Chapter 19. Networks and Distributed Systems
- 과목: Operating System
- 기준 교재: Operating System Concepts 10th
- 관련 페이지: PDF pp. 871-907
- 우선순위: 심화
개요
distributed system은 memory나 clock을 공유하지 않는 여러 processors/nodes가 network를 통해 통신하며 하나의 더 큰 system처럼 동작하는 구조다. 각 node는 자기 local memory를 가지고, 다른 node와 resources는 remote로 본다. 이 장은 distributed systems를 가능하게 하는 network 구조, communication protocols, network OS와 distributed OS의 차이, distributed file systems(DFS)의 naming, transparency, caching, consistency 문제를 다룬다.
핵심은 “원격을 어떻게 로컬처럼 안전하고 효율적으로 보이게 할 것인가”다. File, computation, storage, service가 여러 sites에 흩어져 있어도 user와 process는 resource sharing, computation speedup, reliability를 기대한다. 그 대신 naming, failure detection, reconfiguration, transparency, scalability, cache consistency 같은 문제가 OS 설계의 중심으로 올라온다.
핵심 개념
| 개념 | 핵심 의미 |
|---|---|
distributed system | memory/clock을 공유하지 않는 loosely coupled nodes가 communication network로 연결된 system. |
node, site, host, machine | distributed system의 개별 computer를 부르는 용어. 이 장은 location은 site, specific system은 node로 주로 표현한다. |
local, remote | 특정 node 기준으로 자기 resources는 local, 다른 nodes와 그 resources는 remote. |
client-server | server node가 resource/service를 제공하고 client node가 이를 요청하는 구성. |
peer-to-peer(P2P) | fixed server/client 구분 없이 nodes가 equal responsibilities를 공유하는 구성. |
resource sharing | remote files, database, printer, GPU/supercomputer 같은 specialized hardware를 network로 공유하는 목적. |
computation speedup | computation을 subcomputations로 나누어 여러 sites에서 concurrent execution하여 전체 시간을 줄이는 목적. |
load balancing | overloaded site의 requests/jobs를 lighter-loaded sites로 이동·우회하는 방식. |
reliability, redundancy | 일부 sites가 fail해도 hardware/data 중복으로 system operation을 계속하는 성질. |
LAN(Local-Area Network) | single building 또는 adjacent buildings처럼 작은 범위의 high-speed, low-error network. |
WAN(Wide-Area Network) | 국가/전세계처럼 넓은 범위의 network. Routers와 long-distance links로 sites를 연결한다. |
router | traffic을 다른 routers/networks로 directed routing하고 sites 간 information transfer를 담당하는 communication processor. |
DNS(Domain Name System) | human-friendly host name을 numeric host-id/IP address로 resolve하는 distributed naming system. |
name server | 특정 domain/name component에 대한 name-to-address resolution을 제공하는 process/system. |
host name, host-id, <host name, identifier> | remote process를 찾기 위한 host 식별자와 host 내부 process/service 식별자 조합. |
caching | 이미 resolved한 addresses나 remote file data를 local에 저장해 repeated access cost를 줄이는 기법. |
communication protocol | hosts, connections, routing, delivery, reliability 등을 위해 systems가 따르는 rules의 집합. |
OSI model | networking을 physical, data-link, network, transport, session, presentation, application 7 layers로 설명하는 conceptual model. |
TCP/IP model | Internet에서 널리 쓰이는 protocol stack. Application, transport, IP 중심으로 구성된다. |
packet, frame, header, trailer | network message가 layer별 metadata와 함께 작은 전달 단위로 나뉜 형태. |
IP(Internet Protocol) | IP datagrams/packets를 Internet을 통해 routing하는 network-layer protocol. |
MAC address | Ethernet device에 부여되는 data-link layer 주소. LAN 안 device 전달에 사용된다. |
ARP(Address Resolution Protocol) | local Ethernet network에서 IP address를 MAC address로 변환하기 위한 broadcast-based protocol. |
port number | 한 host 안 여러 server/client processes 중 transport packet을 받을 process를 식별하는 번호. |
UDP(User Datagram Protocol) | connectionless, unreliable transport protocol. Port number만 더한 bare-bones IP extension에 가깝다. |
TCP(Transmission Control Protocol) | reliable, connection-oriented transport protocol. ACK, sequence number, retransmission, flow/congestion control을 제공한다. |
network operating system | 사용자가 remote login, file transfer, cloud storage 등으로 remote resources에 명시적으로 접근하는 OS. |
distributed operating system | remote resources를 local resources처럼 접근하게 하고 data/process migration을 OS가 투명하게 관리하는 OS. |
remote login, SSH | encrypted socket connection으로 remote machine에 로그인해 그 machine의 process를 proxy처럼 사용하는 방식. |
FTP, SFTP | remote file transfer를 위해 get/put 등 별도 command set으로 files를 복사하는 방식. |
data migration, computation migration, process migration | data, computation, 또는 process 자체를 sites 사이에서 이동시켜 remote resources를 활용하는 방식. |
fault tolerance | link/host/site/message/storage failure가 있어도 degraded form으로 계속 function하는 능력. |
heartbeat, timeout | sites가 주기적으로 I-am-up/Are-you-up messages를 주고받아 failure를 추정하는 절차. |
reconfiguration, recovery | failure 후 routing/service/coordinator를 조정하고, repaired site/link를 system에 다시 통합하는 절차. |
transparency, user mobility | local/remote resource 차이를 숨기고 사용자가 어느 machine에서든 자기 environment를 사용할 수 있게 하는 성질. |
scalability | service load, users, resources 증가를 graceful하게 수용하는 능력. |
DFS(Distributed File System) | clients, servers, storage devices가 distributed system의 여러 machines에 흩어진 file-service system. |
service, server, client | DFS에서 service는 기능 제공 software entity, server는 단일 machine의 service software, client는 service interface를 호출하는 process. |
metadata server, data server, chunk | cluster-based DFS에서 file metadata를 관리하는 server, file chunks를 저장하는 servers, file의 분할 단위. |
NFS(Network File System) | UNIX 기반에서 흔한 client-server DFS. Stateless server와 remote service 중심 설계가 특징. |
OpenAFS(Andrew File System) | scalability와 location independence를 강조한 client-server DFS. File을 local에 cache하고 close 시 update하는 방식이 특징. |
GFS(Google File System), HDFS(Hadoop Distributed File System) | large data sets와 parallel processing을 위해 chunks, replication, metadata server를 사용하는 cluster-based DFS. |
location transparency, location independence | file name이 physical location을 드러내지 않는 성질과, location이 바뀌어도 file name이 바뀌지 않는 더 강한 성질. |
remote service, RPC | file access request를 server로 보내 server가 access를 수행하고 result를 돌려주는 방식. |
cache-consistency problem | client cache copies와 server master copy를 어떤 semantics로 일치시킬지의 문제. |
write-through, delayed-write, write-back, write-on-close | modified cached data를 server master copy에 반영하는 cache-update policies. |
pNFS, CFS, PFS | parallel NFS, clustered file system, parallel file system. DFS architecture 경계가 흐려지는 예. |
세부 정리
19.1 Advantages of Distributed Systems
Distributed system은 communication network로 연결된 loosely coupled nodes의 집합이다. 특정 node 관점에서는 자기 resources가 local이고, 나머지 nodes와 그 resources는 remote다. Nodes는 microprocessors, personal computers, large general-purpose systems처럼 크기와 역할이 다양할 수 있다.
Nodes의 구성은 크게 세 가지로 볼 수 있다.
| 구성 | 의미 |
|---|---|
client-server | server가 resource/service를 가지고 client가 사용 요청 |
peer-to-peer(P2P) | 모든 nodes가 동등한 책임을 가지며 client와 server 역할을 모두 수행 |
| hybrid | service 성격에 따라 client-server와 P2P 특징을 섞음 |
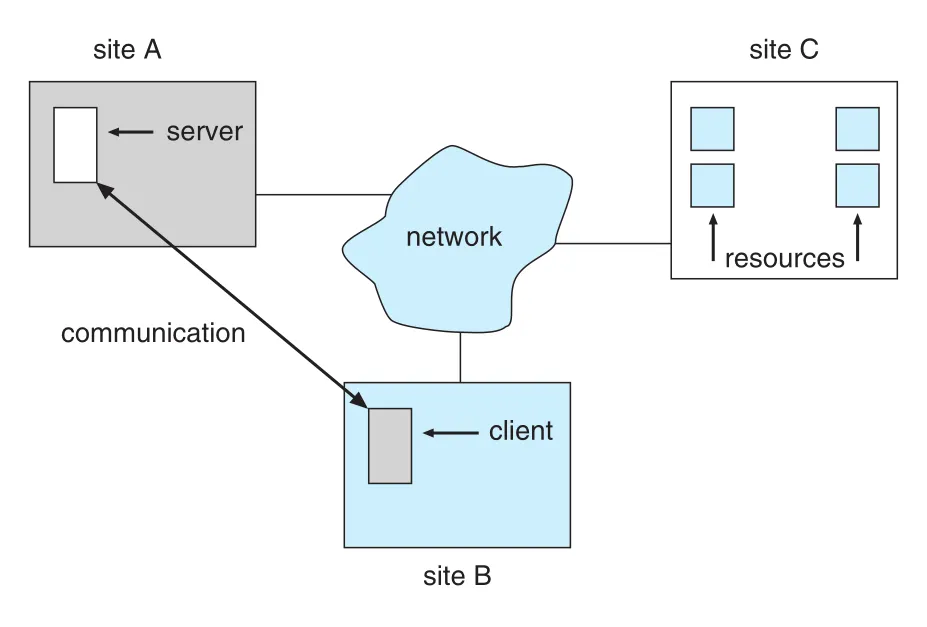
Figure 19.1 · PDF p. 872 · 서로 다른 sites의 client와 server가 network를 통해 resources를 공유하는 구조
Figure 19.1은 distributed system에서 resource가 특정 site에 있어도 다른 site의 client가 network communication으로 접근할 수 있음을 보여 준다. Low level에서는 messages가 systems 사이를 이동하고, 그 위에 file storage, application execution, RPC(remote procedure calls) 같은 higher-level functionality가 쌓인다.
Distributed systems를 만드는 주요 이유는 세 가지다.
19.1.1 Resource Sharing
서로 다른 capabilities를 가진 sites가 연결되면 한 site의 user가 다른 site의 resources를 사용할 수 있다. 예를 들어 site A의 user가 site B의 database를 query하거나, site B의 user가 site A에 있는 file에 접근할 수 있다.
Resource sharing의 대상은 remote files, distributed database, remote printers, specialized hardware devices, supercomputer, GPU(Graphics Processing Unit) 등이다. 핵심은 physical location이 user가 resource를 활용하는 능력을 제한하지 않도록 mechanisms를 제공하는 것이다.
19.1.2 Computation Speedup
어떤 computation이 concurrent subcomputations로 나뉠 수 있다면 distributed system은 각 subcomputation을 여러 sites에 분배해 speedup을 얻을 수 있다. Big data sets를 분석하거나 scientific data를 parallel processing하는 경우 특히 중요하다.
또한 특정 site가 overloaded되면 requests를 lighter-loaded sites로 move/reroute할 수 있다. 이 작업이 load balancing이다. Internet services와 distributed nodes에서는 load balancing이 common design element다.
19.1.3 Reliability
한 site가 fail해도 나머지 sites가 계속 동작하면 distributed system은 더 높은 reliability를 제공한다. 단, 모든 distributed systems가 자동으로 reliable한 것은 아니다. 여러 autonomous installations가 서로 독립적으로 기능하면 한 site failure가 전체를 멈추지 않을 수 있지만, 특정 machine이 web server나 file system처럼 crucial function을 독점하면 single failure가 전체 system operation을 멈출 수 있다.
Reliability에는 redundancy가 필요하다. Hardware와 data가 충분히 중복되어 있어야 일부 nodes가 fail해도 system이 계속 operation할 수 있다. 또한 failure를 감지하고, failed site services 사용을 중단하고, 가능하면 다른 site가 function을 takeover하며, failed site가 repaired/recovered되면 smooth하게 다시 integrate하는 mechanisms가 필요하다.
19.2 Network Structure
Distributed systems를 이해하려면 nodes를 연결하는 network를 알아야 한다. 이 장은 network 자체를 깊게 다루기보다 distributed system 설계에 필요한 basic networking concepts와 challenges를 소개한다.
Network는 크게 LAN(Local-Area Network)과 WAN(Wide-Area Network)으로 나뉜다.
| 구분 | LAN | WAN |
|---|---|---|
| geographic scope | single building, adjacent buildings, home/office | large region, country, worldwide |
| speed/error tendency | high speed, low error rate | 상대적으로 느리고 heterogeneous links |
| common technology | Ethernet, WiFi | routers, leased lines, optical cable, microwave, satellite, Internet |
| design impact | close nodes, shared peripherals, local resource sharing | routing, latency, reliability, large-scale naming이 중요 |
19.2.1 Local-Area Networks
LAN은 여러 small computers가 각자 applications를 실행하면서도 disks/printers/data를 공유해야 하는 필요에서 자연스럽게 등장했다. 보통 office나 home처럼 좁은 geographical area를 커버하므로 communication links가 빠르고 error rate가 낮다.
Typical LAN은 workstations, servers, laptops, tablets, smartphones, shared peripherals, 그리고 다른 networks로 연결해 주는 routers를 포함할 수 있다.
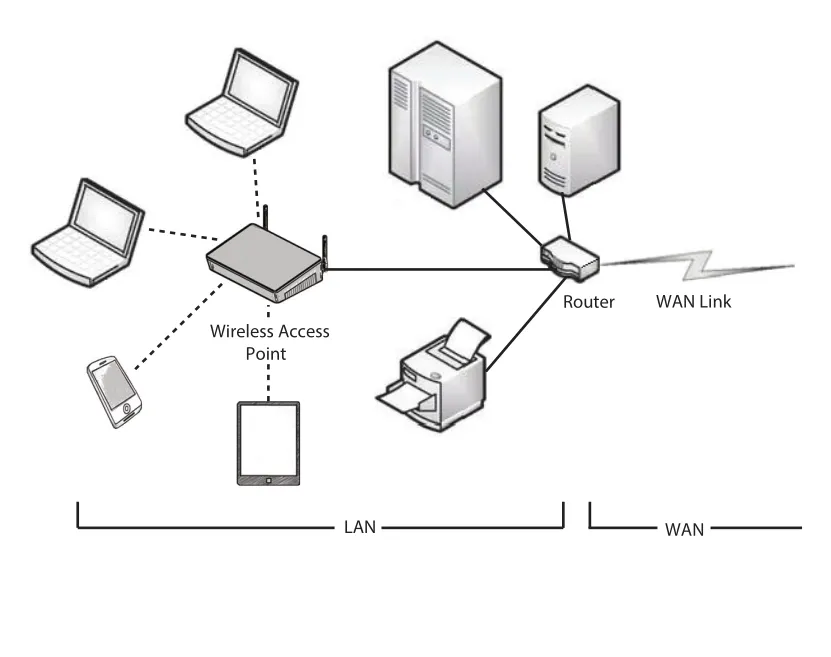
Figure 19.2 · PDF p. 874 · wireless access point, LAN, router, WAN link가 연결된 local-area network 예
Ethernet은 businesses/organizations에서 nonmobile computers와 peripherals를 연결하는 데 흔하다. Coaxial, twisted pair, fiber optic cables를 사용하며, multiaccess bus 구조라 central controller 없이 new hosts를 쉽게 추가할 수 있다. Ethernet protocol은 IEEE 802.3으로 정의된다.
WiFi는 physical cable 없이 hosts의 wireless transmitter/receiver로 network에 참여하게 한다. IEEE 802.11로 정의되며 home, business, public areas, transportation 등에서 널리 쓰인다. 원문은 특정 speed 수치를 제시하지만, 표준과 속도는 계속 바뀌므로 핵심은 wired Ethernet과 wireless WiFi가 LAN을 구성하는 대표 기술이라는 점이다.
19.2.2 Wide-Area Networks
WAN은 geographically dispersed sites 간 communication과 sharing을 위해 등장했다. 초기 WAN의 대표가 ARPANET이고, 이는 worldwide network of networks인 Internet으로 발전했다.
WAN links에는 telephone lines, leased lines, optical cable, microwave links, radio waves, satellite channels 등이 있다. 이 links를 제어하고 traffic을 전달하는 핵심 장치가 routers다.
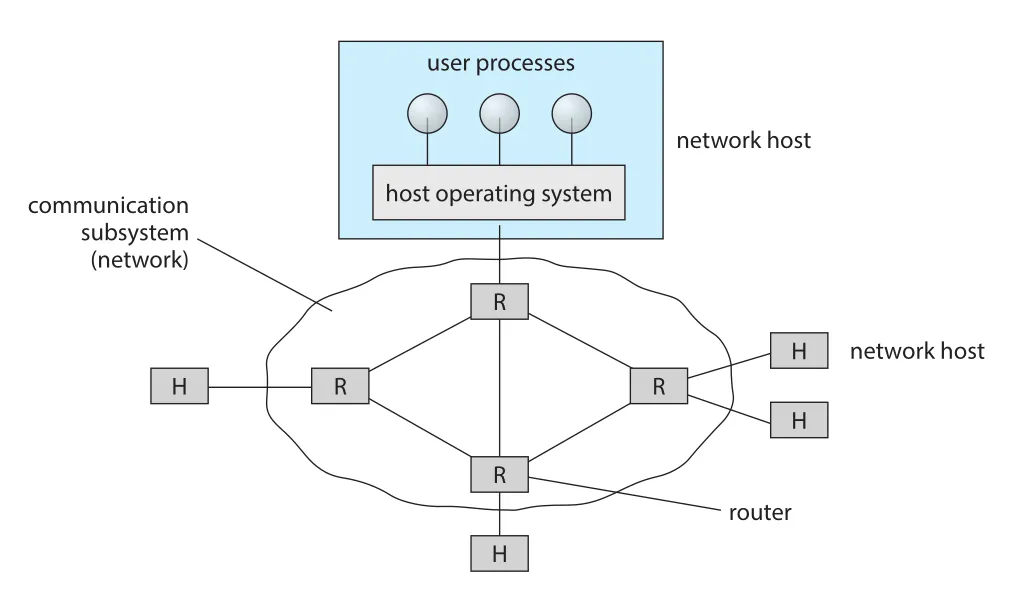
Figure 19.3 · PDF p. 875 · WAN에서 hosts와 routers가 regional/global networks를 통해 traffic을 전달하는 구조
Internet WAN에서는 geographically separate hosts가 통신한다. Hosts는 speed, CPU type, OS가 서로 다를 수 있고, 보통 LAN에 붙어 있으며, LAN은 regional networks와 routers를 통해 Internet에 연결된다. Residences도 telephone/cable/ISP-provided routers를 통해 central services에 연결된다.
WAN은 보통 LAN보다 느리지만 backbone WAN links는 fiber optic cable로 매우 빠를 수 있다. 실제 bottleneck은 backbone보다 local ISP와 home/business를 잇는 access links일 수 있다. Cellular data network처럼 LAN과 WAN의 경계가 흐린 경우도 있다. Cell phone은 tower까지는 radio wave로 접속하고, towers/hubs는 더 WAN-like한 infrastructure로 packets를 destination 쪽으로 route한다.
19.3 Communication Structure
Network의 physical aspect를 본 뒤, 이제 internal communication structure를 본다.
19.3.1 Naming and Name Resolution
Network communication의 첫 문제는 naming이다. Site A의 process가 site B의 process와 정보를 교환하려면 서로를 지정할 수 있어야 한다. Single computer 안에서는 process identifier로 messages를 보낼 수 있지만, networked systems는 memory를 공유하지 않으므로 다른 host의 processes를 처음부터 알 수 없다.
일반적으로 remote process는 <host name, identifier> 쌍으로 식별한다. host name은 network 안에서 unique한 host 이름이고, identifier는 해당 host 내부의 process identifier나 service-specific unique number다. Host name은 user가 기억하기 쉽도록 alphanumeric name을 사용하고, networking hardware는 numeric host-id/IP address를 선호한다.
따라서 host name을 numeric host-id로 resolve하는 mechanism이 필요하다. 이는 Chapter 9의 name-to-address binding과 비슷하다.
| 방식 | 의미 | 문제/장점 |
|---|---|---|
| host file | 모든 host가 reachable hosts의 name/address file을 가짐 | host 추가/삭제 시 모든 files update 필요, scale 불가능 |
| distributed name service | network의 name servers가 information을 나누어 관리 | execution-time binding처럼 필요할 때 retrieve, scale 가능 |
Internet은 DNS(Domain Name System)를 사용한다. DNS는 host naming structure와 name-to-address resolution을 정의한다. eric.cs.yale.edu 같은 multipart name은 specific한 component에서 general한 top-level domain으로 구성된다.
DNS resolution은 보통 reverse component direction으로 진행된다. 예를 들어 system A가 eric.cs.yale.edu와 통신하려면 다음 흐름을 따른다.
| 단계 | 동작 |
|---|---|
| 1 | system A의 library/kernel이 known address의 edu name server에 yale.edu name server 주소를 요청 |
| 2 | edu name server가 yale.edu name server address 반환 |
| 3 | system A가 그 address에 cs.yale.edu에 대해 query |
| 4 | 최종적으로 eric.cs.yale.edu host-id/IP address를 반환 |
이 protocol은 여러 query를 거쳐 비효율적으로 보일 수 있지만, hosts는 resolved IP addresses를 cache하여 반복 lookup을 빠르게 한다. Cache는 name server 이동이나 address 변경을 반영하기 위해 시간이 지나면 refresh되어야 한다. DNS는 중요도가 높으므로 primary server failure에 대비해 secondary/backup name servers를 둔다.
DNS 도입 전에는 모든 hosts가 central site에서 갱신된 host file을 periodic copy해야 했다. DNS는 responsibility를 domain별 name server에 분산한다. Yale University host changes는 yale.edu name server가 관리하면 되고, global central file에 모두 보고할 필요가 없다. Domains는 autonomous subdomains를 포함할 수 있어 책임을 더 분산한다.
19.3.2 Communication Protocols
Communication network 설계의 어려움은 asynchronous operations를 slow/error-prone environment에서 조정해야 한다는 점이다. Systems는 host names, host locating, connection establishment 등에 대해 공통 rules를 가져야 한다. 이 rules의 집합이 protocol이다.
복잡도를 줄이기 위해 network problem은 여러 layers로 나뉜다. 각 layer는 상대 system의 같은 layer와 logical하게 통신하고, 실제 physical data flow는 sender의 upper layer에서 lower layer로 내려간 뒤 network를 지나 receiver의 lower layer에서 upper layer로 올라간다.
OSI(Open Systems Interconnection) model은 networking을 이해하기 위한 7-layer conceptual model이다.
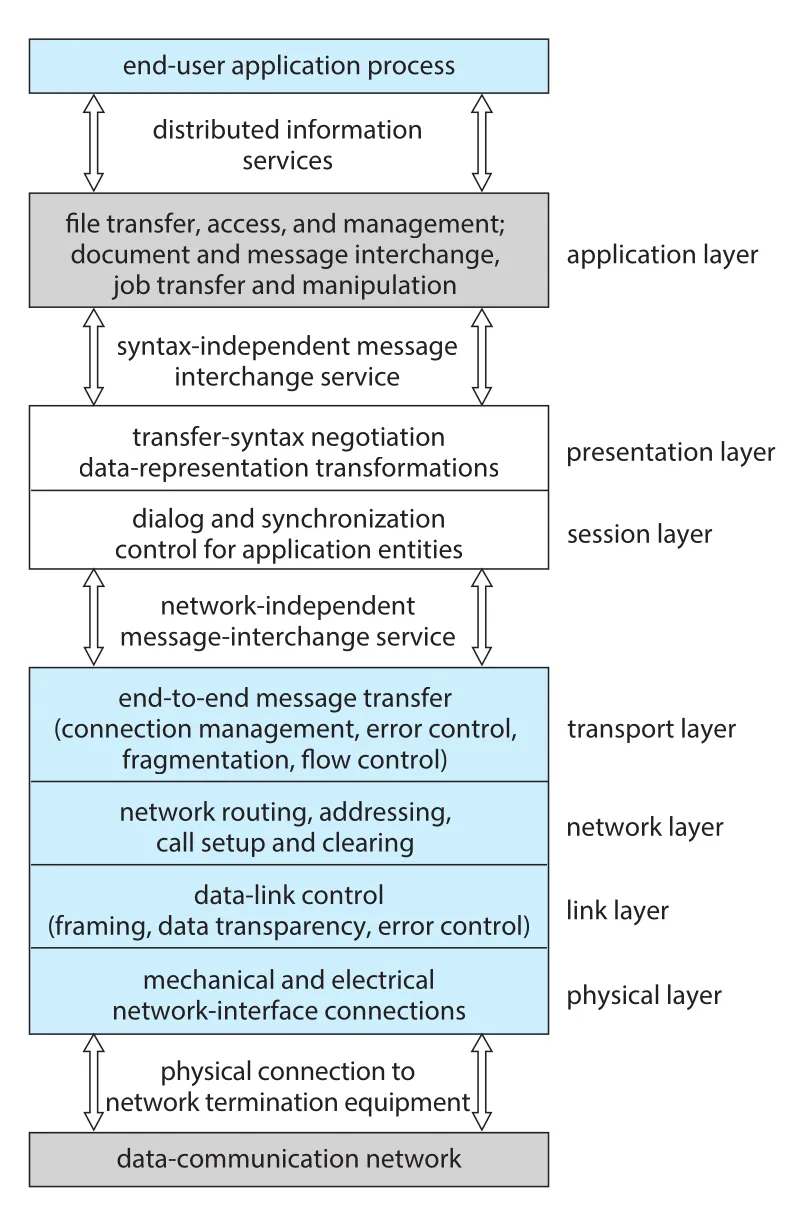
Figure 19.6 · PDF p. 881 · application부터 physical layer까지 OSI protocol stack의 역할 계층
| OSI layer | 핵심 역할 |
|---|---|
Layer 1 physical | bits의 mechanical/electrical transmission. Network device hardware가 binary 0/1 signal을 전달 |
Layer 2 data-link | frames 처리, physical layer error detection/recovery, physical addresses 간 frame 전송 |
Layer 3 network | messages를 packets로 나누고 logical addresses 간 routing 수행. Routers가 이 layer에서 동작 |
Layer 4 transport | nodes 사이 message transfer, packet ordering, flow control, congestion avoidance |
Layer 5 session | process-to-process communication sessions 구현 |
Layer 6 presentation | character conversion, data format 차이, half/full duplex 같은 representation 문제 해결 |
Layer 7 application | file transfer, remote login, electronic mail, distributed database schemas 등 user-facing services |
Layering의 중요한 동작은 encapsulation이다. Message가 내려가면서 각 layer는 receiver의 peer layer가 사용할 header를 추가할 수 있다. Network로 전송될 때는 one or more packets가 되고, receiver 쪽에서는 headers가 해석·제거되며 위로 올라간다.
OSI model은 실제 Internet의 지배 protocol stack은 아니지만 networking logic을 설명하기 좋다. 실제 Internet에서는 TCP/IP model이 널리 쓰인다.
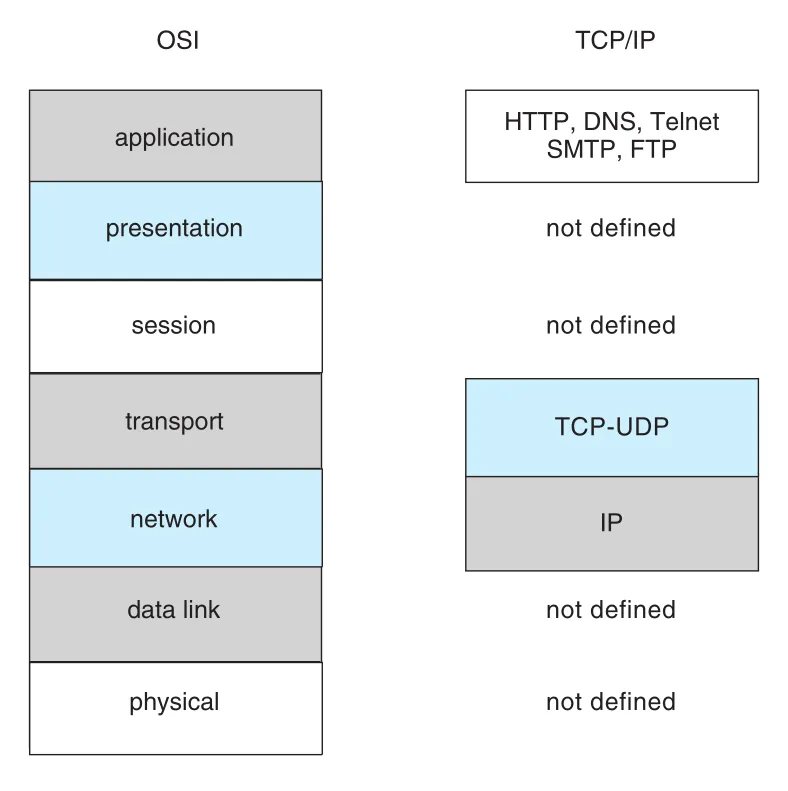
Figure 19.8 · PDF p. 882 · OSI 7 layers와 TCP/IP stack의 application, TCP/UDP, IP 대응 관계
TCP/IP application layer에는 HTTP, FTP, SSH, DNS, SMTP 등이 있다. Transport layer에는 unreliable/connectionless UDP와 reliable/connection-oriented TCP가 있다. IP는 IP datagrams 또는 packets를 Internet을 통해 route한다. TCP/IP는 link/physical layer를 formal하게 지정하지 않으므로 다양한 physical networks 위에서 traffic을 운반할 수 있다.
Modern communication protocol 설계에서는 security가 필수다. Strong authentication은 sender/receiver가 올바른 identity임을 보장하고, encryption은 eavesdropping으로부터 contents를 보호한다. 오래된 protocols는 performance, simplicity, efficiency를 우선해 weak authentication이나 clear text를 쓰는 경우가 많았고, 기존 infrastructure에 security를 나중에 붙이는 것은 어렵고 복잡하다.
19.3.3 TCP/IP Example
TCP/IP network에서 모든 host는 unique한 name과 associated IP address 또는 host-id를 가진다. Host-id는 network number와 host number로 나뉘며, network number를 부여받은 site는 그 안의 host-ids를 할당할 수 있다.
Sending system은 routing table을 보고 packet을 보낼 router를 찾는다. Routing table은 administrator가 manually configure하거나 BGP(Border Gateway Protocol) 같은 routing protocols가 populate할 수 있다. Routers는 host-id의 network part를 보고 source network에서 destination network까지 packet을 전달한다.
LAN 내부에서는 IP address만으로 충분하지 않다. Ethernet device는 unique MAC address를 사용한다. IP address를 MAC address로 바꾸기 위해 ARP(Address Resolution Protocol)를 사용한다.
ARP 흐름은 다음과 같다.
| 단계 | 동작 |
|---|---|
| 1 | sender가 destination IP address를 담은 ARP packet 생성 |
| 2 | local Ethernet network에 broadcast |
| 3 | IP address가 일치하는 host만 response로 자기 MAC address 전송 |
| 4 | sender가 IP-MAC pair를 ARP cache에 저장 |
| 5 | 이후 같은 host로 보낼 때 cache를 사용하고, 오래된 entry는 aging으로 제거 |
Broadcast는 local network의 모든 hosts가 받는 special address를 사용하지만, routers가 다른 networks로 재전송하지 않는다. 따라서 ARP는 local Ethernet network 범위에서 동작한다.
Ethernet packet은 data-link layer의 header/trailer를 포함한다.
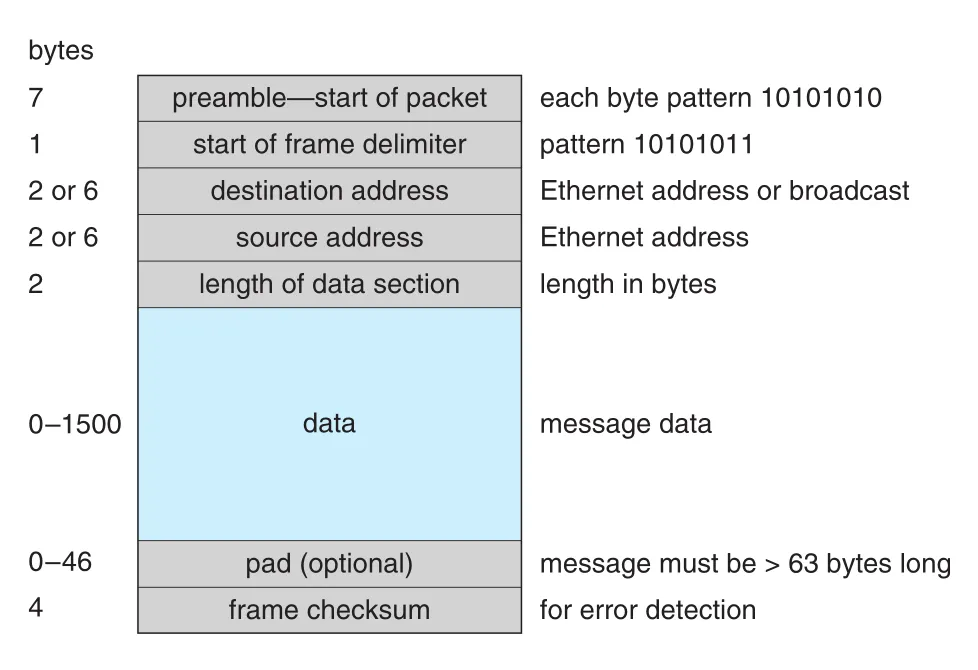
Figure 19.9 · PDF p. 884 · preamble, destination/source address, data, checksum으로 구성된 Ethernet packet 구조
Destination이 same local network에 있으면 sender는 ARP cache에서 MAC address를 찾아 packet을 wire에 올리고, destination Ethernet device가 자기 address를 보고 packet을 읽어 protocol stack 위로 넘긴다. Destination이 다른 network에 있으면 source는 local router로 packet을 보내고, routers가 WAN을 따라 destination network까지 전달한다. Data-link header는 next router의 Ethernet address에 맞춰 hop마다 바뀔 수 있지만, upper-level headers는 destination protocol stack이 처리할 때까지 유지된다.
19.3.4 Transport Protocols UDP and TCP
IP address가 특정 host까지 packet을 전달해도, host 안의 어느 process가 받아야 하는지는 따로 식별해야 한다. Transport protocols인 TCP와 UDP는 port number로 sending/receiving processes를 식별한다. 한 IP address를 가진 host도 port numbers가 다르면 여러 server processes를 동시에 실행할 수 있다. Well-known ports의 예는 FTP 21, SSH 22, SMTP 25, HTTP 80이다.
Transport layer는 process 식별뿐 아니라 packet stream reliability도 제공할 수 있다. UDP와 TCP는 이 지점에서 큰 차이를 보인다.
19.3.4.1 User Datagram Protocol
UDP(User Datagram Protocol)는 unreliable transport protocol이다. UDP header는 source port number, destination port number, length, checksum 네 fields만 가진다. 빠르게 packet을 보낼 수 있지만 lower layers가 delivery를 보장하지 않으므로 packets가 lost되거나 out of order로 도착할 수 있다. Error handling은 application이 직접 해야 한다.
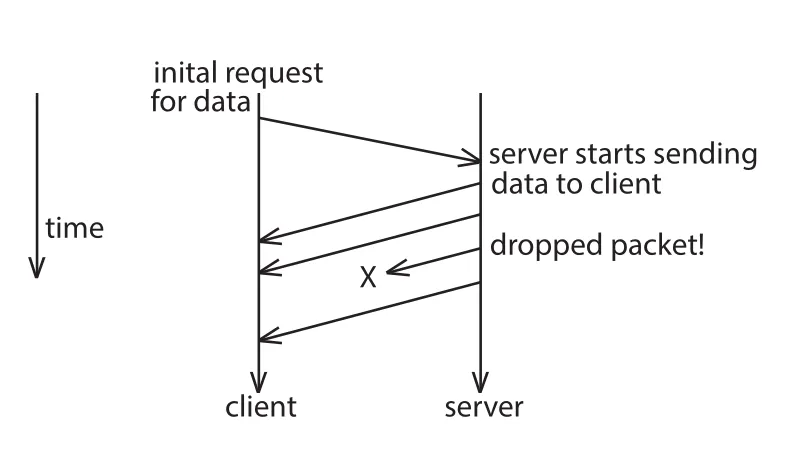
Figure 19.10 · PDF p. 885 · UDP에서 server가 보낸 datagrams 중 하나가 router overload로 drop되는 예
UDP는 connectionless protocol이다. Transmission 시작 전에 connection setup으로 state를 만들지 않고, 끝날 때 teardown도 없다. Client가 요청을 보내면 server가 datagrams를 보내고, 중간에 packet이 drop되면 client는 남은 packets만 사용하거나 application-level logic으로 missing packet을 요청해야 한다.
19.3.4.2 Transmission Control Protocol
TCP(Transmission Control Protocol)는 reliable and connection-oriented transport protocol이다. TCP는 port numbers뿐 아니라, sender process가 receiver process로 in-order, uninterrupted byte stream을 보내는 abstraction을 제공한다.
TCP reliability의 핵심 mechanisms는 다음과 같다.
| mechanism | 역할 |
|---|---|
ACK(acknowledgment) | receiver가 packet 수신을 sender에게 알림 |
| timeout/retransmission | ACK가 timer expiration 전에 오지 않으면 sender가 packet 재전송 |
sequence number | receiver가 packets를 올바른 order로 재정렬하고 missing packets를 감지 |
| connection setup/teardown | three-way handshake와 control packets로 sender/receiver state를 생성·제거 |
| flow control | receiver capacity를 넘지 않도록 sender rate 조정 |
| congestion control | routers/network congestion을 추정해 packet send rate 조정 |
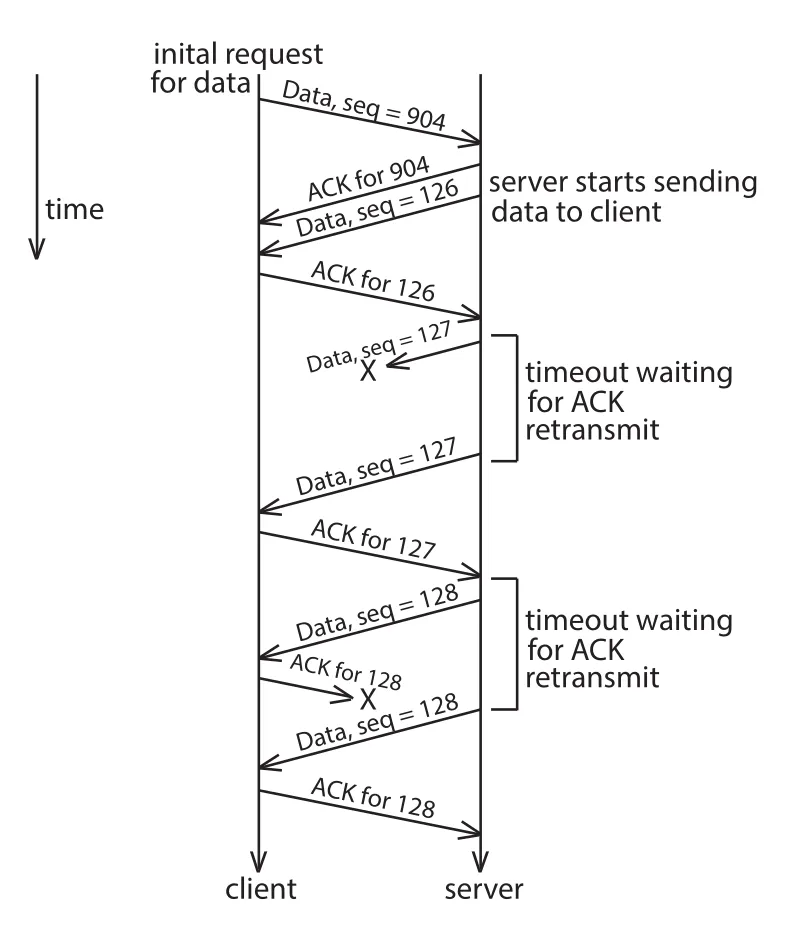
Figure 19.11 · PDF p. 887 · TCP에서 lost data packet과 lost ACK가 timeout, retransmission, duplicate discard로 처리되는 흐름
Figure 19.11의 핵심은 TCP가 loss를 “없애는” 것이 아니라 감지하고 복구한다는 점이다. Data packet 127이 lost되면 receiver는 ACK를 보낼 수 없고, sender는 timeout 후 retransmit한다. Data packet 128의 ACK가 lost되면 sender가 packet 128을 다시 보내고, receiver는 sequence number를 보고 duplicate를 버리면서 ACK를 다시 보낸다.
실제 TCP는 모든 packet마다 ACK를 요구하지 않고, 여러 packets를 한 번에 인정하는 cumulative ACK를 사용할 수 있다. 또한 throughput을 활용하기 위해 여러 data packets를 연속 전송한 뒤 ACK를 기다릴 수 있다. TCP는 UDP보다 느리지만, distributed system이 lost/out-of-order packets를 직접 처리하지 않아도 되게 해 준다.
19.4 Network and Distributed Operating Systems
Network-oriented operating systems는 크게 network operating systems와 distributed operating systems로 나눌 수 있다. Network OS는 구현이 비교적 단순하지만 user가 remote resource를 명시적으로 다루어야 한다. Distributed OS는 더 많은 features를 제공해 user에게는 편리하지만 구현이 더 어렵다.
19.4.1 Network Operating Systems
network operating system은 users가 remote resources에 접근할 수 있는 environment를 제공한다. 접근 방식은 보통 remote machine에 login하거나, remote machine의 data를 local machine으로 transfer하는 형태다. 현대의 general-purpose OS와 Android/iOS 같은 embedded OS도 모두 network OS 기능을 가진다.
19.4.1.1 Remote Login
Remote login은 user가 remote machine에 접속해 그 machine에서 직접 compute하는 기능이다. Internet에서는 SSH(Secure Shell)가 대표적이다. 예를 들어 사용자가 ssh kristen.cs.yale.edu를 실행하면 local machine과 remote computer 사이 encrypted socket connection이 만들어진다.
Connection이 established되면 networking software가 transparent, bidirectional link를 만든다. User가 입력한 characters는 remote machine의 process로 보내지고, 그 process의 output은 다시 user에게 돌아온다. Remote process는 login name/password를 요구하고, 인증이 끝나면 user의 proxy처럼 동작해 remote machine에서 local user처럼 compute할 수 있게 한다.
19.4.1.2 Remote File Transfer
Remote file transfer에서는 각 computer가 자기 local file system을 유지하고, user가 explicit하게 files를 복사한다. 한 site의 user가 다른 site의 file을 쓰려면 FTP(File Transfer Protocol) 또는 SFTP(Secure File Transfer Protocol) 같은 tool로 remote system에 login하고 commands를 실행해야 한다.
대표 commands는 다음과 같다.
| command | 의미 |
|---|---|
get | remote machine의 file을 local machine으로 transfer |
put | local machine의 file을 remote machine으로 transfer |
ls, dir | remote current directory의 files list |
cd | remote current directory 변경 |
이 방식은 communication이 explicit, one-directional, individual하다. 다른 users가 같은 sites 사이에서 file을 옮기려면 각자 별도 commands를 실행해야 한다.
19.4.1.3 Cloud Storage
Cloud storage applications도 기본적으로 remote file transfer를 제공한다. User는 cloud server에 files를 upload/download하고, web link나 sharing mechanism으로 다른 users와 files를 공유한다. Dropbox, Google Drive 같은 services가 예다.
SSH, FTP/SFTP, cloud storage의 공통점은 user가 paradigm을 바꿔야 한다는 점이다. FTP는 normal OS commands와 다른 command set을 요구한다. SSH는 remote system의 command syntax를 알아야 한다. Windows user가 UNIX machine에 SSH로 접속하면 그 session 동안 UNIX commands를 사용해야 한다. Cloud storage는 web browser나 native app의 graphical commands를 익혀야 한다. Distributed OS는 이런 불편을 줄이기 위해 설계된다.
19.4.2 Distributed Operating Systems
distributed operating system에서는 user가 remote resources를 local resources와 같은 방식으로 접근한다. Data와 process migration은 distributed OS가 제어한다. 목표에 따라 data migration, computation migration, process migration 중 하나 또는 조합을 구현할 수 있다.
19.4.2.1 Data Migration
Site A user가 site B에 있는 file을 접근한다고 하자. Data migration에는 두 방식이 있다.
| 방식 | 동작 | trade-off |
|---|---|---|
| entire file transfer | 전체 file을 site A로 가져온 뒤 local access, 수정 후 필요하면 site B로 돌려보냄 | automated FTP처럼 단순하지만 large file에 작은 변경만 있어도 전체 transfer 필요 |
| needed portions transfer | immediate task에 필요한 file portions만 transfer, 나중에 필요한 부분은 추가 transfer | demand paging과 유사, modern distributed systems가 주로 사용 |
Data migration은 단순 data copy가 아니다. Sites가 서로 다른 character-code representations나 integer bit order/size를 쓰면 data translations도 수행해야 한다.
19.4.2.2 Computation Migration
computation migration은 data를 옮기는 대신 computation을 data가 있는 site로 옮기는 방식이다. 여러 large files가 여러 sites에 있고 summary만 필요하다면, files를 모두 local로 가져오는 것보다 각 site에서 computation을 수행하고 results만 돌려받는 편이 효율적이다. 일반적으로 data transfer time이 remote command execution time보다 길면 remote command가 더 낫다.
Computation migration의 구현 방식은 두 가지로 볼 수 있다.
| 방식 | 동작 |
|---|---|
RPC(remote procedure call) | process P가 site A의 predefined procedure를 invoke하고, procedure가 실행 후 result 반환 |
| message + remote process creation | P가 site A에 message를 보내고, site A OS가 task 수행용 process Q를 생성한 뒤 result를 P에게 보냄 |
Process P는 remote process Q와 concurrent하게 실행될 수 있고, 여러 sites에서 여러 remote computations를 동시에 수행할 수 있다. 또한 RPC가 다른 RPC를 부르거나, remote process가 또 다른 site에 message를 보내는 recursive/distributed execution도 가능하다.
19.4.2.3 Process Migration
process migration은 computation migration의 확장이다. Process가 submitted된 site가 아니라 다른 site에서 전체 process 또는 일부 subprocesses가 실행될 수 있다.
Process migration의 이유는 다음과 같다.
| 이유 | 의미 |
|---|---|
load balancing | processes/subprocesses를 sites에 분산해 workload를 고르게 함 |
computation speedup | subprocesses가 여러 sites/nodes에서 concurrent execution |
| hardware preference | GPU 같은 specialized processor에 더 적합한 작업을 그 site로 이동 |
| software preference | 특정 software가 특정 site에만 있거나 software 이동보다 process 이동이 저렴 |
| data access | large data가 있는 server에서 process를 실행해 data transfer를 줄임 |
Process movement에는 두 접근이 있다. 첫째, system이 migration 사실을 client에게 숨긴다. Client program은 migration을 explicit하게 코딩하지 않아도 되며, homogeneous systems에서 load balancing/computation speedup에 적합하다. 둘째, user가 process migration 방식을 명시적으로 지정한다. Hardware/software preference를 만족해야 할 때 쓰인다.
World Wide Web은 distributed computing의 여러 측면을 보여 준다. Web server와 client 사이 data migration이 있고, web client가 server의 database operation을 trigger하면 computation migration이 일어나며, Java applets나 JavaScript scripts는 server에서 client로 code가 이동해 실행된다는 점에서 process migration과 유사한 성격을 가진다.
19.5 Design Issues in Distributed Systems
Distributed system 설계자는 robustness, transparency, scalability를 고려해야 한다. Robustness는 failures를 견디는 능력이고, transparency는 file location과 user mobility를 숨기는 능력이며, scalability는 users/resources/load 증가를 받아들이는 능력이다.
19.5.1 Robustness
Distributed system은 link failure, host failure, site failure, message loss 같은 hardware/communication failures를 겪을 수 있다. Robust system은 failure를 detect하고, computation이 계속되도록 reconfigure하며, failure가 repaired되면 recover해야 한다.
fault tolerance는 일정 수준의 failure를 tolerate하고 계속 function하는 능력이다. Degraded form으로 동작할 수는 있지만, degradation은 failure 정도에 proportional해야 한다. Component 하나가 fail했다고 전체 system이 멈추면 fault tolerant하다고 보기 어렵다.
Fault tolerance는 구현 비용이 크다. Network layer에서는 redundant communication paths, switches, routers가 필요하고, storage failure에 대비하려면 redundant hardware components나 RAID 같은 mechanism이 필요하다.
19.5.1.1 Failure Detection
Shared memory가 없는 environment에서는 link failure, site failure, host failure, message loss를 명확히 구분하기 어렵다. 보통은 “어떤 failure가 발생했다”는 사실만 알 수 있다.
대표 detection 방식은 heartbeat다. Sites A와 B가 direct physical link를 가진다면 fixed intervals마다 서로 I-am-up message를 보낸다. Site A가 predetermined time 안에 B의 message를 받지 못하면 B가 down되었거나, A-B link가 fail했거나, message가 lost되었다고 추정한다.
Site A는 더 기다리거나 Are-you-up? message를 보낼 수 있다. 그래도 reply가 없으면 procedure를 반복하지만, 안전하게 결론낼 수 있는 것은 “failure가 발생했다”는 것뿐이다. 다른 route가 있으면 A는 B에 alternative path로 Are-you-up?을 보낼 수 있고, B가 reply하면 B는 살아 있으며 direct link가 문제라고 판단할 수 있다. 그러나 timeout이 발생하면 B down, direct link down, alternative path down, message loss 중 무엇인지 확정할 수 없다.
19.5.1.2 Reconfiguration
Failure가 감지되면 system은 normal operation을 계속하기 위해 reconfigure해야 한다.
| failure 추정 | reconfiguration 필요 |
|---|---|
| direct link A-B failed | 모든 sites에 broadcast하여 routing tables update |
| site failed/unreachable | 모든 sites가 failed site services를 더 이상 사용하지 않도록 notify |
| central coordinator failed | deadlock detection, mutual exclusion 같은 activity를 위해 new coordinator election |
주의점은 network partition이다. Site가 실제로 failed된 것이 아니라 unreachable한 것뿐이면, partitions마다 coordinator가 생길 수 있다. Mutual exclusion coordinator가 partition마다 존재하면 두 processes가 동시에 critical sections에 들어가는 conflicting actions가 발생할 수 있다.
19.5.1.3 Recovery from Failure
Failed link나 site가 repaired되면 system에 graceful하게 다시 integrate해야 한다. Link A-B가 repair되면 A와 B가 이를 알아야 하며, heartbeat procedure를 계속 반복하면 repair 상태를 detect할 수 있다.
Site B가 failed 후 recover되면 다른 sites에 자신이 up again임을 notify해야 한다. 이후 local tables를 update하기 위해 routing table information, down sites list, undelivered messages, unexecuted transactions의 transaction log, mail 등을 받을 수 있다. Site가 실제로 fail한 것이 아니라 temporarily unreachable했던 경우에도 이런 정보 동기화가 필요하다.
19.5.2 Transparency
Distributed system의 중요한 목표는 users에게 multiple processors와 storage devices를 숨기는 것이다. 이상적인 transparent distributed system은 conventional centralized system처럼 보인다. User interface는 local resources와 remote resources를 구분하지 않아야 하며, user가 remote resource를 local처럼 접근하면 system이 location과 interaction을 알아서 처리해야 한다.
Transparency의 또 다른 측면은 user mobility다. User가 특정 machine에 묶이지 않고 system의 어떤 machine에 login해도 자기 environment를 사용할 수 있어야 한다. 이를 위해 user home directory 같은 environment를 login 위치로 가져오거나, LDAP 같은 protocol로 local/remote/mobile users authentication을 제공하고, desktop virtualization으로 remote facilities의 desktop session을 보여 줄 수 있다.
19.5.3 Scalability
scalability는 service load 증가에 system이 적응하는 능력이다. System resources는 bounded되어 있고, load가 증가하면 saturation될 수 있다. File system 관점에서는 server CPU utilization이 높아지거나 disk I/O requests가 I/O subsystem을 압도하면 saturation이 발생한다.
Scalable system은 nonscalable system보다 load 증가에 graceful하게 반응한다. Performance degradation이 더 완만하고, saturated state에 더 늦게 도달한다. 하지만 어떤 설계도 무한히 증가하는 load를 받아들일 수는 없다. New resources를 추가하면 문제를 해결할 수 있지만, network congestion이나 service load 증가 같은 indirect load를 유발할 수 있다.
Distributed system에서는 machines 추가나 networks interconnection이 흔하므로 graceful scale-up이 특히 중요하다. Scalable design은 high service load를 견디고, user community growth를 수용하며, added resources를 simple하게 integrate할 수 있어야 한다.
Scalability는 fault tolerance와도 연결된다. Heavily loaded component는 faulty component처럼 마비될 수 있고, failed component의 load를 backup으로 옮기면 backup이 saturate될 수 있다. 따라서 spare resources는 reliability와 peak load handling 모두에 필수다. Multiple resources는 fault tolerance와 scalability의 잠재력을 제공하지만, control/data distribution 설계가 부적절하면 그 잠재력이 사라진다.
Scalability는 storage efficiency와도 연결된다. Cloud storage providers는 compression이나 deduplication으로 storage 사용량을 줄일 수 있다. Compression은 lossless compression으로 file size를 줄이고, deduplication은 system 전체에서 redundant data를 제거해 동일 data instance를 하나만 저장한다. File level 또는 block level에서 수행할 수 있고 함께 사용할 수도 있다. Distributed system에 자동으로 내장하면 user complexity 없이 storage space와 network communication cost를 줄일 수 있다.
19.6 Distributed File Systems
DFS(Distributed File System)는 distributed computing의 중요한 응용이다. Web이 대표 distributed system이지만, files를 여러 machines에 흩어 놓고도 centralized file system처럼 쓰게 만드는 DFS는 OS 관점에서 특히 중요하다.
DFS 용어는 다음과 같이 구분한다.
| 용어 | 의미 |
|---|---|
service | one or more machines에서 실행되며 client에게 특정 function을 제공하는 software entity |
server | single machine에서 실행되는 service software |
client | service를 client interface의 operations로 invoke하는 process |
| client interface | create/delete/read/write 같은 primitive file operations |
| intermachine interface | 실제 cross-machine interaction을 위한 lower-level interface |
DFS는 clients, servers, storage devices가 distributed system의 machines에 흩어진 file system이다. Service activity는 network를 건너 수행되고, single centralized repository 대신 multiple independent storage devices를 가질 수 있다. 어떤 구성에서는 servers가 dedicated machines이고, 다른 구성에서는 한 machine이 server와 client를 동시에 할 수 있다.
Ideal DFS는 clients에게 conventional, centralized file system처럼 보여야 한다. Client interface는 local files와 remote files를 구별하지 않아야 하고, DFS가 file location과 data transport를 처리해야 한다. Performance도 transparency의 한 차원이다. Ideal DFS는 remote access overhead가 있어도 conventional file system과 비슷한 response time을 제공해야 한다.
DFS architecture는 목표에 따라 달라진다.
| DFS model | 주목표 | 대표 예 |
|---|---|---|
| client-server DFS | one or more clients가 local처럼 transparent file sharing | NFS, OpenAFS |
| cluster-based DFS | large data sets, high availability, scalability, parallel processing | GFS, HDFS |
19.6.1 The Client-Server DFS Model
Client-server DFS에서 server는 attached storage에 files와 metadata를 저장한다. Clients는 network를 통해 server에 연결되고, NFS 같은 protocol로 files에 접근한다. Server는 authentication, permissions checking, file delivery를 수행한다. Client가 file을 수정하면 master copy를 가진 server에 changes를 전달해야 하며, client/server versions는 network traffic과 server workload를 최소화하면서 consistent해야 한다.
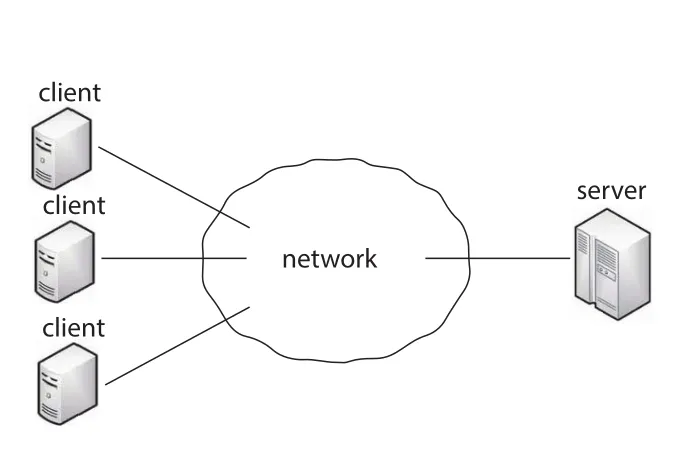
Figure 19.12 · PDF p. 896 · 여러 clients가 network를 통해 file server에 접근하는 client-server DFS 구조
NFS(Network File System)는 Sun Microsystems가 open protocol로 개발했고, early adoption을 촉진했다. NFS의 핵심 목표는 server failure에 대한 simple and fast crash recovery였다. 이를 위해 NFS server는 stateless로 설계되었다. 어떤 client가 어떤 file을 access하는지, open file descriptors나 file pointers 같은 state를 server가 추적하지 않는다.
Stateless server에서는 client file operation이 server crash 후 다시 보내져도 같은 result를 낼 수 있어야 한다. 이를 idempotent operation이라고 한다. Read operation의 경우 file pointer 같은 state는 client가 유지하므로, server가 crash 후 복구되면 client가 operation을 다시 issue할 수 있다.
OpenAFS(Andrew File System)는 scalability에 초점을 맞췄다. Server가 최대한 많은 clients를 지원하려면 server requests와 traffic을 줄여야 한다. Client가 file을 요청하면 file contents를 server에서 download해 client local storage에 저장하고, file이 close될 때 updates를 server로 보낸다. 새 version은 file open 시 client로 전달된다. 반면 NFS는 client가 file을 사용하는 동안 block read/write requests를 server로 자주 보내는 chatty한 방식이다.
Client-server DFS는 local file systems 위에서 동작한다. Server disk partition을 NFS file system으로 format하는 것이 아니라 ext4 같은 local file system으로 format하고, shared directories를 DFS로 export한다. Client는 exported directories를 자기 file-system tree에 attach한다. 이 분리는 DFS가 distributed tasks에 집중하게 한다.
단점도 명확하다. Server가 crash하면 single point of failure가 될 수 있고, server가 data와 metadata requests의 bottleneck이 된다. Clustering과 redundant components로 failover를 구현할 수 있지만, scalability와 bandwidth 문제는 계속 남는다.
19.6.2 The Cluster-Based DFS Model
Data 양, I/O workload, processing이 커지면 DFS는 fault-tolerant하고 scalable해야 한다. Large bottlenecks를 허용할 수 없고, component failures는 예외가 아니라 정상적으로 예상해야 한다. 이 요구에서 cluster-based DFS가 등장했다.
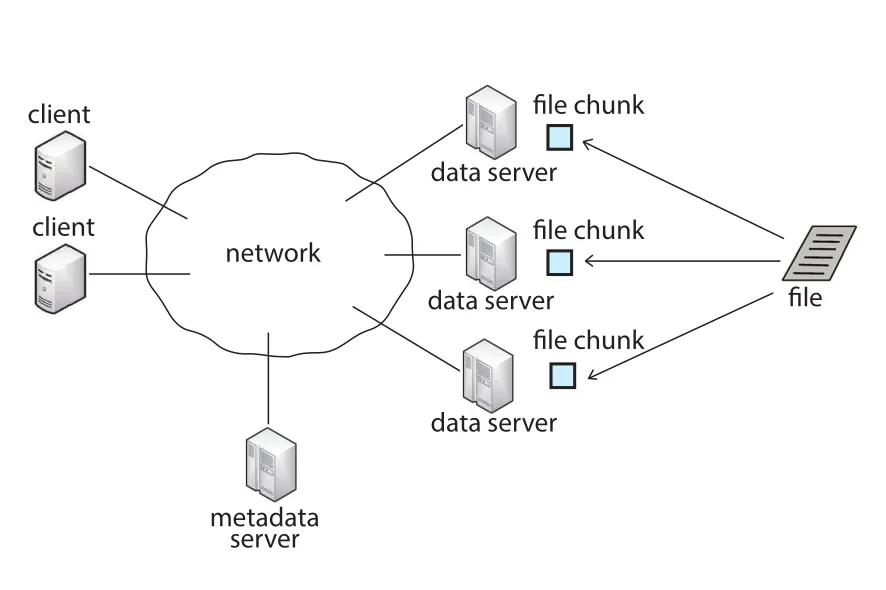
Figure 19.13 · PDF p. 898 · metadata server가 file-to-chunk mapping을 관리하고 여러 data servers가 replicated chunks를 저장하는 cluster-based DFS 구조
GFS와 HDFS의 기본 model은 metadata server와 여러 data servers다. Metadata server는 어떤 data servers가 어떤 file chunks를 가지고 있는지 mapping하고, directory/file hierarchy도 관리한다. File chunks는 data servers에 저장되고, component failure와 faster access를 위해 여러 copies로 replicated된다.
File access 흐름은 다음과 같다.
| 단계 | 동작 |
|---|---|
| 1 | client가 metadata server에 file access 요청 |
| 2 | metadata server가 requested file chunks를 가진 data servers identities 반환 |
| 3 | client가 가까운 data server 또는 여러 data servers에 직접 접근 |
| 4 | file chunks가 다른 data servers에 있으면 parallel read/write 가능 |
| 5 | metadata server는 chunk redistribution과 balancing도 담당 |
이 구조는 metadata server를 덜 bottleneck으로 만든다. Client가 metadata server를 한 번만 contact하고 이후 data servers와 직접 통신할 수 있기 때문이다.
GFS 설계는 네 관찰에 기반했다.
| 관찰 | 설계 의미 |
|---|---|
| hardware failures are normal | replication과 failure recovery를 기본 전제로 설계 |
| files are very large | large chunks와 parallel access가 중요 |
| 대부분 writes는 append | overwrite보다 append-oriented workload 최적화 |
| application/API redesign 가능 | POSIX 호환보다 flexibility와 scalability를 선택 |
GFS는 own API를 export하고 applications가 그 API에 맞게 programmed되도록 요구한다. 이후 MapReduce가 GFS 위에 올라가 large-scale parallel computation을 쉽게 했고, HDFS와 Hadoop framework는 이 흐름을 open-source ecosystem으로 확장했다.
19.7 DFS Naming and Transparency
Naming은 logical objects와 physical objects 사이 mapping이다. User는 textual file name을 다루지만, system은 lower-level numerical identifier를 통해 disk blocks를 찾는다. Conventional file system에서는 naming mapping 범위가 disk address지만, DFS에서는 “어느 machine의 어느 disk인가”가 추가된다.
Transparent DFS는 network location을 숨긴다. 더 나아가 file replication까지 추상화하면 file name이 replicas의 locations set으로 mapping될 수 있지만, user는 multiple copies 존재와 위치를 알 필요가 없다.
19.7.1 Naming Structures
DFS naming에서는 location transparency와 location independence를 구분해야 한다.
| 성질 | 의미 | 강도 |
|---|---|---|
location transparency | file name이 physical storage location을 드러내지 않음 | 약함 |
location independence | file physical location이 바뀌어도 file name이 바뀌지 않음 | 더 강함 |
Location-independent naming은 dynamic mapping이다. 같은 file name이 시간에 따라 다른 locations로 mapping될 수 있기 때문이다. 따라서 location independence는 location transparency보다 강한 성질이다.
대부분 DFS는 user-level names에 대해 static location-transparent mapping을 제공한다. 일부 system은 file migration을 지원해 location independence를 제공한다. OpenAFS는 location independence와 file mobility를 지원한다. HDFS도 file migration을 포함하지만 POSIX standard를 따르지 않아 implementation/interface flexibility를 얻는다. HDFS는 data location을 추적하지만 clients에게 숨기며, 이 dynamic location transparency로 underlying mechanism이 self-tune할 수 있다.
Location independence의 장점은 data를 location에서 분리한다는 점이다. File name은 file contents라는 중요한 attribute를 나타내야지 storage location을 나타내는 데 묶이면 안 된다. Location-independent file은 특정 storage location에 붙어 있지 않은 logical data container처럼 볼 수 있다.
Diskless clients도 이 맥락에서 이해할 수 있다. Client가 disk 없이 server에 모든 files, 심지어 OS kernel까지 의존하려면 boot sequence에는 특별한 protocol이 필요하다. Client는 kernel이 없으므로 DFS code를 사용할 수 없고, ROM에 저장된 boot protocol로 networking을 enable한 뒤 fixed location에서 kernel/boot code를 가져와야 한다. 장점은 client cost와 OS upgrade 관리 부담이 줄어드는 것이고, 단점은 boot protocol 복잡도와 network 사용으로 인한 performance loss다.
19.7.2 Naming Schemes
DFS naming schemes는 세 가지가 대표적이다.
| naming scheme | 의미 | transparency/independence |
|---|---|---|
host:local-name | host name과 local UNIX-like path 조합으로 system-wide unique name 생성 | location transparent도 independent도 아님 |
| NFS-style mount | remote directories를 local directories에 attach하여 coherent directory tree처럼 보이게 함 | 제한적 location transparency |
| single global namespace | system 전체 files에 하나의 global name structure 제공 | 더 uniform한 transparency, OpenAFS 예 |
NFS-style structure는 versatile하지만 administrative complexity가 크다. Remote directory를 local tree 어디든 붙일 수 있어 hierarchy가 highly unstructured해질 수 있고, server unavailable 시 여러 machines의 arbitrary directories가 unavailable해질 수 있다. 또한 어떤 client가 어떤 directory를 attach할 수 있는지 별도 accreditation mechanism이 필요해, 같은 user라도 client machine에 따라 access 가능 여부가 달라질 수 있다.
19.7.3 Implementation Techniques
Transparent naming 구현에는 file name을 location으로 mapping하는 mechanism이 필요하다. Mapping을 manageable하게 하려면 single-file 단위가 아니라 component units 단위로 files를 aggregate해야 한다. UNIX-like systems는 hierarchical directory tree로 name-to-location mapping과 recursive file aggregation을 제공한다.
Mapping information의 availability를 높이려면 replication, local caching 또는 둘 다 사용할 수 있다. 하지만 location independence에서는 mapping이 시간에 따라 변하므로, mapping replication을 consistent하게 update하기 어렵다.
해결책은 low-level, location-independent file identifiers를 도입하는 것이다. OpenAFS가 이 접근을 사용한다. Textual file name은 component unit을 나타내는 lower-level file identifier로 mapping되고, 이 identifier는 location independent하므로 component unit migration으로 invalidated되지 않는다. 대신 두 번째 mapping level이 필요하다. Component unit identifiers를 actual locations로 mapping하는 table은 consistent하게 update되어야 한다.
Structured names는 low-level identifiers의 흔한 구현 방식이다. Bit string이 component unit identifier와 unit 내부 file identifier 등 여러 parts로 구성된다. Uniqueness를 유지하려면 사용 중인 name을 재사용하지 않거나, 충분히 많은 bits를 추가하거나, timestamp를 part로 사용할 수 있다.
19.8 Remote File Access
Naming scheme으로 remote file server를 찾은 뒤에는 actual data transfer가 필요하다. 대표 방식은 remote service와 caching이다.
Remote service는 access requests를 server에 보내고, server machine이 access를 수행한 뒤 results를 client에게 돌려주는 방식이다. RPC paradigm이 대표 구현이다. Conventional file system에서 access마다 disk I/O를 하는 것과 비슷하게, DFS remote service는 access마다 network/server interaction이 필요하다.
Performance를 위해 DFS는 caching을 사용한다. Conventional file system의 cache는 disk I/O를 줄이기 위한 것이지만, DFS cache는 disk I/O와 network traffic을 모두 줄이려는 목적을 가진다.
19.8.1 Basic Caching Scheme
Caching의 기본 원리는 필요한 data가 local cache에 없으면 server에서 copy를 가져오고, 이후 accesses는 cached copy에서 수행하는 것이다. Recently accessed disk blocks를 cache에 유지하면 repeated accesses를 network 없이 local에서 처리할 수 있다. Cache size는 LRU(least-recently-used) 같은 replacement policy로 bounded하게 유지한다.
DFS cache는 demand-paged virtual memory와 비슷하다. 다만 backing store가 local disk가 아니라 remote server인 경우가 많다. 그래서 DFS caching을 network virtual memory처럼 볼 수 있다.
Caching granularity는 file blocks부터 entire file까지 다양하다. 보통 single access에 필요한 것보다 더 많은 data를 cache해 다음 accesses를 local에서 처리하려 한다. 이는 disk read-ahead와 유사하다.
| caching unit | 장점 | 단점 |
|---|---|---|
| small block | miss penalty 작고 consistency 범위 작음 | hit ratio 낮을 수 있음 |
| large chunk/file | hit ratio 증가, sequential/locality workload에 유리 | miss마다 큰 transfer, consistency problem 증가 |
OpenAFS는 64 KB large chunks를 cache한다. 다른 systems는 client demand에 따라 individual blocks를 cache할 수 있다. Network transfer unit이 Ethernet packet 약 1.5 KB 수준이면, 큰 cached data unit은 delivery를 위해 disassemble/reassemble되어야 한다.
19.8.2 Cache Location
Cache는 disk 또는 main memory에 둘 수 있다.
| cache location | 장점 | 단점 |
|---|---|---|
| disk cache | crash 후에도 cached data가 남아 recovery 시 다시 fetch할 필요가 적음 | memory보다 느림, local disk 필요 |
| main-memory cache | diskless workstation 가능, access 빠름, server/user cache mechanism 통합 가능 | volatile memory라 crash 시 modified cached data 손실 가능 |
NFS는 remote service 기반에 client/server-side memory caching을 더한 hybrid로 볼 수 있다. NFS protocol과 대부분 implementations는 disk caching을 제공하지 않지만, OpenAFS는 disk caching을 제공한다.
19.8.3 Cache-Update Policy
Modified cached data blocks를 server master copy에 언제 반영할지는 performance와 reliability에 큰 영향을 준다.
| policy | 동작 | 장점 | 단점 |
|---|---|---|---|
write-through | cache에 쓰는 즉시 server disk까지 write | client crash 시 data loss 적음 | 모든 write가 server round trip/disk write를 기다려 poor write performance |
delayed-write / write-back | cache에 먼저 쓰고 나중에 server로 write | write latency 낮고 overwritten data는 마지막 update만 write | client crash 시 unwritten data loss |
| flush-on-eviction | cache에서 block을 eject하기 직전에 server로 write | performance 좋음 | block이 오래 cache에 남아 master copy가 오래 stale 가능 |
| periodic flush | 정기적으로 modified blocks를 scan/write | write-through와 pure delayed-write 사이 절충 | scan interval에 따라 reliability/performance trade-off |
write-on-close | file close 시 server로 write | long-open/frequently modified files에 network traffic 감소 | close process가 write 완료를 기다림 |
NFS는 file data에 대해 periodic flush 계열을 사용하지만, flush로 server에 write가 issue되면 server disk에 도달해야 complete로 본다. Metadata changes(directory data, file-attribute data)는 synchronously server로 issue해 crash 시 file/directory structure corruption을 줄인다. OpenAFS는 write-on-close policy를 사용한다.
19.8.4 Consistency
Client는 local cached copy가 server master copy와 consistent한지 판단해야 한다. Out-of-date라면 up-to-date copy를 다시 cache한 뒤 access해야 한다. Validity check approaches는 두 가지다.
| approach | 동작 | trade-off |
|---|---|---|
| client-initiated | client가 server에 local data와 master copy consistency를 확인 | check frequency가 semantics와 cost를 결정. 매 access마다 check하면 느리고, open 때만 check하면 stale risk 증가 |
| server-initiated | server가 client별 cached files/parts를 기록하고 potential inconsistency 시 반응 | server state 관리 필요. Conflicting opens 감지 시 caching disable하고 remote-service mode로 전환 가능 |
Cluster-based DFS에서는 consistency가 더 복잡하다. Metadata server와 여러 data servers, replicated chunks가 있기 때문이다. HDFS는 append-only writes와 single file writer를 허용해 consistency를 단순화한다. GFS는 random writes와 concurrent writers를 허용하므로 write consistency guarantees가 더 복잡해진다.
19.9 Final Thoughts on Distributed File Systems
DFS의 client-server architecture와 cluster-based architecture 사이 경계는 흐려지고 있다. pNFS(parallel NFS)처럼 NFS Version 4.1에 parallel NFS protocol이 포함되었지만 adoption은 느렸다.
GFS, HDFS 같은 large-scale DFS는 non-POSIX API를 export하므로 NFS/OpenAFS처럼 regular user machines에 directories를 transparent하게 mount하는 방식과 다르다. 이런 DFS에 접근하려면 client code가 필요하다. 그래서 cluster-based DFS의 scalability를 활용하면서도 native OS utilities와 users가 direct file access를 할 수 있게 NFS를 위에 mount하는 software layers가 개발되고 있다.
HDFS NFS Gateway는 HDFS와 NFS server software 사이 proxy 역할을 한다. 다만 HDFS가 random writes를 지원하지 않으므로 gateway도 이를 지원하지 못한다. 한 byte만 바꾸어도 file을 삭제하고 새로 만들어야 할 수 있다. Commercial organizations와 researchers는 DFS, parallel computing modules(MapReduce), distributed databases, NFS-exported volumes를 stackable framework로 쌓는 방향을 연구한다.
CFS(Clustered File System) 또는 PFS(Parallel File System)는 client-server DFS보다 복잡하지만 cluster-based DFS보다는 덜 복잡한 또 다른 범주다. 보통 LAN 위에서 동작하며, 여러 data-storing systems와 여러 accessing systems를 하나의 client-server instance처럼 취급한다. Lustre, GPFS가 대표적이다. CFS는 여러 storage devices/servers의 contents를 uniform, transparent namespace로 묶는다.
DFS는 LAN, cluster environments, WAN 전반에서 common하게 쓰인다. 구현 난도는 낮게 보면 안 된다. Widespread adoption을 위해 OS-independent해야 하고, long distance, commodity hardware failures, fragile networking, increasing users/workloads 속에서도 availability와 good performance를 제공해야 한다.
19.10 Summary
Distributed system은 memory와 clock을 공유하지 않는 processors/nodes가 network로 통신하는 구조다. Users는 shared resources에 접근할 수 있고, access는 data migration, computation migration, process migration으로 제공될 수 있다. 이 access는 user가 explicit하게 요청할 수도 있고, OS/applications가 implicit하게 제공할 수도 있다.
Network communication은 protocol stacks와 layering으로 복잡도를 나눈다. Message는 layers를 내려가며 headers/trailers를 얻고, network를 지나 receiver에서 다시 layers를 올라간다. DNS는 host name을 network address로 바꾸고, ARP는 IP/network address를 Ethernet MAC address로 바꾸며, routers는 packets를 source network에서 destination network로 전달한다.
Transport layer에서는 UDP와 TCP가 port numbers로 waiting processes에 packets를 전달한다. UDP는 빠르고 connectionless하지만 reliability를 application에 맡긴다. TCP는 ACK, sequence number, retransmission, flow control, congestion control로 reliable, connection-oriented byte stream을 제공한다.
Distributed system의 핵심 design challenges는 naming, fault tolerance, error recovery, transparency, scalability다. Scalability는 load 증가뿐 아니라 fault tolerance와 storage efficiency(compression, deduplication)와도 연결된다.
DFS는 clients, servers, storage devices가 distributed sites에 흩어진 file-service system이다. Client-server model은 transparent file sharing에 적합하고, cluster-based model은 large-scale parallel data processing에 적합하다. Naming scheme은 host:local-name, NFS-style mount, global namespace로 나눌 수 있고, ideal DFS는 centralized file system처럼 보여야 한다. Remote file access는 remote service와 caching의 조합으로 구현되며, cached copies와 master file 사이의 cache-consistency problem이 핵심이다.
연결 관계
Chapter 3의 message passing, sockets, RPC 개념은 distributed system communication과 computation migration의 기반이다. Remote procedure call은 local procedure처럼 보이지만 network protocol과 failure 가능성을 품고 있다.
Chapter 9-10의 address binding, virtual memory, demand paging은 DNS name resolution, DFS naming, DFS caching을 이해하는 데 직접 연결된다. DNS는 host name을 address로 bind하고, DFS caching은 remote server를 backing store로 둔 network virtual memory처럼 동작한다.
Chapter 11-15의 storage, file system, file-system implementation은 DFS의 metadata, block/chunk, caching, write policy, consistency semantics와 이어진다. NFS/OpenAFS/HDFS의 차이는 local file system 위에 distributed layer를 어떻게 얹는가의 문제다.
Chapter 16-17의 security/protection은 protocol authentication/encryption, SSH/SFTP, NFSv4 security, DFS access permission checking과 연결된다. Distributed system에서는 network가 attack surface가 되므로 naming, authentication, encryption, authorization이 모두 중요해진다.
Chapter 18의 virtualization/cloud computing과도 연결된다. Cloud storage, desktop virtualization, clustered services는 distributed systems와 virtualization이 결합된 대표 사례다.
오해하기 쉬운 내용
Distributed system은 단순히 network로 연결된 computers의 모음이 아니다. Users와 processes가 remote resources를 shared, transparent, reliable하게 사용할 수 있게 하는 naming, communication, failure handling, consistency mechanisms가 필요하다.
LAN과 WAN의 차이는 거리만이 아니다. Speed, error rate, routing complexity, latency, failure handling 방식이 달라 distributed system design에 영향을 준다.
DNS와 ARP는 모두 “주소 변환”이지만 계층이 다르다. DNS는 host name을 IP address로 바꾸고, ARP는 local network에서 IP address를 MAC address로 바꾼다.
UDP는 “나쁜 TCP”가 아니다. Reliability가 필요 없거나 application이 직접 처리할 수 있고 latency/overhead가 중요한 경우 UDP가 적합할 수 있다.
Network OS와 distributed OS는 user experience가 다르다. Network OS는 remote login/transfer를 명시적으로 요구하지만, distributed OS는 remote resources를 local처럼 보이게 하려 한다.
Location transparency와 location independence는 다르다. Location transparency는 위치를 이름에 드러내지 않는 것이고, location independence는 위치가 바뀌어도 이름이 바뀌지 않는 것이다.
DFS caching은 성능 최적화이지만 consistency problem을 만든다. Cache unit이 커질수록 hit ratio는 좋아질 수 있지만 miss penalty와 consistency 위험도 커진다.
Cluster-based DFS는 POSIX-like transparent file system과 목표가 다를 수 있다. GFS/HDFS는 big data와 parallel processing을 위해 API와 consistency semantics를 다르게 설계한다.
면접 질문
distributed system을 정의하고 local resource와 remote resource의 차이를 설명하라.- Distributed systems를 구축하는 세 가지 이유인 resource sharing, computation speedup, reliability를 예시와 함께 설명하라.
- LAN과 WAN을 speed, error rate, routing, geographic scope 관점에서 비교하라.
- DNS name resolution이 host file 방식보다 scalable한 이유는 무엇인가?
- DNS와 ARP의 역할 차이를 계층 관점에서 설명하라.
- OSI 7-layer model에서 network layer와 transport layer의 역할 차이는 무엇인가?
- TCP/IP stack이 OSI model과 어떻게 대응되는지 설명하라.
- Same LAN destination과 different network destination으로 Ethernet packet을 보낼 때 routing/ARP 흐름은 어떻게 달라지는가?
- UDP가 connectionless/unreliable하다는 말의 의미와 application 책임을 설명하라.
- TCP가 reliable byte stream을 제공하기 위해 사용하는 ACK, sequence number, retransmission, flow control, congestion control을 설명하라.
- Network operating system과 distributed operating system의 차이를 user command paradigm 관점에서 설명하라.
- Data migration, computation migration, process migration의 차이와 각각 적합한 상황을 설명하라.
- Heartbeat와 timeout으로 failure를 감지할 때 link failure와 site failure를 정확히 구분하기 어려운 이유는 무엇인가?
- Network partition이 coordinator election이나 mutual exclusion에 어떤 위험을 만드는가?
- Distributed system에서 transparency와 user mobility가 의미하는 바를 설명하라.
- Scalability와 fault tolerance가 서로 연결되는 이유를 설명하라.
- DFS에서 service, server, client, client interface, intermachine interface를 구분하라.
- NFS의 stateless server 설계가 crash recovery에 유리한 이유와 idempotent operation의 의미를 설명하라.
- OpenAFS가 NFS보다 server scalability를 중시하기 위해 선택한 caching/write policy를 설명하라.
- Client-server DFS와 cluster-based DFS를 bottleneck, metadata, data placement, workload 관점에서 비교하라.
- Location transparency와 location independence 중 어느 쪽이 더 강한 성질인지 설명하라.
- DFS naming schemes인 host:local-name, NFS-style mount, global namespace를 비교하라.
- Remote service와 caching 방식의 remote file access를 비교하라.
- Write-through, delayed-write/write-back, write-on-close의 reliability/performance trade-off를 설명하라.
- Client-initiated consistency check와 server-initiated consistency check의 차이를 설명하라.