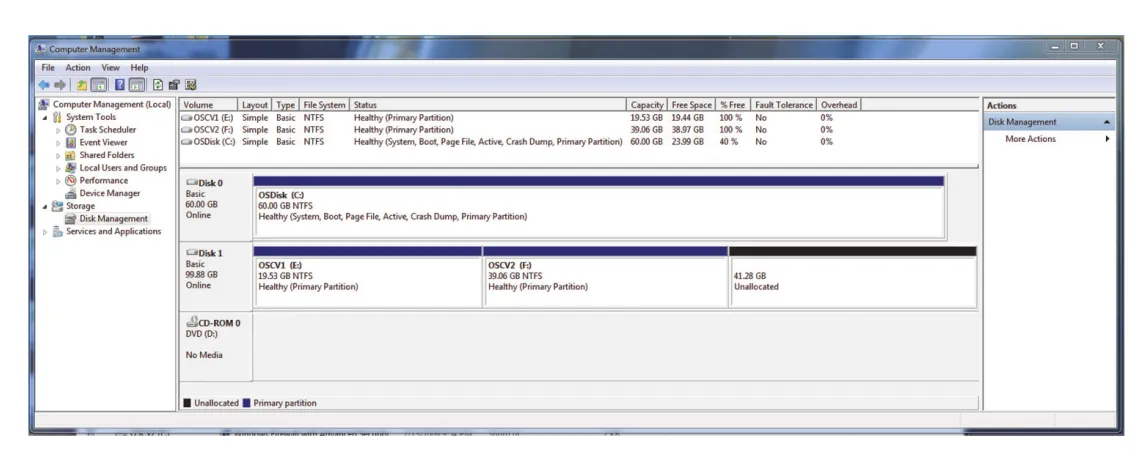
Figure 11.9 · PDF p. 589 · devices, partitions, volumes, file systems를 보여 주는 Windows Disk Management 예
Windows는 volumes를 C:, D:, E:처럼 separate drive letters로 보여 주는 반면, Linux는 boot file system을 root로 mount하고 다른 file systems를 tree 안에 mount한다. 따라서 Linux에서는 single file access가 여러 mounted devices를 traverse할 수 있다.
File systems는 efficiency를 위해 blocks를 larger chunks인 clusters로 묶는 경우가 많다. Device I/O는 blocks 단위지만 file-system I/O는 clusters 단위가 되어 sequential-access 성격이 늘고 random-access가 줄어든다. File systems는 file contents를 metadata 근처에 배치해 HDD head seeks를 줄이려 한다.
일부 OS는 special programs가 partition을 file system 없이 large sequential array of logical blocks처럼 쓰도록 허용한다. 이것이 raw disk, raw I/O다. Raw I/O는 buffer cache, file locking, prefetching, space allocation, file names, directories 같은 file-system services를 우회한다. Database systems나 swap space가 raw I/O를 선호할 수 있지만, 대부분 applications는 OS file system services를 쓰는 편이 낫다. Linux는 일반적으로 raw I/O를 직접 지원하지 않지만 open() system call의 DIRECT flag로 비슷한 access를 제공할 수 있다.
11.5.2 Boot Block
Computer가 power up 또는 reboot될 때는 처음 실행할 initial program이 필요하다. 이 bootstrap loader는 보통 system motherboard의 NVM flash firmware에 저장되고 known memory location에 mapped된다. Firmware는 CPU registers, device controllers, main memory contents 같은 system 기본 상태를 초기화한다.
Tiny bootstrap loader는 secondary storage의 fixed location에 저장된 full bootstrap program을 가져올 만큼만 똑똑하다. Full bootstrap program은 boot blocks에 저장되고, OS kernel을 device의 non-fixed location에서 찾아 load할 수 있다. Boot partition이 있는 device는 boot disk 또는 system disk라고 한다.
Windows boot 과정을 예로 보면, drive는 partitions로 나뉘고 boot partition에는 OS와 device drivers가 있다. Windows는 first logical block 또는 first NVM page에 boot code를 두며, 이를 MBR (master boot record)라고 한다.
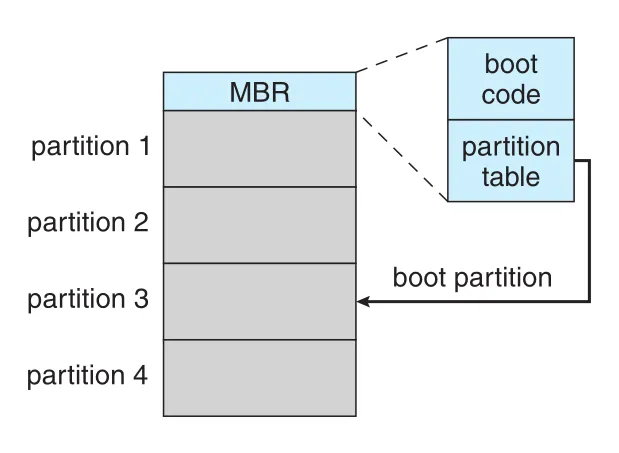
Figure 11.10 · PDF p. 590 · MBR의 boot code와 partition table을 통해 boot partition을 찾아 OS loading으로 이어지는 Windows boot 구조
Firmware code는 MBR의 boot code를 read하고 실행한다. MBR은 boot code뿐 아니라 drive partitions table과 어떤 partition으로 boot할지 나타내는 flag를 가진다. System은 boot partition을 식별한 뒤 그 partition의 first sector/page, 즉 boot sector를 읽고, 여기서 kernel 위치를 찾아 나머지 boot process를 계속한다.
11.5.3 Bad Blocks
HDD는 moving parts와 작은 tolerances 때문에 failure에 취약하다. 완전 failure가 나면 drive를 교체하고 backup에서 contents를 restore해야 한다. 더 흔한 경우는 one or more sectors가 defective해지는 것이다. 많은 disks는 factory 출하 시점부터 bad blocks를 가지고 있다.
Older disks에서는 bad blocks를 manual하게 처리했다. Formatting 중 scan해 bad blocks를 찾아 unusable로 flag하고, file system이 할당하지 않게 한다. Operation 중 blocks가 bad가 되면 Linux badblocks 같은 special program으로 찾아 lock away해야 하고, 그 blocks에 있던 data는 보통 lost된다.
Sophisticated disks는 controller가 bad blocks list를 유지한다. Factory low-level formatting 때 초기화되고 lifetime 동안 update된다. 또 OS에 보이지 않는 spare sectors를 따로 둔다. Controller가 bad sector를 spare sector로 logically replace하는 방식을 sector sparing 또는 forwarding이라고 한다.
Typical bad-sector transaction은 다음과 같다.
- OS가 logical block 87을 read하려 한다.
- Controller가 ECC를 계산해 sector가 bad임을 발견하고 OS에 I/O error를 보고한다.
- Device controller가 bad sector를 spare sector로 replace한다.
- 이후 logical block 87 요청은 controller가 replacement sector address로 translate한다.
Controller redirection은 OS disk-scheduling optimization을 무효화할 수 있다. 그래서 disks는 보통 각 cylinder에 spare sectors를 두고 spare cylinder도 둔다. Bad block remap 시 가능하면 같은 cylinder의 spare sector를 사용해 scheduling locality를 덜 깨뜨린다.
대안으로 sector slipping이 있다. 예를 들어 logical block 17이 defective이고 first available spare가 sector 202 뒤에 있다면, sector 202를 spare로 복사하고 201을 202로, 200을 201로, … 18을 19로 밀어 sector 18 자리를 비워 17을 remap한다.
NVM devices도 manufacturing time 또는 lifetime 중 bad pages가 생길 수 있다. 하지만 seek time이 없으므로 bad-page replacement location이 physically 가까워야 할 필요가 작다. Multiple replacement pages를 두거나 over-provisioning area를 사용한다. Controller는 bad pages table을 유지하고 그런 pages를 future writes에서 제외한다.
11.6 Swap-Space Management
Chapter 9에서 swapping은 entire process를 secondary storage와 main memory 사이에서 이동시키는 것으로 소개되었다. 하지만 modern OS는 보통 entire process swapping보다 Chapter 10의 virtual memory techniques와 결합해 pages를 swap한다. 그래서 일부 systems에서는 swapping과 paging을 거의 interchangeably 사용한다.
swap-space management는 OS의 low-level task다. Virtual memory는 secondary storage를 main memory extension처럼 사용하지만, drive access는 memory access보다 훨씬 느리다. 따라서 swap space design의 목표는 virtual memory system throughput을 최대화하는 것이다.
11.6.1 Swap-Space Use
Swap space 사용 방식은 OS memory-management algorithm에 따라 다르다. Swapping system은 entire process image, code/data segments까지 swap space에 저장할 수 있다. Paging system은 main memory에서 밀려난 pages만 저장할 수 있다.
필요한 swap space 양은 physical memory, backing해야 할 virtual memory, virtual memory 사용 방식에 따라 몇 MB부터 수 GB까지 달라질 수 있다. Underestimate보다 overestimate가 안전하다. Swap space가 부족하면 system이 processes를 abort하거나 crash할 수 있다. Overestimate는 secondary storage space를 낭비하지만 그 외 harm은 작다.
Linux는 multiple swap spaces를 허용하며, swap files와 dedicated swap partitions를 모두 사용할 수 있다. 여러 storage devices에 swap spaces를 분산하면 paging/swapping I/O load를 system I/O bandwidth에 나눌 수 있다.
11.6.2 Swap-Space Location
Swap space는 file system 안의 large file일 수도 있고, separate raw partition일 수도 있다.
| 위치 | 장점 | 단점 |
|---|---|---|
swap file | normal file-system routines로 create/name/allocate가 쉬움 | file-system overhead와 fragmentation 가능성 |
swap partition, raw partition | file-system structure 없이 speed-optimized allocation 가능 | fixed size. 늘리려면 repartitioning 또는 추가 swap 필요 |
Raw partition의 swap-space storage manager는 storage efficiency보다 speed를 위해 optimize된다. Swap space는 file system보다 훨씬 자주 access될 수 있고, data lifetime이 files보다 짧다. Internal fragmentation이 늘어도 boot time에 reinitialized되므로 short-lived이다. Trade-off는 file-system allocation/management convenience와 raw partition performance 사이에 있다.
11.6.3 Swap-Space Management: An Example
Traditional UNIX는 entire processes를 contiguous disk regions와 memory 사이에서 copy하는 swapping으로 시작했다. 이후 paging hardware가 등장하면서 swapping과 paging을 결합했다.
Solaris 1에서는 text-segment code pages를 file system에서 가져오고, pageout 대상으로 선택되면 그냥 버렸다. Code page는 file system에서 다시 read하는 것이 swap space에 write했다가 다시 read하는 것보다 효율적이기 때문이다. Swap space는 stack, heap, uninitialized data 같은 file-backed가 아닌 anonymous memory의 backing store로 사용되었다.
Later Solaris는 virtual memory page가 처음 만들어질 때가 아니라 physical memory에서 밀려날 때 swap space를 allocate하도록 바뀌었다. Modern computers는 physical memory가 많고 page out이 덜 발생하므로 이 방식이 성능에 더 좋다.
Linux도 Solaris와 비슷하게 swap space를 anonymous memory에 주로 사용한다. Linux는 one or more swap areas를 만들 수 있고, 각 swap area는 regular file system의 swap file이거나 dedicated swap partition일 수 있다. 각 swap area는 swapped pages를 담는 4-KB page slots의 series로 구성된다. 각 swap area에는 swap map이 있으며, page slot마다 integer counter가 대응된다.
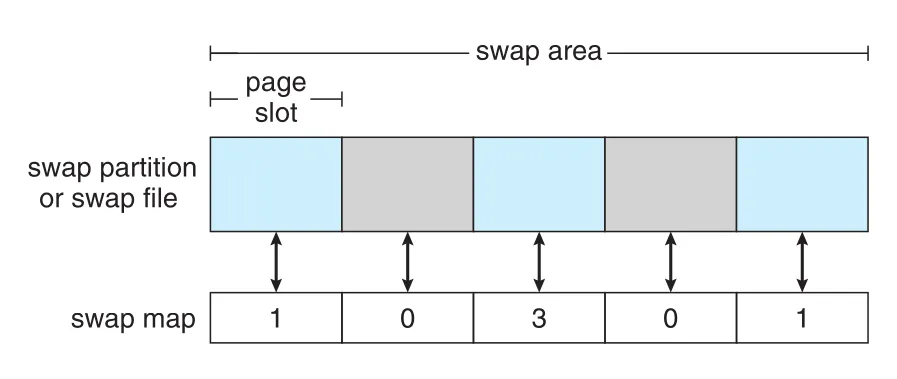
Figure 11.11 · PDF p. 594 · Linux swap area의 page slots와 각 slot의 사용 여부 및 mapping count를 담는 swap map
Swap map counter가 0이면 해당 page slot은 available하다. 0보다 크면 swapped page가 occupied하고 있다는 뜻이다. Counter value는 그 swapped page에 대한 mappings 수를 나타낸다. 예를 들어 3이면 shared memory region처럼 세 processes가 같은 swapped page를 mapping하고 있을 수 있다.
11.7 Storage Attachment
Computer는 secondary storage를 세 방식으로 access한다. host-attached storage, network-attached storage, cloud storage다. 여기에 enterprise 환경에서는 SAN과 storage array가 결합되어 storage를 여러 hosts에 flexible하게 제공한다.
11.7.1 Host-Attached Storage
host-attached storage는 local I/O ports를 통해 access하는 storage다. 흔한 technology는 SATA이고, USB, FireWire, Thunderbolt로 external devices/chassis를 붙일 수도 있다. High-end workstations와 servers는 더 많은 storage 또는 shared storage가 필요해 FC (fibre channel) 같은 high-speed serial architecture를 사용하기도 한다.
Host-attached storage의 I/O command는 특정 storage unit, 예를 들어 bus ID나 target logical unit에 directed된 logical data blocks의 reads/writes다. 즉 host는 storage를 block device로 보고 logical blocks를 읽고 쓴다.
11.7.2 Network-Attached Storage
NAS (network-attached storage)는 network를 통해 storage access를 제공한다. NAS device는 special-purpose storage system일 수도 있고, 자기 storage를 network로 제공하는 general computer일 수도 있다.
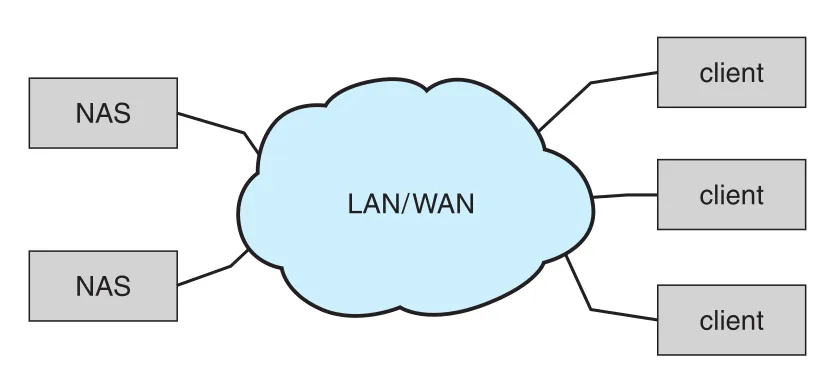
Figure 11.12 · PDF p. 595 · LAN/WAN을 통해 clients가 NAS devices의 storage를 공유하는 구조
Clients는 UNIX/Linux의 NFS, Windows의 CIFS 같은 RPC interface로 NAS를 access한다. RPCs는 TCP 또는 UDP over IP network로 전달되며, 보통 clients의 data traffic과 같은 LAN을 쓴다. NFS/CIFS는 file sharing protocols이므로 locking features를 제공해 여러 hosts가 같은 files를 공유할 수 있게 한다.
NAS의 장점은 LAN 안의 computers가 local storage처럼 naming/access 편의성을 가진 shared storage pool을 쓸 수 있다는 것이다. 단점은 direct-attached storage보다 효율과 performance가 낮을 수 있다는 점이다.
iSCSI는 IP network로 SCSI protocol을 운반한다. NFS/CIFS가 file system을 제공하고 file pieces를 network로 보낸다면, iSCSI는 logical blocks를 network로 보내고 client가 그 blocks를 직접 쓰거나 그 위에 file system을 만든다. 그래서 storage가 멀리 있어도 host는 directly attached block device처럼 다룰 수 있다.
11.7.3 Cloud Storage
cloud storage는 NAS처럼 network를 통해 storage를 제공하지만, 보통 Internet 또는 WAN을 통해 remote data center storage를 fee 또는 free로 사용하는 방식이다. NAS가 OS에 integrated된 NFS/CIFS/iSCSI protocols로 file system 또는 block device처럼 보이는 반면, cloud storage는 주로 API-based access를 제공한다. Amazon S3, Dropbox, Microsoft OneDrive, Apple iCloud가 예다.
Cloud storage가 기존 NAS protocols 대신 APIs를 많이 쓰는 이유는 WAN latency와 failure scenarios 때문이다. NFS/CIFS는 LAN처럼 latency가 낮고 connectivity loss가 드문 환경을 전제로 설계되었다. WAN에서는 connectivity failure가 더 흔하므로, application이 access를 pause하고 connectivity restoration을 기다리는 API model이 더 적합할 수 있다.
11.7.4 Storage-Area Networks and Storage Arrays
NAS의 단점은 storage I/O가 data network bandwidth를 사용해 network communication latency를 높일 수 있다는 것이다. Large client-server installations에서는 server-client traffic과 server-storage traffic이 같은 network bandwidth를 두고 경쟁한다.
SAN (storage-area network)은 servers와 storage units를 연결하는 private network다. Networking protocols가 아니라 storage protocols를 사용한다.
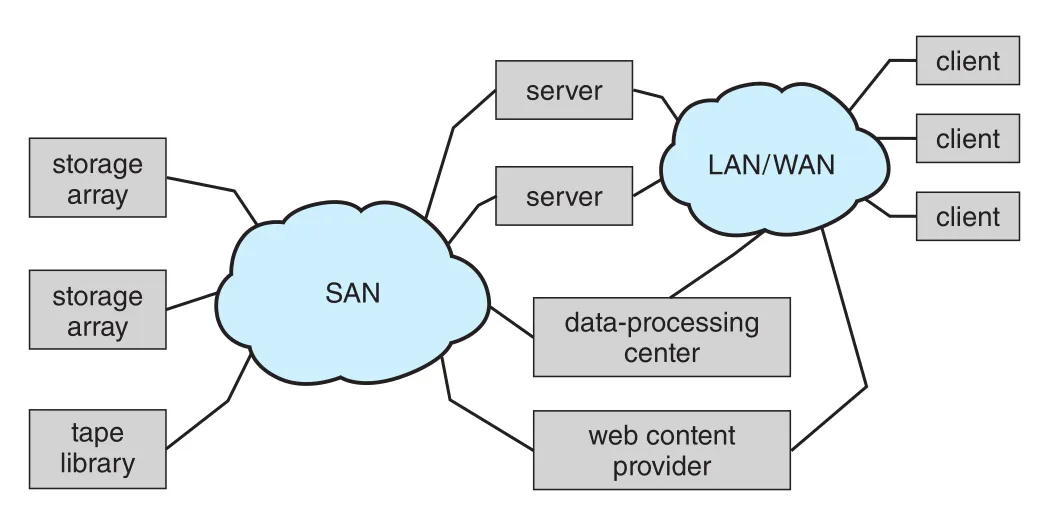
Figure 11.13 · PDF p. 596 · servers, storage arrays, tape library를 private storage network로 연결하는 SAN 구조
SAN의 장점은 flexibility다. Multiple hosts와 multiple storage arrays가 같은 SAN에 attach될 수 있고, storage를 hosts에 dynamically allocate할 수 있다. SAN switch는 hosts와 storage 사이 access를 허용하거나 금지한다. Host disk space가 부족하면 SAN configuration으로 더 많은 storage를 줄 수 있고, server cluster가 같은 storage를 공유할 수도 있다.
storage array는 SAN ports, network ports 또는 둘 다를 가진 purpose-built device다. 내부에는 drives와 controller 또는 redundant controllers가 있으며, controllers는 CPUs, memory, software로 구성되어 storage access와 features를 제공한다.

Figure 11.14 · PDF p. 597 · drives와 controllers를 포함하고 RAID, snapshots, replication 등을 제공할 수 있는 storage array
Storage array는 RAID protection, snapshots, replication, compression, deduplication, encryption 등을 제공할 수 있다. SSD-only array는 maximum performance를 제공하지만 capacity가 작을 수 있고, SSD+HDD mixed array는 SSD를 cache로 쓰고 HDD를 bulk storage로 쓰는 식으로 balance를 잡을 수 있다. SAN interconnect로는 FC가 흔하고, iSCSI는 단순성 때문에 사용이 늘고 있으며, InfiniBand도 high-speed server/storage interconnect로 쓰인다.
Attachment 방식은 다음처럼 비교할 수 있다.
| 방식 | Host가 보는 interface | 주 사용 환경 | 핵심 trade-off |
|---|---|---|---|
host-attached storage | local block device | single host, direct I/O | 단순하고 빠르지만 sharing/flexibility 제한 |
NAS | network file system 또는 iSCSI block device | LAN file sharing | 편리하지만 data network bandwidth 사용 |
cloud storage | API object/file service | WAN/Internet remote storage | scalable하지만 latency/failure handling이 application/API 중심 |
SAN | private storage fabric의 block storage | enterprise servers/clusters | flexible/high performance이지만 비용과 복잡도 증가 |
11.8 RAID Structure
Storage devices가 작고 저렴해지면서 한 system에 여러 drives를 붙이는 것이 경제적으로 가능해졌다. 여러 drives를 parallel로 동작시키면 read/write rate를 높일 수 있고, redundant information을 여러 drives에 저장하면 한 drive failure가 곧 data loss로 이어지지 않게 할 수 있다. 이런 organization techniques를 통틀어 RAID (redundant arrays of independent disks)라고 한다.
초기 RAID의 I는 inexpensive를 뜻하는 맥락이 강했지만, 현대 RAID는 값싼 disk 대체재라기보다 higher reliability와 higher data-transfer rate를 위한 구조로 이해하는 편이 정확하다. RAID는 HDD뿐 아니라 NVM devices에도 적용될 수 있다. 다만 NVM은 moving parts가 없어 HDD보다 failure characteristics가 다르다.
RAID는 여러 위치에서 구현될 수 있다.
| 구현 위치 | 특징 |
|---|---|
| OS 또는 volume-management software | kernel/system software가 RAID를 구현한다. Hardware는 단순해도 된다. |
HBA hardware | host bus-adapter가 직접 연결된 drives로 RAID set을 만든다. 비용은 낮지만 flexibility가 낮다. |
storage array hardware | array controller가 RAID sets/volumes를 만들고 OS에는 volume을 제공한다. SAN/multiple hosts와 결합하기 쉽다. |
SAN interconnect virtualization device | hosts와 storage 사이 device가 commands를 받아 mirroring 등 storage virtualization을 수행한다. |
11.8.1 Improvement of Reliability via Redundancy
Drive 수가 늘어나면 “어떤 drive 하나가 실패할 확률”은 단일 drive failure 확률보다 훨씬 커진다. 예를 들어 single disk의 MTBF가 100,000 hours라도 100개 disks array에서는 어떤 disk 하나가 fail할 평균 시간이 대략 1,000 hours, 약 41.66 days가 된다. 따라서 data를 한 copy만 저장하면 대규모 drive set은 data loss 위험이 너무 커진다.
해결책은 redundancy다. 정상 동작 중에는 필요하지 않지만 drive failure가 발생했을 때 lost information을 rebuild하는 extra information을 저장한다.
가장 단순한 redundancy는 mirroring이다. Logical disk를 두 physical drives로 구성하고 every write를 both drives에 수행한다. 한 drive가 fail하면 다른 drive에서 data를 읽을 수 있다. Data loss는 failed drive를 replace/rebuild하기 전에 mirror 쪽 drive까지 fail할 때 발생한다.
Mirrored volume의 reliability는 individual drives의 MTBF와 failed drive를 replace하고 data를 restore하는 MTTR에 의해 결정된다. 책의 예시처럼 single drive MTBF가 100,000 hours, MTTR이 10 hours라면 mirrored drive system의 mean time to data loss는 매우 커진다. 하지만 drive failures가 완전히 independent라고 가정하면 안 된다. Power failure, 자연재해, 같은 batch의 manufacturing defects, drive aging은 correlated failures를 만들 수 있다.
Power failure는 mirroring에서도 주의해야 한다. 같은 block을 두 drives에 write하는 중 power가 끊기면 두 copies가 inconsistent할 수 있다. 한 copy를 먼저 쓰고 다음 copy를 쓰는 방식, 또는 ECC/mirroring으로 보호되는 solid-state nonvolatile write-back cache를 RAID array에 두는 방식으로 이 문제를 줄일 수 있다.
11.8.2 Improvement in Performance via Parallelism
RAID의 성능 향상은 parallelism에서 나온다. Mirroring은 read requests를 두 drives 중 하나로 보낼 수 있으므로 처리 가능한 read requests rate를 높인다. Single read transfer rate는 같아도 unit time당 처리 가능한 reads가 늘어난다.
striping은 transfer rate를 높이기 위해 data를 여러 drives에 분산한다.
| Striping level | 방식 | 효과 |
|---|---|---|
bit-level striping | byte의 bit들을 여러 drives에 나누어 저장 | 모든 drive가 매 access에 참여해 한 번에 더 많은 data를 전송 |
block-level striping | file blocks를 drives에 round-robin으로 배치. n drives라면 block i는 drive (i mod n) + 1 | 여러 independent requests를 drives에 분산하고 large access response time을 줄임 |
실제로 널리 쓰이는 것은 block-level striping이다. Striping이 추구하는 목표는 두 가지다. 첫째, multiple small accesses, 예를 들어 page accesses를 load balancing해 throughput을 높인다. 둘째, large accesses의 response time을 줄인다.
11.8.3 RAID Levels
Mirroring은 reliability가 높지만 expensive하다. Striping은 data-transfer rate를 높이지만 reliability를 높이지 않는다. RAID levels는 striping과 redundancy, 특히 parity를 결합해 cost-performance trade-off를 나눈 분류다.
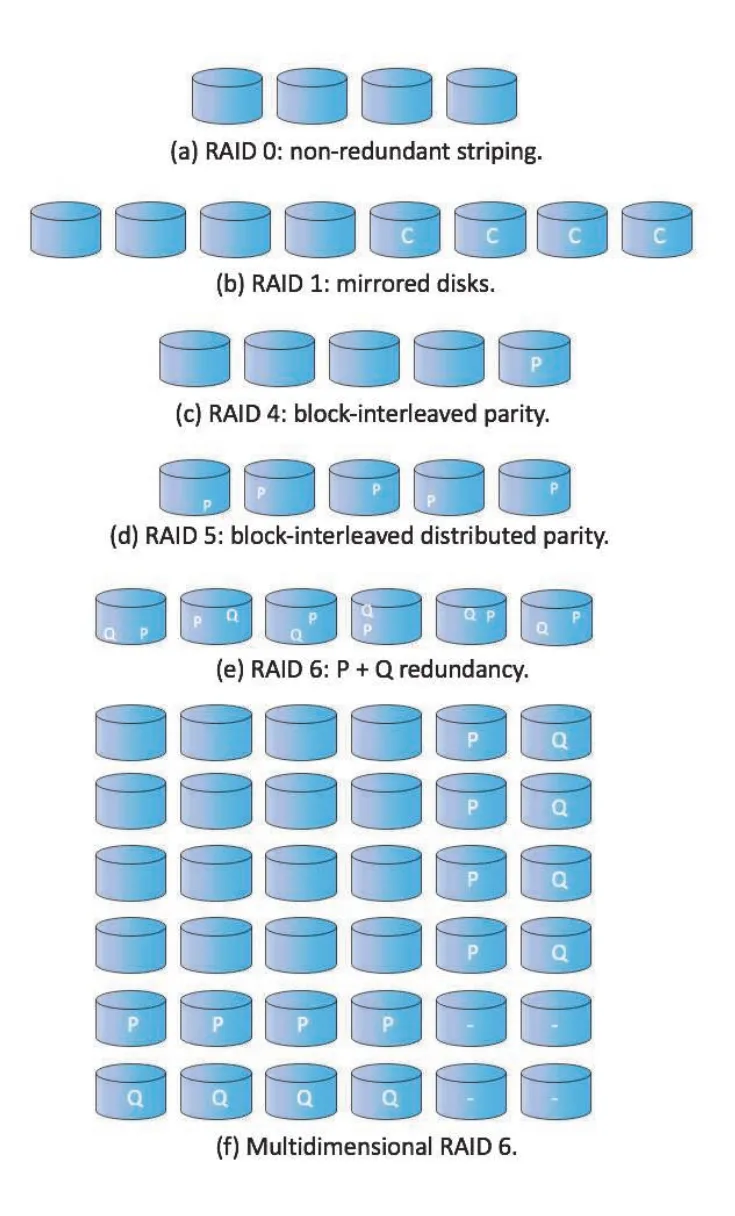
Figure 11.15 · PDF p. 600 · RAID 0, 1, 4, 5, 6, multidimensional RAID 6의 data/parity 배치
| RAID level | 핵심 구조 | 장점 | 주의점 |
|---|---|---|---|
RAID 0 | block-level striping, no redundancy | high performance, full capacity use | drive failure 시 data protection 없음 |
RAID 1 | mirroring | high reliability, fast recovery, read parallelism | capacity overhead가 큼. 두 배 drives 필요 |
RAID 4 | N data drives + dedicated parity drive | RAID 1보다 낮은 redundancy overhead, large read/write parallelism | parity drive bottleneck, small write의 read-modify-write overhead |
RAID 5 | block-interleaved distributed parity | RAID 4 parity drive bottleneck 완화, common parity RAID | single drive failure tolerance. parity update cost는 남음 |
RAID 6 | P + Q redundancy, double redundant blocks | two drive failures tolerate | RAID 5보다 redundancy/write cost 증가 |
Multidimensional RAID 6 | rows/columns 등 multiple dimensions에 RAID 6 적용 | hundreds of drives arrays에서 multiple failures recovery 강화 | 구조와 controller logic이 복잡 |
RAID 4는 blocks를 drives에 stripe하고 parity block을 dedicated parity drive에 저장한다. Drive controller가 sector read correctness를 알 수 있으므로, 어떤 sector가 damaged인지 알 때 remaining sectors와 parity를 이용해 missing bit를 reconstruct할 수 있다. 하지만 small write는 data block과 parity block을 모두 갱신해야 하므로 read-modify-write cycle이 필요하다. Old data, old parity를 읽고 new data, new parity를 쓰는 네 번의 drive accesses가 필요할 수 있다.
Parity-based RAID의 write overhead는 XOR parity computation과 parity writes에서 온다. Modern CPUs나 RAID hardware controller가 parity computation을 빠르게 처리하고, NVRAM cache가 writes를 buffer하여 full stripe 단위로 모으면 read-modify-write overhead를 줄일 수 있다. 그래서 cache와 hardware acceleration이 있는 parity RAID는 non-parity RAID에 가까운 성능을 보이기도 한다.
RAID 5는 parity를 하나의 drive에 몰지 않고 all drives에 distribute한다. 그래서 RAID 4의 dedicated parity drive overuse를 피한다. RAID 6는 single parity로는 identical parity copies가 되어 추가 복구력이 없기 때문에 Galois field math 같은 error-correcting code로 Q redundancy를 계산해 two drive failures를 견딘다.
RAID 0 + 1과 RAID 1 + 0은 striping과 mirroring을 결합한다.
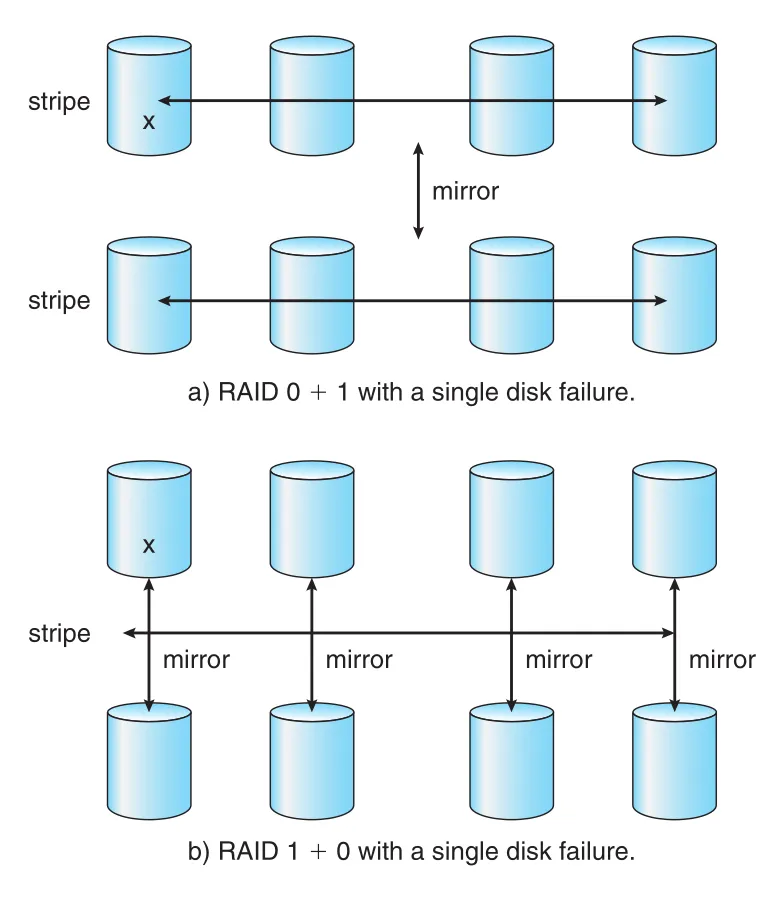
Figure 11.16 · PDF p. 603 · single disk failure 시 RAID 0 + 1과 RAID 1 + 0의 availability 차이
RAID 0 + 1은 stripe set을 만들고 그 stripe 전체를 mirror한다. Single drive failure가 나면 해당 stripe 전체가 inaccessible해지고 다른 stripe에 의존한다. RAID 1 + 0은 drives를 mirror pairs로 만든 뒤 그 pairs를 stripe한다. Single drive failure가 나도 해당 mirror partner는 계속 available하고 나머지 pairs도 그대로 available하므로, 이론적으로 더 유리하다.
RAID와 함께 snapshot, replication, hot spare도 자주 쓰인다. snapshot은 last update 이전 file system view이고, replication은 separate sites 또는 copies 사이 writes를 자동 duplicate하는 기능이다. Synchronous replication은 local/remote write가 모두 끝나야 complete로 보아 data loss 위험이 낮지만 느리고 distance 제약이 크다. Asynchronous replication은 writes를 묶어 periodic하게 보내므로 빠르고 distance limitation이 작지만 primary site failure 시 data loss 가능성이 있다. hot spare는 평소 data를 저장하지 않다가 drive failure 시 자동으로 rebuild 대상이 되어 RAID level을 human intervention 없이 회복시킨다.
11.8.4 Selecting a RAID Level
RAID level 선택은 reliability, performance, cost만의 문제가 아니라 rebuild performance까지 포함한다. Drive 하나가 fail하면 lost data를 rebuild해야 하는데, rebuild가 오래 걸리면 그동안 performance가 떨어지고, 두 번째 failure가 발생할 위험도 커진다. RAID 1은 mirror copy에서 data를 copy하면 되어 rebuild가 쉽다. RAID 5 같은 parity RAID는 failed drive data를 만들기 위해 array의 다른 drives를 모두 access해야 하므로 large drive set에서는 rebuild가 hours 단위가 될 수 있다.
원문의 선택 기준을 정리하면 다음과 같다.
| 선택 상황 | 적합한 RAID |
|---|---|
| data loss가 critical하지 않고 performance가 중요한 scientific data exploration 등 | RAID 0 |
| high reliability와 fast recovery가 중요한 workload | RAID 1 |
| performance와 reliability가 모두 중요하고 small database 같은 workload | RAID 0 + 1, RAID 1 + 0 |
| moderate data volume을 저장하고 RAID 1의 high space overhead를 피하고 싶을 때 | RAID 5 |
| storage arrays에서 good performance/protection과 낮은 space overhead를 원할 때 | RAID 6, multidimensional RAID 6 |
RAID set에 몇 drives를 넣을지도 trade-off다. Drives가 많을수록 data-transfer rate는 높아지지만 비용이 증가하고, 하나의 parity가 보호하는 bits가 많을수록 space overhead는 줄지만 첫 failure repair 전에 second drive가 fail할 가능성은 커진다.
11.8.5 Extensions
RAID의 아이디어는 HDD/NVM arrays를 넘어 tapes와 wireless broadcast에도 확장될 수 있다. Tape arrays에서는 여러 tapes 중 하나가 damaged되어도 data를 recover할 수 있고, tape-drive robots가 multiple tape drives에 data를 stripe해 backup throughput을 높일 수 있다. Broadcast data에서도 data block을 작은 units와 parity unit으로 나누어 보내면 일부 unit을 받지 못해도 나머지 units로 reconstruct할 수 있다.
11.8.6 Problems with RAID
RAID는 physical media failure를 견디는 데 초점이 있다. 따라서 RAID가 있다고 해서 OS와 users에게 data가 항상 available하거나 correct하다는 뜻은 아니다. File pointer가 잘못될 수 있고, file-structure pointers가 corrupt될 수 있으며, incomplete writes인 torn writes가 corrupt data를 만들 수 있다. 다른 process나 bug가 file-system structures를 덮어쓸 수도 있다. Hardware RAID controller failure나 software RAID code bug도 total data loss로 이어질 수 있다.
ZFS는 이런 문제를 줄이기 위해 all blocks, including data and metadata에 internal checksums를 유지한다. 중요한 점은 checksum을 checksummed block 자체에 저장하지 않고, 그 block을 가리키는 pointer 쪽에 저장한다는 것이다.
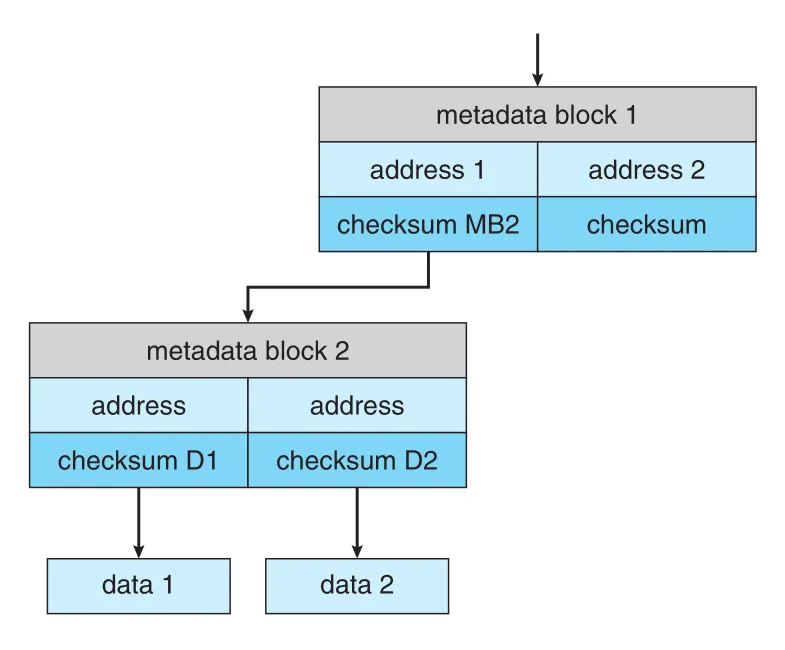
Figure 11.17 · PDF p. 606 · ZFS가 metadata/data blocks의 checksum을 parent pointer 쪽에 저장해 corruption을 탐지하는 구조
예를 들어 inode 안에는 data blocks의 checksums가 있고, directory entry는 inode의 checksum을 가진다. Data block에 문제가 생기면 checksum mismatch로 감지된다. Mirrored data에서 한 copy는 checksum이 맞고 다른 copy가 틀리면 ZFS는 good block으로 bad block을 자동 update할 수 있다. 이 방식은 RAID drive sets나 standard file systems보다 더 높은 consistency, error detection, error correction을 제공한다.
RAID의 또 다른 문제는 flexibility 부족이다. 예를 들어 20 drives를 5 drives씩 4개의 RAID 5 sets로 나누면 4개의 volumes가 생긴다. 어떤 file system은 너무 크고 다른 file system은 거의 space를 쓰지 않는 상황이 생길 수 있다. Volume manager가 volume size 변경을 지원하지 않거나, file system이 grow/shrink를 지원하지 않으면 storage를 재배치하거나 file system을 재생성해야 한다.
ZFS는 file-system management와 volume management를 결합한다. Drives 또는 drive partitions를 RAID sets로 묶어 storage pools를 만들고, pool 안에 one or more ZFS file systems를 둔다. Pool의 free space는 pool 안 모든 file systems가 공유한다. ZFS는 malloc()/free() memory model처럼 file system이 blocks를 사용하고 해제할 때 storage를 allocate/release한다. 그래서 fixed volume boundary 때문에 file system을 옮기거나 volume을 resize할 필요가 줄어든다. 필요하면 quotas와 reservations로 file-system size/growth guarantee를 조절한다.
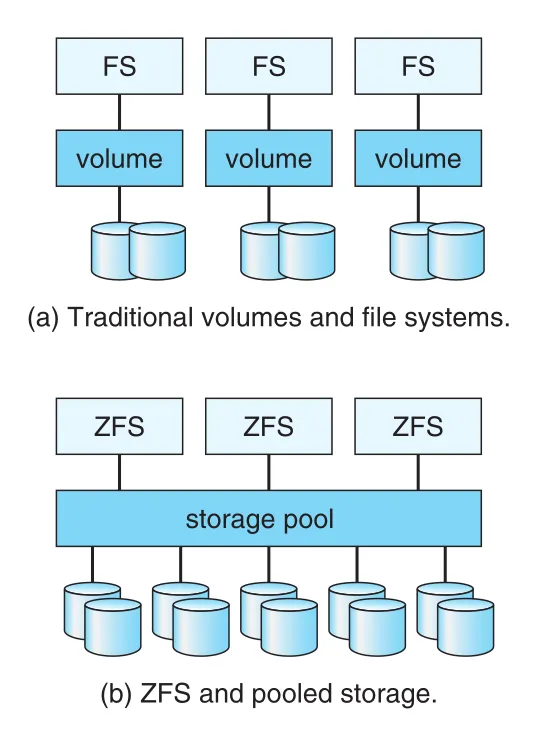
Figure 11.18 · PDF p. 608 · traditional volumes/file systems와 ZFS pooled storage model의 차이
11.8.7 Object Storage
object storage는 file-system path hierarchy 대신 storage pool 안에 objects를 만들고 object ID로 access하는 방식이다. 일반적인 sequence는 object를 생성하고 object ID를 받은 뒤, 필요할 때 object ID로 access하고, 필요 없으면 object ID로 delete하는 것이다.
Object storage는 user가 directory tree를 탐색하는 구조라기보다 programs가 large-scale data를 저장/조회하기 위한 computer-oriented model이다. HDFS와 Ceph 같은 object storage management software는 objects를 어디에 저장할지 결정하고 object protection을 관리한다. 보통 RAID arrays보다 commodity hardware 위에서 동작하며, 예를 들어 HDFS는 object를 N copies로 N different computers에 저장할 수 있다.
이 방식은 storage array보다 비용이 낮을 수 있고, object copy가 있는 systems에서는 빠른 local access를 제공한다. Hadoop cluster처럼 computation을 data가 있는 nodes에서 수행하고 results만 network로 보내는 방식과 잘 맞는다. 반대로 object copy가 없는 systems는 network connectivity로 read/write해야 하므로 high-speed random access보다는 bulk storage에 적합하다.
Object storage의 큰 장점은 horizontal scalability다. Storage array는 maximum capacity가 정해져 있지만, object store는 internal disks나 attached external disks를 가진 computers를 더 추가해 pool capacity를 키울 수 있다. Object storage pools는 petabytes 규모까지 확장될 수 있다.
또한 object는 self-describing이며 contents description을 포함한다. 이 때문에 content-addressable storage라고도 불린다. 저장되는 것은 fixed file format이 아니라 unstructured data다. Google search contents, Dropbox contents, Spotify songs, Facebook photos, Amazon S3 같은 cloud storage가 대규모 object storage의 대표적인 사용처다.
11.9 Summary
Chapter 11은 secondary storage를 단순한 “큰 byte array”로 보지 않고, device physics와 system architecture가 OS 정책에 주는 영향을 정리한다. HDD는 mechanical seek/rotation 때문에 scheduling이 중요하고, NVM은 moving parts가 없어 scheduling보다 controller-level write management, wear leveling, garbage collection, write amplification이 중요하다. OS는 device를 logical blocks/LBA로 추상화하지만, performance/reliability를 위해 이 내부 차이를 고려한다.
Storage device는 partition, volume, file system, boot block, bad-block handling을 거쳐 OS가 사용할 수 있는 namespace와 allocation unit으로 바뀐다. Virtual memory는 swap space를 통해 secondary storage를 memory pressure의 backing store로 활용하지만, modern systems에서는 file-backed pages보다 anonymous memory가 핵심 swap 대상이다.
Attachment 방식은 host-attached, NAS, cloud storage, SAN으로 나뉜다. Host-attached는 단순하고 빠른 local block access에 강하고, NAS는 LAN file sharing에 편리하며, cloud storage는 WAN/API failure model에 맞는다. SAN과 storage array는 enterprise 환경에서 performance, dynamic allocation, RAID/snapshot/replication 같은 advanced features를 제공한다.
RAID는 여러 drives를 parallel/redundant하게 묶어 performance와 reliability를 높인다. 하지만 RAID는 media failure에 대한 protection일 뿐, file-system corruption, software bug, controller bug, torn writes, 잘못된 pointers까지 모두 해결하지 않는다. ZFS와 object storage는 RAID 이후 storage system이 consistency, flexibility, scalability를 어떻게 확장하는지 보여주는 연결점이다.
연결 관계
- Chapter 9/10의 virtual memory와 연결된다.
swap-space management는 paging, anonymous memory, pageout policy가 secondary storage를 어떻게 사용하는지 설명한다. - Chapter 12/13/14의 file-system 구현과 연결된다. Partition, volume, logical formatting, free-space maps, boot blocks, bad-block handling은 file system이 올라갈 storage substrate다.
- Chapter 1의 cloud computing과 연결된다.
cloud storage는 local OS protocol보다 WAN/API failure model이 중요하다는 점에서 storage abstraction이 deployment environment에 따라 달라짐을 보여준다. - Chapter 14의 advanced file systems와 연결된다.
snapshots,replication,ZFS checksums, pooled storage는 file system design에서 더 깊게 다룰 주제다. - Concurrency/reliability 관점에서는 storage writes의 atomicity, power failure, torn writes, cache consistency가 OS correctness와 이어진다.
오해하기 쉬운 내용
RAID 0은 RAID라는 이름이 붙지만 redundancy가 없다. Performance를 위해 striping만 제공하므로 drive failure 시 data protection을 기대하면 안 된다.NVM scheduling은 HDD scheduling과 같은 문제가 아니다. NVM은 seek/rotation이 없으므로 FCFS-like scheduling이 충분한 경우가 많고, 핵심 병목은 write amplification, garbage collection, wear leveling 쪽이다.NAS와SAN은 둘 다 networked storage지만 abstraction이 다르다. NAS는 보통 file-system/RPC 중심이고, SAN은 private storage fabric을 통한 block storage 중심이다.iSCSI는 NAS 문맥에서 등장하지만 file protocol이 아니라 SCSI commands/logical blocks를 IP 위로 운반해 remote storage를 block device처럼 보이게 한다.RAID는 backup이 아니다. RAID는 drive failure availability를 높이지만, accidental deletion, file-system corruption, software bugs, site disaster에는 snapshot/replication/backup이 별도로 필요하다.ZFS checksum은 block 안에 자기 checksum을 넣는 단순 방식이 아니다. Pointer 쪽에 checksum을 두어 잘못된 block을 detect하고, mirror가 있으면 self-healing할 수 있게 한다.
면접 질문
- HDD에서
seek time,rotational latency,transfer time이 각각 무엇이며, 왜 HDD scheduling이 필요한가? SCAN과C-SCAN의 차이는 무엇이고, C-SCAN이 wait time을 더 uniform하게 만드는 이유는 무엇인가?- NVM/SSD에서는 왜 HDD-style scheduling 효과가 제한적인가? 대신 어떤 controller-level 문제가 중요한가?
low-level formatting,partitioning,logical formatting,mounting의 차이를 설명하라.- Linux
swap map의 counter가 0, 1, 3일 때 각각 어떤 의미인가? host-attached storage,NAS,SAN,cloud storage를 interface와 failure/performance model 관점에서 비교하라.RAID 4의 small write가 왜 read-modify-write cycle을 일으키는가?RAID 5가 RAID 4의 dedicated parity drive bottleneck을 어떻게 완화하는가?RAID 6가 RAID 5보다 제공하는 추가 보호와 그 비용은 무엇인가?RAID 0 + 1과RAID 1 + 0에서 single drive failure 후 availability가 어떻게 다른가?- RAID가 보호하지 못하는 storage failure/corruption 사례를 들어라.
- ZFS가 checksums와 storage pools를 통해 standard RAID/file-system 구조의 어떤 한계를 보완하는가?
object storage가 file system과 다른 점은 무엇이며, 왜 big data/cloud storage에 적합한가?