Chapter 6. Synchronization Tools
- 과목: Operating System
- 기준 교재: Operating System Concepts 10th
- 관련 페이지: PDF pp. 332-362
- 우선순위: 필수
개요
synchronization은 cooperating processes 또는 cooperating threads가 shared data를 동시에 다룰 때 data consistency가 깨지지 않도록 실행 순서를 제어하는 운영체제 핵심 주제다. Chapter 3의 shared memory producer-consumer problem, Chapter 4의 multithreading, Chapter 5의 preemptive scheduling과 multicore execution이 결합되면, 하나의 high-level statement도 여러 machine instructions로 쪼개져 interleaving될 수 있다. 이 interleaving 때문에 결과가 실행 순서에 따라 달라지는 race condition이 발생한다.
이 장은 critical-section problem을 중심으로 software solution, hardware support, mutex locks, semaphores, monitors, condition variables, liveness 문제를 설명한다. 목표는 단순히 lock API 이름을 외우는 것이 아니라, 왜 mutual exclusion이 필요하고, 어떤 도구가 busy waiting, bounded waiting, deadlock, priority inversion 같은 trade-off를 만드는지 이해하는 것이다.
핵심 개념
| 개념 | 핵심 의미 |
|---|---|
cooperating process | 다른 process에 영향을 주거나 다른 process의 영향을 받을 수 있는 process |
shared data | 여러 processes/threads가 함께 접근하는 data |
race condition | concurrent access 결과가 access/interleaving 순서에 의존하는 상황 |
critical section | shared data를 access/update하는 code segment |
entry section | critical section 진입 허가를 요청하는 code |
exit section | critical section 사용 후 동기화 상태를 정리하는 code |
remainder section | shared data와 무관한 나머지 code |
mutual exclusion | 한 process가 critical section에 있을 때 다른 process는 critical section에 들어가지 못하는 조건 |
progress | critical section이 비어 있고 들어가려는 process가 있으면, 결정이 무기한 연기되지 않아야 하는 조건 |
bounded waiting | 어떤 process가 요청한 뒤 다른 processes가 먼저 들어갈 수 있는 횟수에 bound가 있어야 하는 조건 |
Peterson's solution | 두 processes를 위한 classic software-only critical-section solution |
preemptive kernel | kernel mode에서 실행 중인 process도 preempt될 수 있는 kernel |
nonpreemptive kernel | kernel mode process가 kernel을 빠져나가거나 block/yield할 때까지 preempt하지 않는 kernel |
세부 정리
6.1 Background
Concurrent execution과 parallel execution은 shared data consistency 문제를 만든다. Concurrent execution에서는 CPU scheduler가 processes 사이를 빠르게 전환하므로 한 process가 instruction stream 중간에서 interrupt될 수 있다. Parallel execution에서는 서로 다른 processing cores에서 둘 이상의 instruction streams가 실제로 동시에 실행된다. 두 경우 모두 shared variable을 다루는 high-level statement가 원자적으로 실행된다고 가정하면 안 된다.
Chapter 3의 bounded-buffer producer-consumer problem을 다시 보자. 기존 해법은 buffer에 최대 BUFFER_SIZE - 1 items만 둘 수 있었다. 이를 고치기 위해 count 변수를 추가해 producer가 item을 넣으면 count++, consumer가 item을 빼면 count--를 수행한다고 하자.
/* producer */
while (true) {
while (count == BUFFER_SIZE)
;
buffer[in] = next_produced;
in = (in + 1) % BUFFER_SIZE;
count++;
}
/* consumer */
while (true) {
while (count == 0)
;
next_consumed = buffer[out];
out = (out + 1) % BUFFER_SIZE;
count--;
}Producer와 consumer code는 각각 따로 보면 맞다. 하지만 동시에 실행되면 count가 잘못될 수 있다. 이유는 count++와 count--가 machine level에서는 여러 instructions로 분해되기 때문이다.
count++ -> register1 = count
register1 = register1 + 1
count = register1
count-- -> register2 = count
register2 = register2 - 1
count = register2count == 5에서 producer와 consumer가 동시에 실행되는 한 interleaving은 다음과 같다.
| Time | Process | Statement | Result |
|---|---|---|---|
T0 | producer | register1 = count | register1 = 5 |
T1 | producer | register1 = register1 + 1 | register1 = 6 |
T2 | consumer | register2 = count | register2 = 5 |
T3 | consumer | register2 = register2 - 1 | register2 = 4 |
T4 | producer | count = register1 | count = 6 |
T5 | consumer | count = register2 | count = 4 |
정상 결과는 producer가 하나 늘리고 consumer가 하나 줄였으므로 count == 5여야 한다. 그러나 위 순서에서는 count == 4가 된다. T4와 T5 순서를 바꾸면 count == 6도 가능하다. 이처럼 여러 processes가 같은 data를 concurrent하게 access/manipulate하고, 결과가 access 순서에 의존하면 race condition이다.
Operating system 내부에서도 race condition은 흔하다. Open-file list, memory allocation structures, process lists, interrupt handling structures 같은 kernel data structures는 여러 kernel activities가 동시에 수정할 수 있다. Multicore systems와 multithreaded applications가 일반화되면서 synchronization은 OS 내부뿐 아니라 application design에서도 기본 문제가 되었다.
6.2 The Critical-Section Problem
critical-section problem은 shared data를 안전하게 공유하기 위한 protocol 설계 문제다. n개의 processes {P0, P1, ..., Pn-1}가 있고, 각 process에는 shared data를 access/update하는 critical section이 있다. 핵심 요구는 한 process가 자신의 critical section을 실행 중이면 다른 process는 자신의 critical section을 동시에 실행할 수 없어야 한다는 것이다.
Figure 6.1은 typical process가 entry section, critical section, exit section, remainder section으로 반복되는 구조를 보여준다.
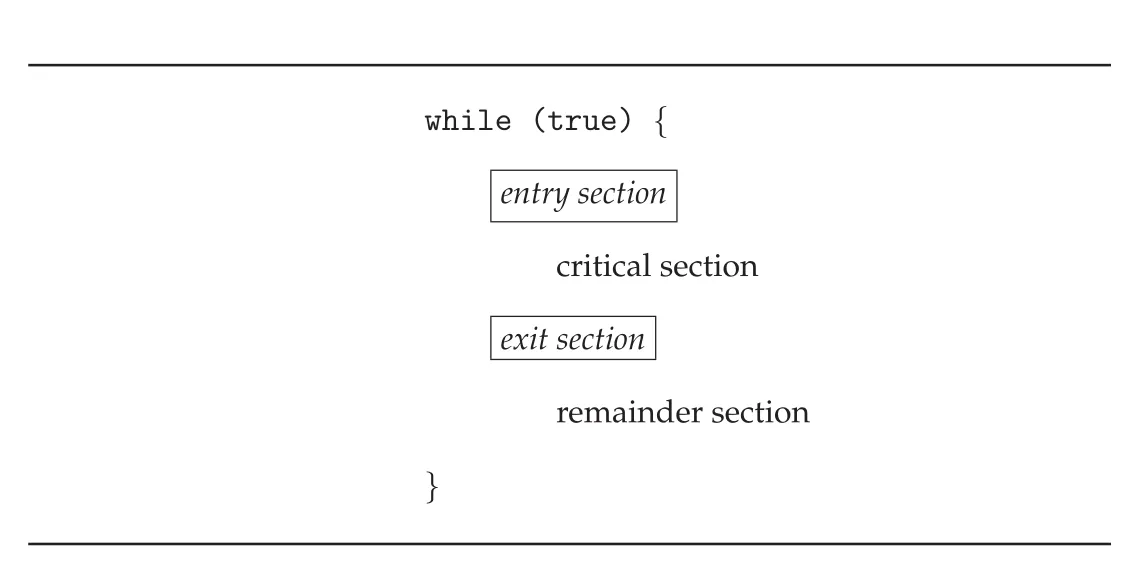
Figure 6.1 · PDF p. 335 · entry section, critical section, exit section, remainder section으로 이루어진 process 구조
Critical-section solution은 세 조건을 만족해야 한다.
| 조건 | 의미 | 깨졌을 때 생기는 문제 |
|---|---|---|
mutual exclusion | Pi가 critical section에 있으면 다른 process는 critical section에 있으면 안 됨 | shared data corruption |
progress | critical section이 비어 있고 들어가려는 process가 있으면, remainder section에 있지 않은 process들만 다음 진입자를 결정하고 결정이 무한히 미뤄지면 안 됨 | 아무도 들어가지 못하는 비합리적 지연 |
bounded waiting | 어떤 process가 entry 요청을 한 뒤, 그 요청이 승인되기 전 다른 processes가 critical section에 들어가는 횟수에 limit가 있어야 함 | starvation |
여기서는 각 process가 nonzero speed로 실행된다고만 가정하고, processes의 상대 속도에 대해서는 아무 가정도 하지 않는다. 즉 solution은 “어떤 process가 빠르다/느리다” 같은 timing assumption에 의존하면 안 된다.
Kernel code도 critical-section problem의 대상이다. 예를 들어 fork() system call로 child process를 만들 때 kernel variable next_available_pid를 읽고 갱신한다고 하자. 두 processes가 거의 동시에 fork()를 호출하면 같은 PID를 둘 다 받을 수 있다.
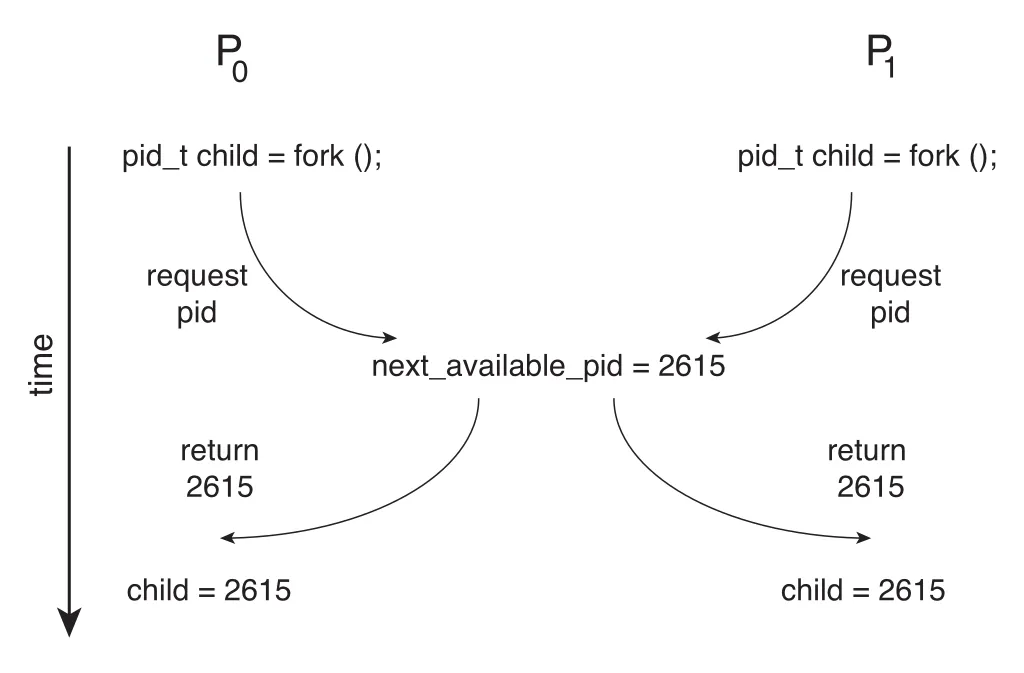
Figure 6.2 · PDF p. 336 · 두 fork() 호출이 같은 next_available_pid를 받아 같은 pid가 배정되는 race condition
Single-core 환경에서는 shared variable을 수정하는 동안 interrupts를 disable하면 간단히 race를 막을 수 있다. 현재 instruction sequence가 preemption 없이 순서대로 실행되므로 다른 code가 끼어들 수 없기 때문이다. 하지만 multiprocessor 환경에서는 이 방법이 부적절하다. 모든 processors에 interrupt disable message를 보내야 하므로 critical section 진입이 느려지고, system clock처럼 interrupts에 의존하는 기능에도 영향을 줄 수 있다.
OS kernel은 critical section을 다루기 위해 크게 두 접근을 가진다.
| Kernel type | 동작 | 장점 | 단점 |
|---|---|---|---|
nonpreemptive kernel | kernel mode process를 preempt하지 않음 | 한 번에 하나만 kernel에서 active하므로 kernel data race가 단순해짐 | kernel code가 오래 실행되면 responsiveness가 나빠질 수 있음 |
preemptive kernel | kernel mode process도 preempt 가능 | responsiveness와 real-time programming에 유리 | SMP에서 여러 kernel-mode processes가 동시에 실행될 수 있어 설계가 어려움 |
Preemptive kernel은 waiting process나 real-time process가 kernel-mode process를 기다리느라 오래 지연되는 위험을 줄인다. 그래서 반응성과 real-time suitability는 좋아지지만, shared kernel data를 보호하기 위한 synchronization 설계가 훨씬 중요해진다.
6.3 Peterson’s Solution
Peterson's solution은 두 processes를 위한 classic software-based critical-section solution이다. 현대 architecture에서는 load/store reordering 때문에 그대로 correctness를 보장하기 어렵지만, mutual exclusion, progress, bounded waiting을 동시에 만족하려면 어떤 상태와 protocol이 필요한지 보여주는 교육적 가치가 크다.
Peterson’s solution은 두 processes P0, P1이 critical section과 remainder section을 번갈아 실행한다고 가정한다. Pi를 설명할 때 다른 process를 Pj라고 쓰며, j = 1 - i다. 두 shared data items를 사용한다.
int turn;
boolean flag[2];turn: critical section에 들어갈 차례가 누구인지 나타낸다.turn == i이면Pi가 들어갈 수 있다.flag[i]:Pi가 critical section에 들어가고 싶다는 의사를 나타낸다.

Figure 6.3 · PDF p. 338 · process Pi가 flag와 turn으로 critical section 진입을 조정하는 Peterson's solution
Pi는 critical section에 들어가기 전에 flag[i] = true로 자기 의사를 표시하고, turn = j로 상대에게 우선권을 양보한다. 그런 다음 flag[j] && turn == j인 동안 기다린다. 즉 상대도 들어가고 싶고 상대 차례라면 기다리고, 그렇지 않으면 critical section에 들어간다.
두 processes가 동시에 들어가려 하면 둘 다 자기 flag를 true로 만들고 turn을 서로에게 넘긴다. turn에는 결국 하나의 값만 남으므로 둘 중 하나만 while 조건을 통과한다. 이 구조가 mutual exclusion을 만든다.
Peterson’s solution의 correctness는 세 관점으로 설명된다.
mutual exclusion: 두 process가 동시에 critical section에 있으려면flag[0] == flag[1] == true여야 한다. 하지만turn은 동시에 0과 1일 수 없으므로 둘 다 while을 통과할 수 없다.progress: critical section에 아무도 없고 들어가려는 process가 있으면, remainder section에 있는 process는 결정에 관여하지 않는다. 기다리는 조건은 상대의flag와turn에 의해 풀릴 수 있다.bounded waiting:Pi가 들어가려고flag[i] = true를 설정하면,Pj가 먼저 들어가더라도Pj가 exit하면서flag[j] = false로 만들기 때문에Pi가 무한히 밀리지 않는다.
좀 더 구체적으로, Pi가 critical section에 들어가지 못하는 유일한 경우는 flag[j] == true && turn == j인 while loop에 걸려 있을 때다. Pj가 들어갈 의사가 없으면 flag[j] == false라서 Pi가 들어간다. 둘 다 들어가려 하면 turn의 마지막 값이 한쪽을 먼저 통과시킨다. Pj가 먼저 들어갔다 해도 나올 때 flag[j] = false로 만들고, 다시 들어가려면 turn = i를 설정해야 하므로 Pi는 최대 한 번의 Pj 진입 뒤에 들어갈 수 있다.
하지만 Peterson’s solution은 modern computer architectures에서 그대로 동작한다고 보장할 수 없다. Processors나 compilers는 performance 향상을 위해 dependency가 없는 read/write operations를 reorder할 수 있다. Single-threaded application에서는 final result가 같다면 문제가 없어 보이지만, shared data를 쓰는 multithreaded application에서는 reordering이 다른 thread에게 관찰되는 순서를 바꿔 unexpected result를 만들 수 있다.
예를 들어 shared data가 다음과 같다고 하자.
boolean flag = false;
int x = 0;Thread 1은 while (!flag) ;로 기다린 뒤 x를 출력하고, Thread 2는 x = 100; flag = true;를 실행한다. 기대 결과는 Thread 1이 100을 출력하는 것이다. 그러나 x와 flag 사이에 data dependency가 없으므로 Thread 2의 stores가 flag = true 다음 x = 100 순서로 reorder될 수 있다. 그러면 Thread 1은 flag가 true인 것을 보고 빠져나왔지만 x == 0을 출력할 수 있다. 반대로 Thread 1 쪽 load가 reorder되어 x를 먼저 읽어도 같은 문제가 생긴다.
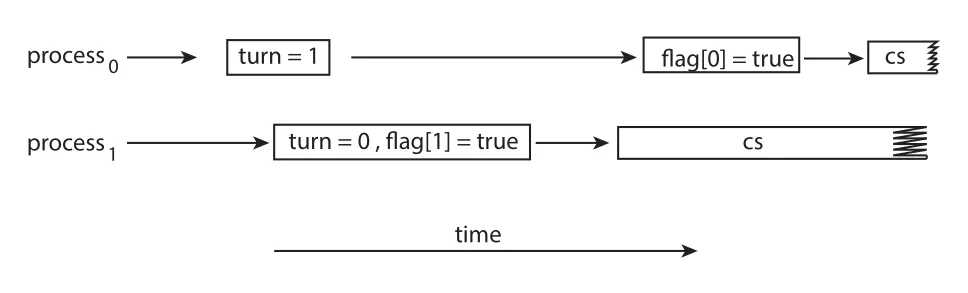
Figure 6.4 · PDF p. 340 · Peterson's solution의 entry assignment가 reorder되어 두 process가 동시에 critical section에 들어갈 수 있는 경우
Figure 6.4는 Peterson’s solution에서 entry section의 처음 두 assignments가 reorder되면 두 threads가 동시에 critical section에 있을 수 있음을 보여준다. 결론은 software-only reasoning만으로는 현대 hardware/compiler 환경에서 mutual exclusion을 보장하기 어렵고, 올바른 synchronization tools가 필요하다는 것이다.
6.4 Hardware Support for Synchronization
Hardware support는 critical-section problem을 풀기 위한 primitive를 제공한다. 이 primitive는 직접 synchronization tool로 쓰일 수도 있고, mutex locks, semaphores 같은 high-level mechanisms의 foundation으로 쓰일 수도 있다.
Memory Barriers
memory model은 computer architecture가 application program에 제공하는 memory visibility guarantee를 말한다. 크게 두 범주가 있다.
| Memory model | 의미 |
|---|---|
strongly ordered | 한 processor의 memory modification이 모든 다른 processors에 즉시 보임 |
weakly ordered | 한 processor의 memory modification이 다른 processors에 즉시 보이지 않을 수 있음 |
Shared-memory multiprocessor에서 kernel developer는 “내 store가 다른 core에서 곧바로 보일 것”이라고 가정할 수 없다. 이를 위해 architectures는 memory changes를 다른 processors에 전파하고 ordering을 강제하는 instructions를 제공한다. 이를 memory barrier 또는 memory fence라고 한다.
Memory barrier가 실행되면 barrier 이전의 all loads and stores가 완료된 뒤 barrier 이후의 load/store가 수행되도록 보장한다. 즉 processor/compiler가 instructions를 reorder하더라도, memory barrier는 특정 지점 전후의 memory operation visibility/order를 강제한다.
위 flag와 x 예시는 memory barrier로 고칠 수 있다.
/* Thread 1 */
while (!flag)
memory_barrier();
print x;
/* Thread 2 */
x = 100;
memory_barrier();
flag = true;Thread 1에서는 flag load가 x load보다 먼저 일어나게 하고, Thread 2에서는 x = 100 store가 flag = true store보다 먼저 visible하게 만든다. Peterson’s solution에서도 entry section의 첫 두 assignments 사이에 memory barrier를 넣으면 Figure 6.4의 reordering 문제를 피할 수 있다. 다만 memory barriers는 매우 low-level operations라 일반 application code보다 kernel이나 specialized synchronization code에서 주로 사용된다.
Hardware Instructions
Modern systems는 한 word를 test-and-modify하거나 두 words의 내용을 swap하는 atomic hardware instructions를 제공한다. 여기서 atomic은 operation이 하나의 uninterruptible unit처럼 실행된다는 뜻이다. 두 cores가 동시에 같은 atomic instruction을 실행해도 hardware는 어느 한 순서로 serial하게 보이도록 처리한다.
대표 추상 instruction은 test_and_set()과 compare_and_swap()이다.

Figure 6.5 · PDF p. 341 · target의 기존 값을 반환하고 target을 true로 설정하는 atomic test_and_set() 정의
test_and_set()은 target의 old value를 반환하면서 target을 true로 바꾼다. 이 전체가 atomic이다. 이를 사용하면 boolean lock, 초기값 false로 mutual exclusion을 구현할 수 있다.

Figure 6.6 · PDF p. 342 · test_and_set()으로 lock이 false가 될 때까지 spin한 뒤 critical section에 들어가는 구조
Figure 6.6의 핵심은 while (test_and_set(&lock)) ;이다. Lock이 이미 잡혀 있으면 test_and_set()은 old value true를 반환하므로 계속 기다린다. Lock이 풀린 순간 old value false를 반환하고 동시에 lock을 true로 만들기 때문에, 한 process만 critical section에 들어간다.
compare_and_swap (CAS)는 세 operands를 사용한다.

Figure 6.7 · PDF p. 342 · value가 expected와 같을 때만 new_value로 바꾸고 old value를 반환하는 atomic CAS
compare_and_swap(value, expected, new_value)는 *value == expected이면 *value = new_value로 바꾸고, 항상 original *value를 반환한다. 이 동작도 atomic이다.

Figure 6.8 · PDF p. 343 · compare_and_swap(&lock, 0, 1)이 성공할 때 critical section에 들어가는 CAS lock
CAS lock에서는 global lock을 0으로 초기화한다. 처음 compare_and_swap(&lock, 0, 1)를 성공시킨 process가 lock을 1로 바꾸고 critical section에 들어간다. 다른 process들은 lock이 0이 아니므로 실패하며 spin한다. Exit section에서 lock = 0으로 되돌리면 다음 process가 들어갈 수 있다.
하지만 Figure 6.8의 단순 CAS algorithm은 mutual exclusion은 만족해도 bounded waiting을 만족하지 않는다. 어떤 process가 계속 CAS 경쟁에서 밀리면 starvation이 가능하다.

Figure 6.9 · PDF p. 343 · waiting array와 cyclic scan으로 bounded waiting을 보장하는 CAS 기반 mutual exclusion
Figure 6.9는 waiting[n] array와 lock을 사용해 bounded waiting을 추가한다. Process가 critical section을 나갈 때 waiting array를 (i + 1, i + 2, ..., n - 1, 0, ..., i - 1) 순서로 scan하고, entry section에서 기다리는 첫 process를 다음 진입자로 지정한다. 따라서 기다리는 process는 최대 n - 1 turns 안에 들어갈 수 있다.
Intel x86에서는 compare_and_swap() 계열을 cmpxchg instruction으로 구현하며, atomic execution을 강제하기 위해 lock prefix를 사용해 destination operand update 동안 bus를 lock할 수 있다. 이 내용은 hardware가 “원자적”이라고 약속한 primitive 위에 OS synchronization abstraction이 올라간다는 점을 보여준다.
Atomic Variables
atomic variable은 integers나 booleans 같은 basic data types에 atomic operations를 제공하는 도구다. 보통 CAS 같은 hardware instruction으로 구현된다. 예를 들어 atomic integer sequence를 증가시키는 increment()는 다음처럼 CAS retry loop로 만들 수 있다.
void increment(atomic_int *v)
{
int temp;
do {
temp = *v;
}
while (temp != compare_and_swap(v, temp, temp + 1));
}Atomic variables는 counter나 sequence generator처럼 single shared variable update에는 유용하다. 그러나 모든 race condition을 해결하지는 못한다. Bounded-buffer에서 count를 atomic integer로 바꾸면 count++와 count-- 자체는 atomic해진다. 하지만 while (count == 0) 같은 condition check와 이후 consume operation 전체가 하나의 atomic critical section이 되는 것은 아니다. Buffer가 비어 있다가 producer가 item 하나를 넣으면, 두 consumers가 모두 loop를 빠져나와 item 하나를 둘 다 consume하려 할 수 있다.
즉 atomic variable은 “단일 update의 원자성”을 주지만, 여러 shared states와 control flow가 묶인 일반 critical section 보호에는 mutex locks, semaphores, monitors 같은 더 높은 수준의 tool이 필요하다.
6.5 Mutex Locks
Hardware-based solutions는 복잡하고 application programmer가 직접 쓰기 어렵다. 그래서 OS designers는 critical-section problem을 해결하기 위한 higher-level software tools를 제공한다. 가장 단순한 도구가 mutex lock이다. mutex는 mutual exclusion의 줄임말이다.
Mutex lock은 critical section을 보호한다. Process는 critical section에 들어가기 전에 acquire()로 lock을 얻고, 나올 때 release()로 lock을 반환한다. Mutex lock 내부에는 lock이 사용 가능한지를 나타내는 boolean variable available이 있다. Lock이 available이면 acquire()가 성공하고 lock은 unavailable이 된다. 이미 unavailable이면 process는 lock이 release될 때까지 기다린다.
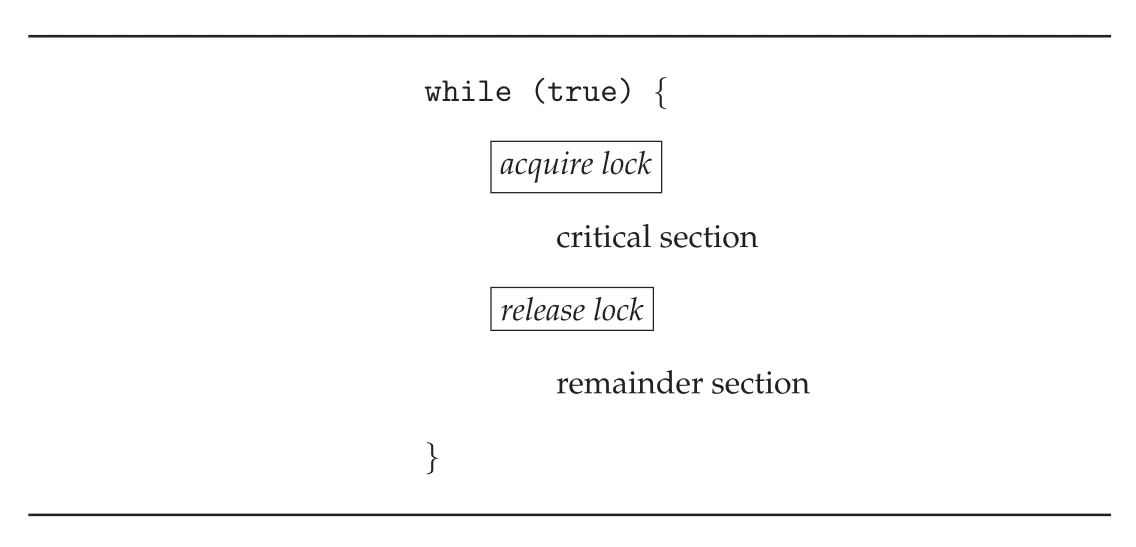
Figure 6.10 · PDF p. 346 · acquire lock 후 critical section에 들어가고 release lock 후 remainder section으로 돌아가는 mutex 구조
기본 acquire()와 release()는 다음처럼 표현된다.
acquire() {
while (!available)
; /* busy wait */
available = false;
}
release() {
available = true;
}acquire()와 release() 호출 자체는 atomic하게 수행되어야 한다. 그렇지 않으면 두 processes가 동시에 available을 보고 둘 다 lock을 획득했다고 판단할 수 있다. 실제 구현은 Section 6.4의 compare_and_swap() 같은 atomic operation으로 만들 수 있다.
Lock은 contention 여부에 따라 성능 특성이 크게 달라진다.
| 상태 | 의미 |
|---|---|
uncontended lock | thread가 lock을 요청할 때 lock이 available한 상태 |
contended lock | thread가 lock을 얻으려다 block 또는 wait해야 하는 상태 |
high contention | 많은 threads가 같은 lock을 얻으려 경쟁 |
low contention | 적은 수의 threads만 lock을 얻으려 경쟁 |
High-contention locks는 concurrent application의 전체 performance를 떨어뜨리기 쉽다. Lock이 보호하는 critical section이 길거나, 너무 많은 threads가 같은 shared structure를 자주 건드리면 parallelism이 lock 앞에서 직렬화된다.
위 구현의 가장 큰 단점은 busy waiting이다. 한 process가 critical section에 있는 동안 다른 process는 acquire() 안에서 계속 loop를 돌며 CPU cycles를 낭비한다. 이런 mutex lock을 spinlock이라고도 한다. Process가 lock이 풀리기를 기다리며 “spins”하기 때문이다.
Spinlock은 단점만 있는 것은 아니다. Lock을 기다리는 process를 sleep 상태로 보내면 최소 두 번의 context switch가 필요하다.
- Waiting state로 보내는 context switch
- Lock이 available해졌을 때 waiting thread를 restore하는 context switch
따라서 lock이 아주 짧은 시간만 유지된다면, 특히 multicore system에서 spinlock이 더 나을 수 있다. 한 core에서 thread가 spin하는 동안 다른 core에서 lock holder가 critical section을 빠르게 끝내면 context switch overhead를 피할 수 있다. 실무적 기준은 lock hold duration이 two context switches보다 짧으면 spinlock이 유리할 수 있다는 것이다. 그래서 modern multicore OS kernels는 짧은 critical section 보호에 spinlocks를 널리 사용한다.
6.6 Semaphores
semaphore는 mutex lock보다 더 일반적인 synchronization tool이다. Mutex처럼 mutual exclusion에 쓸 수도 있고, resource instances 수를 관리하거나 process 간 execution order를 강제하는 데도 쓸 수 있다.
Semaphore S는 integer variable이며, initialization을 제외하면 두 atomic operations로만 접근한다.
wait(S) {
while (S <= 0)
; /* busy wait */
S--;
}
signal(S) {
S++;
}wait()는 전통적으로 Dijkstra의 P operation, signal()은 V operation이라고도 불렸다. 중요한 점은 wait()와 signal() 안에서 semaphore value를 test하고 modify하는 부분이 atomic해야 한다는 것이다. 특히 wait(S)에서는 S <= 0 test와 S--가 interruption 없이 수행되어야 한다.
Semaphore Usage
Operating systems는 보통 semaphore를 두 종류로 구분한다.
| 종류 | 값의 범위 | 대표 용도 |
|---|---|---|
binary semaphore | 0 또는 1 | mutex lock처럼 mutual exclusion 제공 |
counting semaphore | 제한 없는 integer domain | finite resource instances 접근 제어 |
Counting semaphore는 resource가 여러 instance 있는 경우에 적합하다. Semaphore를 available resource count로 초기화한다. Process가 resource를 사용하려면 wait()로 count를 줄이고, release할 때 signal()로 count를 늘린다. Count가 0이면 모든 resources가 사용 중이므로, 이후 process는 count가 0보다 커질 때까지 기다린다.
Semaphores는 execution ordering에도 사용할 수 있다. 두 concurrent processes P1, P2가 있고, statement S2는 반드시 S1이 끝난 뒤 실행되어야 한다고 하자. Shared semaphore synch를 0으로 초기화하고 다음처럼 둔다.
/* P1 */
S1;
signal(synch);
/* P2 */
wait(synch);
S2;synch가 0으로 시작하므로 P2는 wait(synch)에서 기다린다. P1이 S1을 끝낸 뒤 signal(synch)를 호출해야 P2가 S2를 실행할 수 있다. 이 패턴은 “상호 배제”가 아니라 “happens-before order”를 만드는 semaphore 사용이다.
Semaphore Implementation
앞의 semaphore 정의도 mutex lock과 같은 busy waiting 문제를 가진다. 이를 줄이려면 wait()에서 semaphore value가 positive가 아닐 때 spin하지 않고 process를 suspend해야 한다. Suspend된 process는 해당 semaphore의 waiting queue에 들어가고, process state는 waiting state가 된다. CPU scheduler는 다른 process를 실행한다.
다른 process가 signal()을 수행하면, semaphore를 기다리던 process 중 하나를 wakeup()으로 깨워 waiting state에서 ready state로 옮긴다. CPU가 즉시 그 process로 전환될지는 CPU scheduling algorithm에 달려 있다.
이 방식의 semaphore는 다음 구조로 표현된다.
typedef struct {
int value;
struct process *list;
} semaphore;wait()와 signal()은 다음처럼 정의된다.
wait(semaphore *S) {
S->value--;
if (S->value < 0) {
add this process to S->list;
sleep();
}
}
signal(semaphore *S) {
S->value++;
if (S->value <= 0) {
remove a process P from S->list;
wakeup(P);
}
}이 구현에서는 semaphore value가 negative가 될 수 있다. Classical busy-waiting definition에서는 semaphore value가 음수가 되지 않지만, 여기서는 wait()가 먼저 decrement하고 나중에 test하므로 음수가 가능하다. S->value < 0이면 그 절댓값은 해당 semaphore를 기다리는 processes 수를 나타낸다.
Waiting list는 PCB의 link field로 구현할 수 있다. Bounded waiting을 보장하려면 FIFO queue를 사용할 수 있고, semaphore는 head/tail pointers를 가질 수 있다. 그러나 semaphore의 올바른 사용 자체가 반드시 특정 queueing strategy에 의존하는 것은 아니다.
Semaphore operations도 그 자체가 critical section이다. 같은 semaphore에 대해 두 processes가 동시에 wait()나 signal()을 실행하면 semaphore value와 list가 깨질 수 있다. Single-processor 환경에서는 operation 동안 interrupts를 inhibit하면 interleaving을 막을 수 있다. 그러나 multicore 환경에서는 모든 cores에서 interrupts를 막아야 하므로 비용이 크다. SMP systems는 보통 compare_and_swap()이나 spinlocks 같은 다른 primitive로 wait()와 signal()의 atomicity를 보장한다.
Blocking semaphore 구현은 busy waiting을 완전히 제거하지 않는다. Busy waiting을 application-level entry section에서 semaphore 내부의 매우 짧은 critical section으로 옮긴 것이다. 제대로 작성된 wait()/signal() 내부 critical section은 대략 몇 instructions 수준으로 짧기 때문에, 긴 critical section을 spin하며 기다리는 것보다 훨씬 낫다.
반대로 application program의 critical section이 minutes 또는 hours처럼 길거나 거의 항상 occupied되어 있다면 busy waiting은 극도로 비효율적이다. 이 distinction이 중요하다. Spin과 busy wait는 “항상 나쁜 것”이라기보다, 기다리는 시간이 짧고 context switch 비용보다 작을 때만 실용적이다.
6.7 Monitors
Semaphores는 편리하고 효과적이지만, 잘못 쓰면 timing errors가 쉽게 생긴다. 이런 오류는 특정 execution sequence에서만 발생하기 때문에 reproduce하기 어렵다. Producer-consumer의 count 문제처럼 결과가 1만 어긋나도 겉으로는 그럴듯해 보일 수 있다.
Binary semaphore mutex를 사용한 critical section 보호를 생각해 보자. 모든 process는 critical section 전에 wait(mutex), 나간 뒤 signal(mutex)를 실행해야 한다. 하지만 다음 실수 하나만 있어도 correctness가 깨진다.
| 실수 | 예 | 결과 |
|---|---|---|
wait()와 signal() 순서 바꿈 | signal(mutex); ... critical section ... wait(mutex); | 여러 processes가 동시에 critical section에 들어가 mutual exclusion 위반 |
signal() 대신 wait() 사용 | wait(mutex); ... critical section ... wait(mutex); | 두 번째 wait()에서 자기 자신이 permanent block |
wait() 또는 signal() 누락 | 한쪽 또는 둘 다 빠짐 | mutual exclusion 위반 또는 permanent block |
이 문제는 programmer가 synchronization protocol을 매번 정확히 지켜야 하기 때문에 생긴다. 이를 줄이는 전략 중 하나가 synchronization을 high-level language construct로 통합하는 것이다. 대표 construct가 monitor type이다.
Monitor Usage
abstract data type (ADT)는 data와 그 data를 조작하는 functions를 encapsulate한다. monitor type은 여기에 mutual exclusion을 포함한 ADT다. Monitor 안에는 shared state variables와 programmer-defined operations가 있고, monitor가 보장하는 중요한 성질은 한 번에 하나의 process만 monitor 내부에서 active할 수 있다는 것이다.

Figure 6.11 · PDF p. 352 · shared variables, operations, initialization code를 캡슐화한 monitor pseudocode syntax
Monitor의 representation은 외부 processes가 직접 사용할 수 없다. Monitor function은 monitor 내부 variables와 formal parameters에만 접근하고, monitor local variables는 monitor functions만 접근한다. 이 encapsulation 덕분에 programmer가 모든 operation마다 wait(mutex)와 signal(mutex)를 직접 쓰지 않아도 monitor 내부 mutual exclusion이 유지된다.
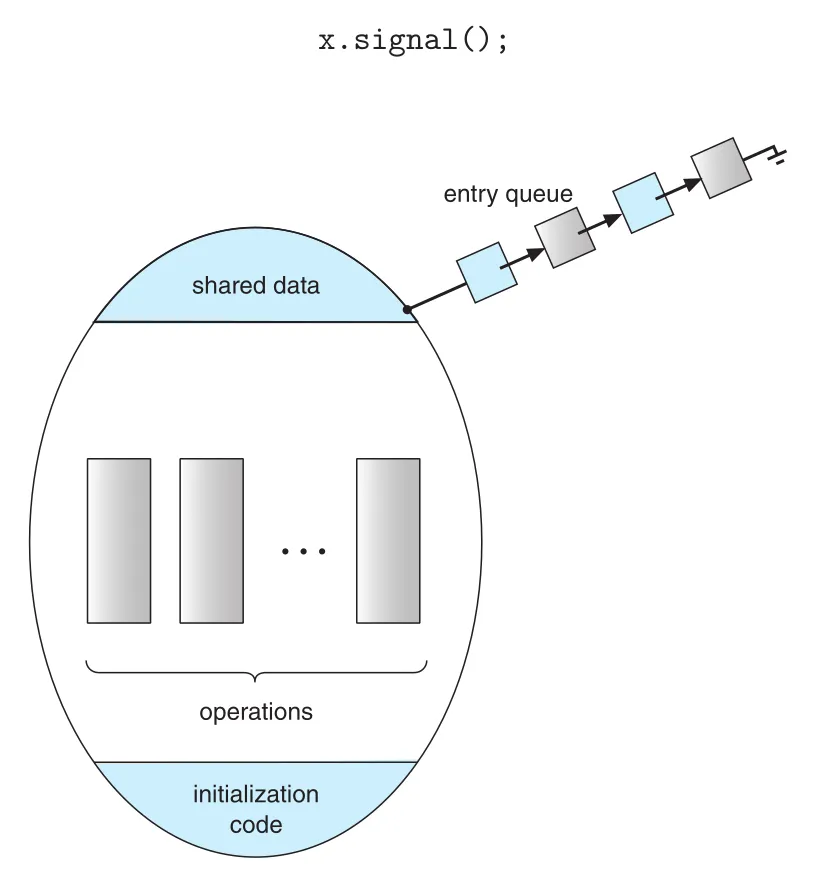
Figure 6.12 · PDF p. 353 · entry queue를 통해 한 process만 monitor operations 안에서 active해지는 구조
하지만 monitor만으로는 모든 synchronization scheme을 표현하기 부족하다. 어떤 condition이 만족될 때까지 monitor 내부에서 기다려야 할 수 있다. 이를 위해 condition variable을 둔다.
condition x, y;Condition variable에는 두 operation만 호출할 수 있다.
x.wait();
x.signal();x.wait()는 호출한 process를 suspend한다. 이 process는 다른 process가 x.signal()을 호출할 때까지 기다린다. x.signal()은 condition x에서 suspend된 process 하나를 resume한다. Suspend된 process가 없으면 아무 효과가 없다. 이 점은 semaphore의 signal()과 다르다. Semaphore signal()은 value를 증가시켜 state를 바꾸지만, monitor condition signal()은 기다리는 process가 없으면 lost signal처럼 아무 상태도 남기지 않는다.
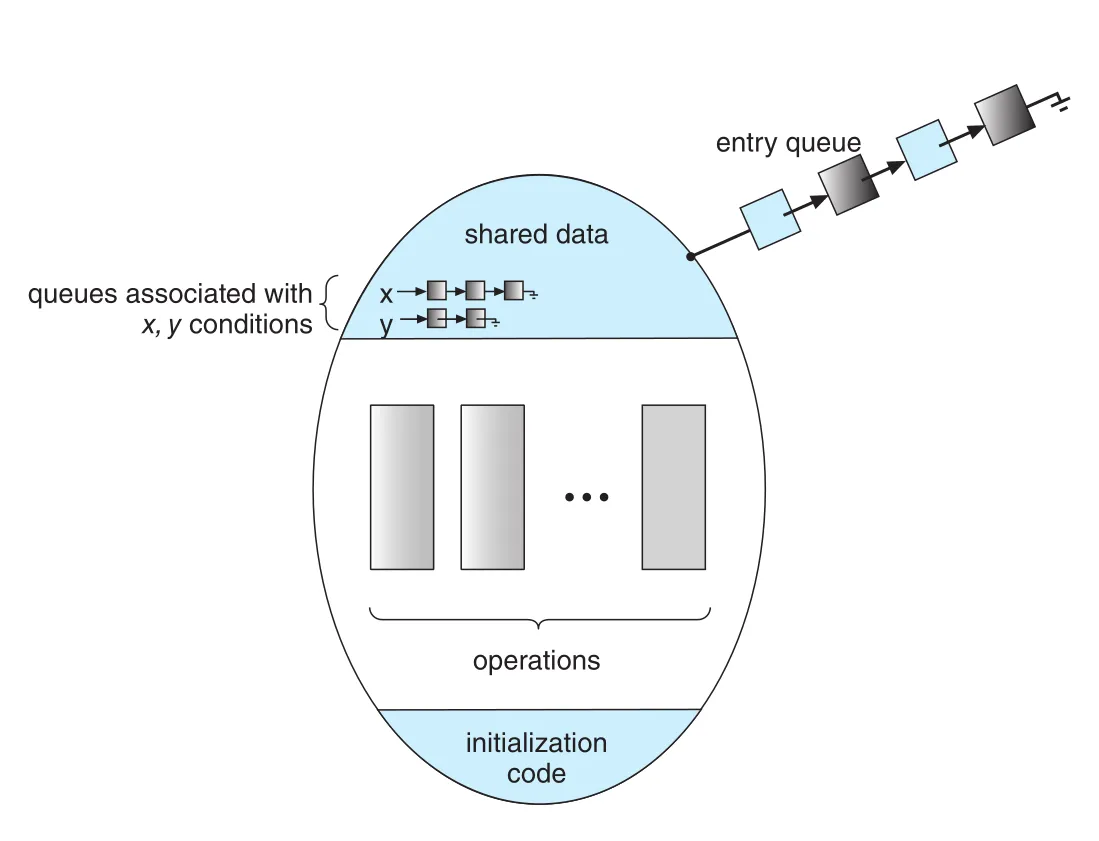
Figure 6.13 · PDF p. 354 · condition variables x, y별 waiting queue가 monitor 내부 synchronization을 보강하는 구조
x.signal() 호출 시 condition x에서 기다리던 process Q가 있고, signal을 호출한 process P도 monitor 안에 있다면 문제가 생긴다. Monitor는 한 번에 하나만 active해야 하므로 P와 Q가 동시에 monitor 안에서 실행될 수 없다. 두 semantics가 가능하다.
| 방식 | 의미 | 직관 |
|---|---|---|
signal and wait | P가 기다리고 Q가 즉시 resume | Q가 기다리던 logical condition이 아직 참일 때 바로 실행 |
signal and continue | P가 계속 실행하고 Q는 P가 monitor를 떠난 뒤 resume | 이미 monitor 안에서 실행 중인 P를 유지해 구현/흐름이 단순 |
Compromise로 P가 signal을 실행하면 즉시 monitor를 떠나고 Q가 바로 resume되는 방식도 있다. 중요한 trade-off는 condition이 signal 시점 이후에도 유지되는지다. signal and continue에서는 Q가 나중에 resume될 때 Q가 기다리던 condition이 더 이상 참이 아닐 수 있다.
Implementing a Monitor Using Semaphores
Monitor는 semaphores로 구현할 수 있다. 각 monitor마다 binary semaphore mutex, 초기값 1을 두어 mutual exclusion을 보장한다. Process는 monitor에 들어가기 전 wait(mutex), monitor를 떠날 때 signal(mutex)를 수행한다.
Signal-and-wait scheme을 구현하려면 추가 binary semaphore next, 초기값 0과 integer next_count가 필요하다. Signaling process는 resumed process가 monitor를 leave하거나 wait할 때까지 next에서 suspend된다. 각 external function F는 개념적으로 다음 형태로 감싸진다.
wait(mutex);
...
body of F
...
if (next_count > 0)
signal(next);
else
signal(mutex);Condition variable x마다 binary semaphore x_sem과 integer x_count를 둔다. x.wait()는 x_count를 증가시키고 monitor lock을 다음 process에게 넘긴 뒤 x_sem에서 sleep한다. x.signal()은 x_count > 0이면 waiting process 하나를 깨우고, signaler 자신은 next에서 기다린다. 이 구조가 monitor 내부의 mutual exclusion과 condition waiting을 동시에 유지한다.
Resuming Processes within a Monitor
Condition x에 여러 processes가 suspend되어 있을 때 x.signal()이 호출되면 누구를 깨울지 결정해야 한다. 가장 단순한 방법은 FCFS ordering이다. 가장 오래 기다린 process를 먼저 resume한다. 하지만 모든 상황에서 FCFS가 충분하지는 않다.
더 정교한 방식으로 conditional-wait construct가 있다.
x.wait(c);여기서 c는 wait 실행 시 evaluation되는 integer expression이며, priority number로 저장된다. x.signal()이 실행되면 가장 작은 priority number를 가진 process가 다음으로 resume된다.

Figure 6.14 · PDF p. 356 · single resource를 busy flag와 condition x로 할당하는 ResourceAllocator monitor
Figure 6.14의 ResourceAllocator monitor는 single resource를 competing processes 사이에 배정한다. Process가 resource를 요청할 때 사용 예정 최대 시간 time을 넘기고, monitor는 가장 짧은 time-allocation request를 가진 process에 resource를 배정할 수 있다. 사용 sequence는 다음처럼 의도된다.
R.acquire(t);
access the resource;
R.release();하지만 monitor concept만으로 이 sequence가 반드시 지켜진다고 보장할 수는 없다. Process가 permission 없이 resource에 직접 접근하거나, resource를 받고 release하지 않거나, 요청하지 않은 resource를 release하거나, release 없이 같은 resource를 두 번 요청할 수 있다.
즉 monitor는 monitor 내부 mutual exclusion과 condition synchronization을 돕지만, programmer-defined operations를 올바른 순서로 호출하고 shared resource를 우회 접근하지 않는다는 broader access-control property까지 자동으로 보장하지는 않는다. 작은 static system에서는 모든 program을 검사할 수 있지만, large/dynamic system에서는 어렵다. 이런 access-control 문제는 Chapter 17의 protection/security mechanisms와 연결된다.
6.8 Liveness
Synchronization tools는 critical section 접근을 조정하지만, 잘못 설계하면 process가 critical section에 들어가려고 영원히 기다릴 수 있다. 이런 indefinite waiting은 Section 6.2의 progress와 bounded waiting 조건을 위반한다.
liveness는 processes가 execution life cycle 동안 계속 progress를 만들 수 있도록 system이 만족해야 하는 properties의 집합이다. Process가 무기한 기다리는 상태는 liveness failure다. Liveness failure는 여러 형태가 있지만 보통 poor performance와 poor responsiveness로 나타난다. Infinite loop나 arbitrarily long busy wait도 단순한 liveness failure 예다.
Deadlock
deadlock은 둘 이상의 processes가, 그 processes 중 하나만 일으킬 수 있는 event를 서로 기다리며 영원히 진행하지 못하는 상태다. Semaphore waiting queue 구현에서도 deadlock이 생길 수 있다.
두 semaphores S, Q가 모두 1로 초기화되어 있고, 두 processes가 다음 순서로 실행한다고 하자.
P0 P1
wait(S); wait(Q);
wait(Q); wait(S);
... ...
signal(S); signal(Q);
signal(Q); signal(S);P0가 wait(S)를 먼저 실행하고, P1이 wait(Q)를 먼저 실행하면 각자 하나의 semaphore를 잡은 상태가 된다. 이제 P0는 Q를 기다리고, P1은 S를 기다린다. 그런데 signal(Q)는 P1이 나중에 실행해야 하고, signal(S)는 P0가 나중에 실행해야 한다. 둘 다 다음 단계로 가지 못하므로 deadlock이다.
더 일반적으로, process set의 모든 process가 그 set 안의 다른 process만 발생시킬 수 있는 event를 기다리면 deadlocked state다. 여기서 event는 주로 mutex locks나 semaphores 같은 resources의 acquisition/release다. Deadlock은 Chapter 8에서 더 체계적으로 다룬다.
Priority Inversion
priority inversion은 high-priority process가 필요한 resource를 low-priority process가 holding하고 있고, 그 low-priority process가 medium-priority process에 의해 preempt되면서 high-priority process의 실행이 간접적으로 지연되는 문제다.
세 processes L, M, H가 있고 priority가 L < M < H라고 하자. H가 semaphore S를 필요로 하는데 L이 이미 S를 잡고 있다. 보통은 H가 L이 resource를 release할 때까지 기다린다. 그런데 M이 runnable해져 L을 preempt하면, M은 H보다 priority가 낮지만 결과적으로 H가 기다리는 시간을 늘린다. 이것이 priority inversion이다.
Priority inversion은 priority levels가 두 개보다 많은 system에서 발생한다. 보통 priority-inheritance protocol로 해결한다. Higher-priority process가 필요로 하는 resource를 lower-priority process가 잡고 있으면, 그 lower-priority process는 resource를 놓을 때까지 higher priority를 임시로 inherit한다. 위 예에서 L은 H의 priority를 임시로 받아 M에게 preempt되지 않고 S를 빨리 release한다. 이후 L은 원래 priority로 돌아가고, S를 기다리던 H가 실행된다.
Real-time systems에서는 priority inversion이 단순 지연을 넘어 system failure를 만들 수 있다. Mars Pathfinder 사례는 high-priority task가 low-priority task가 가진 shared resource를 기다리고, medium-priority tasks가 low-priority task를 preempt하면서 reset이 반복된 classic priority inversion 사례다. VxWorks의 priority inheritance를 semaphore에 적용해 해결했다는 점이 핵심이다.
6.9 Evaluation
Synchronization tool 선택은 correctness뿐 아니라 contention load와 overhead에 크게 좌우된다. Section 6.4의 hardware primitives는 매우 low-level이며, 보통 mutex locks 같은 higher-level tools의 foundation으로 쓰인다. 하지만 CAS를 직접 활용한 lock-free algorithms도 점점 중요하다.
CAS-based approach는 optimistic strategy다. 먼저 variable update를 시도하고, 다른 thread와 collision이 있으면 감지한 뒤 성공할 때까지 retry한다. Mutual-exclusion locking은 pessimistic strategy다. 다른 thread가 동시에 update할 수 있다고 보고, update 전에 lock을 획득한다.
Contention 수준별 일반 경향은 다음과 같다.
| Contention | CAS-based synchronization | Traditional synchronization, mutex/semaphore |
|---|---|---|
uncontended | 둘 다 빠르지만 CAS가 약간 더 빠를 수 있음 | overhead가 있어 CAS보다 약간 무거울 수 있음 |
moderate contention | 대부분 성공하고 실패해도 몇 번 retry 후 성공하므로 빠를 수 있음 | contended lock acquisition이 wait queue, suspend, context switch로 이어져 더 비쌀 수 있음 |
high contention | 많은 retries와 cache coherence traffic으로 비효율적 | 결국 blocking/waiting 기반 traditional synchronization이 더 빠를 수 있음 |
Moderate contention이 특히 CAS에 유리하다. CAS는 Figure 6.8의 loop를 몇 번 돌다가 성공할 가능성이 높지만, mutex lock은 contended 순간 더 복잡한 code path, wait queue 삽입, context switch를 동반할 수 있다. 반대로 high contention에서는 CAS retry 자체가 과도해져 traditional synchronization이 더 낫다.
도구 선택 기준을 요약하면 다음과 같다.
| 상황 | 적합한 도구 | 이유 |
|---|---|---|
| Single shared counter update | atomic integer, atomic variable | mutex/semaphore보다 lightweight |
| 아주 짧은 critical section on multiprocessor | spinlock | context switch보다 spin 비용이 작을 수 있음 |
| 일반 critical section 보호 | mutex lock | binary semaphore보다 단순하고 overhead가 작음 |
| finite number of resource instances 제어 | counting semaphore | resource count를 자연스럽게 표현 |
| multiple readers 허용, writer는 exclusive | reader-writer lock | mutex보다 concurrency가 높음 |
| 복잡한 condition-based synchronization | monitor, condition variable | high-level abstraction으로 사용 실수를 줄임 |
Monitors와 condition variables는 사용하기 쉽고 단순한 high-level tools라는 장점이 있다. 그러나 구현에 따라 overhead가 크고 high-contention 상황에서 scale이 잘 안 될 수 있다. 그래서 compiler 최적화, concurrent language support, libraries/APIs 성능 개선이 계속 연구된다. 다음 Chapter 7은 여기서 배운 tools가 classical synchronization problems와 실제 OS/API에서 어떻게 쓰이는지 보여준다.
연결 관계
- Chapter 3의 shared-memory producer-consumer problem은 Chapter 6에서
countrace condition과 bounded-buffer synchronization 문제로 다시 등장한다. - Chapter 4의 multithreading과 Chapter 5의 preemptive scheduling은 instruction interleaving과 race condition이 실제로 발생하는 실행 환경을 제공한다.
- Chapter 5의 preemptive kernel, SMP, real-time scheduling은 여기서 kernel race, spinlock, priority inversion, priority inheritance와 연결된다.
- Chapter 7은 mutex locks, semaphores, monitors를 classical synchronization problems와 실제 OS examples에 적용한다.
- Chapter 8은 deadlock을 독립 주제로 확장해 resource allocation graph, prevention, avoidance, detection 같은 체계적 방법을 다룬다.
- Chapter 17은 monitor가 보장하지 못하는 resource access protocol 우회 문제를 protection/access-control mechanisms로 다룬다.
오해하기 쉬운 내용
count++같은 한 줄 statement는 atomic하지 않다. Load, add, store로 나뉘며 중간에 interrupt 또는 interleaving될 수 있다.mutual exclusion만 만족하면 충분하지 않다.progress와bounded waiting이 없으면 deadlock이나 starvation이 가능하다.- Peterson’s solution은 conceptually important하지만 modern architecture에서 instruction reordering 때문에 그대로 안전하다고 보면 안 된다.
memory barrier는 lock 자체가 아니라 memory operation ordering/visibility를 강제하는 low-level primitive다.atomic variable은 단일 variable update에는 유용하지만, 여러 조건과 shared data access를 묶은 critical section 전체를 자동으로 보호하지는 않는다.spinlock은 CPU를 낭비하지만, 짧은 critical section과 multicore 환경에서는 context switch보다 나을 수 있다.- Semaphore
signal()과 monitor condition variablesignal()은 다르다. Semaphore signal은 state를 바꾸지만, condition signal은 기다리는 process가 없으면 효과가 없다. - Monitor는 내부 mutual exclusion을 제공하지만, process가 resource protocol을 우회해서 직접 shared resource에 접근하는 것까지 막지는 못한다.
- Priority inversion은 high-priority process가 low-priority process를 직접 기다리는 상황에서 medium-priority process가 끼어들 때 특히 문제가 된다.
면접 질문
- Race condition이 무엇이며
count++와count--예시에서 왜 잘못된 값이 나오는가? - Critical-section problem의 세 조건
mutual exclusion,progress,bounded waiting은 각각 무엇을 보장하는가? - Preemptive kernel과 nonpreemptive kernel은 synchronization 관점에서 어떤 trade-off가 있는가?
- Peterson’s solution에서
flag[]와turn은 각각 어떤 역할을 하는가? - Peterson’s solution이 modern architecture에서 깨질 수 있는 이유는 무엇인가?
- Memory barrier 또는 memory fence는 어떤 문제를 해결하는가?
test_and_set()과compare_and_swap()은 어떻게 mutual exclusion 구현의 foundation이 되는가?- CAS 기반 단순 lock이 bounded waiting을 보장하지 못하는 이유는 무엇인가?
- Atomic variable이 유용한 경우와 충분하지 않은 경우를 구분해 설명하라.
- Mutex lock과 spinlock의 차이와 spinlock이 유리한 조건은 무엇인가?
- Binary semaphore와 counting semaphore는 어떤 용도로 구분되는가?
- Blocking semaphore 구현에서 semaphore value가 음수가 되는 의미는 무엇인가?
- Semaphore를 잘못 사용하면 어떤 timing errors가 생길 수 있는가?
- Monitor와 condition variable은 semaphore 사용 실수를 어떻게 줄이는가?
signal and wait와signal and continue의 차이는 무엇인가?- Deadlock과 priority inversion은 각각 어떤 liveness failure인가?
- Priority-inheritance protocol은 priority inversion을 어떻게 완화하는가?
- Low, moderate, high contention에서 CAS와 traditional locking의 성능 경향은 어떻게 달라지는가?