Chapter 3. Processes
- 과목: Operating System
- 기준 교재: Operating System Concepts 10th
- 관련 페이지: PDF pp. 133-187
- 우선순위: 필수
개요
Chapter 3의 중심 개념은 프로세스(process)다. 초기 컴퓨터는 한 번에 하나의 program만 실행했지만, 현대 운영체제는 여러 program을 memory에 올려 concurrent하게 실행한다. 이때 운영체제는 CPU, memory, file, I/O device 같은 resource를 각 실행 단위에 배분하고, 서로 침범하지 않도록 통제해야 한다. 그 결과로 등장한 실행 단위가 process, 즉 program in execution이다.
프로세스는 단순히 실행 파일(executable file)을 뜻하지 않는다. Program은 disk에 저장된 instruction 목록이라는 passive entity이고, process는 program counter, CPU registers, address space, open files, scheduling state 같은 실행 상태와 resource를 가진 active entity다. 같은 browser program을 여러 번 실행하면 text section은 같을 수 있지만, 각 process의 data, heap, stack, register state는 별개다.
이 장은 process가 운영체제 안에서 어떻게 표현되는지, process scheduler가 process를 어떻게 이동시키는지, process creation/termination이 어떻게 일어나는지, 그리고 서로 다른 process가 interprocess communication(IPC)으로 어떻게 협력하는지를 다룬다. Chapter 4의 threads, Chapter 5의 CPU scheduling, Chapter 9의 memory management로 이어지는 기반 장이다.
핵심 개념
| 개념 | 핵심 의미 |
|---|---|
process | 실행 중인 program. program counter, registers, address space, resource를 가진 active entity |
program | disk에 저장된 instruction 목록. 실행 전에는 passive entity |
text section | executable code가 놓이는 영역 |
data section | global/static data가 놓이는 영역 |
heap | runtime에 동적으로 할당되는 memory 영역 |
stack | function call의 parameter, return address, local variable 등을 저장하는 영역 |
process state | 현재 process가 생성 중인지, 실행 중인지, 대기 중인지 등을 나타내는 상태 |
process control block (PCB) | process를 중단했다가 다시 시작하기 위해 필요한 운영체제 내부 record |
ready queue | CPU core에 배정될 준비가 된 process들의 queue |
wait queue | I/O completion, signal, child termination 같은 event를 기다리는 process들의 queue |
CPU scheduler | ready queue에서 다음 실행 process를 선택해 CPU core를 배정하는 운영체제 구성요소 |
context switch | 현재 process의 context를 저장하고 다른 process의 context를 복원하는 전환 작업 |
세부 정리
3.1 Process Concept
Process는 무엇인가
Operating system 문맥에서 CPU activity를 부르는 이름은 시대에 따라 달라졌다. Batch system에서는 job, time-sharing system에서는 user program 또는 task라는 말이 쓰였지만, 현대 운영체제는 사용자 program뿐 아니라 memory management 같은 내부 활동도 함께 다룬다. 책은 이 모든 실행 활동을 통합해서 process라고 부른다. 단, job scheduling처럼 역사적으로 굳어진 용어에서는 job이라는 단어가 여전히 남는다.
Process의 현재 실행 상태는 적어도 두 가지로 설명된다.
program counter: 다음에 실행할 instruction의 주소processor registers: 현재 계산 중인 값, stack pointer, condition code 등 CPU 내부 상태
Process는 memory 안에서 보통 다음 영역으로 나뉜다.
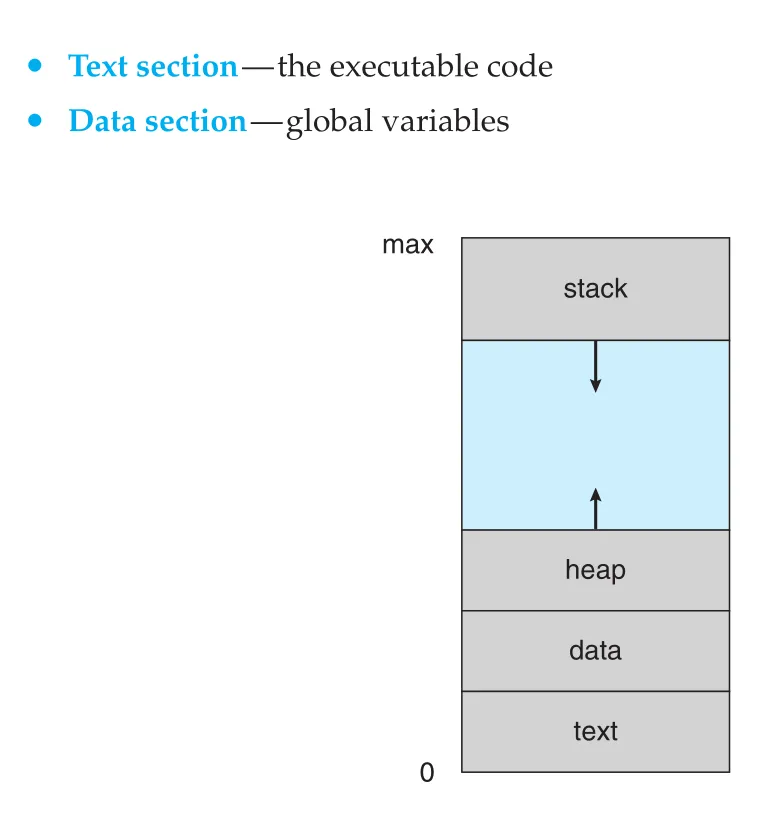
Figure 3.1 · PDF p. 144 · process address space의 text, data, heap, stack 배치
| 영역 | 역할 | 크기 변화 |
|---|---|---|
text section | 실행 가능한 code | 보통 고정 |
data section | global variables, static data | 보통 고정 |
heap section | malloc() 같은 dynamic allocation으로 얻는 memory | 실행 중 증가/감소 |
stack section | function parameter, local variable, return address 등 activation record | function call/return에 따라 증가/감소 |
Text와 data는 program이 실행되는 동안 크기가 고정되는 경향이 있다. 반면 stack과 heap은 실행 중 동적으로 움직인다. Function call이 발생하면 activation record가 stack에 push되고, return하면 pop된다. Heap은 dynamic allocation으로 커지고 deallocation으로 줄어든다. Stack과 heap은 서로를 향해 자랄 수 있으므로, 운영체제는 두 영역이 overlap하지 않도록 관리해야 한다.
원문 박스의 C program memory layout은 Figure 3.1의 일반 구조를 실제 C program에 연결한다. int y = 15; 같은 initialized global data와 int x; 같은 uninitialized data가 분리될 수 있고, main(int argc, char *argv[])의 argc, argv도 stack 쪽 실행 환경에 놓인다. GNU size 명령은 executable의 text, data, bss 크기를 보여주며, bss는 uninitialized data를 가리키는 역사적 용어다. 여기서 중요한 점은 C source의 변수 선언이 process address space의 특정 영역으로 대응된다는 감각이다.
Program과 process의 차이
Program은 disk에 있는 file이고, process는 그 file이 memory에 load되어 실행되는 상태다. 사용자가 executable icon을 double-click하거나 command line에서 prog.exe, a.out 같은 이름을 입력하면 program이 process가 된다. 같은 program에서 여러 process가 나올 수 있고, 각 process는 독립적인 실행 sequence다.
JVM(Java Virtual Machine) 예시는 process 개념을 한 번 더 넓힌다. java Program을 실행하면 java라는 JVM 자체가 ordinary process로 실행되고, 그 process 안에서 Java bytecode가 해석되거나 실행된다. 즉 어떤 process는 다른 code를 위한 execution environment가 될 수 있다.
Process State
Process는 실행 중 계속 state를 바꾼다. 원문은 기본 state를 다섯 가지로 설명한다.
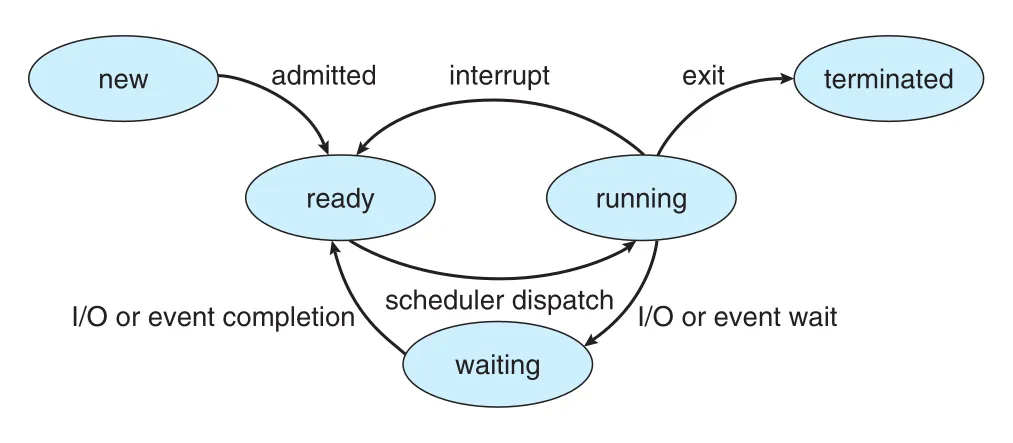
Figure 3.2 · PDF p. 147 · new, ready, running, waiting, terminated 사이의 process state transition
| State | 의미 | 대표 전이 |
|---|---|---|
new | process가 생성 중 | admission 후 ready |
ready | CPU에 배정되기를 기다림 | scheduler dispatch 후 running |
running | instruction이 CPU에서 실행 중 | interrupt, I/O wait, exit |
waiting | I/O completion, signal 등 event를 기다림 | event completion 후 ready |
terminated | 실행이 끝남 | resource 회수 |
State 이름은 운영체제마다 다를 수 있지만, 개념 자체는 대부분의 system에 존재한다. 단일 CPU core에서는 한 순간에 오직 하나의 process만 running일 수 있다. 반면 ready나 waiting인 process는 여러 개일 수 있다. Multicore system에서는 core 수만큼 여러 process가 동시에 running일 수 있다.
Process Control Block (PCB)
운영체제는 각 process를 process control block (PCB) 또는 task control block으로 표현한다. PCB는 process를 멈췄다가 다시 시작하기 위한 최소 실행 문맥과 관리 정보를 담는 record다.

Figure 3.3 · PDF p. 147 · process state, process number, program counter, registers 등을 담는 PCB
PCB에 들어가는 대표 정보는 다음과 같다.
| PCB field | 의미 |
|---|---|
process state | new, ready, running, waiting, halted 등 현재 상태 |
program counter | 다음에 실행할 instruction 주소 |
CPU registers | accumulator, index register, stack pointer, general-purpose register, condition code 등 |
CPU-scheduling information | process priority, scheduling queue pointer, scheduling parameter |
memory-management information | base/limit register, page table, segment table 등 |
accounting information | CPU time, real time, time limit, account number, process number 등 |
I/O status information | allocated I/O device, open file list 등 |
Interrupt가 발생하면 CPU register와 program counter를 저장해야 한다. 그래야 process가 다시 schedule될 때 같은 지점에서 정확히 이어서 실행할 수 있다. 따라서 PCB는 단순한 metadata가 아니라 process의 재시작 가능성을 보장하는 핵심 구조다.
Linux에서는 PCB에 해당하는 구조가 kernel source의 task_struct다. task_struct는 long state, struct sched_entity se, struct task_struct *parent, struct list_head children, struct files_struct *files, struct mm_struct *mm 같은 field를 포함한다. Linux kernel은 active process를 task_struct의 doubly linked list로 관리하고, 현재 실행 중인 process를 가리키는 pointer로 current를 둔다. 예를 들어 현재 process state를 바꾸려면 개념적으로 current->state = new_state;처럼 조작한다.
Threads와 process 개념의 확장
여기까지의 process model은 하나의 process가 하나의 thread of execution을 가진다고 가정한다. 그러나 현대 운영체제는 한 process 안에 multiple threads of control을 둘 수 있다. 예를 들어 word processor가 한 thread로 user input을 처리하고 다른 thread로 spell checker를 실행할 수 있다. Multicore system에서는 이런 threads가 parallel하게 실행될 수 있다.
Thread를 지원하는 system에서는 PCB가 thread별 실행 정보를 포함하도록 확장되고, scheduling과 synchronization 등 운영체제 여러 부분이 thread-aware하게 바뀐다. 이 장은 process 중심이고, threads 자체는 Chapter 4로 이어진다.
3.2 Process Scheduling
Multiprogramming과 time sharing의 목표
Process scheduling의 기본 목표는 두 가지다.
multiprogramming: 항상 어떤 process가 CPU를 쓰도록 해서 CPU utilization을 높인다.time sharing: CPU core를 process들 사이에서 자주 전환해 사용자가 여러 program과 interactive하게 상호작용할 수 있게 한다.
각 CPU core는 한 순간에 하나의 process만 실행할 수 있다. Ready process가 core보다 많으면 일부 process는 기다려야 한다. Memory에 올라와 있는 process 수를 degree of multiprogramming이라고 한다.
Process의 성격도 scheduling에 중요하다.
| 구분 | 의미 | scheduling 관점 |
|---|---|---|
I/O-bound process | computation보다 I/O에 더 많은 시간을 쓰는 process | 짧게 CPU를 쓰고 자주 wait queue로 이동 |
CPU-bound process | I/O request가 드물고 computation에 많은 시간을 쓰는 process | 오래 CPU를 쓰려 하므로 preemption이 중요 |
Scheduling Queues
Process가 system에 들어오면 먼저 ready queue에 놓인다. Ready queue는 CPU core에 배정될 준비가 된 process들의 queue다. 보통 linked list로 구현되며, ready-queue header는 첫 PCB를 가리키고 각 PCB는 다음 PCB를 가리키는 pointer field를 가진다.
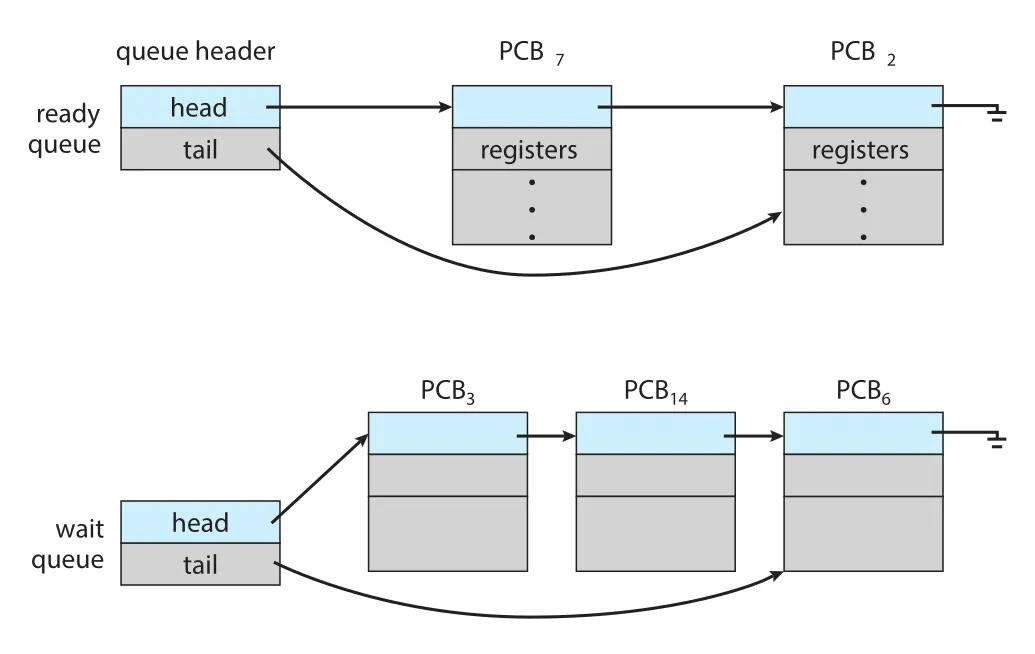
Figure 3.4 · PDF p. 150 · ready queue와 wait queue가 PCB linked list로 연결되는 방식
System에는 ready queue 말고도 여러 wait queue가 있다. Process가 CPU를 배정받아 실행되다가 disk I/O 같은 느린 device request를 내면, completion까지 CPU를 붙잡고 있을 이유가 없다. 이 process는 해당 event를 기다리는 wait queue로 이동한다.
Scheduling 흐름은 queueing diagram으로 보면 더 명확하다.
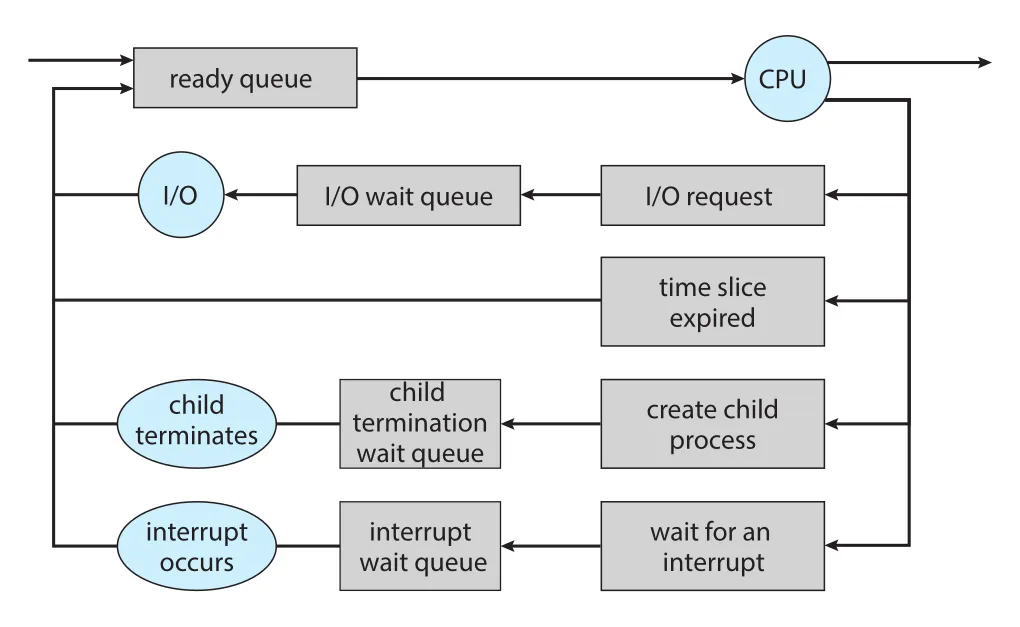
Figure 3.5 · PDF p. 151 · ready queue, CPU, I/O wait queue, child termination wait queue, interrupt wait queue 사이의 이동
대표 흐름은 다음과 같다.
- New process가
ready queue에 들어간다. CPU scheduler가 process를 선택하면scheduler dispatch로 CPU core에 올라가running이 된다.- Running process는 I/O request를 내고 I/O wait queue로 갈 수 있다.
- Child process를 만들고 child termination을 기다리는 wait queue로 갈 수 있다.
- Interrupt 또는 time slice expiration 때문에 CPU에서 내려와 ready queue로 돌아갈 수 있다.
- Termination되면 queue에서 제거되고 PCB와 resource가 회수된다.
CPU Scheduling
CPU scheduler는 ready queue에 있는 process 중 하나를 선택해 CPU core를 할당한다. Scheduler는 매우 자주 실행된다. I/O-bound process는 몇 millisecond만 CPU를 쓰고 I/O wait으로 빠질 수 있고, CPU-bound process도 무한히 CPU를 독점하도록 두지 않는다. 그래서 scheduler는 적어도 100ms마다, 실제로는 더 자주 개입하는 경우가 많다.
일부 운영체제에는 중간 형태의 scheduling으로 swapping이 있다. Swapping은 process를 memory에서 disk로 잠시 내보내 active CPU 경쟁에서 제외해 degree of multiprogramming을 줄이는 방식이다. 나중에 다시 memory로 swapped in하면 저장된 상태에서 실행을 이어갈 수 있다. 원문은 swapping이 memory overcommit 상황에서 특히 필요하며, 자세한 내용은 Chapter 9로 연결된다고 설명한다.
Context Switch
Interrupt나 system call이 발생하면 CPU core는 현재 실행하던 user process에서 kernel routine으로 넘어간다. 이때 운영체제는 현재 process의 context를 저장해야 한다. Context에는 CPU registers, process state, memory-management information 등이 포함되며, 일반적으로 PCB에 저장된다.
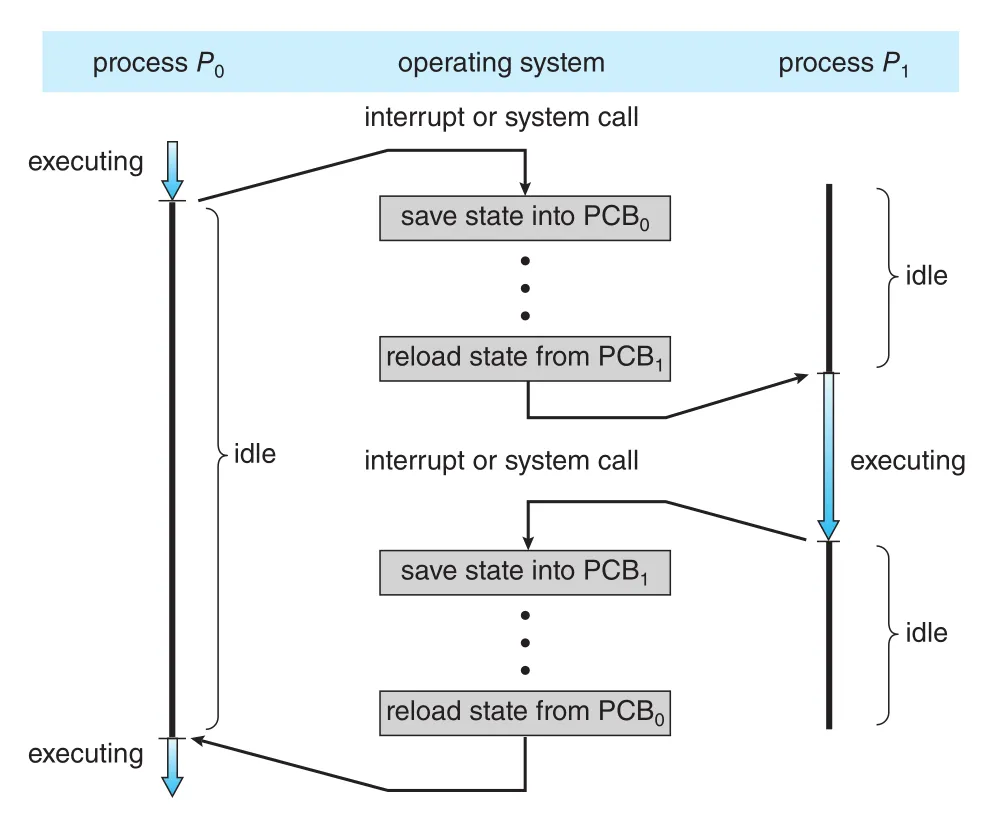
Figure 3.6 · PDF p. 152 · process P0의 state를 저장하고 process P1의 state를 복원하는 context switch
context switch는 현재 process의 state save와 다음 process의 state restore를 수행하는 작업이다. Kernel은 old process의 context를 그 process의 PCB에 저장하고, scheduler가 선택한 new process의 context를 PCB에서 load한다.
중요한 trade-off는 context-switch time이 pure overhead라는 점이다. 전환 중에는 user program의 실질적 계산이 진행되지 않는다. 하지만 context switch가 없으면 time sharing, preemption, responsive interaction을 구현하기 어렵다. 즉 context switch는 성능 비용을 내고 concurrency와 responsiveness를 얻는 운영체제의 기본 메커니즘이다.
Context-switch speed는 machine마다 다르다. Memory speed, 복사해야 하는 register 수, register save/load를 지원하는 special instruction 유무가 영향을 준다. 일부 processor는 multiple register sets를 제공해 current register set pointer만 바꾸는 식으로 빠른 context switch를 지원할 수 있다. 그러나 active process 수가 register set 수보다 많으면 결국 register data를 memory로 저장하고 다시 읽어야 한다.
운영체제가 복잡해질수록 context switch 때 해야 할 일도 늘어난다. 특히 Chapter 9의 advanced memory-management techniques에서는 address space를 보존하고 다음 task의 address space를 준비해야 하므로, 단순 register 저장보다 더 많은 정보가 전환 대상이 된다.
Mobile system의 multitasking은 resource constraint와 연결된다. 초기 iOS는 foreground application 하나만 사용자 app으로 실행하고 나머지는 suspend하는 식으로 제한했지만, hardware memory, multicore, battery capacity가 좋아지면서 background application과 split-screen 같은 richer multitasking을 지원하게 되었다. Android는 초기부터 background application을 허용했고, background processing이 필요하면 UI가 없는 작은 component인 service를 사용하게 한다. 이 예시는 scheduling과 process lifetime 정책이 hardware resource와 user experience의 trade-off 위에서 결정된다는 점을 보여준다.
3.3 Operations on Processes
Process Creation
대부분의 system에서 process는 concurrently 실행될 뿐 아니라 dynamically create/delete된다. 따라서 운영체제는 process creation과 process termination mechanism을 제공해야 한다.
실행 중인 process는 새 process를 만들 수 있다. 새 process를 만든 쪽은 parent process, 만들어진 쪽은 child process다. Child도 다시 child를 만들 수 있으므로 process들은 tree 구조를 이룬다. UNIX, Linux, Windows 같은 운영체제는 process를 보통 unique integer인 process identifier (pid)로 식별한다. Kernel은 이 pid를 index처럼 사용해 process attribute에 접근할 수 있다.
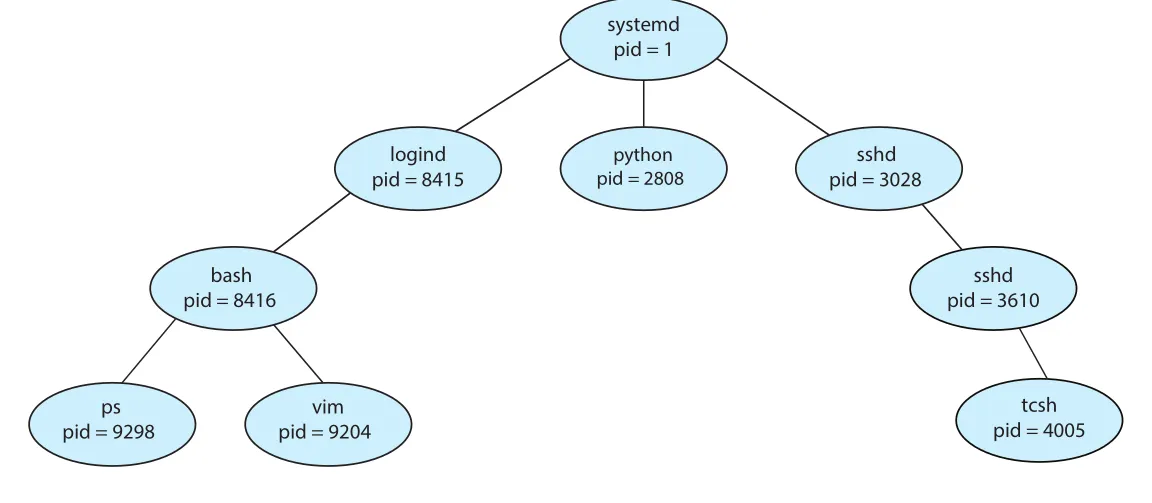
Figure 3.7 · PDF p. 154 · `systemd`를 root로 하는 Linux process tree와 pid 관계
Linux에서는 systemd가 pid 1을 가지며, boot 이후 user process들의 root parent 역할을 한다. 예전 UNIX 계열에서는 init이 같은 역할을 했다. logind, sshd, shell(bash, tcsh), ps, vim 같은 process는 parent-child 관계로 이어진다. ps -el로 process 목록을 볼 수 있고, Linux의 pstree는 process tree를 직접 표시한다.
Child process가 생성될 때 중요한 설계 선택은 세 가지다.
| 선택 지점 | 가능성 |
|---|---|
| Resource 획득 | child가 OS에서 직접 resource를 받거나, parent resource의 subset/share를 받음 |
| Parent-child 실행 관계 | parent와 child가 concurrent하게 실행되거나, parent가 child termination까지 wait |
| Address space | child가 parent의 duplicate가 되거나, child에 새 program이 load됨 |
Resource 제한은 system 보호와 연결된다. Child가 parent resource의 subset만 쓰도록 제한하면 어떤 process가 child를 너무 많이 만들어 system을 overload하는 상황을 줄일 수 있다. Parent는 child에게 initialization data를 넘길 수도 있다. 예를 들어 file display process를 만들 때 parent가 hw1.c라는 file name과 output device 정보를 넘길 수 있다.
UNIX fork(), exec(), wait()
UNIX에서 새 process는 fork() system call로 생성된다. fork()는 parent의 address space를 복사해 child를 만든다. Fork 직후 parent와 child는 둘 다 fork() 다음 instruction부터 실행을 계속하지만, return value가 다르다.
| Process | fork() return value |
|---|---|
| child process | 0 |
| parent process | child의 pid, 즉 0보다 큰 integer |
| error | 음수 값 |

Figure 3.8 · PDF p. 156 · `fork()`로 child를 만들고 child에서 `execlp()`를 호출하는 UNIX 예제
Figure 3.8의 흐름은 UNIX process creation의 핵심 idiom이다.
- Parent가
pid = fork();를 호출한다. - 실패하면
pid < 0branch로 error 처리한다. - Child에서는
pid == 0이므로execlp("/bin/ls", "ls", NULL);을 호출한다. - Parent에서는
pid > 0이므로wait(NULL);로 child completion을 기다린다. - Child가 종료되면 parent가
Child Complete를 출력하고 종료한다.

Figure 3.9 · PDF p. 157 · `fork()` 이후 parent와 child가 갈라지고 child가 `exec()`로 새 program을 실행하는 흐름
exec() system call은 현재 process의 memory space를 새 program으로 overlay한다. 즉 exec()를 호출한 process의 기존 memory image는 새 binary file로 대체되고, 정상적으로 성공하면 원래 code로 return하지 않는다. Parent와 child가 처음에는 같은 program image를 공유하듯 출발하지만, 보통 child가 exec()를 호출해 완전히 다른 program으로 바뀌는 이유가 여기에 있다.
Child가 exec()를 호출하지 않으면 parent와 child는 같은 code instruction을 실행하는 concurrent processes가 된다. 그러나 child는 parent의 copy이므로 각 process는 자기 data copy를 가진다. 이 점이 threads와 다르다. Threads는 같은 process address space를 공유하지만, fork() 뒤의 parent/child process는 별도의 address space를 가진다.
Windows CreateProcess()
Windows API의 process creation은 CreateProcess() function을 사용한다. Parent가 child를 만든다는 점은 fork()와 비슷하지만, 중요한 차이가 있다.
| 구분 | UNIX fork() | Windows CreateProcess() |
|---|---|---|
| 기본 동작 | parent address space를 복사 | 지정한 program을 child address space에 load |
| parameter | 없음에 가까움 | 10개 이상의 parameter |
| 새 program 실행 | 보통 child가 exec() 호출 | creation 시 command/application 지정 |
| parent waiting | wait() | WaitForSingleObject() |

Figure 3.10 · PDF p. 158 · Windows API `CreateProcess()`로 `mspaint.exe` child process를 만드는 예제
Figure 3.10의 예제는 STARTUPINFO와 PROCESS_INFORMATION 구조체를 준비한 뒤 CreateProcess()를 호출한다. STARTUPINFO는 새 process의 window size, appearance, standard input/output handle 같은 시작 속성을 담고, PROCESS_INFORMATION은 새 process와 primary thread에 대한 handle 및 identifier를 담는다. ZeroMemory()는 이 구조체들을 초기화한다.
첫 두 parameter는 application name과 command-line parameter다. Application name이 NULL이면 command-line parameter가 load할 application을 지정한다. 예제에서는 mspaint.exe를 실행한다. Parent는 WaitForSingleObject(pi.hProcess, INFINITE);로 child process completion을 기다리고, 종료 후 CloseHandle()로 process/thread handle을 닫는다.
Process Termination
Process는 final statement 실행 후 exit() system call로 운영체제에 자신을 삭제해 달라고 요청하면서 종료된다. 이때 waiting parent에게 status value를 돌려줄 수 있다. 종료 시 운영체제는 physical/virtual memory, open files, I/O buffers 같은 resource를 회수한다.
Process는 다른 process에 의해 종료될 수도 있다. Windows의 TerminateProcess()가 예다. 보통 이런 termination 권한은 parent에게 제한된다. 아무 process나 다른 사용자의 process를 죽일 수 있으면 system protection이 깨지기 때문이다. Parent가 child를 종료하려면 child identity, 즉 pid나 handle을 알고 있어야 한다.
Parent가 child를 종료시키는 대표 이유는 다음과 같다.
- Child가 할당된 resource limit을 초과했다.
- Child에게 맡긴 task가 더 이상 필요 없다.
- Parent가 종료되며, 운영체제가 parent 없는 child continuation을 허용하지 않는다.
어떤 system은 parent가 종료되면 children도 함께 종료시킨다. 이를 cascading termination이라고 하며, 보통 운영체제가 시작한다.
UNIX/Linux에서 정상 종료는 exit(status)로 표현된다. C runtime library가 기본적으로 exit() 호출을 포함하므로, C program의 main()이 return해도 간접적으로 process termination이 일어난다. Parent는 wait(&status)로 child termination을 기다리며 child의 exit status를 얻는다. wait()는 terminated child의 pid도 return하므로, parent는 여러 child 중 누가 끝났는지 알 수 있다.
Zombie process와 orphan process
Process가 종료되면 resource는 회수되지만, parent가 아직 wait()를 호출하지 않았다면 process table entry는 잠시 남아 있어야 한다. 그 entry 안에 child의 exit status가 들어 있기 때문이다. 이렇게 종료되었지만 parent가 status를 수거하지 않은 process를 zombie process라고 한다.
모든 process는 종료 순간 짧게 zombie가 될 수 있다. Parent가 wait()를 호출하면 zombie의 pid와 process table entry가 release된다. 반대로 parent가 wait()를 호출하지 않고 먼저 종료하면 남은 child는 orphan process가 된다. Traditional UNIX는 orphan process의 새 parent로 init을 지정했고, init이 주기적으로 wait()를 호출해 orphan의 exit status를 수거했다. 현대 Linux에서는 systemd가 이 역할을 할 수 있고, Linux는 systemd 외의 다른 process가 orphan을 inherit해 termination을 관리하는 것도 허용한다.
Android Process Hierarchy
Mobile OS는 memory 같은 resource가 제한적이므로, 새 process나 더 중요한 process를 위해 기존 process를 종료해야 할 수 있다. Android는 arbitrary process를 죽이지 않고 importance hierarchy를 둔다. Resource를 회수해야 하면 낮은 중요도의 process부터 종료한다.
| Android process class | 의미 | 종료 우선순위 |
|---|---|---|
foreground process | 화면에 보이고 user가 현재 상호작용 중인 app process | 가장 늦게 종료 |
visible process | foreground는 아니지만 foreground activity가 참조하는 visible status를 수행 | 높음 |
service process | streaming music처럼 user가 인지하는 background work 수행 | 중간 |
background process | user에게 직접 보이지 않는 activity 수행 | 낮음 |
empty process | active application component가 없음 | 가장 먼저 종료 |
Android는 process에 가능한 한 높은 importance ranking을 부여한다. 예를 들어 어떤 process가 service를 제공하면서 visible이기도 하면 더 중요한 visible process로 분류한다. Android development practice는 process life cycle guideline을 따라 termination 전에 state를 저장하고, user가 돌아오면 saved state에서 resume할 수 있게 설계하도록 요구한다.
3.4 Interprocess Communication
Independent process와 cooperating process
Concurrent하게 실행되는 process는 크게 두 종류로 볼 수 있다.
| 구분 | 의미 |
|---|---|
independent process | 다른 process와 data를 공유하지 않아 서로 영향을 주지 않는 process |
cooperating process | 다른 process에 영향을 주거나 영향을 받을 수 있는 process. 특히 data를 공유하면 cooperating process |
운영체제가 process cooperation을 지원하는 이유는 다음과 같다.
information sharing: copy/paste처럼 여러 application이 같은 information에 접근해야 한다.computation speedup: task를 subtasks로 나눠 parallel하게 실행하면 더 빠르게 끝낼 수 있다. 단, 실제 speedup은 multiple processing cores가 있어야 가능하다.modularity: Chapter 2의 system design처럼 기능을 separate processes 또는 threads로 나누면 system을 더 모듈화할 수 있다.
Cooperating processes는 data를 보내고 받기 위한 interprocess communication (IPC) mechanism이 필요하다. 원문은 IPC의 fundamental model을 두 가지로 나눈다.
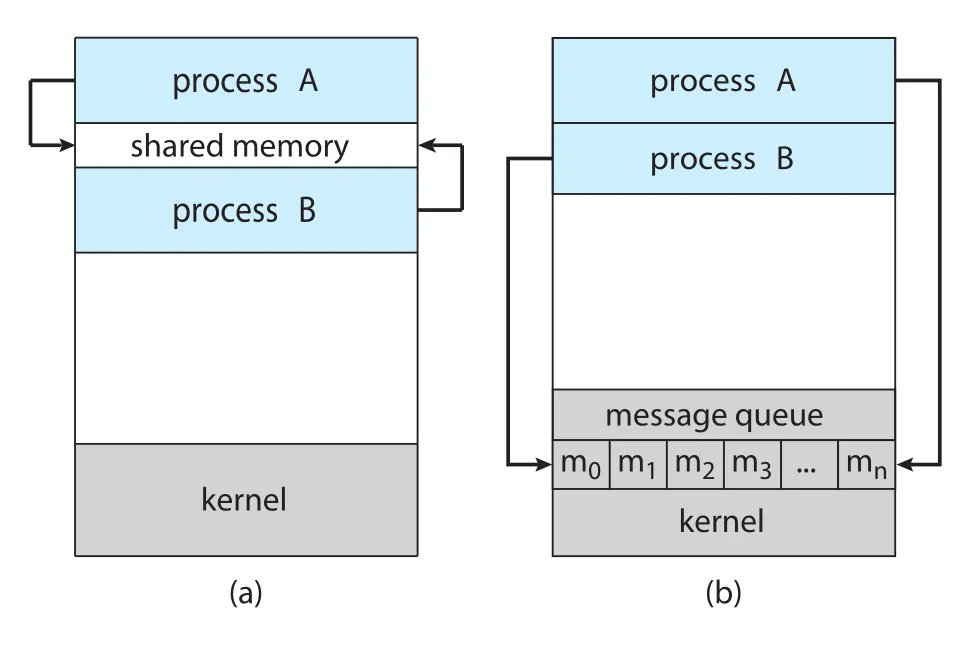
Figure 3.11 · PDF p. 163 · shared memory와 message passing의 communication model 비교
| IPC model | 방식 | 장점 | 비용/주의점 |
|---|---|---|---|
shared memory | 여러 process가 공유 memory region을 attach하고 직접 read/write | 한 번 설정하면 kernel intervention 없이 ordinary memory access처럼 빨라질 수 있음 | 동시에 같은 위치를 쓰지 않도록 synchronization을 process들이 책임져야 함 |
message passing | process들이 message를 send/receive | 작은 data 교환에 편하고 conflict 회피가 쉬우며 distributed system에 구현하기 좋음 | 보통 system call과 kernel intervention이 필요해 overhead가 큼 |
Chrome browser의 multiprocess architecture는 cooperating process 설계의 실제 예다. Browser process는 UI와 disk/network I/O를 관리하고, renderer process는 tab의 web page rendering logic을 담당하며, plug-in process는 plug-in code와 browser/renderer와의 communication을 담당한다. 이 구조의 장점은 isolation이다. 한 tab의 web application이 crash해도 해당 renderer process만 영향을 받고, 다른 tabs와 browser process는 유지된다. 또한 renderer process를 sandbox로 제한하면 disk/network I/O 접근을 줄여 security exploit의 피해 범위를 낮출 수 있다.
3.5 IPC in Shared-Memory Systems
Shared-memory IPC에서는 cooperating processes가 먼저 shared memory region을 설정한다. 보통 shared-memory region은 그 segment를 만든 process의 address space 안에 위치하고, 다른 process가 그 segment를 자기 address space에 attach한다.
원래 운영체제는 한 process가 다른 process의 memory에 접근하지 못하도록 막는다. Shared memory는 cooperating processes가 이 보호 제한을 의도적으로 제거하기로 합의하는 방식이다. 이후 어떤 data 형식을 어느 위치에 둘지는 process들이 정한다. 운영체제는 shared region의 설정에는 관여하지만, 설정 후 read/write 자체의 의미와 충돌 방지는 application의 책임이다.
Producer-consumer problem
Shared memory의 대표 예시는 producer-consumer problem이다. Producer process는 information을 만들고, consumer process는 그것을 소비한다. Compiler가 assembly code를 만들고 assembler가 소비하는 구조, web server가 HTML/image를 제공하고 browser client가 소비하는 구조가 모두 producer-consumer metaphor로 설명될 수 있다.
Producer와 consumer가 concurrent하게 실행되려면 둘 사이에 shared buffer가 필요하다. Producer는 buffer에 item을 넣고, consumer는 buffer에서 item을 꺼낸다. Producer가 한 item을 만드는 동안 consumer는 다른 item을 소비할 수 있다. 다만 consumer가 아직 생산되지 않은 item을 소비하려 하거나, producer와 consumer가 같은 slot을 동시에 조작하는 상황은 막아야 한다.
Buffer에는 두 종류가 있다.
| Buffer type | 의미 | 대기 조건 |
|---|---|---|
unbounded buffer | practical limit이 없는 buffer | consumer는 empty이면 기다릴 수 있지만 producer는 항상 produce 가능 |
bounded buffer | fixed size buffer | buffer empty이면 consumer가 wait, buffer full이면 producer가 wait |
Bounded buffer 예제는 shared memory에 다음 변수를 둔다.
#define BUFFER_SIZE 10
typedef struct {
...
} item;
item buffer[BUFFER_SIZE];
int in = 0;
int out = 0;이 buffer는 circular array로 동작한다.
| 변수/조건 | 의미 |
|---|---|
in | 다음 free position |
out | 첫 번째 full position |
in == out | buffer empty |
((in + 1) % BUFFER_SIZE) == out | buffer full |
Producer는 in이 가리키는 위치에 item을 넣고 in = (in + 1) % BUFFER_SIZE로 이동한다. Consumer는 out이 가리키는 위치에서 item을 꺼내고 out = (out + 1) % BUFFER_SIZE로 이동한다.

Figure 3.12 · PDF p. 165 · bounded buffer에 item을 넣는 shared-memory producer loop

Figure 3.13 · PDF p. 165 · bounded buffer에서 item을 꺼내는 shared-memory consumer loop
Figure 3.12와 Figure 3.13의 scheme은 동시에 최대 BUFFER_SIZE - 1개의 item만 저장한다. 한 칸을 비워 두는 이유는 in == out을 empty로 해석해야 하기 때문이다. 모든 BUFFER_SIZE slot을 쓰려면 별도의 count 변수나 full flag 같은 추가 상태가 필요하다.
이 예제에서 빠진 핵심 문제는 synchronization이다. Producer와 consumer가 shared buffer를 동시에 access하면 race condition이 생길 수 있다. Shared memory 자체는 빠르지만, 올바른 동작을 위해 mutual exclusion, semaphore, monitor 같은 synchronization mechanism이 필요하며, 이는 Chapter 6과 Chapter 7로 이어진다.
3.6 IPC in Message-Passing Systems
Message passing은 shared address space 없이 process가 communication과 synchronization을 하게 하는 IPC 방식이다. 특히 communicating processes가 서로 다른 computer에 있고 network로 연결된 distributed environment에서 자연스럽다. 예를 들어 Internet chat program은 participants가 message를 주고받는 방식으로 설계할 수 있다.
Message-passing facility는 최소 두 operation을 제공한다.
send(message)
receive(message)Message size는 fixed-size 또는 variable-size일 수 있다.
| Message size 정책 | System implementation | Programmer 관점 |
|---|---|---|
| fixed-sized messages | 구현이 단순 | application이 message format/fragmentation을 더 신경 써야 함 |
| variable-sized messages | 구현이 복잡 | programming은 쉬워짐 |
이 trade-off는 운영체제 설계에서 반복되는 패턴이다. Kernel implementation을 단순하게 만들면 application programmer가 더 많은 일을 하고, programming model을 편하게 만들면 system-level implementation이 복잡해진다.
Process P와 Q가 communication하려면 둘 사이에 communication link가 있어야 한다. 원문은 physical implementation이 아니라 logical implementation에 집중한다. Link와 send()/receive()를 논리적으로 설계할 때 핵심 축은 naming, synchronization, buffering이다.
Naming: direct communication과 indirect communication
Direct communication에서는 process가 상대방 process를 명시적으로 이름으로 지정한다.
send(P, message)
receive(Q, message)이 방식의 link property는 다음과 같다.
- Communication하려는 process pair 사이에 link가 자동으로 establish된다.
- Link는 정확히 두 process와 연결된다.
- 각 process pair 사이에는 정확히 하나의 link가 존재한다.
위 방식은 sender와 receiver가 서로를 모두 지명하므로 symmetric addressing이다. Asymmetric variant에서는 sender만 recipient를 지명하고, receiver는 아무 process로부터 받을 수 있다.
send(P, message)
receive(id, message)여기서 id는 실제 communication이 일어난 process의 name으로 설정된다.
Direct communication의 약점은 modularity가 낮다는 것이다. Process identifier를 code에 hard-coding하면 process name이 바뀔 때 관련된 모든 process definition을 찾아 수정해야 한다. 그래서 indirect communication처럼 indirection을 두는 방식이 더 유연하다.
Indirect communication에서는 message를 process가 아니라 mailbox 또는 port로 보낸다.
send(A, message)
receive(A, message)Mailbox는 process가 message를 넣고 꺼내는 abstract object다. 각 mailbox는 unique identification을 가지며, POSIX message queues에서는 integer value가 mailbox 식별에 쓰인다. 두 process는 shared mailbox가 있을 때만 communicate할 수 있다.
Indirect communication의 link property는 direct communication과 다르다.
- Process pair가 shared mailbox를 가질 때만 link가 establish된다.
- 하나의 link가 둘보다 많은 process와 연결될 수 있다.
- 같은 process pair 사이에도 mailbox가 여러 개이면 multiple links가 존재할 수 있다.
문제는 하나의 mailbox A를 P1, P2, P3가 공유할 때 생긴다. P1이 A로 message를 보냈고 P2, P3가 모두 receive(A, message)를 실행하면 누가 message를 받을 것인가? 가능한 정책은 link를 최대 두 process로 제한하거나, 한 번에 하나의 receiver만 receive하도록 하거나, system이 round robin 같은 algorithm으로 receiver를 선택하는 것이다.
Mailbox ownership도 중요하다.
| Mailbox owner | 특징 |
|---|---|
| process-owned mailbox | owner는 receive만, user는 send만 한다. Owner process가 terminate하면 mailbox도 사라진다. 이후 sender는 mailbox가 없음을 통지받아야 한다. |
| OS-owned mailbox | 특정 process와 독립적으로 존재한다. OS가 create, send/receive, delete mechanism을 제공한다. |
OS-owned mailbox에서는 mailbox를 만든 process가 default owner가 되고, 처음에는 owner만 receive할 수 있다. 하지만 system call을 통해 ownership이나 receiving privilege가 다른 process로 넘어갈 수 있으며, 그 결과 multiple receivers가 생길 수 있다.
Synchronization: blocking과 nonblocking
Message passing의 send()와 receive()는 blocking 또는 nonblocking으로 구현될 수 있다. 이는 synchronous/asynchronous behavior라고도 부른다.
| Operation | 의미 |
|---|---|
blocking send | sender가 message가 receiver 또는 mailbox에 의해 receive될 때까지 block |
nonblocking send | sender가 message를 보내고 즉시 계속 실행 |
blocking receive | receiver가 message가 available할 때까지 block |
nonblocking receive | receiver가 valid message를 얻거나, 없으면 null을 얻음 |
send()와 receive()가 모두 blocking이면 sender와 receiver 사이에 rendezvous가 생긴다. Producer-consumer problem은 blocking send/receive로 매우 단순해진다. Producer는 item을 만들고 send(next_produced)에서 delivery까지 기다리며, consumer는 receive(next_consumed)에서 item이 올 때까지 기다린다.

Figure 3.14 · PDF p. 169 · blocking `send()`를 사용하는 message-passing producer

Figure 3.15 · PDF p. 169 · blocking `receive()`를 사용하는 message-passing consumer
Buffering
Direct든 indirect든, message는 communication link 안의 temporary queue에 머문다. Queue capacity 설계는 세 가지다.
| Buffering policy | 의미 | Sender 동작 |
|---|---|---|
zero capacity | queue length가 0이라 message가 기다릴 수 없음 | receiver가 받을 때까지 sender block. no buffering |
bounded capacity | queue length가 finite n | queue가 full이면 sender block, 아니면 enqueue 후 계속 실행 |
unbounded capacity | queue length가 사실상 infinite | sender는 block되지 않음 |
Zero capacity는 no buffering system이고, bounded/unbounded capacity는 automatic buffering system이다. 현실적으로 unbounded capacity는 메모리 자원 한계가 있으므로 추상적 모델에 가깝고, bounded capacity에서는 full queue 처리 정책이 중요하다.
3.7 Examples of IPC Systems
POSIX Shared Memory
POSIX system은 shared memory와 message passing을 포함한 여러 IPC mechanism을 제공한다. 원문은 POSIX shared memory를 memory-mapped files로 설명한다. Memory-mapped file은 shared memory region을 file과 associate하는 방식이다.
POSIX shared memory 사용 흐름은 다음과 같다.
| 단계 | API | 의미 |
|---|---|---|
| shared-memory object 생성/열기 | `shm_open(name, O_CREAT | O_RDWR, 0666)` |
| object 크기 설정 | ftruncate(fd, 4096) | shared-memory object의 byte size 설정 |
| address space에 mapping | `mmap(0, SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0)` |
| object 제거 | shm_unlink(name) | shared-memory segment 제거 |
MAP_SHARED flag는 shared-memory object의 변경이 같은 object를 공유하는 모든 process에게 보이도록 한다. Shared memory object를 열 때 name을 쓰기 때문에, producer와 consumer는 같은 name으로 같은 shared region을 찾는다.

Figure 3.16 · PDF p. 171 · `shm_open()`, `ftruncate()`, `mmap()`으로 shared memory를 만들고 쓰는 producer
Figure 3.16의 producer는 OS라는 shared-memory object를 만들고, 크기를 4096 bytes로 잡은 뒤 mmap()으로 pointer ptr을 얻는다. 이후 sprintf(ptr, "%s", message_0);처럼 pointer가 가리키는 memory에 string을 쓰고, 쓴 byte 수만큼 pointer를 증가시켜 다음 문자열을 이어 쓴다. 중요한 점은 write() system call로 kernel에 매번 data를 넘기는 것이 아니라, mapping된 memory address에 ordinary memory write처럼 접근한다는 것이다.

Figure 3.17 · PDF p. 172 · 같은 shared-memory object를 열어 읽고 `shm_unlink()`로 제거하는 consumer
Figure 3.17의 consumer는 같은 name OS로 object를 O_RDONLY mode로 열고, mmap()으로 자기 address space에 attach한다. printf("%s", (char *)ptr);로 shared memory 내용을 출력한 뒤 shm_unlink(name);으로 segment를 제거한다. 여기서 producer와 consumer가 같은 physical shared object를 서로 다른 virtual address space에 mapping해 사용한다는 점이 shared-memory IPC의 핵심이다.
Mach Message Passing
Mach는 distributed system을 염두에 두고 설계되었고, macOS와 iOS에도 포함된 kernel 계열이다. Mach에서 process와 유사한 단위는 task이며, task는 multiple threads of control을 가질 수 있고 process보다 resource 연관이 적다. Mach의 inter-task communication은 거의 모두 message로 이루어진다.
Mach의 mailbox는 port라고 불린다. Port의 특징은 다음과 같다.
| Mach port 특징 | 의미 |
|---|---|
| finite queue | port마다 message queue가 있고 크기가 유한함 |
| unidirectional | 한 방향 communication만 담당. two-way communication에는 reply port가 필요 |
| multiple senders, one receiver | 여러 task가 보낼 수 있지만 receive 권한은 하나의 task가 가짐 |
| resource representation | task, thread, memory, processor 같은 resource도 port로 표현 |
Mach는 port rights로 port 접근 capability를 관리한다. 예를 들어 어떤 task가 port에서 message를 받으려면 해당 port에 대한 MACH_PORT_RIGHT_RECEIVE capability가 있어야 한다. Port를 만든 task가 owner이며, owner만 receive할 수 있고 port capability를 조작할 수 있다. Reply를 기대하는 task는 상대 task에게 자기 reply port에 대한 MACH_PORT_RIGHT_SEND 권한을 넘겨야 한다.
Task가 생성되면 special ports인 Task Self port와 Notify port도 생성된다. Kernel은 Task Self port에 대한 receive right를 가지고, task는 이 port로 kernel에 message를 보낼 수 있다. Kernel은 Notify port로 event notification을 보낼 수 있다.
Port 생성은 mach_port_allocate()로 한다.
mach_port_t port;
mach_port_allocate(
mach_task_self(),
MACH_PORT_RIGHT_RECEIVE,
&port);각 task는 bootstrap port에도 접근할 수 있다. Task가 만든 port를 system-wide bootstrap server에 등록하면, 다른 task가 registry에서 port를 찾아 send right를 얻을 수 있다.
Mach message는 두 부분으로 구성된다.
| Field | 내용 |
|---|---|
| fixed-size message header | message size, source port, destination port 같은 metadata |
| variable-sized body | 실제 data |
Message는 simple message 또는 complex message일 수 있다. Simple message는 kernel이 해석하지 않는 ordinary user data를 담는다. Complex message는 out-of-line data pointer나 port rights transfer를 포함할 수 있다. Large data를 보낼 때 out-of-line data는 data 전체를 message에 복사해 넣는 대신 memory location pointer를 전달하므로 비용을 줄일 수 있다.

Figure 3.18 · PDF p. 175 · client와 server가 `mach_msg()`로 message를 send/receive하는 예제
Mach의 표준 send/receive API는 mach_msg()다. Parameter에 MACH_SEND_MSG를 주면 send, MACH_RCV_MSG를 주면 receive가 된다. User program의 mach_msg()는 kernel system call인 mach_msg_trap()으로 들어가고, kernel 내부에서 실제 message passing이 처리된다.
Port queue가 full일 때 Mach sender는 여러 정책을 고를 수 있다.
| 정책 | 의미 |
|---|---|
| indefinitely wait | queue에 room이 생길 때까지 계속 wait |
| timed wait | 최대 n milliseconds만 wait |
| no wait | 기다리지 않고 즉시 return |
| temporarily cache | full queue로 보낼 message를 OS에 임시 보관시키고, 나중에 enqueue되면 notification을 받음 |
Message system의 고전적 성능 문제는 sender port에서 receiver port로 message를 copy하는 비용이다. Mach는 virtual-memory-management technique으로 이를 줄인다. Sender의 message가 있는 address space를 receiver의 address space에 map해 실제 message copy를 피하는 방식이다. 이 최적화는 큰 성능 이득을 주지만, 같은 system 안의 intrasystem messages에만 적용된다.
Windows ALPC
Windows는 modularity를 높이기 위해 여러 operating environment, 즉 subsystem을 지원한다. Application program은 subsystem server의 client처럼 동작하고, message-passing mechanism으로 subsystem과 communication한다.
Windows의 message-passing facility는 advanced local procedure call (ALPC)이다. ALPC는 같은 machine 위의 두 process 사이 communication에 쓰이며, standard remote procedure call (RPC)와 유사하지만 local Windows communication에 최적화되어 있다.
Windows는 Mach처럼 port object로 process 사이 connection을 establish/maintain한다. Port는 두 종류다.
| Port type | 역할 |
|---|---|
connection port | server process가 publish하며 client가 service 요청을 보내기 위해 여는 public port |
communication port | server가 connection 요청을 받은 뒤 만드는 private channel port |
Client가 subsystem service를 원하면 server의 connection-port object handle을 열고 connection request를 보낸다. Server는 channel을 만들고 client에게 handle을 돌려준다. Channel은 private communication ports의 pair로 구성된다. 하나는 client-to-server messages, 다른 하나는 server-to-client messages를 담당한다. Callback mechanism도 있어, client/server가 reply를 기다릴 상황에서도 request를 받을 수 있다.
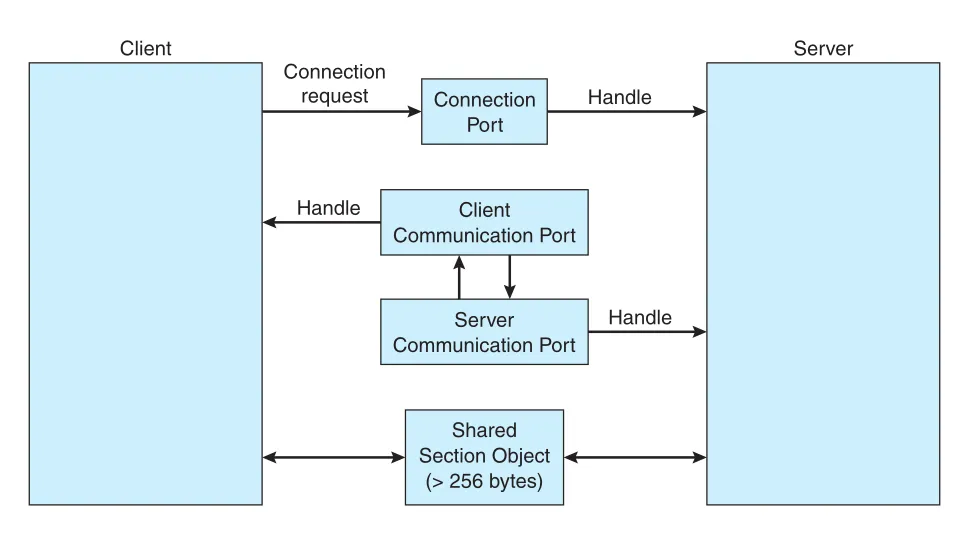
Figure 3.19 · PDF p. 177 · connection port, communication ports, shared section object를 사용하는 Windows ALPC 구조
ALPC channel이 만들어질 때 message-passing technique은 data size에 따라 달라진다.
| Data size | 방식 | 비용 특성 |
|---|---|---|
| small messages, up to 256 bytes | port message queue에 intermediate storage로 저장하고 process 사이 copy | 단순하지만 copy 발생 |
| larger messages | channel에 연결된 section object, 즉 shared memory region 사용 | 복잡하지만 copy 감소 |
| section object에도 너무 큰 data | server가 client address space를 직접 read/write하는 API 사용 | 더 강한 권한/관리 필요 |
Client가 large message를 보낼 필요가 있으면 channel setup 때 section object 생성을 요청한다. Server reply가 large이면 server도 section object를 만든다. Section object를 사용하려면 작은 message에 section object의 pointer와 size 정보를 담아 보낸다. ALPC 자체는 Windows API로 application programmer에게 직접 노출되지 않고, application이 local system에서 standard RPC를 호출하면 내부적으로 ALPC가 사용된다. 많은 kernel services도 client process와 통신할 때 ALPC를 사용한다.
Pipes
pipe는 두 process가 communication할 수 있게 해 주는 conduit이다. UNIX 초기부터 사용된 가장 오래된 IPC mechanism 중 하나이며, 단순하지만 제한도 있다. Pipe를 설계/이해할 때는 네 가지 질문을 봐야 한다.
| 질문 | 선택지 |
|---|---|
| 방향성 | unidirectional 또는 bidirectional |
| 양방향이면 | half duplex 또는 full duplex |
| process 관계 | parent-child 관계가 필요한가 |
| 위치 | 같은 machine만 가능한가, network across machines도 가능한가 |
원문은 UNIX와 Windows에서 모두 쓰이는 ordinary pipes와 named pipes를 다룬다.
Ordinary Pipes
ordinary pipe는 standard producer-consumer 방식으로 두 process를 연결한다. Producer는 pipe의 write end에 쓰고, consumer는 read end에서 읽는다. Ordinary pipe는 unidirectional이므로 one-way communication만 가능하다. Two-way communication이 필요하면 opposite direction을 담당하는 pipe를 하나 더 만들어야 한다.
UNIX ordinary pipe는 다음 function으로 만든다.
pipe(int fd[])fd[0]은 read end, fd[1]은 write end다. UNIX는 pipe를 special type of file로 취급하므로 ordinary read()와 write() system calls로 접근할 수 있다.
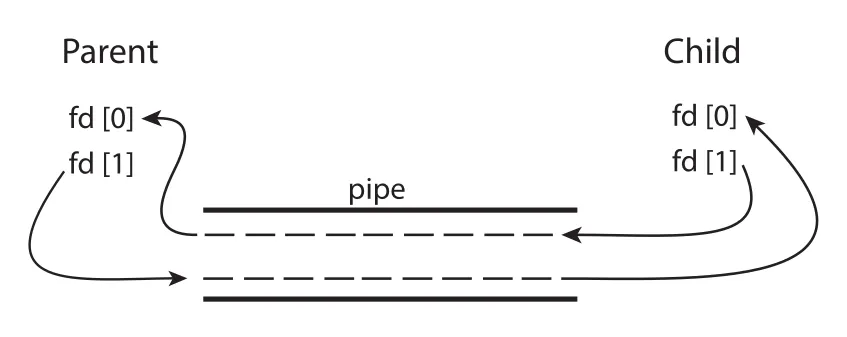
Figure 3.20 · PDF p. 178 · parent와 child가 ordinary pipe의 read/write file descriptor를 공유하는 구조
Ordinary pipe는 만든 process 밖에서는 접근할 수 없다. 일반적으로 parent process가 pipe를 만들고, fork()로 child를 만든 뒤 parent-child 사이 communication에 사용한다. Child는 parent의 open files를 inherit하므로, special file인 pipe의 file descriptors도 함께 inherit한다.

Figure 3.21 · PDF p. 179 · UNIX ordinary pipe 예제의 include, buffer, file descriptor 준비

Figure 3.22 · PDF p. 180 · `pipe()`, `fork()`, `close()`, `write()`, `read()`로 parent-child pipe 통신 수행
Figure 3.21과 Figure 3.22의 UNIX example은 parent가 "Greetings" message를 pipe에 쓰고 child가 읽는 흐름이다.
pipe(fd)로 pipe를 만들고fd[READ_END],fd[WRITE_END]를 얻는다.fork()로 child process를 만든다.- Parent는 사용하지 않는 read end를
close(fd[READ_END])로 닫는다. - Parent는
write(fd[WRITE_END], write_msg, strlen(write_msg)+1);로 pipe에 쓴다. - Parent는 write end를 닫는다.
- Child는 사용하지 않는 write end를 닫고,
read(fd[READ_END], read_msg, BUFFER_SIZE);로 message를 읽는다. - Child는 read end를 닫는다.
사용하지 않는 pipe end를 닫는 것은 관례 이상의 의미가 있다. Reader가 read()에서 end-of-file을 감지하려면 writer 쪽 end가 닫혀야 한다. Writer end가 남아 있으면 reader는 더 올 data가 있다고 보고 block될 수 있다. 따라서 parent와 child가 자기에게 필요 없는 end를 초기에 닫는 습관은 pipe program의 correctness와 연결된다.
Windows ordinary pipe는 anonymous pipe라고 부른다. UNIX counterpart처럼 unidirectional이고, communicating processes 사이에 parent-child relationship을 사용한다. Pipe read/write는 ordinary ReadFile()과 WriteFile()로 수행한다.
Windows pipe 생성 API는 CreatePipe()이며, read handle, write handle, inheritance를 위한 SECURITY_ATTRIBUTES, pipe size를 parameter로 받는다. UNIX에서는 child가 parent의 pipe를 자동으로 inherit하지만, Windows에서는 programmer가 child가 inherit할 attribute와 handle을 명시해야 한다.

Figure 3.23 · PDF p. 181 · Windows anonymous pipe parent process의 handle과 structure 준비

Figure 3.24 · PDF p. 182 · `CreatePipe()`, handle inheritance, `CreateProcess()`, `WriteFile()` 흐름

Figure 3.25 · PDF p. 183 · child process가 standard input handle로 pipe를 읽는 Windows anonymous pipe 예제
Figure 3.23-3.25의 Windows example은 parent가 anonymous pipe를 만들고 child의 standard input을 pipe read end로 redirect한다.
SECURITY_ATTRIBUTES sa = {..., TRUE};로 handle inheritance를 허용한다.CreatePipe(&ReadHandle, &WriteHandle, &sa, 0)로 read/write handle을 만든다.GetStartupInfo(&si)뒤si.hStdInput = ReadHandle로 child standard input을 pipe read end에 연결한다.si.dwFlags = STARTF_USESTDHANDLES로 standard handle 설정을 사용하게 한다.SetHandleInformation(WriteHandle, HANDLE_FLAG_INHERIT, 0)으로 child가 write end를 inherit하지 못하게 한다.CreateProcess(..., TRUE, ..., &si, &pi)로 handle inheritance를 켠 상태에서 child를 만든다.- Parent는 unused read end를 닫고
WriteFile()로 message를 pipe에 쓴다. - Child는
GetStdHandle(STD_INPUT_HANDLE)로 read handle을 얻고ReadFile()로 message를 읽는다.
Ordinary pipe와 anonymous pipe는 parent-child relation이 필요하고, 같은 machine 안의 process 사이에서만 쓸 수 있다.
Named Pipes
named pipe는 ordinary pipe보다 강력하다. Ordinary pipe는 communicating processes가 끝나면 사라지지만, named pipe는 establish된 뒤 여러 process가 사용할 수 있고 communicating processes가 종료된 뒤에도 남을 수 있다.
| 구분 | UNIX FIFO | Windows named pipe |
|---|---|---|
| 이름 | FIFO | named pipe |
| 생성 | mkfifo() | CreateNamedPipe() |
| 사용 | open(), read(), write(), close() | ConnectNamedPipe(), ReadFile(), WriteFile() |
| 방향성 | bidirectional 가능하지만 half-duplex만 허용 | full-duplex 가능 |
| process 관계 | parent-child 관계 불필요 | parent-child 관계 불필요 |
| machine 범위 | 같은 machine | same or different machines |
| data 형태 | byte-oriented | byte-oriented 또는 message-oriented |
UNIX FIFO는 file system에 ordinary file처럼 나타나며, 명시적으로 delete될 때까지 존재한다. 하지만 intermachine communication이 필요하면 FIFO가 아니라 socket을 써야 한다. Windows named pipe는 더 풍부해서 full-duplex와 cross-machine communication을 지원한다.
Pipe는 shell에서도 매우 자주 쓰인다. UNIX command line에서 ls | less는 ls process의 output을 less process의 input으로 전달한다. 여기서 ls는 producer, less는 consumer다. Windows DOS shell에서도 dir | more처럼 | character로 pipe를 만들 수 있다. 이 예시는 pipe가 단순한 API 예제가 아니라, command-line process composition의 기본 도구라는 점을 보여준다.
3.8 Communication in Client-Server Systems
Shared memory와 message passing은 client-server system에도 사용할 수 있다. 원문은 client-server communication의 추가 전략으로 sockets와 remote procedure calls (RPCs)를 소개한다. Chapter 3 범위에서는 sockets를 실제 code 예제로 다루고, RPC는 message-based remote service abstraction으로 들어가는 부분까지 연결한다.
Sockets
socket은 communication endpoint다. Network를 통해 communication하는 process pair는 각 process마다 socket 하나씩, 즉 socket pair를 사용한다. Socket은 IP address + port number로 식별된다.
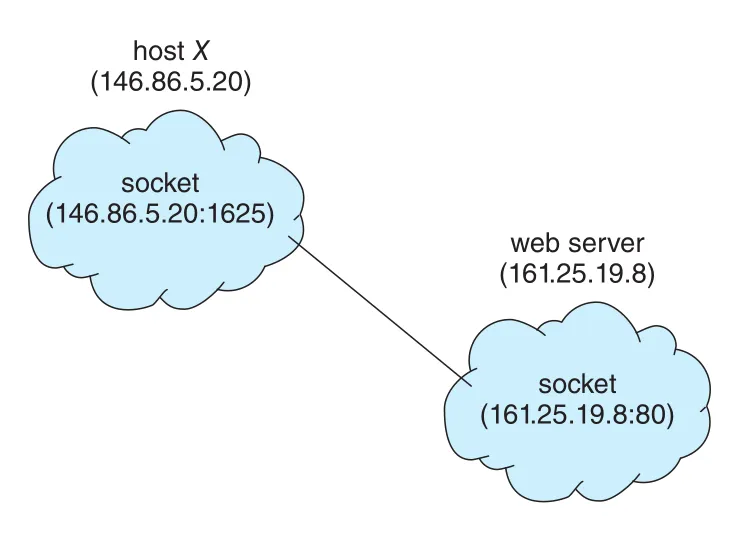
Figure 3.26 · PDF p. 185 · client socket과 web server socket이 IP address와 port number로 연결되는 구조
Socket communication은 일반적으로 client-server architecture를 따른다.
- Server는 특정 port를 listening한다.
- Client가 connection request를 보낸다.
- Server가 client socket의 connection을 accept한다.
- Packet은 destination port number를 기준으로 적절한 process에 deliver된다.
Well-known service는 well-known ports를 사용한다.
| Service | Well-known port |
|---|---|
| SSH | 22 |
| FTP | 21 |
| HTTP | 80 |
1024보다 작은 port는 standard service 구현에 쓰이는 well-known port로 간주된다. Client process가 connection을 시작하면 client host는 보통 1024보다 큰 arbitrary port를 배정한다. 예를 들어 client host 146.86.5.20이 local port 1625를 받고 web server 161.25.19.8:80에 연결하면 connection은 (146.86.5.20:1625)와 (161.25.19.8:80)라는 socket pair로 식별된다. 모든 connection은 unique해야 하므로, 같은 client host의 다른 process가 같은 web server에 연결하더라도 port 1625와 다른 port를 받아야 한다.
Java는 socket interface를 비교적 쉽게 보여준다.
| Java socket class | 의미 |
|---|---|
Socket | connection-oriented TCP socket |
DatagramSocket | connectionless UDP socket |
MulticastSocket | 여러 recipient에게 data를 보내는 multicast socket. DatagramSocket subclass |
원문 예제는 TCP socket을 쓰는 date server/client다. Server는 port 6013을 listen하고, client가 연결하면 현재 date/time string을 보내고 connection을 닫는다.

Figure 3.27 · PDF p. 186 · Java `ServerSocket`으로 port 6013을 listen하고 date를 반환하는 server
Figure 3.27의 server 흐름은 다음과 같다.
ServerSocket sock = new ServerSocket(6013);으로 port 6013을 listen한다.sock.accept()에서 client connection request가 올 때까지 block한다.accept()가 return한Socket client로 client와 communication한다.PrintWriter를 client output stream에 연결한다.pout.println(new java.util.Date().toString());로 date를 socket에 쓴다.client.close();로 client socket을 닫고 다시 listen loop로 돌아간다.

Figure 3.28 · PDF p. 187 · Java `Socket`으로 loopback address의 date server에 연결하는 client
Figure 3.28의 client는 new Socket("127.0.0.1", 6013)으로 server에 연결한다. 127.0.0.1은 loopback address로, host가 자기 자신을 가리킬 때 쓴다. Client는 socket input stream을 BufferedReader로 감싸고, server가 보낸 line을 읽어 출력한 뒤 socket을 닫는다. 같은 host에서 client와 server를 실험할 때 loopback을 쓰고, 다른 host의 server에 연결하려면 해당 host의 IP address나 hostname을 쓰면 된다.
Sockets는 common하고 efficient하지만 low-level communication 방식이다. 이유는 socket이 communicating threads 사이에 unstructured stream of bytes만 제공하기 때문이다. Data의 message boundary, record format, protocol semantics는 client/server application이 직접 정해야 한다. 이 한계 때문에 더 높은 수준의 remote communication abstraction인 remote procedure call (RPC)가 등장한다.
Remote Procedure Calls (RPCs)
remote procedure call (RPC)는 network connection으로 떨어진 system 사이에서 procedure-call mechanism을 추상화하려는 paradigm이다. Local function call처럼 보이게 만들지만, 실제로는 separate systems에서 실행되는 processes 사이의 message-based communication 위에 구축된다.
RPC는 Section 3.4의 IPC와 비슷하지만, remote service를 다루므로 shared memory가 아니라 message-based communication을 써야 한다. Android도 같은 system 위 process들 사이 IPC 형태로 remote procedure를 활용한다는 점에서, RPC는 network-only 개념이 아니라 “procedure call 형태로 감싼 message passing”이라는 관점으로 이해하는 편이 좋다.
연결 관계
| 이 장의 개념 | 이어지는 장/주제 |
|---|---|
process, PCB, context switch | Chapter 4 threads, Chapter 5 CPU scheduling |
ready queue, wait queue, CPU scheduler | Scheduling algorithm, preemption, dispatcher latency |
fork(), exec(), wait(), exit() | UNIX process model, shell, server process management |
shared memory, bounded buffer | Chapter 6 synchronization, Chapter 7 synchronization examples |
message passing, mailbox, port | Distributed systems, microkernel design, RPC |
mmap(), memory-mapped file | Chapter 9/10 memory management, Chapter 13 file-system implementation |
socket, port number, TCP/UDP | Network programming, distributed client-server architecture |
오해하기 쉬운 내용
program과process는 다르다. Program은 passive executable file이고, process는 program counter/register/resource를 가진 active execution이다.ready는 “실행 중”이 아니다. Ready process는 CPU에 올라갈 준비가 된 상태이고, 실제 instruction 실행은runningstate다.- PCB는 단순한 process 목록 entry가 아니다. Context switch 후 process를 정확히 재개하기 위한 saved execution context를 포함한다.
fork()는 새 program을 실행하는 call이 아니다. Parent address space의 copy를 만들고, 새 program 실행은 보통 child가exec()로 수행한다.exec()가 성공하면 원래 program으로 return하지 않는다. 기존 process memory image가 새 program으로 overlay되기 때문이다.- Zombie process는 resource를 계속 많이 쓰는 살아 있는 process가 아니다. 실행은 끝났지만 parent가 exit status를 collect하지 않아 process table entry가 남은 상태다.
- Shared memory는 “운영체제가 알아서 안전하게 공유해 주는 memory”가 아니다. 공유 region 설정 이후 data layout과 synchronization은 cooperating processes의 책임이다.
- Message passing이 항상 느리고 shared memory가 항상 답인 것은 아니다. Distributed system, 작은 message, conflict avoidance 측면에서는 message passing이 더 단순하고 안전하다.
- Ordinary pipe는 기본적으로 unidirectional이다. 양방향 communication에는 pipe 두 개가 필요하다.
- Socket은 message object를 자동으로 보존해 주는 high-level protocol이 아니다. 기본적으로 byte stream이므로 application protocol을 설계해야 한다.
면접 질문
program과process의 차이를 memory layout과 execution state 관점에서 설명하라.- Process state diagram에서
ready,running,waiting의 차이와 전이 조건을 설명하라. process control block (PCB)에는 어떤 정보가 들어가며, context switch에서 왜 필요한가?I/O-bound process와CPU-bound process는 scheduler 관점에서 어떻게 다르게 보이는가?context switch가 pure overhead인데도 운영체제가 반드시 수행해야 하는 이유는 무엇인가?- UNIX
fork()이후 parent와 child를 구분하는 방법은 무엇이며,exec()는 어떤 역할을 하는가? wait()를 호출하지 않은 parent 때문에 생기는zombie process와 parent가 먼저 종료되어 생기는orphan process를 비교하라.- Android process hierarchy에서
foreground process,service process,empty process의 종료 우선순위가 왜 다른가? - Shared memory IPC와 message passing IPC의 성능, 구현 난이도, synchronization 책임을 비교하라.
- Bounded buffer에서
in == out과((in + 1) % BUFFER_SIZE) == out조건은 각각 무엇을 의미하는가? - Direct communication과 indirect communication의 차이를
mailbox또는port개념으로 설명하라. - Blocking send/receive가 rendezvous를 만든다는 말은 무슨 뜻인가?
- POSIX shared memory에서
shm_open(),ftruncate(),mmap(),shm_unlink()의 역할을 순서대로 설명하라. - Mach의
port rights는 왜 capability처럼 동작하는가? - Windows ALPC가 small message와 large message를 다르게 처리하는 이유는 무엇인가?
- UNIX ordinary pipe에서 사용하지 않는 pipe end를 닫아야 하는 이유는 무엇인가?
- Ordinary pipe와 named pipe의 차이를 parent-child relation, lifetime, bidirectionality 관점에서 비교하라.
- Socket이
IP address + port number로 식별된다는 말의 의미를 client-server connection 예시로 설명하라. - Java date server 예제에서
accept()가 block되는 이유와 return 후 얻는Socket의 의미를 설명하라. - Socket이 low-level communication이고 RPC가 higher-level abstraction이라는 말의 의미를 설명하라.