Chapter 8. Deadlocks
- 과목: Operating System
- 기준 교재: Operating System Concepts 10th
- 관련 페이지: PDF pp. 415-442
- 우선순위: 필수
개요
deadlock은 여러 threads/processes가 finite resources를 두고 경쟁하다가, 각자가 가진 resource를 놓지 않은 채 서로가 가진 resource를 기다려 영원히 진행하지 못하는 liveness failure다. Chapter 6에서는 deadlock을 synchronization 도구 사용 중 생기는 liveness 문제로 짧게 보았고, Chapter 7에서는 dining-philosophers problem 같은 classic examples에서 deadlock 가능성을 확인했다. Chapter 8은 deadlock을 system model, 발생 조건, graph characterization, prevention, avoidance, detection, recovery로 체계화한다.
운영체제는 일반적으로 모든 application deadlock을 자동으로 예방해 주지 않는다. Deadlock-free program을 설계하는 책임은 상당 부분 programmer에게 있다. 특히 multicore systems에서 concurrency와 parallelism 요구가 커질수록 lock ordering, resource request pattern, recovery policy 설계가 더 어려워진다.
핵심 개념
| 개념 | 핵심 의미 |
|---|---|
deadlock | set 안의 모든 threads가 그 set 안의 다른 thread만 발생시킬 수 있는 event를 기다리는 상태 |
resource type | CPU, file, I/O device, mutex lock처럼 동일 instance들로 구성된 resource class |
resource instance | 특정 resource type에 속하는 개별 자원 |
request-use-release | thread가 resource를 요청하고, 사용하고, 해제하는 정상 사용 sequence |
livelock | threads가 block되지는 않지만 실패하는 action을 계속 반복해 progress를 못 하는 상태 |
mutual exclusion | resource가 nonsharable mode로 held되는 deadlock necessary condition |
hold and wait | thread가 resource를 hold한 채 다른 resource를 기다리는 condition |
no preemption | resource를 강제로 빼앗을 수 없고 holder가 자발적으로 release해야 하는 condition |
circular wait | threads가 cycle 형태로 서로의 resource를 기다리는 condition |
resource-allocation graph | threads와 resource types, request/assignment edges로 deadlock 가능성을 표현하는 directed graph |
request edge | Ti -> Rj, thread가 resource type instance를 기다림 |
assignment edge | Rj -> Ti, resource instance가 thread에 할당됨 |
세부 정리
8.1 System Model
System은 competing threads 사이에 분배되는 finite number of resources로 구성된다. Resources는 여러 resource types 또는 classes로 나뉘고, 각 resource type은 하나 이상의 identical instances를 가진다.
예를 들어 CPU cycles, files, network interfaces, DVD drives는 resource types가 될 수 있다. System에 CPUs가 4개 있으면 CPU resource type은 4 instances를 가진다. Network interfaces가 2개면 network resource type은 2 instances를 가진다. 어떤 thread가 resource type의 instance 하나를 요청했을 때 그 type의 아무 instance나 할당해도 request를 만족해야 한다. 그렇지 않다면 instances가 동일하지 않은 것이므로 resource type classification이 잘못된 것이다.
Chapter 6의 mutex locks, semaphores 같은 synchronization tools도 system resources다. 현대 computer systems에서 deadlock의 가장 흔한 원천은 이런 locks다. Lock은 보통 특정 data structure에 연결되므로, queue를 보호하는 lock과 linked list를 보호하는 lock은 서로 다른 resource class로 보는 것이 자연스럽다.
Thread는 resource를 사용하기 전에 request하고, 사용 후 release해야 한다. 정상적인 resource 사용 sequence는 다음 세 단계다.
| 단계 | 의미 | 예시 |
|---|---|---|
Request | resource를 요청한다. 즉시 받을 수 없으면 wait state로 간다. | held mutex를 요청한 thread가 block |
Use | resource를 실제로 사용한다. | mutex를 얻은 thread가 critical section 접근 |
Release | 사용을 끝내고 resource를 반환한다. | mutex unlock, file close, memory free |
Request/release는 system calls일 수 있다. Device의 request()/release(), file의 open()/close(), memory의 allocate()/free(), semaphore의 wait()/signal(), mutex lock의 acquire()/release()가 모두 이 model에 들어간다.
Kernel-managed resource에 대해 OS는 thread가 resource를 request했고 allocation을 받았는지 확인한다. System table은 각 resource가 free인지 allocated인지 기록하고, allocated resource에 대해서는 어느 thread에 할당되었는지도 기록한다. Thread가 이미 다른 thread에게 allocated된 resource를 요청하면, 해당 resource를 기다리는 queue에 들어갈 수 있다.
Deadlock의 일반 정의는, 어떤 thread 집합의 모든 thread가 그 집합 안의 다른 thread가 일으켜야만 하는 event를 기다리고 있어 아무도 진행할 수 없는 상태다.
여기서 주로 다루는 events는 resource acquisition과 release다. Resource는 mutex locks, semaphores, files 같은 logical resources가 많지만, network interface read나 Chapter 3의 IPC facilities 같은 event도 deadlock을 만들 수 있다.
Dining-philosophers problem은 직관적 예다. 모든 philosophers가 동시에 hungry해져 각자 왼쪽 chopstick을 잡으면 available chopsticks가 사라진다. 모두 오른쪽 chopstick을 기다리지만, 오른쪽 chopstick은 neighbor가 쥐고 있으므로 아무도 진행하지 못한다.
8.2 Deadlock in Multithreaded Applications
Deadlock은 Pthreads mutex locks 같은 일반 application-level synchronization에서도 쉽게 발생한다. pthread_mutex_init()은 unlocked mutex를 초기화하고, pthread_mutex_lock()과 pthread_mutex_unlock()으로 acquire/release한다. 이미 locked mutex를 acquire하려 하면 owner가 unlock할 때까지 calling thread가 block된다.
두 mutex가 있다고 하자.
pthread_mutex_t first_mutex;
pthread_mutex_t second_mutex;
pthread_mutex_init(&first_mutex, NULL);
pthread_mutex_init(&second_mutex, NULL);thread_one은 first_mutex를 먼저 잡고 그 다음 second_mutex를 잡는다. 반대로 thread_two는 second_mutex를 먼저 잡고 그 다음 first_mutex를 잡는다.

Figure 8.1 · PDF p. 418 · 두 threads가 두 mutex를 반대 순서로 획득해 deadlock이 가능해지는 Pthreads 예
Deadlock은 다음 interleaving에서 발생한다.
| Step | Thread one | Thread two |
|---|---|---|
| 1 | pthread_mutex_lock(&first_mutex) 성공 | |
| 2 | pthread_mutex_lock(&second_mutex) 성공 | |
| 3 | second_mutex를 기다리며 block | |
| 4 | first_mutex를 기다리며 block |
각 thread는 자신이 가진 mutex를 release하기 전에 상대 mutex를 얻어야 하는데, 상대 mutex는 상대 thread가 release해야 한다. 둘 다 release 지점에 도달하지 못하므로 deadlock이다.
이 예의 중요한 점은 deadlock이 항상 발생하지는 않는다는 것이다. thread_one이 두 locks를 모두 acquire/release한 뒤 thread_two가 실행되면 deadlock은 발생하지 않는다. 즉 deadlock은 CPU scheduler가 만든 특정 scheduling circumstance에서만 드러날 수 있어 test와 reproduce가 어렵다.
Livelock
livelock도 liveness failure다. Deadlock과 마찬가지로 두 개 이상의 threads가 progress하지 못하지만, 이유가 다르다. Deadlock에서는 threads가 block되어 event를 기다린다. Livelock에서는 threads가 block되지는 않고 계속 action을 시도하지만, 그 action이 계속 실패해 실질적 progress가 없다.
복도에서 두 사람이 서로 길을 비켜 주려고 동시에 같은 방향으로 움직였다가, 다시 반대 방향으로 동시에 움직여 계속 못 지나가는 상황과 비슷하다. 둘 다 움직이고 있지만 앞으로 나아가지 못한다.
Pthreads에서는 pthread_mutex_trylock()으로 livelock을 만들 수 있다. trylock()은 blocking하지 않고 lock acquire를 시도한다. 실패하면 thread가 가진 lock을 풀고 다시 반복하도록 만들면, 두 threads가 계속 같은 pattern으로 실패할 수 있다.

Figure 8.2 · PDF p. 420 · trylock 실패 시 자기 lock을 풀고 재시도하면서 livelock이 가능한 예
Figure 8.2에서 thread_one이 first_mutex를 잡고, thread_two가 second_mutex를 잡은 뒤 서로의 두 번째 mutex에 trylock()을 시도한다고 하자. 둘 다 실패하면 각자 자기 mutex를 풀고 loop를 반복한다. 같은 timing이 계속되면 둘은 block되지 않지만 영원히 일을 끝내지 못한다.
Livelock은 보통 threads가 실패한 operation을 같은 timing으로 반복할 때 생긴다. 해결은 retry timing을 randomize하는 것이다. Ethernet collision 이후 host들이 즉시 재전송하지 않고 random backoff 후 재시도하는 방식이 같은 아이디어다. Livelock은 deadlock보다 덜 흔하지만, deadlock처럼 특정 scheduling circumstances에서만 나타날 수 있어 concurrent application 설계에서 까다롭다.
8.3 Deadlock Characterization
Necessary Conditions
Deadlock이 발생하려면 다음 네 조건이 동시에 성립해야 한다.
| Condition | 의미 |
|---|---|
mutual exclusion | 적어도 하나의 resource가 nonsharable mode로 held되어야 한다. 다른 thread가 요청하면 resource release까지 기다려야 한다. |
hold and wait | Thread가 적어도 하나의 resource를 holding한 채, 다른 threads가 holding 중인 additional resources를 기다린다. |
no preemption | Resource를 강제로 빼앗을 수 없다. Holder가 task를 끝내고 자발적으로 release해야 한다. |
circular wait | {T0, T1, ..., Tn}에서 T0는 T1이 가진 resource를, T1은 T2가 가진 resource를, …, Tn은 T0가 가진 resource를 기다린다. |
Deadlock이 발생하려면 네 조건이 모두 필요하다. circular wait는 hold and wait를 함의하므로 완전히 독립적이지는 않지만, Section 8.5의 prevention에서는 각 조건을 따로 깨뜨리는 전략을 세우기 때문에 구분해서 보는 것이 유용하다.
Resource-Allocation Graph
Deadlock은 system resource-allocation graph라는 directed graph로 더 정확히 표현할 수 있다. Graph는 vertices V와 edges E로 구성된다.
- : active threads 집합
- : resource types 집합
Edges는 두 종류다.
| Edge | 이름 | 의미 |
|---|---|---|
request edge | Thread 가 resource type 의 instance를 요청했고 기다리는 중 | |
assignment edge | Resource type 의 instance 하나가 thread 에 allocated됨 |
Pictorially, thread는 circle, resource type은 rectangle로 표현한다. Resource type에 여러 instances가 있으면 rectangle 안의 dots로 instances를 나타낸다. Request edge는 resource rectangle을 향하고, assignment edge는 그 resource type 안의 특정 dot에서 thread로 향한다.
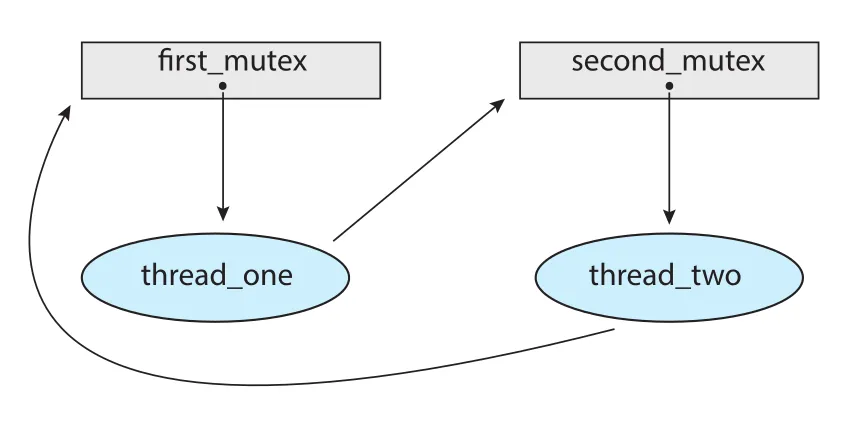
Figure 8.3 · PDF p. 421 · Figure 8.1의 first_mutex/second_mutex deadlock을 resource-allocation graph로 표현한 모습
Thread가 resource instance를 요청하면 request edge가 graph에 추가된다. Request가 fulfill되면 request edge는 즉시 assignment edge로 변환된다. Thread가 resource를 release하면 assignment edge가 삭제된다.
Figure 8.4는 다음 상태를 표현한다.
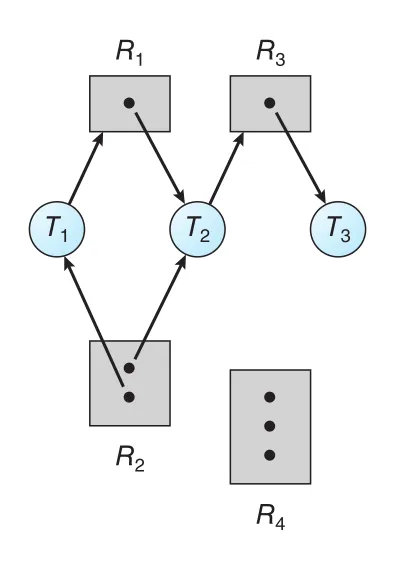
Figure 8.4 · PDF p. 422 · threads T1-T3와 resource types R1-R4의 request/assignment 관계
- 은 instance 1개, 는 2개, 는 1개, 는 3개
- 은 instance를 holding하고 instance를 waiting
- 는 , instances를 holding하고 instance를 waiting
- 는 instance를 holding
Resource-allocation graph의 핵심 판정은 cycle이다.
| Graph 상태 | Deadlock 판정 |
|---|---|
| No cycle | Deadlock 없음 |
| Cycle + 각 resource type instance가 1개 | Deadlock 발생. Cycle은 necessary and sufficient condition |
| Cycle + resource type에 여러 instances 가능 | Deadlock일 수도 있고 아닐 수도 있음. Cycle은 necessary but not sufficient condition |
Figure 8.4 상태에서 가 instance를 요청하면 available instance가 없으므로 request edge 가 추가된다.
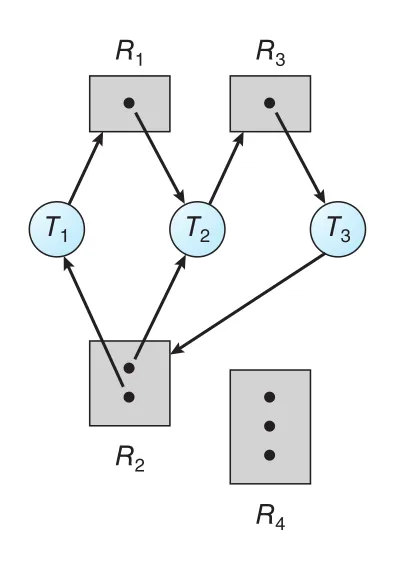
Figure 8.5 · PDF p. 423 · T3가 R2를 요청하면서 두 minimal cycles가 생기고 deadlock이 발생한 graph
이때 두 minimal cycles가 생긴다.
, , 모두 deadlocked다. 는 가 가진 를 기다리고, 는 또는 가 가진 release를 기다리고, 은 가 가진 release를 기다린다.
반면 Figure 8.6에는 cycle이 있지만 deadlock은 없다.
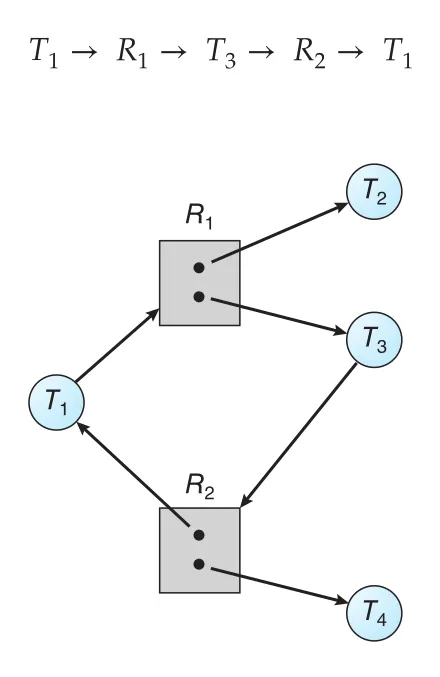
Figure 8.6 · PDF p. 423 · cycle은 있지만 T4가 R2 instance를 release하면 cycle이 깨질 수 있어 deadlock이 아닌 graph
Cycle 이 존재하지만, 가 instance를 release할 수 있다. 그러면 그 instance를 에 allocate해 cycle을 깰 수 있다. 따라서 multiple instances가 있는 resource-allocation graph에서는 cycle만 보고 deadlock이라고 단정하면 안 된다.
8.4 Methods for Handling Deadlocks
Deadlock 문제를 다루는 방법은 크게 세 가지다.
| 접근 | 핵심 아이디어 | 대표 사용 맥락 |
|---|---|---|
| Ignore | deadlock이 발생하지 않는다고 가정하고 별도 처리를 하지 않음 | 대부분의 general-purpose OS, Linux/Windows |
| Prevent or avoid | system이 deadlocked state에 들어가지 않도록 protocol 사용 | programmer가 lock ordering/resource policy 설계 |
| Detect and recover | deadlock 발생을 허용하고, detect한 뒤 recovery 수행 | databases 등 일부 system |
대부분의 OS는 첫 번째 접근, 즉 deadlock을 OS 차원에서 일반적으로 처리하지 않는 방식을 쓴다. 대신 kernel/application developers가 deadlock-free program을 작성해야 한다. 이유는 비용이다. 많은 system에서 deadlock은 드물게 발생하므로, 항상 prevention/avoidance/detection overhead를 지불하는 것이 비싸다고 판단할 수 있다.
Deadlock을 무시하면, 실제 deadlock 발생 시 system은 이를 인식하지 못한다. Deadlocked threads가 resources를 holding한 채 실행되지 못하고, 더 많은 threads가 resource request를 하다가 deadlocked state로 들어가면서 performance가 점점 악화된다. 결국 system restart 같은 manual recovery가 필요할 수 있다.
Deadlock을 원천적으로 막으려면 두 방식이 있다.
deadlock prevention: Section 8.3.1의 necessary conditions 중 적어도 하나가 성립하지 못하도록 resource request 방식을 제한한다.deadlock avoidance: thread가 lifetime 동안 어떤 resources를 request/use할지 advance information을 OS가 알고, 각 request를 허용해도 safe한지 판단한다.
Prevention은 request pattern 자체를 제약한다. Avoidance는 현재 available resources, 각 thread에 allocated된 resources, future requests/releases 정보를 함께 고려해 이번 request를 즉시 만족할지 delay할지 결정한다.
Prevention/avoidance를 쓰지 않는 system에서는 deadlock이 발생할 수 있다. 이때는 deadlock detection algorithm으로 system state를 검사하고, deadlock이 확인되면 recovery algorithm으로 복구한다. 어떤 단일 접근도 OS의 모든 resource-allocation 문제에 최적인 것은 아니므로, resource class별로 서로 다른 접근을 조합할 수 있다.
8.5 Deadlock Prevention
Deadlock prevention은 네 necessary conditions 중 적어도 하나가 성립하지 못하게 하는 방식이다.
Mutual Exclusion
mutual exclusion condition은 적어도 하나의 resource가 nonsharable이어야 한다는 조건이다. Sharable resources는 simultaneous access를 허용하므로 deadlock에 직접 관여하지 않는다. Read-only file이 대표적인 sharable resource다. 여러 threads가 read-only file을 동시에 open해도 상호 배제가 필요 없다.
하지만 deadlock prevention을 위해 mutual exclusion을 부정하는 것은 일반적으로 불가능하다. 어떤 resources는 본질적으로 nonsharable이다. mutex lock은 여러 threads가 동시에 공유할 수 없고, critical section 보호 자체가 mutual exclusion을 전제로 한다.
Hold and Wait
hold and wait condition을 막으려면 thread가 resource를 요청할 때 다른 resource를 hold하고 있지 않게 해야 한다. 두 protocol이 가능하다.
| Protocol | 설명 | 문제 |
|---|---|---|
| All-at-once request | thread가 execution 시작 전에 필요한 모든 resources를 request하고 allocate받음 | dynamic resource request가 많은 application에는 비현실적 |
| Request only when holding none | thread가 추가 resource를 요청하려면 현재 allocated resources를 모두 release해야 함 | resource utilization 저하, starvation 가능 |
두 방식 모두 단점이 크다. Resource utilization이 낮아질 수 있다. 예를 들어 thread가 mutex lock을 전체 execution 동안 미리 할당받지만 실제로는 짧은 구간에서만 필요할 수 있다. 또한 여러 popular resources가 필요한 thread는 필요한 resource 중 하나가 항상 다른 thread에게 할당되어 있어 indefinite waiting, 즉 starvation을 겪을 수 있다.
No Preemption
no preemption condition을 깨려면 이미 할당된 resource를 강제로 회수할 수 있어야 한다. 한 protocol은 다음과 같다. Thread가 some resources를 holding한 상태에서 즉시 할당받을 수 없는 다른 resource를 요청하면, 현재 holding 중인 모든 resources를 preempt한다. 즉 implicitly release한다. Thread는 이전 resources와 새로 요청한 resources를 모두 다시 얻을 수 있을 때 restart된다.
다른 protocol도 가능하다. Thread가 resources를 요청하면 먼저 available한지 확인한다. Available하면 allocate한다. Available하지 않다면, 그 resources가 additional resources를 기다리는 다른 thread에게 할당되어 있는지 확인한다. 그렇다면 waiting thread로부터 desired resources를 preempt하여 requesting thread에 준다. 그렇지 않으면 requesting thread가 wait한다. Waiting 중인 thread가 가진 resources도 다른 thread가 요청하면 preempt될 수 있다.
이 protocol은 state를 저장하고 나중에 restore하기 쉬운 resources에는 적용 가능하다. CPU registers나 database transactions가 예다. 그러나 mutex locks와 semaphores처럼 deadlock이 흔히 발생하는 resource에는 일반적으로 적용하기 어렵다. Lock을 강제로 빼앗으면 critical section consistency가 깨질 수 있기 때문이다.
Circular Wait
앞의 세 조건을 깨는 방법은 현실적으로 제약이 크다. 가장 실용적인 prevention target은 circular wait이다. 핵심은 모든 resource types에 total ordering을 부여하고, threads가 increasing order로만 resources를 요청하게 하는 것이다.
Resource types 집합을 이라 하고, 각 resource type에 unique integer를 부여하는 one-to-one function 을 정의한다. 예를 들어 Figure 8.1의 두 mutex에 다음 ordering을 줄 수 있다.
Protocol은 다음과 같다.
- Thread는 처음에 임의의 resource 를 요청할 수 있다.
- 이후 resource 를 요청하려면 반드시 여야 한다.
- 또는 를 요청하기 전에 인 resources를 모두 release해야 한다.
- 같은 resource type의 여러 instances가 필요하면 한 번의 request로 모두 요청해야 한다.
이 ordering이 circular wait을 막는 이유는 contradiction으로 볼 수 있다. Circular wait이 있다고 가정하면 는 를 기다리고, 는 이 holding한다. 그런데 이 를 holding한 상태에서 을 요청했다면 ordering protocol 때문에 이어야 한다. Cycle 전체에 대해 가 되어야 하는데, 이는 불가능하다. 따라서 circular wait은 생길 수 없다.
다만 ordering을 정의하는 것만으로 deadlock이 자동으로 방지되지는 않는다. Application developers가 그 ordering을 실제 code에서 지켜야 한다. Locks가 수백/수천 개 있는 system에서는 hierarchy 설계 자체가 어렵다. Java 개발자들은 때때로 System.identityHashCode(Object)를 lock acquisition ordering function으로 사용하기도 한다.
Dynamic lock acquisition에서는 ordering이 더 까다롭다. 두 accounts 사이 funds transfer를 생각하자. 각 account에 mutex lock이 있고 get_lock(account)로 얻는다고 하자.

Figure 8.7 · PDF p. 428 · from/to account 순서로 lock을 얻는 transaction()에서 dynamic lock ordering deadlock이 가능한 예
한 thread가 transaction(checking_account, savings_account, 25.0)을 호출하고, 다른 thread가 동시에 transaction(savings_account, checking_account, 50.0)을 호출하면 각자 첫 번째 account lock을 잡고 두 번째 account lock을 기다릴 수 있다. 함수 인자 순서가 lock ordering을 결정하게 두면 global total ordering을 깨기 쉽다. Dynamic resources에 대해서도 항상 stable total order를 적용해야 circular wait prevention이 의미가 있다.
8.6 Deadlock Avoidance
deadlock prevention은 requests를 제한해 necessary condition 중 하나를 깨뜨린다. 하지만 그 부작용으로 device utilization이 낮아지고 system throughput이 줄 수 있다. deadlock avoidance는 더 많은 정보를 사용해, 각 request를 허용해도 미래에 deadlock 가능성이 없는지 판단한다.
Avoidance에는 thread가 앞으로 어떤 resources를 request/use할지에 대한 추가 정보가 필요하다. 가장 단순하고 유용한 model은 각 thread가 각 resource type에 대해 필요할 수 있는 maximum number를 미리 declare하는 것이다. 이 a priori information을 바탕으로 system은 현재 resource-allocation state를 동적으로 검사하여 circular-wait condition이 생기지 않게 한다.
Resource-allocation state는 다음 정보로 정의된다.
- 현재 available resources 수
- 각 thread에 currently allocated resources
- 각 thread의 maximum demands
Linux의 lockdep tool은 kernel lock ordering을 동적으로 검증하는 대표적 도구다. Lock acquisition/release patterns를 관찰해, locks가 inconsistent order로 acquire되거나 interrupt handler에서도 쓰이는 spinlock을 interrupts enabled 상태에서 acquire하는 위험한 pattern을 보고한다. Production system용이라기보다 kernel module/device driver 개발 중 possible deadlock source를 찾는 도구다.
Safe State
System state가 safe하다는 것은, system이 어떤 order로든 각 thread에게 maximum까지 resources를 할당해도 deadlock을 피하며 모든 threads를 끝낼 수 있다는 뜻이다. 더 형식적으로, current allocation state에 대해 safe sequence가 존재하면 system은 safe state다.
Thread sequence <T1, T2, ..., Tn>이 safe sequence라는 뜻은 각 Ti가 앞으로 요청할 수 있는 remaining resources를 현재 available resources와 Ti보다 앞선 Tj들이 종료 후 반환할 resources로 만족시킬 수 있다는 뜻이다. Ti가 당장 필요한 resources를 못 받더라도 앞선 threads가 finish하고 resources를 반환하면 Ti가 완료될 수 있고, 그 다음 Ti+1도 같은 방식으로 진행된다.
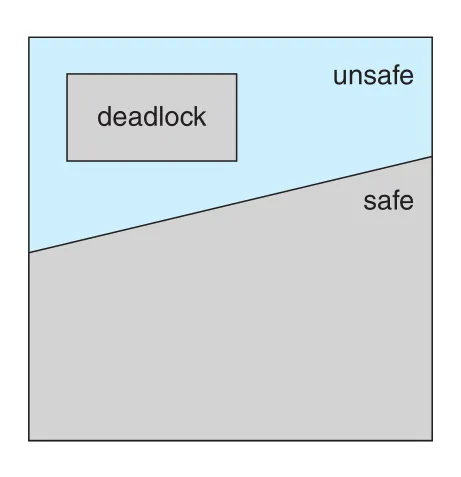
Figure 8.8 · PDF p. 430 · safe state, unsafe state, deadlocked state의 포함 관계
Figure 8.8의 관계가 중요하다.
| State | 의미 |
|---|---|
safe state | deadlock이 아니며, OS가 계속 safe state만 유지하면 deadlock을 피할 수 있음 |
unsafe state | 당장 deadlock은 아닐 수 있지만, threads의 future requests에 따라 deadlock으로 갈 수 있음 |
deadlocked state | 항상 unsafe state |
즉 all deadlocks are unsafe, but not all unsafe states are deadlocks.
예를 들어 resource가 12개 있고 threads T0, T1, T2가 있다고 하자.
| Thread | Maximum needs | Current allocation |
|---|---|---|
T0 | 10 | 5 |
T1 | 4 | 2 |
T2 | 9 | 2 |
현재 allocated 총합은 9이므로 available은 3이다. 이 상태는 safe하다. Safe sequence <T1, T0, T2>가 존재한다.
T1은 추가 2개만 있으면 maximum 4를 만족하므로 available 3으로 완료 가능하다. 종료 후 allocated 2개를 반환해 available은 5가 된다.T0는 추가 5개가 필요하므로 available 5로 완료 가능하다. 종료 후 10개를 반환해 available은 10이 된다.T2는 추가 7개가 필요하므로 available 10으로 완료 가능하다.
하지만 T2가 resource 하나를 더 요청하고 할당받으면 available은 2가 된다. 이제 T1만 완료 가능하고, T1 종료 후 available은 4가 된다. T0는 추가 5개, T2는 추가 6개가 필요하므로 둘 다 기다릴 수 있고 deadlock으로 갈 수 있다. 즉 resource가 available하더라도 그 request를 grant하면 unsafe state가 될 수 있다. Avoidance algorithm은 바로 이런 request를 delay한다.
Resource-Allocation-Graph Algorithm
각 resource type에 instance가 하나만 있는 system에서는 resource-allocation graph를 avoidance에 사용할 수 있다. 기존 request edge, assignment edge에 더해 claim edge를 도입한다.
| Edge | 의미 |
|---|---|
claim edge Ti -> Rj | Ti가 미래에 Rj를 request할 수 있음을 미리 선언 |
request edge Ti -> Rj | 실제로 Ti가 Rj를 요청해 기다리는 중 |
assignment edge Rj -> Ti | Rj가 Ti에 allocated됨 |
Claim edge는 request edge와 방향은 같지만 dashed line으로 표시된다. Thread가 resource를 실제 요청하면 claim edge가 request edge로 바뀐다. Resource가 할당되면 request edge는 assignment edge로 바뀐다. Thread가 resource를 release하면 assignment edge는 다시 claim edge가 된다.
Claim edges는 a priori로 선언되어야 한다. Thread가 실행되기 전에 자신이 요청할 수 있는 resources가 graph에 나타나야 한다. 완화된 조건으로는 thread와 관련된 모든 edges가 claim edges일 때만 새 claim edge를 추가할 수 있다.
Thread Ti가 resource Rj를 요청할 때, request edge를 assignment edge로 바꿔도 graph에 cycle이 생기지 않을 때만 request를 grant한다. Cycle이 없으면 allocation 후에도 safe state다. Cycle이 생기면 unsafe state가 되므로 Ti는 wait해야 한다. Cycle detection은 threads 수가 n일 때 order of n^2 operations가 필요하다.
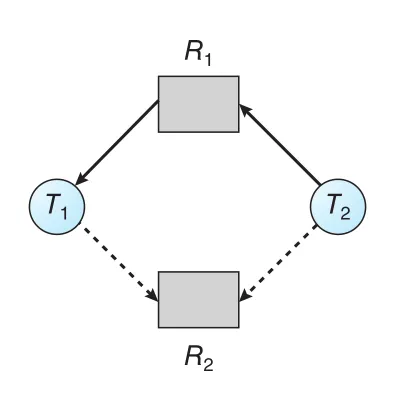
Figure 8.9 · PDF p. 432 · claim edge를 포함한 deadlock avoidance용 resource-allocation graph
Figure 8.9에서 T2가 R2를 요청한다고 하자. R2가 free라도 이를 T2에게 할당하면 graph에 cycle이 생긴다.
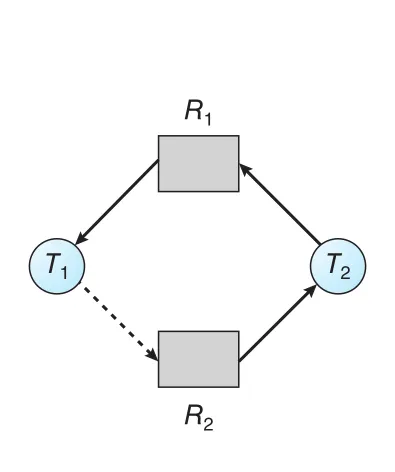
Figure 8.10 · PDF p. 432 · T2에 R2를 할당하면 cycle이 생겨 unsafe state가 되는 graph
Cycle은 unsafe state를 의미한다. 이후 T1이 R2를 요청하고 T2가 R1을 요청하면 deadlock이 발생할 수 있다.
Banker’s Algorithm
Banker's Algorithm은 각 resource type에 multiple instances가 있는 system을 위한 deadlock-avoidance algorithm이다. Resource-allocation-graph algorithm보다 덜 효율적이지만 더 일반적이다. 이름은 bank가 available cash를 할당할 때 모든 customers의 future needs를 만족할 수 있도록 유지해야 한다는 비유에서 왔다.
New thread가 system에 들어올 때 각 resource type에 대해 maximum number of instances를 declare해야 한다. 이 maximum은 system 전체 resource 수를 넘을 수 없다. Thread가 resources를 request하면 system은 그 allocation이 safe state를 유지하는지 판단한다. Safe하면 allocate하고, unsafe하면 다른 thread가 충분한 resources를 release할 때까지 wait시킨다.
Banker’s Algorithm은 threads, resource types에 대해 다음 data structures를 유지한다.
| Data structure | 크기 | 의미 |
|---|---|---|
Available | length vector | 각 resource type의 available instances 수. 이면 가 개 available |
Max | matrix | 각 thread의 maximum demand. 이면 가 를 최대 개 요청 가능 |
Allocation | matrix | 현재 allocation. 이면 가 를 개 holding |
Need | matrix | remaining need. |
Vector 비교는 component-wise로 한다. 는 모든 에 대해 라는 뜻이다.
Safety Algorithm
System이 safe state인지 확인하는 algorithm은 다음이다.
1. Work = Available
Finish[i] = false for all i
2. Find i such that:
Finish[i] == false
Need_i <= Work
If no such i exists, go to step 4.
3. Work = Work + Allocation_i
Finish[i] = true
Go to step 2.
4. If Finish[i] == true for all i,
then the system is in a safe state.이 algorithm은 state가 safe인지 판단하는 데 order of m x n^2 operations가 필요할 수 있다.
Resource-Request Algorithm
Thread 의 request vector를 라고 하자. 이면 가 resource type 의 instances를 요청한다.
Request 처리 흐름은 다음과 같다.
1. If Request_i <= Need_i, continue.
Otherwise error: maximum claim exceeded.
2. If Request_i <= Available, continue.
Otherwise Ti must wait: resources not available.
3. Pretend allocation:
Available = Available - Request_i
Allocation_i = Allocation_i + Request_i
Need_i = Need_i - Request_i
4. Run Safety Algorithm.
If safe, complete allocation.
If unsafe, restore old state and make Ti wait.핵심은 실제로 할당하기 전에 “pretend allocation”을 해 보고 safe state인지 검사한다는 것이다. Resource가 현재 available하더라도 allocation 결과가 unsafe면 grant하지 않는다.
Illustrative Example
Threads -, resource types , , 가 있고 total instances가 , , 이라고 하자. Snapshot은 다음과 같다.
| Thread | Allocation A B C | Max A B C |
|---|---|---|
T0 | 0 1 0 | 7 5 3 |
T1 | 2 0 0 | 3 2 2 |
T2 | 3 0 2 | 9 0 2 |
T3 | 2 1 1 | 2 2 2 |
T4 | 0 0 2 | 4 3 3 |
이고, 은 다음과 같다.
| Thread | Need A B C |
|---|---|
T0 | 7 4 3 |
T1 | 1 2 2 |
T2 | 6 0 0 |
T3 | 0 1 1 |
T4 | 4 3 1 |
이 상태는 safe하다. Safe sequence 가 존재한다.
이 를 요청하면 이므로 현재 resources는 충분하다. Pretend allocation 후에도 safe sequence 가 존재하므로 request를 grant할 수 있다. 반대로 이 상태에서 의 request는 resources가 available하지 않아 grant할 수 없고, 의 request는 resources는 available하지만 resulting state가 unsafe하므로 grant할 수 없다.
8.7 Deadlock Detection
Prevention이나 avoidance를 사용하지 않는 system에서는 deadlock이 발생할 수 있다. 이 경우 system은 두 가지 algorithm을 제공할 수 있다.
- System state를 검사해 deadlock 발생 여부를 결정하는
deadlock detection algorithm - Deadlock이 발생했을 때 system을 복구하는
recovery algorithm
Detection-and-recovery scheme은 공짜가 아니다. Necessary information을 유지하는 runtime cost, detection algorithm 실행 비용, recovery 과정에서 잃는 work와 resources 비용을 모두 고려해야 한다.
Single Instance of Each Resource Type
모든 resource type에 instance가 하나씩만 있다면 wait-for graph를 사용할 수 있다. Wait-for graph는 resource-allocation graph에서 resource nodes를 제거하고, thread-to-thread waiting 관계만 남긴 graph다.
Ti -> Tj edge는 Ti가 필요한 resource를 Tj가 release하기를 기다린다는 뜻이다. Resource-allocation graph에 Ti -> Rq와 Rq -> Tj가 있으면 wait-for graph에는 Ti -> Tj가 생긴다.
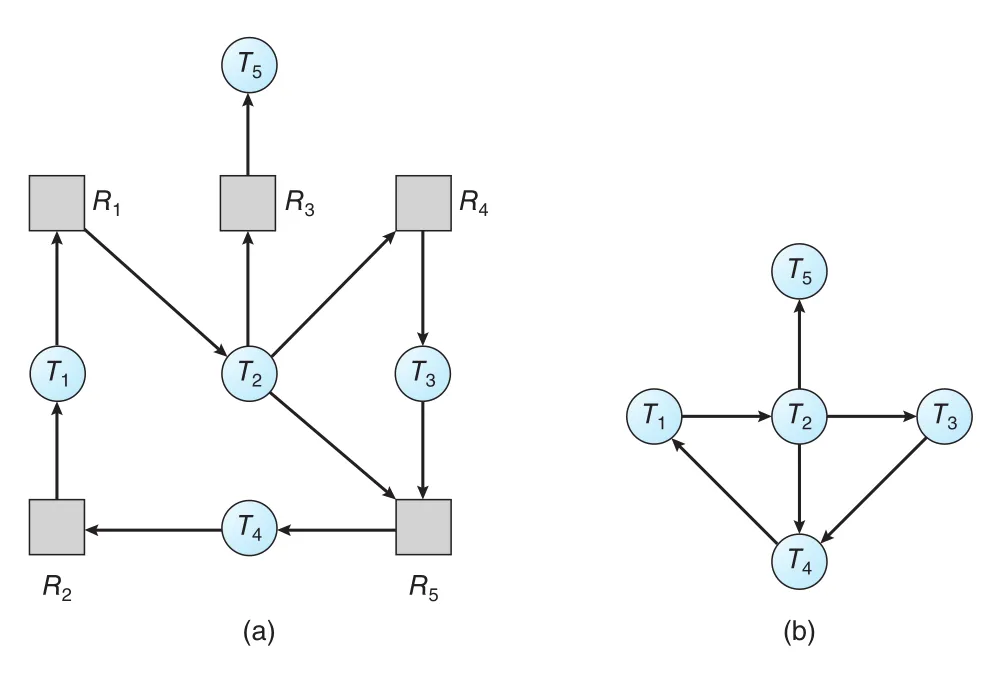
Figure 8.11 · PDF p. 436 · resource-allocation graph에서 resource nodes를 제거해 wait-for graph로 변환한 모습
Single-instance system에서는 wait-for graph에 cycle이 있으면 deadlock이 존재한다. 따라서 system은 wait-for graph를 유지하고 주기적으로 cycle-detection algorithm을 실행한다. Vertices 수가 n일 때 cycle detection은 O(n^2) operations가 필요하다.
Linux user process의 Pthreads mutex deadlock을 찾는 도구로 BCC toolkit의 deadlock detector가 언급된다. 이 tool은 pthread_mutex_lock()과 pthread_mutex_unlock() 호출에 probes를 삽입해 process 내부 mutex wait-for graph를 만들고, cycle을 발견하면 possible deadlock을 보고한다.
Java는 명시적인 deadlock detection API를 제공하지 않지만, thread dump로 running program의 threads 상태와 locking information을 볼 수 있다. Thread dump는 blocked thread가 어떤 lock을 기다리는지도 보여준다. Thread dump 생성 시 JVM은 wait-for graph를 검색해 cycles를 찾고 detected deadlocks를 보고할 수 있다. Command-line에서는 UNIX/Linux/macOS에서 Ctrl-\, Windows에서 Ctrl-Break가 사용된다.
Several Instances of a Resource Type
각 resource type에 여러 instances가 있으면 wait-for graph만으로는 충분하지 않다. 이 경우 Banker’s Algorithm과 비슷한 data structures를 사용하는 detection algorithm을 적용한다.
| Data structure | 크기 | 의미 |
|---|---|---|
Available | length vector | 각 resource type의 available instances 수 |
Allocation | matrix | 각 thread에 currently allocated된 resources |
Request | matrix | 각 thread의 current request. 이면 가 를 개 더 요청 중 |
Rows는 vectors로 취급해 , 라고 쓴다. Detection algorithm은 completion 가능한 threads를 하나씩 가정하며, 완료 가능한 thread가 가진 resources를 회수한다고 보고 나머지를 검사한다.
1. Work = Available
if Allocation_i != 0 then Finish[i] = false
else Finish[i] = true
2. Find i such that:
Finish[i] == false
Request_i <= Work
If no such i exists, go to step 4.
3. Work = Work + Allocation_i
Finish[i] = true
Go to step 2.
4. If Finish[i] == false for some i,
the system is deadlocked.
Each Ti with Finish[i] == false is deadlocked.이 algorithm은 order의 operations가 필요할 수 있다. Banker’s Algorithm의 safety algorithm과 비슷하지만 목적이 다르다. Banker’s Algorithm은 request를 grant하기 전에 unsafe state를 피하려고 검사한다. Detection algorithm은 이미 발생한 deadlock을 찾기 위해 현재 requests를 기준으로 completion 가능한 sequence가 있는지 본다.
Step 3에서 인 thread의 resources를 회수한다고 가정하는 이유는, 그 thread는 현재 deadlock에 참여하지 않았다고 볼 수 있기 때문이다. 이 thread가 더 이상 resources를 요구하지 않고 곧 끝나서 allocated resources를 반환한다고 optimistic하게 가정한다. 이 가정이 틀리면 나중에 deadlock이 발생할 수 있지만, 다음 detection run에서 잡힐 수 있다.
예시로 resource types , , 가 각각 7, 2, 6 instances 있고 threads -가 있다고 하자.
| Thread | Allocation A B C | Request A B C |
|---|---|---|
T0 | 0 1 0 | 0 0 0 |
T1 | 2 0 0 | 2 0 2 |
T2 | 3 0 3 | 0 0 0 |
T3 | 2 1 1 | 1 0 0 |
T4 | 0 0 2 | 0 0 2 |
이다. Detection algorithm을 실행하면 순서로 모든 를 true로 만들 수 있으므로 deadlock은 없다.
그런데 가 resource type 를 하나 더 요청하면 Request에서 이 된다. 이제 의 resources는 회수할 수 있지만, 나머지 requests를 만족할 available resources가 부족하다. 따라서 , , , 가 deadlocked set이 된다.
Detection-Algorithm Usage
Detection algorithm을 언제 실행할지는 두 요소에 달려 있다.
- Deadlock이 얼마나 자주 발생할 가능성이 있는가?
- 발생하면 몇 개 threads가 영향을 받는가?
Deadlock이 자주 발생하면 detection도 자주 해야 한다. Deadlocked threads가 holding한 resources는 deadlock이 깨질 때까지 idle 상태가 되고, deadlock cycle에 참여하는 threads 수가 커질 수 있기 때문이다.
이론적으로는 resource request가 즉시 grant되지 않을 때마다 detection algorithm을 실행할 수 있다. 그러면 deadlocked set뿐 아니라 cycle을 완성한 recent request도 식별하기 쉽다. 하지만 매 request마다 detection을 돌리면 computation overhead가 크다.
더 저렴한 방법은 정해진 interval마다 실행하는 것이다. 예를 들어 한 시간에 한 번 또는 CPU utilization이 40% 아래로 떨어질 때 실행할 수 있다. Deadlock은 system throughput을 망가뜨리고 CPU utilization을 떨어뜨릴 수 있기 때문이다. 다만 arbitrary time에 detection을 실행하면 resource graph에 cycles가 여러 개 있을 수 있어 어떤 thread가 “원인”인지 단정하기 어렵다. 실제로는 cycle 안의 모든 deadlocked threads가 공동 원인이다.
Database systems는 detection-and-recovery 방식이 실제로 잘 맞는 예다. Concurrent transactions는 여러 locks를 잡으므로 deadlock이 가능하다. Database server는 wait-for graph에서 cycles를 주기적으로 찾고, deadlock을 발견하면 victim transaction을 선택해 abort/rollback한다. Victim이 holding한 locks가 release되면 나머지 transactions가 진행할 수 있고, aborted transaction은 다시 issue된다. Victim 선택 기준은 DBMS마다 다르며, 예를 들어 변경 row 수를 줄이는 방향으로 cost를 낮추려 할 수 있다.
8.8 Recovery from Deadlock
Detection algorithm이 deadlock을 발견하면 system은 operator에게 알려 manual recovery를 맡길 수도 있고, 자동으로 recover할 수도 있다. Deadlock을 깨는 기본 방법은 두 가지다.
- Circular wait을 깨기 위해 하나 이상의 threads/processes를 abort한다.
- Deadlocked threads 중 하나 이상에서 resources를 preempt하여 다른 threads에 준다.
Process and Thread Termination
Process/thread termination으로 deadlock을 제거하는 방법은 두 가지다.
| 방법 | 장점 | 비용 |
|---|---|---|
| Abort all deadlocked processes | deadlock cycle을 확실히 깨뜨림 | 모든 partial computation을 버려야 하며 재계산 비용이 큼 |
| Abort one process at a time | 필요한 만큼만 종료할 수 있음 | 하나 abort할 때마다 detection algorithm을 다시 실행해야 함 |
Abort는 단순해 보이지만 쉽지 않다. Process가 file update 중이었다면 file이 inconsistent state로 남을 수 있다. Process가 mutex lock을 holding한 채 shared data를 update 중이었다면 system은 lock을 available로 되돌릴 수는 있어도 shared data integrity를 보장하기 어렵다.
Partial termination을 사용한다면 어떤 process를 abort할지 결정해야 한다. 이는 CPU scheduling처럼 policy decision이며, 기본적으로 cost를 최소화하는 선택이다. Cost factor에는 다음이 포함될 수 있다.
- Process priority
- 지금까지 compute한 시간과 completion까지 남은 예상 시간
- Process가 사용한 resources 수와 types
- Preemption이 쉬운 resources인지 여부
- Completion에 추가로 필요한 resources 수
- Terminate해야 할 processes 수
Resource Preemption
resource preemption으로 recovery하려면 deadlocked processes에서 일부 resources를 차례로 빼앗아 다른 processes에 주어 deadlock cycle을 깬다. 이 접근에는 세 문제가 있다.
| 문제 | 설명 |
|---|---|
selecting a victim | 어떤 process와 resource를 preempt할지 결정해야 한다. Holding resources 수, 지금까지 사용한 시간 등 cost factor를 고려한다. |
rollback | Resource를 빼앗긴 process는 정상 execution을 계속할 수 없으므로 safe state로 rollback 후 restart해야 한다. |
starvation | 같은 process가 계속 victim으로 선택되면 영원히 완료하지 못한다. |
Rollback에서 가장 단순한 방법은 total rollback, 즉 process를 abort하고 restart하는 것이다. Deadlock을 깨는 데 필요한 지점까지만 되돌리는 partial rollback이 더 효율적일 수 있지만, 이를 위해서는 running processes의 state 정보를 더 많이 저장해야 한다.
Starvation 방지를 위해 victim selection에 rollback 횟수를 cost factor로 포함할 수 있다. 같은 process가 계속 victim이 되지 않도록, victim으로 선택될 수 있는 횟수를 작고 finite한 값으로 제한해야 한다.
연결 관계
- Chapter 6의 liveness failure와 semaphore/mutex misuse가 Chapter 8에서 deadlock의 necessary conditions와 graph model로 일반화된다.
- Chapter 7의 dining-philosophers problem은 resource-allocation cycle, deadlock prevention, starvation distinction을 이해하는 대표 예시다.
- Chapter 5의 scheduling은 deadlock을 직접 해결하지는 않지만, livelock과 deadlock이 특정 scheduling circumstances에서만 드러날 수 있음을 설명하는 배경이다.
- Chapter 10 이후 memory/storage resource management에서도 finite resource allocation과 recovery policy가 반복해서 등장한다.
- Database transaction의 deadlock detection/recovery는 OS deadlock 이론이 다른 system domain에 적용되는 예다.
오해하기 쉬운 내용
- Deadlock은 단순히 “느리게 기다리는 상태”가 아니다. Set 안의 모든 threads가 그 set 안의 다른 thread만 발생시킬 수 있는 event를 기다리는 구조적 상태다.
- Resource-allocation graph에 cycle이 있으면 항상 deadlock인 것은 아니다. Resource type에 multiple instances가 있으면 cycle은 necessary but not sufficient condition이다.
- Unsafe state는 deadlock과 같지 않다. Unsafe state는 deadlock으로 갈 수 있는 상태이고, 실제 deadlock은 그중 일부다.
- Deadlock prevention과 avoidance는 다르다. Prevention은 necessary condition을 깨고, avoidance는 사전 정보를 사용해 unsafe state로 들어가지 않게 한다.
- Banker’s Algorithm은 available resource만 보고 grant하지 않는다. Pretend allocation 후 safety algorithm을 통과해야 grant한다.
- Detection algorithm을 자주 실행하면 빨리 찾을 수 있지만 overhead가 크다. 드물게 실행하면 원인 cycle 식별이 어려워질 수 있다.
- Process abort나 resource preemption은 deadlock을 깨도 data consistency와 rollback 비용 문제를 만든다.
- Circular wait prevention을 위한 lock ordering은 ordering을 정하는 것만으로 끝나지 않는다. 모든 code path가 그 ordering을 지켜야 한다.
면접 질문
- Deadlock의 정의를 resource acquisition/release 관점에서 설명하라.
- Deadlock의 네 necessary conditions는 무엇이며, 왜 모두 동시에 필요하다고 보는가?
- Resource type과 resource instance의 차이는 무엇인가?
- Figure 8.1의 Pthreads mutex 예에서 deadlock이 발생하는 interleaving을 설명하라.
- Deadlock과 livelock은 어떻게 다른가?
- Resource-allocation graph에서 request edge와 assignment edge는 각각 무엇을 의미하는가?
- Resource-allocation graph에서 cycle이 deadlock을 의미하는 경우와 그렇지 않은 경우를 구분하라.
- Deadlock을 ignore하는 전략을 대부분의 OS가 사용하는 이유는 무엇인가?
- Deadlock prevention과 deadlock avoidance의 차이는 무엇인가?
- Hold-and-wait condition을 깨는 protocol의 단점은 무엇인가?
- No-preemption condition을 깨는 방식이 mutex lock에는 잘 맞지 않는 이유는 무엇인가?
- Circular wait을 total ordering으로 방지하는 원리를 설명하라.
- Dynamic lock acquisition에서 lock ordering이 깨질 수 있는 예를 설명하라.
- Safe state, unsafe state, deadlocked state의 관계는 무엇인가?
- Resource-allocation-graph avoidance algorithm에서 claim edge는 무엇인가?
- Banker’s Algorithm의
Available,Max,Allocation,Need는 각각 무엇을 나타내는가? - Banker’s Algorithm의 Safety Algorithm은 어떤 방식으로 safe sequence를 찾는가?
- Resource-Request Algorithm에서 pretend allocation 후 unsafe이면 왜 old state를 restore해야 하는가?
- Wait-for graph는 resource-allocation graph에서 어떻게 만들어지는가?
- Multiple-instance deadlock detection algorithm은 Banker’s Algorithm과 어떤 점이 비슷하고 다른가?
- Detection algorithm을 언제 실행할지 결정하는 기준은 무엇인가?
- Deadlock recovery에서 process termination과 resource preemption의 trade-off는 무엇인가?
- Victim selection에서 어떤 cost factors를 고려할 수 있는가?
- Rollback 기반 recovery에서 starvation을 방지하는 방법은 무엇인가?