Chapter 12. I/O Systems
- 과목: Operating System
- 기준 교재: Operating System Concepts 10th
- 관련 페이지: PDF pp. 617-653
- 우선순위: 필수
개요
컴퓨터의 두 큰 일은 computing과 I/O다. 실제 사용자는 웹 페이지를 읽고, 파일을 편집하고, 네트워크로 데이터를 주고받는 데 관심이 있으므로 많은 시스템에서 계산은 I/O를 가능하게 하는 부수 작업에 가깝다. 운영체제의 I/O 역할은 I/O operations와 I/O devices를 manage/control하고, 매우 다양한 device hardware를 application이 사용할 수 있는 일관된 interface로 바꾸는 것이다.
Chapter 12의 핵심 질문은 “device hardware의 복잡성과 application I/O interface 사이를 OS가 어떻게 이어 주는가?”이다. Hardware 쪽에는 ports, buses, controllers, device registers, polling, interrupts, DMA가 있고, software 쪽에는 device drivers, application I/O interface, kernel I/O subsystem, buffering/caching/spooling, error handling, protection, request transformation, STREAMS, performance optimization이 있다.
핵심 개념
| 개념 | 핵심 의미 |
|---|---|
I/O subsystem | 다양한 I/O devices의 차이를 kernel 내부에서 흡수해 나머지 kernel과 applications에 uniform service를 제공하는 부분. |
device driver | 특정 device의 details/oddities를 encapsulate하고 kernel I/O subsystem에 uniform device-access interface를 제공하는 module. |
port | device가 computer와 통신하는 connection point. serial port 같은 물리적/논리적 접점. |
bus | 여러 devices가 공유하는 wires와 protocol의 집합. PCIe, SAS 같은 bus가 대표적이다. |
daisy chain | devices가 연쇄적으로 연결되어 하나의 port에 이어지는 구조. 보통 bus처럼 동작한다. |
controller | port, bus, device를 동작시키는 electronics. processor, microcode, private memory를 가질 수 있다. |
HBA | Host Bus Adapter. Fibre Channel 같은 복잡한 bus protocol을 처리하는 별도 controller board. |
memory-mapped I/O | device-control registers를 processor address space에 mapping해 일반 load/store instruction으로 I/O를 수행하는 방식. |
I/O port address | special I/O instructions가 device registers를 선택하기 위해 사용하는 I/O address. |
status register | command completion, data availability, error 등 device state bits를 host가 읽는 register. |
control register | command start나 device mode 변경을 위해 host가 쓰는 register. |
data-in, data-out register | host가 device input을 읽거나 output을 보내는 data registers. |
FIFO | controller register보다 큰 burst input/output을 잠시 저장하는 small buffer. |
polling, busy-waiting | host가 status bit를 반복적으로 읽어 device ready/completion을 확인하는 방식. |
interrupt | device/controller 또는 exception이 CPU에게 urgent kernel routine 실행을 요청하는 hardware/software mechanism. |
interrupt-request line | CPU가 instruction 사이마다 감지하는 interrupt signal line. |
interrupt handler | interrupt 원인을 처리하고 state restore 후 interrupted execution으로 돌아가게 하는 kernel routine. |
interrupt vector | interrupt number를 specific handler address로 dispatch하는 table. |
interrupt chaining | vector entry가 handler list를 가리키고, servicing 가능한 handler를 찾을 때까지 호출하는 구조. |
maskable interrupt, nonmaskable interrupt | CPU가 일시적으로 mask할 수 있는 device interrupt와 unrecoverable error 등 mask할 수 없는 interrupt. |
interrupt priority | urgent interrupt가 low-priority interrupt handling을 defer/preempt할 수 있게 하는 priority level. |
FLIH, SLIH | First-Level Interrupt Handler, Second-Level Interrupt Handler. 빠른 state save/queueing과 실제 처리를 나누는 interrupt handling 구조. |
trap, software interrupt | system call, page fault, divide-by-zero 등으로 kernel attention을 직접 얻는 exception/interrupt mechanism. |
PIO | Programmed I/O. CPU가 status bits를 보고 controller register에 data를 직접 넣는 방식. |
DMA | Direct Memory Access. DMA controller가 CPU 대신 memory bus를 사용해 device와 memory 사이 bulk transfer를 수행하는 방식. |
scatter-gather | 하나의 DMA command가 noncontiguous sources/destinations list를 따라 여러 transfers를 수행하는 방식. |
cycle stealing | DMA controller가 memory bus를 점유하는 동안 CPU의 main memory access가 잠시 지연되는 현상. |
DVMA | Direct Virtual Memory Access. DMA가 virtual addresses를 사용하고 translation을 거쳐 transfer하는 방식. |
block device | fixed-size blocks 단위로 transfer하며 random access와 seek가 핵심인 device class. Disk가 대표적이다. |
character-stream device | bytes를 linear stream으로 주고받는 device class. Keyboard, mouse, modem, printer, audio device 등이 해당한다. |
raw I/O | file-system buffering/locking을 거치지 않고 block device를 linear block array처럼 직접 access하는 방식. |
direct I/O | file을 사용하되 OS buffering/locking 일부를 disable해 raw I/O와 file interface 사이를 절충하는 방식. |
memory-mapped file | file contents를 virtual memory address range로 map하고 demand paging처럼 필요한 때 transfer하는 interface. |
socket | network communication endpoint. local socket을 remote address와 connect/listen/send/receive할 수 있다. |
select() | 여러 sockets/devices 중 I/O 가능 상태를 확인해 polling/busy waiting을 줄이는 system call. |
programmable interval timer | 일정 시간 후 또는 주기적으로 interrupt를 발생시켜 scheduler, timeout, cache flush 등에 쓰이는 timer hardware. |
blocking I/O | system call completion까지 calling thread가 wait queue에서 block되는 I/O. |
nonblocking I/O | 즉시 return하며 available data만 전달하거나 0 bytes를 반환할 수 있는 I/O. |
asynchronous I/O | request는 즉시 return하고, 전체 I/O completion은 signal/callback/variable 등으로 나중에 통지되는 I/O. |
vectored I/O, readv, writev | 여러 buffers/locations에 대한 scatter-gather I/O를 하나의 system call로 수행하는 interface. |
I/O scheduling | device별 wait queue의 request order를 조정해 throughput, fairness, average response time을 개선하는 작업. |
device-status table | 각 I/O device의 type, address, state, active request 정보를 저장하는 kernel table. |
buffering | producer/consumer speed mismatch, transfer-size mismatch, copy semantics를 위해 transfer 중 data를 임시 저장하는 기법. |
double buffering | 한 buffer가 consumer로 전달되는 동안 다른 buffer가 producer에게 채워지게 해 timing mismatch를 완화하는 방식. |
copy semantics | system call 시점의 application buffer 내용이 이후 application changes와 무관하게 I/O 대상이 되도록 보장하는 의미론. |
caching, buffer cache | 원본 data의 copy를 fast memory에 두어 I/O를 avoid/defer하고 repeated access를 빠르게 하는 기법. |
spooling | printer처럼 interleaved streams를 받을 수 없는 device를 위해 output jobs를 separate files/queue로 모아 순서대로 보내는 방식. |
device reservation | tape drive/printer처럼 multiplexing이 어려운 device에 exclusive access를 제공하는 coordination mechanism. |
errno | UNIX에서 failed I/O system call의 error nature를 나타내는 integer error code. |
privileged instruction | user process가 직접 실행할 수 없고 kernel mode에서만 실행 가능한 instruction. I/O instructions가 여기에 속한다. |
dispatch table | file/device type에 따라 read/write/select/ioctl/close routine pointers를 담는 table. |
power collapse, wakelock | mobile OS에서 deep sleep 진입과 application의 temporary sleep prevention을 관리하는 power-management mechanisms. |
ACPI | Advanced Configuration and Power Interface. device state discovery, error management, power management에 쓰이는 firmware/kernel interface. |
mount table | UNIX에서 pathname prefix를 device name에 연결해 file path를 physical device로 해석하는 table. |
major, minor device number | major는 device driver type을, minor는 driver 내부 device instance/table entry를 식별한다. |
STREAMS | UNIX System V 계열의 full-duplex stream mechanism. stream head, modules, driver end를 queues와 messages로 연결한다. |
stream head, driver end, stream module | user process interface, device control endpoint, 중간 processing module을 이루는 STREAMS 구성요소. |
flow control | adjacent STREAMS queues 사이에서 buffer overflow를 막기 위해 message acceptance를 조절하는 mechanism. |
I/O channel | main CPU에서 I/O work를 offload하는 dedicated special-purpose CPU. Mainframe/high-end system에서 사용된다. |
front-end processor | terminal I/O 등 interrupt burden을 main CPU에서 덜어 주는 별도 processor. |
FUSE | File systems in USEr mode. file-system algorithms를 user mode에서 개발/실행하게 해 flexibility를 높이는 interface. |
세부 정리
12.1 Overview
I/O device는 mouse, hard disk, flash drive, tape robot처럼 function과 speed가 크게 다르다. 따라서 하나의 control method로 모두 다룰 수 없고, 여러 hardware/software techniques가 필요하다. Kernel의 I/O subsystem은 이런 device management complexity를 kernel의 나머지 부분에서 분리한다.
I/O-device technology에는 두 가지 상반된 흐름이 있다.
| 흐름 | 의미 | OS 설계에 주는 영향 |
|---|---|---|
| interface standardization | hardware/software interface가 표준화됨 | 새로운 device generation을 기존 computer/OS에 더 쉽게 통합 |
| device variety 증가 | 이전 device와 성격이 전혀 다른 devices가 계속 등장 | device-specific details를 driver로 숨기고 kernel I/O interface를 유지해야 함 |
이 문제를 해결하는 기본 도구가 ports, buses, device controllers, device-driver modules다. Device drivers는 device마다 다른 details와 quirks를 숨기고, I/O subsystem에 uniform device-access interface를 제공한다. 이 관계는 system calls가 application과 OS 사이에 standard interface를 제공하는 것과 비슷하다.
12.2 I/O Hardware
I/O devices는 크게 storage devices, transmission devices, human-interface devices, specialized devices로 나눌 수 있다. 종류는 매우 다양하지만 OS가 hardware를 제어하는 데 필요한 핵심 개념은 많지 않다. Device는 signals를 cable이나 wireless medium을 통해 보내고, computer와 port 또는 bus를 통해 연결된다.
port는 device와 machine 사이의 connection point다. Devices가 common wires를 공유하면 bus라고 한다. Bus는 wires뿐 아니라 그 위에서 어떤 messages를 어떤 timing/voltage pattern으로 보낼 수 있는지 정의한 protocol까지 포함한다. Devices가 chain처럼 연결되어 하나의 computer port로 이어지면 daisy chain이라고 하며, 대개 bus처럼 동작한다.
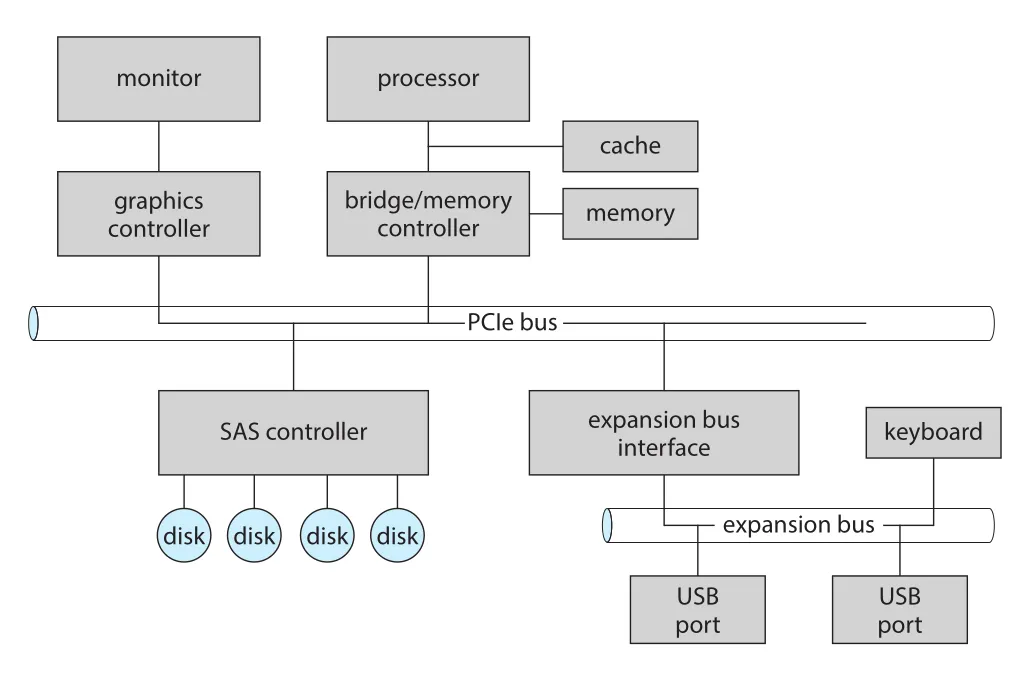
Figure 12.1 · PDF p. 619 · processor-memory subsystem, PCIe bus, expansion bus, SAS controller와 devices가 연결되는 PC bus 구조
Figure 12.1은 fast devices가 PCIe bus로 processor-memory subsystem에 연결되고, 느린 devices는 expansion bus를 통해 연결되는 전형적 구조를 보여준다. PCIe는 lanes를 사용해 packets를 양방향 byte stream으로 보낸다. Lane 수와 generation에 따라 throughput이 달라지지만, 여기서 중요한 점은 bus가 단순 wires가 아니라 signaling method, speed, throughput, connection method를 모두 포함하는 interface라는 것이다.
controller는 port, bus, device를 operate하는 electronics다. 단순 serial-port controller처럼 chip 일부일 수도 있고, FC (Fibre Channel)처럼 복잡한 protocol을 처리하는 별도 HBA (host bus adapter)일 수도 있다. Disk drive에는 자체 disk controller가 있으며, SAS/SATA protocol 처리뿐 아니라 bad-sector mapping, prefetching, buffering, caching 같은 작업도 수행한다.
12.2.1 Memory-Mapped I/O
CPU가 controller에게 command/data를 전달하려면 controller의 registers를 읽고 써야 한다. 방법은 크게 두 가지다.
| 방식 | 동작 | 장점/주의점 |
|---|---|---|
| special I/O instructions | I/O port address에 byte/word를 transfer하는 special instruction 사용 | 전통적 방식. device register access가 일반 memory access와 구분됨 |
memory-mapped I/O | device-control registers를 processor physical address space에 mapping하고 일반 load/store로 access | 대량 data나 device control을 더 단순하고 빠르게 처리 가능 |
현대 시스템은 대부분 memory-mapped I/O 쪽으로 이동했다. 예를 들어 graphics controller는 screen contents를 담는 large memory-mapped region을 제공하고, thread는 이 region에 data를 써서 output을 만든다. Millions of bytes를 graphics memory에 write하는 것이 millions of I/O instructions를 발행하는 것보다 효율적이다.
Device control은 보통 네 종류의 registers로 설명할 수 있다.
| Register | Host 관점의 역할 |
|---|---|
data-in register | input data를 읽음 |
data-out register | output data를 씀 |
status register | command completion, readable byte, device error 같은 state bits를 읽음 |
control register | command 시작, mode 변경, parity checking, word length, speed 같은 설정을 씀 |
Data registers는 보통 1-4 bytes로 작다. 그래서 일부 controllers는 FIFO chips를 두어 input/output burst를 잠시 저장한다. FIFO는 device나 host가 data를 받을 준비가 될 때까지 small burst를 잃지 않게 해 준다.
12.2.2 Polling
Host와 controller는 handshaking으로 서로의 상태를 맞춘다. 원문 예시는 busy bit와 command-ready bit 두 bits로 producer-consumer 관계를 조정한다.
- Host는
busy bit가 clear될 때까지 status register를 반복해서 읽는다. - Host는 command register에 write bit를 set하고
data-out register에 byte를 쓴다. - Host는
command-ready bit를 set한다. - Controller는 command-ready bit를 보고
busy bit를 set한다. - Controller는 command와 data-out register를 읽고 device I/O를 수행한다.
- Controller는 command-ready bit, error bit, busy bit를 적절히 clear하여 완료를 알린다.
이 과정을 byte마다 반복할 수 있다. Step 1처럼 host가 status register를 계속 읽는 것이 polling 또는 busy-waiting이다. Controller/device가 빠르면 polling은 충분히 합리적이다. 하지만 기다림이 길거나 device가 ready인 경우가 드물면 CPU가 useful processing을 하지 못하므로 비효율적이다.
Polling은 기본 operation 자체는 싸다. 많은 architecture에서 device register read, status bit 추출, branch 정도의 몇 instruction cycles로 끝난다. 문제는 “거의 ready가 아닌 device를 계속 확인하는 반복”이다. 이런 경우 device가 CPU에게 ready/completion을 알려 주는 interrupt가 더 적합하다.
12.2.3 Interrupts
interrupt는 asynchronous event나 urgent condition을 처리하기 위해 CPU execution을 잠시 전환시키는 mechanism이다. CPU hardware는 instruction 실행 사이에 interrupt-request line을 감지한다. Controller가 이 line에 signal을 assert하면 CPU는 state를 save하고 fixed address 또는 vector를 통해 interrupt-handler routine으로 jump한다. Handler는 원인을 처리하고 state를 restore한 뒤 return from interrupt instruction으로 이전 execution state로 돌아간다.
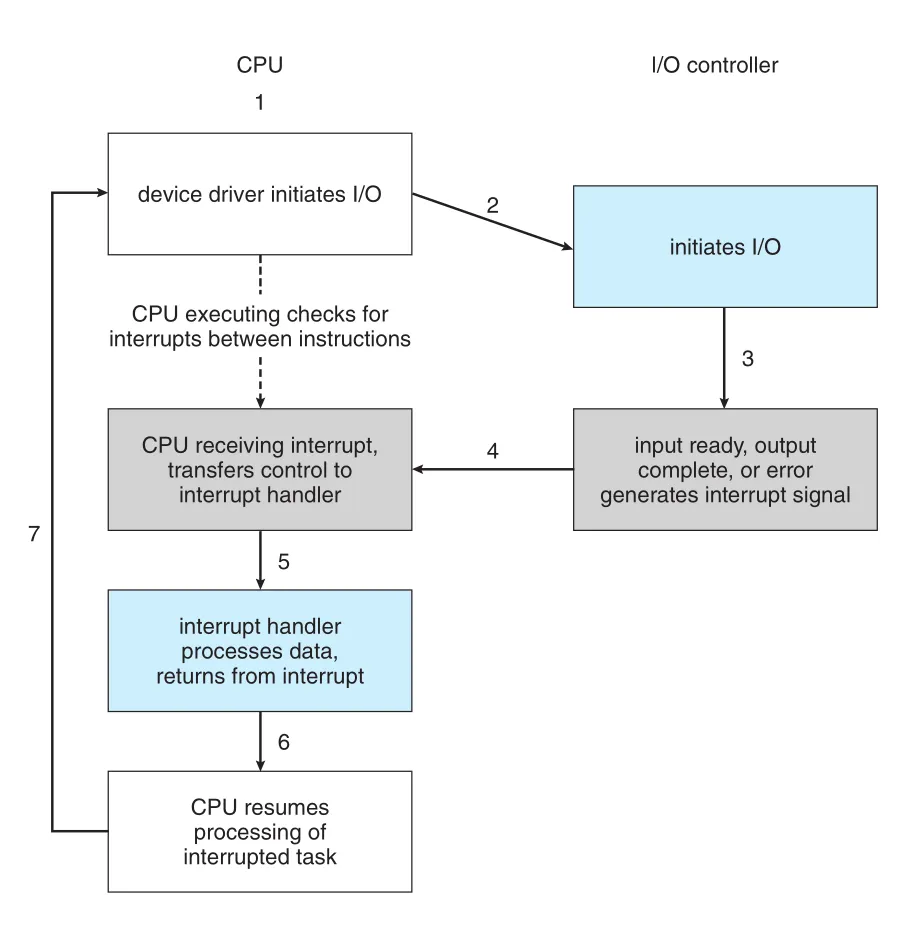
Figure 12.3 · PDF p. 622 · device driver가 I/O를 시작하고 controller interrupt가 handler로 이어진 뒤 CPU가 interrupted task로 돌아가는 흐름
Interrupt-driven I/O의 핵심은 CPU가 I/O completion을 계속 묻는 대신, controller가 input ready, output complete, error 같은 사건이 발생했을 때 CPU를 깨운다는 것이다. 현대 single-user systems도 초당 많은 interrupts를 처리하고, servers는 훨씬 더 많은 interrupts를 처리하므로 efficient interrupt handling은 성능에 중요하다.
Modern interrupt handling에는 기본 interrupt mechanism 이상의 기능이 필요하다.
| 필요 기능 | 이유 |
|---|---|
| interrupt deferral | critical processing 중에는 interrupt handling을 잠시 미뤄야 함 |
| efficient dispatch | 모든 devices를 polling하지 않고 right handler로 가야 함 |
| multilevel interrupts | high/low priority interrupts를 urgency에 맞게 처리해야 함 |
| traps | page fault, divide-by-zero, system call처럼 device I/O가 아닌 event도 kernel attention이 필요함 |
CPU와 interrupt-controller hardware는 이를 위해 maskable interrupt, nonmaskable interrupt, interrupt vector, interrupt priority를 제공한다. nonmaskable interrupt는 unrecoverable memory error 같은 사건에 쓰이고, maskable interrupt는 device controllers가 service를 요청할 때 쓰이며 CPU가 critical instruction sequence 동안 잠시 꺼둘 수 있다.
interrupt vector는 interrupt number를 specialized handler address로 연결하는 table이다. 이 덕분에 single handler가 모든 devices를 뒤질 필요가 줄어든다. Devices/handlers 수가 vector entries보다 많으면 interrupt chaining을 사용한다. Vector entry가 handler list head를 가리키고, request를 service할 수 있는 handler를 찾을 때까지 차례로 호출한다.
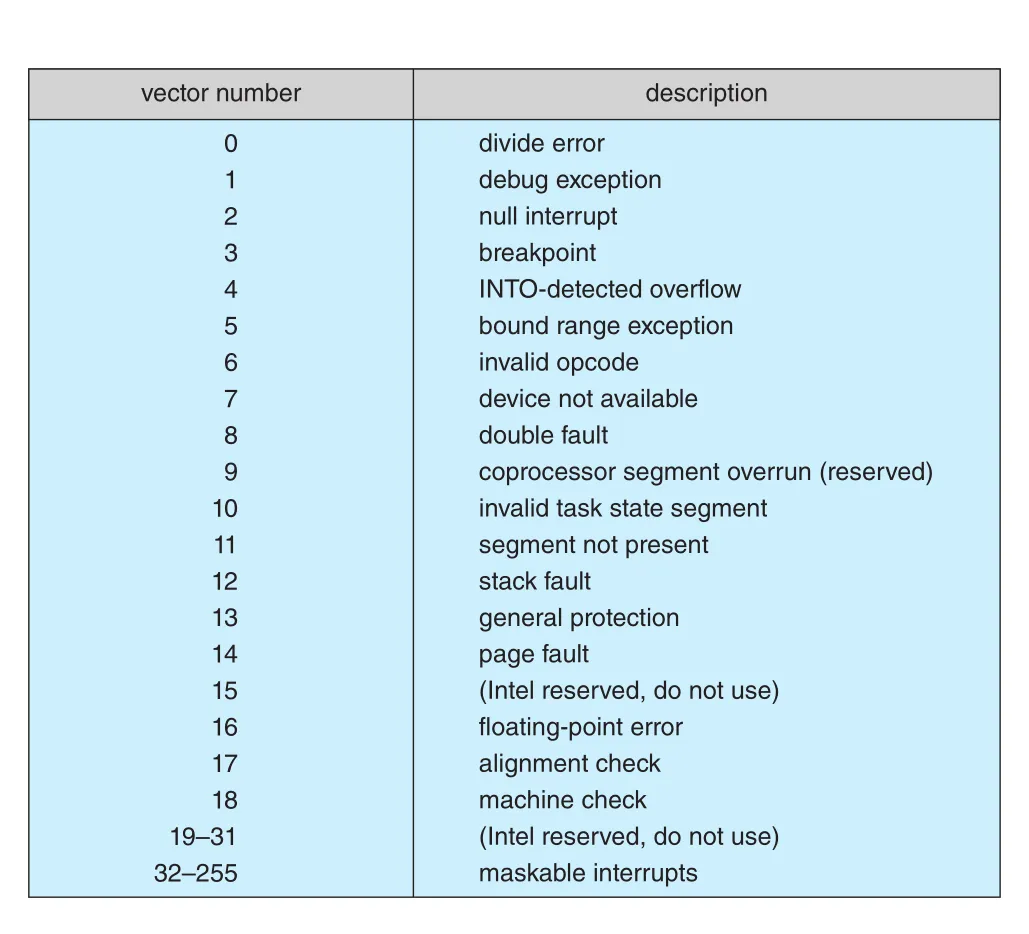
Figure 12.5 · PDF p. 624 · exception과 maskable interrupts를 vector number로 구분해 handler dispatch를 가능하게 하는 event-vector table
Interrupt priority는 low-priority interrupt handling을 defer하면서도 high-priority interrupt는 받을 수 있게 한다. High-priority interrupt가 low-priority handler execution을 preempt할 수도 있다. OS는 boot time에 hardware buses를 probe해 devices를 찾고, corresponding interrupt handlers를 interrupt vector에 설치한다.
Interrupt는 device I/O뿐 아니라 exceptions와 system calls에도 사용된다. page fault는 current process를 suspend하고 page-fault handler로 들어가 page-cache management와 page fetch I/O를 schedule한다. system call은 library routine이 arguments를 준비한 뒤 trap 또는 software interrupt instruction을 실행해 kernel mode service routine으로 들어간다. Trap priority는 보통 device interrupts보다 낮다. Device FIFO overflow를 막는 것이 application system call 처리보다 더 urgent할 수 있기 때문이다.
Interrupt handling은 시간 제약이 크므로 많은 systems는 FLIH (first-level interrupt handler)와 SLIH (second-level interrupt handler)로 나눈다. FLIH는 context switch, state storage, handling operation queueing처럼 빠르게 끝내야 하는 일을 하고, SLIH는 별도로 scheduled되어 실제 처리 작업을 수행한다. Disk read completion처럼 urgent한 “다음 I/O 시작”은 high-priority handler가 처리하고, kernel buffer에서 user buffer로 copy하는 느리지만 덜 급한 작업은 low-priority handler가 나중에 처리할 수 있다.
결론적으로 현대 OS에서 interrupts는 asynchronous events와 supervisor-mode traps를 처리하는 일반 mechanism이다. Interrupt-driven I/O가 polling보다 흔하지만, high-throughput I/O에서는 polling이 더 빠를 수 있어 둘을 조합하기도 한다. 일부 device drivers는 I/O rate가 낮을 때 interrupts를 쓰고, rate가 높아지면 polling으로 전환한다.
12.2.4 Direct Memory Access
큰 transfer를 하는 disk drive 같은 device에서 CPU가 status bits를 보고 controller register에 한 byte씩 data를 넣는 PIO (programmed I/O)는 낭비가 크다. 이를 줄이기 위해 modern computers는 DMA (direct memory access) controller를 사용한다.
DMA transfer 시작 시 host는 memory에 DMA command block을 쓴다. 이 block은 source pointer, destination pointer, byte count를 포함한다. 더 복잡한 command block은 noncontiguous address list를 포함해 scatter-gather transfer를 수행할 수 있다. CPU는 command block address를 DMA controller에 알려 주고 다른 일을 계속한다. DMA controller는 memory bus에 address를 내보내며 main CPU 도움 없이 transfer를 진행한다.
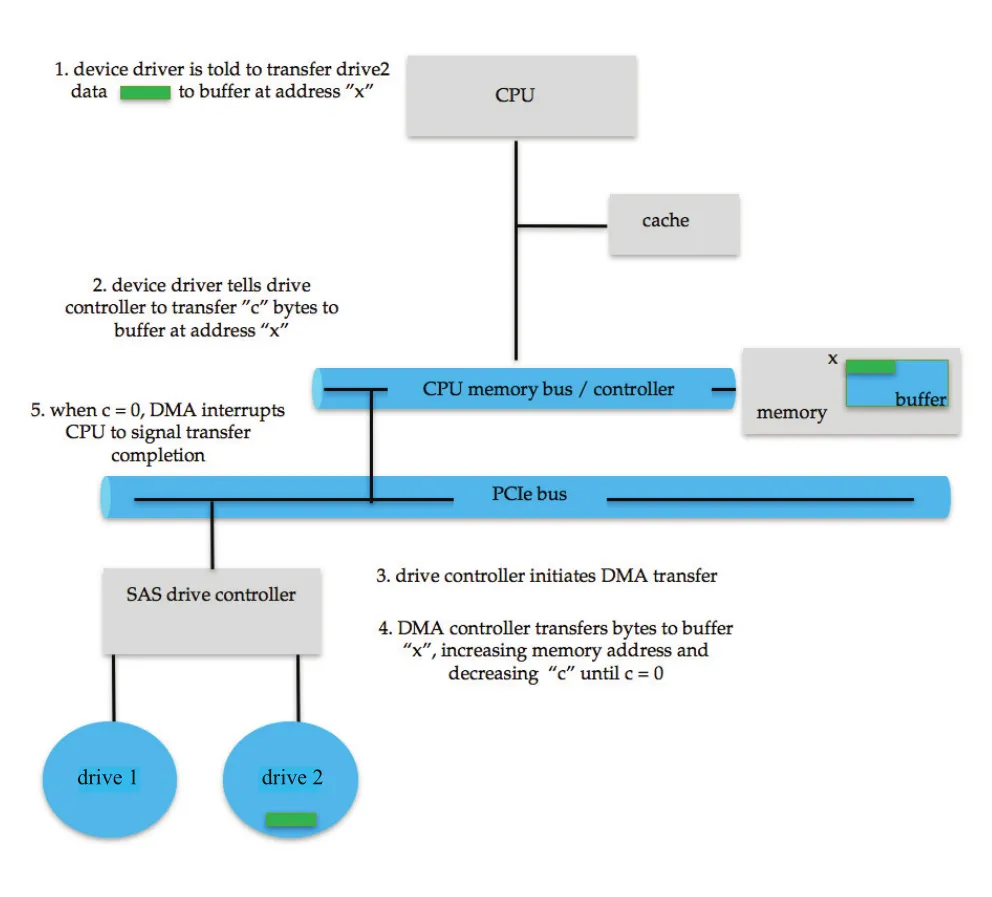
Figure 12.6 · PDF p. 627 · DMA controller가 CPU 대신 memory bus를 사용해 device와 memory 사이 transfer를 수행하는 단계
Device controller와 DMA controller는 DMA-request와 DMA-acknowledge wires로 handshaking한다. Device controller가 transfer할 word가 있다고 DMA-request를 올리면, DMA controller는 memory bus를 seize하고 address를 내보낸 뒤 DMA-acknowledge를 보낸다. Device controller는 acknowledge를 보고 data word를 memory로 transfer하고 request를 내린다. 전체 transfer가 끝나면 DMA controller가 CPU에 interrupt를 건다.
DMA가 memory bus를 점유하는 동안 CPU는 main memory access를 잠시 못 할 수 있다. 이를 cycle stealing이라고 한다. CPU computation은 약간 느려질 수 있지만, byte-by-byte PIO를 CPU가 수행하지 않아도 되므로 전체 system performance는 보통 좋아진다.
DMA target address를 kernel address space에 두는 것이 가장 단순하다. User space에 직접 쓰면 user가 transfer 중 buffer 내용을 바꾸는 등 문제가 생길 수 있기 때문이다. 하지만 kernel buffer로 받은 뒤 user buffer로 한 번 더 copy하면 double buffering overhead가 생긴다. 그래서 OS는 memory mapping을 이용해 devices와 user address space 사이 I/O transfers를 직접 수행하는 방향으로 발전했다. 일부 architectures는 DVMA (direct virtual memory access)로 virtual addresses를 사용해 DMA를 수행하고, translation을 거쳐 physical transfer를 처리한다.
Protected-mode kernels는 일반 processes가 device commands를 직접 발행하지 못하게 막는다. 이는 access-control violations, erroneous controller use, system crash를 막기 위한 I/O protection이다. 반대로 memory protection이 없는 kernels에서는 direct device access로 높은 성능을 낼 수 있지만 security와 stability가 약해진다.
12.2.5 I/O Hardware Summary
I/O hardware의 electronic details는 복잡하지만, OS 관점에서 기억해야 할 축은 명확하다.
- Device는
port,bus,controller로 host와 연결된다. - Controller는 status/control/data registers를 통해 host와 통신한다.
- Host와 controller는 handshaking으로 command readiness와 completion을 맞춘다.
- Handshaking은
pollingloop로 구현될 수도 있고interrupts로 구현될 수도 있다. - Bulk transfer는
DMA controller에 offload해 CPU의 byte-by-byte PIO 부담을 줄인다. - Device variety가 크기 때문에 OS는 device-specific protocols를 drivers로 캡슐화하고 applications에는 uniform I/O interface를 제공해야 한다.
12.3 Application I/O Interface
Application이 disk 종류를 몰라도 file을 열 수 있고, 새로운 devices를 OS 전체 재작성 없이 추가할 수 있는 이유는 abstraction, encapsulation, software layering 때문이다. OS는 I/O devices의 세부 차이를 몇 가지 general kinds로 추상화하고, 각 kind를 standardized functions, 즉 interface로 access하게 한다. Device-specific differences는 device drivers 안에 숨겨진다.
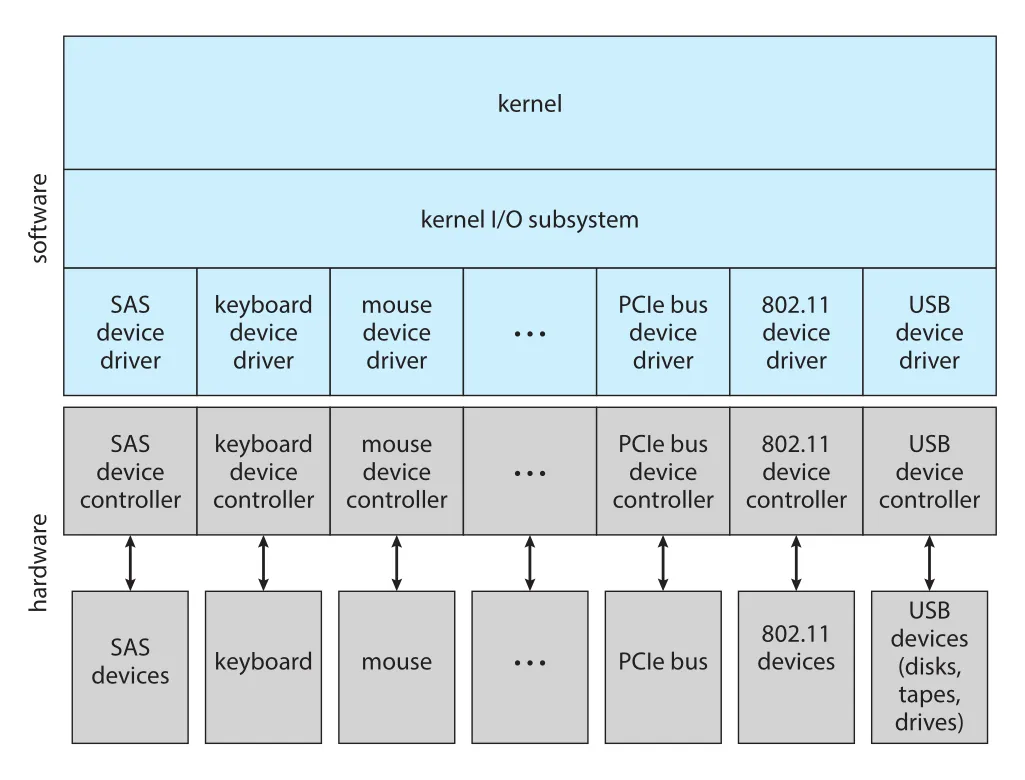
Figure 12.7 · PDF p. 629 · kernel I/O subsystem, device drivers, controllers, hardware devices가 계층적으로 연결되는 구조
Figure 12.7의 핵심은 applications/kernel이 SAS, keyboard, mouse, PCIe, 802.11, USB device의 개별 controller details를 직접 다루지 않는다는 점이다. Device-driver layer가 hardware differences를 숨기고, kernel I/O subsystem은 standard interface를 통해 devices를 다룬다. Hardware manufacturers는 기존 host controller interface, 예를 들어 SATA와 compatible하게 device를 만들거나, popular OS용 driver를 제공함으로써 OS vendor가 직접 support code를 만들 때까지 기다리지 않아도 된다.
다만 각 OS는 device-driver interface standard가 다르다. 같은 device가 Windows, Linux, AIX, macOS용 drivers를 따로 제공할 수 있는 이유다.
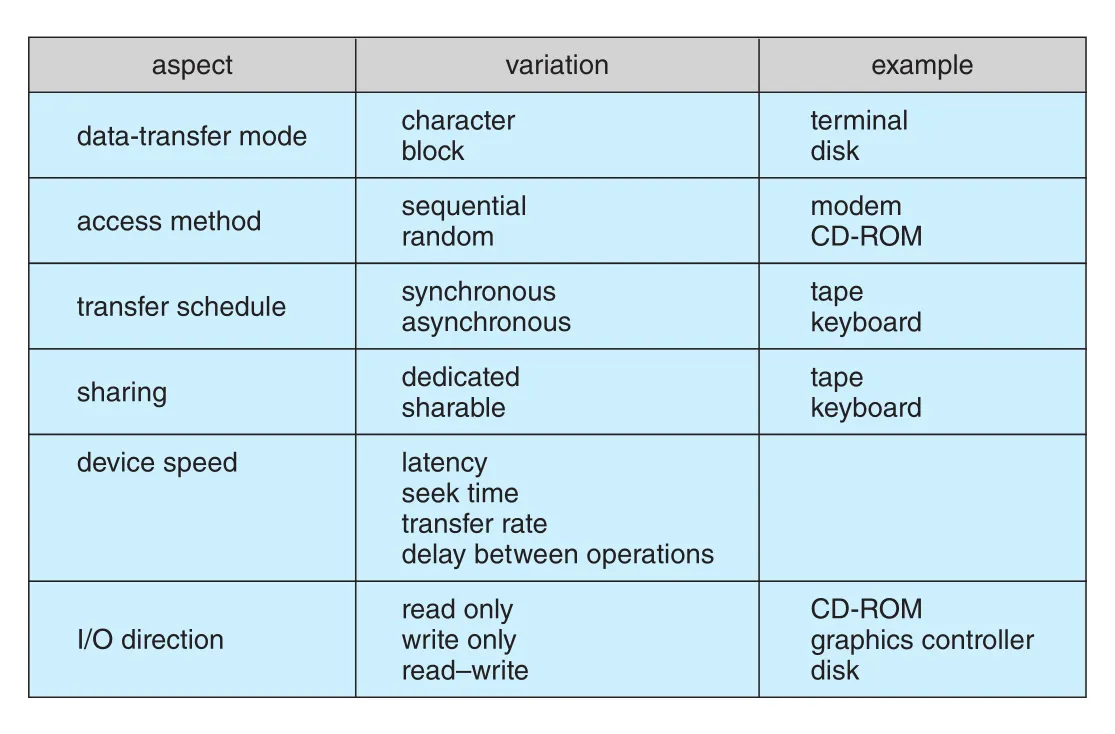
Figure 12.8 · PDF p. 630 · data-transfer mode, access method, transfer schedule, sharing, speed, direction에 따른 I/O device 특성 분류
Device differences는 다음 차원에서 나타난다.
| 차원 | 대표 구분 | 의미 |
|---|---|---|
| data-transfer mode | character vs block | byte stream인지 block unit transfer인지 |
| access method | sequential vs random | device가 정한 fixed order인지 arbitrary location seek가 가능한지 |
| transfer schedule | synchronous vs asynchronous | response time이 predictable/coordinated인지 irregular/unpredictable인지 |
| sharing | sharable vs dedicated | 여러 processes/threads가 concurrent use 가능한지 |
| speed | latency, seek time, transfer rate, delay | device별 속도 차이가 매우 큼 |
| I/O direction | read only, write only, read-write, write once | input/output 가능 방향과 수정 가능성 |
Application access를 위해 OS는 이런 차이의 많은 부분을 숨기고 devices를 conventional types로 묶는다. 주요 access conventions는 block I/O, character-stream I/O, memory-mapped file access, network sockets다. Clocks/timers, graphics, video, audio처럼 별도 system calls가 필요한 devices도 있다.
UNIX의 ioctl()은 표준 system call로 표현하기 어려운 arbitrary device-specific commands를 application에서 driver로 전달하는 escape hatch다. ioctl()은 device identifier, command selector, arbitrary data structure pointer를 사용한다. UNIX/Linux의 device identifier는 major와 minor device numbers tuple이다. Major number는 device type을, minor number는 device instance를 나타내며, OS는 이를 이용해 I/O request를 appropriate driver와 device instance로 route한다.
12.3.1 Block and Character Devices
block-device interface는 disk drives와 block-oriented devices에 필요한 핵심 operation을 제공한다. Device는 read(), write()를 이해해야 하고, random-access device라면 다음 transfer block을 지정하는 seek()도 필요하다. 일반 application은 보통 file-system interface를 통해 block device를 access하므로 low-level device differences에서 보호된다.
OS 자체나 database-management systems 같은 special applications는 block device를 simple linear array of blocks처럼 직접 access하고 싶을 수 있다. 이 방식이 raw I/O다. Application이 자체 buffering을 수행하면 file system buffering은 중복 overhead가 된다. Application이 자체 locking을 제공하면 OS locking은 redundant하거나 충돌할 수도 있다. Raw-device access는 OS가 물러나고 application이 device control을 직접 맡게 하지만, 그만큼 OS services도 제공되지 않는다. 절충으로 UNIX 계열에서는 file operation에서 buffering/locking을 disable하는 direct I/O가 흔해졌다.
memory-mapped file access는 block-device driver 위에 올릴 수 있다. read()/write() 대신 file을 virtual memory address range에 map하고, application은 memory를 읽고 쓰듯 file contents를 다룬다. Actual data transfer는 memory image access를 만족해야 할 때만 수행되며, demand-paged virtual memory와 같은 mechanism을 쓰므로 효율적이다. Program execution에서도 OS는 executable을 memory에 map한 뒤 entry address로 control을 넘긴다. Swap space access에도 mapping interface가 쓰인다.
character-stream interface는 keyboard처럼 byte stream을 spontaneous하게 생성하는 devices에 적합하다. 기본 system calls는 one character를 get()/put()하는 형태다. 그 위에 library가 line-at-a-time access, buffering, editing service를 제공할 수 있다. Keyboard, mouse, modem뿐 아니라 printer, audio board처럼 linear byte stream이 자연스러운 output devices에도 잘 맞는다.
12.3.2 Network Devices
Network I/O는 disk I/O와 performance/addressing characteristics가 크게 다르므로 대부분 OS는 disk의 read()-write()-seek() interface와 다른 network socket interface를 제공한다. Socket은 communication endpoint다. Application은 socket을 만들고, local socket을 remote address에 connect하거나, remote application이 local socket에 connect하기를 listen하고, connection을 통해 packets를 send/receive한다.
Network servers를 위해 socket interface는 select()를 제공한다. select()는 sockets set을 관리하고, 어떤 socket에 받을 packet이 기다리는지, 어떤 socket이 보낼 packet을 받을 room이 있는지 알려 준다. 이렇게 하면 network I/O를 위해 직접 polling/busy waiting을 반복하지 않아도 된다.
UNIX에는 sockets 외에도 half-duplex pipes, full-duplex FIFOs, full-duplex STREAMS, message queues 등 여러 IPC/network mechanisms가 있다. 이 세부 목록보다 중요한 점은 network interface가 storage interface와 다르다는 것이다. Network는 endpoint addressing, packet readiness, congestion/failure, multiplexing이 중심이고, disk는 block location과 sequential/random access가 중심이다.
12.3.3 Clocks and Timers
Hardware clocks와 timers는 세 가지 기본 기능을 제공한다.
- Current time 제공
- Elapsed time 측정
- Time T에 operation X를 trigger하도록 timer 설정
이 기능은 OS와 time-sensitive applications가 모두 많이 사용한다. Elapsed time measurement와 operation trigger에 쓰이는 hardware는 programmable interval timer다. 일정 시간 뒤 interrupt를 발생시키거나 periodic interrupts를 발생시키도록 설정할 수 있다.
Scheduler는 timer interrupt를 사용해 time slice가 끝난 process를 preempt한다. Disk I/O subsystem은 dirty cache buffers를 주기적으로 disk에 flush하는 데 timer를 쓰고, network subsystem은 congestion/failure로 너무 느린 operations를 cancel하는 데 timer를 쓴다.
Hardware timer channels 수보다 더 많은 timer requests를 지원하기 위해 OS는 virtual clocks를 simulate한다. Kernel 또는 timer device driver는 kernel routines와 user requests가 원하는 interrupts를 earliest-time-first order로 정렬한 list를 유지하고, 가장 이른 time으로 hardware timer를 설정한다. Timer interrupt가 발생하면 해당 requester에게 signal을 보내고 다음 earliest time으로 timer를 reload한다.
System clock은 drift할 수 있다. Timer ticks로 time-of-day clock을 유지하면 hardware resolution과 overhead 때문에 오차가 누적될 수 있다. NTP (Network Time Protocol) 같은 protocol은 latency calculation을 사용해 clock accuracy를 보정한다.
12.3.4 Nonblocking and Asynchronous I/O
Application interface에서 중요한 선택은 blocking I/O, nonblocking I/O, asynchronous I/O다.
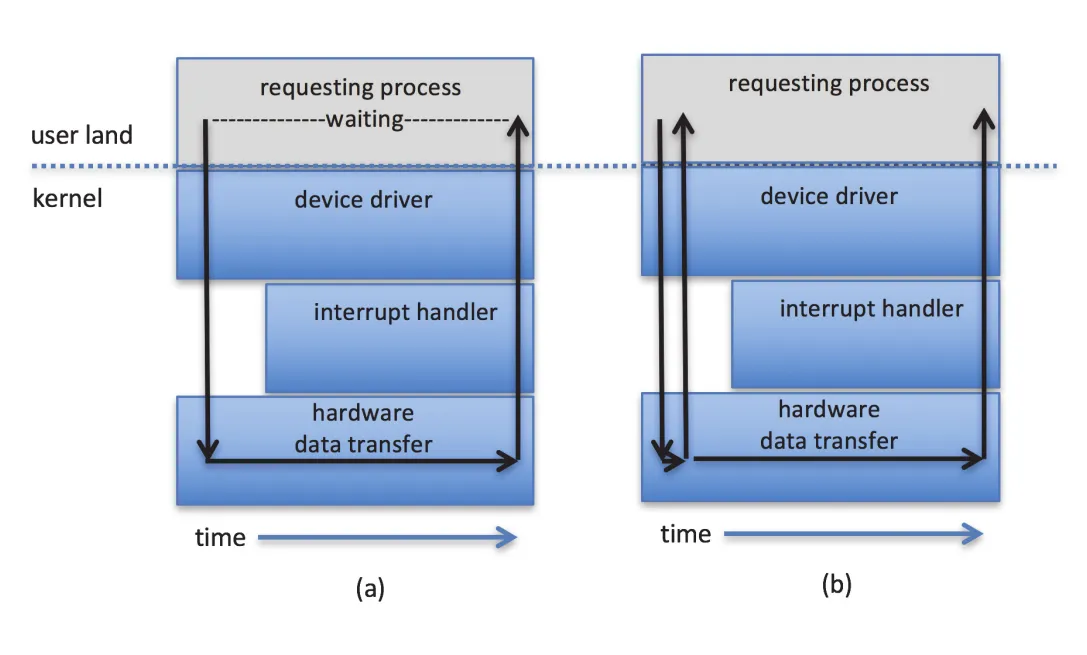
Figure 12.9 · PDF p. 635 · synchronous I/O는 completion까지 기다리고 asynchronous I/O는 request 후 application execution과 I/O가 겹치는 구조
blocking system call에서는 calling thread execution이 suspend된다. Thread는 run queue에서 wait queue로 옮겨지고, system call이 complete되면 run queue로 돌아와 return values를 받는다. Physical I/O는 본질적으로 asynchronous하고 unpredictable하지만, OS가 blocking system call을 제공하는 이유는 blocking application code가 nonblocking/asynchronous code보다 작성하기 쉽기 때문이다.
User interface, video playback처럼 input/output과 computation/display를 overlap해야 하는 processes는 nonblocking I/O가 필요하다. 한 방법은 multithreaded application을 작성해 일부 threads가 blocking calls를 수행하고 다른 threads가 계속 실행되게 하는 것이다. 다른 방법은 OS의 nonblocking I/O system calls를 사용하는 것이다. nonblocking call은 오래 멈추지 않고 빨리 return하며, transferred bytes 수를 return value로 알려 준다.
asynchronous system call은 I/O completion을 기다리지 않고 즉시 return한다. Thread는 계속 실행하고, future completion은 variable setting, signal/software interrupt, callback routine 등으로 통지된다. nonblocking read()는 즉시 return하되 available data만 반환한다. 요청한 bytes 전체, 일부, 또는 none일 수 있다. 반면 asynchronous read()는 transfer 전체가 나중에 완료될 것을 요청하고, completion event가 별도로 온다.
OS 내부에서도 asynchronous behavior가 흔하다. Application이 network send나 storage write를 요청하면 OS가 request를 기록하고 buffer에 담은 뒤 application에 return할 수 있다. 이후 system performance를 고려해 실제 I/O를 complete한다. 이 사이 system failure가 나면 in-flight requests가 lost될 수 있으므로 OS는 buffer delay에 limit을 둔다. UNIX 일부는 secondary storage buffers를 30 seconds마다 flush하거나 request 발생 후 30 seconds 안에 flush한다. Applications가 buffer flush를 명시적으로 요청하는 방법도 제공된다.
Kernel은 data consistency를 위해 device I/O를 아직 하지 않은 buffered data도 read request에 반환한다. 다만 같은 file에 여러 threads가 I/O를 수행하면 kernel 구현에 따라 consistent data를 받지 못할 수 있으므로 locking protocols가 필요할 수 있다. 즉시 수행되어야 하는 I/O는 synchronous로 요청할 수 있어야 한다.
select()는 nonblocking behavior의 좋은 예다. Maximum waiting time을 0으로 설정하면 thread는 blocking 없이 network activity를 poll할 수 있다. 다만 select() 자체는 I/O 가능 여부를 확인할 뿐이므로 실제 transfer를 위해서는 read() 또는 write()가 뒤따라야 한다.
12.3.5 Vectored I/O
vectored I/O는 하나의 system call이 multiple locations에 대한 multiple I/O operations를 수행하게 한다. UNIX readv/writev는 multiple buffers vector를 받아 source에서 vector로 읽거나 vector에서 destination으로 쓴다. 여러 system calls로 나누어 수행할 수도 있지만, scatter-gather 방식은 중요한 이점이 있다.
- Multiple buffers를 하나의 system call로 transfer하여 context-switching과 system-call overhead를 줄인다.
- Data를 먼저 큰 intermediate buffer에 올바른 순서로 복사한 뒤 전송하는 비효율을 피한다.
- 일부 scatter-gather implementations는 atomicity를 제공해 다른 threads가 같은 buffers와 관련된 I/O를 수행할 때 data corruption 위험을 줄인다.
따라서 programmers는 가능할 때 scatter-gather I/O를 사용해 throughput을 높이고 system overhead를 줄일 수 있다.
12.4 Kernel I/O Subsystem
Kernel의 I/O subsystem은 hardware와 device-driver infrastructure 위에서 여러 services를 제공한다. 핵심 services는 scheduling, buffering, caching, spooling, device reservation, error handling, protection, device-driver initialization, power management다. 이 절의 중심은 “device가 다양해도 kernel이 어떤 공통 서비스를 제공해 application과 kernel 내부 subsystems가 I/O를 안정적으로 쓰게 하는가?”이다.
12.4.1 I/O Scheduling
I/O scheduling은 pending I/O requests를 어떤 순서로 실행할지 정하는 작업이다. Application이 system calls를 발행한 순서가 항상 좋은 service order는 아니다. 예를 들어 disk arm이 disk beginning 근처에 있는데 세 applications가 end, beginning, middle block을 요청했다면, OS는 2, 3, 1 순서로 처리해 disk arm 이동 거리를 줄일 수 있다.
I/O scheduling은 세 목표를 가진다.
| 목표 | 설명 |
|---|---|
| performance | device movement/latency를 줄이고 throughput을 높임 |
| fairness | 특정 application이 지나치게 나쁜 service를 받지 않게 함 |
| priority/timeliness | virtual memory 같은 delay-sensitive requests를 application requests보다 우선할 수 있음 |
Kernel은 보통 device마다 wait queue를 유지한다. Blocking I/O system call이 발생하면 request가 해당 device queue에 들어가고, I/O scheduler가 queue order를 재배열한다. Asynchronous I/O를 지원하는 kernel은 동시에 여러 I/O requests를 추적해야 하므로 device-status table 같은 구조를 사용한다.
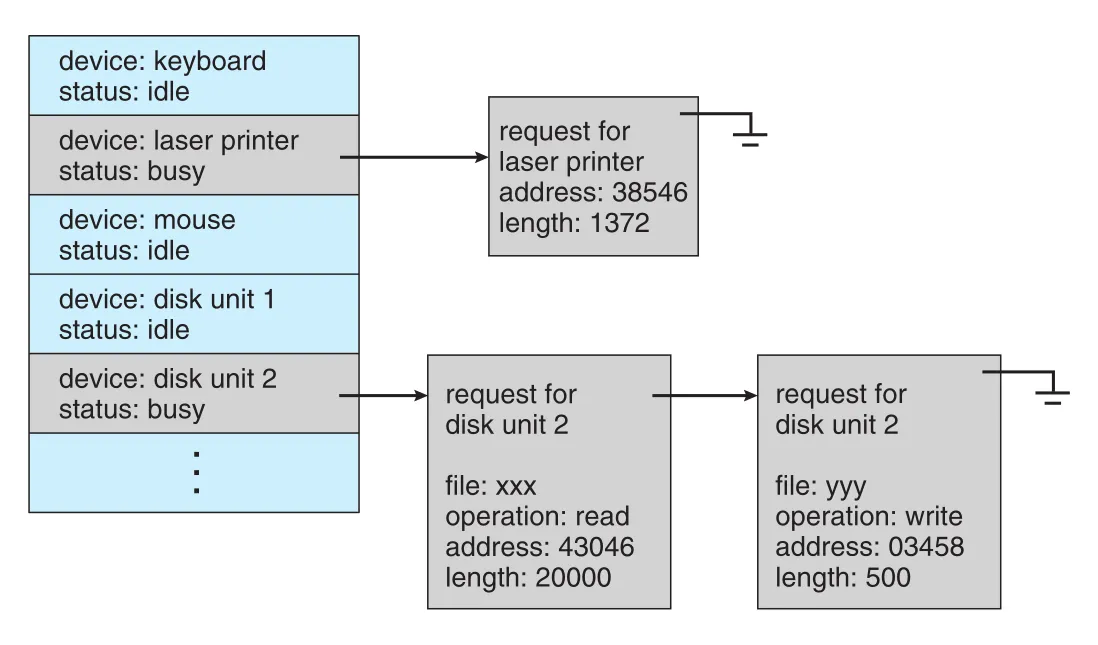
Figure 12.10 · PDF p. 637 · 각 device의 상태와 active/pending I/O request를 추적하는 device-status table
Device-status table entry는 device type, address, state, 예를 들어 not functioning, idle, busy를 담는다. Device가 busy라면 active request type과 parameters도 entry에 저장된다. Chapter 11의 disk scheduling algorithms는 이 I/O scheduling이 storage device에서 어떻게 구체화되는지 보여주는 예다.
12.4.2 Buffering
buffer는 device와 device 사이, 또는 device와 application 사이에서 transfer 중인 data를 저장하는 memory area다. Buffering은 세 가지 이유로 필요하다.
첫째, speed mismatch를 완화한다. 예를 들어 Internet으로 받은 file을 SSD에 저장할 때 network는 drive보다 훨씬 느릴 수 있다. Main memory buffer는 network에서 들어오는 bytes를 모으고, buffer가 가득 차면 drive에 한 번에 write한다. Drive write 중에도 network는 계속 data를 받을 장소가 필요하므로 double buffering을 사용한다. 한 buffer가 drive로 쓰이는 동안 다른 buffer가 network input을 받는다.
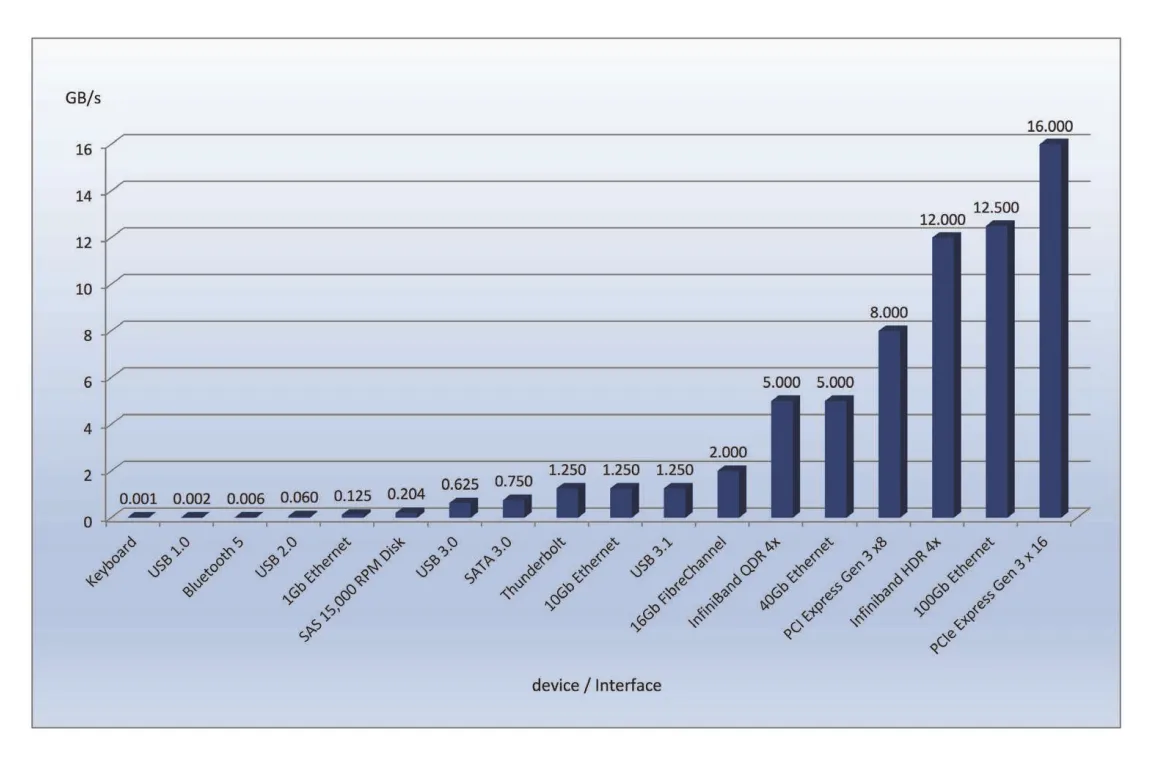
Figure 12.11 · PDF p. 638 · PC/data-center devices와 interfaces의 큰 speed 차이가 buffering 필요성을 만든다
둘째, transfer size가 다른 devices를 맞춘다. Networking에서는 large message를 small packets로 fragment하고, receiving side에서 reassembly buffer에 packets를 모아 original data image를 만든다.
셋째, copy semantics를 제공한다. Application이 write()를 호출하면서 buffer pointer와 byte count를 넘긴 뒤, system call이 return한 후 application buffer 내용을 바꾸면 어떤 data가 disk에 써져야 하는가? Copy semantics는 system call 시점의 data version이 disk에 기록됨을 보장한다. 이를 위해 OS는 write()가 return하기 전에 application data를 kernel buffer로 copy하고, disk write는 kernel buffer에서 수행한다. 이 copy overhead는 크지만 semantics가 명확하다. Virtual memory mapping과 copy-on-write page protection을 잘 활용하면 더 효율적으로 같은 효과를 낼 수 있다.
12.4.3 Caching
cache는 original보다 빠른 storage에 data copy를 두는 영역이다. Buffer와 cache의 차이는 중요하다. Buffer는 data item의 only existing copy를 들고 있을 수 있지만, cache는 definition상 elsewhere에 원본이 있는 item의 copy다.
Caching과 buffering은 다른 기능이지만 같은 memory region이 둘 다 수행할 수 있다. OS는 disk data를 main memory buffers에 보관해 copy semantics와 disk I/O scheduling을 지원하면서, 동시에 buffer cache로 사용해 shared files나 빠르게 write/read되는 files의 I/O efficiency를 높인다.
Kernel이 file I/O request를 받으면 먼저 buffer cache를 확인한다. File region이 이미 memory에 있으면 physical disk I/O를 avoid하거나 defer할 수 있다. Disk writes도 buffer cache에 몇 초 동안 accumulate해 large transfers로 묶고 efficient write schedule을 만들 수 있다. 이 전략은 성능을 올리지만 crash 전 in-flight writes의 durability 문제와 연결된다.
12.4.4 Spooling and Device Reservation
spool은 printer처럼 interleaved data streams를 받아들이면 안 되는 device를 위한 output buffer다. Printer는 한 번에 한 job만 제대로 처리할 수 있지만 여러 applications가 동시에 print를 원할 수 있다. OS는 printer output을 직접 device에 섞어 보내지 않고, 각 application output을 separate secondary storage file에 spooling한다. Application이 printing을 끝내면 corresponding spool file을 printer queue에 넣고, spooling system이 queued spool files를 하나씩 printer로 copy한다.
Spooling은 daemon process나 in-kernel thread가 관리할 수 있다. OS는 queue display, job removal, printer servicing 중 suspend 같은 control interface도 제공한다.
Tape drives와 printers처럼 multiple concurrent requests를 useful하게 multiplex할 수 없는 devices에는 device reservation도 필요하다. 어떤 OS는 idle device를 process가 allocate/deallocate하게 하고, 어떤 OS는 한 번에 하나의 open file handle만 허용한다. Windows처럼 device object가 available해질 때까지 wait하거나 OpenFile()에서 concurrent access type을 선언하게 하는 방식도 있다. 이런 systems에서는 applications가 deadlock을 피하도록 coordination해야 한다.
12.4.5 Error Handling
Protected memory를 사용하는 OS는 많은 hardware/application errors가 전체 system failure로 이어지지 않게 막을 수 있다. I/O failures는 transient reasons, 예를 들어 network overload 때문일 수도 있고, permanent reasons, 예를 들어 defective disk controller 때문일 수도 있다. OS는 transient failures에 대해 retry/resend로 보상할 수 있다. Disk read() failure는 retry하고, network send() error는 protocol이 지정한다면 resend할 수 있다. 하지만 중요한 component의 permanent failure는 OS가 복구하기 어렵다.
일반적으로 I/O system call은 success/failure라는 coarse status를 반환한다. UNIX는 추가로 errno integer variable을 사용해 argument out of range, bad pointer, file not open 같은 general failure nature를 알려 준다. 반면 hardware는 훨씬 상세한 error 정보를 제공할 수 있다. SCSI device failure는 sense key, additional sense code, additional sense-code qualifier처럼 여러 level의 detail을 제공하지만, 많은 OS는 이 detail을 application까지 전달하도록 설계되어 있지 않다.
12.4.6 I/O Protection
I/O protection은 user process가 illegal I/O instructions로 system을 방해하지 못하게 하는 문제다. 기본 원칙은 모든 I/O instructions를 privileged instructions로 정의하는 것이다. User program은 직접 I/O instruction을 실행하지 않고 system call을 통해 OS에게 대신 I/O를 요청한다.
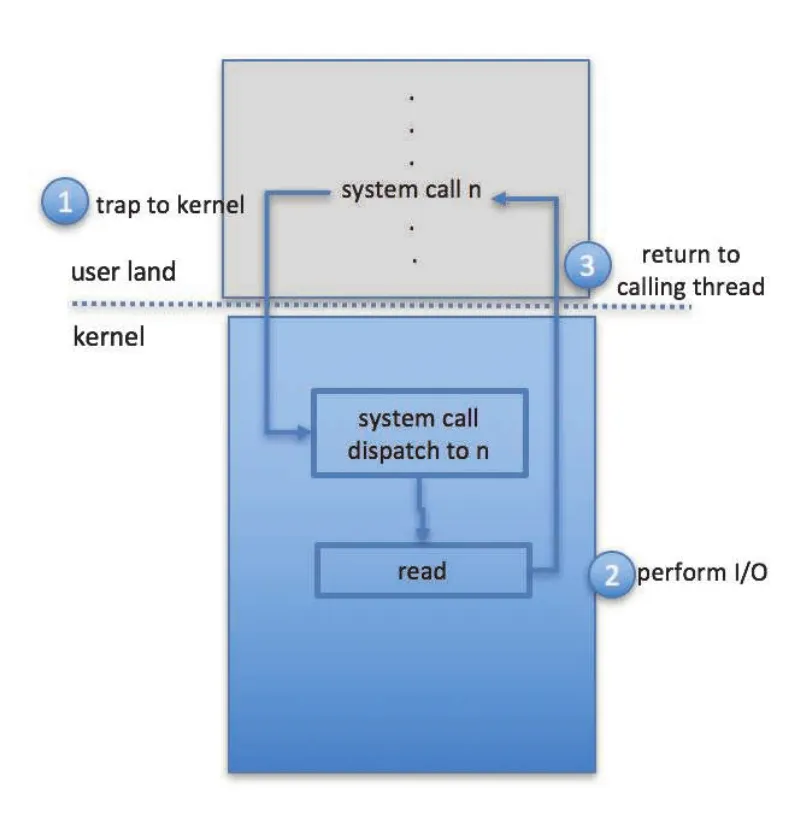
Figure 12.12 · PDF p. 641 · user process가 system call을 통해 kernel mode OS에게 I/O 수행을 요청하는 보호 구조
OS는 monitor mode에서 request validity를 검사하고, 유효하면 requested I/O를 수행한 뒤 user로 돌아간다. Memory-mapped I/O와 I/O port memory locations도 memory-protection system으로 user access를 제한해야 한다.
하지만 모든 user access를 막을 수는 없다. Graphics games나 video editing/playback software는 graphics controller memory에 direct access해야 성능이 나온다. Kernel은 이 경우 screen window에 해당하는 graphics memory section을 한 process에 할당하는 locking mechanism을 제공할 수 있다. 즉 protection과 performance 사이의 균형이 필요하다.
12.4.7 Kernel Data Structures
Kernel은 I/O components 사용 상태를 추적하기 위해 open-file table, network connection tables, character-device communication structures 같은 in-kernel data structures를 유지한다.
UNIX는 user files, raw devices, process address spaces 같은 다양한 entities에 file-system-like access를 제공한다. 모두 read() operation을 지원할 수 있지만 semantics는 다르다.
| 대상 | read() 처리 의미 |
|---|---|
| user file | buffer cache를 먼저 확인하고 필요하면 disk I/O 수행 |
| raw disk | request size가 sector size multiple인지, sector boundary에 aligned인지 확인 |
| process image | memory에서 data copy |
UNIX는 이런 차이를 uniform structure 안에 캡슐화하기 위해 object-oriented technique을 사용한다. Open-file record는 type별 routine pointers를 담은 dispatch table을 가진다.
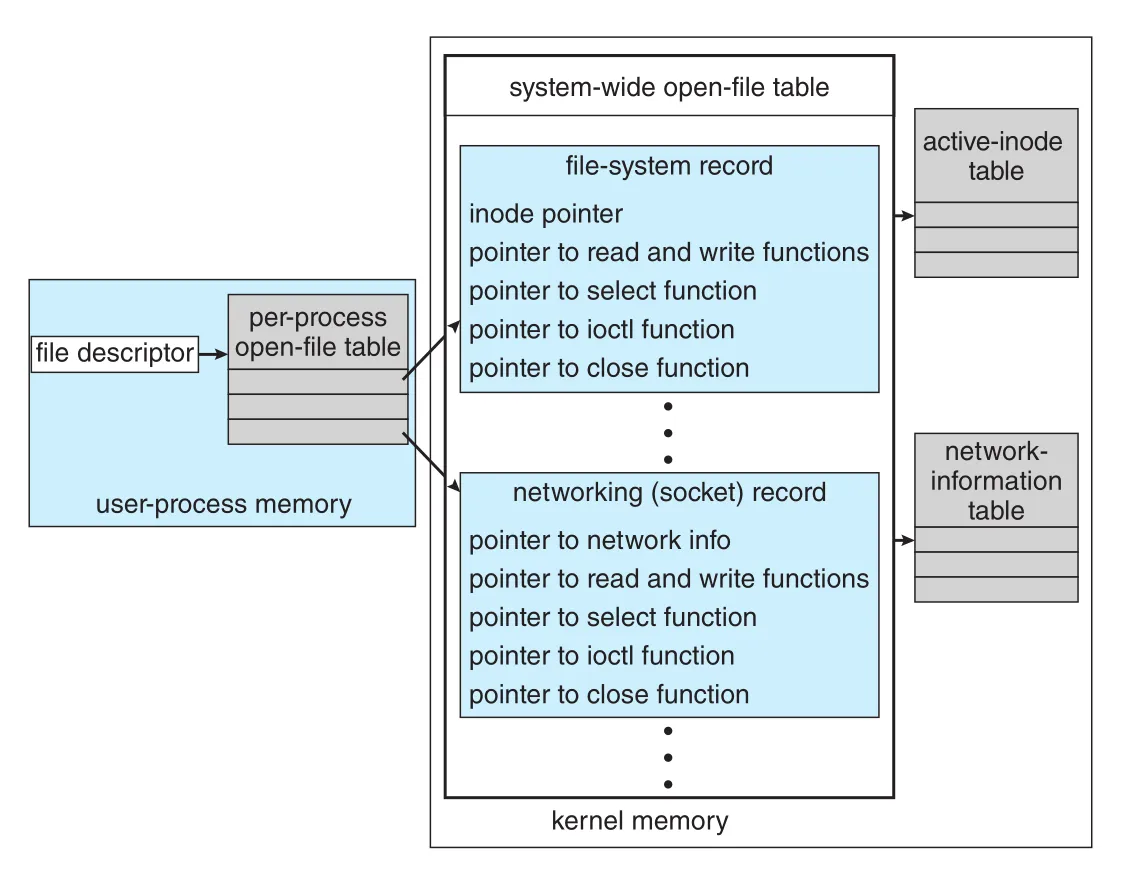
Figure 12.13 · PDF p. 642 · UNIX open-file table이 file-system record와 networking socket record를 dispatch table로 연결하는 구조
Figure 12.13에서 file-system record와 networking socket record는 각각 read/write/select/ioctl/close function pointers를 가진다. User process는 file descriptor를 통해 접근하지만 kernel 내부에서는 entity type에 맞는 routine이 dispatch된다.
Windows는 I/O request를 message로 변환해 kernel의 I/O manager와 device driver로 전달하는 message-passing implementation을 사용한다. Message-passing은 shared data structure를 사용하는 procedural technique보다 overhead가 있을 수 있지만, I/O system structure를 단순화하고 flexibility를 높인다.
12.4.8 Power Management
Power management는 I/O subsystem과 device management의 중요한 일부다. Data center에서는 electricity가 heat를 만들고 cooling cost까지 증가시키므로, OS와 management tools는 load를 조정해 일부 systems를 idle/off 상태로 만들 수 있다. Hardware가 지원하면 OS는 low load에서 CPUs, external I/O devices 같은 components를 power off할 수 있다.
CPU cores는 system load가 낮을 때 suspend되고, load가 증가하면 resume될 수 있다. Suspend/resume 시 state save/restore가 필요하다. 많은 servers가 있는 data center에서는 unused cores를 끄는 것만으로 electricity와 cooling needs를 줄일 수 있다.
Mobile systems에서는 power management가 더 직접적인 user experience 문제다. Android 예시는 세 기능을 보여준다.
| 기능 | 의미 |
|---|---|
power collapse | device를 fully powered off에 가까운 deep sleep state로 두되 external stimuli에 빠르게 깨어나게 함 |
| component-level power management | device tree와 driver state를 이용해 unused components, bus, subsystem을 단계적으로 끔 |
wakelock | application이 update, video, page loading 등 동안 system이 power collapse에 들어가지 못하게 temporarily hold하는 lock |
Component-level power management는 device topology를 나타내는 device tree와 각 component의 driver usage tracking에 의존한다. Flash와 USB storage가 I/O subsystem의 subnodes이고, I/O subsystem이 system bus의 subnode인 식으로 dependency를 알면, unused component부터 bus/subsystem까지 안전하게 끌 수 있다.
General-purpose computers는 firmware와 OS가 device state discovery, hot-plug, power state change를 함께 관리한다. ACPI (Advanced Configuration and Power Interface)는 device state discovery/management, device error management, power management를 위한 firmware routines를 kernel이 호출할 수 있게 한다. 예를 들어 kernel이 device를 quiesce해야 하면 device driver가 ACPI routines를 호출하고, ACPI가 device와 통신한다.
12.4.9 Kernel I/O Subsystem Summary
Kernel I/O subsystem은 application과 kernel의 다른 부분이 사용하는 많은 services를 조정한다.
- files/devices name space management
- files/devices access control
- operation control, 예를 들어 modem은
seek()할 수 없음 - file-system space allocation
- device allocation
- buffering, caching, spooling
- I/O scheduling
- device-status monitoring, error handling, failure recovery
- device-driver configuration and initialization
- I/O devices power management
Upper-level I/O subsystem은 device drivers가 제공하는 uniform interface를 통해 devices에 접근한다. 그래서 kernel은 device-specific details를 직접 흩뿌리지 않고도 다양한 hardware를 관리할 수 있다.
12.5 Transforming I/O Requests to Hardware Operations
Application은 보통 file name이나 file descriptor를 사용하지만, 실제 I/O는 network wires나 disk sector, device controller registers까지 내려가야 한다. 이 절은 user-level request가 어떻게 physical device controller까지 연결되는지 설명한다.
Disk file read를 예로 들면 application은 data를 file name으로 참조한다. File system은 directories를 통해 file name을 space allocation information으로 mapping한다. MS-DOS FAT에서는 name이 file-access table entry를 가리키고, 그 entry가 file에 할당된 disk blocks를 알려 준다. UNIX에서는 name이 inode number로 mapping되고 inode가 space allocation information을 가진다. 하지만 여기서 한 단계 더 필요하다. File name에서 disk controller의 port address 또는 memory-mapped controller registers까지 어떻게 도달하는가?
MS-DOS FAT 방식은 file name 앞부분, 예를 들어 C:가 specific hardware device를 식별한다. C:는 primary hard disk를 의미하도록 OS에 built-in되어 있고, device table을 통해 specific port address로 mapping된다. Colon separator 덕분에 device name space와 file-system name space가 분리된다. 이 방식은 printer에 written files에 spooling을 적용하는 것처럼 device별 extra functionality를 붙이기 쉽다.
UNIX는 device names를 regular file-system name space 안에 포함한다. UNIX pathname에는 device portion이 명확히 분리되어 있지 않다. 대신 UNIX는 mount table을 사용한다. Pathname을 resolve할 때 가장 긴 matching prefix를 mount table에서 찾고, corresponding entry가 device name을 준다. 이 device name도 file-system name space의 name 형태다. UNIX가 이 name을 directory structures에서 찾으면 inode number가 아니라 <major, minor> device number를 얻는다.
major device number는 I/O를 처리할 device driver를 식별한다. minor device number는 device driver 내부에서 device table을 index하는 데 전달된다. 해당 device-table entry가 device controller의 port address 또는 memory-mapped address를 알려 준다.
이 multiple lookup stages 덕분에 modern OS는 flexibility를 얻는다. Application과 drivers 사이 request passing mechanisms는 general하게 유지되고, 새로운 devices와 drivers를 kernel recompilation 없이 추가할 수 있다. 일부 OS는 device drivers를 on demand로 load한다. Boot time에는 hardware buses를 probe해 present devices를 찾고 필요한 drivers를 load한다. Boot 이후 추가된 devices는 interrupt가 발생했지만 handler가 없는 error 같은 상황을 통해 감지되고, kernel이 device details를 조사해 driver를 dynamically load할 수 있다. Dynamic loading/unloading은 static loading보다 device-structure locking, error handling, kernel algorithms가 더 복잡하다.
Typical blocking read() request의 life cycle은 다음과 같다.
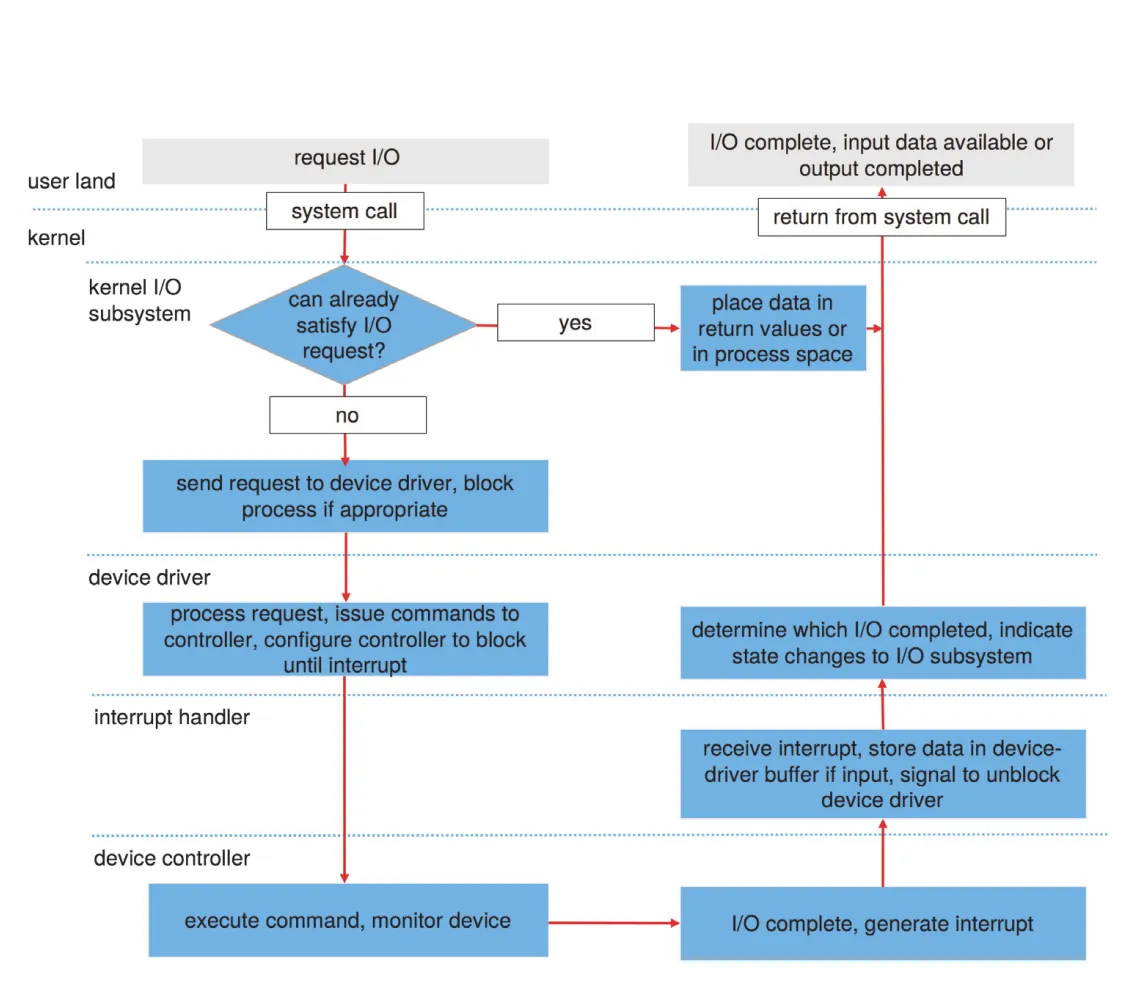
Figure 12.14 · PDF p. 646 · blocking read request가 system call, kernel I/O subsystem, driver, controller, interrupt를 거쳐 완료되는 생애주기
- Process가 이미 open된 file descriptor에 blocking
read()system call을 발행한다. - Kernel system-call code가 parameters를 검사한다. Input data가 buffer cache에 이미 있으면 data를 process에 반환하고 request는 끝난다.
- Cache에 없으면 physical I/O가 필요하다. Process는 run queue에서 제거되어 device wait queue에 들어가고 I/O request가 scheduled된다. I/O subsystem은 request를 device driver로 보낸다.
- Device driver는 data를 받을 kernel buffer space를 allocate하고 I/O를 schedule한다. 이후 device-control registers에 commands를 write해 device controller에 명령한다.
- Device controller가 device hardware를 동작시켜 data transfer를 수행한다.
- Driver는 status/data를 polling할 수도 있고, DMA transfer를 setup할 수도 있다. DMA라면 transfer completion 시 DMA controller가 interrupt를 발생시킨다.
- Interrupt vector table을 통해 correct interrupt handler가 interrupt를 받고 필요한 data를 저장하며 device driver에 signal한 뒤 return한다.
- Device driver는 완료된 request와 status를 판별하고 kernel I/O subsystem에 completion을 알린다.
- Kernel은 data 또는 return codes를 requesting process의 address space로 transfer하고, process를 wait queue에서 ready queue로 옮긴다.
- Scheduler가 process에 CPU를 배정하면 process는 system call completion 지점에서 execution을 재개한다.
이 흐름은 I/O operation 하나가 user/kernel mode switch, cache lookup, queueing, scheduling, driver dispatch, controller programming, DMA/interrupt, buffer copy, scheduler interaction을 모두 거칠 수 있음을 보여준다. I/O performance 최적화가 어려운 이유는 이 단계들이 각각 overhead와 latency를 만들기 때문이다.
12.6 STREAMS
STREAMS는 UNIX System V와 이후 여러 UNIX releases에서 제공된 mechanism으로, application이 driver code pipelines를 dynamically assemble할 수 있게 한다. stream은 device driver와 user-level process 사이의 full-duplex connection이다. Stream은 user process와 접하는 stream head, device를 control하는 driver end, 그리고 그 사이의 zero or more stream modules로 구성된다.
각 STREAMS component는 read queue와 write queue 한 쌍을 가진다. Queues 사이 data transfer는 message passing으로 수행된다.
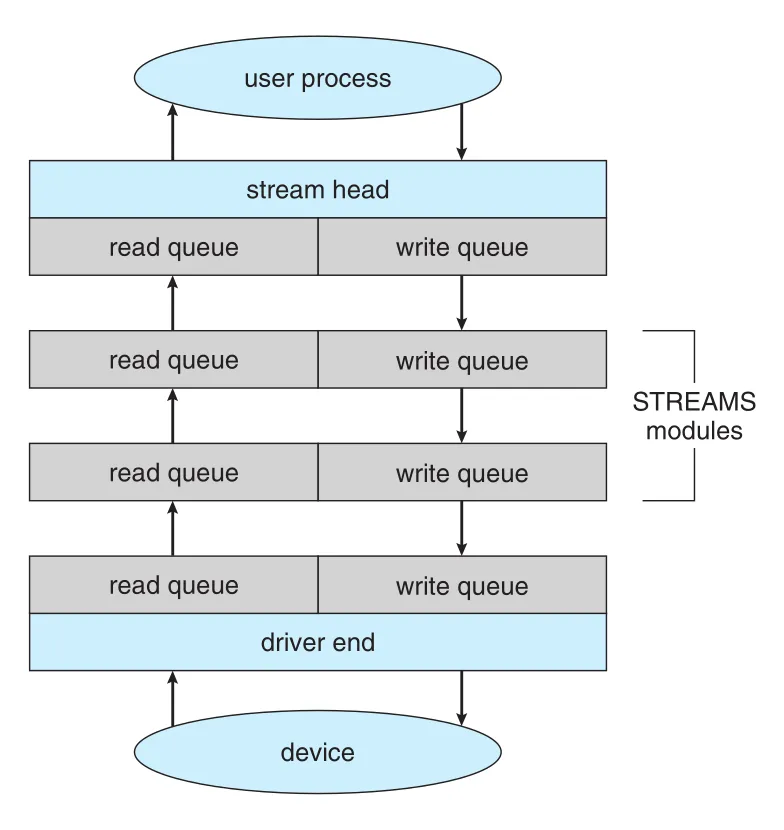
Figure 12.15 · PDF p. 648 · stream head, STREAMS modules, driver end가 read/write queues와 message passing으로 연결되는 구조
Modules는 STREAMS processing 기능을 제공하며 ioctl() system call로 stream에 push된다. 예를 들어 process가 USB keyboard를 stream으로 열고, input editing module을 push할 수 있다.
Adjacent modules 사이에는 messages가 queue로 전달된다. 한 module의 queue가 adjacent queue보다 빠르게 messages를 보내면 overflow가 생길 수 있으므로 flow control이 필요하다. Flow control이 없는 queue는 messages를 모두 받아 즉시 다음 queue로 보낸다. Flow control을 지원하는 queue는 buffer space가 충분하지 않으면 messages를 받지 않고, adjacent queues와 control messages를 교환해 흐름을 조절한다.
User process는 write() 또는 putmsg()로 stream에 data를 쓴다. write()는 raw data를 stream에 쓰고, putmsg()는 structured message를 지정할 수 있다. Stream head는 data를 message로 copy하고 next module queue에 전달한다. 이 message copying은 driver end, 그리고 device까지 계속된다. Read 쪽에서는 user process가 read() 또는 getmsg()를 사용한다. read()는 message를 ordinary byte stream으로 반환하고, getmsg()는 message 형태로 반환한다.
STREAMS I/O는 user process가 stream head와 통신하는 순간을 제외하면 asynchronous 또는 nonblocking이다. Write 시 next queue가 flow control을 사용하고 room이 없다면 user process는 message copy 공간이 생길 때까지 block된다. Read 시에도 data가 available할 때까지 block된다.
Driver end도 read/write queues를 가지지만 stream head와 달리 interrupts에 반응해야 한다. 예를 들어 network frame이 ready 되면 driver end는 incoming data를 모두 처리해야 한다. Stream head는 다음 queue에 copy할 수 없으면 block될 수 있지만, driver end는 device에서 들어오는 data를 무시할 수 없다. Device buffer가 full이면 network card처럼 incoming messages를 drop할 수 있다. 따라서 STREAMS에서도 flow control은 queue overflow뿐 아니라 device-level loss와 연결된다.
STREAMS의 장점은 device drivers와 network protocols를 modular/incremental하게 작성할 수 있는 framework를 제공한다는 점이다. Modules는 여러 streams와 devices에서 reuse될 수 있다. 예를 들어 networking module은 Ethernet card와 802.11 wireless card 모두에서 사용될 수 있다. 또한 character-device I/O를 단순 unstructured byte stream으로만 보지 않고, modules 사이 communication에서 message boundaries와 control information을 유지할 수 있다.
12.7 Performance
I/O는 system performance의 큰 factor다. Device-driver code 실행, fair/efficient process scheduling, block/unblock에 따른 context switches, interrupt handling, controller-physical memory copy, kernel buffer-application space copy가 모두 CPU, hardware caches, memory bus에 부담을 준다. I/O 성능 문제는 단순히 device가 빠른지 느린지의 문제가 아니라 CPU, memory subsystem, bus, controller, kernel software layers가 함께 만드는 문제다.
Interrupt handling은 현대 computer가 초당 많은 interrupts를 처리할 수 있어도 여전히 expensive하다. Interrupt마다 state change, interrupt handler execution, state restore가 필요하다. PIO도 busy waiting cycles가 과하지 않다면 interrupt-driven I/O보다 효율적일 수 있다. I/O completion은 보통 blocked process를 unblock하므로 full context switch overhead로 이어진다.
Network traffic은 context-switch rate를 크게 만들 수 있다. Remote login에서 사용자가 한 character를 입력하면 local machine에서 keyboard interrupt, driver/kernel/user process 전달, network I/O system call, packet construction, network driver/controller transfer, completion interrupt가 발생한다. Remote machine에서도 packet receive interrupt, protocol unpacking, daemon/subdaemon 전달이 이어진다. Receiver가 character를 echo하면 이 작업이 다시 한 번 발생한다.
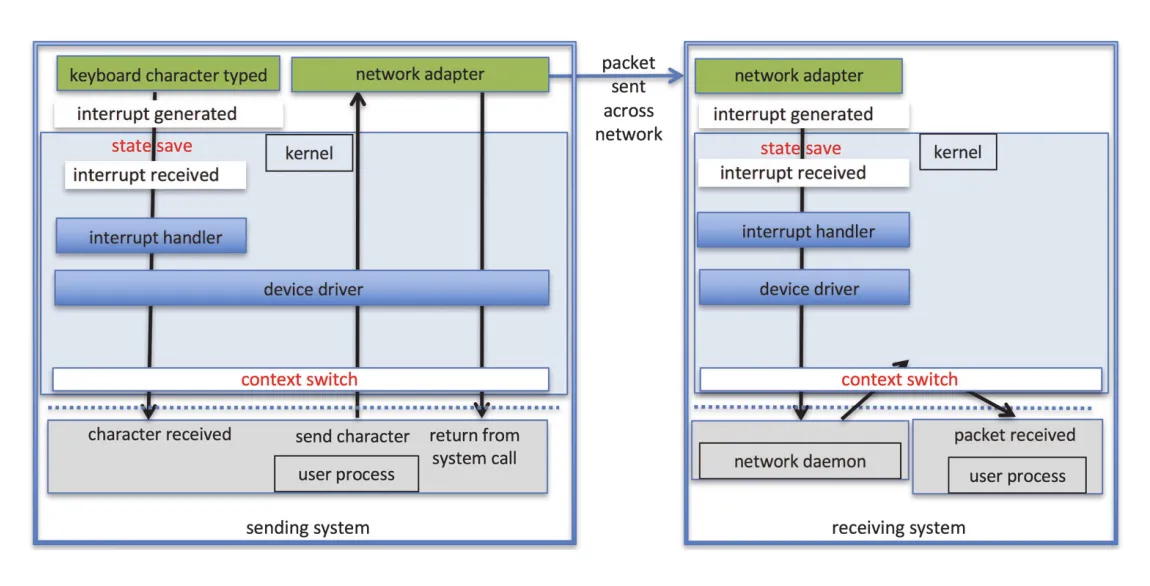
Figure 12.16 · PDF p. 650 · 한 character가 원격 로그인에서 양쪽 시스템의 driver, kernel, daemon, network를 거치며 context/state switches를 만드는 흐름
Interrupt burden을 줄이기 위해 일부 systems는 terminal I/O용 front-end processors를 사용한다. Terminal concentrator는 hundreds of remote terminals traffic을 large computer의 one port로 multiplex할 수 있다. I/O channel은 mainframes/high-end systems에서 I/O work를 main CPU에서 offload하는 dedicated special-purpose CPU다. Channels는 data flow를 유지하고 main CPU는 data processing에 집중하게 한다. Device controllers와 DMA controllers의 더 일반적이고 강력한 형태로 볼 수 있다.
I/O efficiency를 높이는 원칙은 다음과 같다.
| 원칙 | 효과 |
|---|---|
| context switches 줄이기 | protection boundary crossing과 scheduler overhead 감소 |
| memory copy 횟수 줄이기 | controller-memory, kernel-user copy로 인한 CPU/memory bus load 감소 |
| interrupts frequency 줄이기 | large transfers, smart controllers, 적절한 polling으로 interrupt overhead 감소 |
| DMA-aware controllers/channels 사용 | CPU가 simple data copying에서 벗어나 concurrency 증가 |
| processing primitives를 hardware로 이동 | controller operation과 CPU/bus operation을 병렬화 |
| CPU, memory, bus, I/O balance | 한 영역 overload로 다른 영역이 idle해지는 병목 방지 |
I/O functionality를 어디에 구현할지는 중요한 trade-off다. Mouse driver처럼 단순한 device도 있지만, Windows disk device driver처럼 RAID arrays, error handling, data recovery, disk performance optimization까지 수행하는 복잡한 driver도 있다.
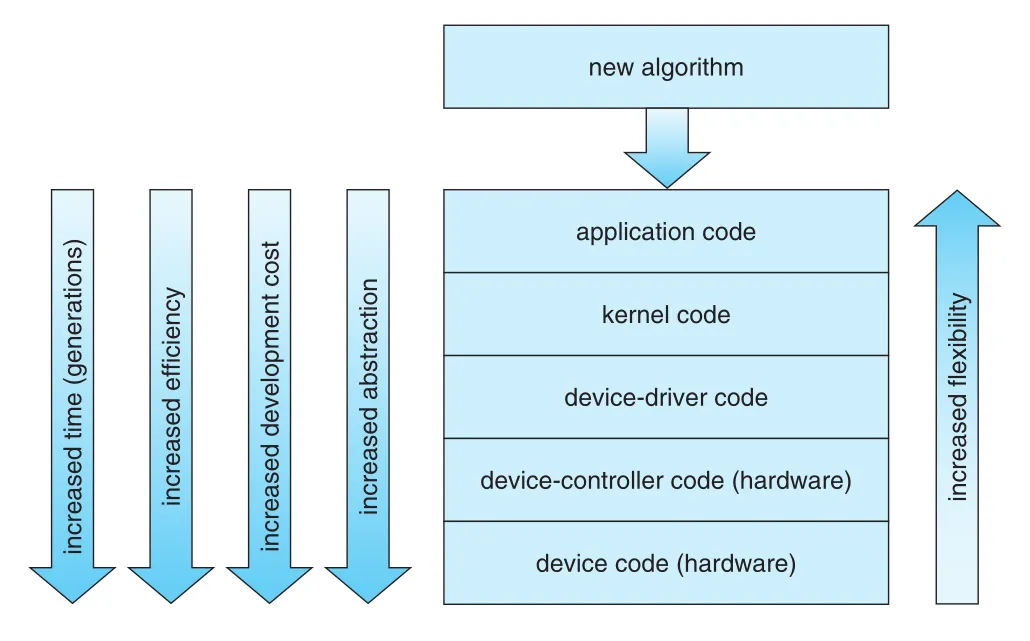
Figure 12.17 · PDF p. 651 · I/O 기능이 application code에서 kernel, device driver, controller/device hardware로 이동할 때 efficiency와 flexibility가 어떻게 변하는지
새로운 I/O algorithm은 보통 application level에서 실험하기 쉽다. Application code는 flexible하고 bug가 system crash로 이어질 가능성이 낮으며, driver reload/reboot 없이 빠르게 수정할 수 있다. 하지만 context switches overhead가 있고, internal kernel data structures나 efficient in-kernel messaging/threading/locking을 활용하기 어렵다. FUSE는 file systems를 user mode에서 작성하고 실행할 수 있게 하는 예다.
Algorithm이 가치 있음을 보이면 kernel implementation으로 옮겨 performance를 높일 수 있다. 대신 kernel은 크고 복잡하며, bug가 data corruption이나 system crash로 이어질 수 있으므로 debugging 부담이 크다. 가장 높은 performance는 device/controller hardware implementation에서 얻을 수 있지만, bug fix와 개선이 어렵고 development time/cost가 커지며 flexibility가 낮아진다. 예를 들어 hardware RAID controller가 kernel에게 individual block reads/writes의 order/location을 조정할 방법을 제공하지 않으면, kernel이 workload 정보를 알고 있어도 성능 최적화를 적용하기 어렵다.
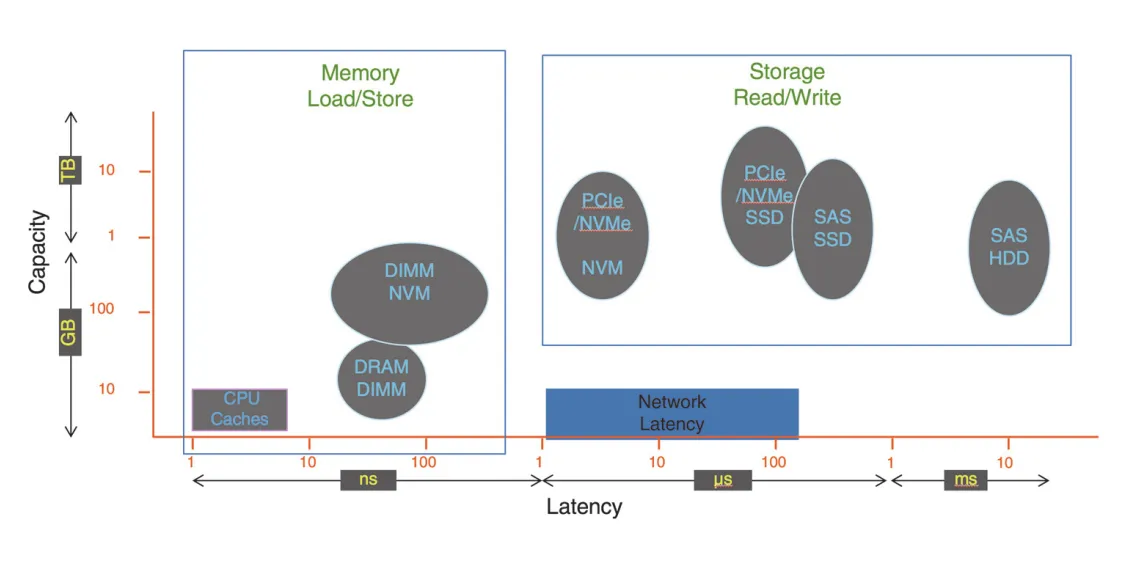
Figure 12.18 · PDF p. 652 · storage capacity와 I/O latency의 관계, 그리고 network latency가 I/O에 추가하는 성능 비용
NVM devices는 speed와 종류가 빠르게 증가하고 있으며, 일부 next-generation devices는 DRAM speed에 가까워지고 있다. 이는 I/O subsystem과 OS algorithms에 압력을 준다. Device가 빨라질수록 기존 kernel path의 context switch, interrupt, memory copy, locking, queueing overhead가 더 잘 드러난다. Network latency는 storage I/O에 별도의 performance tax를 추가한다.
12.8 Summary
Chapter 12는 I/O를 hardware elements와 kernel software layers가 만나는 지점으로 정리한다. Hardware 쪽 기본 요소는 buses, device controllers, devices이며, data movement는 CPU가 PIO로 직접 수행하거나 DMA controller에 offload할 수 있다. Device를 직접 control하는 kernel module은 device driver이고, applications에는 block devices, character-stream devices, memory-mapped files, network sockets, programmable interval timers 같은 categories로 정리된 system-call interface가 제공된다.
Kernel I/O subsystem은 I/O scheduling, buffering, caching, spooling, device reservation, error handling, access control, name translation, power management를 제공한다. 특히 name translation은 application의 character-string file/device name을 specific device driver, device address, physical I/O port 또는 bus controller로 이어 주는 여러 mapping layers로 구성된다. UNIX처럼 device names가 file-system namespace 안에 들어갈 수도 있고, MS-DOS처럼 separate device namespace를 둘 수도 있다.
STREAMS는 driver/protocol code를 stack처럼 조립하는 modular framework다. Data는 stream head, modules, driver end 사이에서 read/write queues와 messages를 통해 bidirectional하게 흐른다. I/O system calls는 physical device와 application 사이 software layers가 많아 CPU 비용이 크다. 주요 overhead는 kernel protection boundary를 넘는 context switching, device service를 위한 signal/interrupt handling, kernel buffers와 application space 사이 data copy다.
연결 관계
- Chapter 11의 storage scheduling과 연결된다. Chapter 11이 HDD/NVM의 device-level scheduling을 다뤘다면, Chapter 12는 모든 I/O devices에 대한 kernel-level scheduling, queues, buffers, drivers를 일반화한다.
- Chapter 9/10의 virtual memory와 연결된다.
memory-mapped file, DMA target address, kernel/user buffer copy, page fault interrupt는 VM mechanism과 직접 이어진다. - Chapter 13/14의 file system과 연결된다. File name, inode, mount table, open-file table, buffer cache, raw/direct I/O는 file-system implementation의 기반이다.
- Chapter 3/4/5의 process/thread/scheduling과 연결된다. Blocking I/O는 process를 wait queue로 보내고, completion interrupt는 ready queue로 되돌린다. Context switch와 scheduler cost가 I/O performance에 직접 영향을 준다.
- Chapter 16/17의 protection/security와 연결된다. Privileged I/O instructions, memory-mapped I/O protection, system-call mediation은 malicious/errant user processes로부터 system을 보호한다.
오해하기 쉬운 내용
polling은 항상 나쁜 방식이 아니다. Device가 빠르거나 I/O rate가 높아 interrupt overhead가 더 커질 때는 polling이 더 효율적일 수 있다.nonblocking I/O와asynchronous I/O는 같지 않다. Nonblocking read는 즉시 available data만 반환하고, asynchronous read는 전체 transfer를 예약한 뒤 나중에 completion을 통지한다.buffer와cache는 같은 말이 아니다. Buffer는 transfer 중 data의 유일한 copy일 수 있고, cache는 elsewhere에 원본이 있는 data의 빠른 copy다.DMA가 CPU 비용을 0으로 만드는 것은 아니다. CPU는 setup과 completion handling을 해야 하고, DMA가 memory bus를 점유하면cycle stealing으로 CPU memory access가 지연될 수 있다.- Device driver가 abstraction을 제공한다고 해서 모든 devices가 같은 semantics를 갖는 것은 아니다.
read()라는 이름은 같아도 user file, raw disk, process image에서 kernel이 수행하는 일은 다르다. - Hardware implementation은 성능이 가장 높을 수 있지만 항상 최선은 아니다. 수정/디버깅이 어렵고 flexibility가 떨어져 kernel이 workload 정보를 활용하지 못할 수 있다.
면접 질문
- OS의
I/O subsystem이 device drivers를 사용하는 이유를 abstraction과 hardware variety 관점에서 설명하라. memory-mapped I/O와 special I/O instructions 방식의 차이는 무엇인가?- Host-controller handshaking에서
busy bit와command-ready bit가 어떤 역할을 하는가? polling과interrupt-driven I/O의 trade-off를 설명하라.interrupt vector,interrupt chaining,interrupt priority가 각각 필요한 이유는 무엇인가?trap또는software interrupt가 system call과 page fault에서 어떻게 사용되는가?DMA가 CPU concurrency를 높이는 방식과cycle stealing문제가 무엇인지 설명하라.raw I/O,direct I/O,memory-mapped file access를 비교하라.blocking I/O,nonblocking I/O,asynchronous I/O의 차이를 예시와 함께 설명하라.- Kernel I/O subsystem의 buffering, caching, spooling은 각각 어떤 문제를 해결하는가?
- UNIX에서 pathname이 device driver와 controller address까지 연결되는 과정을
mount table,major/minor device number로 설명하라. - Blocking
read()request가 application에서 device controller, interrupt, ready queue까지 이동하는 life cycle을 설명하라. - STREAMS의
stream head,stream module,driver end,flow control은 각각 어떤 역할을 하는가? - I/O performance overhead의 주요 원천은 무엇이고, 이를 줄이는 설계 원칙은 무엇인가?