Chapter 14. File-System Implementation
- 과목: Operating System
- 기준 교재: Operating System Concepts 10th
- 관련 페이지: PDF pp. 695-724
- 우선순위: 필수
개요
Chapter 13이 file-system interface, 즉 사용자와 application이 보는 files/directories/protection을 설명했다면, Chapter 14는 그 interface를 실제 storage device 위에 어떻게 구현하는지 다룬다. 핵심은 logical file system을 physical blocks, buffers, caches, metadata, allocation/free-space structures, recovery mechanisms로 연결하는 것이다.
File-system implementation의 큰 질문은 두 가지다. 첫째, user에게 file, attributes, operations, directories를 어떤 모습으로 보여 줄 것인가. 둘째, 이 logical file system을 secondary-storage devices의 physical blocks에 mapping하기 위해 어떤 algorithms와 data structures를 사용할 것인가. 이 장은 두 번째 질문에 더 집중한다.
핵심 개념
| 개념 | 핵심 의미 |
|---|---|
file-system implementation | logical files/directories를 physical storage blocks와 metadata structures로 mapping하는 OS 내부 설계. |
layered file system | application programs, logical file system, file-organization module, basic file system, I/O control, devices로 나뉘는 계층형 구현. |
I/O control | device drivers와 interrupt handlers를 통해 memory와 device 사이 data transfer를 수행하는 layer. |
basic file system, block I/O subsystem | logical block address 기반 read/write commands를 device driver에 보내고 buffers/caches를 관리하는 layer. |
file-organization module | file의 logical blocks와 physical blocks mapping, free-space manager와의 block allocation을 담당하는 layer. |
logical file system | metadata, directory structure, file-control blocks, protection을 관리하는 layer. |
metadata | file contents 자체를 제외한 file-system structure. directories, FCBs, allocation info, permissions 등이 포함된다. |
FCB, inode | File-Control Block. file ownership, permissions, size, data block locations/pointers 등 per-file metadata. UNIX에서는 inode가 대표적이다. |
boot control block | volume에서 OS boot에 필요한 information을 담는 per-volume block. UFS boot block, NTFS partition boot sector가 예다. |
volume control block, superblock | volume size, block size, free-block count/pointers, free-FCB count/pointers 등 volume metadata를 담는 structure. |
directory-structure cache | recently accessed directories의 information을 memory에 저장해 directory operations를 빠르게 하는 cache. |
system-wide open-file table | open file의 FCB copy와 open count 등 process-independent open state를 담는 in-memory table. |
per-process open-file table | process가 연 files에 대한 pointers와 current offset/access mode 등 process-specific state를 담는 table. |
linear list directory | file names와 block pointers/metadata entries를 linear list로 관리하는 directory implementation. |
hash table directory | filename hash로 directory entry lookup을 빠르게 하는 directory implementation. |
contiguous allocation | file이 contiguous blocks를 차지하게 하는 allocation method. start block과 length로 file location을 표현한다. |
external fragmentation | free space가 여러 작은 holes로 나뉘어 충분한 total space가 있어도 contiguous request를 만족하지 못하는 현상. |
extent | file이 커질 때 추가되는 contiguous chunk. Modified contiguous allocation에서 사용된다. |
linked allocation | file을 scattered storage blocks의 linked list로 표현하는 allocation method. |
cluster | 여러 blocks를 묶어 allocation/transfer 단위로 사용하는 larger unit. Pointer overhead와 seek를 줄이지만 internal fragmentation을 키운다. |
FAT | File-Allocation Table. volume 앞부분 table에 block chain pointers를 모아 linked allocation을 구현하는 방식. |
indexed allocation | file별 index block에 data block addresses를 모아 direct access를 지원하는 allocation method. |
index block | file의 logical block i를 physical block address로 연결하는 pointer array block. |
single indirect, double indirect, triple indirect | UNIX inode에서 large file을 지원하기 위해 indirect blocks를 단계적으로 사용하는 pointer scheme. |
free-space list | free device blocks를 추적해 new file allocation과 deleted file space reuse를 가능하게 하는 structure. |
bitmap, bit vector | block마다 1 bit로 free/allocated 상태를 나타내는 free-space management 방식. |
grouping | 첫 free block에 여러 free block addresses를 저장해 많은 free blocks를 빠르게 찾는 방식. |
counting | first free block address와 연속 free block count를 함께 저장하는 free-space management 방식. |
space map, metaslab | ZFS에서 device space를 manageable chunks로 나누고, 각 chunk의 block activity log로 free space를 관리하는 구조. |
TRIM, unallocate | file system이 NVM/SSD controller에 freed pages/blocks를 알려 garbage collection과 erase를 미리 가능하게 하는 command. |
write cliff | SSD가 nearly full 상태에서 GC/erase pressure로 write performance가 급격히 떨어지는 현상. |
buffer cache, page cache | file-system blocks 또는 virtual memory pages를 memory에 cache하여 storage I/O를 줄이는 cache. |
unified buffer cache, unified virtual memory | memory-mapped I/O와 read/write I/O가 같은 page/cache path를 사용해 double caching을 피하는 구조. |
double caching | buffer cache와 page cache에 같은 file data가 중복 저장되어 memory/CPU/I/O를 낭비하고 consistency 위험을 만드는 현상. |
synchronous write, asynchronous write | stable storage 도달까지 caller가 기다리는 write와 cache에 저장 후 caller에게 즉시 return하는 write. |
free-behind, read-ahead | sequential access에서 이미 지난 pages를 빨리 해제하고 앞으로 읽을 pages를 미리 가져오는 cache optimization. |
consistency checker, fsck | file-system metadata와 on-storage state를 비교해 crash/corruption 이후 inconsistency를 탐지·수정하는 system program. |
journaling, log-based transaction-oriented file system | metadata updates를 sequential log에 transaction으로 먼저 기록한 뒤 실제 file-system structures에 replay하는 recovery 방식. |
transaction, commit, undo | 한 logical operation을 이루는 metadata changes 묶음, log에 안전히 기록된 상태, incomplete/aborted changes를 되돌리는 recovery 동작. |
copy-on-write, snapshot | 기존 blocks를 overwrite하지 않고 new blocks에 쓰며, old root/pointers를 보존해 특정 시점 file-system view를 만드는 방식. |
full backup, incremental backup | 전체 file system을 복사하는 backup과 이전 backup 이후 변경된 files만 복사하는 backup. |
WAFL, write-anywhere file layout | random writes에 최적화된 NetApp file system. 기존 blocks를 overwrite하지 않고 가까운 free blocks에 새 data/metadata를 쓴다. |
root inode, metadata files | WAFL에서 file system tree의 base가 되는 inode와, inodes/free-block map/free-inode map 자체를 ordinary files로 두는 구조. |
NVRAM cache | WAFL file servers가 writes를 안정적으로 받아 두기 위해 사용하는 nonvolatile write cache. |
clone, replication | read-write snapshot-like copy와 snapshot 차이를 이용해 remote system을 동기화하는 disaster-recovery mechanism. |
세부 정리
14.1 File-System Structure
File systems는 대부분 secondary storage 위에 유지된다. HDD는 file system에 편리한 두 성질을 갖는다. 첫째, block을 read-modify-write하여 same block에 rewrite in place할 수 있다. 둘째, 임의의 block을 direct access할 수 있어 sequential access와 random access를 모두 지원한다. 반면 NVM devices는 file storage로 점점 많이 쓰이지만, in-place rewrite가 어렵고 performance characteristics가 HDD와 다르다.
I/O efficiency를 위해 memory와 mass storage 사이 transfers는 blocks 단위로 수행된다. HDD block은 one or more sectors를 포함하며 sector size는 보통 512 bytes 또는 4,096 bytes다. NVM devices도 흔히 4,096-byte blocks를 가지며 transfer methods는 disk drives와 유사하게 추상화된다.
File system은 efficient/convenient access를 위해 data를 stored, located, retrieved할 수 있게 한다. 이를 구현하는 전형적 구조가 layered design이다.
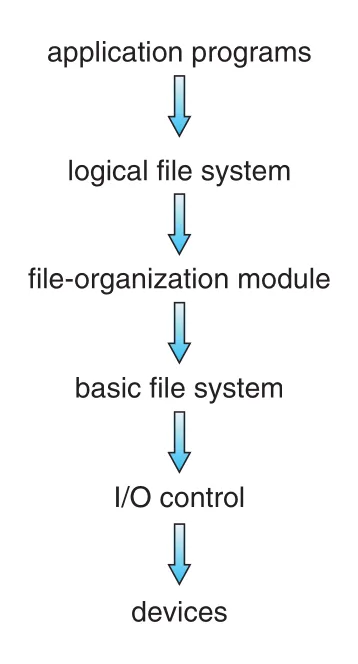
Figure 14.1 · PDF p. 696 · application programs부터 devices까지 file-system functionality를 계층으로 나눈 구조
각 layer는 아래 layer의 기능을 사용해 위 layer에 더 높은 abstraction을 제공한다.
| Layer | 역할 |
|---|---|
application programs | system calls/library calls로 files를 사용 |
logical file system | metadata, directory structure, FCB/inode, protection 관리 |
file-organization module | file logical blocks와 physical blocks mapping, free-space manager와 allocation 처리 |
basic file system | generic block read/write commands, I/O request scheduling, buffers/caches 관리 |
I/O control | device drivers와 interrupt handlers로 controller/device-specific commands 수행 |
devices | HDD/NVM 등 physical storage |
I/O control layer의 device driver는 translator처럼 동작한다. “retrieve block 123” 같은 high-level command를 hardware controller가 이해하는 low-level, hardware-specific instructions로 바꾼다. 이 내용은 Chapter 12의 I/O subsystem과 직접 연결된다.
basic file system은 Linux에서 block I/O subsystem이라고도 부르며, logical block addresses를 기반으로 read/write commands를 device driver에 보낸다. 또한 I/O request scheduling과 buffers/caches를 관리한다. Buffer는 storage block transfer 전에 allocate되어야 하고, buffer가 부족하면 buffer manager가 memory를 확보하거나 free buffer를 찾아야 한다. Cache는 frequently used metadata blocks를 보관해 performance를 높인다.
file-organization module은 file과 file logical blocks를 안다. 각 file의 logical blocks는 0 또는 1부터 N까지 numbered된다. 이 module은 unallocated blocks를 추적하고 요청 시 block을 제공하는 free-space manager도 포함한다.
logical file system은 metadata를 관리한다. Metadata는 actual file data를 제외한 file-system structure 전체다. Logical file system은 symbolic file name으로부터 필요한 directory information을 찾아 file-organization module에 제공하고, FCB (file-control block) 또는 UNIX의 inode를 통해 file structure를 유지한다. FCB에는 ownership, permissions, file contents location 등이 포함된다.
Layering은 code duplication을 줄인다. I/O control과 basic file-system code는 여러 file systems가 공유할 수 있고, 각 file system은 자기 logical file-system/file-organization modules를 둘 수 있다. 단점은 layer를 거치며 OS overhead가 늘어 performance가 떨어질 수 있다는 점이다. 따라서 어떤 기능을 어떤 layer에 둘지와 layer 수를 정하는 것은 중요한 design challenge다.
Modern OS는 여러 file systems를 지원한다. 예를 들어 removable media용 ISO 9660, Windows의 FAT/FAT32/NTFS, Linux의 ext3/ext4, UNIX의 UFS/FFS, distributed file systems 등이 있다. FUSE는 file system을 kernel-level이 아니라 user-level code로 구현/실행해 development flexibility를 높이는 예다.
14.2 File-System Operations
Chapter 13에서 open()/close() interface를 봤다면, 여기서는 이를 구현하기 위해 file system이 어떤 on-storage/in-memory structures를 유지하는지 본다.
14.2.1 Overview
File-system implementation은 on-storage structures와 in-memory structures를 함께 사용한다. On storage에는 boot, volume, directory, per-file metadata가 저장된다.
| On-storage structure | 범위 | 역할 |
|---|---|---|
boot control block | per volume | 해당 volume에서 OS boot에 필요한 information 저장. OS가 없으면 empty 가능 |
volume control block, superblock | per volume | block count, block size, free-block count/pointers, free-FCB count/pointers 등 volume details 저장 |
directory structure | per file system | file names와 associated identifiers/inodes를 organize |
per-file FCB | per file | unique identifier, file attributes, file block locations/pointers 등 file metadata 저장 |
In-memory structures는 management와 caching을 위해 mount time에 load되고, file-system operations 중 update되며, dismount 시 discard된다.
| In-memory structure | 역할 |
|---|---|
in-memory mount table | mounted volumes 정보 유지 |
directory-structure cache | recently accessed directories의 information 보관 |
system-wide open-file table | open file별 FCB copy와 open count 등 저장 |
per-process open-file table | process별 open files에 대한 system-wide table pointers와 offset/access mode 저장 |
buffers | file-system blocks를 read/write 중 임시 보관 |
새 file을 create할 때 process는 logical file system을 호출한다. Logical file system은 directory format을 알고 있으므로, 새 FCB를 allocate하고, appropriate directory를 memory로 읽어 new file name과 FCB를 추가한 뒤 file system에 다시 쓴다.
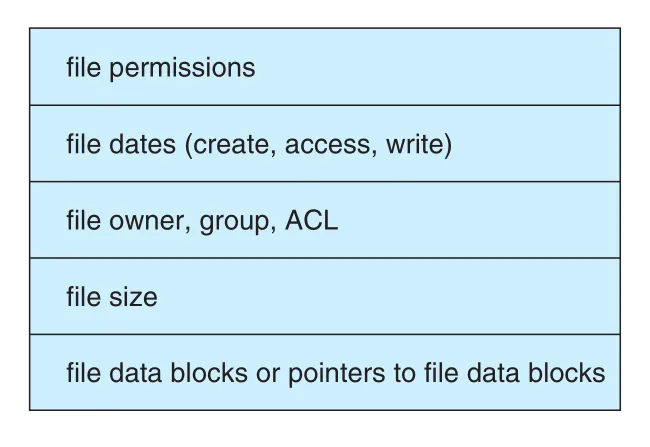
Figure 14.2 · PDF p. 698 · permissions, dates, owner/group/ACL, size, data block pointers를 담는 file-control block 예
UNIX처럼 directory를 type field가 directory인 special file로 취급하는 OS도 있고, Windows처럼 files와 directories에 별도 system calls를 제공하고 directories를 files와 별도 entity로 다루는 OS도 있다. 어느 쪽이든 logical file system은 directory I/O를 storage block locations로 mapping하기 위해 file-organization module을 호출하고, 그 아래 basic file system과 I/O control로 request가 내려간다.
14.2.2 Usage
File을 I/O에 사용하려면 먼저 open()해야 한다. open()은 file name을 logical file system에 전달한다. OS는 먼저 system-wide open-file table을 확인해 다른 process가 이미 그 file을 사용 중인지 본다. 이미 열려 있으면 per-process open-file table entry만 새로 만들고 existing system-wide entry를 가리키게 할 수 있어 overhead를 줄인다.
File이 아직 열려 있지 않으면 directory structure에서 file name을 search한다. Directory structure 일부는 보통 memory에 cached되어 directory operations를 빠르게 한다. File을 찾으면 FCB를 in-memory system-wide open-file table로 copy한다. 이 table은 FCB뿐 아니라 file을 연 processes 수, 즉 open count도 추적한다.
다음으로 per-process open-file table entry가 생성된다. 이 entry는 system-wide open-file table entry를 가리키고, next read()/write()를 위한 current location pointer와 open access mode 같은 process-specific fields를 담는다. open()은 이 per-process table entry pointer를 반환한다. UNIX에서는 file descriptor, Windows에서는 file handle이라고 부른다.
close() 때는 per-process table entry가 제거되고 system-wide entry의 open count가 감소한다. 모든 users가 close하여 open count가 0이 되면 updated metadata가 disk-based directory structure로 복사되고 system-wide open-file table entry가 제거된다.
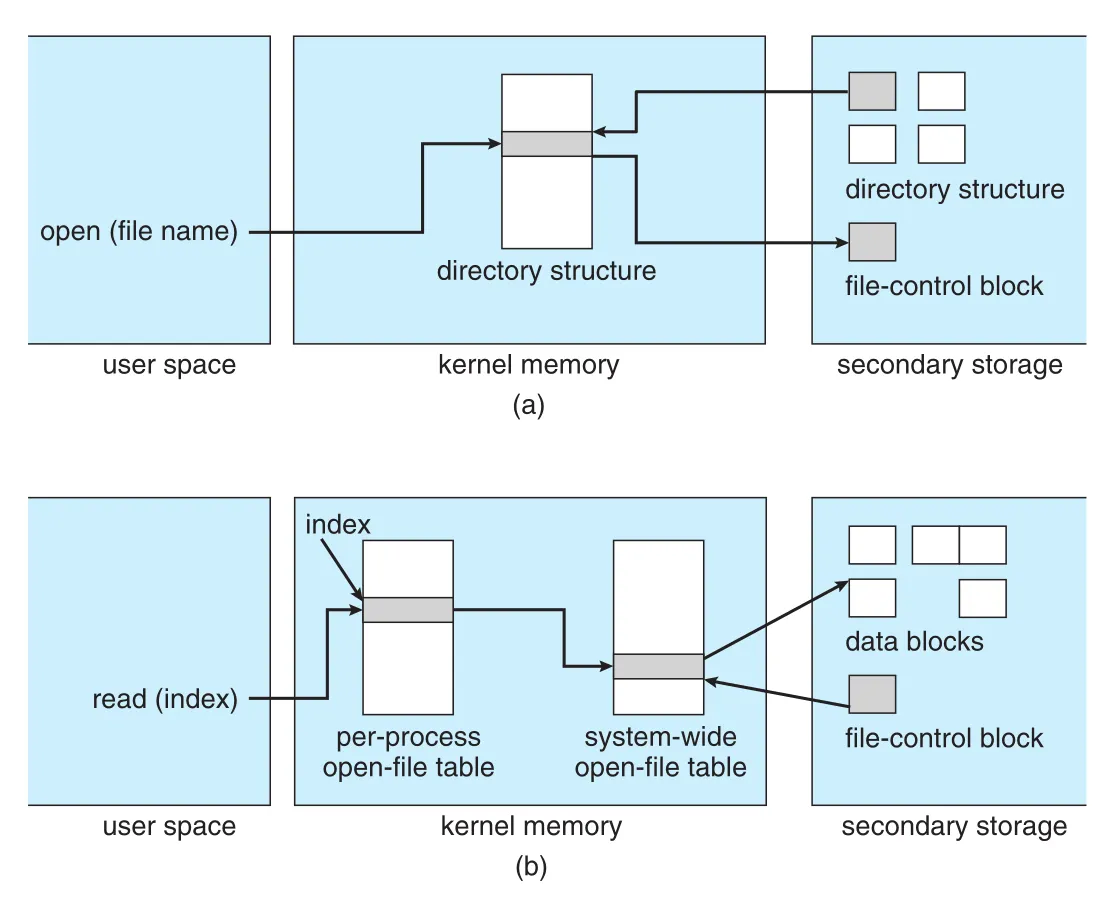
Figure 14.3 · PDF p. 700 · file open과 read 시 user space, kernel memory, secondary storage의 directory/FCB/open-file table 관계
Open file 정보는 actual data blocks를 제외하면 대부분 memory에 유지된다. BSD UNIX는 disk I/O를 줄일 수 있는 곳에 caches를 적극 사용하며, 원문은 average cache hit rate 85 percent를 예로 든다. 여기서 중요한 점은 file-system performance가 metadata caching에 크게 의존한다는 것이다.
14.3 Directory Implementation
Directory allocation/management algorithm 선택은 file system의 efficiency, performance, reliability에 큰 영향을 준다. Directory는 file name lookup이 자주 일어나는 구조이므로 단순성만으로는 충분하지 않을 수 있다.
14.3.1 Linear List
가장 단순한 directory implementation은 file names와 data block pointers 또는 FCB pointers의 linear list다. Programming은 쉽지만 execution time이 길 수 있다.
Create 시에는 같은 name이 이미 있는지 확인하기 위해 directory를 search한 뒤 end에 new entry를 추가한다. Delete 시에는 named file entry를 search하고 file space를 release한다. Freed directory entry는 several ways로 reuse할 수 있다.
- special unused name, invalid inode number, used/unused bit로 mark
- free directory entries list에 연결
- directory의 last entry를 freed location으로 copy하고 directory length 감소
- linked list를 사용해 delete time 감소
진짜 단점은 file lookup이 linear search라는 점이다. Directory information은 매우 자주 사용되므로 access가 느리면 사용자가 체감한다. 많은 OS는 recently used directory information을 software cache에 저장해 cache hit 시 secondary storage reread를 피한다. Sorted list는 binary search를 가능하게 해 average search time을 줄이지만, create/delete 때 sorted order 유지를 위해 많은 directory information을 이동해야 할 수 있다. Balanced tree 같은 더 sophisticated structure도 사용할 수 있다.
14.3.2 Hash Table
Directory에 사용할 수 있는 또 다른 structure는 hash table이다. Linear list가 directory entries를 저장하고, hash table은 file name에서 계산한 value로 linear list의 entry pointer를 반환한다. 이 방식은 directory search time을 크게 줄일 수 있다.
Insertion/deletion도 비교적 straightforward하지만 collisions를 처리해야 한다. Fixed-size hash table은 size와 hash function dependency가 문제다. 예를 들어 64 entries hash table을 쓰다가 65번째 file을 만들려면 table을 128 entries로 늘리고, hash function range도 0-127로 바뀌며, 기존 entries를 reorganize해야 한다.
대안은 chained-overflow hash table이다. 각 hash entry가 single value가 아니라 linked list를 가리키고, collision entries를 그 list에 붙인다. Lookup은 colliding entries linked list를 따라가야 하므로 약간 느려질 수 있지만, 전체 directory linear search보다는 대체로 훨씬 빠르다.
14.4 Allocation Methods
Secondary storage는 direct access가 가능하므로 files를 구현하는 방식에 유연성이 있다. 문제는 같은 device에 많은 files를 저장할 때, storage space를 효과적으로 사용하면서 files를 빠르게 access할 수 있도록 blocks를 어떻게 배치하느냐이다. 대표적인 allocation methods는 contiguous, linked, indexed 세 가지다. 각 방식은 storage efficiency와 access time에서 서로 다른 trade-off를 갖는다.
14.4.1 Contiguous Allocation
contiguous allocation은 file이 device의 contiguous blocks 집합을 차지하게 한다. File이 block 에서 시작하고 길이가 blocks라면, file은 을 차지한다. Directory entry에는 starting block address와 length가 들어간다.
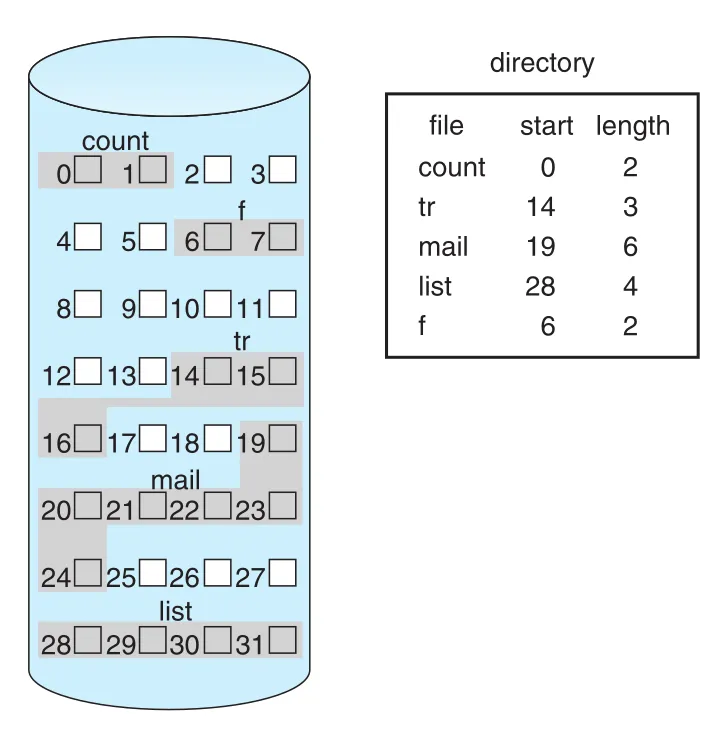
Figure 14.4 · PDF p. 702 · directory entry가 start와 length를 저장하고 file blocks가 연속 배치되는 contiguous allocation
Contiguous allocation은 sequential access와 direct access 모두 빠르다. Sequential access에서는 last referenced block 다음 block을 읽으면 되고, direct access에서는 file block 를 로 즉시 계산할 수 있다. HDD에서는 contiguous access가 seeks를 최소화한다. Logical addresses가 physical proximity와 어느 정도 대응된다는 가정에서 특히 효과가 크다.
하지만 contiguous allocation은 몇 가지 근본 문제가 있다.
| 문제 | 설명 |
|---|---|
| space finding | new file이 요청한 크기만큼 contiguous free hole을 찾아야 함 |
external fragmentation | file create/delete 반복으로 free space가 작은 holes로 쪼개짐 |
| size predeclaration | file 생성 시 필요한 total size를 알아야 함 |
| growth difficulty | file 뒤쪽 space가 이미 사용 중이면 in-place extension이 어려움 |
| compaction cost | free space를 하나로 모으려면 file system copy/defragmentation이 필요하며 시간이 큼 |
Free hole 선택은 dynamic storage-allocation problem과 같다. first fit과 best fit이 일반적이며, 둘 다 worst fit보다 time/storage utilization 측면에서 낫다. First fit은 대체로 더 빠르다.
External fragmentation을 줄이려면 file system 전체를 다른 device로 copy하고 original device를 비운 뒤 다시 contiguous하게 copy back하는 compaction을 할 수 있다. 하지만 large storage device에서는 hours가 걸릴 수 있고, production system에서는 downtime 또는 큰 performance penalty가 생긴다.
File size 예측도 어렵다. 너무 작게 allocate하면 file을 extend할 수 없고, 너무 크게 allocate하면 long period 동안 unused space가 생긴다. 이를 완화하는 방식이 extent 기반 modified contiguous allocation이다. 처음에는 contiguous chunk를 주고, 부족하면 another contiguous chunk인 extent를 추가한다. File location은 (location, block count)와 next extent link로 기록된다. Extents는 performance를 높이지만, extent가 너무 크면 internal fragmentation이 생기고 varying-size extents가 allocate/deallocate되면 external fragmentation도 생긴다.
14.4.2 Linked Allocation
linked allocation은 contiguous allocation의 size declaration과 external fragmentation 문제를 해결한다. File은 storage blocks의 linked list이고, blocks는 device 어디에나 흩어질 수 있다. Directory entry는 file의 first block과 last block pointer를 가진다. 각 block은 next block pointer를 포함한다.
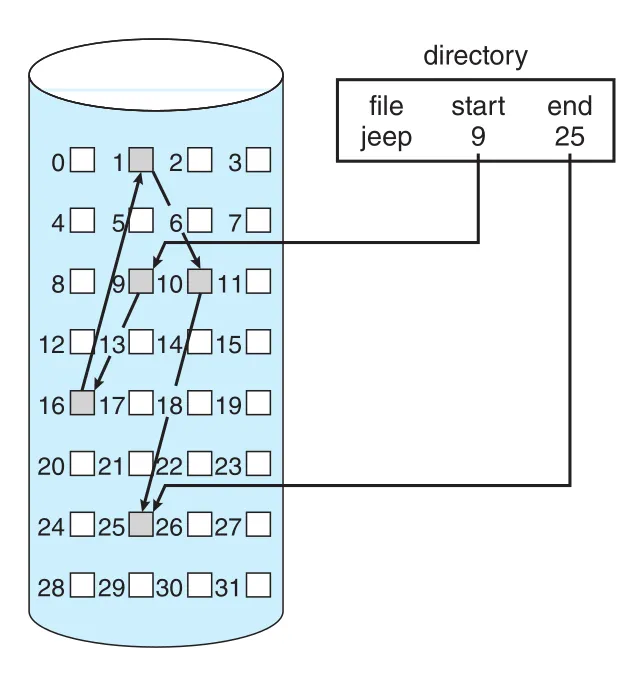
Figure 14.5 · PDF p. 704 · file blocks가 흩어져 있고 각 block이 next block pointer로 연결되는 linked allocation
New file create 시 directory entry의 first pointer는 null이고 size는 0이다. Write가 발생하면 free-space manager가 free block을 찾아 file end에 link한다. Read는 first block부터 pointers를 따라가며 blocks를 읽는다. Any free block can satisfy a request이므로 external fragmentation이 없고, file size를 creation time에 선언할 필요도 없다. Free blocks가 있는 한 file은 계속 grow할 수 있다.
단점도 명확하다.
| 단점 | 이유 |
|---|---|
| poor direct access | i번째 block을 찾으려면 beginning부터 pointers를 i번 따라가야 함 |
| pointer overhead | block마다 next pointer 공간이 data 대신 사용됨 |
| reliability risk | pointer가 손상되면 free-space list나 다른 file로 잘못 연결될 수 있음 |
| HDD seek cost | scattered blocks 때문에 sequential access라도 physical locality가 나쁠 수 있음 |
Pointer overhead를 줄이기 위해 blocks를 clusters로 묶어 cluster 단위로 allocate할 수 있다. Cluster는 pointer 비율을 줄이고 HDD throughput을 높인다. 그러나 partially full cluster가 늘어 internal fragmentation이 커지고, small random I/O도 큰 cluster transfer를 일으켜 random I/O performance를 해칠 수 있다.
Reliability 문제를 줄이기 위해 doubly linked lists를 쓰거나 각 block에 file name과 relative block number를 저장할 수 있지만, overhead가 더 커진다.
FAT (file-allocation table)은 linked allocation의 중요한 변형이다. Volume beginning의 table에 one entry per block을 두고, table entry가 next block number를 저장한다. Directory entry는 first block number를 담고, FAT entry chain을 따라가면 file blocks를 찾는다. Unused block은 0 같은 value로 표시되고, last block은 special end-of-file value를 가진다.
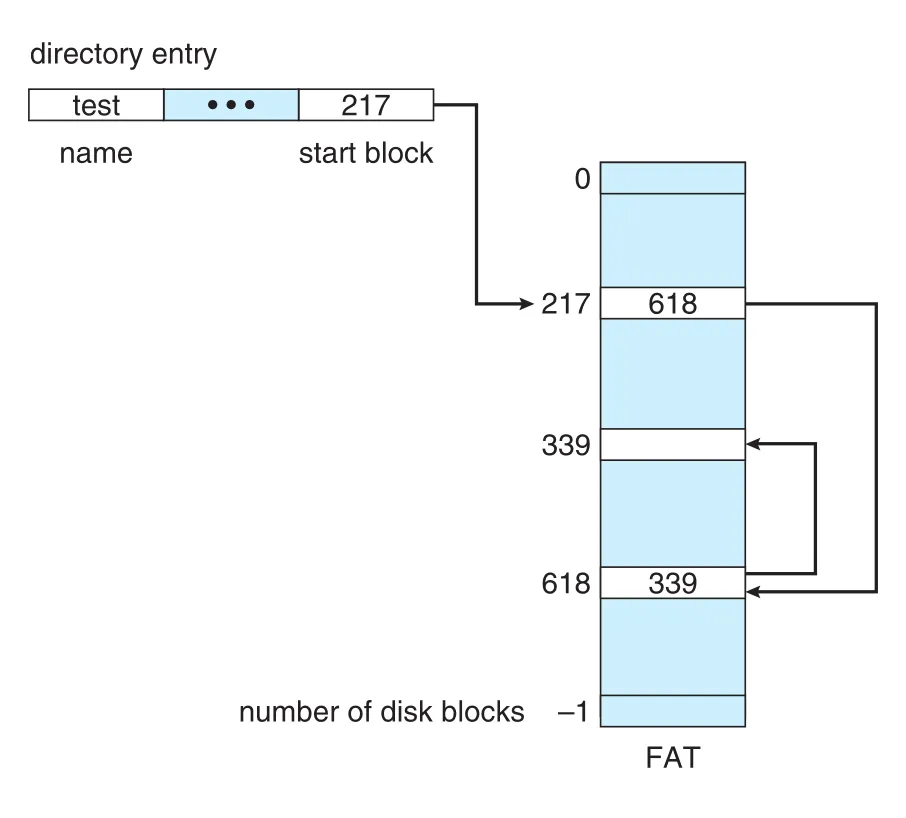
Figure 14.6 · PDF p. 706 · directory의 start block에서 FAT entries를 따라 file block chain을 찾는 구조
FAT는 table을 cache하지 않으면 head seeks가 많을 수 있다. 각 block 위치를 찾기 위해 volume beginning의 FAT로 이동했다가 actual block 위치로 이동해야 할 수 있기 때문이다. 하지만 FAT를 memory에 cache하면 random access가 linked allocation보다 훨씬 좋아진다. Block chain pointers가 disk 전체에 흩어진 것이 아니라 table에 모여 있기 때문이다.
14.4.3 Indexed Allocation
indexed allocation은 linked allocation의 external fragmentation과 size declaration 문제를 해결하면서 direct access를 지원한다. 핵심은 file의 모든 block pointers를 한 곳, 즉 index block에 모으는 것이다.
각 file은 자기 index block을 가진다. Index block은 storage-block addresses의 array이고, i번째 entry가 file의 i번째 block을 가리킨다. Directory entry는 index block address를 담는다.
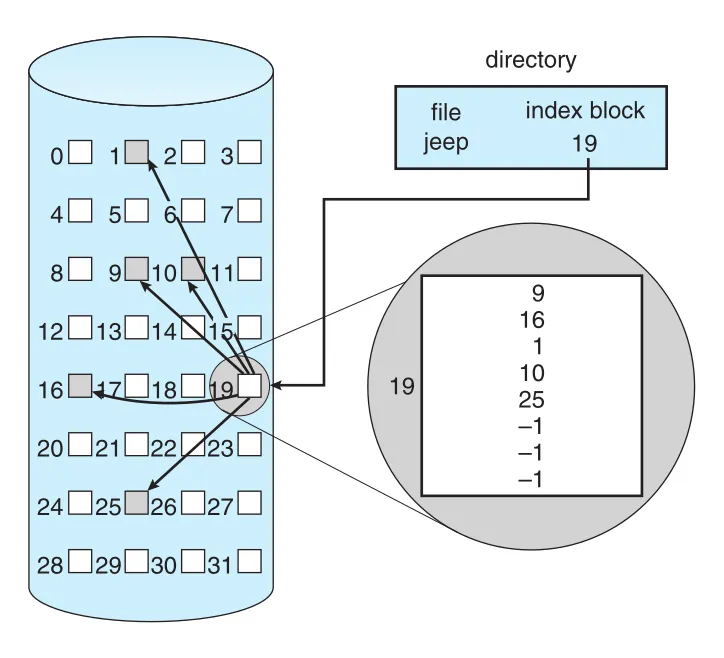
Figure 14.7 · PDF p. 707 · directory가 index block을 가리키고 index block entries가 file data blocks를 가리키는 indexed allocation
File이 create되면 index block pointers는 null로 초기화된다. i번째 block이 처음 write될 때 free-space manager에서 block을 얻고, 그 address를 index block의 i번째 entry에 넣는다. Any free block을 사용할 수 있으므로 external fragmentation이 없고, i번째 block address를 index entry로 바로 찾으므로 direct access가 가능하다.
문제는 index block 공간 낭비다. File이 1-2 blocks뿐이어도 entire index block을 allocate해야 할 수 있다. Index block이 작으면 large file pointers를 담을 수 없고, 크면 small files에서 낭비가 커진다. 이를 해결하는 mechanisms는 다음과 같다.
| Mechanism | 방식 |
|---|---|
| linked scheme | 여러 index blocks를 linked list로 연결 |
| multilevel index | first-level index가 second-level index blocks를 가리키고, 그 blocks가 data blocks를 가리킴 |
| combined scheme | inode 안 direct pointers와 single/double/triple indirect pointers를 함께 둠 |
UNIX-style combined scheme은 small files를 효율적으로 처리하면서 large files도 지원한다. Inode의 첫 12 pointers는 direct blocks를 가리키고, 그다음은 single indirect, double indirect, triple indirect blocks를 가리킨다. Small file은 separate index block 없이 direct pointers만으로 처리되고, large file은 indirect levels를 통해 많은 blocks를 주소화한다.
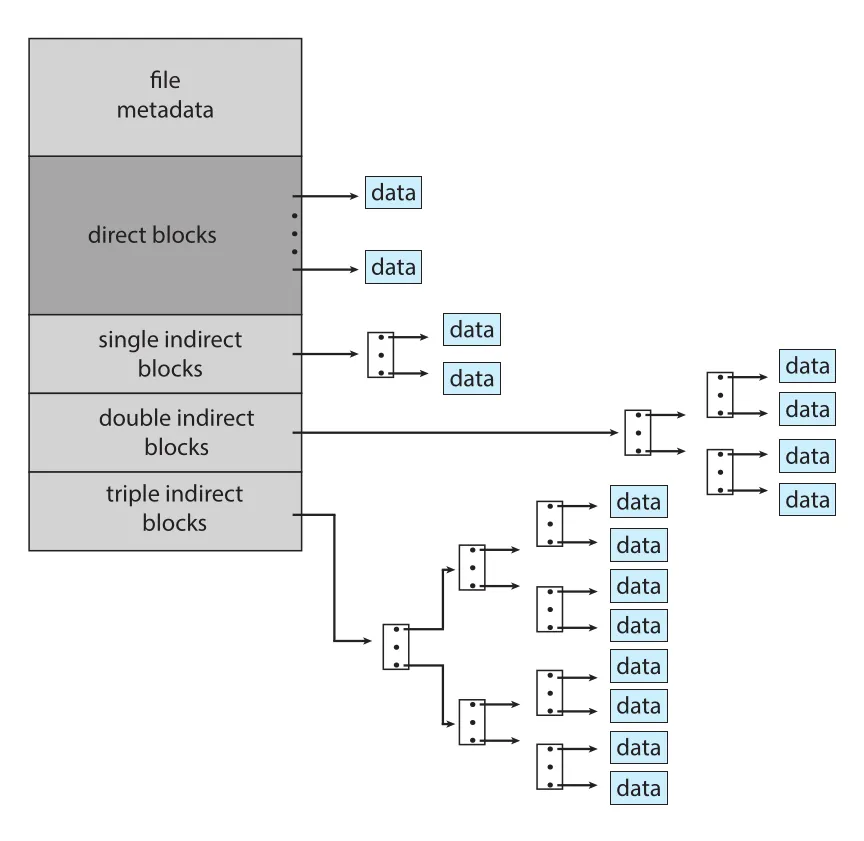
Figure 14.8 · PDF p. 708 · direct blocks와 single/double/triple indirect blocks를 결합해 small/large files를 모두 지원하는 UNIX inode
Pointer size도 maximum file size에 영향을 준다. 32-bit file pointer는 4GB 정도만 address할 수 있지만, 64-bit file pointers는 exbibytes 규모를 지원할 수 있고, ZFS는 128-bit file pointers를 지원한다.
Indexed allocation도 performance 문제가 있다. Index blocks는 memory에 cache할 수 있지만 data blocks는 volume 전체에 흩어질 수 있다. 따라서 direct access 구조는 좋지만 physical locality는 별도의 allocation 정책에 의존한다.
14.4.4 Performance
Allocation method 선택 기준은 storage efficiency와 data-block access time이다. Workload가 mostly sequential인지 random인지에 따라 좋은 방식이 달라진다.
| Method | Sequential access | Direct/random access | 주요 비용 |
|---|---|---|---|
contiguous allocation | 매우 좋음. next block 계산이 쉬움 | 매우 좋음. block b+i 계산 가능 | external fragmentation, size preallocation/growth 문제 |
linked allocation | current next pointer를 memory에 두면 괜찮음 | 나쁨. i번째 block까지 i block reads 필요 가능 | pointer overhead, reliability, poor locality |
FAT | FAT cache 시 좋음 | FAT cache 시 linked보다 개선 | FAT cache 없으면 head seeks 증가 |
indexed allocation | index block cache 시 좋음 | 좋음. index entry로 direct lookup | index block overhead, multi-level lookup, scattered data blocks |
일부 systems는 access type에 따라 allocation method를 다르게 쓴다. Sequential-access files는 linked allocation, direct-access files는 contiguous allocation을 사용하는 식이다. 이 경우 file creation 시 access type을 declare해야 하고, type conversion은 새 file을 원하는 type으로 만들고 old file contents를 copy한 뒤 rename/delete하는 식으로 수행한다.
Indexed allocation performance는 index structure, file size, desired block position에 달려 있다. Index block이 memory에 있으면 direct access가 빠르지만, memory가 부족하면 index block부터 read해야 한다. Two-level index는 data block 접근 전 두 index-block reads가 필요할 수 있고, very large file의 끝부분 block은 여러 index blocks를 거쳐야 할 수 있다.
HDD에서는 disk-head movement를 줄이기 위해 OS에 수천 또는 수십만 instructions를 더 넣는 것이 합리적일 수 있다. CPU와 disk speed disparity가 크기 때문이다. 반면 NVM devices에는 disk head seeks가 없으므로, head movement를 피하려 많은 CPU cycles를 쓰는 old algorithm은 비효율적이다. NVM용 file systems/optimizations는 instruction count와 storage-to-application path를 줄이는 방향으로 발전한다.
14.5 Free-Space Management
Storage space는 한정되어 있으므로 deleted files의 space를 new files에 재사용해야 한다. File system은 allocated되지 않은 device blocks를 기록하는 free-space list를 유지한다. File create 시 필요한 free space를 찾아 allocate하고, deleted file의 blocks는 다시 free-space structure에 추가한다. 이름은 list지만 실제 구현은 bitmap, linked list, grouping, counting, space map 등 다양하다.
14.5.1 Bit Vector
bitmap 또는 bit vector는 block마다 1 bit를 둔다. Block이 free이면 bit는 1, allocated이면 0이다. 예를 들어 blocks 2, 3, 4, 5, 8-13, 17, 18, 25-27이 free라면 bitmap은 001111001111110001100000011100000 ...처럼 표현된다.
Bit vector의 장점은 단순성과 contiguous free blocks 탐색 효율이다. Hardware bit-manipulation instructions를 활용해 nonzero word를 찾고, 그 word 안의 first 1 bit를 찾으면 first free block을 계산할 수 있다.
단점은 bitmap 전체를 main memory에 유지하지 않으면 비효율적이라는 점이다. 큰 storage에서는 bitmap도 커진다. 1TB disk에 4KB blocks를 쓰면 free-space bitmap은 약 32MB 규모가 된다. Disk capacity가 커질수록 bit vector memory footprint도 계속 증가한다.
14.5.2 Linked List
다른 방식은 모든 free blocks를 linked list로 연결하는 것이다. File system의 special location에 first free block pointer를 두고, 그 block이 next free block을 가리키는 식이다.
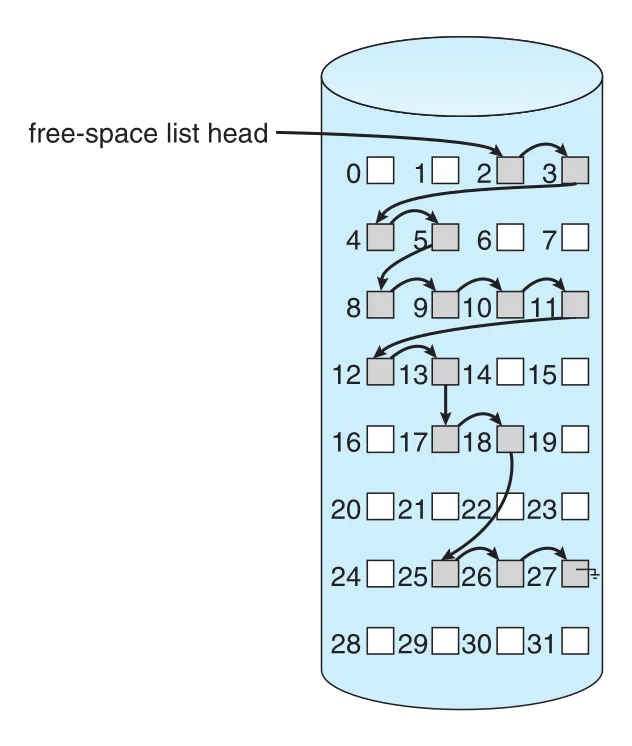
Figure 14.9 · PDF p. 711 · free blocks가 pointers로 연결되고 free-space list head가 첫 free block을 가리키는 구조
Linked free-space list는 전체 list traversal이 느리다. 각 free block을 읽어야 하므로 HDD에서는 substantial I/O time이 든다. 하지만 실제로 OS는 보통 “free block 하나”가 필요할 뿐 전체 free list를 자주 traverse하지 않으므로, 첫 free block을 사용하는 상황에서는 괜찮다. FAT 방식은 allocation data structure 자체에 free-block accounting을 포함하므로 separate free-space method가 필요 없다.
14.5.3 Grouping
grouping은 free-list approach를 변형해 first free block에 n free blocks의 addresses를 저장한다. 첫 n-1 blocks는 실제 free blocks이고, 마지막 block은 다음 n free block addresses를 담는 block이다. Standard linked list보다 한 번에 많은 free block addresses를 빠르게 얻을 수 있다.
14.5.4 Counting
counting은 contiguous free blocks가 한꺼번에 allocate/free되는 경우가 많다는 점을 이용한다. 단순히 free block addresses를 나열하지 않고, first free block address와 그 뒤에 이어지는 free contiguous blocks의 count를 함께 저장한다. Entry는 (device address, count)가 된다. 각 entry는 simple address보다 크지만, count가 1보다 크면 전체 list는 짧아진다. 이 방식은 extent-based allocation과 비슷하며, efficient lookup/insertion/deletion을 위해 balanced tree에 저장할 수 있다.
14.5.5 Space Maps
ZFS는 huge numbers of files/directories/file systems를 다루도록 설계되었고, 이런 scale에서는 metadata I/O가 성능에 큰 영향을 준다. Free-space bitmap을 사용하면 1GB data를 free할 때 blocks가 disk 전체에 scattered되어 있을 수 있어 thousands of bitmap blocks를 update해야 할 수 있다.
ZFS는 이를 줄이기 위해 metaslabs와 space maps를 사용한다. Device space를 manageable-size chunks인 metaslabs로 나누고, 각 metaslab에 space map을 둔다. Space map은 block allocation/free activity를 time order로 기록한 log이며, counting format을 사용한다.
ZFS가 특정 metaslab에서 space를 allocate/free하려 할 때 associated space map을 memory로 load하고, balanced-tree structure에 log를 replay한다. 그 결과 in-memory space map은 해당 metaslab의 allocated/free state를 정확히 나타낸다. Contiguous free blocks는 하나의 entry로 합쳐 map을 줄인다. On-disk update는 ZFS의 transaction-oriented operations 일부로 수행된다. 즉 ZFS에서 free list는 log와 balanced tree가 결합된 구조로 이해할 수 있다.
14.5.6 TRIMing Unused Blocks
HDD처럼 overwrite가 가능한 storage media에서는 freed block을 특별히 지울 필요가 없다. Pointer만 없어질 뿐 data는 다음 allocation에서 overwrite될 때까지 남아 있을 수 있다.
NVM flash-based storage처럼 overwrite가 불가능한 devices에서는 같은 알고리즘을 쓰면 문제가 커진다. Flash는 write 전에 erase가 필요하고, erase는 pages보다 큰 blocks 단위로 수행되며 read/write보다 느리다. File system이 block을 free했다는 사실을 device가 모르면 device는 어떤 pages를 erase candidate로 삼을지 알기 어렵다.
그래서 file system이 storage controller에게 page/block이 free되어 erasure 대상으로 고려될 수 있음을 알려야 한다. ATA-attached drives에서는 TRIM, NVMe storage에서는 unallocate command가 이 역할을 한다. 이런 mechanism이 없으면 device가 full에 가까워질 때 garbage collection과 block erasure가 write path에 몰려 write performance가 급락한다. 이 현상이 write cliff다. TRIM/unallocate는 GC와 erase를 device가 미리 수행하게 하여 더 consistent한 write performance를 가능하게 한다.
14.6 Efficiency and Performance
Allocation과 directory-management algorithms를 선택한 뒤에도 file-system efficiency/performance를 개선할 여지가 많다. HDD는 system performance의 major bottleneck이고, NVM도 CPU/main memory에 비하면 느리므로 storage access path를 최적화해야 한다.
14.6.1 Efficiency
Storage efficiency는 allocation/directory algorithms에 크게 의존한다. UNIX inodes는 volume에 preallocated된다. Empty disk라도 일부 space를 inodes가 차지해 lost space가 생기지만, inodes를 preallocate하고 volume 전체에 spread하면 file data blocks를 inode block 근처에 배치할 수 있어 seek time을 줄인다.
Cluster size도 efficiency/performance trade-off다. Clustering은 file seek와 transfer performance를 개선하지만 internal fragmentation을 증가시킨다. BSD UNIX는 file growth에 따라 cluster size를 다르게 사용해 fragmentation을 줄인다. Large clusters는 채울 수 있을 때 사용하고, small files와 last cluster에는 small clusters를 사용한다.
Directory/inode entry에 어떤 metadata를 유지할지도 성능에 영향을 준다. last write date는 backup 여부 판단에 유용하다. last access date는 언제 읽혔는지 알려 주지만, file read마다 directory/FCB field를 update해야 하므로 extra write가 생긴다. Secondary storage는 block/cluster 단위로만 update되므로, field 하나를 바꾸려 해도 block read-modify-write가 필요하다. 따라서 metadata usefulness와 performance cost를 함께 봐야 한다.
Pointer size도 efficiency 문제다. 32-bit pointers는 file size를 4GB 수준으로 제한하지만 storage overhead가 작다. 64-bit pointers는 매우 큰 files/file systems를 지원하지만 pointers를 저장하는 allocation/free-space structures가 더 많은 space를 쓴다. ZFS는 future capacity를 고려해 128-bit pointers를 사용한다. Fixed allocation size나 table size를 선택할 때는 future hardware growth까지 고려해야 한다.
Fixed-size kernel tables도 비슷한 문제를 만든다. 과거 Solaris는 process table, open-file table 같은 structures를 startup time에 fixed length로 allocate했다. Table이 full이면 더 이상 processes/files를 만들 수 없고, size 변경에는 kernel recompile/reboot가 필요했다. Modern Solaris/Linux는 대부분 kernel structures를 dynamic allocation으로 바꾸어 artificial limit을 줄였다. 대신 algorithms가 복잡해지고 allocation/deallocation overhead가 생긴다.
14.6.2 Performance
Storage device controller는 on-board cache를 가진다. HDD에서는 seek 후 track을 controller cache로 읽어 latency를 줄이고, OS는 controller에서 main memory로 온 blocks를 다시 memory cache에 둘 수 있다.
Some systems는 main memory에 separate buffer cache를 유지해 file-system blocks를 cache한다. Other systems는 virtual memory techniques를 사용해 file data를 pages로 cache하는 page cache를 사용한다. File data를 virtual addresses로 cache하는 것이 physical disk blocks를 통해 cache하는 것보다 efficient할 수 있다. Solaris, Linux, Windows는 process pages와 file data 모두를 page cache로 관리하는 unified virtual memory를 사용한다.
문제는 memory-mapped I/O와 read()/write() I/O가 서로 다른 caches를 사용할 때 생긴다.
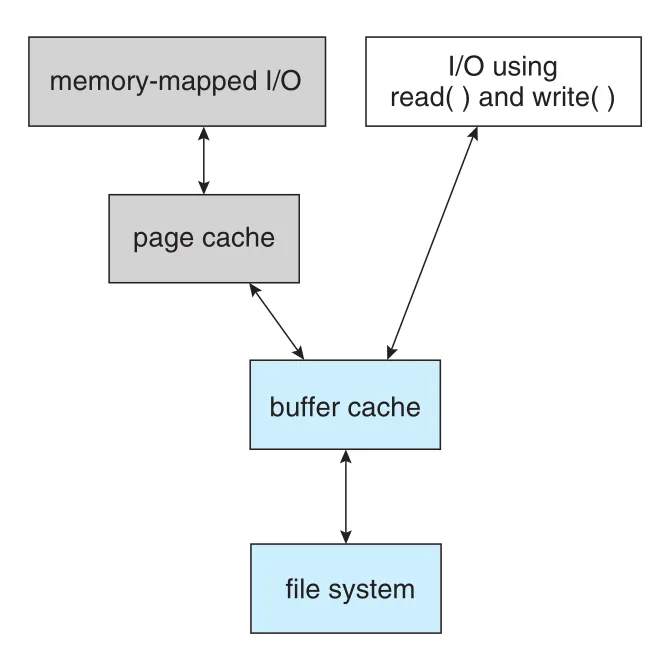
Figure 14.10 · PDF p. 715 · memory-mapped I/O가 page cache와 buffer cache를 모두 거쳐 double caching을 만드는 구조
Unified buffer cache가 없으면 read()/write()는 buffer cache를 사용하고, memory mapping은 page cache와 buffer cache를 모두 사용한다. File data가 buffer cache에서 page cache로 copy되므로 memory를 낭비하고 CPU/I/O cycles도 낭비한다. 두 caches 사이 inconsistency는 file corruption 위험도 만든다.
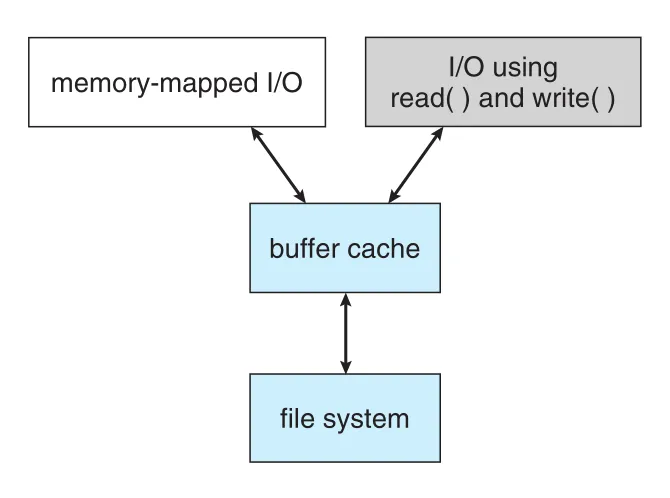
Figure 14.11 · PDF p. 716 · memory-mapped I/O와 read/write가 같은 cache path를 사용해 double caching을 피하는 unified buffer cache
Unified buffer cache에서는 memory mapping과 read()/write() system calls가 같은 page cache를 사용한다. Double caching을 피하고 virtual memory system이 file-system data를 직접 관리할 수 있다.
Replacement algorithm도 쉽지 않다. LRU는 general-purpose로 합리적이지만, page cache와 process pages가 memory를 공유하면 I/O-heavy workload가 process pages를 밀어내 thrashing을 만들 수 있다. Solaris는 versions를 거치며 priority paging, fixed limits, memory-use maximization 등 여러 정책을 실험했다. 이 사례는 file-system cache policy가 VM policy와 분리될 수 없음을 보여준다.
Writes는 synchronous/asynchronous 여부가 중요하다. synchronous writes는 storage subsystem이 받은 순서대로 수행되고 buffered되지 않으며, caller는 data가 drive에 도달할 때까지 기다린다. asynchronous writes는 data를 cache에 저장하고 caller에게 control을 반환한다. 대부분 writes는 asynchronous지만, metadata writes나 database atomic transactions처럼 ordering/durability가 중요한 경우 synchronous write가 필요하다. OS는 보통 open flag로 synchronous writes를 요청할 수 있게 한다.
Sequential file access에는 일반 LRU보다 free-behind와 read-ahead가 더 적합하다. Free-behind는 next page가 요청되면 previous page를 곧바로 buffer에서 제거한다. Sequential scan에서 이미 지나간 pages는 다시 쓰이지 않을 가능성이 높기 때문이다. Read-ahead는 requested page와 이후 several pages를 미리 read/cache한다. 이후 pages가 곧 요청될 가능성이 높으므로, 한 번의 larger transfer로 time을 줄인다. Controller track cache가 있어도 many small transfers의 latency/overhead가 크기 때문에 OS-level read-ahead는 여전히 유용하다.
Page cache, file system, device drivers는 서로 상호작용한다. Small writes는 cache에 buffer되고, storage driver는 output queue를 device address 기준으로 sort해 disk-head seeks를 최소화할 수 있다. Synchronous writes가 필요하지 않다면 process는 cache에 write하고, system이 나중에 asynchronously storage로 write한다.
이 때문에 small transfers에서는 output이 input보다 빠르게 보일 수 있다. Write는 cache에 들어간 뒤 나중에 device로 밀려나지만, read는 적어도 필요한 data가 storage에서 올라와야 하기 때문이다. 그러나 large continuous I/O가 page cache capacity를 넘어서면 buffering의 효과는 사라지고 device performance가 병목이 된다. 예를 들어 page cache보다 큰 movie file을 HDD에 쓰면 결국 drive write speed에 묶이며, 현대 HDD는 대개 read가 write보다 빠르므로 small-I/O에서 보이던 성능 관계가 뒤집힐 수 있다.
14.7 Recovery
Files와 directories는 main memory와 storage volume 양쪽에 존재한다. OS가 I/O performance를 위해 caching을 하기 때문에, crash 시점에 어떤 metadata는 이미 storage에 쓰였고 어떤 metadata는 아직 cache에만 있을 수 있다. 따라서 system failure는 directory structures, free-block pointers, free FCB pointers 같은 on-storage file-system data structures 사이 inconsistency를 만들 수 있다.
예를 들어 file creation은 directory entry 수정, FCB allocation, data block allocation, free counts 감소처럼 여러 구조 변경을 포함한다. 이 중 일부만 완료된 상태에서 crash가 나면 free FCB count는 감소했지만 directory가 그 FCB를 가리키지 않는 식의 손상이 생긴다. File-system implementation bug, device controller bug, user application bug도 corruption 원인이 될 수 있다.
14.7.1 Consistency Checking
Corruption을 다루려면 먼저 문제를 detect하고, 그 다음 가능한 범위에서 correct해야 한다. 가장 직접적인 방법은 file system의 모든 metadata를 scan하여 consistency를 확인하는 것이다. 문제는 이 scan이 minutes 또는 hours가 걸릴 수 있고, crash 후 boot마다 수행하면 availability가 크게 떨어진다는 점이다.
대안으로 file system은 metadata 안에 status bit를 둘 수 있다. Metadata change가 시작되면 “metadata가 in flux”임을 표시하고, 모든 updates가 성공하면 bit를 clear한다. Crash 후에도 bit가 set되어 있으면 consistency checker를 실행한다.
consistency checker는 UNIX의 fsck 같은 system program이다. Directory structure와 다른 metadata를 storage state와 비교하고 inconsistency를 고치려 한다. 어떤 문제를 발견하고 얼마나 복구할 수 있는지는 allocation/free-space-management algorithms에 의존한다.
Linked allocation에서는 각 block이 next block을 가리키므로, directory entry를 잃어도 data block chain을 따라 file을 어느 정도 재구성할 수 있다. 반대로 indexed allocation에서는 data blocks가 서로를 모르기 때문에 directory entry나 index block 손실이 치명적일 수 있다. 이 때문에 일부 UNIX file systems는 directory entries read는 cache하더라도, space allocation이나 metadata change를 동반하는 writes는 corresponding data blocks보다 먼저 synchronously 수행한다. 그래도 synchronous write가 crash로 중단되면 손상 가능성은 남는다.
일부 NVM storage devices는 power loss 중에도 device buffers를 media에 기록할 수 있도록 battery나 supercapacitor를 가진다. 이는 volatile buffer loss를 줄이지만, crash로 인한 logical corruption 자체를 완전히 막지는 못한다.
14.7.2 Log-Structured File Systems
Consistency checking 방식은 “구조가 깨질 수 있음을 허용하고 나중에 수리”하는 접근이다. 하지만 inconsistency가 irreparable할 수 있고, file/directory loss가 생길 수 있으며, human intervention을 요구할 수 있고, terabytes 규모에서는 검사 시간이 매우 길다.
journaling 또는 log-based transaction-oriented file system은 database의 log-based recovery ideas를 file-system metadata updates에 적용한다. NTFS, Veritas file system, Solaris UFS의 newer versions, ext3, ext4, ZFS 등에서 사용된다.
기본 동작은 다음과 같다.
| 단계 | 의미 |
|---|---|
| 1. transaction 구성 | File creation/deletion 같은 task를 수행하는 metadata changes 묶음을 transaction으로 본다. |
| 2. log 기록 | 모든 metadata changes를 actual structures가 아니라 sequential log에 먼저 쓴다. |
| 3. commit | Changes가 log에 기록되면 transaction은 committed 상태가 되고 system call은 user process에 return할 수 있다. |
| 4. replay | Log entries를 실제 file-system structures에 적용한다. 어느 action이 완료되었는지 pointer로 추적한다. |
| 5. completion 기록 | committed transaction 전체가 실제 structures에 반영되면 log에 completion을 표시한다. |
Log file은 circular buffer로 동작한다. 끝까지 쓰면 처음으로 돌아가 older values를 overwrite하지만, 아직 실제 structures에 저장되지 않은 log entries를 덮어쓰면 안 된다. Log는 file system의 separate section에 있을 수도 있고, separate storage device에 있을 수도 있다.
Crash 후 log에는 zero or more transactions가 남는다. Committed되었지만 actual file system에 끝까지 반영되지 않은 transactions는 replay하여 완료한다. 반대로 crash 전에 committed되지 않은 aborted transaction의 일부 changes가 file system에 적용되어 있다면 undo해야 한다. 이 과정을 통해 full consistency check 없이 file-system structures를 consistent하게 만든다.
Journaling의 부수 효과는 performance 개선이다. Metadata-oriented operations는 원래 many synchronous random metadata writes를 요구한다. Journaling은 이를 sequential log writes로 바꾸고, 실제 random writes는 나중에 asynchronously replay할 수 있게 한다. HDD에서는 sequential I/O가 random I/O보다 훨씬 싸므로 file creation/deletion 같은 metadata-heavy operations가 빨라진다.
14.7.3 Other Solutions
WAFL과 ZFS는 consistency checking의 다른 대안을 보여 준다. 이 systems는 blocks를 new data로 overwrite하지 않는다. 대신 transaction의 data와 metadata changes를 모두 new blocks에 쓰고, transaction이 complete되면 old blocks를 가리키던 metadata pointers를 new blocks로 atomically 바꾼다. Old pointers와 old blocks를 제거하면 space를 재사용할 수 있고, 보존하면 특정 시점의 file system view인 snapshot이 된다.
이 방식은 pointer update가 atomic이면 consistency checking이 필요 없도록 설계할 수 있다. 다만 WAFL은 여전히 consistency checker를 가진다. 일부 failure scenario에서는 metadata corruption 가능성이 남기 때문이다. ZFS는 한 단계 더 나아가 metadata와 data blocks 모두에 checksumming을 제공하고, RAID와 결합해 data correctness를 강하게 보장한다. 그래서 ZFS에는 전통적 consistency checker가 없다.
14.7.4 Backup and Restore
Recovery는 crash consistency만의 문제가 아니다. Storage device failure, file deletion, corruption, 운영 실수에 대비하려면 backup이 필요하다. Backup은 data를 다른 storage device나 tape 같은 medium에 복사해 두고, file 하나 또는 전체 device 손실 시 restore할 수 있게 한다.
Directory entry의 last write date는 backup cost를 줄이는 데 쓰인다. Backup program이 file의 last backup time을 알고 있고, directory의 last write date가 그 이후로 변하지 않았다면 file을 다시 복사할 필요가 없다.
전형적인 backup cycle은 다음과 같다.
| 시점 | 방식 | 의미 |
|---|---|---|
| Day 1 | full backup | file system의 모든 files를 backup medium에 복사한다. |
| Day 2 | incremental backup | Day 1 이후 changed files만 다른 medium에 복사한다. |
| Day 3 … Day N | incremental backup | 직전 day 이후 changed files만 복사한다. |
| 이후 | cycle 반복 | 새 cycle은 이전 set 위에 덮어쓰거나 새 media set에 쓸 수 있다. |
전체 restore는 full backup부터 시작해 각 incremental backups를 순서대로 적용한다. N이 커질수록 restore에 읽어야 할 media 수가 늘어난다. 대신 cycle 안에서 실수로 삭제한 file은 이전 day backup에서 복구할 수 있다.
다른 방식은 full backup 이후 매일 “full backup 이후 변경된 모든 files”를 incremental backup하는 것이다. 이 경우 restore에는 full backup과 latest incremental backup만 필요하지만, 시간이 지날수록 매일의 incremental backup이 커진다.
Backup cycle length는 backup volume과 restore coverage의 trade-off다. 오래전에 손상된 file을 뒤늦게 발견할 수 있으므로, 주기적으로 “forever” 보관할 full backup을 따로 만들고 regular backups와 물리적으로 떨어진 곳에 보관하는 것이 안전하다.
14.8 Example: The WAFL File System
WAFL(write-anywhere file layout)은 NetApp file servers에서 쓰이는 file system으로, random writes가 많은 distributed file server workload에 맞춰 설계되었다. NFS와 CIFS clients는 read data를 cache할 수 있지만, writes는 server가 안정적으로 처리해야 하므로 write performance가 핵심이 된다.
WAFL은 특정 architecture 위에서 동작한다는 점을 이용한다. File server는 NVRAM cache를 write 앞단에 두어 stable-storage cache처럼 사용하고, WAFL은 random I/O를 이 환경에 맞춰 최적화한다. 설계 목표에는 ease of use와 efficient read-only snapshots도 포함된다.
WAFL은 Berkeley Fast File System과 유사하게 block-based이고, files를 inode로 설명한다. 각 inode는 해당 file의 blocks 또는 indirect blocks를 가리키는 16 pointers를 가진다. 각 file system에는 root inode가 있으며, WAFL의 중요한 특징은 metadata가 별도 고정 영역이 아니라 files 안에 산다는 점이다.
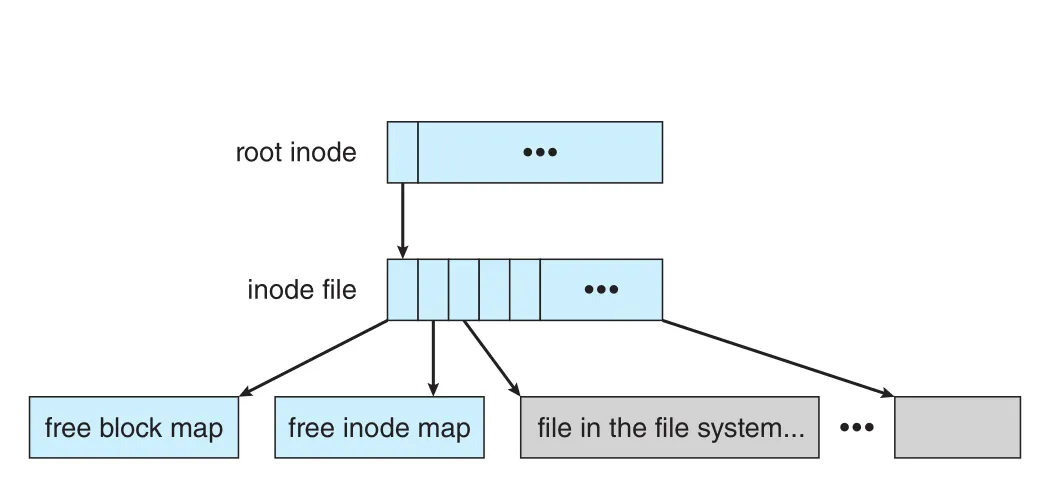
Figure 14.12 · PDF p. 721 · root inode 아래 inode file, free-block map, free-inode map, 일반 files가 모두 file로 배치되는 WAFL layout
WAFL에서 all inodes는 하나의 inode file에, free-block map은 다른 file에, free-inode map은 또 다른 file에 저장된다. 이 metadata files도 standard files이므로 data blocks 위치가 고정되지 않고 anywhere에 배치될 수 있다. File system을 disks 추가로 확장하면 metadata files 길이도 file system이 자동으로 늘린다.
WAFL file system은 root inode를 base로 하는 block tree로 이해할 수 있다. Snapshot을 만들 때 WAFL은 root inode를 copy한다. 이후 file 또는 metadata updates는 existing blocks를 overwrite하지 않고 new blocks에 기록된다. New root inode는 변경된 metadata/data를 가리키고, snapshot의 old root inode는 변경 전 old blocks를 계속 가리킨다. 그래서 snapshot은 “그 시점의 file system view”를 매우 적은 추가 공간으로 제공한다. 추가 공간은 snapshot 이후 modified blocks 정도에 해당한다.
WAFL Free-Block Map과 Snapshot
WAFL의 free-block map은 standard bitmap과 다르다. Block마다 단순히 free/allocated 한 bit만 두지 않고, 어떤 snapshots가 그 block을 사용 중인지 나타낼 수 있도록 multiple bits를 둔다. 특정 block을 사용하던 모든 snapshots가 삭제되어 bitmap이 all zeros가 되면 그 block은 reuse 가능해진다.
Used blocks를 overwrite하지 않기 때문에 writes는 빠를 수 있다. Current head location 근처의 free block에 write하면 되므로 random write 부담을 줄일 수 있다. 이 구조는 snapshot 효율성도 높인다. 많은 snapshots가 동시에 존재할 수 있고, hourly/daily snapshots처럼 여러 시점의 read-only view를 제공할 수 있다.
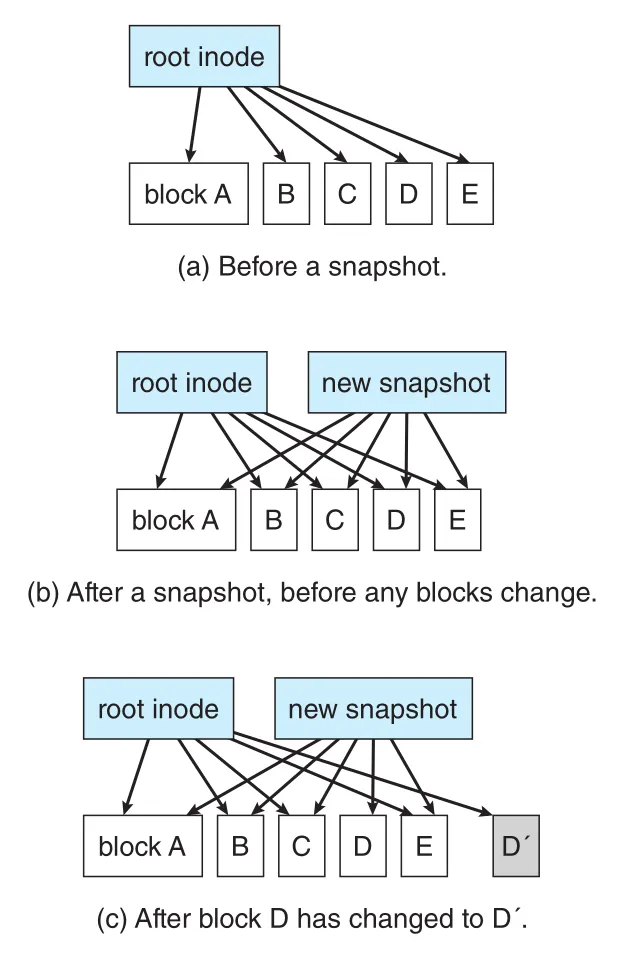
Figure 14.13 · PDF p. 722 · snapshot 생성 뒤 block D가 D'로 바뀌어도 snapshot은 old block D를 계속 가리키는 구조
Figure 14.13의 핵심은 pointer ownership이다. Snapshot 이전에는 root inode가 blocks A-E를 가리킨다. Snapshot 직후에는 current root inode와 snapshot이 같은 blocks를 공유한다. 이후 block D가 D’로 바뀌면 current root inode는 D’를 가리키고, snapshot은 old D를 계속 가리킨다. 따라서 full copy 없이 point-in-time view가 유지된다.
Clones와 Replication
Newer WAFL versions는 read-write snapshots인 clones도 지원한다. Clone은 read-only snapshot을 기준으로 하고, clone에 대한 writes는 new blocks에 저장되며 clone pointers만 update된다. Original snapshot은 변하지 않으므로, clone을 시험/업그레이드용 working copy처럼 사용할 수 있다. Test가 끝나면 clone을 버리거나, 성공 시 clone을 promote하여 original을 대체할 수 있다.
replication도 WAFL 구조에서 자연스럽게 나온다. 먼저 source file system의 snapshot을 remote system에 복제한다. 다음 snapshot이 생성되면 두 snapshots 사이에서 changed blocks만 remote system으로 보내고, remote system은 blocks와 pointers를 갱신한다. 이를 반복하면 remote system은 source system의 near up-to-date copy가 된다. 이는 disaster recovery에 유용하다.
Apple File System(APFS) 예시는 같은 흐름을 보여 주는 modern file-system design 사례다. APFS는 64-bit pointers, clones, snapshots, space sharing, atomic safe-save, copy-on-write, encryption, I/O coalescing 같은 기능을 제공하고 NVM과 HDD를 모두 고려한다. 여기서 중요한 점은 제품명 자체보다, modern file systems가 copy-on-write, snapshots, clones, NVM-aware write optimization을 일반 기능으로 흡수하고 있다는 것이다.
ZFS도 efficient snapshots, clones, replication을 지원한다. WAFL/ZFS/APFS 사례는 Chapter 14의 구조들이 단순한 내부 구현 세부가 아니라, reliability, backup, testing, disaster recovery, performance까지 연결되는 file-system design surface임을 보여 준다.
14.9 Summary
File-system implementation은 persistent storage 위에 logical files/directories를 올리는 작업이다. Storage devices는 partitions로 나뉘고, file systems는 mount되어 logical file-system namespace에 붙는다. Lower layers는 physical storage communication을 담당하고, upper layers는 symbolic names, directories, protection, metadata 같은 logical properties를 다룬다.
Space allocation은 contiguous allocation, linked allocation, indexed allocation이 기본 축이다. Contiguous allocation은 direct/sequential access가 빠르지만 external fragmentation과 file growth 문제가 있다. Linked allocation은 external fragmentation이 없고 growth가 쉽지만 direct access가 비효율적이다. Indexed allocation은 direct access를 지원하지만 index block overhead와 large-file support 문제가 있다. Extents, clusters, indirect blocks는 이 trade-off를 완화하는 변형이다.
Free-space management는 allocation efficiency, performance, reliability에 직접 영향을 준다. Bit vector는 free block 탐색이 빠르지만 bitmap memory/storage 비용이 있고, linked list는 simple하지만 traversal이 느리다. Grouping, counting, FAT, ZFS space maps 같은 변형은 workload와 storage scale에 맞춰 free-space accounting 비용을 줄인다. NVM/SSD에서는 TRIM/unallocate처럼 file system과 device controller 사이의 free-space 정보 전달도 중요하다.
Directory management는 lookup speed와 reliability를 함께 고려해야 한다. Linear list는 단순하지만 search가 느리고, hash table은 빠르지만 collision handling과 table corruption risk를 고려해야 한다. Directory metadata 손상은 allocation 방식에 따라 복구 가능성이 달라진다.
Performance는 caching, write ordering, I/O scheduling, allocation locality가 함께 만든다. buffer cache, page cache, unified buffer cache는 storage I/O를 줄이고 double caching을 피하려는 시도다. synchronous write는 durability/order를 제공하지만 느리고, asynchronous write는 빠르지만 crash risk가 있다. Sequential access에는 read-ahead와 free-behind가 효과적이다.
Recovery는 consistency checking, journaling, copy-on-write, backup/restore가 함께 담당한다. fsck는 손상 후 metadata를 검사·수리하고, journaling은 metadata changes를 log transaction으로 먼저 기록해 crash recovery를 빠르고 안정적으로 만든다. WAFL/ZFS 같은 copy-on-write systems는 overwrite를 피하고 pointer update와 snapshot으로 consistency와 recovery 기능을 제공한다.
연결 관계
- Chapter 13의 file-system interface는
open(),read(),write(), directories, protection을 사용자 관점에서 설명한다. Chapter 14는 그 interface가 FCB/inode, open-file table, allocation method, free-space manager, cache, recovery log로 구현되는 방식을 설명한다. - Chapter 11의 mass-storage structure와 연결된다. HDD seek/rotation cost는 contiguous allocation, read-ahead, queue sorting을 중요하게 만들고, NVM erase-before-write 특성은 TRIM/unallocate와 write cliff 문제를 만든다.
- Chapter 10의 virtual memory와 연결된다. Page cache, memory-mapped I/O, unified virtual memory는 file-system caching과 VM replacement policy가 같은 memory pool을 공유한다는 사실을 보여 준다.
- Chapter 12의 I/O systems와 연결된다. Device drivers, interrupt handlers, controller caches, block I/O subsystem이 file-system requests를 실제 device operations로 바꾼다.
- Reliability 관점에서는 Chapter 8의 resource consistency 문제와 닮아 있다. File-system metadata updates도 transaction 단위 ordering, atomicity, recovery가 필요하다.
오해하기 쉬운 내용
metadata는 file contents가 아니다. File size, ownership, permissions, block pointers, directory entries, free-space structures처럼 contents를 찾고 보호하고 관리하는 정보다.open()은 매번 directory search를 반복하지 않기 위한 operation이다. Open 후에는 file descriptor/file handle로 system-wide/per-process open-file tables를 통해 file state에 접근한다.- Contiguous allocation이 항상 좋은 것은 아니다. Access는 빠르지만 file growth와 external fragmentation이 큰 문제다. Extents는 이 문제를 줄이지만 완전히 없애지는 않는다.
- Linked allocation은 “공간 낭비가 없다”가 아니라 “external fragmentation이 없다”에 가깝다. Pointer overhead, reliability problem, direct access 비효율은 여전히 존재한다.
- Indexed allocation은 direct access를 쉽게 만들지만, index block 자체가 overhead다. Small file이 많으면 unused index entries가 낭비되고, large file은 indirect/multilevel indexing이 필요하다.
- Bitmap은 단순하지만 공짜가 아니다. Large storage에서는 bitmap 자체도 memory/storage를 차지하며, crash recovery를 위해 on-storage copy와 memory copy의 consistency도 신경 써야 한다.
- Journaling은 backup을 대체하지 않는다. Journaling은 crash 중 metadata consistency를 회복하는 mechanism이고, device failure나 user deletion으로 잃은 data는 backup/restore가 필요하다.
- Snapshot도 backup과 같지 않다. Snapshot은 같은 storage system 내부의 point-in-time view일 수 있으므로, storage 전체가 손실되면 함께 사라질 수 있다. Remote replication이나 external backup이 별도로 필요하다.
면접 질문
open()system call 이후 OS가 왜 system-wide open-file table과 per-process open-file table을 나누어 관리하는지 설명하라.- Contiguous allocation, linked allocation, indexed allocation의 direct access 성능과 fragmentation trade-off를 비교하라.
- UNIX inode의 direct, single indirect, double indirect, triple indirect pointers가 small file과 large file을 동시에 지원하는 방식을 설명하라.
- Bitmap free-space management가 linked free list보다 빠를 수 있는 이유와, large storage에서의 비용을 설명하라.
- SSD/NVM에서
TRIM또는unallocate가 필요한 이유를write cliff와 연결해 설명하라. - Unified buffer cache가 없을 때 memory-mapped I/O와
read()/write()가 만드는double caching문제를 설명하라. synchronous write와asynchronous write의 차이를 metadata update, database transaction, 일반 file write 예시로 설명하라.- Consistency checker(
fsck) 방식과 journaling file system 방식의 recovery 철학 차이를 설명하라. - WAFL snapshot이 full copy 없이 point-in-time view를 제공할 수 있는 이유를 root inode와 block pointers 중심으로 설명하라.
- Snapshot, clone, replication, backup의 차이를 file-system recovery/availability 관점에서 구분하라.