Chapter 9. Main Memory
- 과목: Operating System
- 기준 교재: Operating System Concepts 10th
- 관련 페이지: PDF pp. 455-491
- 우선순위: 필수
개요
Chapter 5의 CPU scheduling은 여러 processes가 CPU를 나누어 쓰게 해 CPU utilization과 response time을 개선했다. 하지만 CPU만 공유한다고 성능이 좋아지는 것은 아니다. 여러 processes를 동시에 실행하려면 그 processes의 code와 data가 적어도 일부는 main memory 안에 있어야 하며, 따라서 memory도 공유해야 한다.
Chapter 9의 중심 질문은 “여러 processes가 memory를 공유하면서도 서로를 침범하지 않게 하려면 OS와 hardware가 어떤 주소 변환(address translation), 보호(protection), 배치(allocation), 공유(shared pages) 구조를 제공해야 하는가?”이다. 이 장은 primitive bare-machine 방식부터 contiguous allocation, paging, page-table structures, swapping, IA-32/x86-64/ARMv8 address translation까지 이어지며, 대부분의 memory-management algorithm이 hardware support와 긴밀하게 결합된다는 점을 반복해서 보여 준다.
핵심 개념
| 개념 | 핵심 의미 |
|---|---|
main memory | CPU가 직접 접근할 수 있는 일반 목적 저장장치. 실행 중인 instructions와 operands는 register 또는 main memory에 있어야 한다. |
register | CPU core 내부 저장장치. 보통 한 CPU clock cycle 안에 접근 가능해 main memory보다 훨씬 빠르다. |
cache | CPU와 main memory 사이의 빠른 memory. memory stall을 줄이기 위해 hardware가 자동으로 관리한다. |
base register | process가 접근할 수 있는 가장 작은 legal physical memory address를 담는 register. |
limit register | base부터 시작하는 legal address range의 크기를 담는 register. |
address binding | symbolic address, relocatable address, absolute address를 서로 mapping하는 과정. |
compile-time binding | memory 위치를 compile 시점에 알고 있어 absolute code를 생성하는 방식. 시작 위치가 바뀌면 recompile이 필요하다. |
load-time binding | compile 때 위치를 모르면 relocatable code를 만들고, loading 시점에 absolute address를 결정하는 방식. |
execution-time binding | process가 실행 중에도 memory 위치를 옮길 수 있도록 run time에 address mapping을 수행하는 방식. 대부분의 modern OS가 사용한다. |
logical address, virtual address | CPU가 생성하는 주소. program은 이 주소 공간 안에서 실행된다고 생각한다. |
physical address | memory unit이 실제로 보는 주소. memory-address register에 들어가는 주소다. |
logical address space | program이 생성할 수 있는 모든 logical addresses의 집합. |
physical address space | logical addresses가 mapping되는 실제 physical addresses의 집합. |
MMU | Memory-Management Unit. run time에 logical/virtual address를 physical address로 변환하는 hardware. |
relocation register | execution-time binding에서 logical address에 더해지는 base value. simple MMU scheme의 핵심이다. |
dynamic loading | routine을 처음부터 모두 memory에 올리지 않고, 호출될 때 필요한 routine만 load하는 방식. |
dynamic linking, DLL, shared library | library linking을 execution time까지 미루고, 여러 processes가 library code 한 copy를 공유할 수 있게 하는 방식. |
contiguous memory allocation | 각 process를 memory의 하나의 연속된 구간에 배치하는 allocation 방식. |
relocation register + limit register | contiguous allocation에서 logical address 범위 검사와 physical relocation을 함께 제공하는 protection 구조. |
variable-partition scheme | process 크기에 맞춰 variable-sized partitions를 만들고, 각 partition에 한 process를 담는 방식. |
hole | 현재 비어 있어 process allocation에 사용할 수 있는 contiguous free memory block. |
first fit | 충분히 큰 첫 번째 hole에 process를 배치하는 dynamic storage-allocation strategy. |
best fit | 충분히 큰 hole 중 가장 작은 hole을 선택하는 strategy. leftover hole을 가장 작게 만든다. |
worst fit | 가장 큰 hole을 선택하는 strategy. leftover hole을 크게 남겨 이후 요청에 쓰려는 의도다. |
external fragmentation | total free memory는 충분하지만 free spaces가 contiguous하지 않아 요청을 만족하지 못하는 상태. |
internal fragmentation | allocation 단위 때문에 process가 요청한 크기보다 큰 block을 받고, block 내부에 unused memory가 남는 상태. |
50-percent rule | first fit 분석에서 N allocated blocks가 있으면 약 0.5N blocks가 fragmentation으로 lost될 수 있다는 경험적 성질. |
compaction | scattered holes를 하나의 큰 hole로 만들기 위해 memory contents를 이동시키는 기법. |
paging | logical memory를 fixed-size pages로, physical memory를 같은 크기의 frames로 나누어 process의 physical address space를 noncontiguous하게 배치하는 방식. |
page | logical memory의 fixed-sized block. |
frame | physical memory의 fixed-sized block. page와 같은 크기다. |
page number (p) | logical address의 상위 bits. page table index로 사용된다. |
page offset (d) | page 내부 displacement. Translation 후에도 그대로 유지된다. |
page table | process별 logical page number를 physical frame number로 mapping하는 table. |
frame table | system-wide physical frames의 free/allocated 상태와 owner 정보를 관리하는 OS data structure. |
PTBR | Page-Table Base Register. main memory에 있는 current process page table의 시작 주소를 가리킨다. |
TLB | Translation Look-Aside Buffer. page-table entries 일부를 담는 작은 high-speed associative cache. |
TLB hit, TLB miss | 필요한 page number가 TLB에 있으면 hit, 없어서 page table lookup이 필요하면 miss. |
ASID | Address-Space Identifier. TLB entry가 어느 process address space에 속하는지 구분한다. |
hit ratio | TLB에서 원하는 page number를 찾는 비율. effective access time을 좌우한다. |
valid-invalid bit | page table entry의 page가 process logical address space에 속하는 valid page인지 표시하는 protection bit. |
PTLR | Page-Table Length Register. page table의 유효 길이를 나타내 invalid logical address를 trap하는 데 쓴다. |
reentrant code | 실행 중 자기 자신을 수정하지 않는 non-self-modifying code. 여러 processes가 같은 physical code pages를 공유할 수 있다. |
hierarchical paging | page table을 다시 pages로 나누어 multi-level page table로 구성하는 방식. |
two-level paging | outer page table과 inner page table로 address translation을 나누는 hierarchical paging. |
forward-mapped page table | outer page table에서 시작해 inner page table로 들어가는 translation 구조. |
hashed page table | virtual page number를 hash해 frame mapping을 찾는 page-table structure. |
clustered page table | hash table entry 하나가 여러 pages의 mappings를 담는 hashed page table 변형. sparse address spaces에 유용하다. |
inverted page table | process별 page table 대신 physical frame마다 하나의 entry만 두는 system-wide page table. |
TTE | Translation Table Entry. Solaris/SPARC 같은 구조에서 virtual-to-physical translation 정보를 담는 entry. |
TSB | Translation Storage Buffer. TTE cache로, TLB miss 후 hardware/software translation path에서 사용된다. |
swapping | process 또는 process 일부를 memory에서 backing store로 임시로 내보냈다가 다시 가져오는 기법. |
backing store | swapped-out process/page images를 저장하는 빠른 secondary storage. |
page out, page in | page를 memory에서 backing store로 내보내는 작업, backing store에서 memory로 가져오는 작업. |
segmentation | IA-32에서 logical address를 segment descriptor의 base/limit을 이용해 linear address로 바꾸는 단계. |
linear address | IA-32/x86 계열에서 segmentation 결과로 생성되고 paging unit 입력이 되는 주소. |
LDT, GDT | Local Descriptor Table, Global Descriptor Table. IA-32 segment descriptors를 저장한다. |
CR3 register | IA-32/x86-64에서 current process의 page directory 또는 top-level paging structure를 가리키는 register. |
PAE | Page Address Extension. IA-32가 4 GB를 넘는 physical address space를 접근하도록 paging 구조와 entry size를 확장한 기법. |
x86-64 | IA-32 instruction set을 확장한 64-bit architecture. 현재는 48-bit virtual address와 52-bit physical address를 지원한다. |
translation granule | ARMv8에서 translation 단위가 되는 granularity. 4 KB, 16 KB, 64 KB가 있다. |
TTBR | Translation Table Base Register. ARMv8에서 current thread의 level 0 translation table을 가리킨다. |
세부 정리
9.1 Background
9.1.1 Basic Hardware
Memory는 byte들의 큰 배열이고 각 byte는 address를 가진다. CPU는 program counter가 가리키는 address에서 instruction을 fetch하고, instruction decode 후 operands를 memory에서 읽거나 결과를 다시 memory에 store할 수 있다. Memory unit 입장에서는 주소가 instruction counter, indexing, indirection, literal address 중 무엇에서 왔는지, instruction을 위한 것인지 data를 위한 것인지 알지 못한다. Memory-management 관점에서는 running program이 생성하는 memory address sequence만 중요하다.
CPU가 직접 접근할 수 있는 일반 목적 저장장치는 registers와 main memory뿐이다. Machine instruction은 memory address를 operand로 삼을 수 있지만 disk address를 직접 operand로 삼지는 못한다. 따라서 실행될 instruction과 instruction이 사용할 data는 register나 main memory에 있어야 하며, disk에만 있는 data는 CPU가 다루기 전에 memory로 옮겨야 한다.
성능 측면에서 registers는 CPU core 안에 있어 대개 한 clock cycle 안에 접근 가능하지만, main memory 접근은 memory bus transaction을 거쳐 여러 clock cycles가 걸릴 수 있다. 이때 processor는 필요한 data가 없어 stall될 수 있다. Memory access는 너무 자주 발생하므로 stall을 그대로 두면 성능 손실이 크다. 그래서 CPU와 main memory 사이에 빠른 cache를 두고, cache는 일반적으로 OS가 아니라 hardware가 자동으로 관리한다. Chapter 5의 multithreaded core는 memory stall 동안 다른 hardware thread로 전환해 stall 비용을 숨길 수도 있다.
Memory management는 성능만이 아니라 protection 문제이기도 하다. User process가 OS memory를 수정하거나, 다른 user process의 memory를 읽고 쓰면 system correctness가 깨진다. 그런데 CPU의 모든 memory access마다 OS가 개입하면 성능 비용이 너무 크다. 그래서 기본 protection은 hardware가 제공해야 한다.
가장 단순한 protection 구조는 base register와 limit register다. base는 process가 접근할 수 있는 가장 작은 legal physical address, limit은 접근 가능한 range의 크기다.
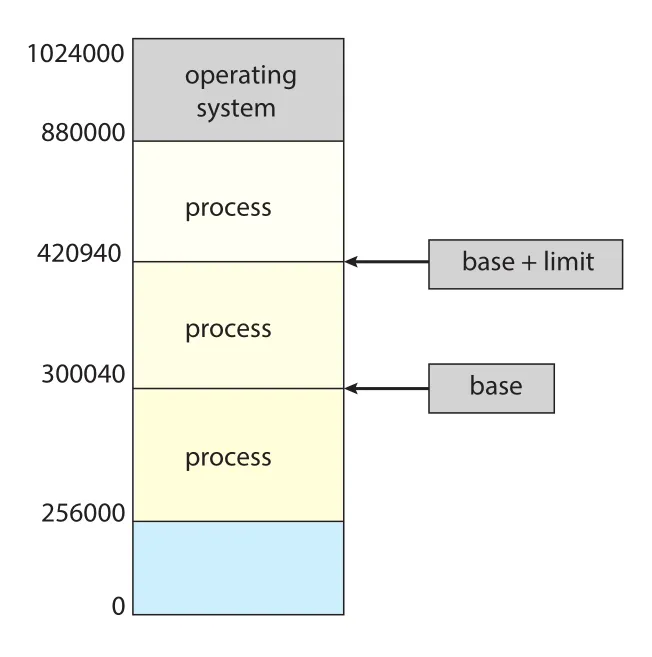
Figure 9.1 · PDF p. 457 · base와 limit register가 process별 logical address space의 물리 범위를 제한하는 구조
예를 들어 , 이면 process는 physical address 부터 까지 접근할 수 있다. CPU hardware는 user mode에서 생성된 모든 address를 이 range와 비교한다.
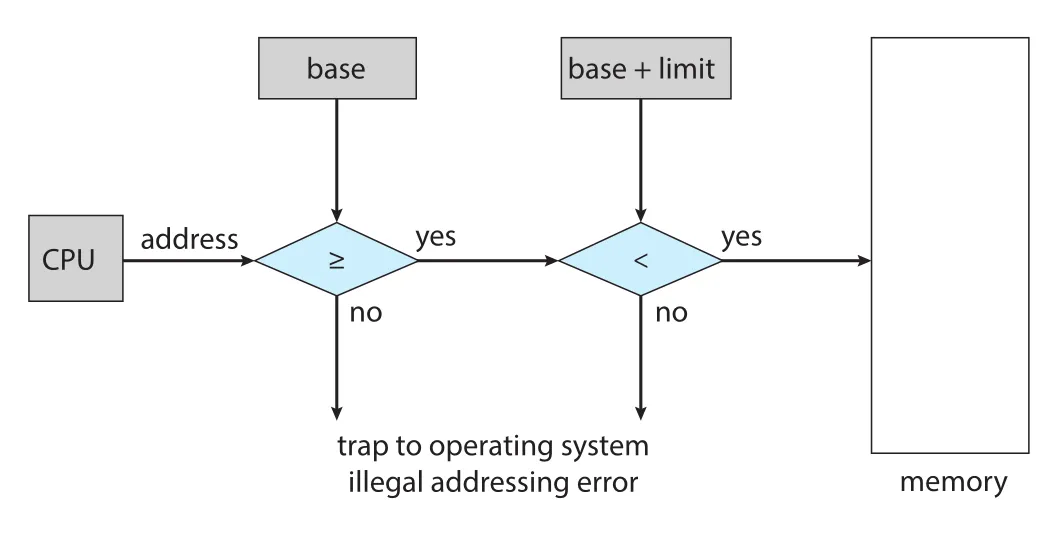
Figure 9.2 · PDF p. 458 · user mode address가 base 이상이고 base+limit 미만인지 검사해 illegal access를 trap으로 처리하는 hardware protection
검사는 개념적으로 다음 조건이다.
User mode program이 OS memory나 다른 process memory에 접근하려 하면 hardware가 trap을 발생시키고, OS는 이를 fatal error로 처리한다. base와 limit register는 privileged instruction으로만 load할 수 있으므로 kernel mode에서 실행되는 OS만 값을 바꿀 수 있다. 반대로 OS는 kernel mode에서 OS memory와 user memory 모두에 unrestricted access를 가진다. 그래야 user program loading, error dump, system call parameter 접근, user memory와 I/O 사이의 복사, context switch 중 register state 저장/복구 같은 일을 수행할 수 있다.
9.1.2 Address Binding
Program은 보통 disk 위의 binary executable file로 존재한다. 실행하려면 memory로 들어와 process context 안에 놓여야 하고, 실행 중에는 memory의 instructions와 data에 접근한다. Process가 끝나면 그 memory는 회수되어 다른 process가 사용할 수 있다.
대부분의 systems는 user process가 physical memory의 어느 부분에나 올라갈 수 있게 한다. 따라서 computer의 address space가 00000에서 시작하더라도 user process의 첫 physical address가 반드시 00000일 필요는 없다. 이 유연성을 얻으려면 program 내부의 주소 표현이 여러 단계에서 변환되어야 한다.
Source program의 address는 대개 count 같은 symbolic address다. Compiler는 이를 “module 시작부터 14 bytes” 같은 relocatable address로 bind할 수 있다. Linker 또는 loader는 relocatable address를 74014 같은 absolute address로 다시 bind한다. 각 binding은 하나의 address space를 다른 address space로 mapping하는 일이다.
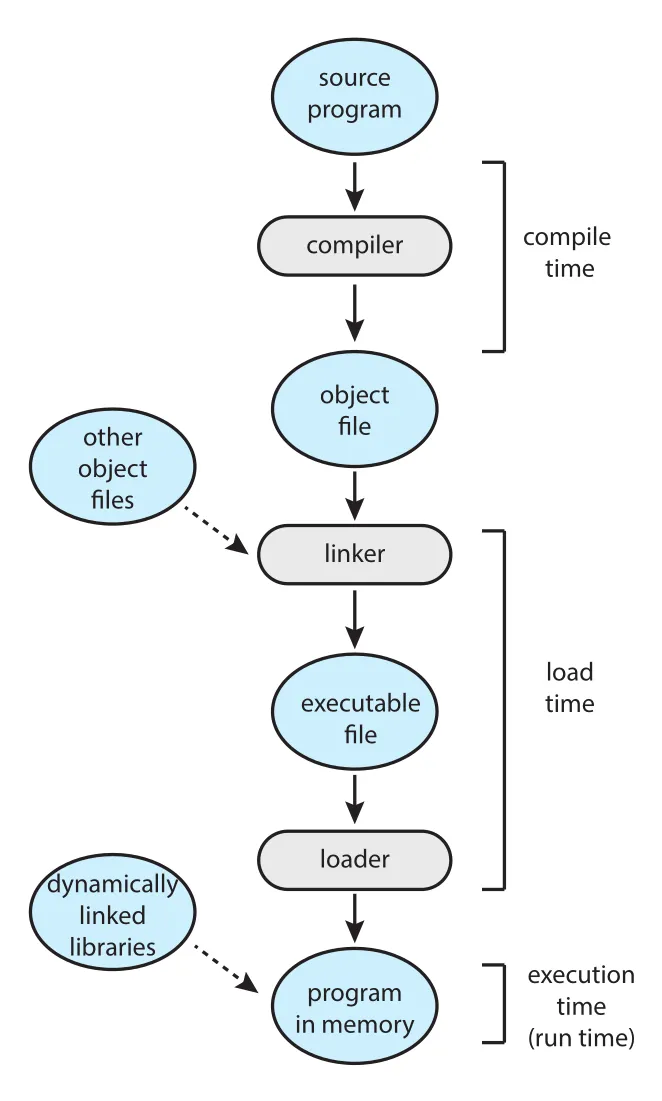
Figure 9.3 · PDF p. 459 · source program이 object file, executable file, in-memory program으로 바뀌며 address binding이 일어나는 단계
Address binding 시점은 세 가지로 나뉜다.
| Binding 시점 | 동작 방식 | 장점 | 제약 |
|---|---|---|---|
compile time | process가 memory의 어디에 올라갈지 미리 알면 compiler가 absolute code를 생성한다. | 실행 시 변환 비용이 작다. | 시작 위치가 바뀌면 recompile이 필요하다. |
load time | compile 때 위치를 모르면 compiler가 relocatable code를 만들고, loader가 loading 시점에 final address를 결정한다. | 시작 위치 변경 시 reload로 대응 가능하다. | 실행 중 위치 이동은 어렵다. |
execution time, run time | process가 실행 중에도 다른 memory segment로 이동할 수 있으므로 address binding을 memory reference 시점까지 미룬다. | relocation, swapping, paging 같은 현대적 memory management와 잘 맞는다. | MMU 같은 special hardware support가 필요하다. |
이 장의 많은 내용은 이 binding들을 hardware와 OS가 어떻게 효율적으로 구현하는지에 대한 설명이다.
9.1.3 Logical Versus Physical Address Space
CPU가 생성하는 주소는 logical address라고 하고, memory unit이 실제로 보는 주소는 physical address라고 한다. Compile-time 또는 load-time binding에서는 logical address와 physical address가 같을 수 있다. 하지만 execution-time binding에서는 둘이 달라진다. 이때 logical address를 보통 virtual address라고도 부르며, 이 책에서는 logical address와 virtual address를 같은 의미로 사용한다.
logical address space: program이 생성할 수 있는 모든 logical addresses의 집합physical address space: logical addresses에 대응되는 실제 physical addresses의 집합
Run-time mapping은 hardware 장치인 MMU가 수행한다.
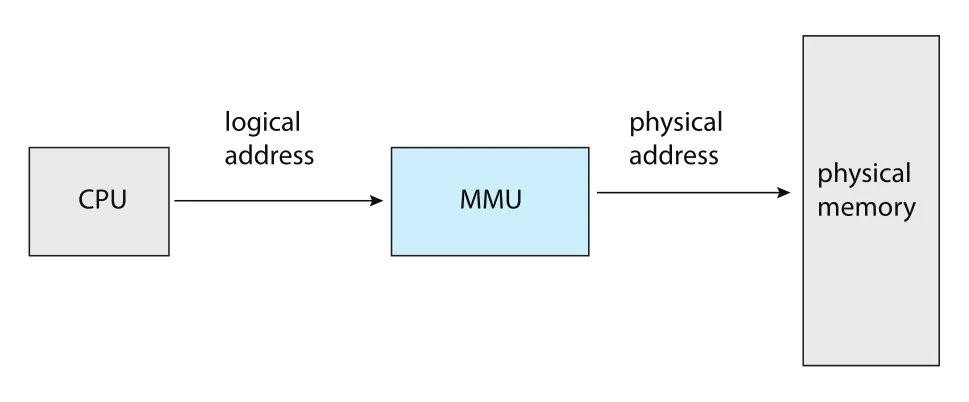
Figure 9.4 · PDF p. 460 · CPU가 만든 logical address를 MMU가 physical address로 변환해 memory에 전달하는 구조
가장 단순한 MMU scheme은 앞의 base-register scheme을 일반화한 것이다. 여기서 base register는 relocation register로 볼 수 있다. CPU가 logical address를 생성하면 MMU가 relocation register 값을 더해 physical address를 만든다.
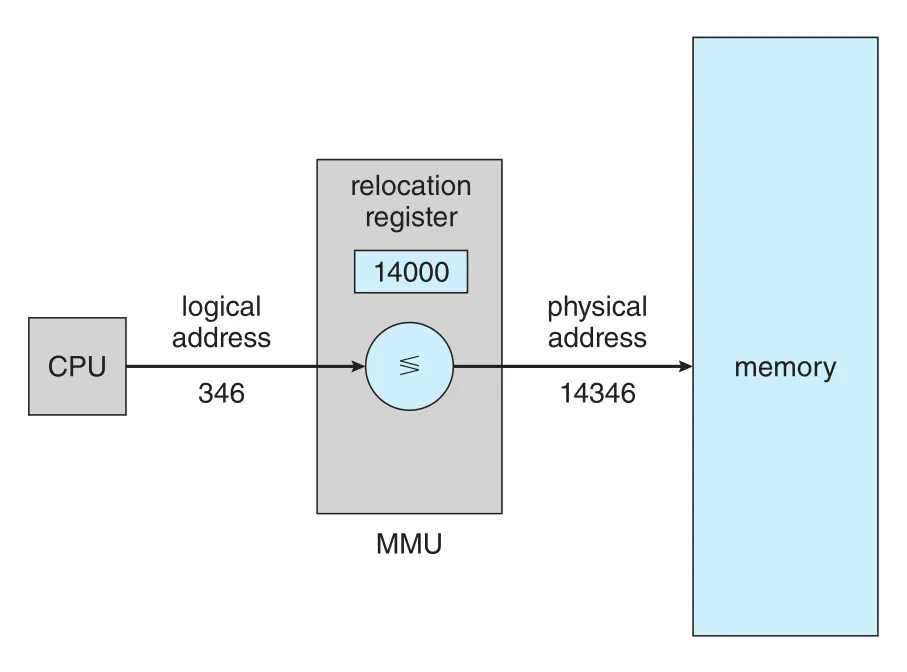
Figure 9.5 · PDF p. 461 · relocation register 값 14000을 logical address 346에 더해 physical address 14346으로 변환하는 dynamic relocation
예를 들어 이면 user program이 logical address 을 참조할 때 physical address 으로, logical address 을 참조할 때 physical address 으로 변환된다.
중요한 점은 user program이 실제 physical address를 직접 보지 않는다는 것이다. Program은 pointer 을 만들고, 저장하고, 비교하고, 조작할 수 있지만, 그 값이 memory address로 실제 사용되는 순간에만 MMU가 physical address로 변환한다. 따라서 process는 자신이 부터 까지의 logical memory에서 실행된다고 생각하고, hardware는 이를 부터 까지의 physical memory로 mapping한다. Logical address space와 physical address space의 분리는 memory management의 핵심 전제다.
9.1.4 Dynamic Loading
지금까지의 설명에서는 process의 entire program과 all data가 physical memory에 있어야 실행 가능하다고 보았다. 그러면 process size가 physical memory size에 의해 제한된다. dynamic loading은 이를 완화하기 위해 routine을 호출될 때까지 load하지 않는 방식이다.
모든 routines는 disk에 relocatable load format으로 보관된다. Main program만 먼저 memory에 올라와 실행된다. 어떤 routine이 다른 routine을 호출해야 하면, 호출하는 routine은 먼저 그 routine이 이미 load되었는지 확인한다. 아직 없다면 relocatable linking loader를 호출해 필요한 routine을 memory로 load하고, program의 address tables를 갱신한 다음 새 routine으로 control을 넘긴다.
Dynamic loading의 장점은 실제 필요한 routine만 memory를 차지한다는 것이다. 특히 error-handling routines처럼 code는 크지만 드물게 실행되는 부분에 효과적이다. 전체 program size가 크더라도 실행 중 실제로 load되는 부분은 훨씬 작을 수 있다.
Dynamic loading은 특별한 OS support를 요구하지 않는다. Program이 이 방식을 활용하도록 설계하는 책임은 기본적으로 user/programmer에게 있다. OS는 dynamic loading을 쉽게 구현하도록 library routines를 제공할 수는 있다.
9.1.5 Dynamic Linking and Shared Libraries
dynamic linking은 linking을 execution time까지 미루는 방식이다. Dynamically linked libraries (DLLs)는 program 실행 중에 user program과 link되는 system libraries이며, shared libraries라고도 부른다.
static linking에서는 system library가 다른 object module처럼 loader에 의해 binary program image에 합쳐진다. 이 방식에서는 각 executable image가 필요한 library routine copy를 포함해야 하므로 executable size가 커지고 main memory도 낭비될 수 있다. 반대로 dynamic linking에서는 library routine의 실제 연결을 run time까지 미루므로, 여러 processes가 memory 안의 library 한 copy를 공유할 수 있다.
Program이 dynamic library routine을 참조하면 loader는 해당 DLL을 찾고, 필요하면 memory에 load한 뒤, dynamic library function을 참조하는 addresses를 DLL의 actual memory location에 맞게 조정한다.
Dynamic linking은 library update에도 유리하다. Bug fix나 minor update가 library에 반영되면, program들을 다시 relink하지 않아도 새 library를 사용할 수 있다. 다만 incompatible change가 accidental execution으로 이어지지 않게 program과 library는 version information을 가진다. Minor changes는 같은 version number를 유지할 수 있고, major incompatible changes는 version number를 올려 새 version을 기준으로 compile된 programs만 영향을 받게 한다.
Dynamic loading과 달리 dynamic linking과 shared libraries는 일반적으로 OS support가 필요하다. Processes가 서로 보호되는 환경에서는 어떤 routine이 다른 process의 memory space에 이미 있는지 확인하거나, 여러 processes가 같은 memory addresses를 공유하도록 허용할 수 있는 주체가 OS뿐이기 때문이다. 이 shared library 개념은 Section 9.3.4의 paging environment에서 shared pages로 다시 등장한다.
9.2 Contiguous Memory Allocation
contiguous memory allocation은 각 process를 memory 안의 하나의 연속된 section에 배치하는 초기 memory-management 방식이다. Main memory에는 OS와 여러 user processes가 함께 있어야 하므로, OS는 available memory를 가능한 효율적으로 나누어야 한다. 보통 memory는 OS partition과 user-process partition으로 나뉘며, Linux와 Windows를 포함한 많은 OS는 OS를 high memory에 둔다.
여러 user processes가 동시에 memory에 있으려면, OS는 memory로 들어오기를 기다리는 processes에 available memory를 어떻게 배정할지 결정해야 한다. Contiguous allocation에서는 process 하나가 하나의 contiguous region을 차지하므로 이해와 hardware protection은 단순하지만, 시간이 지나며 holes가 흩어지는 fragmentation 문제가 생긴다.
9.2.1 Memory Protection
Contiguous allocation에서 process가 자기 memory 밖을 접근하지 못하게 하려면 Section 9.1의 relocation register와 limit register를 결합하면 된다. relocation register는 가장 작은 physical address를 담고, limit register는 process가 생성할 수 있는 logical address range를 담는다.
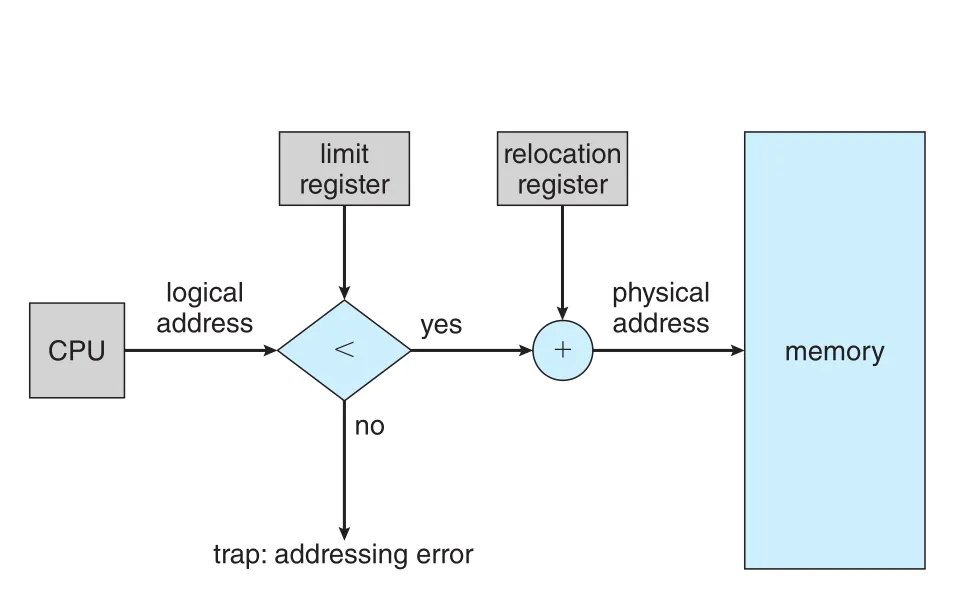
Figure 9.6 · PDF p. 463 · logical address가 limit보다 작은지 확인한 뒤 relocation 값을 더해 physical address를 만드는 protection 구조
CPU가 만든 logical address는 먼저 limit과 비교된다. 주소가 limit보다 작으면 MMU가 relocation 값을 더해 physical address를 만들고 memory로 보낸다. 범위를 넘으면 addressing error trap이 발생한다.
if logical_address < limit:
physical_address = relocation + logical_address
else:
trap: addressing errorCPU scheduler가 process를 선택하면 dispatcher는 context switch의 일부로 해당 process의 relocation/limit registers를 load한다. 이후 CPU가 생성하는 모든 address는 이 registers에 의해 검사되므로 running process가 OS나 다른 user process의 program/data를 수정하지 못하게 할 수 있다.
이 방식은 OS size가 동적으로 변하는 상황에도 유용하다. 예를 들어 device driver code와 buffers는 해당 device가 사용될 때만 memory에 load하고, 필요 없어지면 제거해 다른 용도로 memory를 줄 수 있다. 이때 relocation-register scheme은 OS 영역과 user 영역의 기준을 조정할 수 있는 단순한 mechanism이 된다.
9.2.2 Memory Allocation
variable-partition scheme에서는 memory를 process 크기에 맞는 variable-sized partitions로 나누고, 각 partition에는 정확히 하나의 process를 둔다. OS는 memory의 어느 부분이 occupied인지, 어느 부분이 available인지 table로 관리한다. 처음에는 user processes가 사용할 memory 전체가 하나의 큰 available block, 즉 hole이다. 시간이 지나 processes가 들어오고 나가면 memory에는 다양한 크기의 holes가 흩어진다.
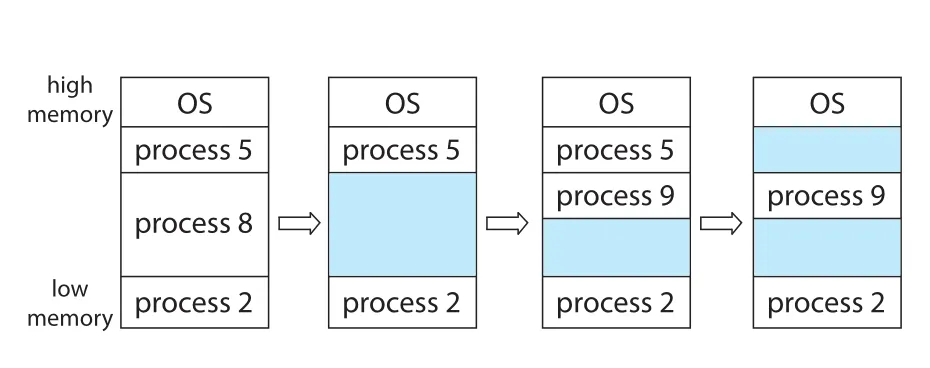
Figure 9.7 · PDF p. 464 · process가 종료되고 새 process가 들어오면서 variable partitions와 holes가 생기는 모습
Process가 도착하면 OS는 process의 memory requirement와 available memory를 보고 allocation 여부를 결정한다. 충분한 memory가 있으면 process를 memory에 load하고 CPU 경쟁에 참여시킨다. Process가 terminate하면 그 memory는 release되고, OS는 이를 다른 process에 줄 수 있다.
도착한 process를 만족할 memory가 없을 때 선택지는 두 가지다. 하나는 process를 reject하고 error message를 주는 것이다. 다른 하나는 process를 wait queue에 넣었다가 memory가 release될 때 기다리는 process의 요구를 만족할 수 있는지 검사하는 것이다.
Available memory는 다양한 크기의 holes set으로 표현된다. Process가 size n을 요구하면 OS는 충분히 큰 hole을 찾는다. Hole이 너무 크면 두 부분으로 나눈다. 한 부분은 arriving process에 할당하고, 나머지는 holes set으로 되돌린다. Process가 terminate하면 release된 block을 holes set에 넣고, adjacent holes가 있으면 merge해 더 큰 hole로 만든다.
이 문제는 일반적인 dynamic storage-allocation problem이다. Free holes list에서 size n 요청을 어떻게 만족할지 결정해야 한다. 대표 전략은 first fit, best fit, worst fit이다.
| Strategy | 선택 기준 | 탐색 비용 | 남는 hole의 성격 | 핵심 trade-off |
|---|---|---|---|---|
first fit | 충분히 큰 첫 번째 hole | 앞에서부터 찾다가 성공하면 중단 가능 | 위치와 요청 history에 따라 달라짐 | 일반적으로 빠르고, storage utilization도 worst fit보다 낫다. |
best fit | 충분히 큰 hole 중 가장 작은 hole | size-ordered list가 아니면 전체 탐색 필요 | 가장 작은 leftover hole | 공간을 아끼려 하지만 작은 unusable holes를 많이 만들 수 있다. |
worst fit | 가장 큰 hole | size-ordered list가 아니면 전체 탐색 필요 | 가장 큰 leftover hole | 큰 leftover를 남기려 하지만 simulation상 time/storage utilization이 좋지 않다. |
Simulation 결과로는 first fit과 best fit이 time과 storage utilization 측면에서 worst fit보다 낫다. first fit과 best fit 중 어느 쪽이 storage utilization에서 항상 우월하다고 말하기는 어렵지만, first fit은 일반적으로 더 빠르다.
9.2.3 Fragmentation
first fit과 best fit 모두 external fragmentation을 겪는다. Processes가 memory에 load되고 제거되면서 free memory가 작은 조각들로 나뉘기 때문이다. External fragmentation은 total free memory는 요청을 만족할 만큼 충분하지만, free spaces가 contiguous하지 않아 실제 allocation이 불가능한 상태다.
Worst case에서는 모든 두 processes 사이에 작은 free block이 하나씩 남을 수 있다. 이 작은 pieces가 하나의 큰 free block이었다면 여러 processes를 더 실행할 수 있지만, 흩어져 있으므로 사용할 수 없다.
Fragmentation의 양은 allocation strategy와 free block의 어느 쪽 끝을 allocation하는지에도 영향을 받는다. 어떤 systems에서는 first fit이 낫고, 다른 systems에서는 best fit이 나을 수 있다. 하지만 어떤 algorithm을 쓰든 external fragmentation 자체는 피하기 어렵다.
First fit에 대한 statistical analysis는 50-percent rule을 보여 준다. 일부 optimization을 해도 N개의 allocated blocks가 있으면 약 0.5N개의 blocks가 fragmentation으로 lost될 수 있다. 즉 memory의 약 1/3이 unusable해질 수 있다.
internal fragmentation은 allocation된 partition 내부에 unused memory가 남는 경우다. 예를 들어 18,464 bytes hole이 있고 process가 18,462 bytes를 요청했다고 하자. 정확히 18,462 bytes만 주면 2 bytes hole이 남는데, 이 tiny hole을 추적하는 overhead가 hole 자체보다 커질 수 있다. 일반적 해결은 physical memory를 fixed-sized blocks로 나누고 block 단위로 allocation하는 것이다. 그러면 process가 요청한 것보다 약간 큰 memory를 받을 수 있고, 그 차이가 internal fragmentation이다.
Fragmentation은 다음처럼 구분하면 헷갈리지 않는다.
| 구분 | free memory의 위치 | 문제 상황 | 대표 원인 |
|---|---|---|---|
external fragmentation | allocated blocks 바깥의 holes | 전체 free memory는 충분하지만 연속되지 않음 | variable-sized contiguous allocation |
internal fragmentation | allocated block 내부 | 할당받은 block 일부를 process가 사용하지 않음 | fixed-sized allocation unit, rounding |
External fragmentation의 한 해결책은 compaction이다. Memory contents를 이동시켜 free memory를 한쪽으로 모아 하나의 큰 block을 만드는 것이다. 하지만 compaction은 항상 가능하지 않다. Relocation이 assembly time이나 load time에 정적으로 끝났다면 process를 옮긴 뒤 주소를 고치기 어렵다. Compaction은 relocation이 execution time에 동적으로 수행될 때 가능하다. 이 경우 program과 data를 옮기고 base register를 새 base address로 바꾸면 된다.
Compaction이 가능해도 비용이 문제다. 가장 단순한 algorithm은 모든 processes를 memory의 한쪽 끝으로 밀고, 모든 holes를 반대쪽으로 모아 하나의 큰 hole을 만드는 방식이다. 하지만 많은 memory contents를 복사해야 하므로 expensive할 수 있다.
External fragmentation을 피하는 또 다른 해결책은 process의 logical address space가 physical memory에서 noncontiguous하게 배치되는 것을 허용하는 것이다. 즉 process의 logical memory는 연속적이라고 보이지만, 실제 physical memory는 여기저기 흩어진 free frames를 사용할 수 있게 만든다. 이 전략이 다음 Section 9.3의 paging이며, 현대 computer systems에서 가장 흔한 memory-management technique이다.
9.3 Paging
지금까지의 방식은 process의 physical address space가 contiguous해야 한다고 가정했다. paging은 이 제약을 없애 process의 physical address space를 noncontiguous하게 배치할 수 있게 한다. 그 결과 contiguous allocation의 핵심 문제였던 external fragmentation과 compaction 필요를 제거한다.
Paging은 거의 모든 종류의 operating systems에서 사용되며, OS와 hardware의 협력으로 구현된다. OS는 free frames와 per-process page tables를 관리하고, hardware는 매 memory reference마다 빠르게 address translation을 수행한다.
9.3.1 Basic Method
Paging의 기본 아이디어는 physical memory를 fixed-sized blocks인 frames로 나누고, logical memory를 같은 크기의 pages로 나누는 것이다. Process가 실행될 때 각 page는 file system이나 backing store에서 available memory frames 중 아무 곳에나 load된다. Backing store도 보통 frame과 같은 크기의 fixed-sized blocks 또는 여러 frames의 cluster로 나뉜다.
이 방식의 효과는 크다. Logical address space와 physical address space가 분리되므로, process는 64-bit logical address space를 가질 수 있지만 실제 physical memory는 bytes보다 훨씬 작을 수 있다.
CPU가 생성하는 logical address는 두 부분으로 나뉜다.
는 per-process page table의 index로 사용된다. Page table entry는 해당 page가 들어 있는 physical 를 담는다. 는 page 내부 위치이므로 변하지 않는다.
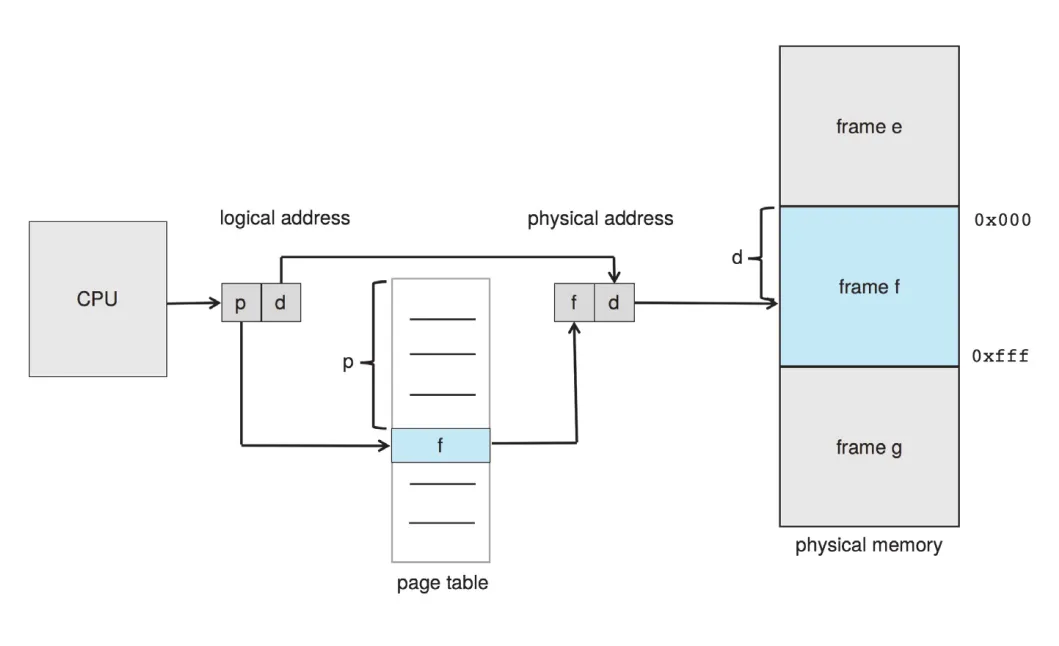
Figure 9.8 · PDF p. 467 · page number로 page table을 조회하고 frame number와 offset을 결합해 physical address를 만드는 paging hardware
MMU의 logical-to-physical translation은 다음 순서다.
- Logical address에서 를 추출해 page table index로 사용한다.
- Page table에서 대응하는 를 가져온다.
- Logical address의 를 로 대체하고, 는 그대로 둔다.
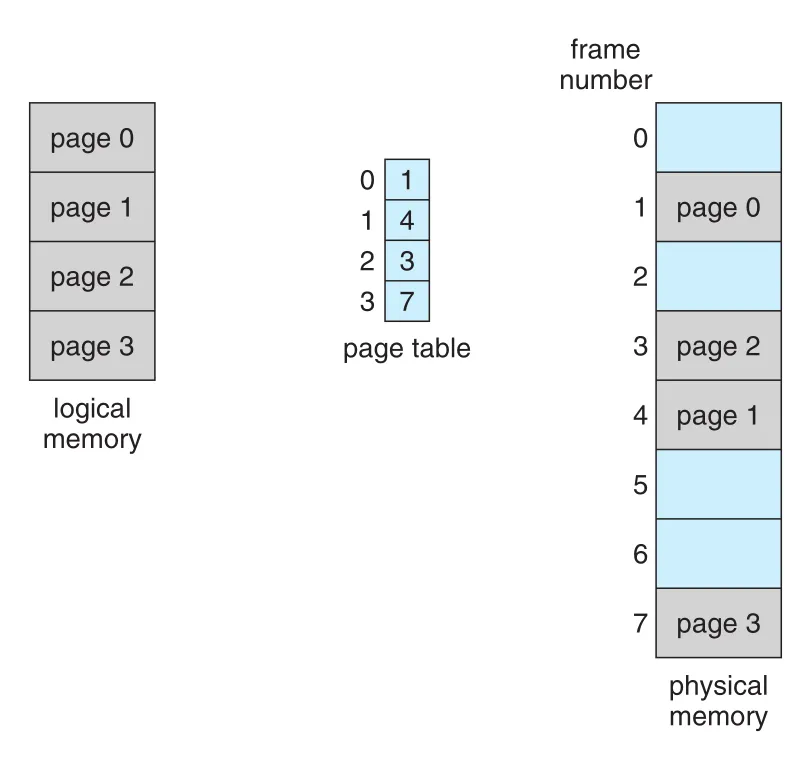
Figure 9.9 · PDF p. 468 · programmer가 보는 logical pages가 physical memory의 frames에 흩어져 배치되는 paging model
Page size와 frame size는 hardware가 정하며, 보통 2의 거듭제곱이다. Logical address space 크기가 , page size가 bytes라면 logical address의 상위 bits가 page number, 하위 bits가 page offset이 된다.
Page size를 2의 거듭제곱으로 잡으면 bit slicing만으로 page number와 offset을 분리할 수 있어 address translation이 단순해진다.
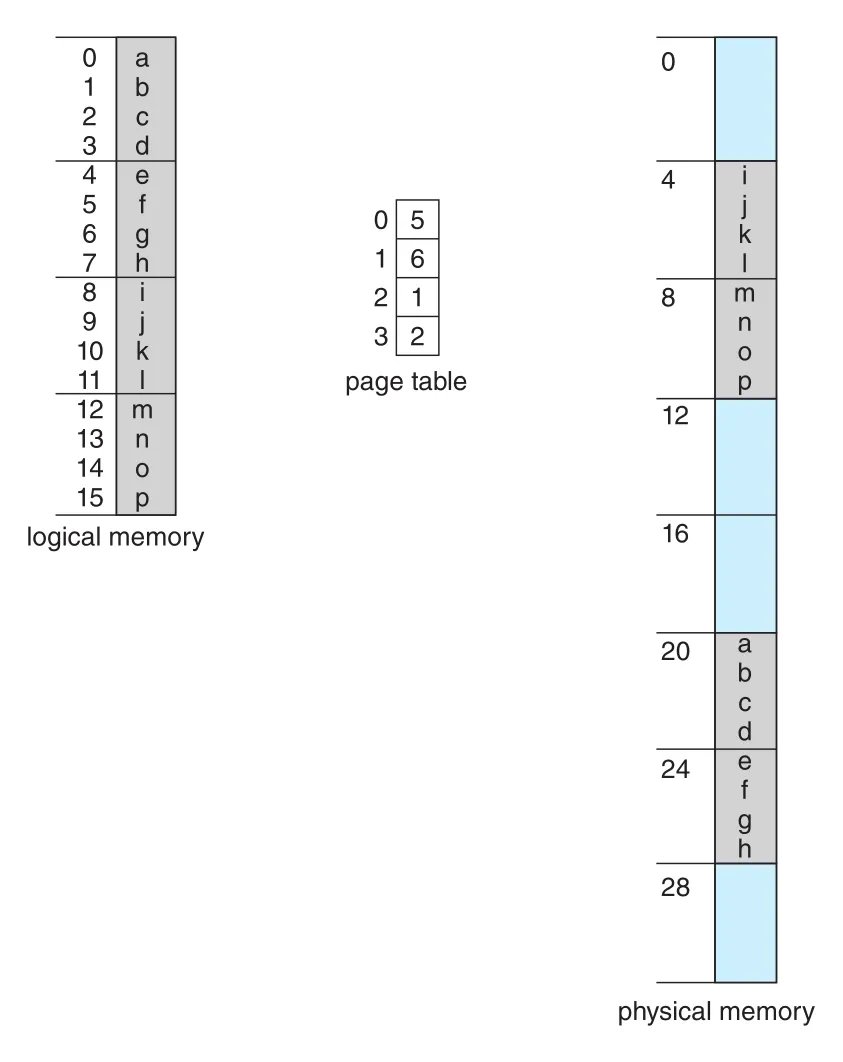
Figure 9.10 · PDF p. 469 · 32-byte physical memory와 4-byte pages에서 logical address를 physical address로 변환하는 예
Figure 9.10의 작은 예에서 page size는 4 bytes이므로 offset은 2 bits다. Logical address 은 page , offset 이고, page table에서 page 은 frame 에 있다. 따라서 physical address는 이다. Logical address 은 page , offset 이므로 physical address 이 된다. Logical address 는 page , offset 이고 page 이 frame 에 있으므로 physical address 로 mapping된다.
Paging은 dynamic relocation의 한 형태다. 차이는 relocation register 하나가 아니라 page별 base register table, 즉 page table을 사용한다는 점이다. 그래서 logical page마다 서로 다른 physical frame으로 mapping할 수 있다.
Paging은 external fragmentation을 없앤다. 어떤 free frame이든 필요한 process page에 배정할 수 있기 때문이다. 그러나 internal fragmentation은 생길 수 있다. Frames는 unit 단위로 allocation되므로 process size가 page boundary와 딱 맞지 않으면 마지막 frame 일부가 비게 된다.
예를 들어 page size가 2,048 bytes이고 process size가 72,766 bytes라면 35 pages와 1,086 bytes가 필요하므로 총 36 frames가 할당된다. 마지막 frame의 unused space는 bytes다. Worst case에서는 process가 를 요구해 frames를 받고, 거의 한 frame 전체가 internal fragmentation이 될 수 있다. Process size가 page size와 독립적이라면 평균 internal fragmentation은 process당 half page 정도로 기대된다.
Page size 선택에는 trade-off가 있다.
| Page size | 장점 | 단점 |
|---|---|---|
| Smaller pages | 평균 internal fragmentation 감소 | page-table entries 수 증가, page table overhead 증가 |
| Larger pages | page table overhead 감소, 큰 disk I/O transfer에 유리 | 평균 internal fragmentation 증가 |
현대 systems에서는 4 KB 또는 8 KB pages가 흔하고, 일부 systems는 2 MB 같은 larger pages 또는 huge pages를 지원한다. Page-table entry size도 architecture에 따라 다르다. 예를 들어 32-bit page-table entry가 4 bytes이고 frame size가 4 KB라면 이론상 개의 frames, 즉 bytes = 16 TB physical memory를 가리킬 수 있다. 하지만 page-table entry에는 frame number 외에도 protection, valid bit 같은 정보가 들어가므로 실제 addressable physical memory는 이론 최대보다 작을 수 있다.
Process가 도착하면 OS는 process size를 pages 단위로 본다. Process가 pages를 요구하면 적어도 free frames가 필요하다. 충분하면 OS는 각 page를 free frame에 load하고, 각 mapping을 process page table에 기록한다.

Figure 9.11 · PDF p. 470 · free-frame list에서 frames를 골라 새 process pages에 할당하고 page table을 채우는 과정
Paging의 중요한 성질은 programmer’s view와 actual physical memory의 분리다. Programmer는 memory를 자기 program만 담긴 하나의 연속된 logical space처럼 본다. 실제로는 user program pages가 physical memory 곳곳에 흩어져 있고, 그 사이에는 다른 programs도 있다. 이 차이는 address-translation hardware가 숨기며, mapping은 OS가 통제한다. User process는 자기 page table에 없는 memory를 address할 방법이 없으므로, 정의상 자신이 소유하지 않은 memory에 접근할 수 없다.
OS는 physical memory를 관리하므로 각 frame의 상태를 알아야 한다. 일반적으로 frame table이라는 system-wide data structure가 있고, physical page frame마다 free인지 allocated인지, allocated라면 어느 process의 어느 page에 속하는지 기록한다. System call에서 user가 buffer address를 parameter로 넘길 때처럼 OS가 logical address를 physical address로 직접 변환해야 하는 경우도 있으므로, OS는 process마다 page table copy를 유지한다. CPU dispatcher도 process를 CPU에 올릴 때 hardware page table을 설정하기 위해 이 정보를 사용한다. 따라서 paging은 context-switch time을 증가시킨다.
9.3.2 Hardware Support
Page table은 per-process data structure이므로 process control block (PCB)에는 instruction pointer 같은 registers와 함께 page table을 가리키는 정보가 저장된다. CPU scheduler가 process를 선택하면 user registers와 page-table 관련 hardware values를 reload해야 한다.
Page table 구현 방식은 여러 가지다. 가장 단순한 방식은 page table 전체를 dedicated high-speed hardware registers에 두는 것이다. Translation은 빠르지만, context switch 때 모든 registers를 교체해야 하므로 page table이 작을 때만 현실적이다.
현대 CPUs는 매우 큰 page tables를 지원하므로 page table 전체를 registers에 두기 어렵다. 대신 page table은 main memory에 두고, page-table base register (PTBR)가 current process page table의 시작 주소를 가리키게 한다. 이 경우 context switch 때 PTBR 하나만 바꾸면 되므로 context-switch overhead는 줄지만, memory access마다 page table을 읽어야 하는 문제가 생긴다.
9.3.2.1 Translation Look-Aside Buffer
Page table을 main memory에 두면 data 하나를 읽기 위해 memory access가 두 번 필요할 수 있다. 예를 들어 location i에 접근하려면 먼저 page table entry를 memory에서 읽어 frame number를 얻고, 그 다음 실제 data memory를 읽는다. 단순히 보면 memory access time이 2배가 되므로 대부분의 systems에서 받아들이기 어렵다.
이를 해결하는 hardware cache가 translation look-aside buffer (TLB)다. TLB는 작고 빠른 associative memory이며, page-table entries 일부를 저장한다. 각 TLB entry는 key/tag와 value로 구성된다. CPU가 logical address를 생성하면 MMU는 먼저 page number가 TLB에 있는지 검사한다.
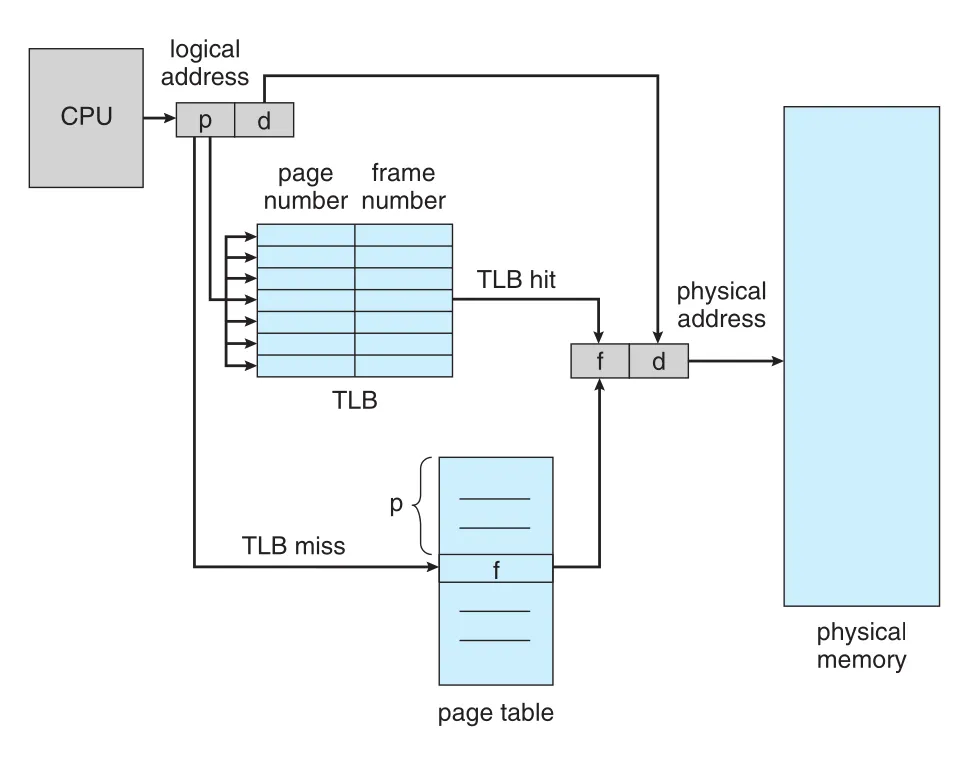
Figure 9.12 · PDF p. 473 · TLB hit이면 page table memory access 없이 frame number를 얻고, miss이면 page table을 조회한 뒤 TLB를 갱신하는 구조
TLB lookup은 현대 hardware에서 instruction pipeline의 일부로 수행되어, hit이면 paging이 없는 경우와 비교해 거의 추가 penalty가 없다. 하지만 pipeline step 안에 lookup을 끝내야 하므로 TLB는 작게 유지된다. 보통 32-1,024 entries 정도이고, instruction TLB와 data TLB를 분리하거나 multi-level TLB를 두는 CPUs도 있다.
TLB 동작은 다음과 같다.
| 경우 | 동작 | 비용 |
|---|---|---|
TLB hit | page number가 TLB에 있어 frame number를 즉시 얻고 memory를 접근한다. | 거의 한 번의 memory access 비용 |
TLB miss | page table을 memory에서 조회해 frame number를 얻고, 그 mapping을 TLB에 추가한 뒤 memory를 접근한다. | page-table lookup + data access |
TLB가 가득 차면 기존 entry를 교체해야 한다. Replacement policy는 LRU, round-robin, random 등 다양하다. 일부 CPUs는 OS가 replacement에 참여하게 하고, 일부는 hardware가 자체 처리한다. 또 어떤 TLB는 특정 entries를 wired down하여 제거되지 않게 할 수 있는데, 보통 key kernel code의 TLB entries가 이런 대상이다.
ASID (Address-Space Identifier)가 있는 TLB는 여러 processes의 translations를 동시에 담을 수 있다. TLB entry에는 virtual page number뿐 아니라 ASID가 함께 저장되고, 현재 실행 중인 process의 ASID와 entry ASID가 맞을 때만 hit로 인정된다. ASID가 없으면 context switch로 새 page table이 선택될 때마다 TLB를 flush해야 한다. 그렇지 않으면 이전 process의 valid virtual address가 새 process에서 잘못된 physical address로 해석될 수 있다.
TLB 성능은 hit ratio에 크게 좌우된다. Memory access가 10 ns이고, TLB hit이면 10 ns, miss이면 page table access 10 ns + data access 10 ns = 20 ns가 걸린다고 하자.
80% hit ratio에서는 평균 access time이 10 ns에서 12 ns로 20% 느려진다. 99% hit ratio에서는 10.1 ns로 약 1% slowdown에 그친다. Modern CPUs는 multi-level TLB를 제공하므로 실제 effective memory-access time 계산은 더 복잡하다. L1 TLB miss 후 L2 TLB를 확인하고, L2 miss이면 hardware가 page table walk를 수행하거나 OS interrupt가 필요할 수 있다. 이 때문에 OS designer는 특정 hardware platform의 TLB design을 이해하고 paging implementation을 맞춰야 한다.
9.3.3 Protection
Paged environment의 memory protection은 각 frame에 연결된 protection bits로 구현되며, 보통 page table entry 안에 저장된다. 가장 단순한 bit는 page가 read-write인지 read-only인지 나타낸다. 모든 memory reference는 frame number를 찾기 위해 page table을 거치므로, physical address를 계산하는 동시에 protection bits도 검사할 수 있다. Read-only page에 write하려 하면 hardware trap이 발생하고 OS는 memory-protection violation으로 처리한다.
Protection은 더 세분화할 수 있다. Hardware가 read-only, read-write, execute-only를 제공하거나, read/write/execute 각각에 별도 bits를 두어 조합을 허용할 수 있다. Illegal access는 OS로 trap된다.
Page table entry에는 일반적으로 valid-invalid bit도 있다. valid이면 해당 page가 process의 logical address space에 속하는 legal page이고, invalid이면 그 page는 process logical address space 밖이다.
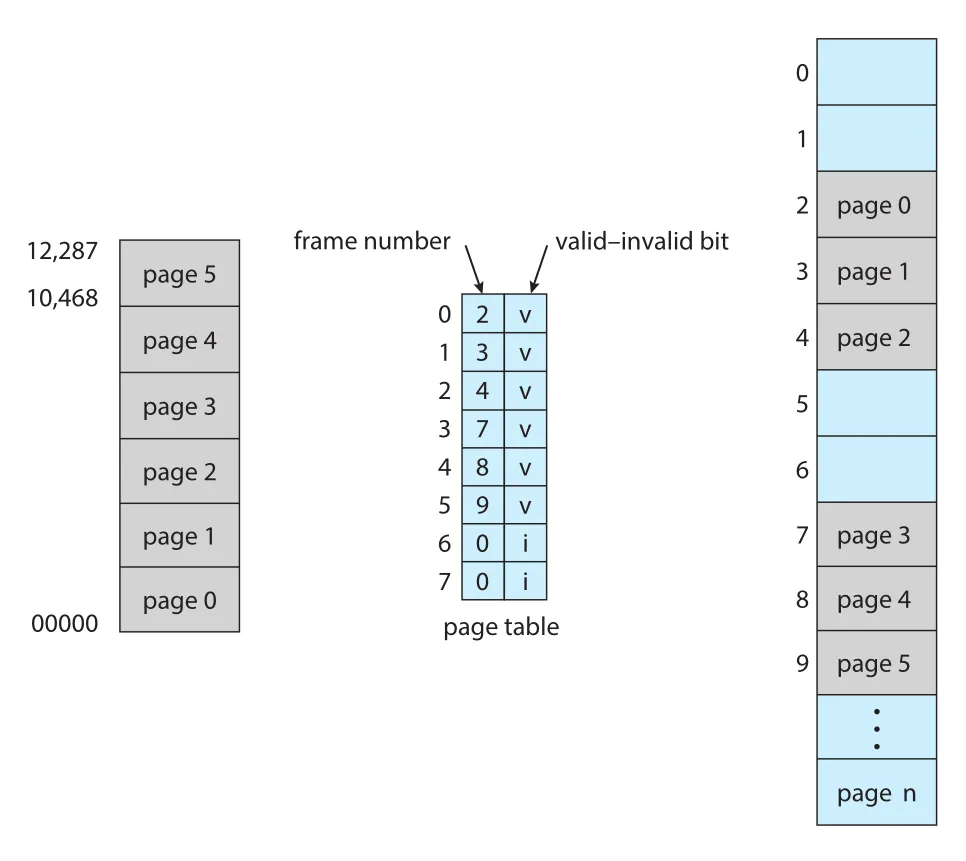
Figure 9.13 · PDF p. 475 · page table entry의 valid-invalid bit로 legal page와 invalid page reference를 구분하는 예
예를 들어 14-bit address space가 0부터 16383까지이고, program이 실제로 0부터 10468까지만 사용한다고 하자. Page size가 2 KB이면 pages 0-5는 valid로 표시되고, pages 6-7은 invalid로 표시된다. Pages 6 또는 7을 참조하면 invalid page reference trap이 발생한다.
다만 page 단위 protection은 internal fragmentation과 같은 경계 문제를 가진다. 위 예에서 program의 실제 끝은 address 10468이지만 page 5 전체가 valid이므로 10469부터 12287까지도 hardware상 valid reference가 된다. Page granularity 때문에 page 내부의 일부 unused address까지 legal하게 보일 수 있는 것이다.
Process가 전체 address range를 거의 쓰지 않는 경우, 모든 possible pages에 대해 page-table entries를 만드는 것은 낭비다. 일부 systems는 page-table length register (PTLR)를 제공해 page table size를 표시한다. Hardware는 logical address가 process의 valid page-table range 안에 있는지 검사하고, 실패하면 OS로 error trap을 보낸다.
9.3.4 Shared Pages
Paging은 common code sharing을 쉽게 만든다. 여러 processes가 같은 library code를 사용한다면 각 process가 자기 address space에 library copy를 따로 load하는 것은 memory 낭비다. 예를 들어 40 user processes가 각각 2 MB짜리 libc를 load하면 80 MB가 필요하다.
공유하려는 code가 reentrant code라면 physical memory에는 code pages 한 copy만 두고, 각 process의 page table이 같은 frames를 가리키게 만들 수 있다. Reentrant code는 execution 중 자기 자신을 수정하지 않는 non-self-modifying code다. 각 process는 자기 registers와 data storage를 따로 가지므로, code pages만 공유하고 process-specific data는 분리할 수 있다.
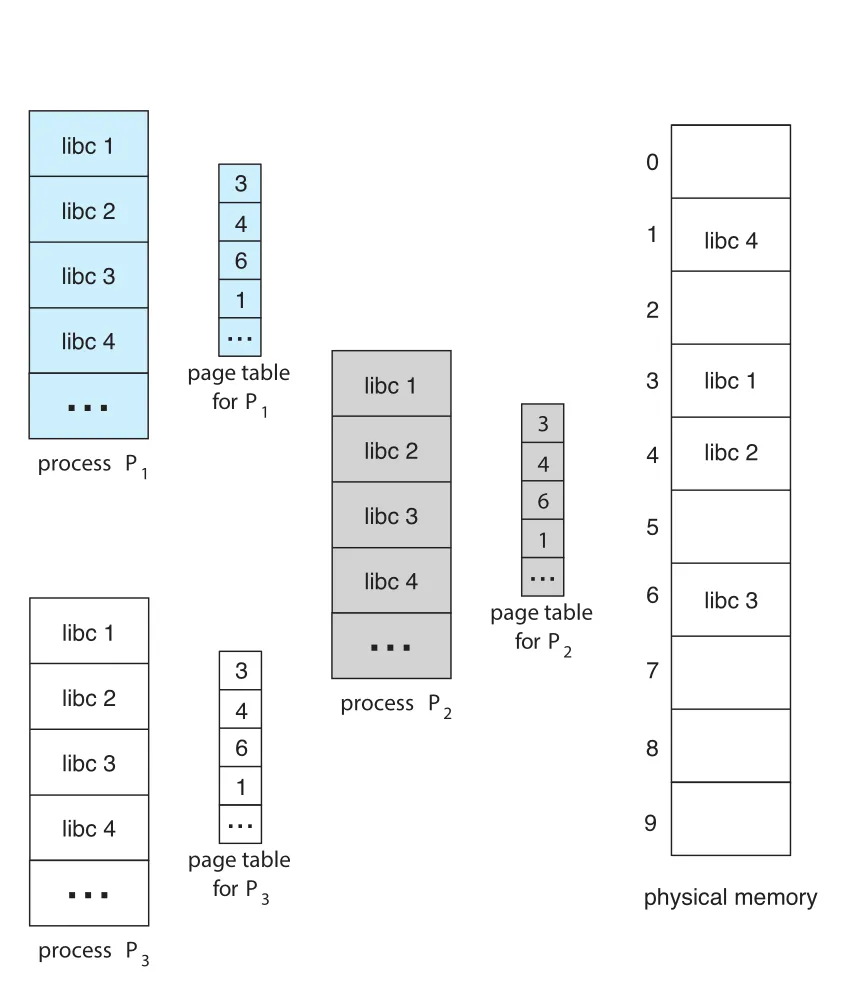
Figure 9.14 · PDF p. 476 · 여러 processes의 page tables가 같은 physical libc pages를 가리켜 standard C library를 공유하는 구조
이 방식에서는 40 processes가 libc를 사용해도 physical memory에는 2 MB copy 하나만 있으면 된다. Standard C library뿐 아니라 compilers, window systems, database systems처럼 많이 쓰이는 programs도 shared pages의 대상이 될 수 있다. Section 9.1.5의 shared libraries는 보통 shared pages로 구현된다.
공유 code가 read-only라는 사실을 code의 선의에 맡기면 안 된다. OS는 page-table protection bits를 통해 shared code pages를 read-only로 강제해야 한다. Memory sharing은 Chapter 4의 threads가 task address space를 공유하는 것과 유사하고, Chapter 3의 shared memory IPC도 일부 OS에서 shared pages로 구현된다. Paging의 여러 추가 장점, 특히 demand paging과 virtual memory의 효과는 Chapter 10에서 이어진다.
9.4 Structure of the Page Table
Paging의 기본 구조는 단순하지만, modern systems의 logical address space는 매우 크다. 32-bit에서 64-bit로 갈수록 page table 자체가 너무 커져 “page table을 어디에 어떻게 둘 것인가”가 별도의 설계 문제가 된다. Section 9.4는 대표 구조인 hierarchical paging, hashed page tables, inverted page tables를 비교한다.
9.4.1 Hierarchical Paging
큰 logical address space에서는 linear page table 하나가 과도하게 커질 수 있다. 예를 들어 32-bit logical address space와 4 KB () page size를 가진 system을 생각하자. Page table은 , 즉 1 million entries 이상을 가질 수 있다. Entry 하나가 4 bytes라면 process마다 page table만 최대 4 MB physical memory를 요구한다. 이런 page table을 contiguous main memory에 통째로 두고 싶지는 않다.
간단한 해결은 page table을 smaller pieces로 나누는 것이다. two-level paging에서는 page table 자체도 paging된다.
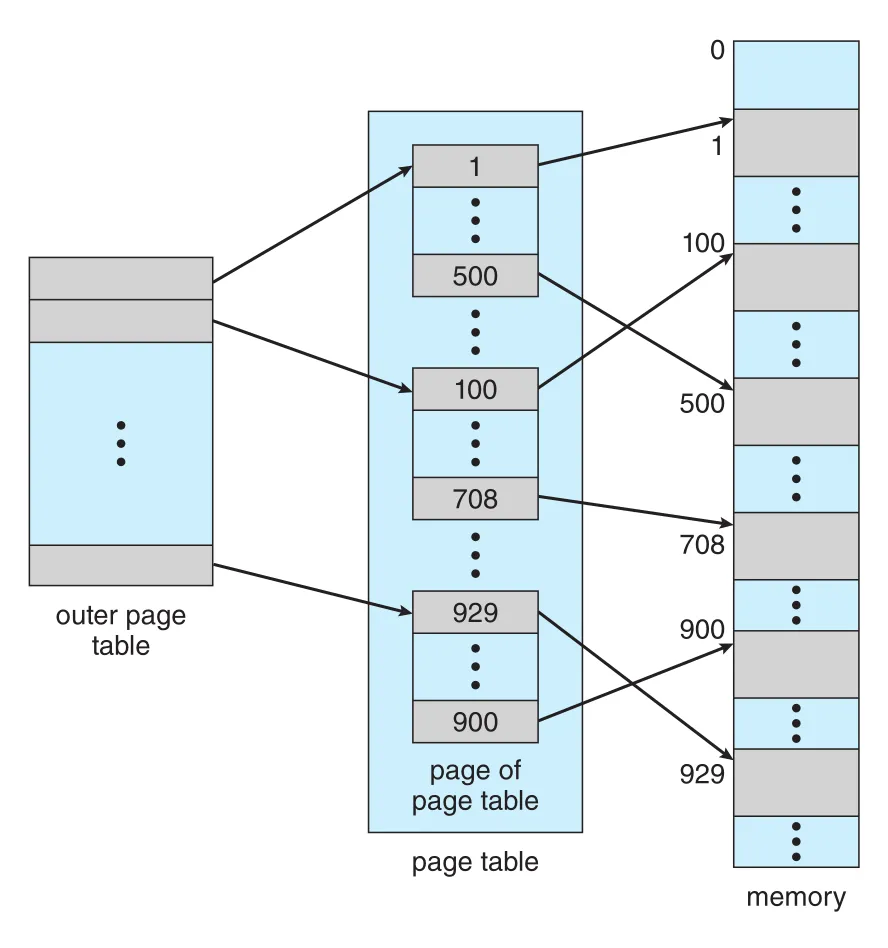
Figure 9.15 · PDF p. 478 · outer page table이 inner page-table pages를 가리키는 two-level page-table scheme
32-bit logical address와 4 KB page size에서는 logical address가 20-bit page number와 12-bit offset으로 나뉜다. Page table도 paging하므로 20-bit page number를 다시 10-bit outer index와 10-bit inner index로 나눈다.
은 outer page table의 index이고, 는 inner page table page 안의 displacement다. Translation은 outer page table에서 시작해 안쪽으로 들어가므로 이 구조를 forward-mapped page table이라고도 한다.
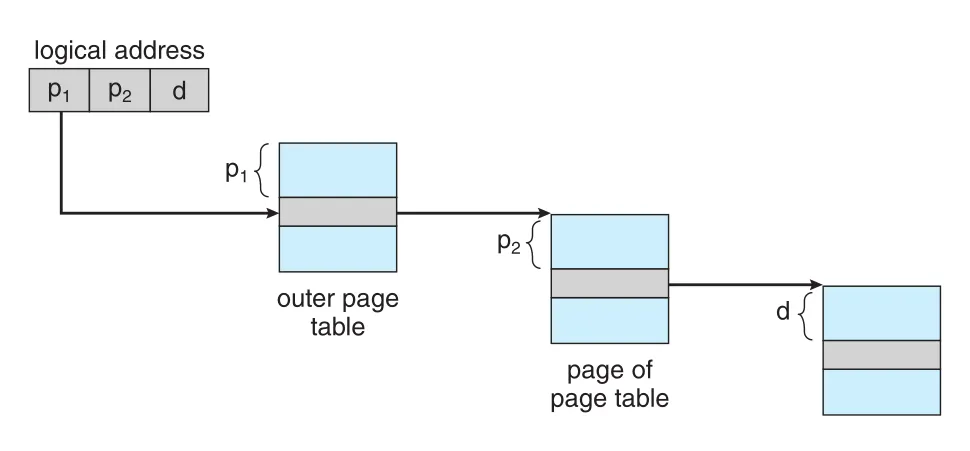
Figure 9.16 · PDF p. 479 · 32-bit two-level paging에서 p1으로 outer table을 찾고 p2로 inner table entry를 찾아 frame을 얻는 과정
하지만 64-bit logical address space에서는 two-level paging이 충분하지 않다. Page size가 4 KB이면 page table은 최대 entries를 가질 수 있다. Inner page table을 한 page 크기, 즉 개의 4-byte entries로 맞추면 outer page table은 entries, bytes가 된다. Outer page table 자체가 너무 크다.
Outer page table을 다시 paging하면 three-level paging이 되지만, 64-bit address space에서는 여전히 큰 구조가 남는다. 계속 더 나누면 four-level, seven-level paging까지 갈 수 있지만, level이 늘수록 logical address 하나를 translate하기 위해 필요한 memory accesses가 증가한다. 그래서 순수 hierarchical page tables는 64-bit architectures에서 부적절해질 수 있다. 실제 systems는 TLB, larger pages, sparse mapping, hashed/inverted structures를 함께 사용해 비용을 줄인다.
9.4.2 Hashed Page Tables
32 bits보다 큰 address spaces를 다루는 한 방법은 hashed page table이다. Hash key는 virtual page number다. Hash table의 각 entry는 같은 location으로 hash된 elements의 linked list를 가리킨다. 각 element는 세 fields를 가진다.
| Field | 의미 |
|---|---|
| virtual page number | 이 mapping이 어떤 virtual page에 대한 것인지 |
| mapped page frame | 대응되는 physical frame number |
| next pointer | collision chain의 다음 element |
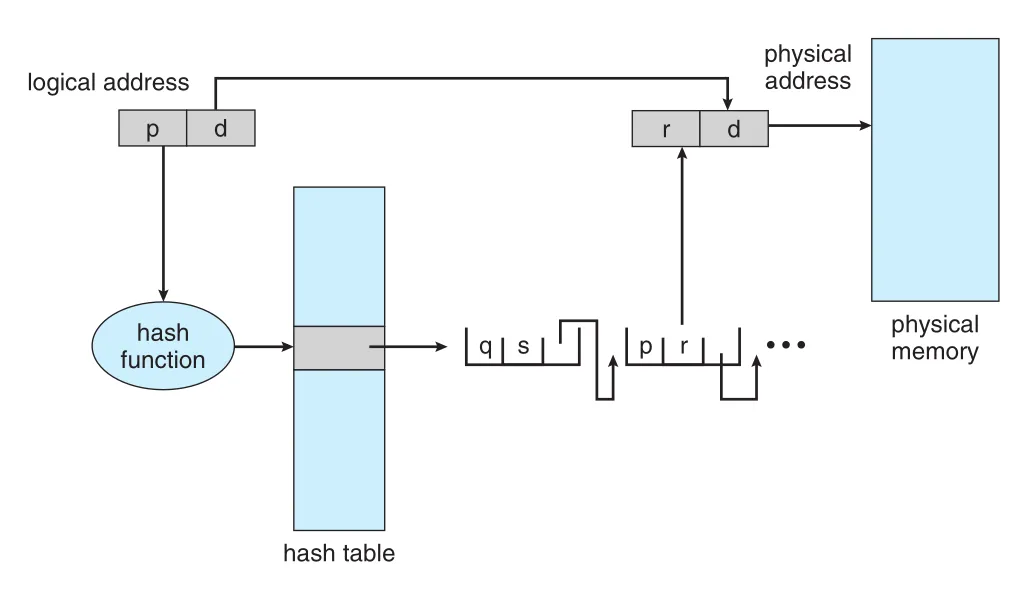
Figure 9.17 · PDF p. 479 · virtual page number를 hash해 collision chain에서 matching page를 찾고 frame number를 얻는 hashed page table
Algorithm은 다음과 같다.
- Virtual address의 virtual page number를 hash table에 hash한다.
- 해당 bucket의 linked list 첫 element와 virtual page number를 비교한다.
- Match되면 mapped frame number를 사용해 physical address를 만든다.
- Match되지 않으면 linked list의 다음 entries를 순서대로 찾는다.
64-bit address spaces에는 clustered page tables 변형이 유용할 수 있다. Clustered page table은 hash table entry 하나가 single page가 아니라 여러 pages, 예를 들어 16 pages의 mappings를 담는다. Memory references가 address space 전체에 noncontiguous하게 흩어진 sparse address spaces에서 특히 유용하다.
9.4.3 Inverted Page Tables
일반 paging에서는 process마다 page table이 있고, process가 사용하는 각 virtual page 또는 가능한 virtual address slot마다 entry를 가진다. 이 구조는 virtual address로 page를 참조하는 process 관점에서는 자연스럽지만, process마다 millions of entries를 둘 수 있어 page tables 자체가 많은 physical memory를 소비한다.
inverted page table은 방향을 뒤집는다. Process별로 virtual pages 수만큼 entries를 두는 대신, system 전체에 physical frame마다 하나의 entry만 둔다. 각 entry는 그 real memory frame에 저장된 page의 virtual address와 owner process 정보를 담는다. 즉 page table 크기는 virtual address space 크기가 아니라 physical memory frame 수에 비례한다.
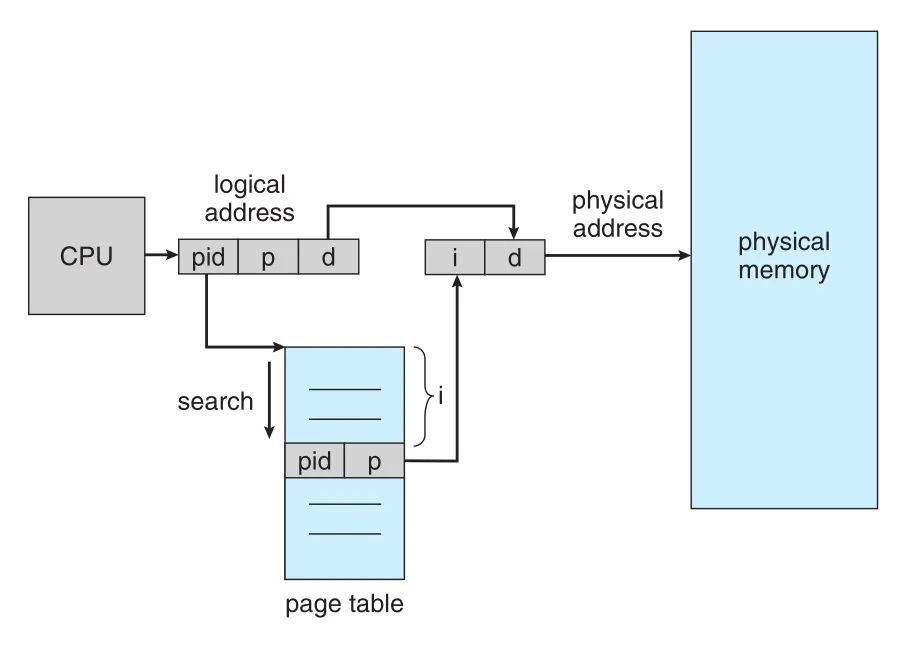
Figure 9.18 · PDF p. 480 · process id와 page number로 inverted page table을 검색해 physical frame index를 찾는 구조
Inverted page table은 여러 address spaces가 하나의 table에 섞이므로 각 entry에 address-space identifier (ASID) 또는 process id가 필요하다. 단순화하면 virtual address는 다음 triple로 볼 수 있다.
Memory reference가 발생하면 <process-id, page-number>를 inverted page table에서 찾는다. Match가 entry i에서 발견되면 physical address는 <i, offset>이 된다. Match가 없으면 illegal address access다.
Inverted page table의 장점은 page table memory 사용량을 줄인다는 것이다. 단점은 lookup time이다. Table은 physical address 순서로 정렬되어 있지만 lookup key는 virtual address이므로, naive하게는 table 전체를 search해야 할 수 있다. 이를 줄이기 위해 hash table을 함께 사용해 search 범위를 하나 또는 몇 개 entries로 제한한다. 그러나 hash table access 자체도 memory reference를 추가하므로, TLB miss 후 path가 비싸질 수 있다.
또 하나의 중요한 trade-off는 shared memory다. Standard paging에서는 여러 process page tables가 같은 physical frame을 가리키면 shared memory가 자연스럽다. Inverted page table은 physical frame마다 virtual page entry가 하나뿐이므로, 하나의 physical page가 둘 이상의 shared virtual addresses를 동시에 entry로 가질 수 없다. 따라서 다른 process가 shared memory를 참조하면 page fault가 발생하고 mapping이 다른 virtual address로 교체될 수 있다.
9.4.4 Oracle SPARC Solaris
Oracle SPARC Solaris 예시는 64-bit CPU와 OS가 virtual memory overhead를 줄이기 위해 얼마나 tight하게 결합될 수 있는지 보여 준다. Solaris는 multi-level page tables만으로 physical memory를 낭비하지 않기 위해 hashed page tables를 사용한다. Kernel용 hash table과 all user processes용 hash table을 두고, 각 hash-table entry는 single page가 아니라 contiguous mapped virtual memory area를 나타낸다. Entry에는 base address와 span, 즉 몇 pages를 대표하는지가 들어간다.
Virtual-to-physical translation을 매번 hash table search로 처리하면 너무 느리므로 CPU는 fast hardware lookup을 위한 TLB를 둔다. 또 최근 접근한 pages의 translation table entries (TTEs)를 담는 translation storage buffer (TSB)를 사용한다. Translation 흐름은 다음과 같다.
virtual address reference
-> TLB lookup
-> TLB miss이면 in-memory TSB walk
-> TSB hit이면 TSB entry를 TLB로 copy
-> TSB miss이면 kernel interrupt
-> kernel이 hash table search 후 TTE 생성
-> TTE를 TSB에 저장
-> MMU가 translation 완료이 예시는 세부 구현 암기보다 구조적 교훈이 중요하다. Large virtual address space에서 page table 구조, TLB design, OS interrupt path, hardware page-table walk는 분리된 주제가 아니라 하나의 performance-critical translation pipeline이다.
9.5 Swapping
Process instructions와 data는 실행되려면 memory에 있어야 한다. 하지만 process 전체 또는 일부는 임시로 memory에서 backing store로 나갔다가, 이후 계속 실행하기 위해 다시 memory로 들어올 수 있다. 이것이 swapping이다. Swapping은 모든 processes의 total physical address space가 실제 physical memory보다 커지는 것을 허용하므로, system의 degree of multiprogramming을 높인다.
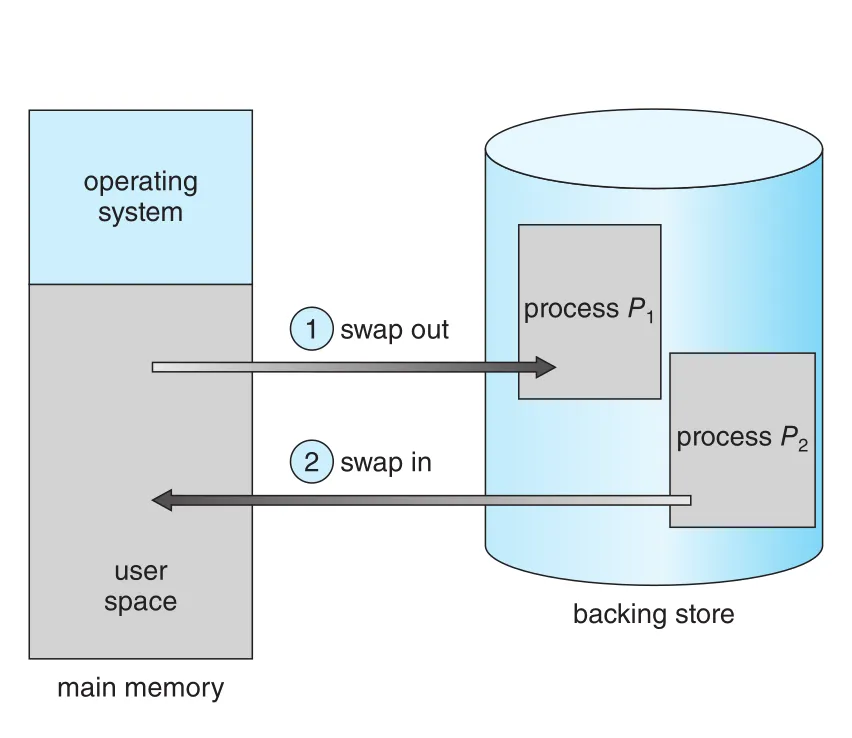
Figure 9.19 · PDF p. 482 · disk backing store를 이용해 process P1을 swap out하고 process P2를 swap in하는 standard swapping
9.5.1 Standard Swapping
standard swapping은 entire process를 main memory와 backing store 사이에서 이동시킨다. Backing store는 보통 빠른 secondary storage이며, 저장/복원해야 할 process memory images를 담을 만큼 충분히 커야 하고 direct access를 제공해야 한다. Process가 backing store로 나갈 때는 process와 관련된 data structures도 함께 저장되어야 한다. Multithreaded process라면 per-thread data structures도 swap 대상이다. OS는 swapped-out processes를 다시 memory로 복원하기 위한 metadata도 유지해야 한다.
Standard swapping의 장점은 physical memory oversubscription이다. 실제 physical memory보다 더 많은 processes를 system에 수용할 수 있다. Idle 또는 mostly idle processes는 좋은 swap candidates이고, 이 processes가 차지하던 memory는 active processes에 줄 수 있다. Swapped-out process가 다시 active해지면 memory로 swap in되어야 한다.
9.5.2 Swapping with Paging
Traditional UNIX systems는 standard swapping을 사용했지만, contemporary OS에서는 entire process를 backing store와 memory 사이에서 옮기는 시간이 너무 커서 일반적으로 사용하지 않는다. Solaris도 available memory가 극도로 낮은 dire circumstances에서만 standard swapping을 사용한다.
Linux와 Windows를 포함한 대부분의 systems는 process 전체가 아니라 process의 pages를 swap한다. 이 방식은 physical memory oversubscription을 허용하면서도 entire process 이동 비용을 피한다. 보통 소수의 pages만 swapping에 관여하기 때문이다.
현대 문맥에서 용어는 다소 구분된다.
| 용어 | 의미 |
|---|---|
swapping | 보통 standard swapping, 즉 entire process 이동을 가리킴 |
paging | pages 단위로 backing store와 memory 사이를 이동하는 swapping with paging을 가리킴 |
page out | page를 memory에서 backing store로 내보냄 |
page in | page를 backing store에서 memory로 가져옴 |
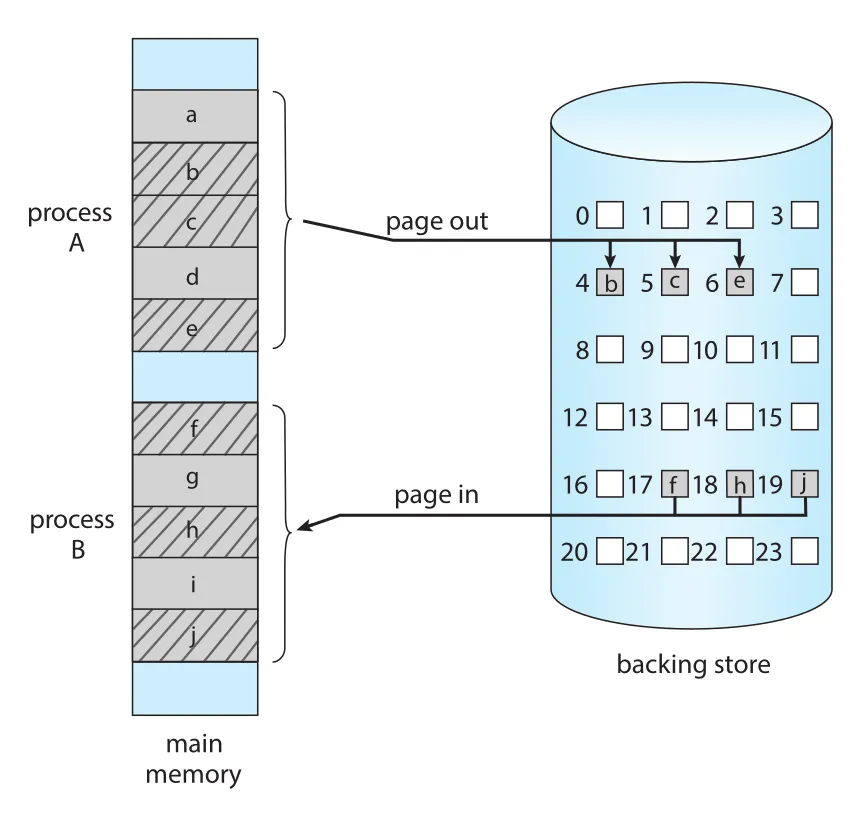
Figure 9.20 · PDF p. 484 · processes A와 B의 일부 pages만 page out/page in하는 swapping with paging
Swapping with paging은 Chapter 10의 virtual memory와 잘 결합된다. Virtual memory에서는 process 전체를 memory에 올리지 않고 필요한 pages만 memory에 유지하며, page fault가 나면 필요한 page를 page in할 수 있다.
9.5.3 Swapping on Mobile Systems
PC와 server OS는 pages swapping을 지원하는 경우가 많지만, mobile systems는 보통 어떤 형태의 swapping도 지원하지 않는다. Mobile devices는 nonvolatile storage로 spacious hard disk가 아니라 flash memory를 사용한다. Flash storage는 공간 제약이 있고, write 횟수 제한이 있으며, main memory와 flash memory 사이 throughput도 낮기 때문에 swapping에 불리하다.
그래서 mobile OS는 다른 memory pressure 대응 전략을 쓴다. iOS는 free memory가 threshold 아래로 떨어지면 applications에 allocated memory를 자발적으로 반납하도록 요청한다. Read-only data, 예를 들어 code는 main memory에서 제거했다가 필요하면 flash에서 다시 load할 수 있다. 하지만 stack처럼 modified data는 제거하지 않는다. 충분한 memory를 내놓지 못한 application은 OS에 의해 terminate될 수 있다.
Android도 비슷하게 free memory가 부족하면 process를 terminate할 수 있다. 다만 terminate 전에 application state를 flash memory에 기록해 빠르게 restart할 수 있게 한다. 따라서 mobile systems 개발자는 memory allocation/release를 조심스럽게 관리해 memory leaks와 excessive memory usage를 피해야 한다.
Swapping이 발생한다는 것은 종종 active processes가 available physical memory보다 많다는 신호다. Pages 단위 swapping이 entire process swapping보다 효율적이더라도, sustained swapping은 성능 저하를 뜻한다. 근본적 대응은 active workload를 줄이거나 physical memory를 늘리는 것이다.
9.6 Example: Intel 32- and 64-bit Architectures
Intel architecture 예시는 특정 chip history를 외우기 위한 부분이 아니라, 실제 mainstream architecture가 앞에서 배운 segmentation, paging, hierarchical paging, PAE, TLB를 어떻게 결합하는지 보여 주는 사례다. 여기서는 IA-32와 x86-64의 memory-management concepts만 남긴다.
9.6.1 IA-32 Architecture
IA-32 memory management는 segmentation과 paging 두 단계로 나뉜다. CPU가 logical address를 만들면 segmentation unit이 이를 linear address로 바꾼다. 그 linear address가 paging unit으로 들어가 physical address로 변환된다. 이 두 unit이 합쳐져 MMU 역할을 한다.
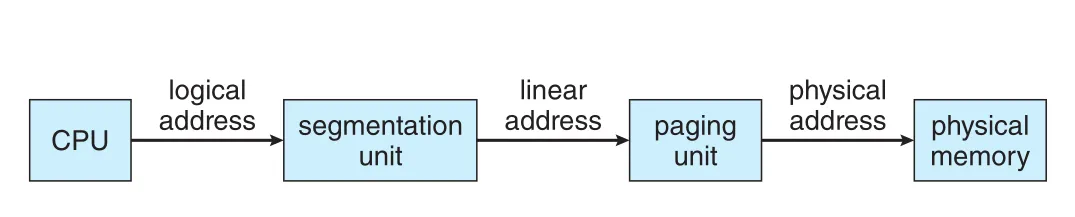
Figure 9.21 · PDF p. 485 · IA-32에서 logical address가 segmentation unit을 거쳐 linear address가 되고, paging unit을 거쳐 physical address가 되는 흐름
CPU logical address
-> segmentation unit
-> linear address
-> paging unit
-> physical address
-> physical memory9.6.1.1 IA-32 Segmentation
IA-32에서 segment는 최대 4 GB까지 가능하고, process당 최대 16 K segments를 가질 수 있다. Process logical address space는 두 partitions로 나뉜다.
| Partition | Segment 수 | 저장 table | 의미 |
|---|---|---|---|
| private segments | up to 8 K | LDT | 해당 process에 private |
| shared segments | up to 8 K | GDT | 모든 processes가 공유 |
LDT (local descriptor table)와 GDT (global descriptor table)의 각 entry는 8-byte segment descriptor이며, segment의 base location, limit, protection 정보 등을 담는다.
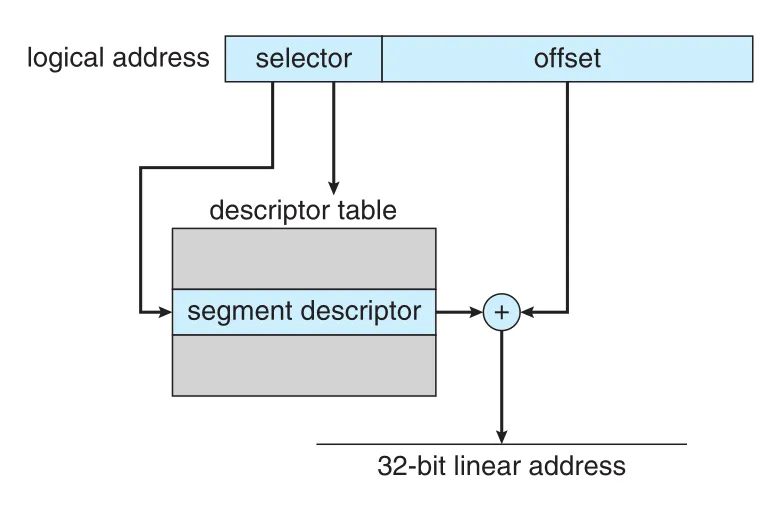
Figure 9.22 · PDF p. 486 · selector가 descriptor table entry를 고르고 segment base와 offset을 더해 32-bit linear address를 만드는 과정
IA-32 logical address는 (selector, offset) pair다. Selector는 16-bit이고 다음 fields로 나뉜다.
Offset은 해당 segment 안의 byte 위치를 나타내는 32-bit number다. Segment register는 LDT 또는 GDT의 적절한 entry를 가리킨다. Hardware는 먼저 descriptor의 limit으로 offset이 valid한지 검사한다. Invalid이면 memory fault가 발생해 OS로 trap된다. Valid이면 descriptor의 base에 offset을 더해 32-bit linear address를 만든다.
9.6.1.2 IA-32 Paging
IA-32는 4 KB 또는 4 MB page size를 지원한다. 4 KB pages에서는 32-bit linear address를 10-bit page directory index, 10-bit page table index, 12-bit offset으로 나누는 two-level paging을 사용한다.
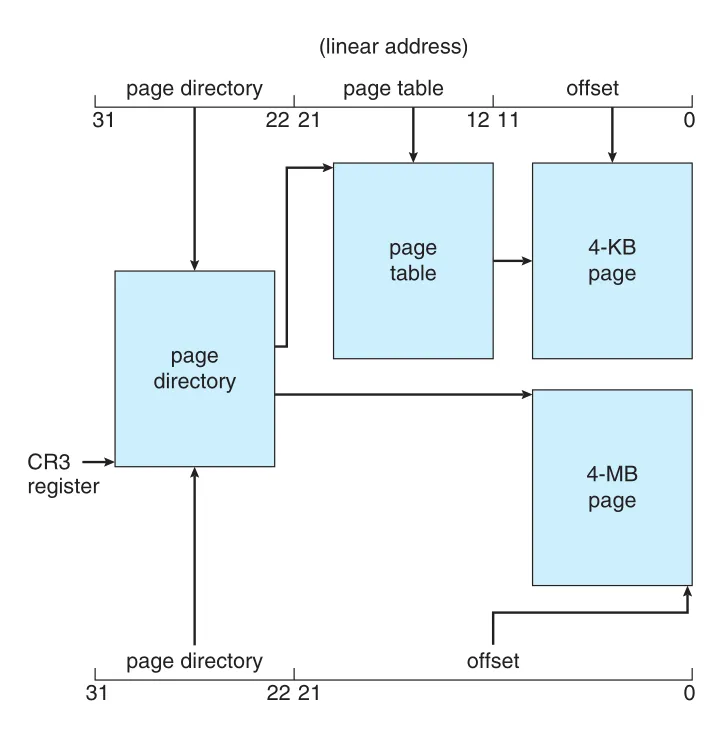
Figure 9.23 · PDF p. 487 · CR3가 page directory를 가리키고, page directory와 page table을 거쳐 4-KB page frame을 찾는 IA-32 paging
상위 10 bits는 IA-32가 page directory라고 부르는 outer page table entry를 선택한다. CR3 register는 current process의 page directory를 가리킨다. Page directory entry는 inner page table을 가리키고, 다음 10 bits가 page table entry를 고른다. 하위 12 bits는 4-KB page 내부 offset이다.
Page directory entry에는 Page Size flag가 있다. 이 flag가 set되면 page frame size가 4 MB라는 뜻이고, inner page table을 건너뛰어 page directory entry가 직접 4-MB page frame을 가리킨다. 이때 linear address의 하위 22 bits가 4-MB page frame offset이다.
IA-32 page tables 자체도 disk로 swap될 수 있다. Page directory entry의 invalid bit는 해당 entry가 가리키는 table이 memory에 있는지 disk에 있는지 나타낼 수 있다. Table이 disk에 있으면 OS는 나머지 bits로 disk location을 표현하고, 필요할 때 table을 memory로 가져올 수 있다.
32-bit architecture의 4-GB memory limitation을 완화하기 위해 IA-32는 page address extension (PAE)를 도입했다. PAE는 two-level paging을 three-level scheme으로 확장하고, top two bits가 page directory pointer table을 가리키게 한다.
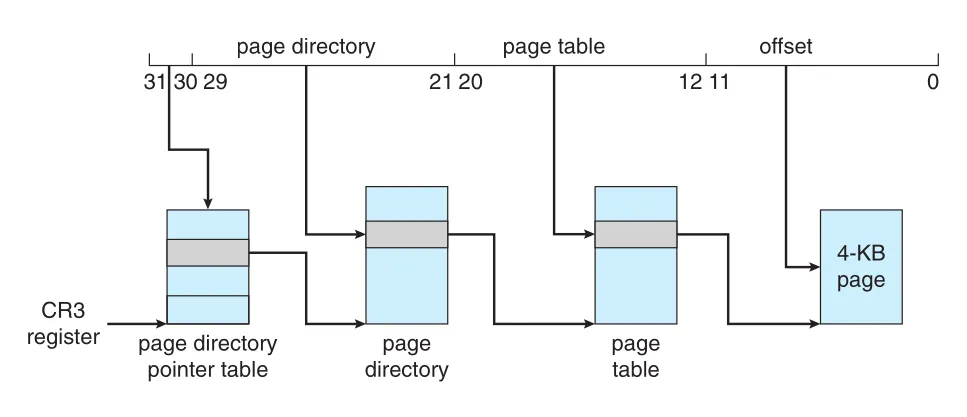
Figure 9.24 · PDF p. 488 · PAE에서 page directory pointer table을 추가해 IA-32 physical address space를 확장하는 구조
PAE는 page-directory/page-table entries를 32 bits에서 64 bits로 키웠고, page tables와 page frames의 base address field를 20 bits에서 24 bits로 확장했다. 여기에 12-bit offset을 더하면 36-bit address space가 되어 최대 64 GB physical memory를 지원할 수 있다. 단, PAE 사용에는 OS support가 필요하다.
9.6.2 x86-64
x86-64는 IA-32 instruction set을 확장한 64-bit architecture다. 이론적으로 64-bit address space는 bytes를 표현할 수 있지만, 현재 설계에서는 실제로 모든 64 bits를 address representation에 쓰지는 않는다. x86-64는 현재 48-bit virtual address를 제공하고, 4 KB, 2 MB, 1 GB page sizes를 지원하며, four-level paging hierarchy를 사용한다. PAE를 사용할 수 있어 virtual address는 48 bits지만 physical address는 52 bits, 즉 4,096 TB까지 지원한다.

Figure 9.25 · PDF p. 488 · x86-64에서 48-bit linear address를 four-level paging index와 offset으로 나누는 구조
4-KB pages 기준으로 x86-64 linear address는 다음처럼 읽으면 된다.
핵심은 64-bit architecture라고 해서 항상 64-bit virtual address 전체를 paging index로 쓰는 것이 아니라는 점이다. 현재 systems는 architecture가 허용하는 큰 주소 공간 중 일부 bits만 실제 translation에 사용하고, page sizes와 multi-level hierarchy로 translation overhead와 page-table memory overhead를 조절한다.
9.7 Example: ARMv8 Architecture
ARMv8은 64-bit ARM architecture 예시다. ARM은 mobile devices와 embedded systems에서 널리 쓰이며, 이 절의 핵심도 market history가 아니라 ARMv8이 page size, region size, multi-level paging, TLB를 어떻게 구성하는가이다.
ARMv8에는 세 가지 translation granules가 있다.
| Translation granule size | Page size | Region size |
|---|---|---|
| 4 KB | 4 KB | 2 MB, 1 GB |
| 16 KB | 16 KB | 32 MB |
| 64 KB | 64 KB | 512 MB |
4-KB와 16-KB granules에서는 최대 four levels of paging을 사용할 수 있고, 64-KB granules에서는 최대 three levels of paging을 사용할 수 있다. ARMv8은 64-bit architecture지만 현재는 48 bits만 사용한다.

Figure 9.26 · PDF p. 490 · ARMv8 4-KB translation granule에서 48-bit address를 level 0-3 indexes와 offset으로 나누는 구조
4-KB granule에서 address는 level 0, level 1, level 2, level 3 indexes와 12-bit offset으로 나뉜다.
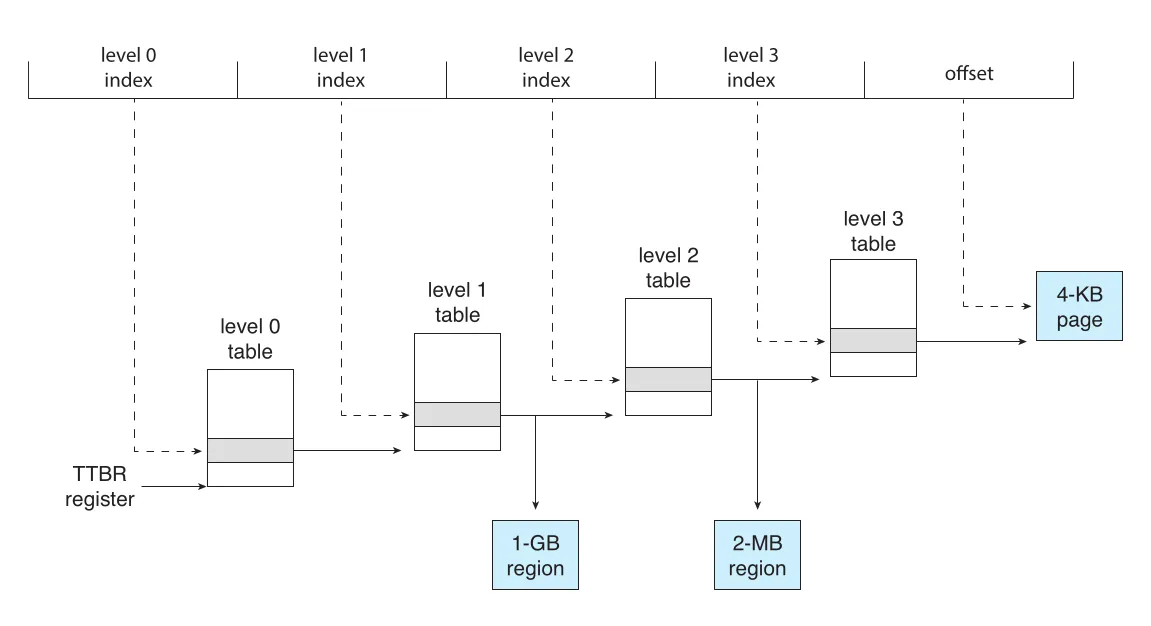
Figure 9.27 · PDF p. 490 · TTBR이 level 0 table을 가리키고, table entries가 다음 table 또는 큰 region을 가리키는 ARMv8 four-level hierarchical paging
TTBR (translation table base register)는 current thread의 level 0 table을 가리킨다. 모든 four levels를 사용하면 offset bits 0-11은 4-KB page 내부 offset이다. 하지만 level 1과 level 2 table entries는 다음 table을 가리키는 대신 큰 region을 직접 가리킬 수도 있다. Level-1 entry가 1-GB region을 가리키면 low-order 30 bits가 1-GB region 내부 offset이 되고, level-2 entry가 2-MB region을 가리키면 low-order 21 bits가 2-MB region 내부 offset이 된다.
ARM architecture도 two levels of TLBs를 지원한다. Inner level에는 data용 micro TLB와 instruction용 micro TLB가 있고, micro TLB도 ASID를 지원한다. Outer level에는 single main TLB가 있다. Address translation은 micro-TLB lookup에서 시작하고, miss이면 main TLB를 확인한다. 둘 다 miss이면 hardware page table walk가 수행된다.
연결 관계
Chapter 9는 앞 장들과 뒤 장들을 이어 주는 memory-management 중심축이다.
| 연결 대상 | 연결 내용 |
|---|---|
| Chapter 1 | main memory, registers, cache, hardware protection의 기반 개념을 사용한다. |
| Chapter 2 | program loading, linker/loader, process context와 연결된다. |
| Chapter 3 | shared memory IPC가 shared pages로 구현될 수 있다. |
| Chapter 4 | threads가 address space를 공유하는 것과 shared pages의 memory sharing이 구조적으로 닮아 있다. |
| Chapter 5 | CPU scheduling으로 여러 processes를 실행하려면 여러 processes가 memory에 함께 있어야 한다. |
| Chapter 10 | paging, page in/page out, valid-invalid bit, backing store가 demand paging과 virtual memory로 확장된다. |
| Chapter 11-15 | fragmentation과 block management 문제는 storage management에서도 다시 등장한다. |
오해하기 쉬운 내용
logical address와 physical address는 항상 다르지 않다. Compile-time 또는 load-time binding에서는 같을 수 있고, execution-time binding에서 달라진다. 이때 logical address를 virtual address라고도 부른다.
base register와 relocation register는 맥락상 같은 아이디어를 가리킨다. Base/limit protection에서는 legal physical range의 시작이 base이고, execution-time mapping에서는 logical address에 더하는 값이 relocation register다.
Paging은 external fragmentation을 없애지만 memory 낭비를 완전히 없애지는 않는다. Page/frame 단위 allocation 때문에 마지막 frame에 internal fragmentation이 생길 수 있고, page tables 자체도 memory를 소비한다.
TLB는 OS가 아니라 hardware cache지만, OS 설계와 무관하지 않다. ASID 지원 여부, TLB flush 비용, wired entries, hardware page-table walk 방식은 context switch와 page table design에 직접 영향을 준다.
shared library와 shared pages는 같은 층위의 용어가 아니다. Shared library는 user/program/library 수준의 기능이고, shared pages는 이를 실제 physical memory에서 한 copy로 공유하게 만드는 paging mechanism이다.
swapping은 현대 문맥에서 혼동되기 쉽다. 책은 entire process 이동을 standard swapping이라고 설명하고, 현대 OS의 일반적 방식은 pages 단위 page out/page in이며 Chapter 10의 virtual memory와 연결된다.
64-bit architecture라고 해서 반드시 64-bit address 전체를 현재 hardware가 translation에 쓰는 것은 아니다. x86-64와 ARMv8 모두 현재 설명에서는 48-bit virtual address 구조를 사용한다.
면접 질문
logical address와physical address의 차이는 무엇이고,MMU는 어느 시점에 개입하는가?compile-time,load-time,execution-time address binding의 차이와 trade-off는 무엇인가?base register와limit register만으로 memory protection을 어떻게 구현할 수 있는가?first fit,best fit,worst fit은 각각 어떤 hole을 선택하며, 왜first fit이 일반적으로 빠른가?external fragmentation과internal fragmentation의 차이를 contiguous allocation과 paging 예로 설명하라.- Paging에서 logical address
(p, d)가 physical address(f, d)로 바뀌는 과정을 설명하라. - Page size를 크게 잡을 때와 작게 잡을 때의 trade-off는 무엇인가?
- Page table을 main memory에 두면 왜 TLB가 필요한가?
TLB hit ratio가 effective memory-access time에 어떤 영향을 주는가?ASID가 없는 TLB에서는 context switch 때 왜 TLB flush가 필요한가?valid-invalid bit와 protection bits는 각각 어떤 illegal access를 막는가?shared pages가shared libraries의 memory 사용량을 어떻게 줄이는가?- 64-bit address space에서 single-level 또는 simple hierarchical page table이 왜 문제가 되는가?
hashed page table과inverted page table은 각각 어떤 page-table memory 문제를 해결하고, 어떤 비용을 만든다?standard swapping과swapping with paging의 차이는 무엇인가?- IA-32에서 segmentation과 paging은 address translation pipeline에서 각각 어떤 역할을 하는가?
PAE는 IA-32의 어떤 한계를 어떻게 완화하는가?- x86-64와 ARMv8이 64-bit architecture이면서도 48-bit virtual address를 사용하는 이유를 어떻게 이해해야 하는가?