Chapter 10. Virtual Memory
- 과목: Operating System
- 기준 교재: Operating System Concepts 10th
- 관련 페이지: PDF pp. 501-553
- 우선순위: 필수
개요
Chapter 9의 memory-management strategies는 여러 processes를 memory에 동시에 두어 multiprogramming을 가능하게 하는 것이 목표였다. 하지만 대부분 “process 전체가 physical memory에 있어야 실행 가능하다”는 제약을 전제로 한다. virtual memory는 이 제약을 깨고, process가 완전히 memory에 있지 않아도 실행되게 하는 기법이다.
Virtual memory의 장점은 단순히 “program이 physical memory보다 커질 수 있다”가 아니다. Programmer가 보는 logical memory를 실제 physical memory와 분리해 매우 큰 uniform storage array처럼 보이게 만들고, 필요한 pages만 memory에 올려 CPU utilization과 throughput을 높이며, files/libraries/shared memory/process creation을 효율화한다. 반대로 careless하게 쓰면 page fault와 I/O 때문에 performance가 급격히 나빠질 수 있다.
핵심 개념
| 개념 | 핵심 의미 |
|---|---|
virtual memory | process 전체가 physical memory에 없어도 실행되게 하고, logical memory와 physical memory를 분리하는 memory-management technique. |
virtual address space | process가 보는 logical/virtual memory layout. 보통 text, data, heap, stack이 있는 contiguous view로 보인다. |
sparse address space | heap과 stack 사이의 hole처럼 virtual address space에는 있지만 실제 physical pages는 필요할 때만 할당되는 address space. |
demand paging | page가 실제로 참조될 때만 memory에 load하는 virtual memory 구현 방식. |
valid-invalid bit | demand paging에서 page가 legal and in memory인지, invalid이거나 secondary storage에 있는지 구분하는 page-table bit. |
page fault | process가 memory에 없는 page를 참조해 hardware가 OS로 trap하는 event. |
pure demand paging | page가 필요해질 때까지 절대 memory에 가져오지 않는 방식. 첫 instruction부터 page fault로 시작할 수 있다. |
swap device, swap space | memory에 없는 pages를 저장하는 secondary storage와 그 영역. |
free-frame list | page fault 해결, heap/stack expansion 등에 쓸 수 있는 free frames pool. |
zero-fill-on-demand | free frame을 allocation하기 전에 0으로 지워 이전 process data를 노출하지 않는 기법. |
effective access time | memory access와 page fault service time을 확률적으로 합친 평균 access time. |
anonymous memory | file과 직접 연결되지 않은 process memory. stack, heap이 대표적이며 swap space나 compression 대상이 된다. |
copy-on-write (COW) | parent/child가 처음에는 pages를 공유하다가 write가 발생한 page만 copy하는 process creation optimization. |
vfork() | parent를 suspend하고 child가 parent address space를 직접 쓰는 UNIX 계열 fork 변형. child가 곧바로 exec()할 때 사용해야 한다. |
page replacement | free frame이 없을 때 기존 frame의 page를 victim으로 골라 내보내고 desired page를 가져오는 기법. |
victim frame | replacement algorithm이 내보내기로 선택한 frame. |
modify bit, dirty bit | page가 memory에 들어온 뒤 write되어 secondary storage와 달라졌는지 표시하는 hardware bit. |
reference string | replacement algorithm 평가에 쓰는 page number sequence. |
FIFO page replacement | memory에 가장 먼저 들어온 oldest page를 먼저 replace하는 algorithm. |
Belady's anomaly | 일부 algorithms에서 frames 수를 늘렸는데도 page faults가 증가하는 현상. FIFO가 대표적이다. |
OPT, MIN | 앞으로 가장 오래 사용되지 않을 page를 replace하는 optimal page-replacement algorithm. 실제 구현보다 비교 기준으로 쓴다. |
LRU | Least Recently Used. 과거에 가장 오래 사용되지 않은 page를 replace하는 OPT approximation. |
stack algorithm | frames가 n개일 때의 resident pages set이 n+1개일 때의 resident set의 subset이 되는 algorithm. Belady’s anomaly가 없다. |
reference bit | page가 read/write로 reference될 때 hardware가 set하는 bit. LRU approximation에 사용된다. |
additional-reference-bits algorithm | reference bit history를 shift register처럼 저장해 최근 사용성을 근사하는 algorithm. |
second-chance, clock algorithm | FIFO에 reference bit를 더해 recently used page에 한 번 더 기회를 주는 LRU approximation. |
enhanced second-chance | reference bit와 modify bit를 함께 고려해 clean and not recently used page를 우선 replace하는 clock 변형. |
LFU, MFU | Least Frequently Used, Most Frequently Used. reference count 기반 replacement algorithms. |
page buffering | free-frame pool, modified-page list, old-page cache 등을 유지해 replacement penalty를 줄이는 보조 기법. |
raw I/O, raw disk | database 같은 application이 OS file-system buffering을 우회해 storage partition을 logical blocks array처럼 직접 쓰는 방식. |
equal allocation | available frames를 processes 수로 균등하게 나누는 frame-allocation policy. |
proportional allocation | process size 또는 priority 비율에 따라 frames를 나누는 policy. |
global replacement | process가 자기 frames뿐 아니라 다른 process frames에서도 victim을 고를 수 있는 replacement scope. |
local replacement | process가 자기 allocated frames 안에서만 victim을 고르는 replacement scope. |
major page fault, minor page fault | backing store read가 필요한 fault와, page는 memory에 있지만 mapping만 없는 fault. |
reaper | free memory가 threshold 아래로 떨어지면 pages를 reclaim해 free-frame list를 채우는 kernel routine. |
OOM killer | Linux에서 free memory가 매우 낮을 때 process를 terminate해 memory를 확보하는 routine. |
NUMA | Non-Uniform Memory Access. CPU마다 local memory latency가 달라 frame placement가 performance에 영향을 주는 architecture. |
thrashing | process가 executing보다 paging에 더 많은 시간을 쓰는 high paging activity 상태. |
locality | program execution 중 함께 active하게 사용되는 pages set. |
working set | 최근 Δ page references 안에 등장한 pages set. current locality의 approximation. |
working-set window Δ | working set을 정의하기 위해 보는 최근 memory references 범위. |
| process 의 working-set size. process 가 현재 active하게 필요로 하는 frame 수로 볼 수 있다. | |
PFF | Page-Fault Frequency. page-fault rate upper/lower bounds로 frames를 조절하는 thrashing control strategy. |
memory compression | modified frames를 swap space로 내보내는 대신 여러 frames를 압축해 하나의 frame에 저장하는 memory-saving technique. |
compression ratio | compression으로 원래 크기 대비 얼마나 줄였는지 나타내는 비율. 보통 speed와 trade-off가 있다. |
buddy system | physically contiguous pages segment를 power-of-2 units로 쪼개고 coalescing할 수 있는 kernel memory allocator. |
coalescing | free buddies를 합쳐 더 큰 contiguous segment를 만드는 buddy system operation. |
slab allocation | kernel data structure별 cache와 slab을 두고 preallocated objects를 빠르게 할당/회수하는 kernel memory allocation scheme. |
slab, cache, object | slab은 contiguous pages 묶음, cache는 특정 kernel object type의 slabs 집합, object는 cache 안의 실제 할당 단위. |
prepaging | page faults를 줄이기 위해 곧 필요할 pages 일부 또는 전체를 미리 memory에 가져오는 기법. |
TLB reach | TLB entries가 직접 cover할 수 있는 memory 양. . |
huge pages | TLB reach를 늘리기 위해 일반 page보다 큰 page size를 쓰는 기능. Linux의 예가 대표적이다. |
I/O interlock | I/O 중인 user buffer page가 replacement되지 않도록 보장해야 하는 문제. |
page locking, pinning | 특정 pages/frames를 memory에 고정해 replacement 대상에서 제외하는 기법. |
lock bit | frame이 locked 상태라 replacement될 수 없음을 나타내는 bit. |
active list, inactive list | Linux에서 recently used pages와 reclaim 대상 pages를 나누어 관리하는 lists. |
kswapd | Linux page-out daemon. free memory가 threshold 아래로 떨어지면 inactive list를 scan해 pages를 reclaim한다. |
working-set trimming | Windows에서 free memory threshold 회복을 위해 processes working sets에서 pages를 제거하는 global replacement tactic. |
pageout | Solaris에서 free memory가 threshold 아래로 떨어지면 pages를 scan/reclaim하는 process. |
scanrate, slowscan, fastscan | Solaris page scanner가 pages를 초당 얼마나 scan할지 조절하는 parameters. |
lotsfree, desfree, minfree | Solaris free memory thresholds. scanning, aggressive pageout, swapping trigger와 연결된다. |
priority paging | Solaris가 process pages와 regular file pages 등을 구분해 reclaim priority를 다르게 두는 policy. |
세부 정리
10.1 Background
Virtual memory가 필요한 이유는 “실행 중인 instruction은 physical memory에 있어야 한다”는 기본 요구 때문이다. 가장 단순한 해결은 entire logical address space를 physical memory에 올리는 것이다. 하지만 실제 programs를 보면 전체 program이 항상 필요한 것은 아니다.
대표적으로 error-handling code는 거의 실행되지 않을 수 있고, arrays/lists/tables는 실제보다 크게 allocate되는 경우가 많으며, 특정 options/features는 드물게 사용된다. 심지어 전체 program이 결국 필요하더라도, 같은 시점에 모두 필요하지는 않을 수 있다.
Process가 부분적으로만 memory에 있어도 실행 가능하면 다음 이점이 생긴다.
| 이점 | 의미 |
|---|---|
| 더 큰 program 실행 | program size가 physical memory size에 묶이지 않는다. |
| 더 많은 processes 동시 실행 | process당 필요한 physical memory가 줄어 CPU utilization과 throughput이 증가할 수 있다. |
| I/O 감소 | 필요한 부분만 load/swap하므로 program startup과 execution이 빨라질 수 있다. |
| programmer 부담 감소 | physical memory 크기를 덜 의식하고 problem solving에 집중할 수 있다. |
Virtual memory는 developer가 보는 logical memory와 실제 physical memory를 분리한다. 작은 physical memory만 있어도 매우 큰 virtual memory를 제공할 수 있다.
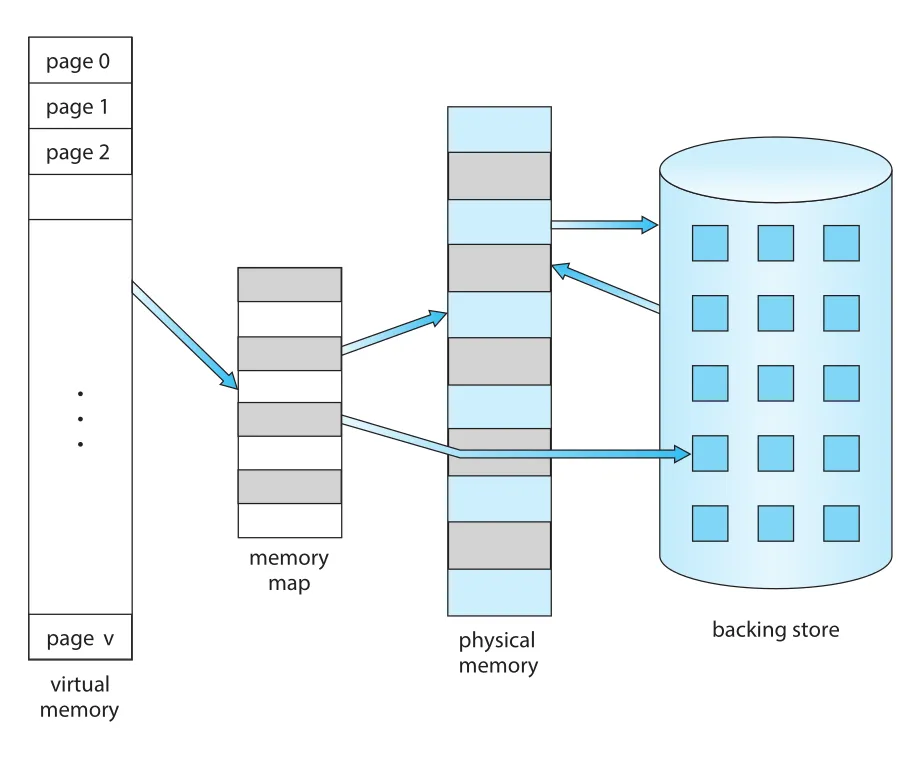
Figure 10.1 · PDF p. 503 · virtual memory가 physical memory보다 크고, 일부 page만 physical memory에 mapping되는 구조
Process의 virtual address space는 보통 address 0부터 시작하는 contiguous memory처럼 보인다. 하지만 Chapter 9의 paging 관점에서 실제 physical memory는 page frames로 구성되고, process pages는 physical frames 여기저기에 noncontiguous하게 배치될 수 있다. 이 mapping은 MMU가 담당한다.
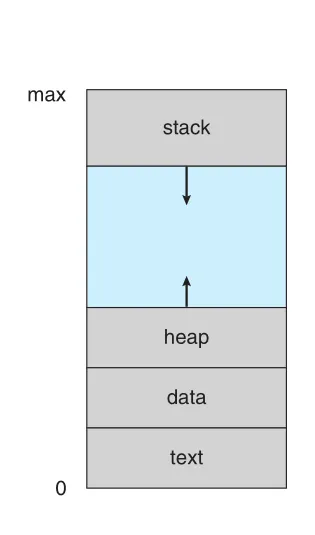
Figure 10.2 · PDF p. 503 · text, data, heap, stack으로 구성된 process virtual address space와 heap/stack 사이의 hole
Heap은 dynamic memory allocation에 따라 upward로 자라고, stack은 function calls에 따라 downward로 자란다. Heap과 stack 사이의 large blank space는 virtual address space에는 있지만, 실제 heap/stack이 자라 그 영역을 쓰기 전까지 physical pages가 필요하지 않다. 이런 hole을 포함한 address space가 sparse address space다. Sparse address space는 stack/heap growth와 dynamic libraries/shared objects mapping에 유리하다.
Virtual memory는 page sharing으로 files와 memory를 둘 이상의 processes가 공유하게 한다.
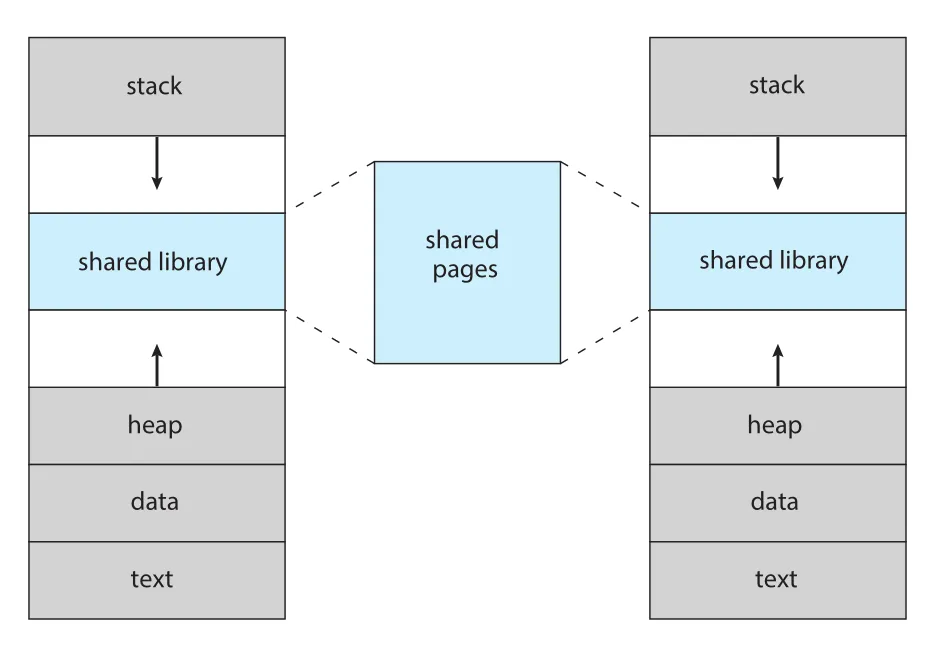
Figure 10.3 · PDF p. 504 · 각 process의 virtual address space에 library가 있는 것처럼 보이지만 physical shared pages는 하나만 존재하는 구조
System libraries, 예를 들어 standard C library는 각 process의 virtual address space에 mapping되지만, 실제 physical pages는 모든 processes가 공유할 수 있다. 보통 library는 각 process 공간에 read-only로 mapping된다. Chapter 3의 shared memory IPC도 virtual memory를 통해 구현될 수 있다. Process creation에서도 fork() 시 pages를 공유하면 child creation을 빠르게 만들 수 있으며, 이 아이디어가 Section 10.3의 copy-on-write로 이어진다.
10.2 Demand Paging
Executable program을 secondary storage에서 memory로 load하는 가장 단순한 방식은 program 전체를 physical memory에 올리는 것이다. 하지만 program 시작 시 모든 options/features의 code가 필요하지 않을 수 있다. demand paging은 대안적으로 pages를 실제로 요구될 때만 load한다. 접근되지 않는 pages는 physical memory에 들어오지 않는다.
Demand-paged virtual memory는 Chapter 9의 swapping with paging과 닮았다. Processes는 secondary memory, 보통 HDD 또는 NVM device에 있고, 필요한 pages만 main memory로 들어온다. 이 때문에 memory는 더 효율적으로 사용된다.
10.2.1 Basic Concepts
Demand paging에서는 process 실행 중 일부 pages는 memory에 있고, 일부 pages는 secondary storage에 있다. Hardware는 둘을 구분해야 하며, Chapter 9의 valid-invalid bit를 사용할 수 있다. 다만 demand paging에서 invalid의 의미는 두 가지다.
| Bit 상태 | 의미 |
|---|---|
valid | page가 legal하고 현재 memory에 있다. |
invalid | page가 process logical address space 밖이거나, legal하지만 현재 secondary storage에 있다. |
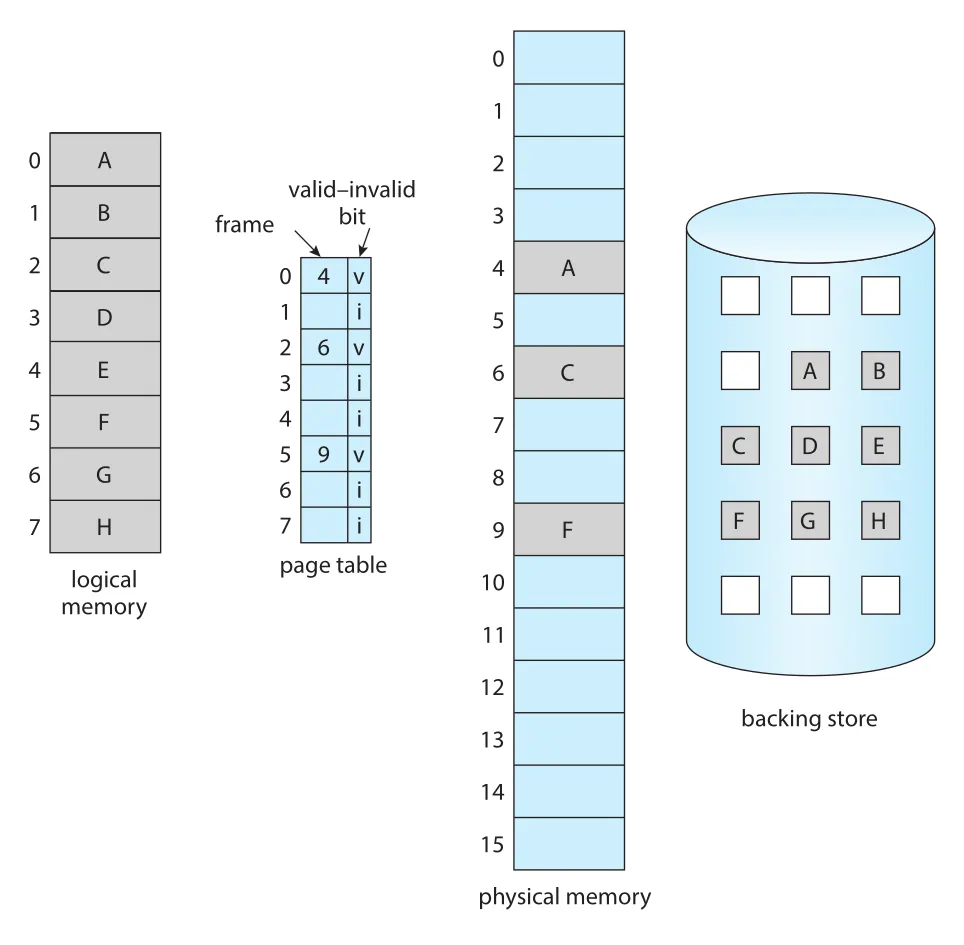
Figure 10.4 · PDF p. 505 · 일부 pages는 physical memory에 있고 나머지는 backing store에 있어 page table entry가 invalid로 표시되는 demand paging 상태
Process가 invalid로 표시된 page를 참조하면 page fault가 발생한다. Paging hardware가 page table translation 중 invalid bit를 보고 OS로 trap한다. 이 trap은 desired page를 아직 memory에 가져오지 않은 OS의 지연 load 결과다.
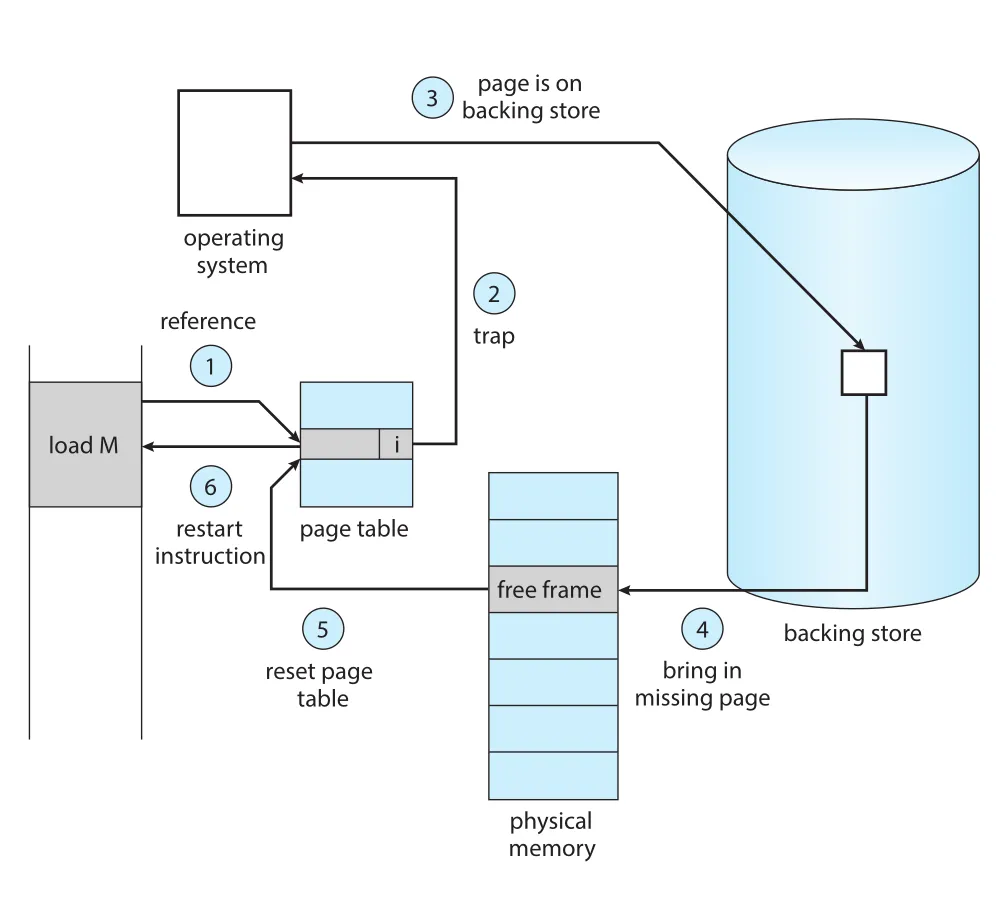
Figure 10.5 · PDF p. 506 · page fault 발생 후 reference 검사, free frame 확보, missing page read, page table 갱신, instruction restart까지의 흐름
Page fault 처리 절차는 다음과 같다.
- Process의 internal table, 보통
PCB와 함께 유지되는 정보를 확인해 reference가 valid memory access인지 검사한다. - Invalid reference이면 process를 terminate한다. Valid하지만 page가 memory에 없으면 page in을 진행한다.
free-frame list등에서 free frame을 찾는다.- Secondary storage에서 desired page를 새 frame으로 read하도록 I/O를 schedule한다.
- Read가 끝나면 process internal table과 page table을 수정해 page가 memory에 있음을 표시한다.
- Trap으로 중단된 instruction을 restart한다. 이제 process는 page가 원래 memory에 있었던 것처럼 접근한다.
극단적으로 process를 memory에 page 하나도 없이 시작할 수 있다. OS가 instruction pointer를 첫 instruction으로 설정하면 그 instruction이 있는 page가 memory에 없으므로 즉시 page fault가 난다. Page를 가져온 뒤 실행을 계속하고, 필요한 pages마다 fault가 발생한다. 필요한 모든 pages가 memory에 들어온 뒤에는 더 이상 fault 없이 실행된다. 이것이 pure demand paging이다.
Theoretically, 한 instruction이 instruction page와 여러 data pages를 동시에 새로 참조해 multiple page faults per instruction을 만들 수도 있다. 그러면 성능은 받아들일 수 없을 정도로 나빠진다. 하지만 실제 programs는 locality of reference를 보이므로 demand paging은 일반적으로 reasonable performance를 낸다.
Demand paging을 지원하는 hardware는 paging/swapping과 같다.
| Hardware/Storage | 역할 |
|---|---|
page table | valid-invalid bit 또는 protection bits 특수값으로 page resident 여부를 표현한다. |
secondary memory | main memory에 없는 pages를 저장한다. swap device와 swap space가 여기에 해당한다. |
Demand paging의 중요한 요구는 page fault 후 instruction을 정확히 restart할 수 있어야 한다는 것이다. Page fault 시 registers, condition code, instruction counter 같은 process state를 저장하므로, desired page가 memory에 들어온 뒤 fault가 난 instruction을 같은 상태에서 다시 수행해야 한다.
Instruction fetch에서 fault가 나면 instruction을 다시 fetch하면 된다. Operand fetch에서 fault가 나면 instruction을 다시 fetch/decode하고 operand를 다시 fetch한다. ADD A, B -> C 같은 three-address instruction에서 store C 시점에 fault가 나면 page를 가져오고 page table을 고친 뒤 instruction 전체를 다시 실행한다. 반복되는 작업은 한 instruction보다 작고, page fault 때만 필요하다.
어려운 경우는 한 instruction이 여러 memory locations를 수정하는 architecture다. 예를 들어 IBM System 360/370의 MVC (move character) instruction은 source/destination blocks가 page boundary를 걸치거나 overlap될 수 있다. Fault가 partial modification 뒤에 발생하면 단순 restart가 위험하다. 해결 방법은 fault 가능 pages를 미리 touch해 modification 전에 fault를 발생시키거나, overwritten locations를 temporary registers에 보관했다가 fault 시 원상복구하는 것이다. 즉 demand paging은 “paging을 CPU와 memory 사이에 끼우면 끝”이 아니라, architecture가 restartable instructions를 제공해야 제대로 동작한다.
10.2.2 Free-Frame List
Page fault가 발생하면 OS는 desired page를 secondary storage에서 main memory로 가져와야 한다. 대부분의 OS는 page fault 처리를 위해 free-frame list를 유지한다. 이 list는 page-in 요청과 stack/heap expansion 때 사용할 free frames pool이다.

Figure 10.6 · PDF p. 508 · page fault와 stack/heap growth를 처리하기 위해 OS가 유지하는 free-frame list
OS는 보통 zero-fill-on-demand를 사용한다. Frame을 allocation하기 전에 0으로 지워 이전 contents를 제거한다. 그렇지 않으면 새 process가 이전 process의 memory contents를 볼 수 있어 security 문제가 된다.
System startup 때 available memory는 free-frame list에 들어간다. Demand paging으로 free frames가 소비되면 list는 줄어든다. 어느 시점에 list가 0이 되거나 threshold 아래로 떨어지면 OS는 page replacement 같은 전략으로 list를 다시 채워야 한다.
10.2.3 Performance of Demand Paging
Demand paging의 성능은 page-fault rate에 극도로 민감하다. Memory access time을 ma, page fault probability를 p라고 하면 effective access time은 다음과 같다.
Page fault service에는 trap, process state save, fault 원인 확인, reference legality 검사, page location 확인, storage read, 다른 process 실행 가능성, I/O completion interrupt, page table update, process 재스케줄링, state restore가 포함될 수 있다. 핵심 구성은 세 가지다.
- page-fault interrupt service
- missing page read
- interrupted process restart
HDD를 paging device로 쓰는 예에서 average page-fault service time을 8 ms, memory access time을 200 ns라고 하자.
1,000번 중 1번만 page fault가 나도 effective access time은 약 8.2 us가 되어 40배 느려진다. Performance degradation을 10% 미만으로 유지하려면 대략 p < 0.0000025, 즉 399,990 memory accesses당 page fault가 1번보다 적어야 한다. 따라서 demand-paging system에서 low page-fault rate는 성능의 생명줄이다.
Swap space handling도 중요하다. Swap space I/O는 file system I/O보다 빠른 편이다. 큰 blocks로 allocation되고 file lookup/indirect allocation을 거치지 않기 때문이다. 한 방법은 process startup 때 entire file image를 swap space로 복사한 뒤 swap space에서 demand paging하는 것이다. 단점은 startup copy 비용이다.
Linux와 Windows를 포함한 여러 OS는 처음에는 file system에서 demand-page하고, replacement 시 pages를 swap space에 기록한다. 이렇게 하면 필요한 pages만 file system에서 읽고 이후 paging은 swap space에서 처리할 수 있다. Binary executable file의 read-only demand pages는 modified되지 않으므로 replacement 때 overwrite해도 되고, 필요하면 file system에서 다시 읽으면 된다. 반면 stack/heap 같은 anonymous memory는 file과 연결되어 있지 않으므로 swap space가 필요하다.
Mobile OS는 일반적으로 swapping을 지원하지 않는다. 대신 file system에서 demand-page하고, memory pressure가 있으면 read-only pages를 reclaim한다. iOS에서는 anonymous memory pages가 application terminate 또는 explicit release 전에는 reclaim되지 않는다. Mobile systems에서는 Section 10.7의 memory compression이 swapping 대안으로 중요해진다.
10.3 Copy-on-Write
fork()는 child process를 parent의 duplicate로 만든다. 전통적 방식은 parent address space의 pages를 child에게 모두 copy하는 것이다. 하지만 많은 child processes는 생성 직후 exec()를 호출해 새 program으로 바뀐다. 이 경우 parent address space를 미리 copy한 비용은 낭비가 된다.
copy-on-write (COW)는 parent와 child가 처음에는 같은 pages를 공유하게 하고, 둘 중 하나가 shared page에 write하려 할 때만 그 page를 copy한다. Shared pages는 copy-on-write pages로 marked된다.
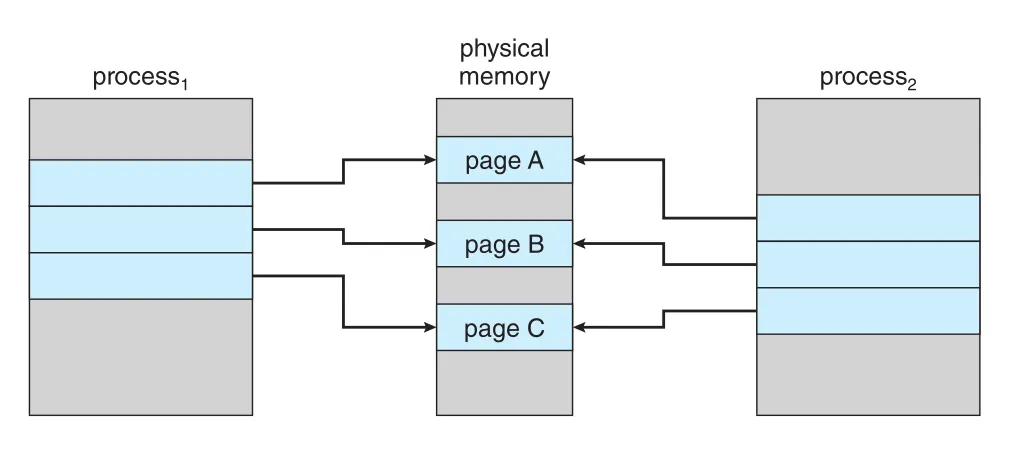
Figure 10.7 · PDF p. 512 · process 1과 process 2가 page A, B, C를 공유하고 있는 copy-on-write 전 상태
예를 들어 child가 stack 일부가 들어 있는 COW page를 수정하려 하면 OS는 free-frame list에서 frame을 얻고 해당 page copy를 만든다. Child page table은 새 copy를 가리키도록 바뀌고, child는 parent의 page가 아니라 자기 copy를 수정한다.
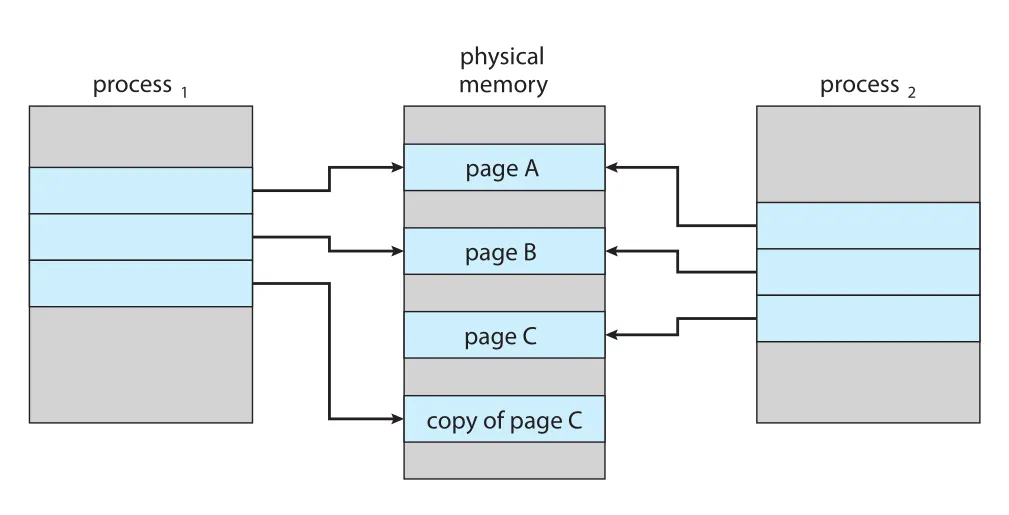
Figure 10.8 · PDF p. 512 · process 1이 page C를 수정하자 page C copy가 만들어지고 modified process만 새 page를 가리키는 상태
COW를 쓰면 modified pages만 copy되고, unmodified pages는 parent/child가 계속 공유한다. Executable code pages처럼 수정될 수 없는 pages는 애초에 COW가 아니라 read-only shared pages로 공유하면 된다. Windows, Linux, macOS가 모두 COW를 사용한다.
UNIX 계열의 vfork()는 COW fork와 다르다. vfork()에서는 parent process가 suspend되고 child가 parent address space를 그대로 사용한다. COW를 쓰지 않으므로 child가 parent address space의 pages를 수정하면 parent가 resume했을 때 그 변경이 보인다. 따라서 vfork()는 child가 creation 직후 곧바로 exec()를 호출할 때만 조심해서 사용해야 한다.
10.4 Page Replacement
앞의 demand paging 설명에서는 page가 처음 참조될 때 최대 한 번만 fault난다고 단순화했다. 하지만 multiprogramming degree를 높이면 physical memory는 over-allocated될 수 있다. 예를 들어 각 process가 10 pages 크기지만 실제로 5 pages만 쓴다고 보고 더 많은 processes를 실행했는데, 어느 순간 각 process가 10 pages를 모두 필요로 하면 available frames가 부족해진다.
System memory는 program pages만 담지 않는다. I/O buffers도 많은 memory를 소비한다. 어떤 systems는 I/O buffers에 fixed percentage를 배정하고, 어떤 systems는 processes와 I/O subsystem이 전체 memory를 두고 경쟁하게 한다. 따라서 virtual memory policy는 I/O buffering policy와도 연결된다.
Free-frame list가 비어 있는데 page fault가 발생하면 OS는 desired page의 secondary storage 위치를 알아도 넣을 frame이 없다.
Figure 10.9 · PDF p. 514 · page fault가 났지만 free frame이 없어 page replacement가 필요한 상황
Process를 terminate하는 것은 paging의 transparency 목표와 맞지 않는다. Entire process를 standard swapping으로 빼는 것도 현대 OS에서는 비용이 너무 크다. 그래서 대부분의 OS는 pages 단위 swapping과 page replacement를 결합한다.
10.4.1 Basic Page Replacement
page replacement는 free frame이 없을 때 현재 덜 필요한 frame을 골라 비우고, 그 frame에 fault를 일으킨 desired page를 load하는 방식이다.
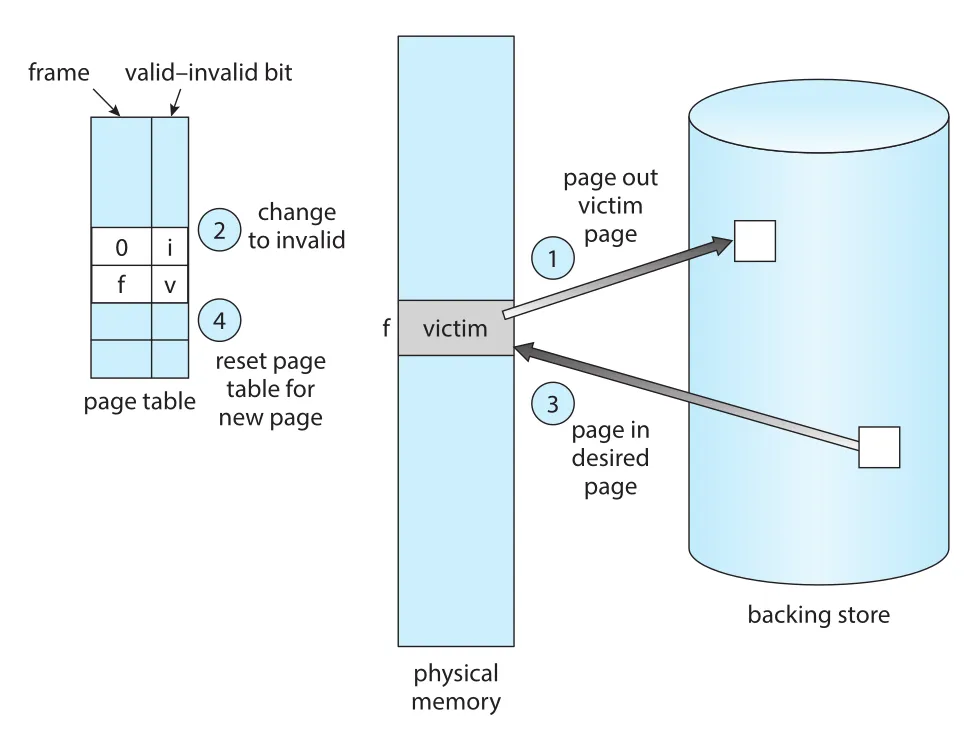
Figure 10.10 · PDF p. 515 · victim page를 page out하고 page table을 invalid로 바꾼 뒤 desired page를 page in하는 replacement 과정
Page fault service routine은 replacement를 포함해 다음처럼 바뀐다.
- Desired page의 secondary storage 위치를 찾는다.
- Free frame을 찾는다.
- Free frame이 있으면 그대로 사용한다.
- Free frame이 없으면 page-replacement algorithm으로
victim frame을 고른다. - 필요하면 victim frame을 secondary storage에 write하고 page/frame tables를 갱신한다.
- Desired page를 freed frame에 read하고 page/frame tables를 갱신한다.
- Page fault가 난 지점부터 process를 계속 실행한다.
Free frame이 없으면 page-out과 page-in, 두 번의 page transfers가 필요할 수 있어 page-fault service time이 사실상 두 배가 된다. 이 비용을 줄이는 장치가 modify bit 또는 dirty bit다. Hardware는 page의 어떤 byte라도 write되면 modify bit를 set한다. Replacement 때 modify bit가 set되어 있으면 secondary storage의 copy와 memory copy가 다르므로 write-out이 필요하다. Modify bit가 clear이면 page는 read-in 이후 변경되지 않았으므로 그냥 discard할 수 있다. Read-only code pages도 같은 이유로 write-out 없이 버릴 수 있다.
Page replacement는 logical memory와 physical memory의 분리를 완성한다. Demand paging만 있고 replacement가 없다면 physical memory보다 큰 working demand를 처리하지 못한다. Replacement까지 있으면 20-page process를 10 frames에서 실행할 수 있다. 다만 필요한 순간마다 어떤 page를 내보낼지 결정해야 한다.
Demand paging 구현에는 두 문제가 함께 존재한다.
| 문제 | 질문 |
|---|---|
frame-allocation algorithm | 여러 processes에 frames를 몇 개씩 줄 것인가? |
page-replacement algorithm | replacement가 필요할 때 어떤 frame을 victim으로 고를 것인가? |
Secondary storage I/O는 매우 비싸기 때문에 page-fault rate를 조금만 줄여도 system performance가 크게 좋아진다.
Replacement algorithm은 reference string에 대해 page faults 수를 세어 평가한다. 전체 memory addresses를 그대로 쓰지 않고 page number sequence만 본다. 같은 page가 연속으로 여러 번 reference되면 첫 reference 후에는 memory에 있으므로 즉시 뒤따르는 같은 page references는 fault를 만들지 않는다.
예를 들어 100 bytes per page에서 address sequence는 page number 기준 reference string으로 줄어든다.
addresses:
0100, 0432, 0101, 0612, ...
reference string:
1, 4, 1, 6, 1, 6, ...Available frames 수가 늘면 일반적으로 page faults는 줄어든다.
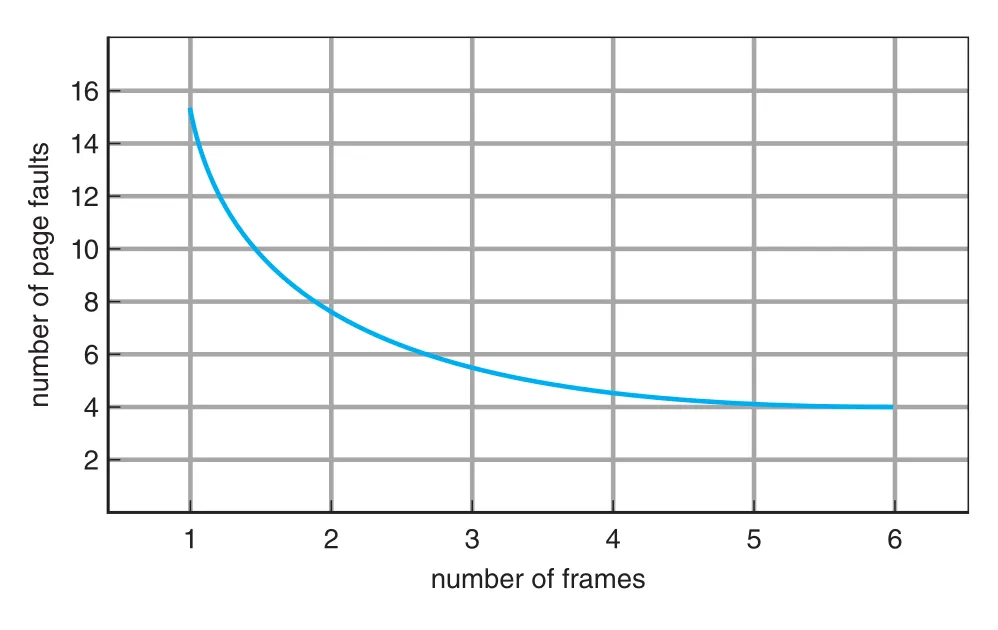
Figure 10.11 · PDF p. 517 · frames 수가 증가하면 page faults가 감소해 최소 수준으로 접근하는 일반적 경향
10.4.2 FIFO Page Replacement
FIFO page replacement는 page가 memory에 들어온 시간을 기준으로 가장 오래된 page를 replace한다. 실제 time을 저장할 필요는 없고, resident pages를 FIFO queue에 넣으면 된다. Replacement 때 queue head의 page를 victim으로 고르고, 새 page는 tail에 넣는다.
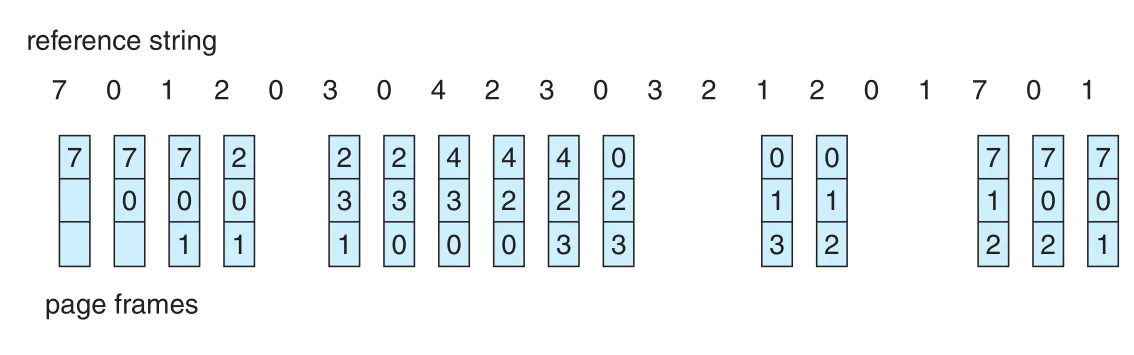
Figure 10.12 · PDF p. 517 · 3 frames와 reference string에서 FIFO가 oldest page를 순서대로 replace하는 예
FIFO는 이해와 구현이 쉽지만 성능이 항상 좋지는 않다. 가장 오래 전에 들어온 page가 initialization module처럼 더 이상 안 쓰이는 page일 수도 있지만, 반대로 일찍 초기화된 heavily used variable을 담은 page일 수도 있다. Active page를 잘못 내보내도 correctness는 깨지지 않는다. 곧바로 page fault가 나서 다시 가져올 뿐이다. 문제는 page-fault rate 증가와 execution slowdown이다.
FIFO의 중요한 약점은 Belady's anomaly다. 어떤 reference string에서는 allocated frames 수를 늘렸는데 page faults가 오히려 증가한다.
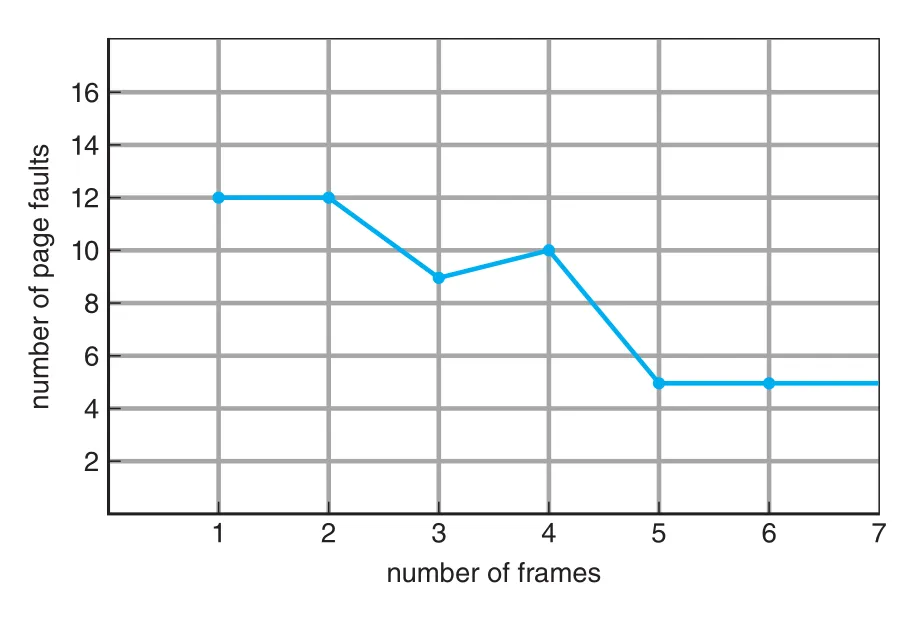
Figure 10.13 · PDF p. 518 · FIFO에서 frames 수가 3에서 4로 늘었는데 page faults가 증가하는 Belady's anomaly 예
우리는 memory를 더 주면 performance가 좋아질 것이라고 기대하지만, FIFO 같은 일부 algorithms에서는 이 가정이 항상 성립하지 않는다.
10.4.3 Optimal Page Replacement
optimal page-replacement algorithm, 즉 OPT 또는 MIN은 앞으로 가장 오랫동안 사용되지 않을 page를 replace한다.
Replace the page that will not be used for the longest period of time.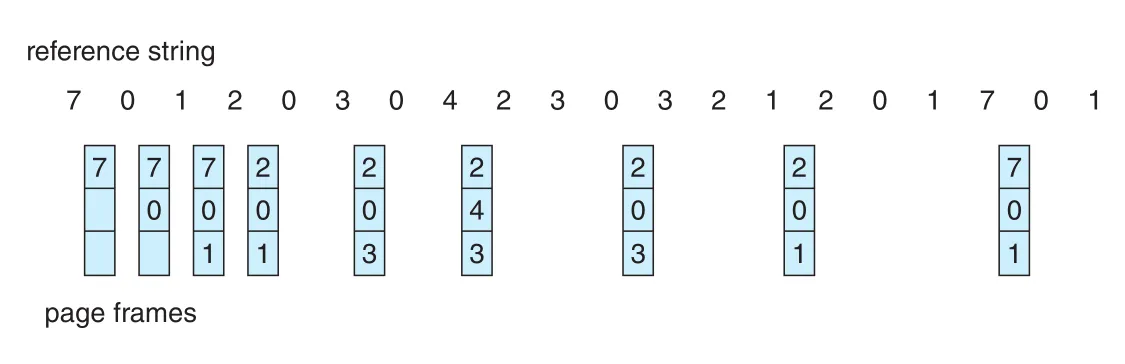
Figure 10.14 · PDF p. 519 · future reference string을 알고 있을 때 page faults를 최소화하는 optimal replacement 예
OPT는 fixed number of frames에서 lowest possible page-fault rate를 보장하고 Belady’s anomaly를 겪지 않는다. 하지만 future reference string을 알아야 하므로 실제 OS에서 구현할 수 없다. Chapter 5의 SJF CPU scheduling이 future CPU burst를 알아야 하는 것과 비슷하다. 따라서 OPT는 practical algorithm이 아니라 comparison baseline이다.
10.4.4 LRU Page Replacement
LRU (Least Recently Used)는 near future를 recent past로 근사한다. OPT가 “앞으로 가장 늦게 쓸 page”를 내보낸다면, LRU는 “과거에 가장 오래 안 쓴 page”를 내보낸다.
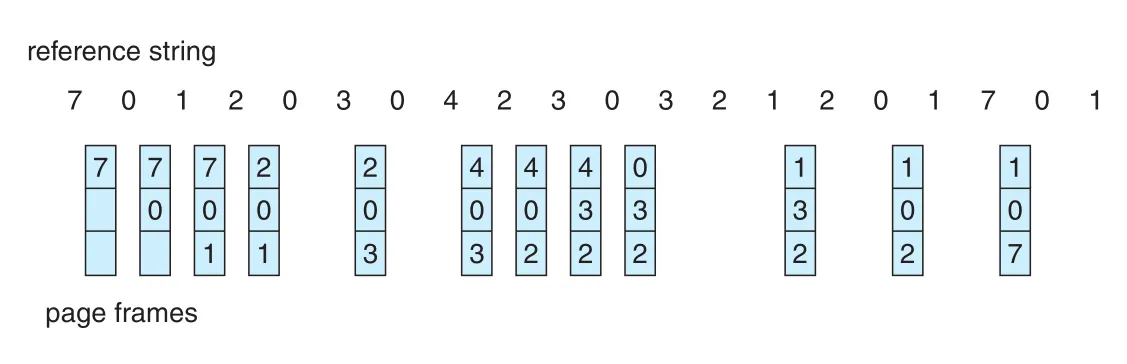
Figure 10.15 · PDF p. 520 · 최근 사용 시점을 기준으로 가장 오래 참조되지 않은 page를 replace하는 LRU 예
LRU는 FIFO보다 좋은 경우가 많고 널리 쓰이는 policy지만 구현이 어렵다. Page마다 last-use time을 알아야 하므로 hardware assistance가 필요하다.
대표 구현은 두 가지다.
| 구현 | 방식 | 비용 |
|---|---|---|
Counters | CPU logical clock/counter를 두고, page reference마다 page-table entry의 time-of-use field에 현재 clock을 기록한다. 가장 작은 time value를 가진 page가 LRU다. | 모든 memory reference마다 page table write가 필요하고, replacement 때 page table search가 필요하다. clock overflow와 context switch 처리도 고려해야 한다. |
Stack | referenced page를 stack top으로 옮긴다. top은 most recently used, bottom은 least recently used다. | doubly linked list로 구현하면 update마다 여러 pointers를 바꿔야 하지만 replacement search는 tail pointer로 해결된다. |
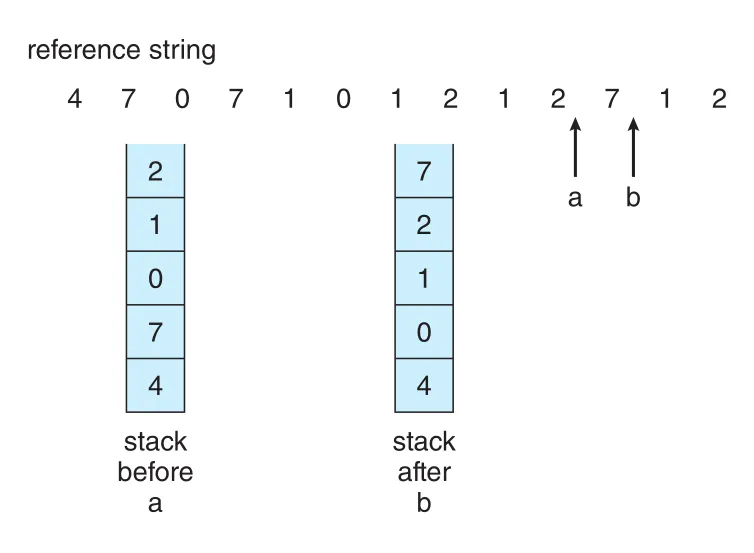
Figure 10.16 · PDF p. 521 · page reference가 발생할 때 해당 page를 stack top으로 옮겨 LRU order를 유지하는 방식
LRU와 OPT는 stack algorithms에 속해 Belady’s anomaly가 없다. Stack algorithm은 n frames에서 memory에 있는 pages set이 n+1 frames에서 memory에 있는 pages set의 subset임을 보일 수 있는 algorithm이다.
하지만 true LRU는 standard TLB registers 이상의 hardware support 없이는 현실적으로 어렵다. 모든 memory reference마다 software interrupt로 clock field나 stack을 갱신하면 memory reference 전체가 최소 10배 느려질 수 있다.
10.4.5 LRU-Approximation Page Replacement
많은 systems는 true LRU를 구현할 만큼 hardware support를 제공하지 않는다. 대신 hardware가 page reference 때 set하는 reference bit를 제공한다. OS는 초기에 reference bits를 0으로 clear하고, process가 실행되면 hardware가 read/write reference가 발생한 page bit를 1로 set한다. 이 bit는 어떤 pages가 사용되었는지 알려 주지만 사용 순서는 알려 주지 않는다.
Additional-Reference-Bits Algorithm
additional-reference-bits algorithm은 일정 시간마다 reference bit history를 저장해 ordering 정보를 근사한다. 각 page마다 8-bit byte를 두고, timer interrupt마다 current reference bit를 high-order bit로 shift in하며 기존 bits를 오른쪽으로 이동시킨다.
예를 들어 history가 00000000이면 8 periods 동안 사용되지 않은 page다. 11111111이면 매 period에 적어도 한 번 사용된 page다. Unsigned integer로 해석했을 때 가장 작은 값을 가진 page를 LRU에 가깝다고 보고 replace할 수 있다. 값이 같으면 그중 FIFO로 고를 수 있다.
Second-Chance Algorithm
second-chance algorithm은 FIFO에 reference bit를 결합한 방식이다. FIFO queue에서 victim candidate를 고르되, reference bit가 0이면 replace한다. Reference bit가 1이면 page에 second chance를 주고 bit를 0으로 clear한 뒤 다음 FIFO page로 넘어간다. Second chance를 받은 page는 arrival time이 현재로 reset된 것처럼 뒤로 밀린다.
이 algorithm은 보통 circular queue와 clock hand로 구현되어 clock algorithm이라고도 부른다.
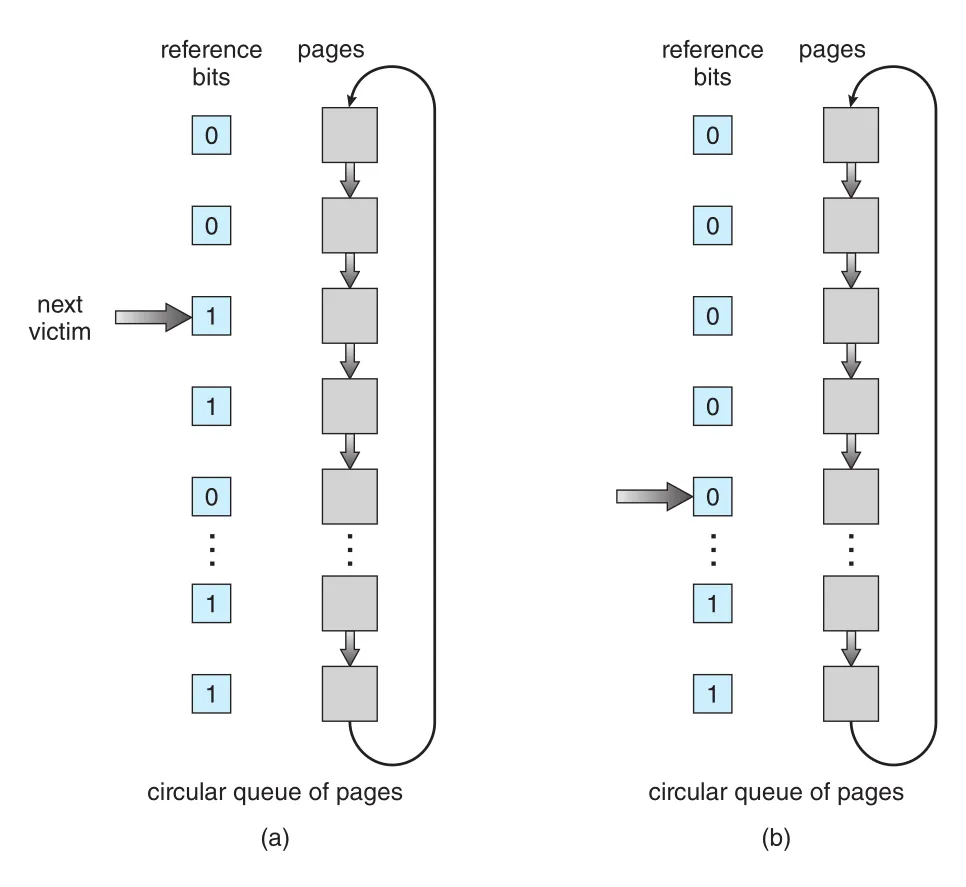
Figure 10.17 · PDF p. 523 · circular queue에서 clock hand가 reference bit를 확인하고 1이면 clear, 0이면 victim으로 선택하는 second-chance algorithm
Worst case에서 모든 reference bits가 1이면 hand가 전체 queue를 한 바퀴 돌며 모든 bits를 0으로 clear한 뒤 다음 page를 replace한다. 이 경우 second-chance는 FIFO처럼 동작한다.
Enhanced Second-Chance Algorithm
enhanced second-chance algorithm은 reference bit와 modify bit를 ordered pair로 본다.
| Class | 의미 | Replacement 선호도 |
|---|---|---|
(0, 0) | recently used 아님, modified 아님 | 가장 좋음. write-out 필요 없음 |
(0, 1) | recently used 아님, modified됨 | 가능하지만 write-out 필요 |
(1, 0) | recently used, clean | 곧 다시 쓸 가능성 있음 |
(1, 1) | recently used, modified | 곧 다시 쓸 가능성 있고 write-out도 필요 |
Replacement 때 lowest nonempty class의 첫 page를 고른다. 단순 clock보다 여러 번 scan할 수 있지만, modified pages를 피하려 하므로 I/O를 줄일 수 있다.
10.4.6 Counting-Based Page Replacement
Counting-based algorithms는 page마다 reference count를 둔다. LFU (Least Frequently Used)는 count가 가장 작은 page를 replace한다. Actively used page는 count가 클 것이라는 가정이다. 문제는 초기 phase에서 많이 쓰였지만 이후 안 쓰이는 page가 count가 커서 계속 남을 수 있다는 점이다. 이를 완화하려면 count를 주기적으로 right shift해 exponentially decaying average처럼 만들 수 있다.
MFU (Most Frequently Used)는 반대로 count가 작은 page는 막 들어와 아직 충분히 쓰이지 않은 page일 수 있으므로, count가 큰 page를 replace한다는 아이디어다. 하지만 LFU/MFU는 구현 비용이 비싸고 OPT approximation도 좋지 않아 흔하지 않다.
10.4.7 Page-Buffering Algorithms
Page replacement algorithm 위에 보조적으로 page buffering을 둘 수 있다. 흔한 방식은 free frames pool을 유지하는 것이다. Page fault가 발생하면 victim을 고르되, desired page를 pool의 free frame에 먼저 read한다. 그러면 process는 victim write-out을 기다리지 않고 빨리 restart할 수 있다. Victim page는 나중에 write-out되고 그 frame이 free-frame pool에 들어간다.
또 다른 방식은 modified pages list를 유지하는 것이다. Paging device가 idle할 때 modified page를 미리 secondary storage에 write하고 modify bit를 reset한다. 그러면 나중에 victim으로 선택될 때 clean page일 가능성이 커져 replacement I/O가 줄어든다.
Free-frame pool에 어떤 page가 있었는지 기억하는 방식도 있다. Frame contents는 secondary storage로 write된 뒤에도 reuse되기 전까지 남아 있으므로, old page가 다시 필요해졌고 그 frame이 아직 재사용되지 않았다면 I/O 없이 바로 되살릴 수 있다. 잘못된 victim 선택의 penalty를 줄이는 augmentation이다.
10.4.8 Applications and Page Replacement
OS의 general-purpose virtual memory policy가 항상 application-specific policy보다 좋은 것은 아니다. Database systems는 자체 memory management와 I/O buffering을 제공하는 경우가 많다. OS도 buffering하고 DB도 buffering하면 같은 I/O set에 memory가 두 번 쓰일 수 있다.
Data warehouse처럼 massive sequential reads 후 computation/writes를 수행하는 workloads에서는 LRU가 오히려 좋지 않을 수 있다. LRU는 오래된 pages를 제거하고 새 pages를 보존하지만, application은 sequential scan을 다시 시작하면서 오래된 pages를 다시 읽을 가능성이 있다. 이 경우 MFU가 LRU보다 더 효율적일 수도 있다.
그래서 일부 OS는 special programs가 file-system buffering을 우회해 storage partition을 logical blocks의 큰 sequential array처럼 쓰도록 허용한다. 이 partition을 raw disk, 그 I/O를 raw I/O라고 한다. Raw I/O는 file I/O demand paging, file locking, prefetching, space allocation, file names, directories 같은 file-system services를 우회한다. 다만 대부분의 일반 applications는 regular file-system services를 사용할 때 더 잘 동작한다.
10.5 Allocation of Frames
Page replacement가 “어떤 frame을 비울 것인가”라면, allocation of frames는 “fixed amount of free memory를 여러 processes 사이에 어떻게 나눌 것인가”다. 예를 들어 93 free frames와 2 processes가 있을 때 각 process에 몇 frames를 줄지 결정해야 한다.
가장 단순한 전략에서는 user process가 어떤 free frame이든 받는다. Pure demand paging에서는 처음 모든 free frames가 free-frame list에 있다. Process가 실행되며 page faults를 내고, fault마다 free frame을 받는다. Free-frame list가 고갈되면 replacement algorithm으로 in-memory page를 victim으로 골라 새 page와 교체한다.
OS는 free-frame list에 항상 몇 개 frames를 reserve해 둘 수도 있다. Page fault가 발생하면 즉시 page-in할 free frame을 제공하고, 그동안 replacement victim을 골라 storage에 write할 수 있다. 기본 원리는 같다. User process는 available free frames 중 하나를 받는다.
10.5.1 Minimum Number of Frames
Frame allocation에는 하한과 상한이 있다. 상한은 available physical memory이고, 하한은 architecture가 요구하는 minimum number of frames다.
Minimum frames가 필요한 첫 이유는 performance다. Process에 allocated frames가 줄수록 page-fault rate가 올라가 execution이 느려진다. 더 근본적인 이유는 instruction restart다. Page fault가 instruction completion 전에 발생하면 instruction을 restart해야 하므로, 하나의 instruction이 참조할 수 있는 서로 다른 pages를 담을 만큼 frames가 있어야 한다.
예를 들어 모든 memory-reference instruction이 memory address 하나만 참조하는 machine에서는 최소한 instruction page용 frame 하나와 memory reference page용 frame 하나가 필요하다. One-level indirect addressing이 허용되면 instruction page, indirect address page, final referenced page가 필요할 수 있어 최소 3 frames가 필요하다.
Architecture가 더 복잡하면 minimum frames도 늘어난다. Instruction itself가 frame boundary를 걸쳐 두 frames에 있을 수 있고, operands가 각각 indirect references일 수 있다면 총 6 frames가 필요할 수 있다. 반대로 Intel 32/64-bit architectures처럼 memory-to-memory move를 제한하고 register-memory 또는 register-register movement만 허용하면 process에 필요한 minimum frames를 제한할 수 있다.
10.5.2 Allocation Algorithms
equal allocation은 가장 단순한 frame allocation이다. frames와 processes가 있으면 각 process에 frames를 준다. 예를 들어 93 frames와 5 processes가 있으면 각 process에 18 frames를 주고, 남는 3 frames는 free-frame buffer pool로 둘 수 있다.
하지만 process sizes가 다르면 equal allocation은 낭비를 만들 수 있다. 1-KB frame system에서 10-KB student process와 127-KB database process가 62 free frames를 나눠 가진다고 하자. 각자 31 frames를 주면 student process는 10 frames 이상을 쓰지 못해 21 frames가 사실상 낭비된다.
proportional allocation은 process size에 비례해 frames를 준다. Process 의 virtual memory size를 , total size를 , total available frames를 이라고 하면 process 의 allocation 는 다음과 같다.
10-page process와 127-page process가 62 frames를 나누면 다음처럼 계산된다.
실제로는 각 를 integer로 조정하고, instruction set이 요구하는 minimum frames 이상이어야 하며, 총합은 을 넘지 않아야 한다.
Equal/proportional allocation 모두 multiprogramming level이 바뀌면 allocation도 변한다. New process가 들어오면 기존 processes가 frames를 잃고, process가 떠나면 그 frames가 남은 processes에 분배될 수 있다. 또한 process size만이 아니라 priority를 반영할 수 있다. High-priority process에 더 많은 frames를 주어 execution을 빠르게 하고, low-priority process가 그 비용을 부담하게 할 수 있다.
10.5.3 Global versus Local Allocation
Multiple processes가 frames를 두고 경쟁할 때 page replacement scope는 global replacement와 local replacement로 나뉜다.
| 구분 | Victim 선택 범위 | 장점 | 단점 |
|---|---|---|---|
global replacement | all frames. 다른 process의 frame도 빼앗을 수 있다. | system throughput이 보통 더 높고, active/high-priority process가 frames를 더 얻을 수 있다. | process performance가 다른 processes의 paging behavior에 영향을 받아 예측성이 낮다. |
local replacement | process 자신의 allocated frames 안에서만 선택한다. | process performance가 자기 behavior에만 의존해 isolation이 좋다. | 덜 쓰이는 다른 process frames를 활용하지 못해 throughput이 낮아질 수 있다. |
Global replacement에서는 high-priority process가 low-priority process의 frames를 victim으로 선택하게 만들 수도 있다. 이 경우 high-priority process는 allocation을 늘릴 수 있다. 반면 local replacement에서는 process의 frame 수가 고정되고, 자기 frames 안에서만 replacement가 일어난다.
OS는 major page faults와 minor page faults를 구분한다. Major page fault는 page가 memory에 없어 backing store에서 read해야 하는 fault다. Minor page fault는 process page table에는 mapping이 없지만 page 자체는 memory에 있는 경우다. 예를 들어 shared library가 이미 memory에 있는데 process mapping만 없으면 page table update만으로 해결된다. 또는 reclaimed page가 free-frame list에 있지만 아직 zeroed/reallocated되지 않았다면 다시 process에 연결할 수 있다. Minor fault는 major fault보다 훨씬 싸다.
Global replacement를 구현하는 한 방법은 free-frame list가 완전히 0이 될 때까지 기다리지 않고, minimum threshold 아래로 떨어질 때 page reclamation을 시작하는 것이다.
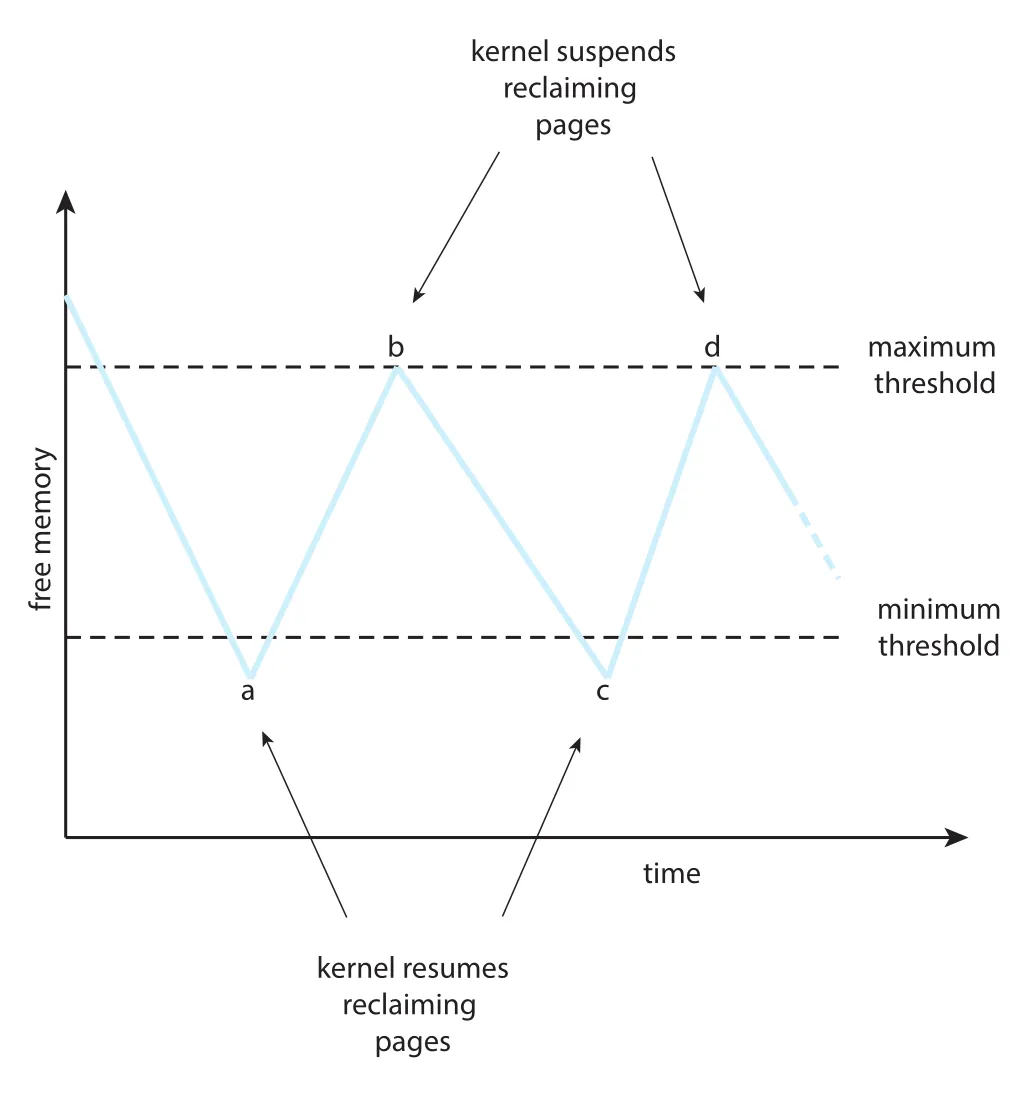
Figure 10.18 · PDF p. 529 · free memory가 minimum threshold 아래로 떨어지면 kernel reaper가 pages를 회수하고 maximum threshold에 도달하면 중단하는 흐름
이때 kernel routine을 reaper라고 부르며, LRU approximation 같은 replacement algorithm으로 pages를 reclaim한다. Free memory가 maximum threshold에 도달하면 reaper는 중단되고, 다시 minimum threshold 아래로 떨어지면 재개된다. Reaper가 free-frame list를 유지하지 못하면 더 aggressive한 strategy로 바꾸거나, Linux처럼 OOM killer가 process를 terminate할 수 있다. Linux의 OOM score는 process가 사용하는 memory percentage 등에 기반하며, score가 높을수록 terminate될 가능성이 크다.
10.5.4 Non-Uniform Memory Access
지금까지는 main memory access latency가 모두 같다고 가정했다. 하지만 NUMA (Non-Uniform Memory Access) systems에서는 CPU마다 local memory가 있고, 어떤 memory section은 더 빠르게 접근할 수 있다.
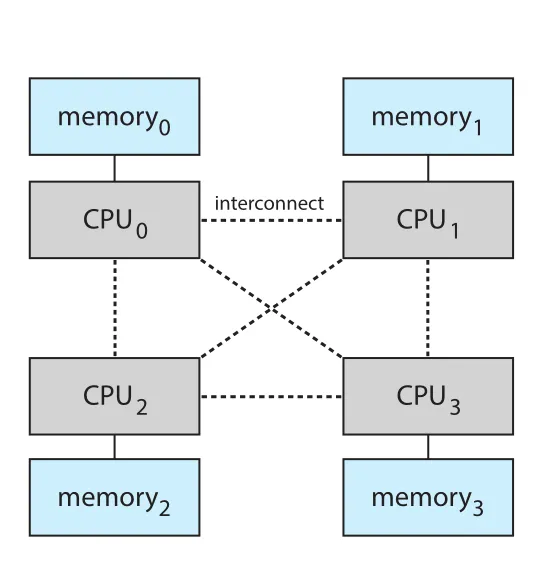
Figure 10.19 · PDF p. 530 · 각 CPU가 local memory를 가지고 interconnect로 연결되는 NUMA multiprocessing architecture
NUMA systems는 uniform memory systems보다 single access latency는 나쁠 수 있지만, 더 많은 CPUs를 수용해 throughput과 parallelism을 높일 수 있다. 따라서 virtual memory system은 frame을 process가 실행되는 CPU에 “가까운” memory에 할당해야 한다. 여기서 가깝다는 것은 minimum latency, 보통 같은 system board 또는 NUMA node를 뜻한다.
NUMA-aware allocation은 scheduler와도 연결된다. Scheduler가 process가 마지막으로 실행된 CPU를 추적하고 가능하면 같은 CPU에 다시 schedule하며, virtual memory system이 그 CPU 가까운 frames를 allocate하면 cache hits가 늘고 memory access time이 줄어든다.
Threads가 추가되면 더 복잡하다. Many threads가 여러 system boards에서 실행될 수 있기 때문이다. Linux는 scheduling domains hierarchy를 두어 threads migration으로 인한 memory access penalty를 줄이고, NUMA node별 free-frame list를 유지해 thread가 실행 중인 node에서 memory를 받게 한다. Solaris는 lgroups (locality groups)로 CPU와 memory를 latency 기준으로 묶고, 가능하면 process threads와 memory를 같은 lgroup 안에 둔다.
10.6 Thrashing
Process가 current working set을 담을 만큼 충분한 frames를 받지 못하면 빠르게 page fault를 낸다. Replacement를 해도 victim page 역시 active use 중인 page라 곧 다시 필요해진다. 그러면 process는 page를 내보내고 다시 가져오기를 반복한다. 이 high paging activity가 thrashing이다.
Thrashing은 severe performance problem이다. CPU가 일을 하지 않는 것이 아니라, processes가 계속 paging device를 기다리며 effective progress를 못 하기 때문이다.
10.6.1 Cause of Thrashing
초기 paging systems에서 흔했던 시나리오는 다음과 같다.
- OS가 CPU utilization을 monitor한다.
- CPU utilization이 낮으면 multiprogramming degree를 높이기 위해 새 process를 추가한다.
- Global page replacement가 process 구분 없이 pages를 빼앗는다.
- 어떤 process가 새 execution phase로 들어가 더 많은 frames를 요구한다.
- 그 process가 다른 processes의 frames를 빼앗고, 빼앗긴 processes도 page fault를 낸다.
- Processes가 paging device queue에 몰리면서 ready queue가 비고 CPU utilization이 더 낮아진다.
- Scheduler는 CPU utilization이 낮다고 보고 또 multiprogramming degree를 높인다.
- Page faults와 paging queue가 폭증하고 throughput이 붕괴한다.
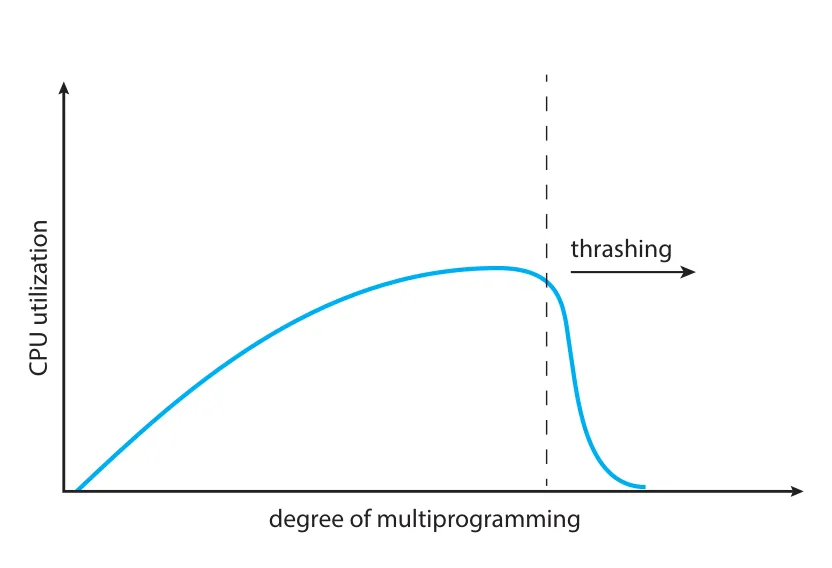
Figure 10.20 · PDF p. 532 · multiprogramming degree가 일정 수준을 넘으면 thrashing으로 CPU utilization이 급격히 떨어지는 현상
Thrashing이 시작된 지점에서는 CPU utilization을 높이려면 multiprogramming degree를 늘리는 것이 아니라 줄여야 한다. Local replacement나 priority replacement는 한 process가 다른 process frames를 빼앗아 함께 thrashing하게 만드는 효과를 제한할 수 있다. 하지만 paging device queue가 길어지면 thrashing하지 않는 process의 page fault service time도 늘어난다.
Thrashing을 막으려면 process에 필요한 만큼 frames를 줘야 한다. 이 “필요한 만큼”을 이해하기 위한 모델이 locality model이다. locality는 함께 active하게 사용되는 pages set이다. Function call은 function instructions, local variables, 일부 global variables로 새 locality를 만들 수 있다. Function에서 return하면 그 locality를 떠난다.
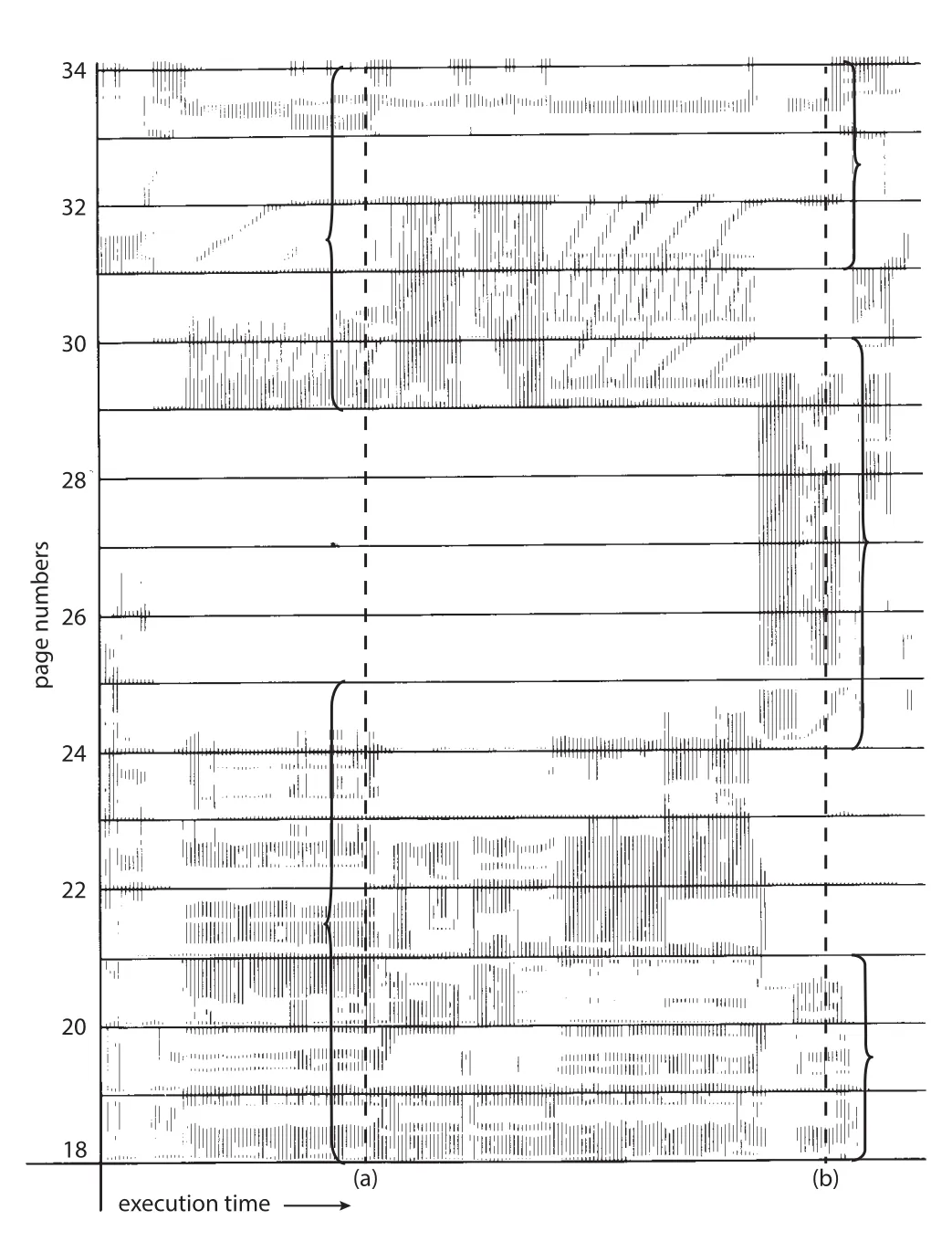
Figure 10.21 · PDF p. 533 · execution time에 따라 process가 서로 겹치기도 하는 다른 localities로 이동하는 memory-reference pattern
Localities는 program structure와 data structures가 만든다. 이 원리는 cache가 동작하는 이유와도 같다. Data access가 완전히 random이라면 caching은 쓸모가 없다. Process에 current locality를 담을 frames를 주면 locality pages를 load할 때만 fault가 나고, 이후 locality가 바뀔 때까지 fault가 줄어든다. Current locality를 담지 못하면 process는 active pages를 모두 유지하지 못해 thrashing한다.
10.6.2 Working-Set Model
working-set model은 locality assumption에 기반한다. Parameter Δ가 working-set window를 정의하고, 최근 Δ page references 안에 등장한 pages set이 working set이다.
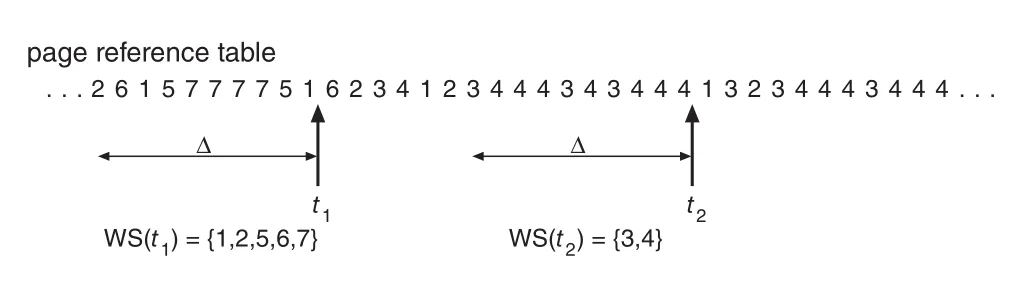
Figure 10.22 · PDF p. 534 · 최근 Δ references 안의 pages set을 working set으로 보고 locality를 근사하는 모델
Page가 active use 중이면 working set 안에 있다. 더 이상 사용되지 않으면 마지막 reference 후 Δ time units가 지나 working set에서 빠진다. 따라서 working set은 current locality의 approximation이다.
Δ 선택이 중요하다.
| Δ 선택 | 결과 |
|---|---|
| 너무 작음 | 전체 locality를 포함하지 못한다. |
| 너무 큼 | 여러 localities가 겹쳐 working set이 과대해진다. |
| 무한대 | process execution 중 한 번이라도 touched된 모든 pages가 working set이 된다. |
Process 의 working-set size를 라고 하자. System의 total demand for frames는 다음과 같다.
Available frames가 일 때 이면 어떤 processes는 current working set을 담을 만큼 frames를 받지 못하므로 thrashing이 발생한다. OS는 각 process의 working set을 monitor하고 만큼 frames를 준다. Extra frames가 있으면 새 process를 시작할 수 있다. Working-set sizes sum이 available frames를 넘으면 process 하나를 suspend하고 pages를 swapped out하여 frames를 다른 processes에 재분배한다.
Working-set strategy는 thrashing을 막으면서 multiprogramming degree를 가능한 높게 유지하려는 전략이다. 어려움은 moving window를 추적하는 cost다. 모든 memory reference마다 window를 정확히 유지하기 어렵기 때문에 timer interrupt와 reference bits로 approximation한다. 예를 들어 Δ가 10,000 references이고 timer interrupt가 5,000 references마다 발생하면, current reference bit와 두 history bits를 보고 최근 10,000-15,000 references 안에 쓰였는지 추정할 수 있다. 더 많은 history bits와 더 잦은 interrupts는 정확도를 높이지만 overhead도 높인다.
Working set과 page-fault rate는 직접 연결된다. Process가 새 locality로 이동하면 demand paging으로 새 working set을 load하며 page-fault rate가 peak를 찍고, working set이 memory에 들어오면 fault rate가 낮아진다. 다음 locality로 이동하면 다시 peak가 온다.
10.6.3 Page-Fault Frequency
page-fault frequency (PFF) strategy는 working set을 직접 추적하지 않고 page-fault rate를 바로 제어한다. Thrashing은 high page-fault rate이므로, page-fault rate가 너무 높으면 process가 frames를 더 필요로 한다고 보고, 너무 낮으면 frames가 과다할 수 있다고 본다.
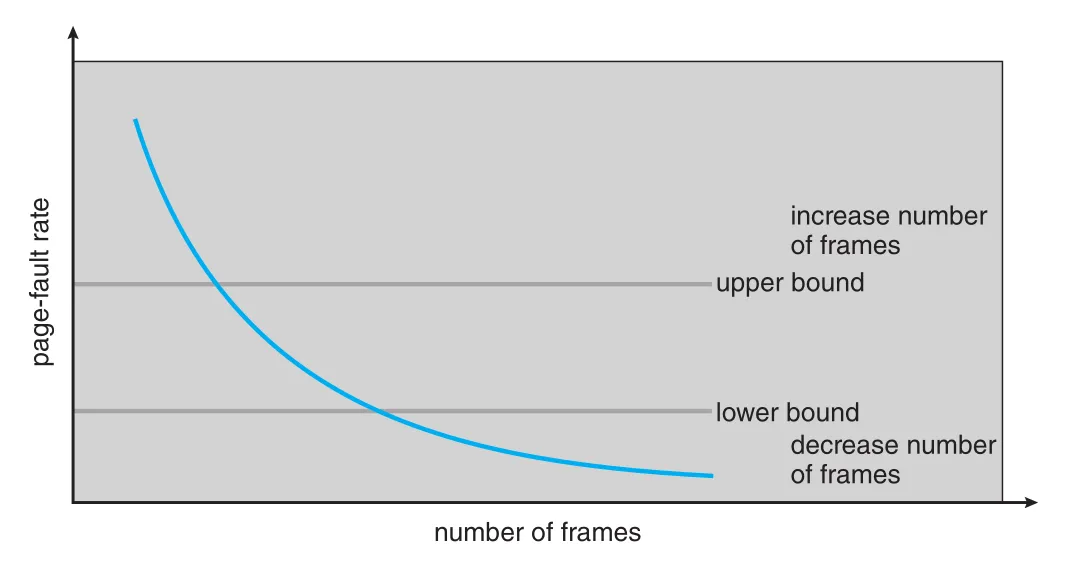
Figure 10.23 · PDF p. 536 · page-fault rate의 upper/lower bounds에 따라 process frames를 늘리거나 줄이는 PFF 제어
Actual page-fault rate가 upper bound를 넘으면 process에 frame을 추가한다. Lower bound 아래로 떨어지면 process에서 frame을 회수한다. Free frames가 없는데 page-fault rate가 높아지면 어떤 process를 선택해 backing store로 swap out하고, freed frames를 high page-fault-rate processes에 나눠 줄 수 있다.
10.6.4 Current Practice
Thrashing과 그 결과로 생기는 swapping은 performance impact가 매우 크다. 실무적으로 가장 좋은 방법은 가능한 한 충분한 physical memory를 제공해, extreme conditions를 제외하면 모든 working sets가 동시에 memory에 머물 수 있게 하는 것이다. Smartphones부터 large servers까지, working sets를 memory에 유지하는 것이 사용자 경험상 가장 좋다.
10.7 Memory Compression
memory compression은 paging의 대안 또는 보완책이다. Modified frames를 swap space로 page out하는 대신, 여러 frames를 압축해 하나의 frame에 저장한다. 이렇게 하면 pages를 secondary storage로 내보내지 않고도 memory usage를 줄일 수 있다.
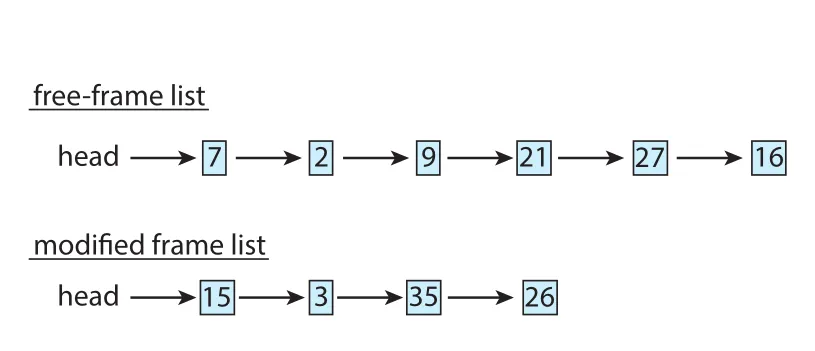
Figure 10.24 · PDF p. 537 · free-frame list가 threshold 아래로 떨어지면 replacement 대상 frames가 modified-frame list에 모이는 compression 전 상태
예를 들어 free-frame list가 threshold 아래로 떨어지면 replacement algorithm이 frames 15, 3, 35, 26을 선택할 수 있다. 전통적 방식이면 modified-frame list의 pages를 swap space에 write하고 frames를 free-frame list에 넣는다. Memory compression에서는 frames 15, 3, 35를 압축해 frame 7 하나에 저장하고, 원래 frames 15, 3, 35를 free-frame list로 돌려보낸다.
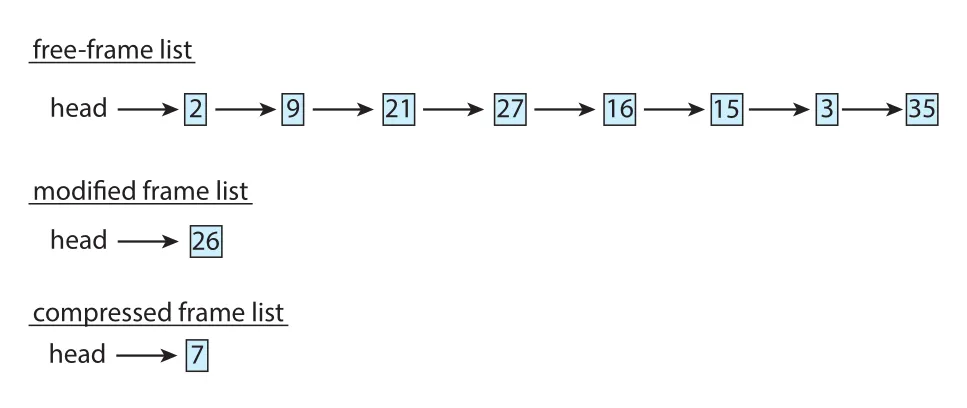
Figure 10.25 · PDF p. 538 · frames 15, 3, 35를 압축해 frame 7에 저장하고 원래 frames를 free-frame list에 돌려보낸 상태
나중에 압축된 pages 중 하나가 reference되면 page fault가 발생하고, compressed frame을 decompress해 pages를 memory에 복원한다.
Mobile systems는 standard swapping이나 pages swapping을 보통 지원하지 않으므로 memory compression이 핵심 전략이 된다. Android와 iOS가 대표적이고, Windows 10과 macOS도 memory compression을 지원한다. macOS는 free memory가 부족할 때 LRU pages를 먼저 compress하고, 그래도 부족하면 paging한다. SSD에 paging하는 것보다 memory compression이 빠른 경우가 많다.
Memory compression의 trade-off는 compression speed와 compression ratio다. 더 높은 compression ratio는 대체로 더 느리고 계산 비용이 큰 algorithms를 요구한다. 실제 systems는 fast algorithms와 parallel compression으로 균형을 잡는다. 핵심은 CPU cycles를 써서 I/O를 피하는 것이다.
10.8 Allocating Kernel Memory
User-mode process가 memory를 요청하면 kernel이 유지하는 free page frames list에서 pages가 할당된다. 이 list는 page-replacement algorithm으로 채워지며 physical memory 여기저기에 흩어진 free pages를 포함한다. User process가 1 byte만 요청해도 page frame 전체를 받을 수 있어 internal fragmentation이 생긴다.
Kernel memory는 보통 user-mode process용 free-page list와 다른 pool에서 할당된다. 이유는 두 가지다.
- Kernel data structures는 page보다 작은 다양한 크기의 allocations를 자주 요구한다. Kernel code/data는 paging 대상이 아닌 경우가 많으므로 fragmentation을 줄여야 한다.
- Hardware devices는 virtual memory interface 없이 physical memory와 직접 상호작용할 수 있다. 이런 devices는 physically contiguous pages를 요구할 수 있다.
10.8.1 Buddy System
buddy system은 physically contiguous pages로 된 fixed-size segment에서 memory를 할당한다. Allocation unit은 4 KB, 8 KB, 16 KB처럼 power of 2 크기다. 요청 크기가 power of 2가 아니면 다음 power of 2로 round up된다. 예를 들어 11 KB 요청은 16-KB segment로 충족된다.
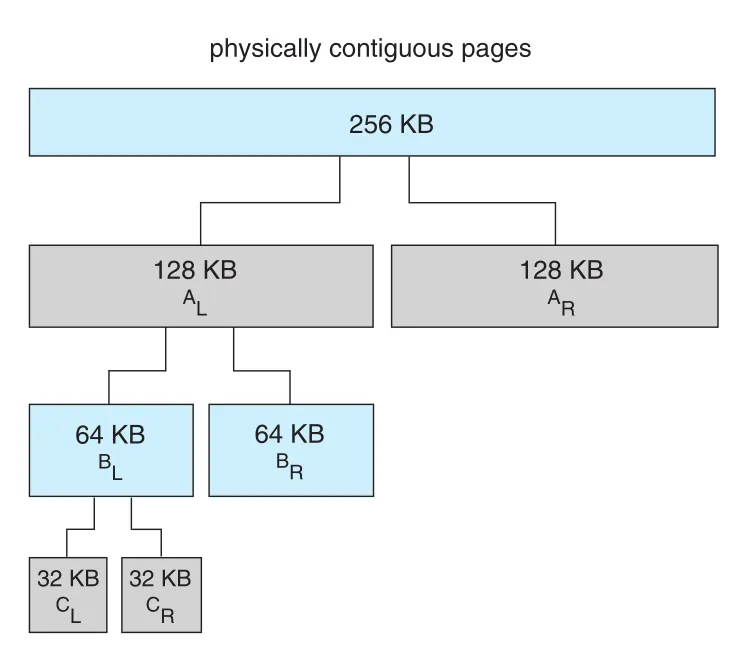
Figure 10.26 · PDF p. 540 · 256-KB contiguous segment를 buddies로 반복 분할해 21-KB 요청을 32-KB unit으로 만족시키는 buddy system
256 KB segment에서 21 KB를 요청하면 256 KB를 128 KB buddies로 나누고, 다시 64 KB, 다시 32 KB buddies로 나눈 뒤 32 KB unit 하나를 할당한다. Buddy system의 장점은 coalescing이 빠르다는 것이다. Allocated unit이 release되면 adjacent buddy가 free인지 확인해 64 KB, 128 KB, 256 KB처럼 다시 합칠 수 있다.
단점은 internal fragmentation이다. 33 KB 요청은 64 KB segment를 받아야 하므로 거의 절반이 낭비될 수 있다. Power-of-2 rounding 때문에 allocated unit의 50% 가까이가 wasted될 수 있다.
10.8.2 Slab Allocation
slab allocation은 kernel objects를 빠르게 할당하고 fragmentation을 줄이기 위한 방식이다. slab은 하나 이상의 physically contiguous pages로 구성된다. cache는 하나 이상의 slabs로 구성되며, 각 unique kernel data structure마다 별도 cache가 있다. 예를 들어 process descriptors, file objects, semaphores는 각각 자기 cache를 가질 수 있다. Cache 안의 objects는 해당 kernel data structure의 instances다.
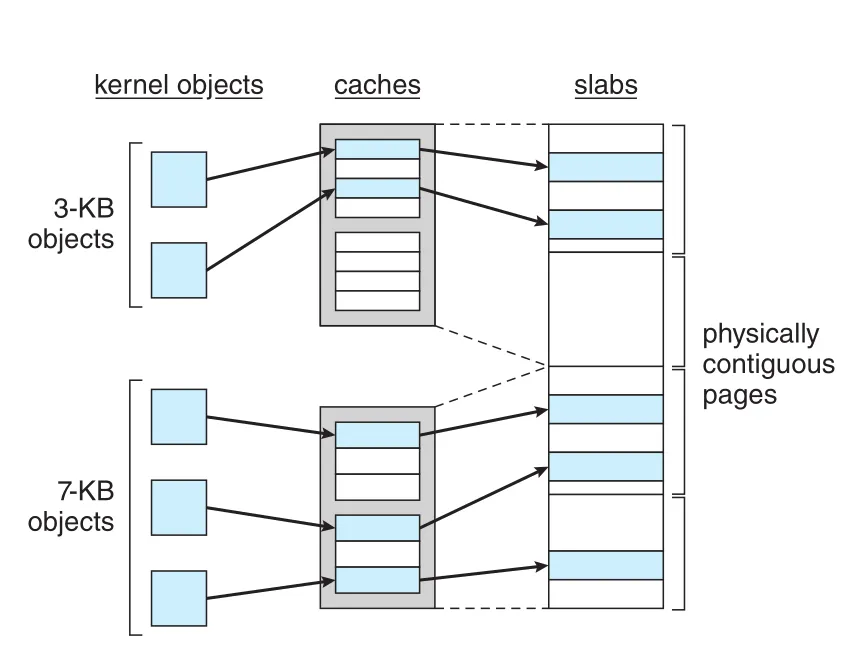
Figure 10.27 · PDF p. 540 · kernel object type별 cache가 slabs를 가지고, slab 안에 fixed-size objects를 담는 slab allocation 구조
Cache가 생성되면 objects가 미리 allocated되고 free로 표시된다. Kernel이 특정 data structure object를 요청하면 allocator는 그 cache의 free object를 반환하고 used로 표시한다. Linux의 struct task_struct 같은 process descriptor도 이런 cache에서 빠르게 할당될 수 있다.
Linux에서 slab은 세 상태를 가진다.
| 상태 | 의미 |
|---|---|
Full | slab의 모든 objects가 used |
Empty | 모든 objects가 free |
Partial | used/free objects가 섞임 |
Allocator는 먼저 partial slab의 free object로 요청을 만족하려고 한다. 없으면 empty slab에서 할당한다. Empty slab도 없으면 contiguous physical pages에서 새 slab을 만들어 cache에 붙인다.
Slab allocator의 이점은 두 가지다.
| 이점 | 설명 |
|---|---|
| fragmentation 감소 | cache가 object size에 맞게 나뉘므로 kernel object 요청에 정확히 필요한 크기를 반환한다. |
| 빠른 allocation | objects가 미리 만들어져 있고, release 시 cache에 free로 되돌아가 다음 요청에 즉시 사용할 수 있다. |
Linux는 SLAB, SLOB, SLUB 같은 slab-family allocators를 사용해 왔다. SLOB는 memory가 제한된 embedded systems를 위한 simple list allocator이고, SLUB는 SLAB의 per-CPU queues와 metadata overhead를 줄여 many-processor systems에서 더 나은 scalability를 제공한다.
10.9 Other Considerations
Paging system의 주요 결정은 replacement algorithm과 allocation policy지만, 실제 design에는 prepaging, page size, TLB reach, inverted page tables, program structure, I/O interlock도 중요하다.
10.9.1 Prepaging
Pure demand paging은 process start 시 initial locality를 가져오느라 page faults가 많이 발생한다. prepaging은 곧 필요할 pages 일부 또는 전체를 한 번에 memory로 가져와 initial page faults를 줄이려는 전략이다.
Working-set model을 쓰는 system에서는 suspend된 process의 working set pages를 기억해 두었다가 process를 resume하기 전에 working set 전체를 memory로 가져올 수 있다. Prepaging이 이득인지 여부는 미리 가져온 pages 중 실제로 사용되는 비율에 달려 있다.
α가 0에 가까우면 prepaging은 손해고, 1에 가까우면 이득이다. Executable program은 어떤 pages가 필요할지 예측하기 어려울 수 있지만, file은 sequential access가 흔해 prefetch가 더 잘 맞는다. Linux의 readahead() system call은 file contents를 미리 memory로 가져와 subsequent file access가 main memory에서 일어나게 한다.
10.9.2 Page Size
Page size에는 single best answer가 없다. Hardware/OS 설계 시 여러 요인이 서로 반대 방향으로 작용한다. Page sizes는 보통 power of 2이고, 4 KB부터 수 MB까지 다양하다.
| 작은 page size가 유리한 이유 | 큰 page size가 유리한 이유 |
|---|---|
| internal fragmentation 감소 | page table size 감소 |
| locality를 더 세밀하게 반영 | HDD/NVM I/O에서 seek/latency overhead를 amortize |
| 실제 필요한 memory만 더 정밀하게 transfer/allocation | page fault 횟수 감소 |
Page size가 작으면 page table entries 수가 늘어난다. 같은 virtual memory space에서 1-KB pages는 8-KB pages보다 훨씬 많은 page table entries가 필요하다. 반대로 page size가 크면 final page의 unused portion이 커져 internal fragmentation이 늘어난다.
I/O 관점에서는 큰 page가 유리할 수 있다. HDD에서는 seek와 latency가 transfer time보다 훨씬 크기 때문에 512 bytes를 한 번 읽든 1,024 bytes를 한 번 읽든 전체 I/O 시간 차이는 작다. 같은 양을 작은 pages 여러 번으로 읽으면 page fault와 I/O overhead가 반복된다.
하지만 page가 너무 크면 locality보다 더 많은 data를 함께 가져오게 된다. 필요한 100 KB만 쓰는 200-KB process를 한 page로 두면 200 KB 전체를 가져와야 한다. 반대로 page size가 지나치게 작으면 page faults 수가 폭증한다. 그래서 modern trend는 memory와 workload 증가에 맞춰 larger pages를 지원하는 방향이지만, internal fragmentation/locality와 TLB/page table trade-off를 함께 고려한다.
10.9.3 TLB Reach
TLB reach는 TLB가 직접 cover할 수 있는 memory 양이다.
Ideal하게는 process working set이 TLB 안에 들어가야 한다. 그렇지 않으면 process는 TLB 대신 page table에서 translations를 자주 resolve해야 한다. TLB entries를 늘리면 reach가 늘지만 associative memory는 expensive and power hungry하다.
다른 방법은 page size를 키우거나 multiple page sizes를 지원하는 것이다. Page size를 4 KB에서 16 KB로 늘리면 같은 TLB entries 수에서 TLB reach가 4배가 된다. 하지만 큰 page는 fragmentation을 늘릴 수 있다. 그래서 Linux의 huge pages처럼 특정 memory region에 2 MB 같은 larger pages를 사용하는 기능이 제공된다.
ARMv8은 page/region sizes를 다양하게 지원하고, TLB entry에 contiguous bit를 둘 수 있다. 이 bit가 set되면 single TLB entry가 adjacent blocks를 mapping해 TLB reach를 늘린다. Multiple page sizes는 TLB entry에 page size 또는 contiguous block 정보를 담아야 하므로, OS가 TLB를 software-managed하는 경우 performance cost가 생길 수 있다. 하지만 hit ratio와 TLB reach 증가가 그 비용을 상쇄할 수 있다.
10.9.4 Inverted Page Tables
inverted page table은 physical frame마다 하나의 entry를 두어 virtual-to-physical translation tracking에 필요한 physical memory를 줄인다. 하지만 demand paging에서는 referenced page가 memory에 없을 때 그 page가 backing store 어디에 있는지 알아야 한다. Inverted table은 process logical address space 전체 정보를 담지 않으므로, process별 external page table이 추가로 필요하다.
External page tables는 page fault 때만 참조되므로 빠르게 접근 가능할 필요는 없고, themselves도 paging될 수 있다. 그러나 page fault 처리 중 external page table을 찾으려다 또 page fault가 날 수 있다. 이 special case는 kernel에서 조심스럽게 처리해야 하며 page lookup delay를 만든다.
10.9.5 Program Structure
Demand paging은 user program에 투명해야 하지만, program structure가 locality를 크게 좌우하므로 성능에 영향을 줄 수 있다. Row-major array를 column-wise로 접근하면 page faults가 폭증할 수 있다.
예를 들어 page size가 128 words이고 int data[128][128]가 row-major로 저장된다고 하자. 아래 코드는 각 column을 먼저 돌며 매번 다른 row page의 한 word만 건드린다.
for (j = 0; j < 128; j++)
for (i = 0; i < 128; i++)
data[i][j] = 0;OS가 program 전체에 128 frames보다 적게 할당하면 이 access pattern은 128 * 128 = 16,384 page faults를 만들 수 있다. 반대로 row-major layout에 맞춰 row를 먼저 돌면 한 page의 words를 모두 처리한 뒤 다음 page로 넘어가므로 page faults를 128 수준으로 줄일 수 있다.
for (i = 0; i < 128; i++)
for (j = 0; j < 128; j++)
data[i][j] = 0;Data structures도 locality를 좌우한다. Stack은 top 근처를 반복 접근하므로 locality가 좋다. Hash table은 references를 흩뜨리도록 설계되어 locality가 나쁠 수 있다. Compiler/loader도 code/data separation, reentrant code, routines packing으로 paging behavior를 개선할 수 있다. Read-only clean code pages는 replacement 때 write-out이 필요 없고, 자주 서로 call하는 routines를 같은 page에 넣으면 interpage references를 줄일 수 있다.
10.9.6 I/O Interlock and Page Locking
Demand paging에서는 어떤 pages는 memory에 locked되어야 한다. 대표 사례는 user virtual memory를 대상으로 하는 I/O다. USB storage controller 같은 I/O processor는 transfer bytes 수와 memory buffer address를 받고, transfer 완료 후 CPU에 interrupt를 보낸다.
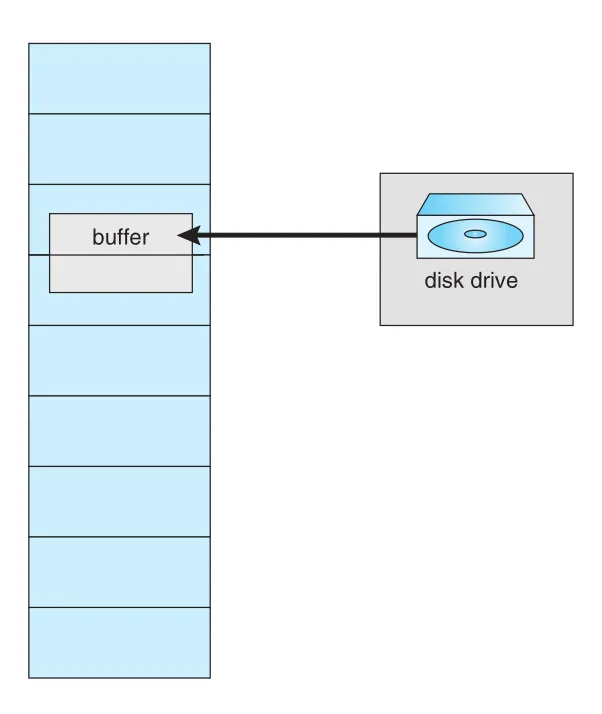
Figure 10.28 · PDF p. 547 · I/O가 진행되는 동안 buffer가 담긴 frame이 다른 page로 replacement되면 안 되는 이유
문제 시나리오는 이렇다. Process가 I/O request를 내고 device queue에서 기다린다. 그동안 CPU는 다른 processes를 실행한다. Global replacement가 waiting process의 I/O buffer page를 victim으로 골라 page out한다. 나중에 I/O request가 device queue head가 되어 지정된 physical address로 transfer가 일어나면, 그 frame은 이미 다른 process의 다른 page일 수 있다. 그러면 wrong memory가 overwrite된다.
해결책은 두 가지다.
| 해결책 | 장점 | 단점 |
|---|---|---|
| user memory로 직접 I/O하지 않음 | I/O buffer page replacement 문제를 피한다. | system memory와 user memory 사이 extra copy overhead가 크다. |
page locking, pinning | I/O buffer pages를 locked 상태로 두어 replacement를 막는다. | lock misuse가 memory pressure를 키우고, unlock 누락 bug는 frame을 unusable하게 만든다. |
Page locking에서는 frame마다 lock bit를 두고, locked frame은 replacement candidate가 될 수 없다. I/O가 끝나면 pages를 unlock한다. Kernel code/data 일부도 page fault를 허용할 수 없으므로 locked될 수 있다. Database process처럼 자기 memory management를 직접 하는 application도 pages를 pin하기를 원할 수 있다. 대부분 OS는 special privileges가 있어야 logical address region pinning을 허용한다.
Lock bit는 정상 page replacement policy에도 사용될 수 있다. Low-priority process가 page fault로 새 page를 가져왔지만 CPU를 아직 받지 못한 상태에서, high-priority process가 그 clean and unreferenced page를 victim으로 고르면 방금 page-in한 비용이 낭비된다. 새로 brought-in page가 한 번 실행될 때까지 lock bit를 켜 두는 policy로 이를 막을 수 있다. 하지만 lock bit가 켜진 뒤 꺼지지 않는 bug가 있으면 frame이 영구적으로 unusable해질 수 있으므로 조심해야 한다.
10.10 Operating-System Examples
Linux, Windows, Solaris는 모두 virtual memory의 핵심 기법인 demand paging, copy-on-write, shared libraries, LRU approximation 계열 replacement를 사용한다. 차이는 pages를 어떤 lists로 관리하고, free memory threshold를 어떻게 유지하며, pressure 상황에서 얼마나 aggressive하게 reclaim/swap하는지에 있다.
10.10.1 Linux
Linux는 demand paging을 사용하고, free frames list에서 pages를 할당한다. Page replacement는 Section 10.4.5.2의 LRU-approximation clock algorithm과 유사한 global policy를 사용한다. Linux는 pages를 크게 active list와 inactive list로 관리한다.
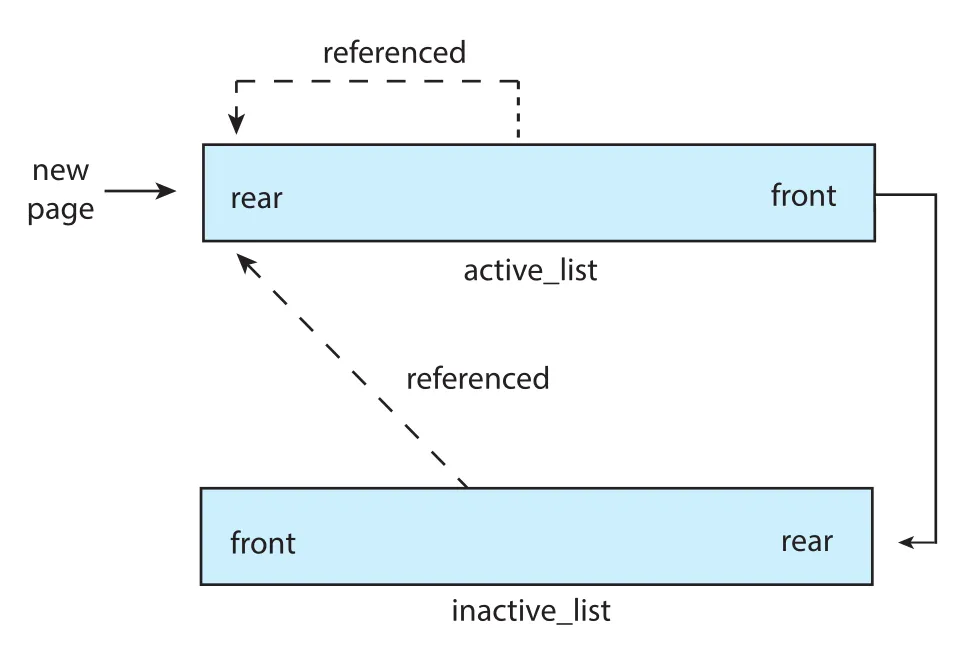
Figure 10.29 · PDF p. 549 · Linux가 active list와 inactive list로 pages의 최근 reference 여부와 reclaim 가능성을 관리하는 구조
active list에는 in use로 간주되는 pages가 들어 있고, inactive list에는 recently referenced되지 않아 reclaim 대상이 될 수 있는 pages가 들어 있다. 각 page에는 referenced/accessed bit가 있다. Page가 처음 allocated되면 accessed bit가 set되고 active list의 rear에 들어간다. Active list의 page가 reference되면 accessed bit가 set되고 list rear로 이동한다. Periodically, active list pages의 accessed bits는 reset된다. 시간이 지나면 least recently used page가 active list front로 이동하고, 거기서 inactive list rear로 migrate될 수 있다. Inactive list page가 reference되면 다시 active list rear로 이동한다.
Linux는 active/inactive lists의 상대적 균형을 유지한다. Active list가 inactive list보다 너무 커지면 active front의 pages가 inactive list로 이동해 reclaim eligible이 된다. kswapd page-out daemon은 주기적으로 wake up해 free memory를 확인하고, threshold 아래로 떨어지면 inactive list pages를 scan해 free list로 reclaim한다.
10.10.2 Windows
Windows 10은 shared libraries, demand paging, copy-on-write, paging, memory compression을 지원한다. Virtual memory는 demand paging with clustering으로 구현된다. clustering은 locality를 이용해 page fault가 발생한 page뿐 아니라 그 앞뒤 pages도 함께 가져오는 전략이다. Data page fault는 보통 faulting page 전후를 포함한 3-page cluster를, 다른 page faults는 7-page cluster를 사용할 수 있다.
Windows virtual memory management의 핵심은 working-set management다. Process가 생성되면 working-set minimum과 maximum이 할당된다. Working-set minimum은 process가 memory에 보장받는 최소 pages 수이고, memory가 충분하면 maximum까지 받을 수 있다. Hard working-set limits가 없으면 이 값들은 상황에 따라 무시될 수 있다. Memory가 충분하면 process가 maximum 이상으로 커질 수 있고, memory demand가 높으면 minimum 아래로 줄어들 수도 있다.
Windows는 LRU-approximation clock algorithm을 local/global replacement와 결합한다. Process가 working-set maximum보다 작고 page fault가 나면 free pages list에서 page를 받는다. Process가 maximum에 있어도 free memory가 충분하면 더 받을 수 있다. Free memory가 부족하면 kernel은 local LRU policy로 process working set에서 page를 replace한다.
Free memory가 threshold 아래로 떨어지면 Windows는 global tactic인 automatic working-set trimming을 수행한다. Processes에 allocated된 pages 수를 평가해, working-set minimum보다 많은 pages를 가진 process에서 pages를 제거한다. 큰 idle processes가 작은 active processes보다 먼저 target이 된다. 필요하면 minimum 아래에 있는 process에서도 pages를 제거할 수 있고, user-mode와 system processes 모두 trimming 대상이 된다.
10.10.3 Solaris
Solaris는 thread가 page fault를 내면 free pages list에서 page를 할당한다. Kernel은 충분한 free memory를 유지해야 하며, lotsfree threshold를 기준으로 paging을 시작한다. lotsfree는 보통 physical memory의 1/64로 설정된다. Kernel은 초당 4번 free memory가 lotsfree보다 작은지 검사하고, 작으면 pageout process를 시작한다.
Solaris pageout은 second-chance algorithm과 유사하지만 clock hand를 두 개 사용한다. Front hand는 all pages를 scan하며 reference bit를 0으로 clear한다. 시간이 지난 뒤 back hand가 reference bit를 검사하고, 여전히 0인 pages를 free list에 붙인다. Modified page는 secondary storage에 write한다. 이 구조는 “clear 후 일정 시간 동안 다시 reference되었는가”를 확인하는 clock approximation이다.
Solaris는 minor page faults도 최적화한다. Page가 free list에 있지만 아직 다른 process에 reassigned되지 않았다면, process가 다시 access할 때 free list에서 reclaim해 mapping할 수 있다.
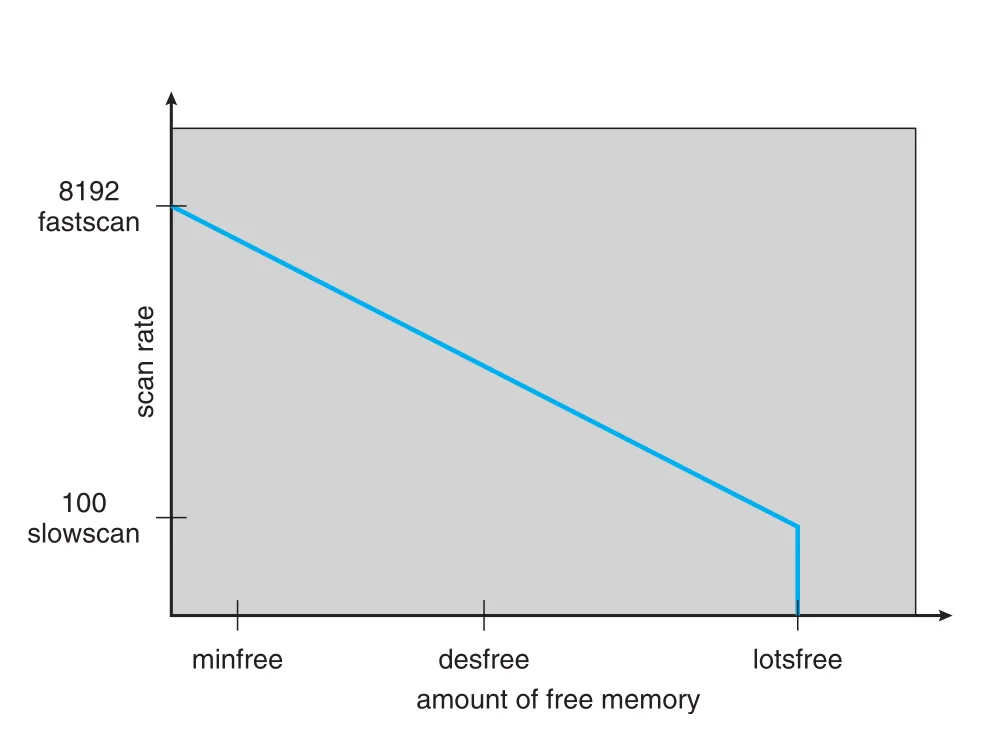
Figure 10.30 · PDF p. 551 · Solaris page scanner가 free memory thresholds에 따라 slowscan부터 fastscan까지 scanrate를 조절하는 구조
Pageout algorithm은 scanrate로 pages per second를 조절한다. Free memory가 lotsfree 아래로 내려가면 slowscan에서 시작해 free memory 양에 따라 fastscan까지 증가한다. Front hand와 back hand 사이 거리는 handspread가 정한다. Scanrate와 handspread가 reference bit clear와 검사 사이 시간을 결정한다.
Free memory가 desfree 아래로 떨어지면 pageout은 초당 100번 실행되어 desired free memory를 유지하려 한다. 30초 평균으로 desfree를 유지하지 못하면 kernel은 idle processes를 골라 swapping을 시작할 수 있다. minfree도 유지하지 못하면 새 page 요청마다 pageout이 호출된다. Solaris scanner는 shared libraries pages를 건너뛰기도 하고, process pages와 regular data file pages를 구분하는 priority paging을 사용한다.
연결 관계
| 연결 대상 | 연결 내용 |
|---|---|
| Chapter 3 | shared memory IPC가 virtual memory page sharing으로 구현될 수 있다. |
| Chapter 4 | threads와 processes의 address-space sharing 차이를 이해하는 기반이 된다. |
| Chapter 5 | CPU utilization을 높이려 multiprogramming degree를 늘리면 thrashing이 발생할 수 있어 scheduling과 memory management가 연결된다. |
| Chapter 9 | paging, page table, TLB, valid-invalid bit, swapping, shared pages가 virtual memory의 직접 기반이다. |
| Chapter 11 | swap space allocation, secondary storage I/O 비용, file-system demand paging과 연결된다. |
| Chapter 14 | I/O buffers와 virtual memory, priority paging, file caching이 연결된다. |
| Chapter 20 | Linux virtual memory implementation의 세부로 이어진다. |
오해하기 쉬운 내용
Virtual memory는 “physical memory보다 큰 program 실행”만 의미하지 않는다. Logical memory와 physical memory를 분리하고, demand paging, sharing, COW, efficient process creation을 가능하게 하는 전체 abstraction이다.
invalid bit는 항상 illegal address만 뜻하지 않는다. Demand paging에서는 legal page이지만 아직 memory에 없어서 secondary storage에 있는 경우도 invalid로 표시될 수 있다. 그래서 page fault handler는 internal table로 illegal reference인지 resident하지 않은 valid page인지 구분해야 한다.
Page fault는 exception이지만 항상 fatal error는 아니다. Demand paging에서는 정상 동작의 일부다. 다만 page-fault rate가 조금만 높아져도 effective access time이 급격히 나빠진다.
LRU는 개념적으로 좋아 보이지만 true LRU는 모든 memory reference를 추적해야 하므로 비용이 크다. 실제 OS는 reference bit 기반 second-chance, clock algorithm, active/inactive list 같은 approximation을 쓴다.
Frames 수를 늘리면 page faults가 항상 줄어드는 것은 아니다. FIFO 같은 algorithms는 Belady's anomaly를 보일 수 있다. OPT와 LRU 같은 stack algorithms는 이 anomaly가 없다.
Thrashing은 단순히 memory가 “조금 부족한 상태”가 아니다. Processes가 executing보다 paging에 더 많은 시간을 쓰고, CPU utilization이 낮아졌다고 multiprogramming degree를 더 늘리면 오히려 throughput이 붕괴하는 상태다.
큰 page size는 항상 좋은 것도, 작은 page size가 항상 좋은 것도 아니다. Page table size, internal fragmentation, I/O overhead, locality, page fault count, TLB reach가 서로 trade-off를 만든다.
Kernel memory allocation은 user memory allocation과 다르다. Kernel은 작은 object를 자주 할당하고, 일부 hardware가 physically contiguous memory를 요구하며, kernel code/data는 paging 대상이 아닐 수 있어 buddy/slab 같은 별도 allocator가 필요하다.
Page locking은 correctness를 위해 필요하지만 남용하면 memory-management algorithms에 stress를 준다. Lock bit가 풀리지 않으면 frame이 사실상 사라진 것처럼 된다.
면접 질문
virtual memory가 제공하는 핵심 이점 네 가지를 설명하라.demand paging에서 page fault가 발생하면 OS는 어떤 순서로 처리하는가?- Demand paging에서
valid-invalid bit의 invalid가 가질 수 있는 두 의미는 무엇인가? pure demand paging은 무엇이고, 왜 locality가 없으면 성능이 나빠지는가?- Effective access time 식에서 page-fault rate
p가 아주 작아야 하는 이유를 설명하라. copy-on-write가fork()성능을 어떻게 개선하는가?- Free frame이 없을 때
page replacement는 어떤 절차로 page fault를 해결하는가? modify bit또는dirty bit가 page replacement I/O 비용을 어떻게 줄이는가?- FIFO page replacement와
Belady's anomaly의 관계를 설명하라. OPT,FIFO,LRU의 victim 선택 기준을 비교하라.- True LRU 구현이 어려운 이유와
clock algorithm이 어떤 타협인지 설명하라. global replacement와local replacement의 장단점을 비교하라.major page fault와minor page fault는 무엇이 다르고 왜 비용 차이가 큰가?working set과thrashing의 관계를 설명하라.PFF방식은 working-set model과 달리 어떤 값을 직접 제어하는가?memory compression은 swapping과 비교해 어떤 비용을 어떤 비용으로 바꾸는가?- Kernel memory에
buddy system과slab allocation이 필요한 이유를 설명하라. - Page size를 정할 때 고려해야 하는 trade-off를 설명하라.
TLB reach는 무엇이고, huge pages가 이를 어떻게 늘리는가?- I/O buffer pages를
pinning하거나page locking해야 하는 이유는 무엇인가? - Linux의
active list와inactive list, Windows의working-set trimming, Solaris의pageoutscanner를 비교하라.